ARDuP: Active Region Video Diffusion for Universal Policies
Reading Report: This paper uses video generation for general robot policy learning, but the key is not to "generate a complete video as real as possible", but to explicitly generate task-related active areas first, so that the video planner and action decoder can pay more attention to the objects/regions that will actually be interacted with.
1. Quick overview of the paper
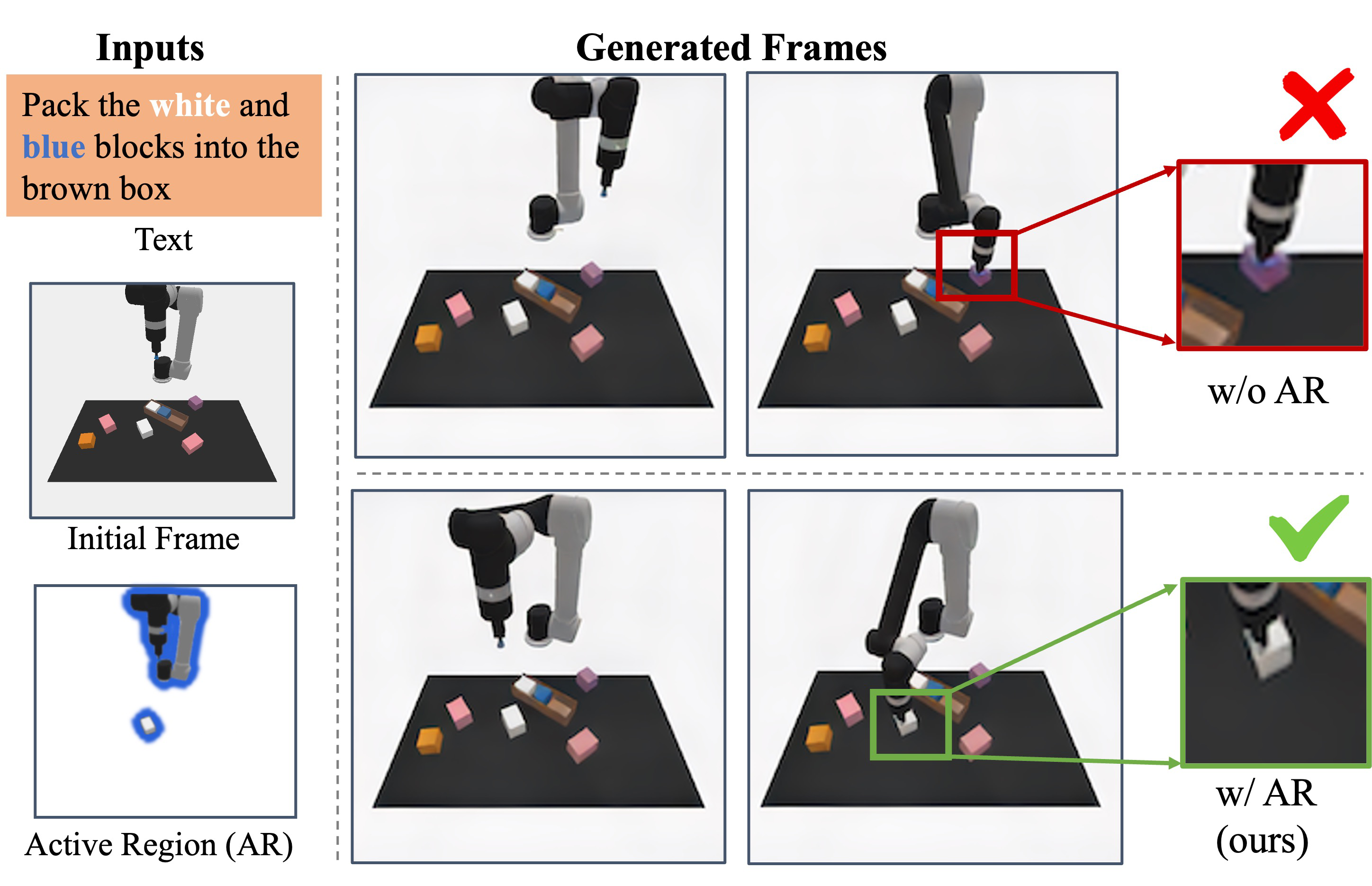
| What should the paper solve? | There are existing video-as-planner methods that generate future frames from text targets and initial images, and then use inverse dynamics to decode actions. However, these models usually treat all pixels equally, are prone to focus on the wrong objects, and even use visual shortcuts such as "changing colors" to reduce the generation loss but generate the wrong plan. What ARDuP wants to solve is: how to make the video planner more stably focus on the areas where the task really requires interaction, and transform this attention into a higher success rate of robot tasks. |
|---|---|
| The author's approach | Introduce active region as an explicit condition. During training, use Co-Tracker to find motion points from the demonstration video, and then use SAM to generate a pseudo active region mask without manual annotation; during inference, use latent active region diffusion to predict the active region based on the initial frame and language commands, then input the region as a condition to the latent video diffusion planner, and finally use latent inverse dynamics to directly generate latent sequences to decode actions. |
| most important results | On the three unseen tasks of CLIPort, ARDuP improved Place Bowl +21.3%, Pack Object +17.2%, and Pack Pair +15.7% respectively compared to UniPi*. The higher the quality of the active region, the higher the success rate; if GT active region is used during testing, the improvement can be +16.6%, +24.4%, +24.8%. On BridgeData v2, ARDuP-generated video plans were qualitatively better at selecting correct objects and placement. |
| Things to note when reading | This article does not directly solve the closed-loop control of real robots, but an offline data-driven video planning + action decoding framework. When reading, you need to distinguish three things: how the active region pseudo-label comes from, how the active region enters latent diffusion, and whether the improvement in mission success rate comes from the active region conditions or the design of latent inverse dynamics. |
2. Background and problem setting
From MDP to UPDP
Traditional MDP requires defining states, actions, rewards, and environment dynamics. For cross-task and cross-environment robot strategies, these definitions are difficult to unify. UniPi introduces the Unified Predictive Decision Process (UPDP): changing the state space into video frames, changing the target into language text, and changing planning into conditional video generation.
UPDP is defined as \(\mathcal{G}=(\mathcal{X}, \mathcal{C}, H, \rho)\). Where \(\mathcal{X}\) is the RGB frame space, \(\mathcal{C}\) is the task text collection, \(H\) is the planning length, and \(\rho(\cdot|x_0, c)\) is the video generator that generates future \(H\) frames based on the initial frame \(x_0\) and task text \(c\). The action prediction algorithm \(\mu(\cdot|\{x_h\}_{h=0}^{H}, c)\) then predicts action sequences from the generated video.
Problems with UPDP
The quality of UPDP actions depends on the quality of the generated frames. However, if the generative model optimizes all pixels equally, it will produce a very dangerous error in robotic tasks: as long as the image looks "close to the target", it may not actually interact with the correct object. For example, the model can first grasp the wrong object, and then change the color of the object to the color in the text description in subsequent frames.
3. Method details
3.1 LUPDP-AR formalization
The author changed UPDP to Latent Unified Predictive Decision Process conditioned on Active Region (LUPDP-AR):
$$\hat{\mathcal{G}}=(\hat{\mathcal{X}}, \mathcal{C}, \hat{\mathcal{O}}, H, \phi)$$
\(\hat{\mathcal{X}}\) is the RGB frame latent space, and \(\hat{\mathcal{O}}\) is the active region latent space. Stable Diffusion style encoder \(\mathcal{E}\) maps RGB frame and active region frame to latent. The video generator was changed from the original \(\rho(\cdot|x_0, c)\) to:
$$\phi(\cdot|\hat{x}_0, c, \hat{o})$$
That is, not only look at the initial frame and text, but also look at the active region latent \(\hat{o}\). Also define active region generator:
$$\psi(\hat{o}|\hat{x}_0, c): \hat{\mathcal{X}}\times\mathcal{C}\rightarrow\hat{\mathcal{O}}$$
The final action prediction is also performed on the latent sequence: \(\pi(\cdot|\{\hat{x}_h\}_{h=0}^{H}, c)\rightarrow \Delta(\mathcal{A}^{H})\). This avoids having to decode each latent back to RGB and do inverse dynamics.
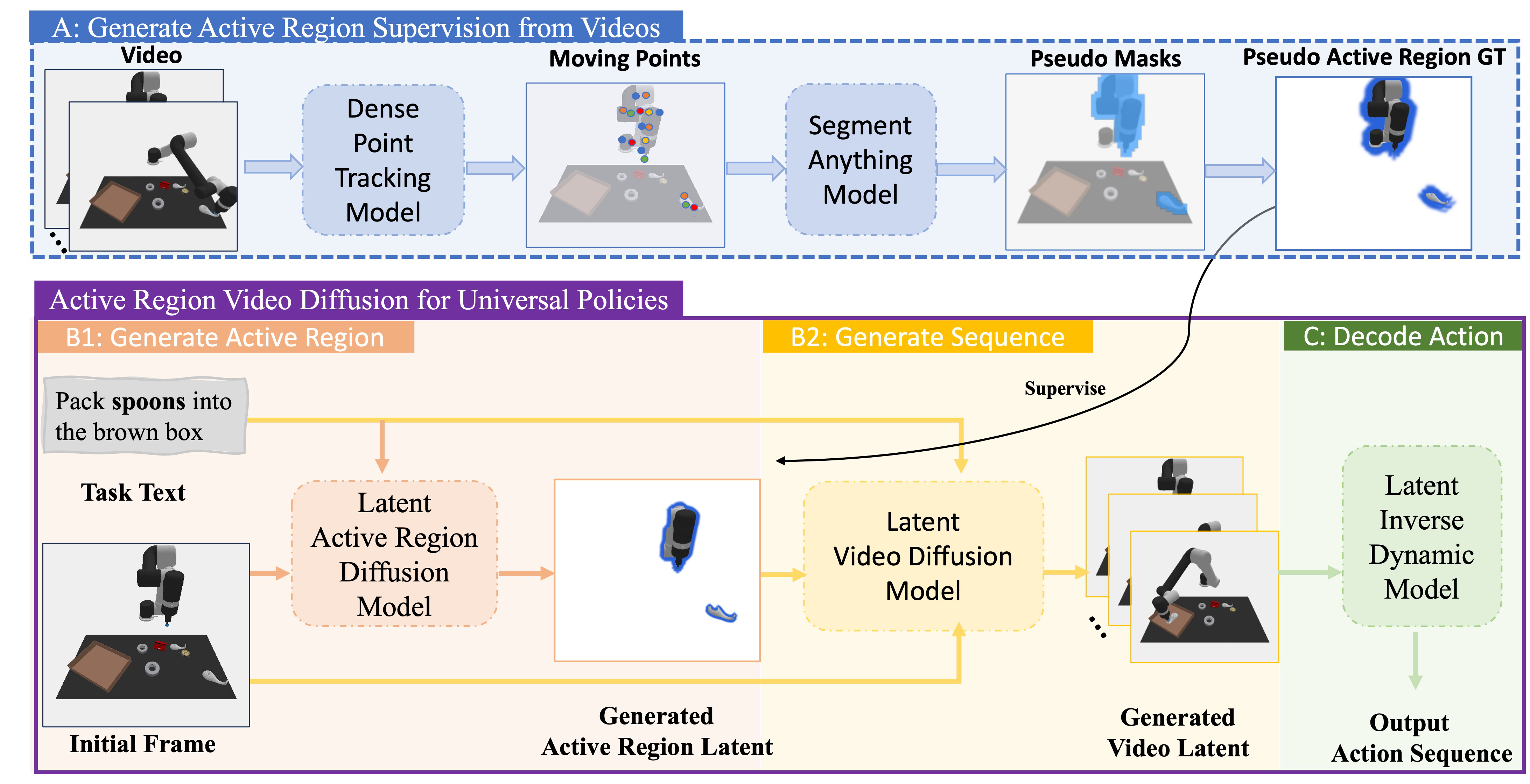
3.2 Automatically construct active region supervision from video
There is no manual active region annotation during training. The author uses the demonstration video \(\mathbf{V}=\{x_h\}_{h=0}^{H}\) to automatically generate a pseudo mask:
- Use Co-Tracker to place the \(M\times M\) grid point on the initial frame and track all points to subsequent frames to obtain the trajectory set \(\mathcal{P}=\mathcal{F}_p(\mathbf{V})\).
- Calculate the adjacent frame movement amount \(\Delta \mathbf{p}_h=\|\mathbf{p}_h-\mathbf{p}_{h-1}\|_2\) for each point trajectory.
- Calculate the average moving amount \(\Delta\bar{\mathbf{p}}=\frac{1}{H}\sum_{h=1}^{H}\Delta\mathbf{p}_h\).
- Filter for moving point \(\mathcal{P}_m=\{\mathbf{p}\in\mathcal{P}|\Delta\bar{\mathbf{p}}>\tau\}\).
- Enter the positions of these points in the initial frame as prompt into SAM to obtain active region mask \(\mathbf{M}\).
In order to form an active region frame, the author keeps the original image inside the mask and whitens the outside of the mask:
$$o=x_0\circ \mathbf{M}+x_b\circ(1-\mathbf{M})$$
Then use encoder \(\mathcal{E}\) to get \(\hat{o}\).
3.3 Latent active region diffusion
There is no future video during inference, and Co-Tracker can no longer be used to extract active regions from the entire video. Therefore, a conditional latent diffusion model \(\psi(\hat{o}|\hat{x}_0, c; \theta_\psi)\) is trained, inputting the initial frame latent and task text, and outputting the active region latent. The author emphasizes that both are indispensable: without images, we do not know the location of objects, and without text, we do not know which objects to interact with in the task.
3.4 Active-region-conditioned latent video planner
Video planner \(\phi(\cdot|\hat{x}_0, c, \hat{o}; \theta_\phi)\) generates future latent sequences. In terms of implementation, the author splices the active region latent with the latent of each frame, and also splices it with the latent of the initial frame, so that the denoising process is always constrained by "where to focus". You can use decoder \(\mathcal{R}\) to restore RGB during visualization, but action decoding does not rely on RGB decoding.
3.5 Latent inverse dynamics and execution
Given the adjacent generated frame latents \(\hat{x}_h, \hat{x}_{h+1}\), the latent inverse dynamics module predicts the action \(a_h\). It consists of a convolutional layer with skip connection plus a linear layer, and outputs a 7-dimensional manipulation action. When executing, it starts from \(x_0, c\), first generates \(\hat{o}\), then generates \(H=6\) step latent sequence, and finally decodes \(H\) actions at once and executes them in an open-loop.
4. Experiments and results
4.1 Implement settings
- Co-Tracker grid size \(M=60\), movement threshold \(\tau=2\).
- Perform connected component labeling on the pseudo mask, retain the operated object, and exclude the robotic arm area.
- The image is resized to \(512\times512\), and the VAE encoder outputs \(128\times128\times4\) latent.
- The active region generator uses T5-XXL text encoding and transforms UNet.
- Latent video diffusion uses something like UNet and adds temporal modules to generate \(H=6\) frame latent.
- Diffusion and inverse dynamics are trained from scratch, using 8 A100s; diffusion learning rate \(3\times10^{-4}\), batch 96; inverse dynamics learning rate \(5\times10^{-4}\), batch 3072.
4.2 CLIPort multi-environment migration
CLIPort is a language-conditional robot manipulation simulation benchmark based on Ravens. The author trained on 11 tasks and 110k demos, tested on 3 unseen tasks, and followed UniPi's multi-environment transfer settings.
| Model | Place Bowl | Pack Object | Pack Pair |
|---|---|---|---|
| State + Transformer BC | 9.8 | 21.7 | 1.3 |
| Image + Transformer BC | 5.3 | 5.7 | 7.8 |
| Image + TT | 4.9 | 19.8 | 2.3 |
| Diffuser | 14.8 | 15.9 | 10.5 |
| UniPi* | 65.4 | 51.8 | 30.9 |
| ARDuP | 86.7 (+21.3) | 69.0 (+17.2) | 46.6 (+15.7) |
This result shows that under the same video planning paradigm, explicit active region conditions significantly help the success rate of unseen tasks.
4.3 BridgeData v2 real data migration
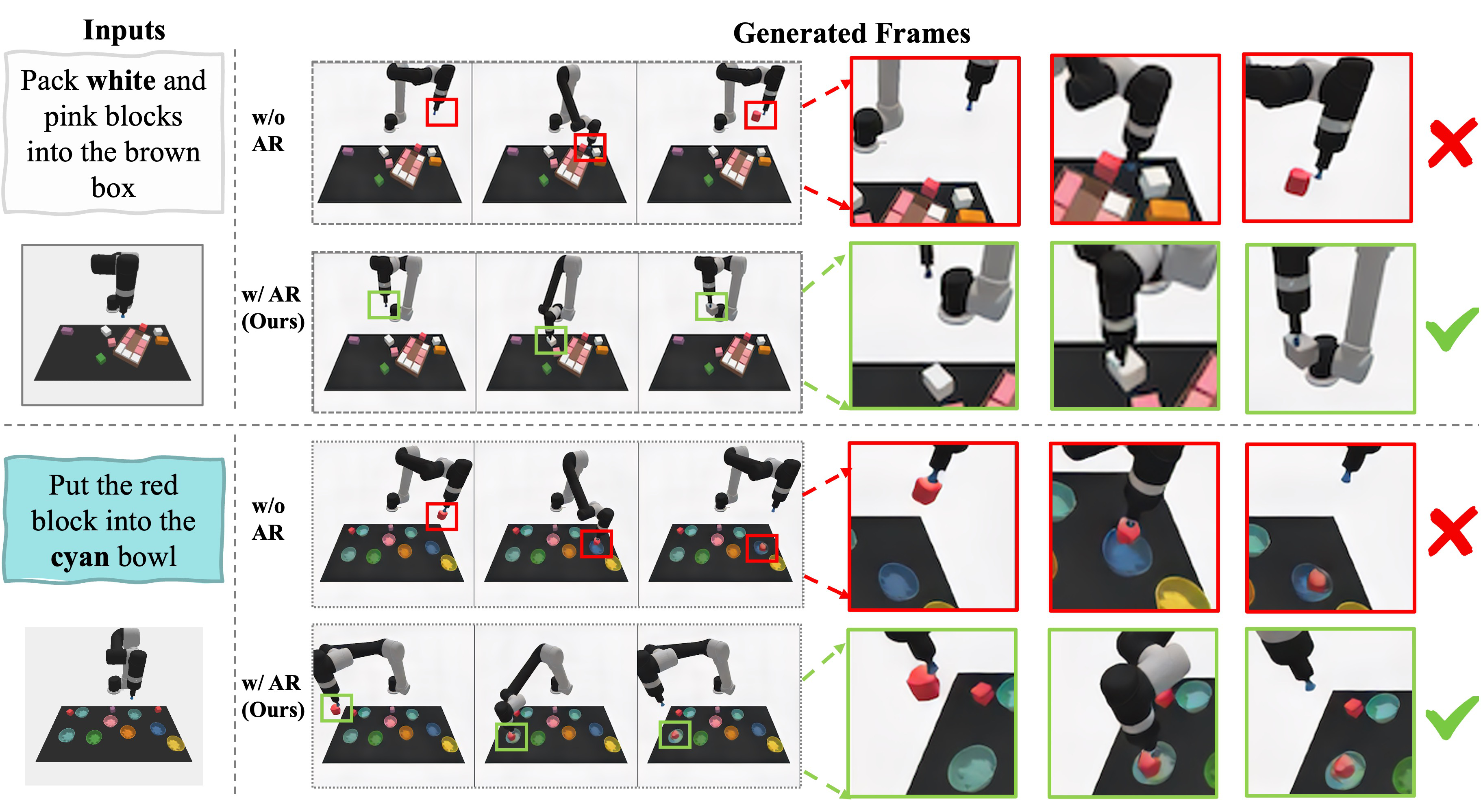
BridgeData v2 contains 60, 096 real robot trajectories, natural language instructions, and 24 environments. The authors use 95% of the data for training and the rest for evaluation. The paper mainly gives qualitative results: ARDuP can select the correct object and place it in the correct location in complex real scenes, while UniPi* is more likely to select the wrong object or place it in the wrong location.

4.4 Ablation: active region quality
| AR training | AR test | Planner | Place Bowl | Pack Object | Pack Pair |
|---|---|---|---|---|---|
| - | - | w/o Active Region | 83.4 | 67.7 | 38.0 |
| Unsupervised | Predicted | +Active Region | 86.7 (+3.3) | 69.0 (+1.3) | 46.6 (+8.6) |
| Supervised | Predicted | +Active Region | 93.3 (+9.9) | 79.6 (+11.9) | 51.7 (+13.7) |
| - | GT | +Active Region | 100.0 (+16.6) | 92.1 (+24.4) | 62.8 (+24.8) |
This table is very critical: the active region does not only look good on qualitative graphs, its quality is positively correlated with the final mission success rate. The more accurate the prediction of the active area, the easier it is to succeed in the task.
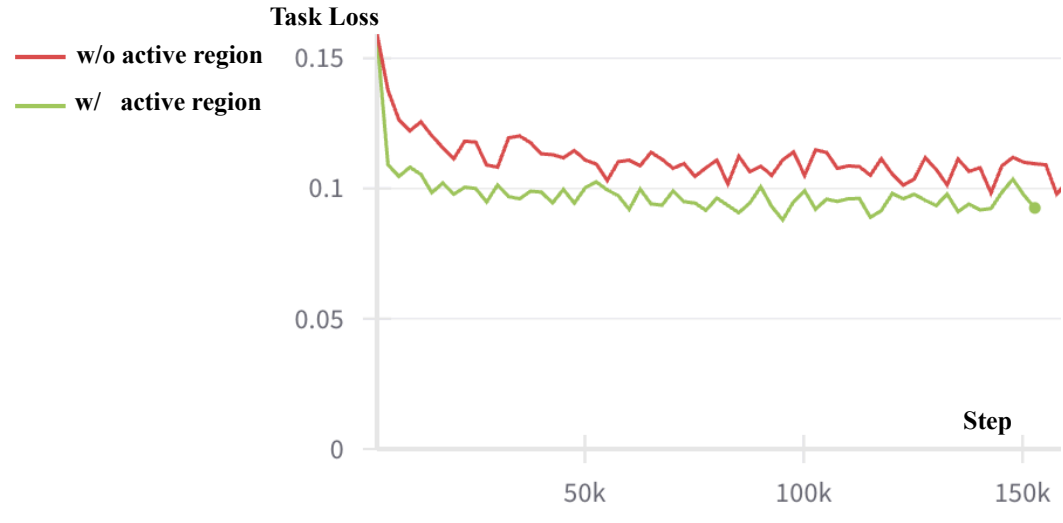
4.5 Ablation: task loss
The author proposes task loss to measure the quality of video generation in control tasks: input generated video latents into pre-trained latent inverse dynamics, decode the action, and then calculate the L1 error of the action and GT action. The task loss of the model with active region is significantly lower on the CLIPort test set, indicating that the generated video is not only more visually reasonable, but also more in line with the needs of the action decoder.
5. Key points of implementation and diagrams
Source code structure
`root.tex` in the arXiv source code is an IEEE template sample. The main file of the actual paper is `iros24_vid_main.tex`, and the text is under `data/`. The source code does not provide a separate appendix. Image resources include `teaser.jpg`, `overview.jpg`, `vis_cliport.jpg`, `bridge_vis.jpg`, `pseudo_bridge.jpg`, `ablation_active.pdf`, etc.
Why do it in latent space?
The author puts both video planning and action decoding in latent space as much as possible: on the one hand, it reduces the computational cost of RGB video generation, and on the other hand, it allows inverse dynamics to directly consume the internal representation of the generator, avoiding decoding RGB first and then re-encoding/perceiving. The visualization is only for human viewing, and the control itself does not require RGB decoding.
Two roles of active region
- training supervision: Use Co-Tracker + SAM to automatically extract pseudo masks from real demonstration videos to avoid manual annotation.
- reasoning conditions: Predict the task-related area through \(\psi(\hat{o}|\hat{x}_0, c)\), as the condition of \(\phi\), to constrain the generation direction of future video latent.
6. Key points of reproducibility and implementation
Minimum recurrence path
- Prepare datasets with language instructions, image sequences, action sequences, such as CLIPort or BridgeData v2.
- Run Co-Tracker on the training video to obtain the full temporal trajectory of the initial frame grid points.
- Filter moving points according to the average displacement threshold, and use SAM to generate a pseudo active region mask.
- Encode initial frame, active region frame to Stable Diffusion VAE latent.
- Training active region diffusion \(\psi\), input \(\hat{x}_0, c\), output \(\hat{o}\).
- Train latent video diffusion \(\phi\), input \(\hat{x}_0, c, \hat{o}\), and output future latent sequences.
- Train latent inverse dynamics \(\pi\), input adjacent latents, and output 7-dimensional actions.
- During inference, open-loop generates \(H=6\) actions and executes them.
An easy place to step into pitfalls
- Co-Tracker will treat the movement of the robotic arm as active and needs to be filtered by connected component to retain the manipulated object.
- The noise of the active region pseudo-label will be passed to diffusion training; the paper itself also points out that noisy label learning may be the direction of future improvement.
- UniPi* is the author's reproduced version. The training/pre-training data of the original UniPi is not fully public, so the baseline alignment is still uncertain.
- BridgeData v2 is mainly a qualitative visualization and does not give a strict success rate comparison like the CLIPort table.
7. Analysis, Limitations and Boundaries
The most valuable part of this paper
It proposes a very practical correction: do not expect the video generator to naturally learn "what is important for control" at the full-image pixel level, but to explicitly model the interaction area. This idea brings video generation back from "good-looking" to "useful for action". At the same time, the author uses Co-Tracker + SAM to automatically construct pseudo labels, so that the active region does not require manual annotation, which is the key to its expansion to large-scale video data.
Why does the result stand?
- There is a clear improvement in task success rate on CLIPort, and UniPi* is compared with various imitation/diffusion baselines.
- The quality ablation of active region shows a monotonic trend: no active region < pseudo predicted < supervised predicted < GT active region, indicating that there is a corresponding relationship between core variables and task success rate.
- Task loss ablation supports the conclusion from the perspective of action decoding: the active region not only improves the visual quality, but also makes the generated latent more suitable for decoding into correct actions.
- The visualization results of BridgeData v2 are consistent with the paper's proposition: in complex real scenes, active area conditions help the model select the right objects and locations.
Main limitations
- open-loop execution: The action sequence is generated and executed once during inference, without online re-planning or closed-loop error correction.
- pseudo active region depends on Co-Tracker: Long-term, complex background, occlusion or camera movement will affect point trajectory quality.
- Real world quantification is insufficient: BridgeData v2 results are primarily qualitative video plan comparisons and lack system success rate tables.
- High training cost: 8 A100 trains diffusion and inverse dynamics from scratch, which is easy to reproduce in ordinary laboratories.
- Action space remains mission/platform dependent: Although the title says universal policies, latent inverse dynamics outputs manipulation actions, and cross-robot forms still need to be re-adapted.
Questions to ask while reading
- Does the active region condition just help with "object selection", or does it also improve contact patterns and fine trajectories?
- If a task requires different active regions for multiple stages, is a single initial active region sufficient?
- Will extending the active region from the initial frame condition to the temporal active region further improve long tasks?
- If real strategy rollout is implemented on BridgeData v2, can the qualitative video advantage be stably transformed into a success rate advantage?
- Can VLM/text-guided segmentation replace the pseudo-label process of Co-Tracker + SAM in the future?