Video Language Planning
1. 论文速览
| 速览问题 | 简明回答 |
|---|---|
| 论文要解决什么 | LLM/VLM 擅长长程语义规划但缺少细粒度物理动态推理;视频模型能表达动态但短 horizon 容易退化。论文要解决的是:如何把二者组合起来,为复杂长程机器人任务生成可执行的多模态视频语言计划。 |
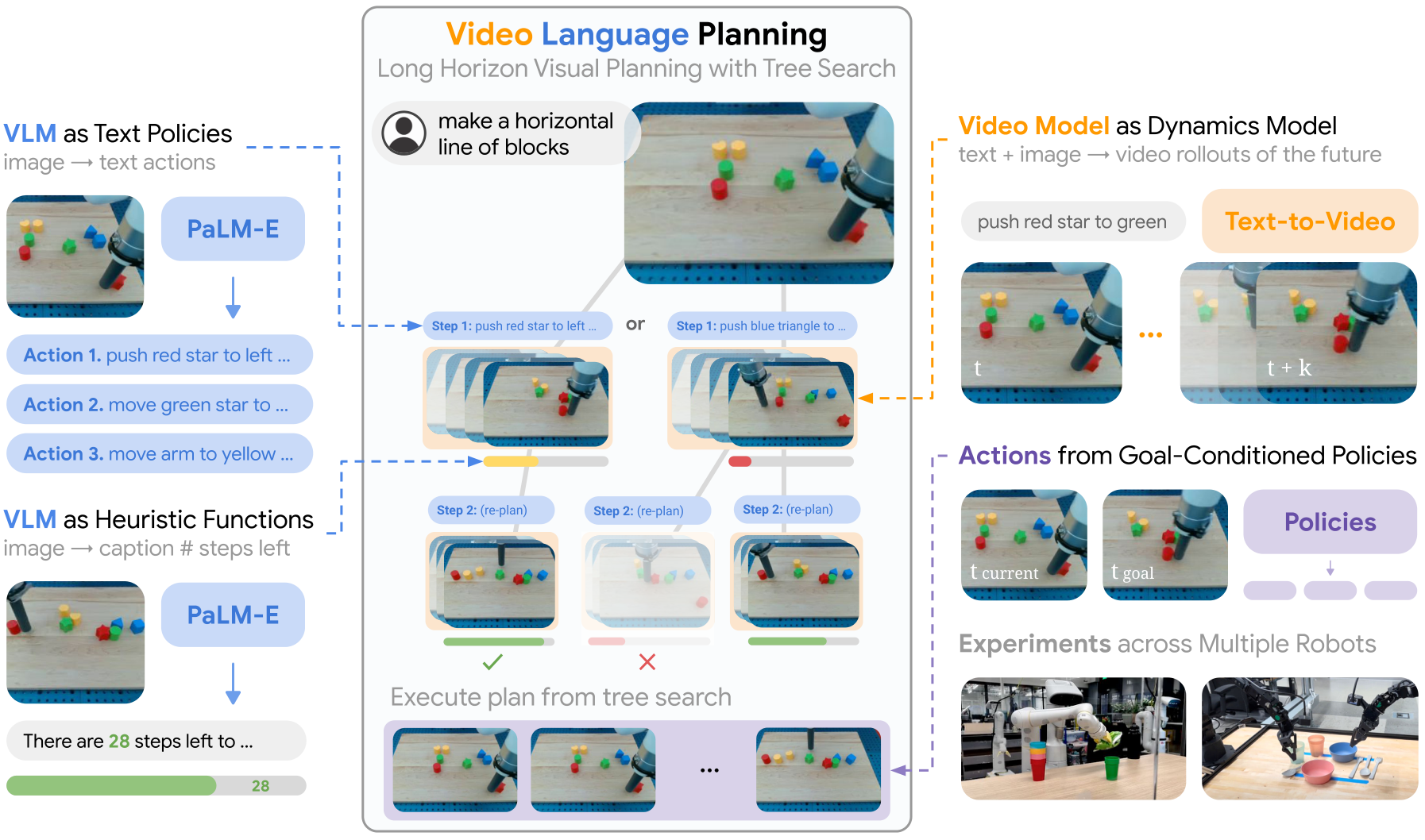
| 作者的方法抓手 | 用 forward tree search 组合三个模块:$\pi_{\text{VLM}}(x,g)$ 生成候选文本动作,$f_{\text{VM}}(x,a)$ 生成该动作的短视频 rollout,$H_{\text{VLM}}(x,g)$ 估计离目标还剩多少步并剪枝。 |
| 最重要的结果 | 在 Language Table 长程执行任务中,VLP 在 Move to Area / Group by Color / Make Line 上分别达到 64% / 92% / 16% completion,显著高于 UniPi、LAVA、RT-2 和 PaLM-E;生成视频计划准确率在 sim/real 多任务上也明显高于无 value function 的组合和 UniPi。 |
| 阅读时要注意的点 | 不要把 VLP 理解成一个端到端 policy。它的核心是 test-time composition 与 search:视频模型不是直接控制器,而是 dynamics-like rollout model;真正执行依赖 goal-conditioned policy,并且规划质量用更多推理计算换来。 |
难度评级:★★★★☆。需要理解 VLM/LLM planning、text-to-video diffusion、tree search、goal-conditioned policy、长程机器人评估。
关键词:video language planning, VLM, text-to-video dynamics model, forward search, heuristic function, goal-conditioned policy, long-horizon manipulation。
核心贡献清单
- 提出 Video Language Planning (VLP)。将 VLM 与视频模型通过树搜索组合,用语言和视频共同表达长程计划。
- 把 VLM 同时用作 policy 和 heuristic。policy 产生下一步文本动作,heuristic 预测离目标完成还剩多少动作,从而评估视频 rollout。
- 把 text-to-video model 用作 dynamics model。给定当前图像和短文本动作,预测未来短视频,递归拼成长程视频计划。
- 展示推理预算可扩展性。增加 language branch、video branch 和 beam 数能提升视频计划成功率。
- 在三类机器人平台上展示执行。包括 Language Table、7DoF mobile manipulator、14DoF bi-manual ALOHA。
2. 动机
2.1 长程任务为什么难
真实机器人长程任务同时需要两类能力:一是高层语义规划,即知道下一步应该做什么;二是低层动态预测,即知道执行某个动作后世界会如何变化。经典 task and motion planning 就长期依赖这种分解,但大模型时代的问题是:能不能用预训练 VLM/视频模型来替代手写 symbolic model 与动力学模型。
2.2 单独使用 LLM/VLM 的局限
LLM 可以生成 step-by-step 文本计划,VLM 可以把图像观察纳入计划;但它们主要受静态图文/问答数据训练,容易缺少动态推理能力。例如只看当前图像和目标,模型可能知道“把碗叠起来”这个语义步骤,却不一定能预测移动、碰撞、遮挡、物体是否可达等视觉动态。
2.3 单独使用视频模型的局限
Text-to-video model 能生成丰富的未来视觉状态,承载比文本更细的物理和空间信息;但生成高质量长视频很难,直接给一个长程 instruction 要求模型一次生成几百帧计划,容易失去一致性或没法完成最终目标。
2.4 本文的高层思路
VLP 的抓手是组合:VLM 负责抽象动作候选和进度评估,视频模型负责短程动态 rollout,树搜索把多个短程 rollout 串成长期计划。这样既不用 VLM 单独想象物理动态,也不用视频模型单独承担完整长程规划。
4. 问题形式化
输入是当前视觉观察 $x_0$ 和自然语言长程目标 $g$。输出是长视频计划 $\{x_t\}_{1:T}$,其中每个图像 $x_t$ 都可以被视为一个视觉子目标。论文假设图像可作为世界状态表示,并用 image goal-conditioned policy 将视觉子目标转成低层动作。
4.1 三个核心函数
| 函数 | 输入输出 | 角色 |
|---|---|---|
| $\pi_{\text{VLM}}(x,g)\rightarrow a$ | 当前图像 $x$ 与目标 $g$,输出文本动作 $a$。 | 高层 policy,提出下一步应该尝试的抽象动作。 |
| $f_{\text{VM}}(x,a)\rightarrow x_{1:S}$ | 当前图像 $x$ 与短文本动作 $a$,输出短程未来视频。 | dynamics-like video model,模拟执行动作后的视觉状态。 |
| $H_{\text{VLM}}(x,g)\rightarrow \mathbb{R}$ | 某个未来图像状态 $x$ 与目标 $g$,输出 heuristic score。 | value/heuristic,评估状态离目标完成还有多近。 |
4.2 优化目标
VLP 搜索的是:由 VLM policy 和视频模型能采样出来的长视频计划中,哪一个最终状态最接近任务完成。
$$x_{1:H}^{*}=\arg\max_{x_{1:H}\sim f_{\text{VM}},\pi_{\text{VLM}}} H_{\text{VLM}}(x_H,g)$$| $x_{1:H}$ | 通过多个短视频 rollout 拼接得到的长程视频计划。 |
| $x_H$ | 长视频计划的最终图像状态。 |
| $H_{\text{VLM}}(x_H,g)$ | VLM heuristic 对最终状态是否接近目标的估计。 |
| $f_{\text{VM}},\pi_{\text{VLM}}$ | 限定候选计划必须由文本动作 policy 和视频模型共同生成。 |
注意这里不是传统 RL 里对真实环境 reward 求最优,而是在模型生成的未来视频树中搜索最有希望完成任务的计划。
5. 方法详解
5.1 VLM as Policy
VLM policy 负责从当前图像和目标中生成候选文本动作。论文实现上遵循 PaLM-E 思路,将自然语言目标与当前图像 token embedding 作为上下文。作者尝试两种构造方式:一种是提供示例 text action labels 后让 VLM 预测动作;另一种是用长轨迹中的随机短片段 $x_{1:S}$ 及其 abstract action labels 微调 PaLM-E。
5.2 Video Model as Dynamics Model
给定当前图像 $x$ 和抽象文本动作 $a$,视频模型 $f_{\text{VM}}(x,a)$ 生成短视频 $x_{1:S}$。这段视频同时提供两个东西:一是动作执行后的可能结果状态,二是从当前状态过渡到结果状态的低层视觉路径。训练数据是短 image trajectory snippets 及对应 language labels。
5.3 VLM as Heuristic Function
VLP 需要在很多候选 rollout 中选一个。为此作者训练 $H_{\text{VLM}}(x,g)$,输入未来图像和长程目标,输出从当前状态到目标完成还需要多少步。训练方式是:从能完成长程目标 $g$ 的 trajectory snippets $x_{1:H}$ 中取某个 $x_t$,让 PaLM-E 预测离 trajectory 结束还剩多少步。实际用于搜索时取预测步数的负值,因此值越高表示越接近完成。
5.4 Tree Search 过程
算法维护 $B$ 条 parallel video plan beams。每个 planning step,对每条 beam:
这里的计算预算由三个超参控制:language branching factor $A$、video branching factor $D$、planning beams $B$。更多预算会生成更多候选文本动作和视频 rollout,因此可能找到更好的计划,但推理时间也更长。
5.5 防止 exploitative model dynamics
当搜索直接优化 $H_{\text{VLM}}$ 时,可能 exploit 视频模型的伪动态。例如物体突然瞬移到目标位置,或最终帧遮挡了未完成部分,heuristic 却给高分。论文因此加入阈值过滤:如果一个 rollout 让 heuristic estimate 的提升超过固定 threshold,就丢弃该视频,避免用不物理的模型漏洞换高分。

5.6 从视频计划到动作执行
与上一篇 UniPi 中逐帧 inverse dynamics 不同,这篇论文强调许多相邻视频帧之间不是单个动作能到达的,因此用短程 goal-conditioned policy:
它输入当前图像 $x$ 和视频计划中的目标帧 $x_g$,输出让机器人朝 $x_g$ 前进的低层控制 $u$。训练时从控制轨迹中随机采样 $x_t$ 与未来状态 $x_{t+h}$,用 $\pi_{\text{control}}(x_t,x_{t+h})$ 预测 $u_t$。
长程执行还会使用 receding horizon control:固定 horizon 生成计划,执行一段后重新观测并 replanning,减轻执行误差累积。
5.7 附录中的实现细节
| 模块 | 配置 | 来源 |
|---|---|---|
| 视频模型训练 | 沿用 UniPi / text-to-video diffusion 架构;base text-conditioned video generation at $24\times40$,再 super-resolve 到 $48\times80$ 与 $192\times320$;每个分辨率生成 16 帧。 | 附录 Training Details |
| 视频模型资源 | base text-conditioned video model 用 64 TPUv3 pods 训练 3 天,高分辨率 super-resolution models 训练 1 天;不同 domain 训练 separate text-to-video models。 | 附录 Training Details |
| VLM models | 跟随 PaLM-E 架构和代码库;fine-tune single 12B PaLM-E 同时预测 heuristics 和 policies;每个 domain 用 64 TPUv3 pods 训练 1 天。 | 附录 Training Details |
| Goal-conditioned policy | 使用 LAVA 架构,将 CLIP text encoder 替换成 goal image 的 ResNet encoder;每个 domain 用 16 TPUv3 pods 训练 1 天。 | 附录 Training Details |
| Language Table planning | horizon 16、beam width 2、language branching factor 4、video branching factor 4;DDIM sampler,base resolution 64 sampling steps,高分辨率 4 sampling steps;classifier-free guidance scale 5。 | 附录 Planning Details |
| 7DoF mobile manipulator planning | 用 PaLM-E 生成 scene captions,用 few-shot prompted PaLM 按 SayCan prompts 生成计划;beam width 3;base resolution $64\times80$,super-resolution $256\times320$;goal policy 使用 generated video segment 的最后一帧。 | 附录 Planning Details |
| 14DoF bi-manual planning | 沿用 Language Table planning setup;heuristic clipping threshold 设为 15。 | 附录 Planning Details |
6. 实验与结果
实验分三类:长程视频合成、长程执行、泛化。论文覆盖 simulated Language Table、真实 Language Table、7DoF mobile manipulator、14DoF bi-manual ALOHA。
6.1 Long-Horizon Video Synthesis
评估生成的视频计划是否完成长程目标。附录说明评估方式是人工判断生成视频中是否在任意时刻满足 long-horizon goal;每个 goal、每个方法生成 50 个视频。由于长程视频生成慢,每个视频约 30 分钟。
| Model | Sim Environment | Real Environment | ||||
|---|---|---|---|---|---|---|
| Move Area | Group Color | Make Line | Move Area | Group Color | Make Line | |
| UniPi | 2% | 4% | 2% | 4% | 12% | 4% |
| VLP (No Value Function) | 10% | 42% | 8% | 20% | 64% | 4% |
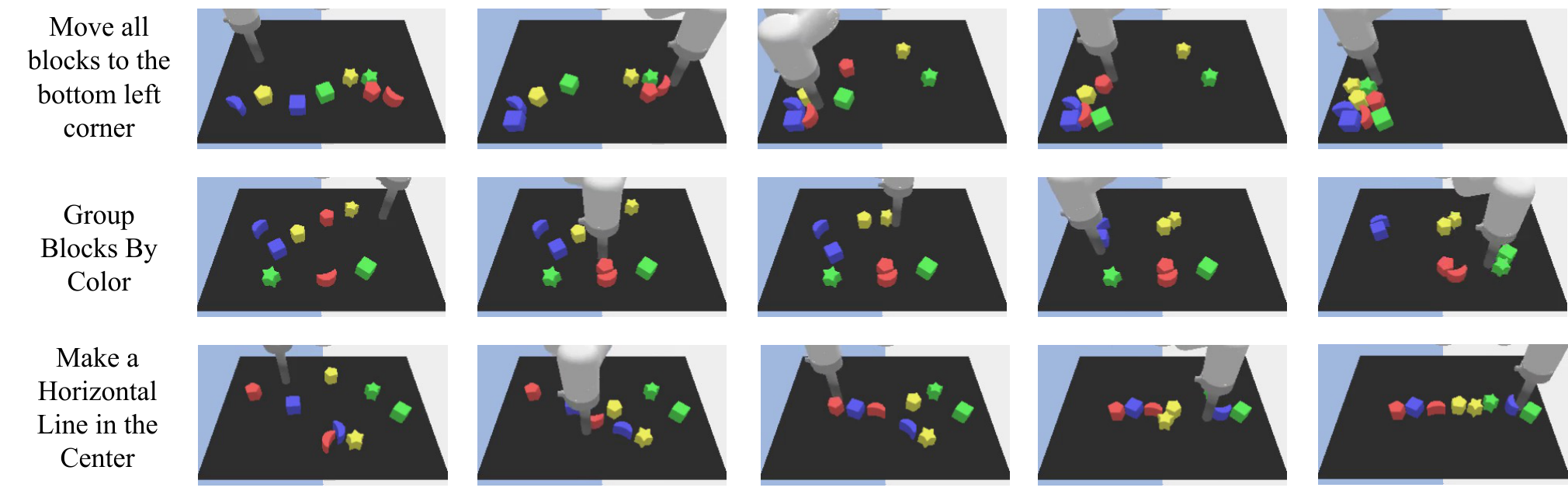
| VLP (Ours) | 58% | 98% | 66% | 78% | 100% | 56% |
该表直接支持 VLP 的两个核心设计:比 UniPi 直接长程视频生成好,说明层级/搜索结构重要;比 no value function 好,说明 heuristic pruning 不只是装饰。
6.2 Search Budget 对视频计划的影响
| Beams | Language Branch | Video Branch | Make Line Performance |
|---|---|---|---|
| 1 | 1 | 1 | 4% |
| 1 | 1 | 4 | 10% |
| 1 | 4 | 4 | 22% |
| 2 | 4 | 4 | 56% |
随着 video branching、language branching、beam 增加,Make Line 视频计划成功率从 4% 到 56%。这说明 VLP 的能力具有 test-time compute scaling:更多候选 rollout 能显著改善长程计划质量。

6.3 Long-Horizon Execution
执行评估使用 Language Table 的 ground-truth simulation state 计算 reward 与完成阈值。每个方法每个任务评估 50 个环境,每个环境最多 1500 timesteps;若中途完成则提前停止。论文说明 VLP 每个环境约 1 小时,RT-2 baseline 约 0.5 小时。
| Model | Move to Area | Group by Color | Make Line | |||
|---|---|---|---|---|---|---|
| Reward | Completion | Reward | Completion | Reward | Completion | |
| UniPi | 30.8 | 0% | 44.0 | 4% | 44.0 | 4% |
| LAVA | 59.8 | 22% | 50.0 | 2% | 33.5 | 0% |
| RT-2 | 18.5 | 0% | 46.0 | 26% | 36.5 | 2% |
| PaLM-E | 36.5 | 0% | 43.5 | 2% | 26.2 | 0% |
| VLP (Ours) | 87.3 | 64% | 95.8 | 92% | 65.0 | 16% |
作者指出这些任务 horizon 很长,许多 baseline 会“stuck”并停止有效行动。VLP 的执行优势来自反复规划视觉子目标,并用 goal-conditioned policy 执行中间帧。
6.4 Execution Budget 与 Action Extraction Ablation
| Beams | Planning Horizon | Branching Factor | Line Score | Line Completion |
|---|---|---|---|---|
| 1 | 1 | 4 | 48.9 | 0% |
| 1 | 1 | 16 | 53.3 | 2% |
| 1 | 2 | 16 | 58.1 | 8% |
| 2 | 2 | 16 | 65.0 | 16% |
执行成功率也随 planning horizon 与 branching factor 增加而提升,再次说明 test-time planning compute 是方法的一部分。
| Action Inference | Group Color Score | Group Color Completion |
|---|---|---|
| Inverse Dynamics | 89.7 | 80% |
| Goal Policy (Last) | 85.0 | 66% |
| Goal Policy (Every) | 95.8 | 92% |
逐帧使用 goal-conditioned policy 最好,说明视频计划中的中间帧本身是有价值的 dense subgoals;只看短视频最后一帧会损失执行引导。
6.5 Real Robot 与 Multi-Platform Planning
VLP 还展示了真实机器人执行与多平台视频计划:Language Table real robot、7DoF mobile manipulator、14DoF bi-manual ALOHA。ALOHA 设置中,视频模型同时输出 4 个 camera views,做法是 channel-wise concatenation;VLM policy 和 heuristic 使用 top/side views。



6.6 Generalization
论文报告了对象、光照和新任务泛化。核心解释是:执行被拆成 visual goal generation 与 goal-conditioned controller 后,视频模型负责生成视觉目标,控制策略只需关注到达附近视觉目标所需的局部信息。


6.7 附录补充结果
附录补充三类结果:失败案例、goal-conditioned policy 对 noisy synthesized goals 的鲁棒性、额外长程视频计划。



7. 分析、局限与边界
7.1 这篇论文最有价值的地方
这篇论文最有价值的地方是把“基础模型组合”落成了一个可操作的长程规划算法。它没有要求单个 VLM 同时理解语义、物理、动态和控制,也没有要求单个视频模型一次生成完整长程计划;而是让每个模型做相对擅长的部分,再用 test-time search 把能力组合起来。
从方法视角看,VLP 的价值在于重新打开了 visual planning 这条路线:视频不是展示结果的附属物,而是搜索空间中的状态轨迹;VLM heuristic 也不是只做 caption,而是作为 value-like pruning signal。这个组合让推理计算成为可调资源,更多 search budget 可以换更好计划。
7.2 结果为什么站得住
首先,论文的主结果和方法主张对齐:VLP 声称 tree search 组合 VLM 与视频模型能改善长程计划,因此实验同时评估视频计划质量和真实执行成功率。视频计划表中,VLP 在 sim/real 的 Move、Group、Make 三类任务上均明显高于 UniPi 和 no-value-function ablation。
其次,对照项覆盖了几个关键替代方案:直接长程视频生成的 UniPi、直接语言/行为克隆的 LAVA、直接 VLM planning 的 PaLM-E、视觉语言动作模型 RT-2,以及去掉 heuristic 的 VLP ablation。VLP 的优势不是只相对一个弱 baseline,而是在不同范式上都更好。
第三,ablation 证明提升与搜索机制相关:视频计划成功率随 beam/language branch/video branch 从 4% 到 56%;执行成功率也随 planning horizon 和 branching factor 增大而提升。action extraction ablation 又说明逐帧 goal policy 是把视频计划转为动作的关键。
7.3 论文明确给出的结果解释
- VLM policy 单独不足以做长程规划,因为它缺少准确动态预测;视频 rollout 可以补足低层视觉动态。
- 视频模型单独直接生成长程计划不足,因为长视频容易失真;语言子动作和树搜索提供层级结构。
- VLM heuristic 的 value-like 作用能过滤掉不利 rollout,no-value-function ablation 明显更差。
- goal-conditioned policy 对生成目标的噪声有一定鲁棒性,因为它可以忽略大部分无关视觉细节,专注局部可执行目标。
7.4 作者自述局限
| 局限 | 论文中的说明 | 影响范围 |
|---|---|---|
| 图像状态不完整 | VLP 用 images 作为 world state representation,但很多任务中图像无法捕捉完整 3D 状态、隐藏物理因素或质量。 | 遮挡、接触力、物体重量、不可见状态相关任务。 |
| 视频动态不总准确 | 作者观察到 synthesized videos 中物体可能 spontaneous appear 或 teleport。 | 搜索可能 exploit 不物理的 rollout,需要阈值过滤但不能根治。 |
| 规划推理成本高 | Language Table 长程规划约 30 分钟;VLP 执行每个环境约 1 小时。 | 实时机器人应用、交互式闭环任务。 |
| 依赖 domain-specific training | 论文训练 separate text-to-video models、separate VLM models per domain,goal-conditioned policy 也按 domain 训练。 | 跨平台泛化仍需要数据与适配训练。 |
7.5 适用边界
VLP 最适合目标可以由语言分解、状态变化可由图像/视频表达、短程 goal-conditioned policy 可学到、并且允许较高推理计算预算的长程机器人任务。它不适合要求高频实时反应、强隐状态推理、精确接触力控制,或视频模型不能可靠模拟关键动态的任务。
8. 可复现性审计
8.1 数据与任务
- 已给出:Language Table 约 10000 long-horizon trajectories,覆盖模拟和真实,几百个 long-horizon goals;实验选 3 个便于自动评估的 goal,约 20000 trajectories 和 400000 short-horizon text labels。
- 已给出:7DoF mobile manipulator 使用 RT-1 dataset;generalization experiments 混合 7DoF、Bridge、RT-2、Ego4D、EPIC-KITCHEN、LAION-400M。
- 已给出:14DoF ALOHA 使用约 1200 teleoped demonstrations,每个约 20 language instructions,总约 25k short-horizon text labels。
8.2 评估细节
- 视频评估:每个 goal、每个方法生成 50 个视频,人工判断是否满足 long-horizon goal。
- 执行评估:Language Table 使用 ground-truth simulation state 计算 reward;每个方法每个任务 50 environments;每个环境最多 1500 timesteps,完成则提前停止。
- VLP 执行设置:planning horizon 2、beam width 2、branching factor 16;模拟中对视频计划前 16 帧每帧调用 goal-conditioned policy 4 次;真实环境中对前 10 帧调用。
8.3 训练与算力
复现门槛很高:视频模型使用 64 TPUv3 pods 训练数天,VLM 是 12B PaLM-E,goal-conditioned policy 也用 16 TPUv3 pods。论文提供了方向性配置,但普通实验室很难等规模复现。
8.4 最小复现路径
更现实的复现路线是先缩小到 Language Table simulation:训练一个小型 VLM/action-label predictor 或固定 action proposal 集合,训练低分辨率短程视频模型,训练 goal-conditioned policy,然后比较 UniPi-style direct long-video generation、no-value-function VLP 和 full VLP。关键不是复现 12B PaLM-E,而是验证“视频 rollout + heuristic search”是否优于直接长程视频生成。