Learning to Act from Actionless Videos through Dense Correspondences
1. Quick overview of the paper
| Reading targeting item | content |
|---|---|
| What should the paper solve? | Learn executable robot strategies from a small number of video demonstrations without action annotations, avoiding the need to recollect action-labeled trajectories for each robot and each task. |
| The author's approach | Split the "action" into two reusable intermediate quantities: text conditional future video and inter-frame dense correspondence. The video represents future state changes, and optical flow and depth restore pixel changes to $SE(3)$ transformation. |
| most important results | Meta-World has an average success rate of 43.1%, which is higher than BC-Scratch 16.2%, BC-R3M 15.4%, and UniPi 6.1%; iTHOR has an average success rate of 31.3%, while the two BC baselines are only 2.1% and 0.4%; the zero-shot success rate from human pushing video to robot execution on Visual Pusher is 90% / 40 runs. |
| Things to note when reading | The method does not directly output actions from the video end-to-end, but relies heavily on optical flow, mask, depth, rigid body motion assumptions and manual action primitives; the appendix report of the real Panda experiment failed 8 times out of 10 tests and needs to be read together with the qualitative display of the main text. |
Difficulty rating: ★★★★☆. Experimental protocols that simultaneously understand diffusion video generation, optical flow/dense correspondence, camera projection geometry, robot motion primitives, and learning from observation are required.
Core contribution list
- Action inference without action tags: The author proposes to use dense correspondences between video frames to infer the rigid body transformation of the object or camera, and then convert it into actions, so the target task video does not require action annotation.
- Cross-task and cross-environment display: The same idea is used for Meta-World desktop operation, iTHOR navigation, Visual Pusher human video to robot pushing things, and Bridge/Panda real robot setup.
- Efficient video strategy modeling implementation: The paper provides a video policy model code framework, and through U-Net, factorized spatial-temporal block, first-frame conditioning and other designs, it can be trained on small environmental data with 4 V100s in one day.

2. Motivation
2.1 What problem should be solved?
A common bottleneck in robot learning is that state and action spaces are highly dependent on embodiment. Folding cloth, pouring water, pick-and-place, and navigation require different state representations and action interfaces; if policy learning requires expert action sequences for each task, the cost of data collection will increase rapidly with the number of robots and scenarios.
The authors capture the versatility of video data: RGB videos can record "how states change" and are easier to collect both on the Internet and in the lab. But the video itself doesn't tell the robot which joint trajectories or end-effector actions it should perform. The question of this article is: can we learn an executable strategy only from RGB video, and then translate the video changes into current robot actions during deployment.
2.2 Limitations of existing methods
- Direct behavior cloning requires action tags: The BC baseline has access to Meta-World's 15, 216 and iTHOR's 5, 757 labeled frame-action pairs, but these labels are exactly the data not used by our method.
- Video planning still lacks action: The UniPi class method expresses policy prediction as text-conditioned video generation, but requires a task-specific inverse dynamics model to infer actions from the video, and still relies on action annotation.
- End-to-end flow diffusion is unstable: The author tried to directly generate optical flow, but believed that the optical flow field is sparse and lacks the spatial/temporal smoothness of ordinary images. The diffusion model directly fitting the flow distribution is not as good as "two stages: first generate RGB video, and then use GMFlow to estimate optical flow."
- Computational cost and code availability: The author points out that the closest UniPi training costs more than 256 TPU pods and has limited source code availability; this paper compresses high-fidelity video policy training onto a small dataset in about a day on 4 GPUs.
2.3 The solution ideas of this article
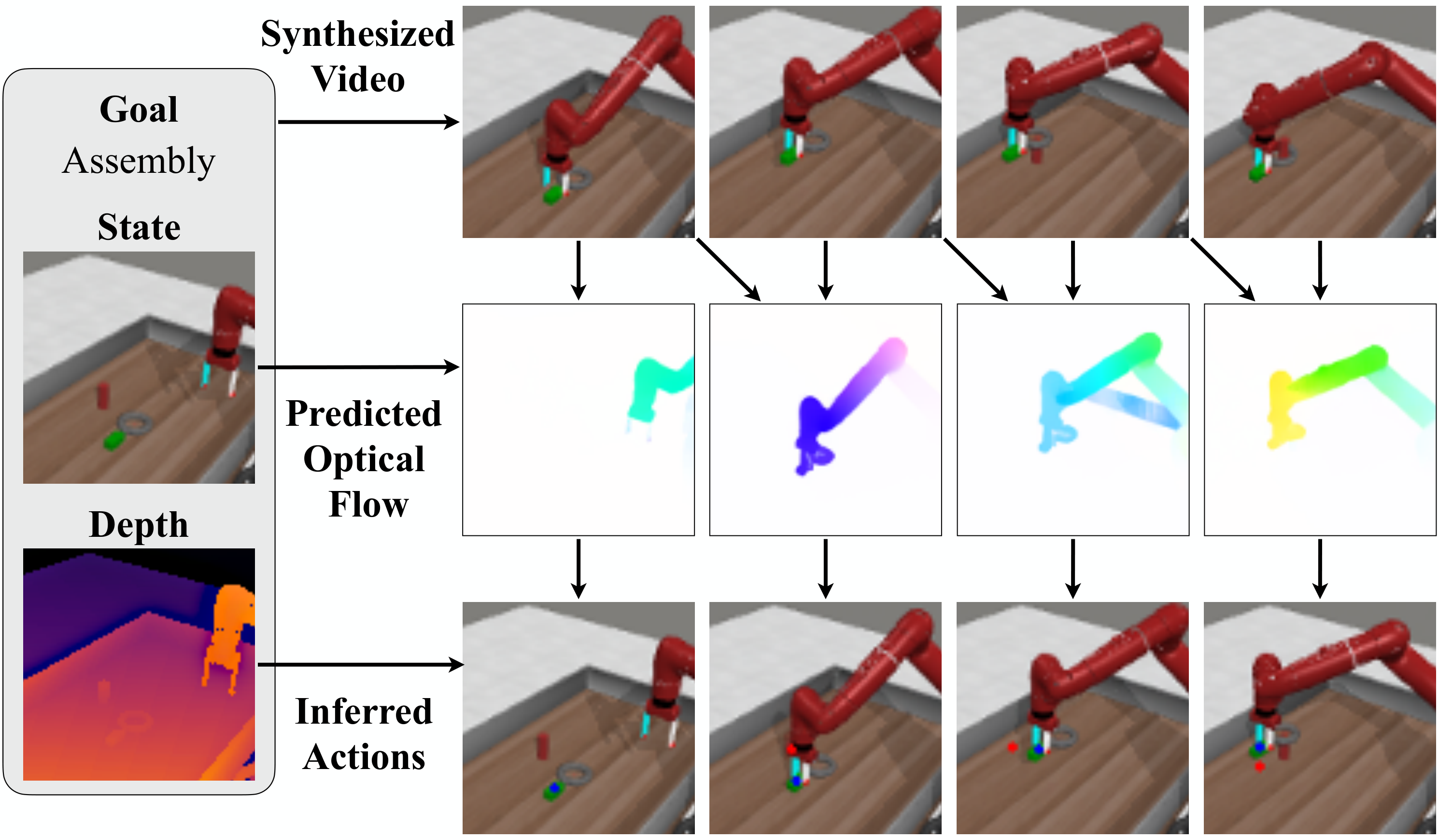
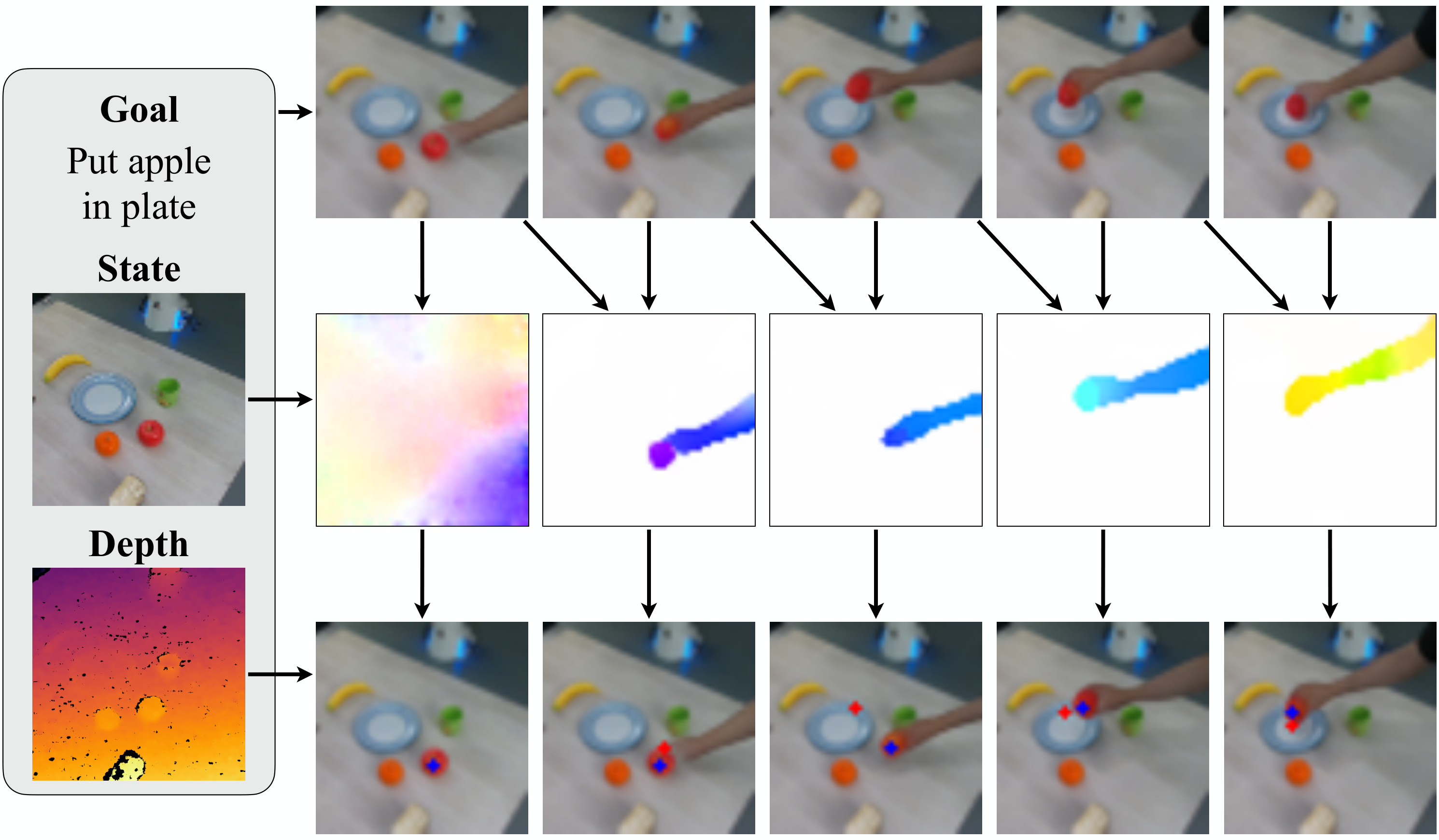
AVDC's high-level thinking is to "imagine the future first, then geometricize the actions." Given the current RGBD observation and text target, the model generates the next 8 frames of video; GMFlow outputs dense correspondence between adjacent generated frames; the initial depth and camera internal parameters upgrade the pixels to 3D; finally, the rigid body transformation of the object or scene is restored through optimization, and the transformation is converted into actions using ready-made grasp, push, IK, and navigation action mapping.
4. Detailed explanation of method
4.1 Overall pipeline
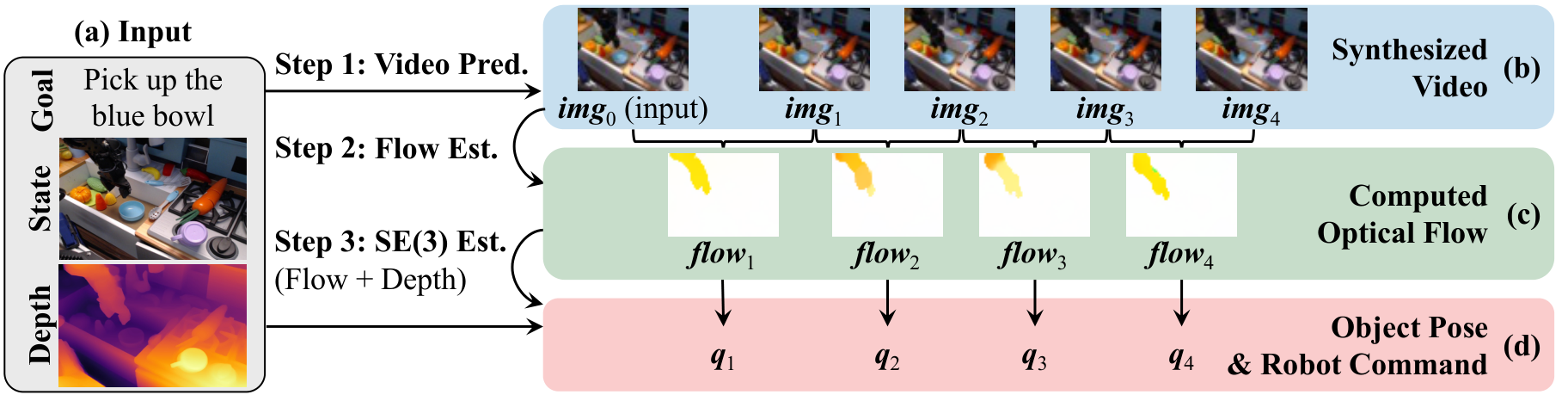
- Video generation: Conditional diffusion model learning $p(\textit{img}_{1: T}\mid \textit{img}_0, \textit{txt})$, experimental $T=8$. Input the current frame and text description, and output the future execution video.
- Optical flow estimation: Use GMFlow to predict optical flow for each pair of adjacent generated frames. The flow of each pixel is dense correspondence, indicating where this point will move in the next frame.
- Geometry recovery: Use the initial depth map and camera intrinsic parameters to convert the initial pixel points into 3D points; then find a rigid body transformation $T_t$ to make the projected position of the transformed 3D point match the 2D point tracked by the optical flow as much as possible.
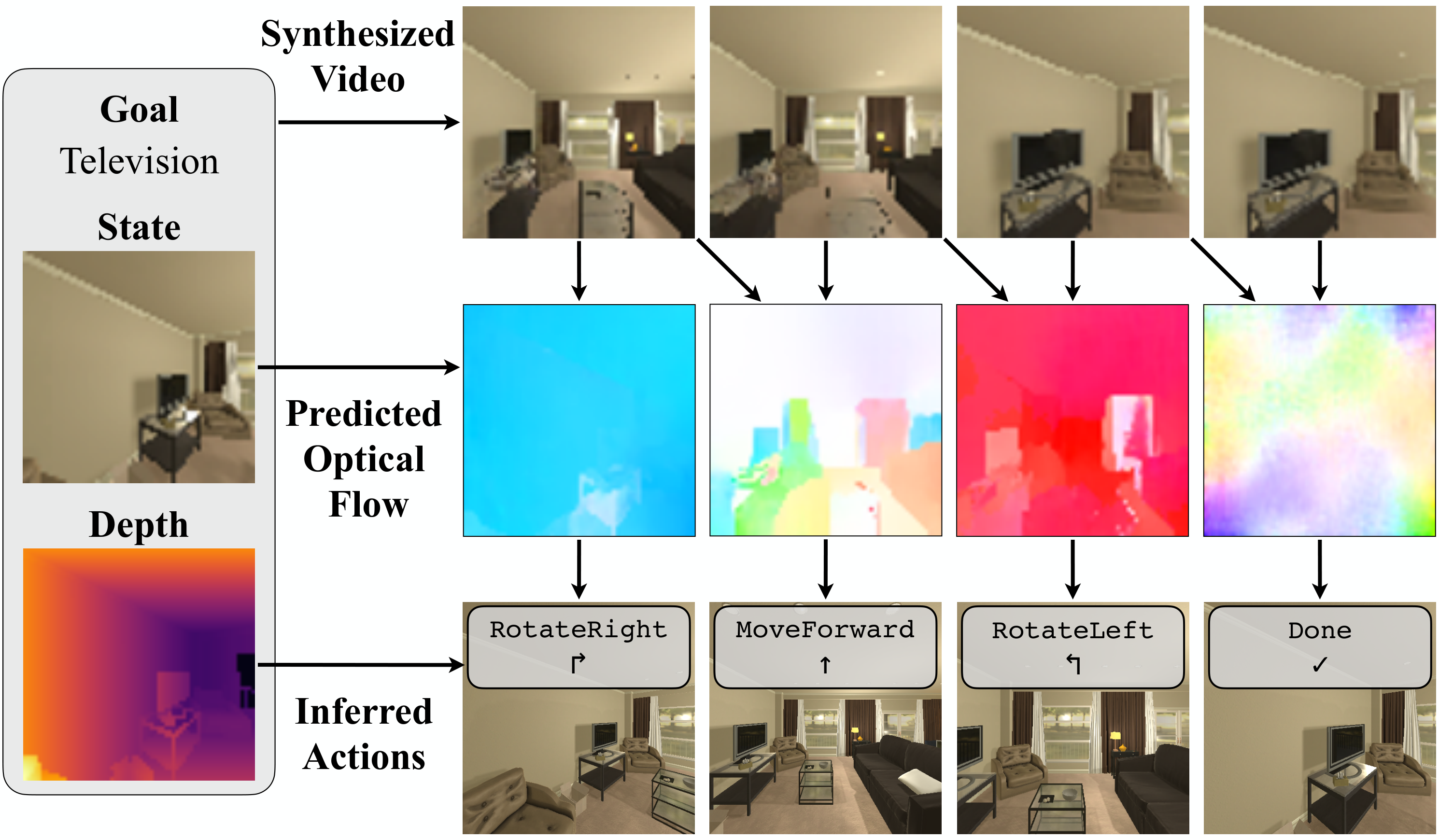
- Action execution: In a fixed camera scene, restore the target object transformation and convert it into grasp/push subgoals; in a navigation scene, invert the scene transformation to obtain camera/robot motion, and then map it to MoveForward, RotateLeft, RotateRight or Done.
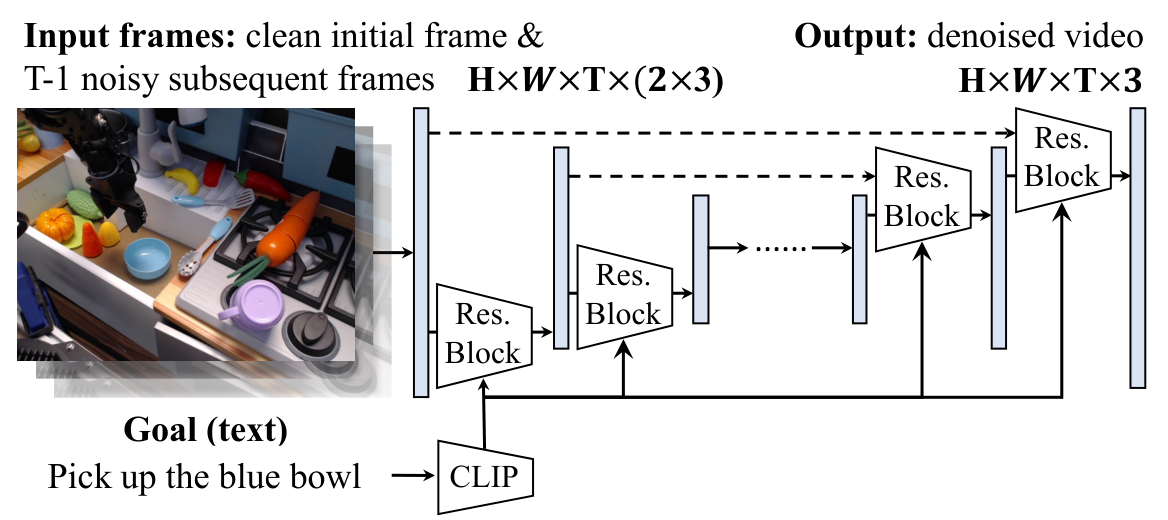
4.2 Text conditional video diffusion model
The goal of the diffusion model is to generate future frames from initial image and text conditions. The training loss written in the paper is:
Intuition: The model learns to denoise the future video after adding noise; the condition is the current frame and task text.
$$ \mathcal{L}_{\mathrm{MSE}} = \left\|\epsilon - \epsilon_\theta\left(\sqrt{1-\beta_t}\, \textit{img}_{1: T} + \sqrt{\beta_t}\, \epsilon, \ t \mid \textit{txt}\right) \right\|^2. $$| $\textit{img}_0$ | The current observation frame is used as the initial condition. |
| $\textit{img}_{1: T}$ | Future $T$ frame, experimental $T=8$. |
| $\textit{txt}$ | Natural language task description, encoded by fixed CLIP-Text encoder and Perceiver pooling. |
| $\epsilon_\theta$ | Video U-Net denoising network, using noise to predict training targets. |
| $\beta_t$ | Diffusion noise scheduling; appendix explains training/inference timesteps=100, beta schedule=cosine, objective=predict_v. |
Architecturally, the author starts from Dhariwal & Nichol's image diffusion U-Net and extends it to video. To enhance consistency with the initial frame, they spliced the conditional frame $\textit{img}_0$ to each future frame in the RGB dimension instead of just adding one frame in front of the timeline. Factorized spatial-temporal convolution is used in the ResNet block: spatial convolution is first performed on each time step, and then temporal convolution is performed on each spatial position, replacing the expensive complete 3D convolution.
4.3 Recovering action from optical flow and depth
In the object manipulation task of a fixed camera, let the initial 3D point set of the target object be $\{x_i\}$, the camera internal parameter be $K$, and $T_t$ is the rigid body transformation of the object in frame $t$ relative to the initial frame. The projection relationship is $K T_t x_i = (u_t, v_t, d_t)$, and the corresponding 2D point is $(u_t/d_t, v_t/d_t)$. GMFlow gives the tracking pixel $(u_t^i, v_t^i)$ of point $x_i$ at frame $t$, so the author optimizes:
This step only requires the initial frame depth, not future frame depth. Because $T_t$ is assumed to be a rigid body transformation, the future 3D depth is implicitly determined through the projected geometry.
Derivation and completion: why this loss is enough to restore $T_t$
The initial point $x_i$ has been determined by the initial RGBD and camera internal parameters. Given a candidate rigid body transformation $T_t$, $x_i$ can be placed under the object coordinates of frame $t$, and then projected to the image plane via $K$. Optical flow provides the 2D position of the same physical point in the generated video frame $t$, so minimizing the projection error is to find the 6DoF transformation that best explains all dense correspondence. In actual implementation, the Meta-World appendix first uses RANSAC to find inliers from 2D correspondence, and then uses these inliers to estimate the 3D transformation. Appendix: Meta-World setup.
4.4 Action mapping in different environments
| environment | The recovered geometry | action mapping | Key implementation details |
|---|---|---|---|
| Meta-World | Target object rigid body transformation | Select grasp or push according to whether the vertical displacement exceeds 10 cm; grasp mode closes the gripper and then follows subgoals, and push mode puts the manipulator in the pushable direction and then follows subgoals. | Sample $N=500$ mask points, using the object centroid as the contact point; use RANSAC to filter correspondence outliers Appendix: 4.1. |
| iTHOR | Static scene transformation, inverse to obtain camera motion | Observe the imaginary point 1m in front of the robot: Done if the displacement is less than 1 mm, MoveForward if the horizontal displacement is less than 25 cm, otherwise press the direction RotateLeft/RotateRight. | Do not track a single object; use the entire frame flow to filter key points that move out of the image; re-plan when inliers are less than 10% of the initial sampling points Appendix: iTHOR setup. |
| Real Panda | Target object initial pose and target pose | Assuming the target is top-graspable and does not require redirection, use the IK solver to generate the robot trajectory. | The hardware is Franka Emika Panda + Intel Realsense D435; appendix explains that target segmentation is manually specified, and small objects/low resolution cause 3D rotation to be unstable Appendix: real-world setup. |
4.5 Key points of training and inference
5. Experiment
5.1 Baselines and variants
| method | training signal | function |
|---|---|---|
| BC-Scratch | Train ResNet-18 + CLIP text + MLP from scratch using expert action labels. | Measuring the difficulty of regular behavioral cloning in a multitasking setting. |
| BC-R3M | Also uses action tags, but the visual backbone is initialized to R3M. | Testing whether robot pretrained visual representations aid action prediction. |
| UniPi baseline | Use the video generated by AVDC to train the inverse dynamics model to output actions. | The route representing "Video Planning + Learning Inverse Dynamics" still requires action tags. |
| AVDC (Flow) | Directly predict inter-frame optical flow. | Verify whether generating flow directly is better than RGB video first and then GMFlow. |
| AVDC (No Replan) | Full geometric motion is restored, but open-loop execution is performed. | Verify the effect of closed-loop replanning. |
| AVDC (Full) | RGB video generation + GMFlow + geometric motion recovery + replanning. | The main method of the paper. |
5.2 Meta-World desktop operation
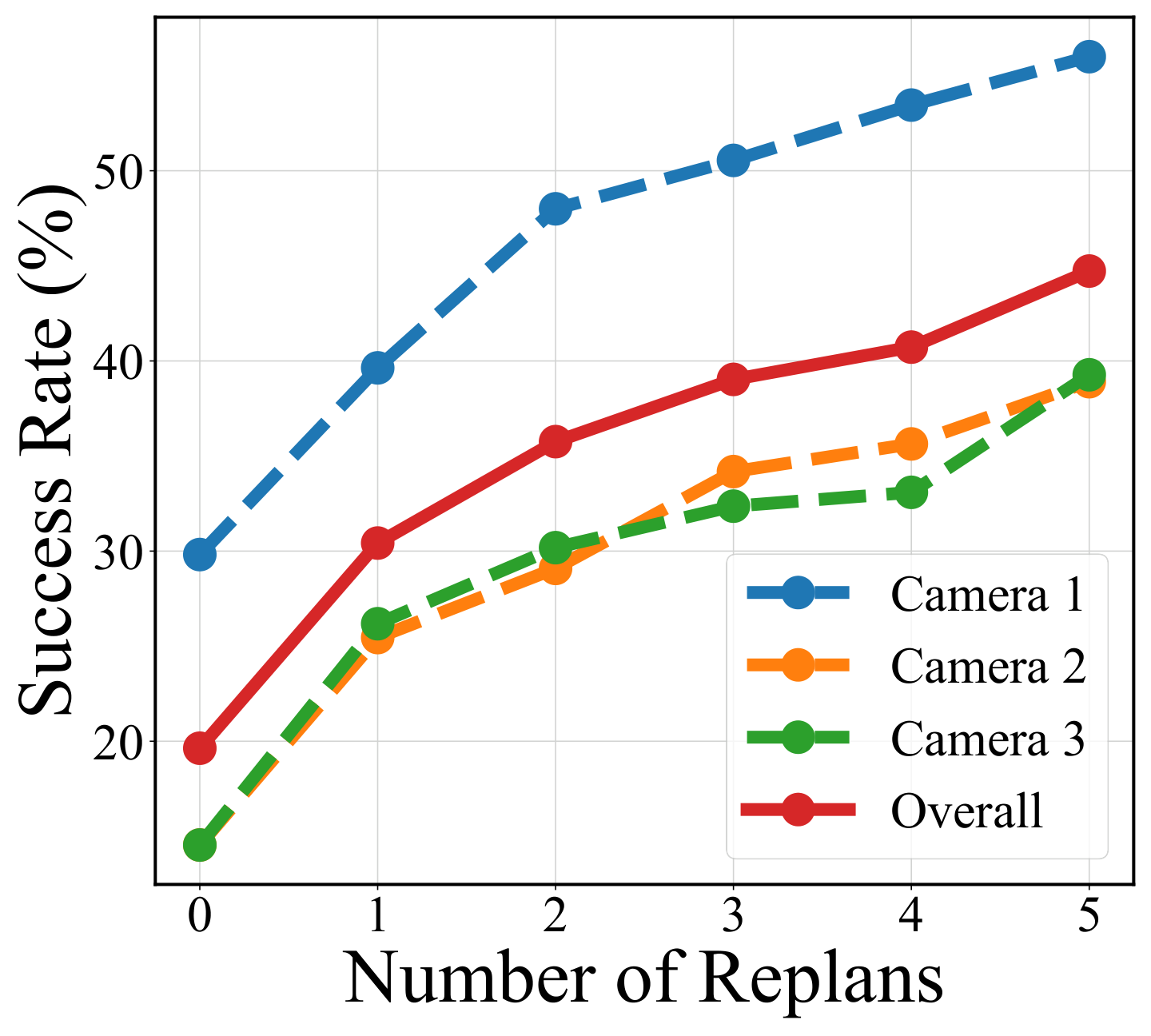
Setup: 11 Sawyer robot arm operation tasks, 3 camera positions per task, 5 demonstrations per camera position, 165 videos in total. Methods and variants use ground-truth target object segmentation mask; BC baseline uses action tags. Evaluated as average success rate for 25 seeds per task, per camera position.
| method | Overall | key phenomena |
|---|---|---|
| BC-Scratch | 16.2% | Even with 15, 216 action labels, multi-task generalization is still weak. |
| BC-R3M | 15.4% | R3M initialization did not improve the overall results. |
| UniPi (With Replan) | 6.1% | Requires inverse dynamics, overall lower than BC. |
| AVDC (Flow) | 13.7% | It performs well on button-press-topdown, faucet-close, and handle-press, but most tasks are poor and supports the author's "two-stage" design. |
| AVDC (No Replan) | 19.6% | It exceeds BC, but is significantly lower than the closed-loop version. |
| AVDC (Full) | 43.1% | The overall best among 11 tasks; door-open 72.0%, door-close 89.3%, handle-press 81.3%. |
5.3 iTHOR target navigation
Settings: 12 target objects, distributed in 4 types of rooms; MoveForward, RotateLeft, RotateRight, and Done can be executed at each time step. The success criterion is that the target object comes into view and is within 1.5m, or Done is predicted in the correct state. 3 objects per room, 20 episodes per object.
| Room | BC-Scratch | BC-R3M | AVDC |
|---|---|---|---|
| Kitchen | 1.7% | 0.0% | 26.7% |
| Living Room | 3.3% | 0.0% | 23.3% |
| Bedroom | 1.7% | 1.7% | 38.3% |
| Bathroom | 1.7% | 0.0% | 36.7% |
| Overall | 2.1% | 0.4% | 31.3% |
The author explains: BC-R3M is worse than BC-Scratch, probably because R3M is pre-trained on robot operation tasks and is not suitable for visual navigation. The intermediate video of AVDC can show the agent navigating to the target, and the optical flow can easily be mapped to movement or rotation; when there is no flow, it means that the target has been found and Done is selected.
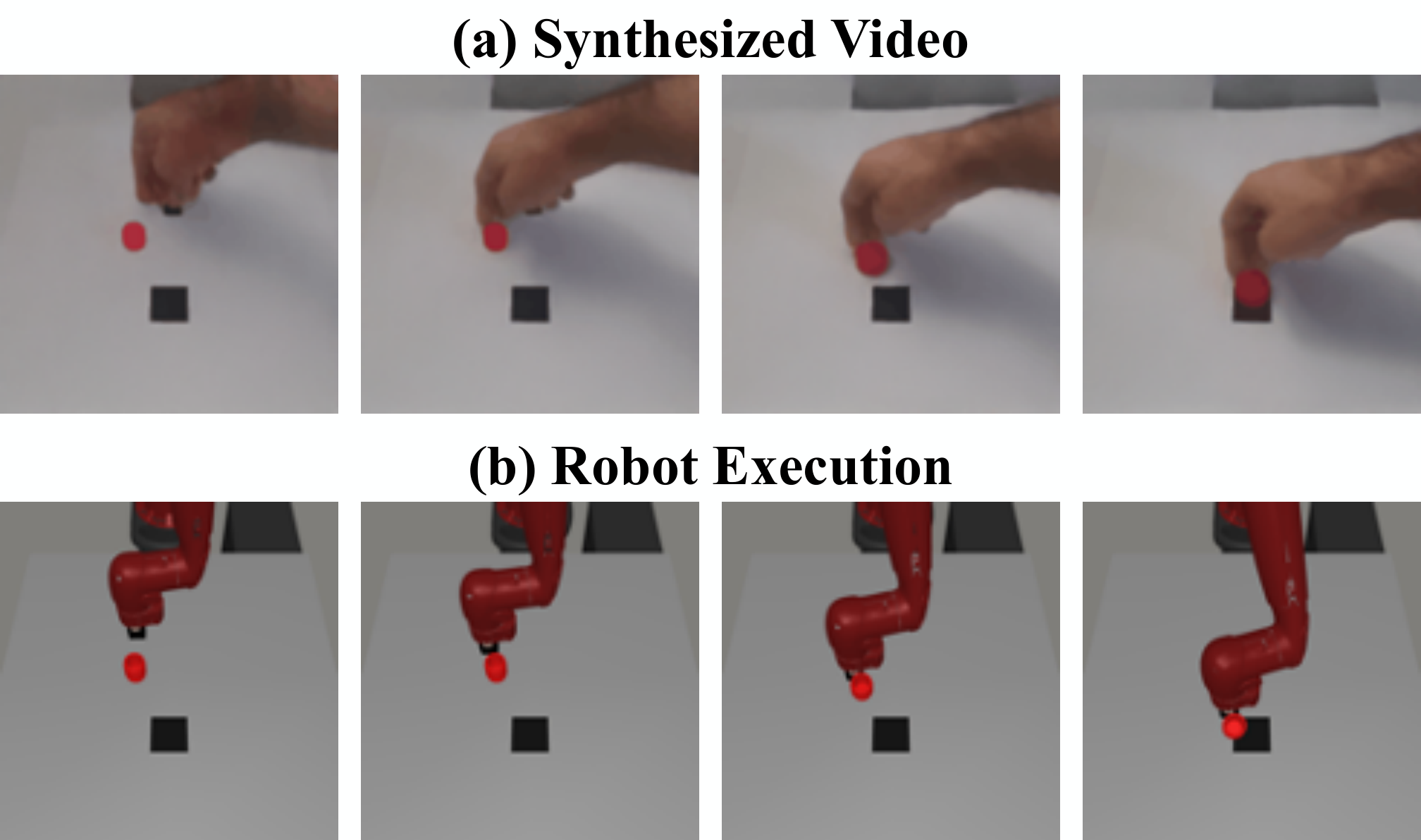
5.4 Cross-embodiment: human video to robot recommendation
The Visual Pusher experiment only uses 198 actionless human pushing videos to train the video diffusion model. The U-Net architecture is the same as Meta-World, and the training is 10k steps; then a zero-shot test is performed on the simulated robot pushing task without fine-tuning. The result was a 90% success rate in 40 runs.
5.5 Bridge to reality Franka Panda
The Bridge dataset contains 33, 078 WidowX 250 kitchen task teleoperation videos, without depth. The author first used Bridge to train the video generation model, and then used 20 human hand demonstration videos to fine-tune in his own real desktop environment. Realistic setup using Franka Emika Panda and a permanently installed Intel Realsense D435 RGBD camera.
The main article emphasizes that the model can generate videos, predict optical flow, identify targets and infer actions; the appendix gives a more specific failure analysis: the real experiment failed 8 times out of 10 tests, 75% of the failure reasons came from the wrong plan generated by the video diffusion model (selecting the wrong object or placing the wrong target), and 25% came from the discontinuity of the generated video, such as the disappearance of objects in the middle frame Appendix: real-world failure mode.

5.6 Appendix Supplementary Experiments
| Appendix content | result | meaning |
|---|---|---|
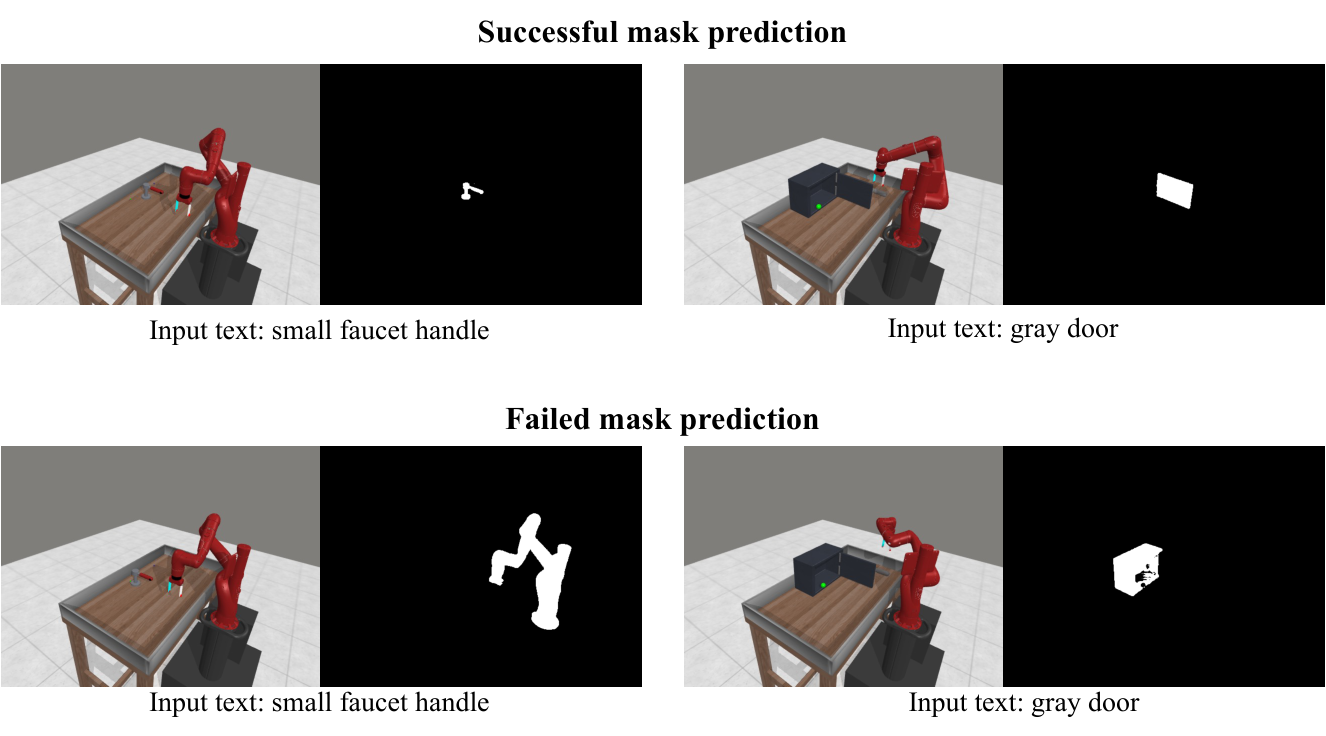
| Object mask with segmentation models | Using Language Segment-Anything instead of GT mask, the average success rate in Meta-World 11 tasks is 34.5%, which is 8.6 percentage points lower than GT mask's 43.1%. | The method is sensitive to segmentation quality; the main results of the paper use GT mask in Meta-World. |
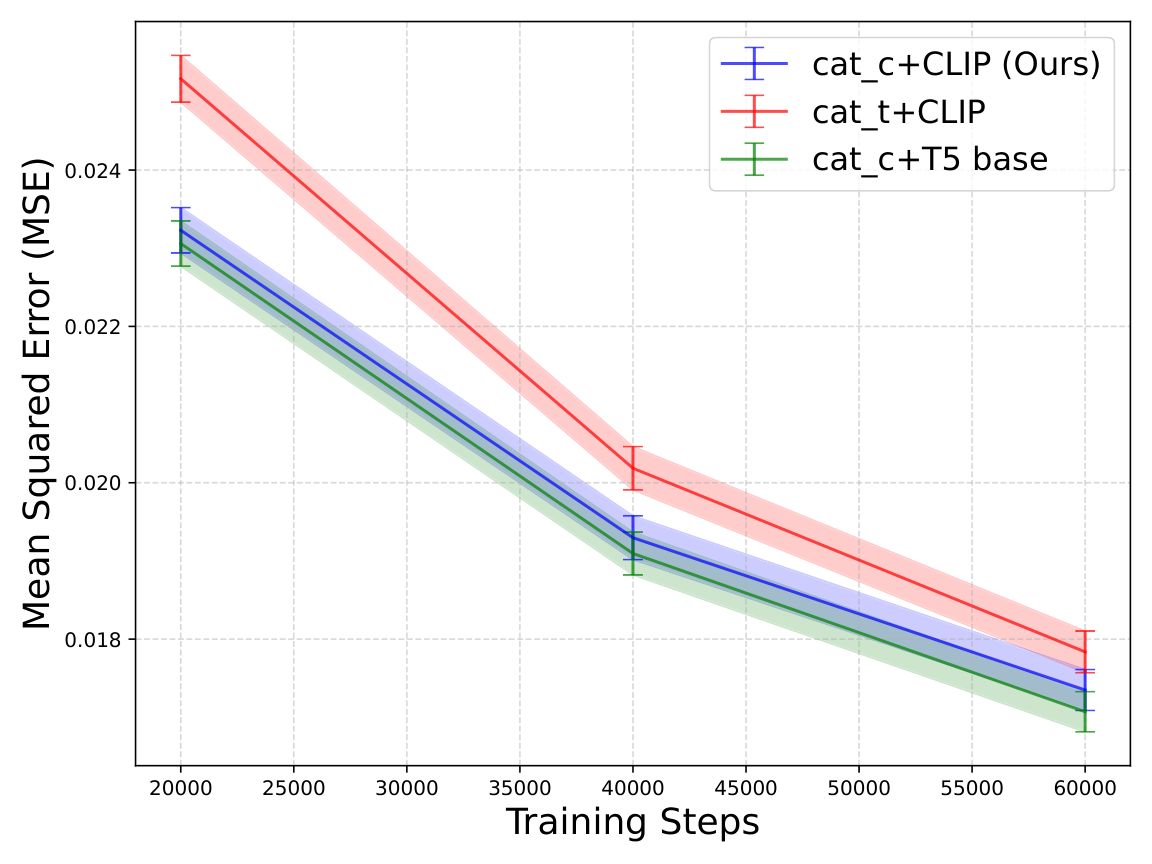
| First-frame conditioning | The last frame MSE of cat_c early in Bridge training is lower than the temporal dimension splicing cat_t; each point is the mean of 4000 samples, and the error bars are the standard error. | RGB channel-wise conditioning is part of the efficiency design. |
| Text encoder | The difference in video generation MSE between CLIP-Text 63M and T5-base 110M is not significant. | The text encoder is not the main bottleneck; the authors use fixed CLIP-Text + Perceiver. |
| Bridge zero-shot real scenes | The Bridge model can generate reasonable videos on complex real-life kitchen images outside the toy kitchen, but the original resolution is 48x64 and the video is blurry. | The video generation model has certain scene migration, but low resolution will affect motion recovery. |
6. Summary of recurrence information
6.1 Data and Evaluation Protocol
| scene | training data | Assessment |
|---|---|---|
| Meta-World | 11 tasks x 3 cameras x 5 demonstrations = 165 videos; BC baseline uses 15, 216 frame-action pairs. | 25 seeds per task, per camera position, average success rate reported. |
| iTHOR | 240 videos; BC baseline uses 5, 757 frame-action pairs. | 12 object navigation tasks, 4 room types, 20 episodes per object. |
| Visual Pusher | 198 human pushing videos, no action labels; training 10k steps. | Simulated robot pushing, zero-shot, no fine-tuning, 40 runs. |
| Bridge/Panda | Bridge 33, 078 WidowX videos; 20 hands-on demonstrations of fine-tuning in real environments. | Real pick-and-place tabletop task, with 10 trials failure analysis provided in the appendix. |
6.2 Model hyperparameters
Common settings for all models: dropout=0, num_head_channels=32, train/inference timesteps=100, training objective=predict_v, beta_schedule=cosine, loss_function=l2, min_snr_gamma=5, learning_rate=1e-4, ema_update_steps=10, ema_decay=0.999 Appendix: Video Diffusion Model.
| parameters | Meta-World | iTHOR | Bridge |
|---|---|---|---|
| num_parameters | 201M | 109M | 166M |
| resolution | 128 x 128 | 64 x 64 | 48 x 64 |
| base_channels | 128 | 128 | 160 |
| num_res_block | 2 | 3 | 3 |
| attention_resolutions | 8, 16 | 4, 8 | 4, 8 |
| channel_mult | 1, 2, 3, 4, 5 | 1, 2, 4 | 1, 2, 4 |
| batch_size | 16 | 32 | 32 |
| training_timesteps | 60k | 80k | 180k |
6.3 Perceiver text aggregator
| Parameter | Value |
|---|---|
| layers | 2 |
| num_attn_heads | 8 |
| num_head_channels | 64 |
| num_output_tokens | 64 |
| num_output_tokens_from_pooled | 4 |
| max_seq_len | 512 |
| ff_expansion_factor | 4 |
6.4 Hardware and time
- Training hardware: 4 x V100 32GB. Meta-World takes about 24 hours to train 165 videos; iTHOR takes about 24 hours to train 240 videos; the real experiment takes about 48 hours Bridge pretraining + 4 hours human-data fine-tuning.
- Inference hardware: RTX 3080Ti. In a single round of Meta-World planning, video generation takes about 10.57s, flow prediction takes about 0.28s for each pair of frames, action regression takes about 1.31s, and action execution takes about 1.53s.
- Code: The appendix to the paper says that the supplementary zip is included
./codebase_AVDC; Project page provides GitHub repository flow-diffusion/AVDC.
tmp/arxiv_source_2310.08576/; PDF at tmp/2310.08576.pdf; The source compressed package is in tmp/arxiv_source_2310.08576.tar.gz; The report chart is in Report/2310.08576/figures/. These temporary materials have not yet been deleted to facilitate continued verification.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
According to the paper's own experimental and method design, the core value is to explicitly remove the missing link between "video without action tags" and "executable actions": the video model is only responsible for generating future visual states, and dense correspondence and geometric optimization are responsible for converting state changes into executable transformations. This split allows the method to be trained using RGB-only demonstrations, while leaving motion recovery to more mature modules such as depth, flow, mask, IK, and motion primitives.
7.2 Why the results hold up
The support for the results mainly comes from three levels. First, the Meta-World table contains multiple action tag baselines and multiple AVDC variants. The Full version is higher than the No Replan and Flow versions and supports "replanning + two-stage RGB-to-flow" design. Second, if the iTHOR task is replaced by navigation, the action space and object operations are completely different, but the same correspondence-to-transform logic can still exceed two BC baselines. Third, the appendix ablation exposes the impact of engineering variables such as segmentation, first-frame conditioning, and number of DDIM steps, and does not only report successful cases of the main method.
7.3 Author's statement of limitations
- Occlusion: When the robot arm covers most areas of the object, the algorithm may lose the object track.
- Optical flow vulnerability: Rapid illumination changes or large attitude changes can render optical flow prediction ineffective.
- Missing contact information: Real manipulation requires grasp or contact surface, and this information cannot be directly transferred from videos of different human and robotic hands.
- Missing force information: RGB video does not have force information, and the author recommends using real interactive learning or fine-tuning to make up for it in the future.
- Real experiment failed: The appendix reports that real Panda failed 8 out of 10 times, 75% due to video model planning errors and 25% due to discontinuities in the generated video.
7.4 Applicable boundaries
| Suitable for use cases | Not suitable or requires additional modules |
|---|---|
| Key changes to the task can be approximated as rigid body transformations of the object or camera. | Flexible objects, complex contacts, force control tasks, or tasks where contact surfaces must be inferred. |
| Initial depth can be obtained during deployment, or can be replaced by monocular depth estimation. | Environments without reliable depth, camera calibration or object/scene masks. |
| There is a clear relationship between language goals and visual changes, such as pick up fruit, navigate to object, push object. | Goals require hidden states, long-term multi-stage symbolic planning, or non-visual feedback. |
| You can accept ten seconds of planning latency, or use sampling acceleration such as DDIM. | Real-time strongly constrained control tasks; even using DDIM 10 steps still sacrifices some success rate. |