Dreamitate: Real-World Visuomotor Policy Learning via Video Generation
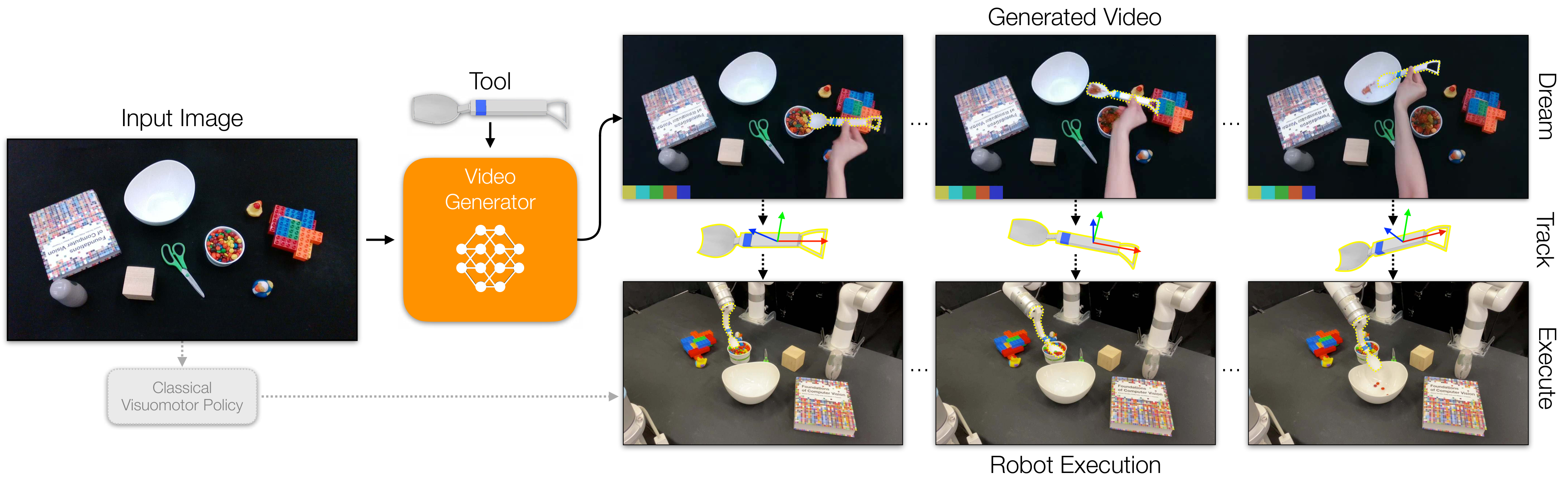
This paper uses "generating a video of a human using a tool to complete a task" as the middle layer of robot strategy learning: the video model first imagines how the tool should move, and then passes the trajectory to the real manipulator for execution through 3D tool tracking.
1. Quick overview of the paper
Dreamitate's core judgment is that for many tool operation tasks, what the robot really needs to reproduce is not the "human" arm movements, but the three-dimensional movement of the "tool". As long as the tool is a known rigid body and the video model can generate a reasonable tool usage process in the new scene, the tool trajectory in the generated video can be extracted and converted into the robot end effector trajectory.
| reading orientation | Short answer |
|---|---|
| What should the paper solve? | Reduce dependence on real robot action annotation and teleoperation data, allowing visual motion strategies to learn from human tool use videos and generalize under unseen objects, lighting and desktop conditions. |
| The author's approach | Connect human demonstration and robotic execution using the same set of 3D printable tools; fine-tune Stable Video Diffusion to generate binocular tool operation videos; track tool 6D pose with MegaPose and binocular geometry; let robots execute tool trajectories. |
| most important results | Significantly outperforms Diffusion Policy on four real-world tasks: rotation 37/40 vs. 22/40, scooping 34/40 vs. 22/40, sweeping 37/40 vs. 5/40, and Push-Shape's mIoU/rotation error is 0.731/8.0° vs. 0.550/48.2°. |
| Things to note when reading | It is not a universal language conditional strategy, nor is it a closed-loop real-time control; the experiments rely on known rigid body tools, binocular cameras, trackable tool motion, and task-level video models. The advantage comes from the tool intermediate representation, and the boundaries mainly come from this representation. |
2. Problems and motivations
2.1 Bottlenecks of behavioral cloning
Traditional behavioral cloning requires pairs of visual observations and robot action labels. Collecting this kind of data with real manipulators is usually slow and expensive, and is prone to out-of-distribution failure once objects, scenes, or tasks are changed. The author believes that learning directly from robot trajectories is clean, but it misses the large amount of human operation videos on the Internet and in the real world that are easier to collect.
2.2 Opportunities and gaps in video generation models
The video diffusion model has been able to generate reasonable future visual dynamics from static images, which means that it may carry priors on human behavior and object interactions. But generating "human videos" is not equivalent to generating "robot actions". There is a clear embodiment gap between human hands, arms, body poses, and robotic end effectors. The key twist in Dreamitate is to bypass the ontological differences between humans and robots and focus on shared tools.
2.3 The middle layer of paper selection
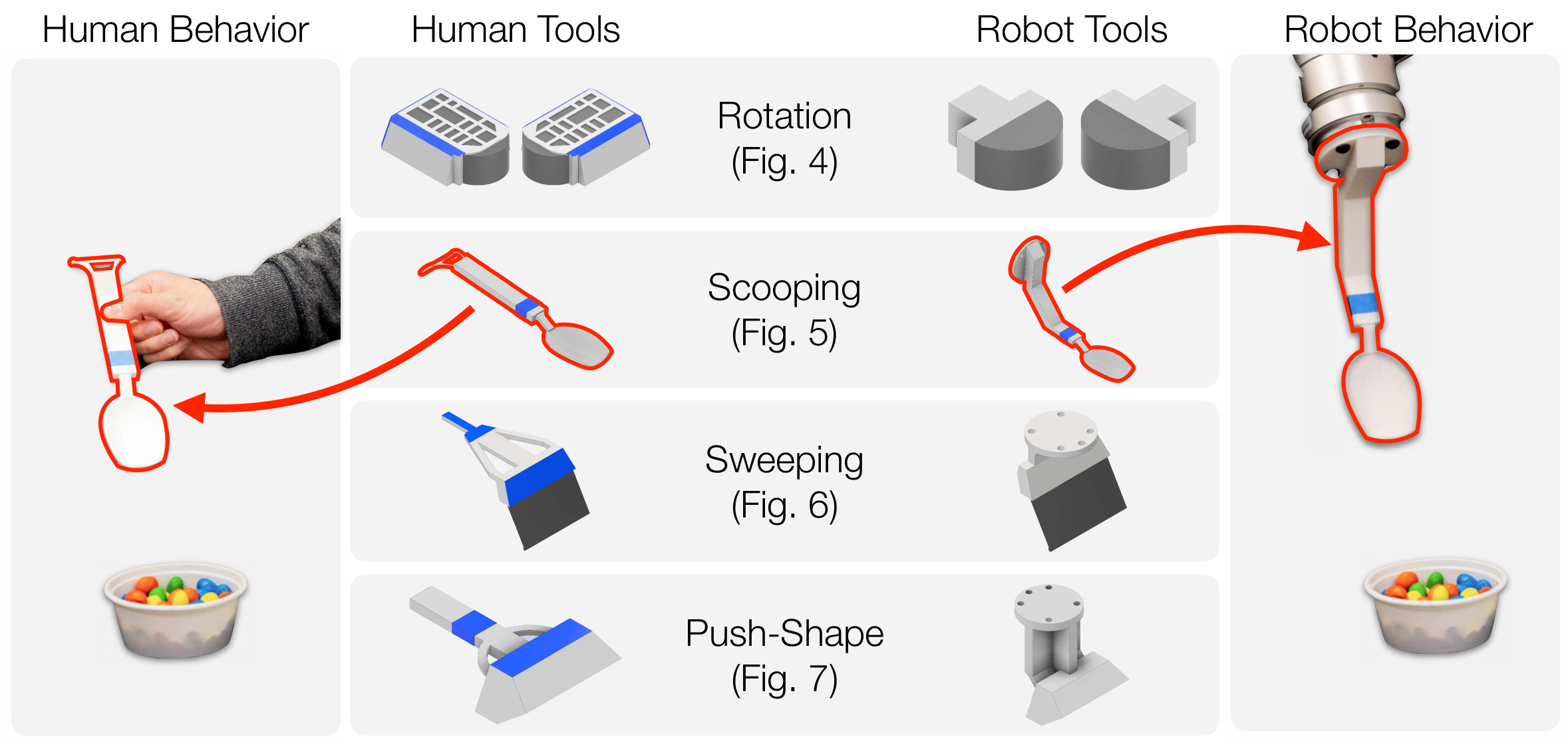
The author regards tools as carriers of action across embodiments: humans use tools in demonstrations, and robots are equipped with the same tools. As long as the tool trajectory is correct, the arm posture can be handed over to the inverse kinematics or trajectory execution module for processing. Therefore, the video model does not have to directly output robot movements, but rather outputs interpretable videos of tool movements.
3. Method dismantling

3.1 Formal goals
Given an initial scene image $v_0$, the goal is to plan a sequence of robot actions $a_t \\in SE(3)$. Dreamitate breaks action prediction into two steps: first generate a future video, and then read the tool trajectory from the video.
Here $f_\theta$ is the task-specific video generation model, and $T$ is the tool tracker. This split allows the strategy to have a visual intermediate result: if the robot fails, the researcher can check whether the video model is thinking wrong, or whether there is a problem with the tool tracking/trajectory execution.
3.2 Data Collection: Binocular Human Tool Demonstration
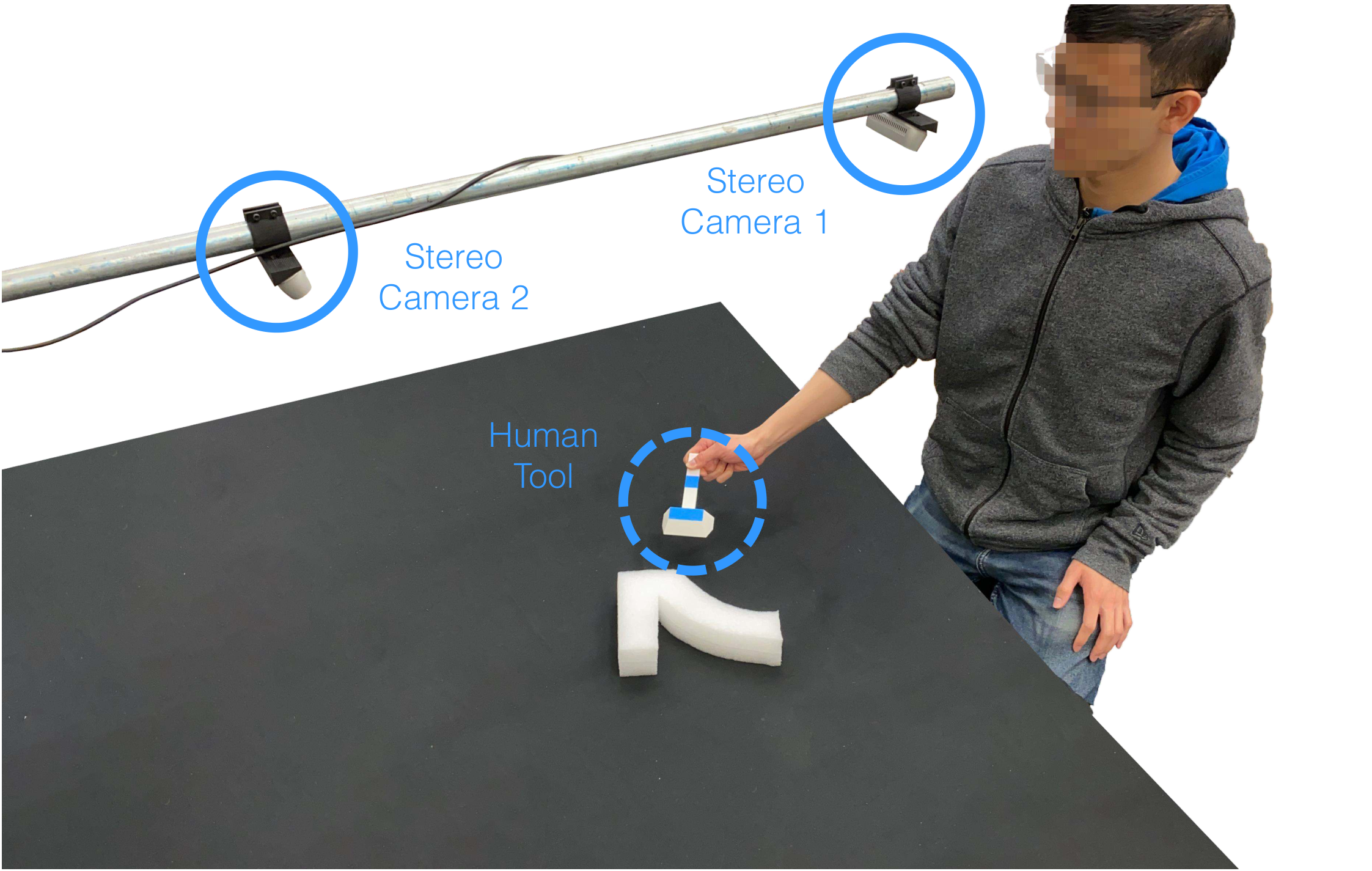
The training data comes from videos of humans using custom tools to complete tasks. The first frame of each demo is the scene input, and subsequent frames record how the person moves the tool. The paper uses two calibrated cameras to observe the desktop from different angles, which not only improves tool visibility, but also provides geometric constraints for subsequent 3D pose recovery.
The appendix supplements the camera setup: two Intel RealSense D435i cameras were placed approximately 660 mm apart, viewing the desktop at approximately 45° viewing angle, and approximately 760 mm from the desktop. The training videos are recorded at 1280×720, then cropped and scaled for use by the model. Use UFACTORY xArm 7 for Rotation and Scooping, and UR5 for Sweeping and Push-Shape.
3.3 Video model: fine-tuning tasks on Stable Video Diffusion
The author initializes with pre-trained Stable Video Diffusion and trains a model for each task. The training goal is to reconstruct the binocular demonstration video from the initial scene image, and the loss is the frame-by-frame $L_2$ distance between the predicted and ground-truth frames:
In implementation, the model generates 25 frames at a time: the first 13 frames correspond to the first perspective, and the last 12 frames correspond to the second perspective. The first frame is the same as the input and will be discarded during testing. The authors freeze the encoder and decoder, only fine-tune the spatial/temporal attention layer, and modify the image conditional embedding of each frame to mark the output perspective. 30 denoising steps are used during inference, and classifier-free guidance is set to 1.0.
3.4 Track then Act: From generating video to robot trajectory
Each task uses a 3D printing tool of a known CAD model. After the video is generated, the system uses MegaPose to estimate the 6D pose of the tool in each frame, and then combines the binocular camera calibration to fuse the estimates from the two perspectives into a three-dimensional trajectory. The appendix explains that the translation fusion method is to take the midpoint of the nearest point of the space straight line projected from the two viewing angles, and the rotation is to take the average of the estimates from the two viewing angles.
For tool parts that are easily blocked, the author has done task-based processing: in the scooping task, only the handle is tracked to avoid obstruction by particulate matter; in cleaning and push-shape, because the handle is blocked by human hands, the main body of the tool is tracked instead. The obtained tool trajectory $a_0, \ldots, a_T$ is directly executed as the robot end effector trajectory.
4. Experimental results
4.1 Experimental tasks and data scale
All experiments are done on real robots and real desktop environments. Training and testing maintain the same camera configuration, but different tabletops, lighting, and object collections; training and test objects do not overlap.
| Task | training object | Number of demos | test subject | Number of tests |
|---|---|---|---|---|
| Rotation | 31 objects | 371 | 10 objects | 40 |
| Scooping | 17 bowls, 8 pellets | 368 | 8 bowls, 4 pellets | 40 |
| Sweeping | 6 types of particulate matter | 356 | 6 types of particulate matter | 40 |
| Push-Shape | 26 letter shapes | 727 | 8 numbers/polygon shapes | 32 |



4.2 Baseline: Diffusion Policy
The main comparison method is the CNN version of Diffusion Policy. To be fair, the baseline uses the same batch of training data; its target trajectories are also extracted from human demonstrations through MegaPose, rather than using additional robot teleoperation data. The input is a binocular image, and the image encoder is two pre-trained ResNet-18, trained for 200 epochs, predicting 12 time steps into the future, and executed in an open-loop manner. The authors also tried a CLIP variant, but with even worse results.
4.3 Main results
| method | Rotation | Scooping | Sweeping | Push-Shape mIoU | Push-Shape rotation error |
|---|---|---|---|---|---|
| Diffusion Policy | 22/40 | 22/40 | 5/40 | 0.550 | 48.2° |
| Dreamitate | 37/40 | 34/40 | 37/40 | 0.731 | 8.0° |
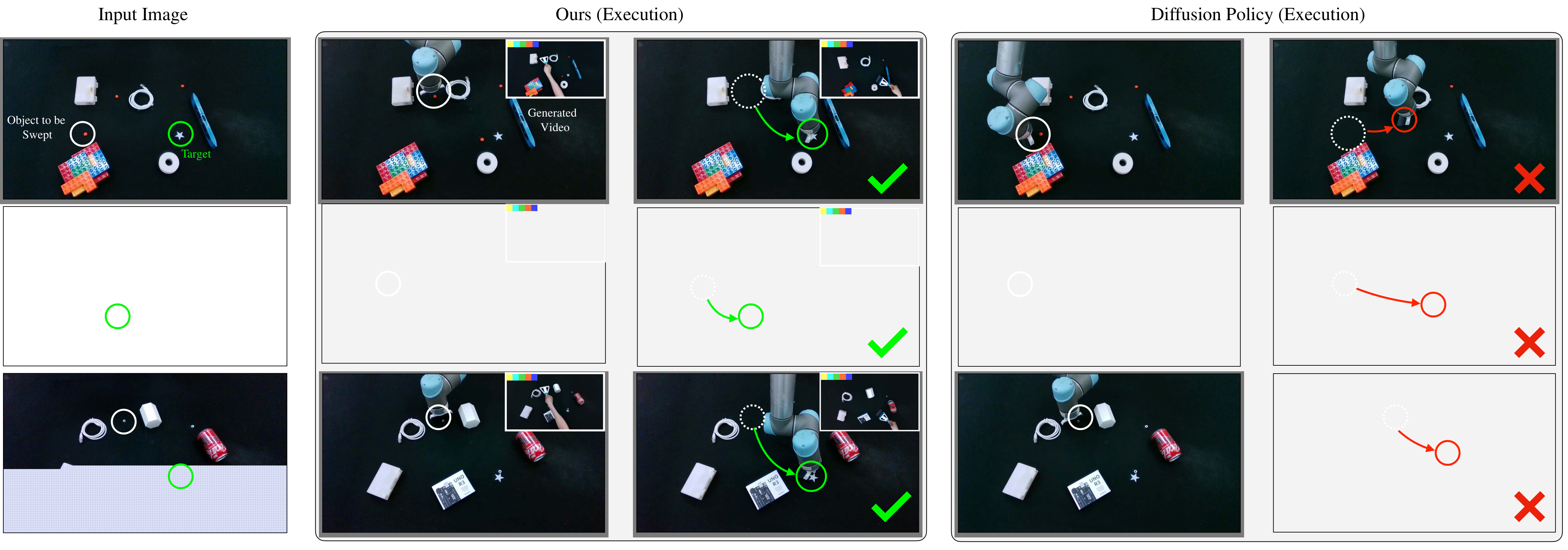
The strongest signal from the results is not a slight improvement in a certain task, but a significant improvement in four types of tasks with different geometries and contact patterns. In particular, Sweeping goes from 5/40 to 37/40, which shows that it is difficult for baseline to directly return a reliable tool path from the image, while Dreamitate's video middle layer can better express the spatial process of "first bypassing obstacles, and then sweeping the material to the target."
4.4 Interpretation of tasks
Rotation
The task requires contacting the object with the clamping tool and rotating it counterclockwise by at least 25° while maintaining contact. Dreamitate is at 92.5% and Diffusion Policy is at 55%. The author pointed out that common failures of baseline are failure to establish contact, unstable grasp points or slipping; the few failures of Dreamitate mostly occur on objects that are more difficult to see/contact, such as transparent bagged toys.
Scooping
The task requires scooping particulate matter into a target container. Dreamitate is 34/40 and Diffusion Policy is 22/40. Qualitative graphs show that baseline is easily disturbed by surrounding objects, or sends materials to the wrong container; the video trajectories generated by Dreamitate are closer to human scooping actions.
Sweeping
The task requires cleaning up particulate matter and avoiding obstacles. Dreamitate is 37/40 and Diffusion Policy is 5/40. The gap here is particularly large, probably because the cleaning task requires not only terminal reach, but also continuous path shape, obstacle avoidance, and contact direction to be jointly correct.
Push-Shape
This is a Push-T style long-term task, where the bubble shape needs to be pushed to the target mask while adjusting its orientation. Dreamitate's mIoU is 0.731 and the rotation error is 8.0°; although Diffusion Policy can push objects closer to the target, it often does not complete the correct rotation.

4.5 Data scale curve
The author conducted a training data proportion experiment on Rotation: when Dreamitate used 1/3 of the data, the success rate was 77.5%, 2/3 of the data was 75.0%, and the full amount of data was 92.5%; Diffusion Policy was 7.5%, 25.0%, and 55.0% respectively. This set of results supports the author's explanation: the pre-trained video model provides additional visual motion priors, allowing Dreamitate to maintain good performance under small-scale human demonstrations.
5. Integration of appendices information
5.1 Model hyperparameters
The appendix gives the video model training settings for each task. The resolution of all tasks is 768×448, and the learning rate is $10^{-5}$. Rotation, Scooping, and Sweeping are mostly trained at 16384 steps; Push-Shape is trained at 17408 steps. The clip duration of Rotation and Push-Shape is 2.0 seconds and fps is 6; the clip duration of Scooping and Sweeping is 3.0 seconds and fps is 5. The motion bucket scores are all 200.
| Task | resolution | learning rate | Batch | Number of training steps | Clip / FPS |
|---|---|---|---|---|---|
| Rotation Full | 768×448 | 1e-5 | 4 | 16384 | 2.0 s / 6 |
| Rotation 1/3 | 768×448 | 1e-5 | 3 | 15360 | 2.0 s / 6 |
| Scooping | 768×448 | 1e-5 | 4 | 16384 | 3.0 s / 5 |
| Sweeping | 768×448 | 1e-5 | 4 | 16384 | 3.0 s / 5 |
| Push-Shape | 768×448 | 1e-5 | 4 | 17408 | 2.0 s / 6 |
5.2 Real experimental layout
A black cloth tabletop was used to increase the frictional difference, which in particular increases the contact uncertainty of the Push-Shape. Push-Shape's mIoU is calculated in the first binocular view, and the best image is selected from the multi-step execution to calculate the IoU and rotation error. Sweeping and Push-Shape also limit the height of the end effector to prevent the tool from hitting the table.
5.3 Consistency of trajectory annotation
It is worth noting that the training labels for Diffusion Policy also come from the same set of MegaPose tool tracking pipelines. Therefore, the main comparison is not "the author's method has better trajectory annotation", but "under the same trajectory source, whether the intermediate layer of video generation is more stable than the direct action diffusion strategy." This allowed the main experiment to more focused on testing Dreamitate's methodological hypotheses.


6. The group will read the clues
6.1 It can be discussed in terms of three levels of questions
- Data layer: Why are human tool videos more scalable than robot motion data? Why can the same set of tools reduce the embodiment gap?
- Presentation layer: Why is generating video a useful intermediate representation? What more interpretable structure does it have than directly predicting actions?
- Execution layer: What errors are amplified when converting generated videos into SE(3) tool trajectories? What problems do binocular tracking and known CAD models each solve?
6.2 Suggested details for discussion
- The success of Dreamitate is not just "using large models", but constraining the video model to the robot executable space of the tool trajectory.
- The comparison with Diffusion Policy is relatively strong because both use the same demonstration data and homologous trajectory annotations; the difference mainly comes from policy representation.
- Scaling curve is a good discussion point in group meetings: Dreamitate is still 77.5% under 1/3 data, but slightly lower than 1/3 under 2/3 data, indicating that there is variance in small sample experiments and cannot be overly interpreted as a monotonic law.
- The rotation error of Push-Shape dropped from 48.2° to 8.0°, indicating that the video middle layer is particularly suitable for expressing the target posture and contact path, not just the end position.
7. Analysis, Limitations and Boundaries
The most valuable part of this paper
The most valuable part is that the visual motion prior of the video generation model falls on an intermediate representation that the robot can execute, inspect, and debug. The paper does not require the video model to directly generate robot joint commands, nor does it regard the generated video as just a good-looking visualization; it explicitly uses the tool 6D tracking to turn the video into a trajectory. This allows for an operational interface between "large-scale video priors" and "real robot control".
The second value is that the experimental design is closer to the real generalization problem. The training and test objects do not overlap, the tasks cover rotation, scooping, sweeping and long-term shape pushing, and the baseline uses the same batch of human demonstrations and homologous trajectory labels. The results are thus more suggestive: when the action space can be expressed by tool trajectories, generative video intermediate layers may be more robust than end-to-end action diffusion strategies.
Why does the result stand?
First, the lifting directions of the four tasks are consistent and cover different contact modes: continuous contact rotation, particle scooping, obstacle cleaning, and Push-Shape that requires joint adjustment of position and orientation. Secondly, the major numerical differences are large, such as Sweeping's 37/40 vs. 5/40, and Push-Shape rotation error 8.0° vs. 48.2°, which are less like small fluctuations caused by individual evaluation details. Third, the author explains in the appendix that both baseline and Dreamitate use MegaPose to obtain trajectories from demonstrations, making the comparison more focused on the form of policy learning rather than the advantages of additional annotation.
However, Rotation's data scale curve also reminds us that real robot experiments have variance, and 1/3 data 77.5% and 2/3 data 75.0% are not monotonic. Therefore, this set of curves is more suitable as supporting evidence that "pre-training video prior brings stability to small data" and should not be read as a precise scaling law.
Limitations explicitly acknowledged by the author
- Actions must be visually trackable: The system relies on recovering tool trajectories from generated videos, making it difficult to handle critical actions that are invisible, heavily occluded, or non-rigid.
- Tool occlusion can cause failure: If the end effector or tool body is severely obscured by hands, objects, or particles, MegaPose tracking will be unstable and subsequent robot trajectories will be affected.
- Rigid tool assumptions limit the scope of the task: Currently, it is more suitable for operations dominated by rigid body tools such as shoveling, pushing, sweeping, and clamping. It is not suitable for fine-grained finger control, flexible object manipulation, or complex assembly.
- High computational cost: The inference cost of the video diffusion model is relatively high, and the paper currently does not support real-time closed-loop control. The authors believe that future video model acceleration may alleviate this.
A deeper level of applicability
Dreamitate's boundaries can be summarized as follows: it is attractive when the "correctness" of the task is primarily determined by the 6D trajectory of the tool; its open-loop video-to-trajectory chain becomes brittle when the task requires high-frequency tactile feedback, closed-loop error correction, subtle force control, or latent variables outside of the tool. In other words, it transforms a complex robot learning problem into a video geometry problem that is easier to supervise and interpret, but does not remove the uncertainty of the contact physics itself.
At the group meeting, this paper can be discussed in the pedigree of "How does the visual generative model enter robot control": its answer is not to let the generative model directly control the robot, but to let the generative model generate an intermediate world that humans can understand, geometric algorithms can analyze, and robots can execute.
Reference and reproducibility Notes
This article is organized based on the LaTeX source code, PDF, main text and appendices of arXiv: 2406.16862. The images in the report come from local image assets that are included with the paper source code or have been converted, and are saved in Report/2406.16862/figures/.
Temporary files have been retained in tmp/arxiv_source_2406.16862.tar.gz, tmp/2406.16862.pdf and tmp/arxiv_source_2406.16862/, to facilitate subsequent verification of source code, PDF and charts.