Unleashing Large-Scale Video Generative Pre-training for Visual Robot Manipulation
1. 论文速览
| 论文要解决什么 | 机器人演示数据稀缺、昂贵,并且包含图像、状态、动作、语言等多模态信号;作者希望用更大规模的非机器人视频数据改善多任务语言条件视觉操作。 |
|---|---|
| 作者的方法抓手 | 把机器人轨迹看作带动作的视觉序列:先用 Ego4D 上的语言条件视频预测学“接下来会发生什么”,再把这个能力迁移到机器人策略学习。 |
| 最重要的结果 | CALVIN ABCD$\rightarrow$D 成功率从最佳基线 88.9% 提升到 94.9%,平均连续完成任务数从 3.06 到 4.21;ABC$\rightarrow$D 未见场景成功率从 53.3% 到 85.4%。 |
| 阅读时要注意的点 | 核心不是单纯换成 Transformer,而是“视频预测 token + 行为克隆 token + 大规模视频预训练”的组合;附录消融表明只有视频预测、没有预训练也有帮助,但完整 GR-1 最强。 |
难度评级:★★★★☆。需要熟悉行为克隆、Transformer 序列建模、视觉编码器、机器人长时序评测,以及 CALVIN 的连续任务协议。
关键词:visual robot manipulation, language-conditioned policy, video generative pre-training, GPT-style transformer, CALVIN, Ego4D。
核心贡献清单
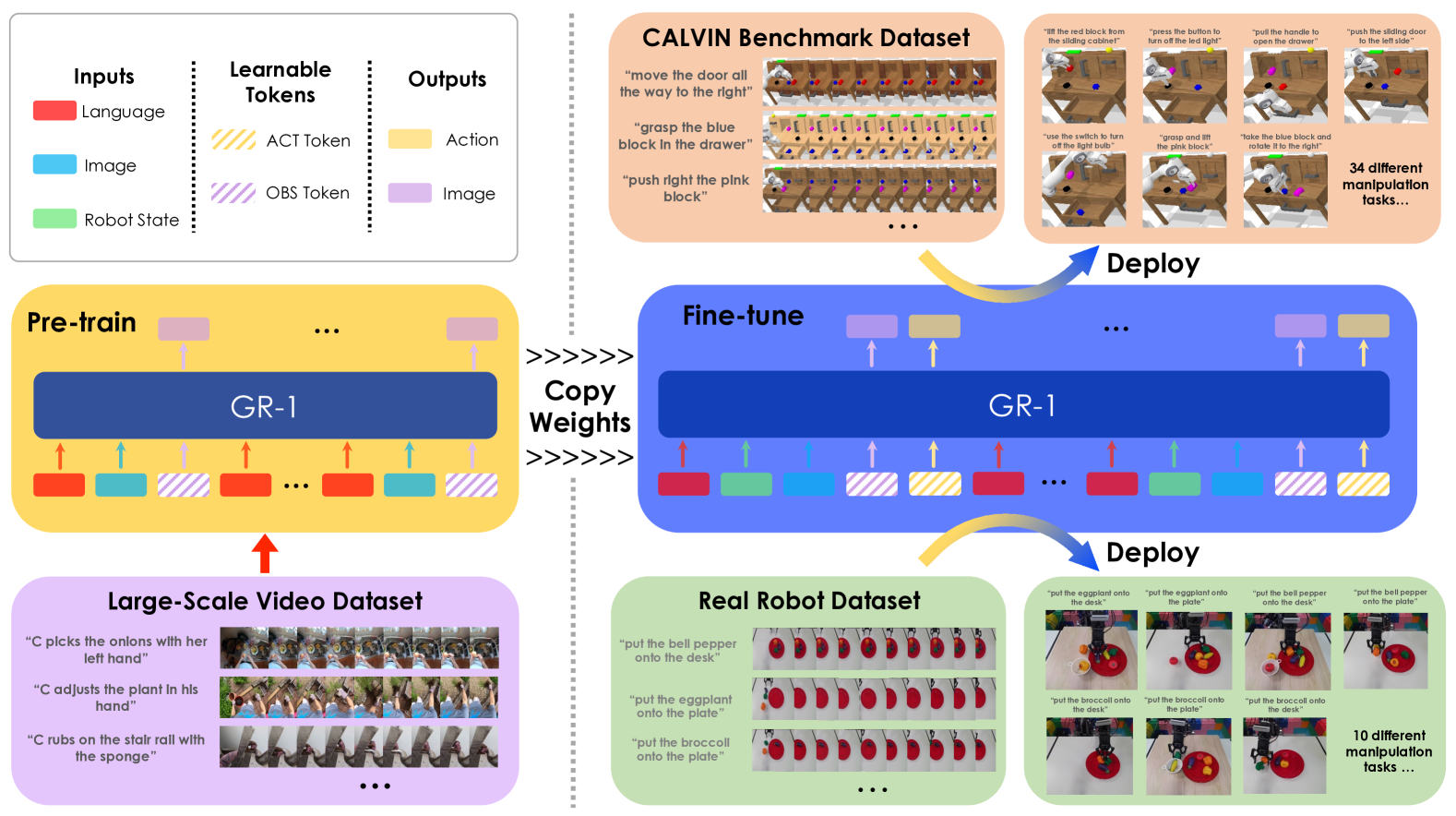
- 证明视频生成式预训练可帮助机器人操作:作者把 Ego4D 中的人物交互视频作为预训练来源,并在 CALVIN 与真实机器人上验证迁移效果。
- 提出统一模型 GR-1:一个 GPT-style causal Transformer 同时接收语言、历史图像和机器人状态,并输出动作与未来图像。
- 系统评估泛化与数据效率:包括多任务、未见场景、10% 数据、未见语言、真实机器人未见实例与未见类别。
2. 动机
2.1 要解决什么问题
NLP 和 CV 中的生成式预训练已经说明,大规模序列数据能提供可迁移的表示。机器人领域的障碍在于:演示采集成本高、数据稀疏;同时机器人数据天然是多模态的,包含图像、语言、状态、动作等。论文的关键判断是:机器人轨迹本身也包含视频序列,因此“根据语言与过去画面预测未来画面”与“根据语言与历史观测选择动作”存在结构相似性。
一个具体场景是长时序 CALVIN 操作:机器人不仅要听懂“slide left the red block”这类语言,还要从视觉中定位物体、预测操作后环境如何变化,并持续完成最多 5 个任务。若只依赖少量带语言标注的机器人数据,模型很难得到足够稳健的视觉-语言-时间结构。
2.2 已有方法的局限
论文把前作分成几条线:语言条件操作方法可以借助 LLM 或 CLIP 等做任务理解,但部分方法预测稀疏关键点并依赖 motion planner,灵活性弱于端到端连续动作;层级方法使用 latent plan 条件化策略,但不是简单统一的 GPT-style 轨迹建模。Transformer 决策模型如 Decision Transformer、GATO、RoboCat 说明序列模型适合决策问题,但 RoboCat 没有做视频预训练且是 goal-image conditioned 而不是 language-conditioned。
预训练方面,R3M、MVP 等多关注视觉表示,VPT/VIPER 使用任务环境内的视频;GR-1 与它们的区别是用非机器人、域外的大规模 Ego4D 视频做语言条件未来帧预测,并在同一模型中保留未来图像和动作预测两个输出头。
2.3 本文的解决思路
高层思路是把预训练任务设计成机器人微调任务的子结构:预训练阶段输入语言和过去帧,输出未来帧;机器人阶段额外加入状态输入和动作输出,同时继续预测未来帧。这样,视频预训练学到的视觉-语言-时间关系可以直接进入机器人策略学习,而不只是作为独立 frozen representation。
4. 方法详解
4.1 问题形式化
视频预训练任务:给语言描述和历史图像序列,预测未来图像。
$$\pi(l, \mathbf{o}_{t-h:t}) \rightarrow \mathbf{o}_{t+\Delta t}$$| $l$ | 视频的自然语言描述。 |
| $\mathbf{o}_{t-h:t}$ | 从 $t-h$ 到当前 $t$ 的视频帧序列。 |
| $\mathbf{o}_{t+\Delta t}$ | 未来第 $\Delta t$ 步的目标帧。 |
机器人微调任务:在视频预测之外,同时预测当前动作。
$$\pi(l, \mathbf{o}_{t-h:t}, \mathbf{s}_{t-h:t}) \rightarrow \mathbf{o}_{t+\Delta t}, \mathbf{a}_{t}$$| $\mathbf{s}_{t-h:t}$ | 机器人状态序列,包含末端执行器 6D pose 与二值 gripper 状态。 |
| $\mathbf{a}_{t}$ | 当前动作:手臂连续动作与 gripper 二值动作。 |
| $D=\{\tau_i\}_{i=1}^{N}$ | 含 $M$ 个任务的专家轨迹数据集,每条轨迹包含语言、图像、状态、动作。 |
4.2 模型输入与 token 组织
GR-1 使用多模态 encoder 把语言、图像与机器人状态映射到同一 Transformer 维度。语言由 CLIP text encoder 编码;视觉观测由 MAE 预训练 ViT 编码,CLS token 作为全局表示,patch token 经过 Perceiver resampler 压缩;机器人状态用线性层编码。附录 Network and Training Details
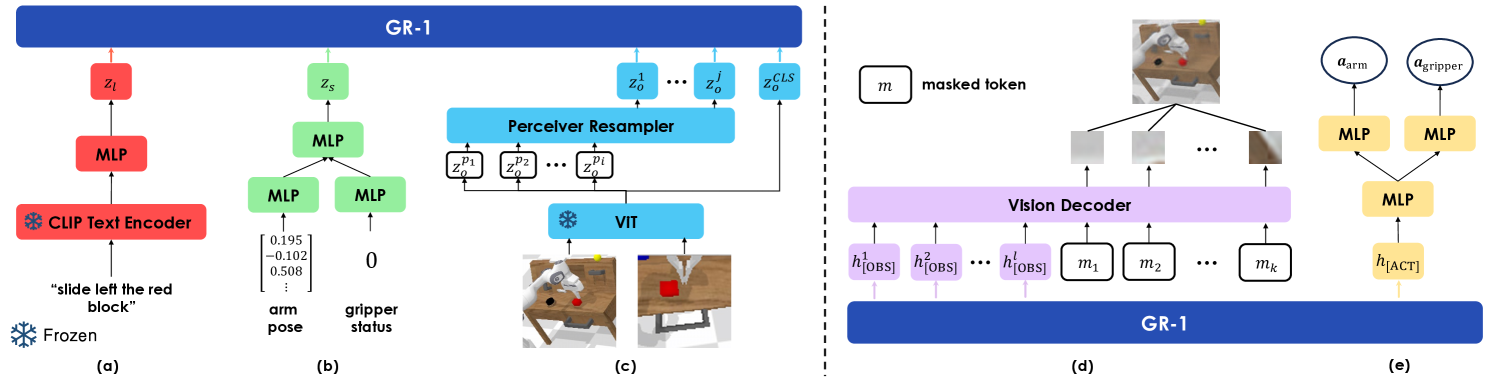
模型学习两类特殊 token:[OBS] 用于未来图像预测,[ACT] 用于动作预测。预训练阶段的序列是语言、图像、[OBS] 交替出现;机器人微调阶段加入状态和 [ACT]。作者重复放置语言 token,原因是避免语言信息被更密集的视觉和状态 token 淹没。每个时间步还加入学习得到的相对时间嵌入,同一时间步的所有模态共享该时间嵌入。
4.3 因果 Transformer 与 mask
GR-1 使用 GPT-style causal Transformer,但对预测 token 做特殊 mask。预训练时,token 可看见之前位置的 token,但不能看见之前的 [OBS] 预测 token;微调时,不能看见之前的 [OBS] 和 [ACT]。这样可避免模型从预测 token 中泄漏目标信息,保持自回归式的历史条件预测。
4.4 输出头与损失
未来图像由 transformer decoder 从 [OBS] 对应输出与 mask token 重建 patch,训练目标是像素空间 MSE,并采用 MAE 风格的 patch-wise normalization。动作由 [ACT] 输出经过三层 MLP,最后分成 arm 和 gripper 两个 head:arm 用 Smooth-L1 loss,gripper 用 BCE loss。微调阶段的总损失为:
这说明视频预测不是预训练结束后被丢掉的辅助任务,而是在机器人微调时仍作为训练信号存在。
4.5 训练细节
预训练数据来自 Ego4D,包含超过 3500 小时人-物交互视频。作者从视频中裁剪 3 秒短 clip,共得到 800,000 个 clip、8M 帧。预训练随机采样序列并预测未来帧。微调时随机采样机器人轨迹片段,同时优化行为克隆和视频预测损失。
| 项目 | 预训练 | 机器人微调 |
|---|---|---|
| 数据 | Ego4D;800k clips;8M frames | CALVIN 或真实机器人数据 |
| 预测步长 | $\Delta t=1$,等间隔帧相距 1/3 秒 | $\Delta t=3$,预测 static camera 与 gripper camera 图像 |
| 序列长度 | 10 | |
| 冻结模块 | CLIP text encoder 与 MAE image encoder | |
| Transformer | 12 层、12 heads、hidden size 384;总参数 195M,其中 46M 可训练 附录 Network and Training Details | |
| 超参数 | 预训练 | 微调 |
|---|---|---|
| batch size | 1024 | 512 |
| learning rate | 3.6e-4 | 1e-3 |
| dropout | 0.1 | 0.1 |
| optimizer | AdamW | AdamW |
| schedule | cosine decay | cosine decay |
| warmup epochs | 5 | 1 |
| training epochs | 50 | 20 |
5. 实验
5.1 实验问题与设置
作者围绕三个问题设计实验:GR-1 是否能提升视觉机器人操作;是否能在真实机器人上工作;是否能处理小数据、未见场景、未见物体和未见语言等挑战。主要评测包括 CALVIN benchmark 和真实机器人 object transportation / articulated object manipulation。

CALVIN 包含 34 个任务和开放语言指令。训练数据有超过 20k 条专家轨迹,但作者模拟真实场景,只使用其中 1% 带 crowdsourced language instruction labels 的数据训练 GR-1、RT-1 和 MT-R3M;MCIL 和 HULC 使用完整 CALVIN 数据。评测使用 1000 个 unique sequence instruction chains,每个 chain 最多连续完成 5 个任务;单任务 360 timesteps 内未完成视为失败。附录 CALVIN Benchmark Experiments
5.2 CALVIN 主结果
| 设置 | 方法 | 1 task | 2 tasks | 3 tasks | 4 tasks | 5 tasks | Avg. Len. |
|---|---|---|---|---|---|---|---|
| ABCD$\rightarrow$D | HULC 最佳基线 | 0.889 | 0.733 | 0.587 | 0.475 | 0.383 | 3.06 |
| ABCD$\rightarrow$D | GR-1 | 0.949 | 0.896 | 0.844 | 0.789 | 0.731 | 4.21 |
| ABC$\rightarrow$D | RT-1/MT-R3M 最佳基线 | 0.533 | 0.234 | 0.105 | 0.043 | 0.018 | 0.93 |
| ABC$\rightarrow$D | GR-1 | 0.854 | 0.712 | 0.596 | 0.497 | 0.401 | 3.06 |
| 10% data | HULC 最佳基线 | 0.668 | 0.295 | 0.103 | 0.032 | 0.013 | 1.11 |
| 10% data | GR-1 | 0.778 | 0.533 | 0.332 | 0.218 | 0.139 | 2.00 |
| unseen language | HULC 最佳基线 | 0.715 | 0.470 | 0.308 | 0.199 | 0.130 | 1.82 |
| unseen language | GR-1 | 0.764 | 0.555 | 0.381 | 0.270 | 0.196 | 2.17 |
ABCD$\rightarrow$D 衡量在全部环境训练并在 D 环境评测的多任务能力;GR-1 在从第 1 个到第 5 个连续任务上均高于基线,尤其 5-task success 从 HULC 的 0.383 到 0.731。ABC$\rightarrow$D 是零样本未见场景泛化,GR-1 的 1-task success 为 0.854,明显高于最佳基线 0.533。10% data 使用 ABCD$\rightarrow$D 总训练集的 10%,即每个任务 66 条、共 2244 条轨迹;GR-1 仍达到 0.778 的 1-task success。
未见语言实验中,作者用 GPT-4 为 34 个任务各生成 50 个同义指令,评测时随机采样。附录示例包括 “use the switch to turn off the light bulb” 到 “use the switch to stop the light source”等。附录 More Results
5.3 真实机器人实验
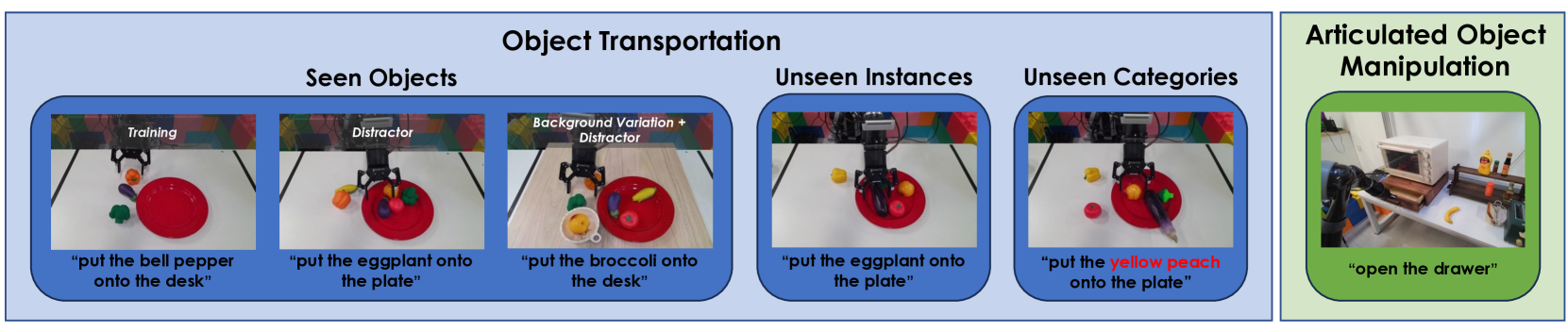
真实机器人使用 7-DoF Kinova Gen2,末端安装 RealSense,相机静态视角来自 Kinect Azure。物体搬运训练场景含 plate、eggplant、broccoli、bell pepper,共 1775 条 VR 采集 demonstrations;抽屉开合训练 2856 条轨迹。真实机器人微调基本沿用 CALVIN 设置,但 batch size 改为 64,training epochs 改为 30。附录 Real Robot Experiments
| 方法 | Seen Objects | Unseen Instances | Unseen Categories | Articulated Object Manipulation |
|---|---|---|---|---|
| RT-1 | 0.27 | 0.13 | 0.00 | 0.35 |
| MT-R3M | 0.15 | 0.13 | 0.10 | 0.30 |
| GR-1 | 0.79 | 0.73 | 0.30 | 0.75 |
作者报告的主要失败模式也很具体:RT-1 和 MT-R3M 常拿错物体、放置错误,RT-1 还可能碰到 plate 或 desk;GR-1 在 unseen categories 中会把颜色相近的 bell pepper 与 peach 混淆;抽屉任务中会出现未完全关闭或未抓住把手。真实机器人 rollout 见 Figure 9。
5.4 视频预测定性结果

这部分支持论文的核心机制解释:未来帧预测信号可以为动作预测提供未来状态约束。作者没有把预测质量转化为独立量化指标,而是以定性图说明在 CALVIN 和真实机器人数据上未来帧结构可被恢复。
5.5 消融实验
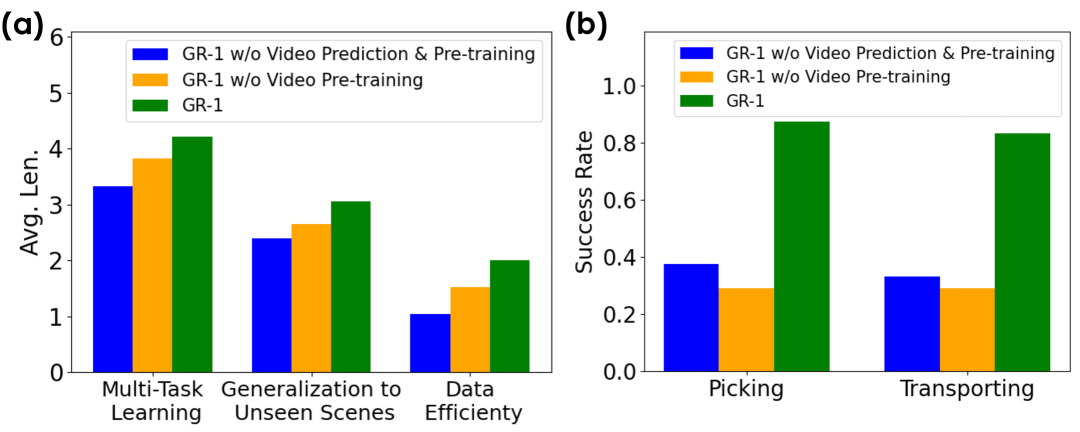
| 设置 | Pre-training | Video Prediction | 1 task | 5 tasks | Avg. Len. |
|---|---|---|---|---|---|
| ABCD$\rightarrow$D | 否 | 否 | 0.889 | 0.459 | 3.33 |
| ABCD$\rightarrow$D | 否 | 是 | 0.918 | 0.619 | 3.82 |
| ABCD$\rightarrow$D | 是 | 是 | 0.949 | 0.731 | 4.21 |
| ABC$\rightarrow$D | 否 | 否 | 0.823 | 0.225 | 2.40 |
| ABC$\rightarrow$D | 否 | 是 | 0.815 | 0.297 | 2.65 |
| ABC$\rightarrow$D | 是 | 是 | 0.854 | 0.401 | 3.06 |
| 10% data | 否 | 否 | 0.526 | 0.022 | 1.04 |
| 10% data | 否 | 是 | 0.698 | 0.052 | 1.52 |
| 10% data | 是 | 是 | 0.778 | 0.139 | 2.00 |
消融结论分两层:第一,加入视频预测但不预训练通常已经提升,说明未来帧辅助任务本身有用;第二,加入大规模视频预训练后进一步提升,尤其在未见场景和小数据上更明显。作者解释为预训练帮助模型学习更鲁棒的视频预测模型,从而形成对未来状态的提示。附录 Ablation Studies
| Future Step | 1 task | 2 tasks | 3 tasks | 4 tasks | 5 tasks | Avg. Len. |
|---|---|---|---|---|---|---|
| 1 | 0.895 | 0.802 | 0.710 | 0.643 | 0.562 | 3.61 |
| 3 | 0.918 | 0.833 | 0.761 | 0.685 | 0.619 | 3.82 |
| 5 | 0.909 | 0.806 | 0.719 | 0.649 | 0.583 | 3.67 |
预测 $\Delta t=3$ 优于 1 和 5。作者给出的解释是:连续帧过近时信息差异不足,过远时又不适合指导当前局部动作。
5.6 逐任务成功率与更多可视化
逐任务成功率表显示,视频预训练对涉及 block manipulation 的任务提升较大,例如 rotate blue block right 从 71.2 到 94.9、stack block 从 45.7 到 80.1、lift red block table 从 76.7 到 97.7。作者解释这些任务难在需要先抓对方块,再按语言操作;视频生成式预训练改善了这类任务的表现。附录 Task Success Rates
| Task | GR-1 | GR-1 w/o Video Prediction & Pre-training | GR-1 10% data |
|---|---|---|---|
| rotate blue block right | 94.9 | 71.2 | 51.6 |
| stack block | 80.1 | 45.7 | 43.2 |
| lift red block table | 97.7 | 76.7 | 36.5 |
| place in slider | 91.3 | 89.1 | 34.8 |
| open drawer | 99.4 | 100.0 | 94.2 |
| turn on/off LED | 100.0 / 100.0 | 98.7 / 100.0 | 95.6 / 95.6 |
| push red/blue block right | 54.2 / 53.6 | 49.3 / 50.0 | 43.6 / 33.9 |





6. 可复现审计
代码与资源
有官方代码:github.com/bytedance/GR-1。README 提供 CALVIN 环境安装、CALVIN 数据下载、MAE ViT-Base 权重下载、GR-1 ABCD-D/ABC-D checkpoint 下载,以及 `evaluate_calvin.sh` 评测命令。
| 复现项 | 论文/代码给出的信息 | 状态 |
|---|---|---|
| 模型结构 | 12 layers、12 heads、hidden size 384、195M 参数、46M 可训练;CLIP text encoder 与 MAE ViT image encoder frozen。 | 充分 |
| 训练超参 | batch size、learning rate、dropout、optimizer、cosine decay、warmup、epochs 均在附录给出。 | 充分 |
| 预训练数据构造 | Ego4D;3 秒 clips;800k clips/8M frames;等间隔帧,间隔 1/3 秒。 | 较充分 |
| CALVIN 评测 | 1000 个 instruction chains;最多 5 个连续任务;360 timesteps 超时;ABCD$\rightarrow$D 与 ABC$\rightarrow$D split。 | 充分 |
| 真实机器人 | 机器人型号、相机、任务、训练轨迹数量、场景设置、batch/epoch 变化均给出。 | 复现实物依赖高 |
| 预训练权重 | 官方 README 提供 GR-1 CALVIN checkpoint;论文没有说明完整 Ego4D 预训练权重的所有训练日志。 | 评测可复现,完整训练成本高 |
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
基于论文自己的实验,最核心的价值在于把“域外大规模视频”从普通视觉表示预训练推进到“未来状态预测”这一更接近机器人策略学习的目标。证据不是单个 benchmark 数字,而是主结果与消融同时支持:只保留视频预测已有增益,叠加 Ego4D 预训练后,在多任务、未见场景和小数据下进一步提升。
7.2 结果为什么站得住
论文使用了多个相互补充的设置:CALVIN 中既有 ABCD$\rightarrow$D 的多任务学习,也有 ABC$\rightarrow$D 的未见场景、10% 数据、未见语言;真实机器人中又有 seen objects、unseen instances、unseen categories 和 articulated object manipulation。附录消融把 video prediction 与 pre-training 分开,并比较 future step,降低了“只是模型容量或 Transformer 架构导致提升”的解释空间。
7.3 作者给出的解释与失败模式
作者认为未见场景泛化来自 Ego4D 中丰富人-物交互带来的视觉-文本对齐;未见语言泛化来自预训练中的多样语言暴露和冻结 CLIP text encoder。真实机器人中,作者明确列出 GR-1 的失败模式:未见类别下会混淆颜色相近物体,例如 bell pepper 与 peach;抽屉任务会出现未完全关闭或未抓住把手。视频预测结果中,作者也指出遮挡物体等细节可能缺失。
7.4 作者自述的未来工作
Conclusion 中作者提出三个方向:结合带语言与不带语言的视频数据训练,以增强鲁棒性与泛化;探索“任意视频预训练”与“更相关的操作视频预训练”的差异;扩大机器人数据,包括更多不同环境下的轨迹数量和更多操作技能。
7.5 适用边界
- GR-1 的实验主要覆盖语言条件视觉操作、未来帧可作为动作提示的任务;论文没有证明该方法对所有接触动力学或高精细力控任务同样有效。
- 真实机器人实验规模相对 CALVIN 小,且任务集中在物体搬运和抽屉操作;复现实验需要相机、机器人、VR 采集与场景布置。
- 完整预训练依赖大规模 Ego4D 数据和较大 batch,计算成本显著高于只下载官方 checkpoint 做评测。