This&That: Language-Gesture Controlled Video Generation for Robot Planning
1. 论文速览
| 速览问题 | 简明回答 |
|---|---|
| 论文要解决什么 | 视频生成可作为机器人计划,但语言-only 指令在复杂或不确定场景中常有歧义,尤其是“把这个放到那里”这类 deictic language。论文要解决的是:如何用简单的人类语言和指向手势无歧义地控制视频计划,并把计划转成机器人动作。 |
| 作者的方法抓手 | 两个模块:一是基于 Stable Video Diffusion 微调的 language-gesture conditioned VDM,用初始帧、文本和两个 2D gesture points 生成视频计划;二是 DiVA,一个 video-conditioned behavior cloning Transformer,用视频计划 tokens 和实时观测 cross-attention 输出动作 chunk。 |
| 最重要的结果 | Bridge 视频质量上,Ours 达到 FID 17.28、FVD 84.58、PSNR 21.71、SSIM 0.787、LPIPS 0.112,全部优于 SVD、StreamingT2V、DragAnything 和 AVDC;Isaac Gym rollout 中,完整 Video-based (V.+Lang.+Gesture) 在 ID/OOD 场景达到 Pick 95/87、Place 93/80,明显高于语言-only 版本。 |
| 阅读时要注意的点 | 这篇论文不是长程规划论文,而是单步/模块化任务中的“指令消歧 + 视频条件执行”论文。它的 real-robot 部分只评估了视频生成质量,动作执行实验目前在 Isaac Gym simulation;因此要区分“视频生成对齐真实机器人数据”和“真实机器人闭环执行”。 |
难度评级:★★★☆☆。需要熟悉 latent video diffusion、ControlNet/FiLM/CLIP conditioning、behavior cloning、ACT/Transformer policy、机器人视觉数据集与 rollout 评估。
关键词:language-gesture conditioning, deictic language, video diffusion model, Stable Video Diffusion, DiVA, video-conditioned behavior cloning, Bridge dataset, Isaac Gym。
核心贡献清单
- 语言-手势条件 VDM。在 SVD 基础上微调机器人视频,并加入稀疏 gesture conditioning,使模型能理解“this/that/there”。
- 自动手势标注流程。用 Bridge metadata、YoloV8 gripper detector 和 TrackAnything 自动恢复真实数据中的 pick/release gesture points。
- DiVA 执行模型。把生成视频作为 dense visual goal sequence,通过 TokenLearner 压缩、cross-attention 融合实时观测,输出动作 chunk。
- 系统性验证手势价值。用户对齐、视频质量、VDM ablation、DiVA ablation 和 simulation rollout 都显示语言+手势优于单一模态。
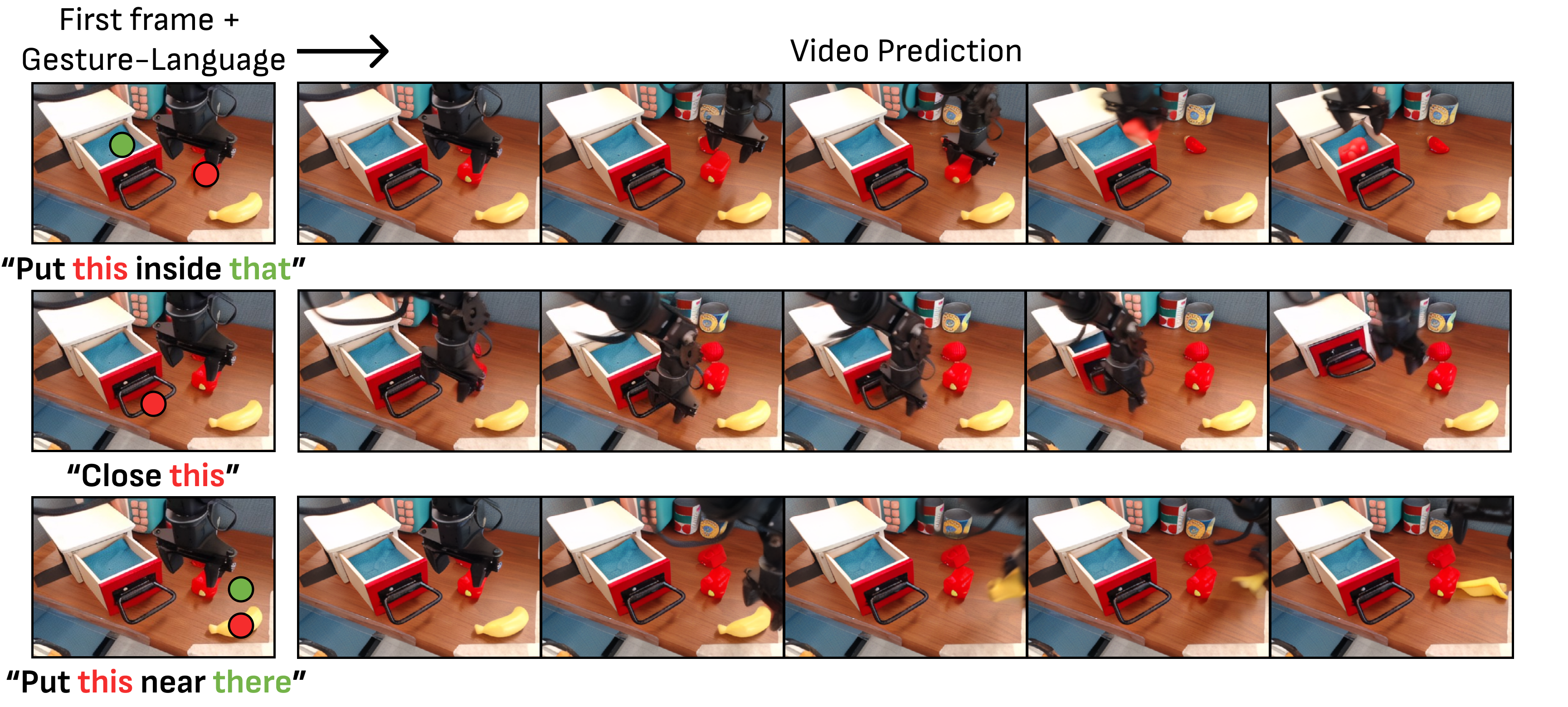
2. 动机
2.1 为什么语言不够
人类给指令时常常说“拿这个”“放到那里”,同时用手指指向目标。单独用自然语言描述同一个任务可能很冗长,而且在真实桌面、柜子、洗衣区这类复杂环境中容易歧义。例如“拿第三排蓝色杯子”依赖准确的空间描述和物体识别,而指向手势可以直接补上空间参照。
2.2 为什么视频计划适合机器人
视频计划比单张目标图更稠密,能描述从初始状态到目标状态的中间过程。对于机器人执行来说,这些中间帧可以作为 dense sequence of visual goals,减少单图目标的歧义,也比直接从语言预测动作更贴近视觉控制。
2.3 已有视频机器人方法的缺口
UniPi、UniSim 等方法展示了视频生成可模拟机器人交互,但常通过 inverse dynamics 将视频转动作。AVDC 用低分辨率视频计划并从 optical flow 提取离散动作。这些方法在模糊场景中很难只靠语言精确指定对象和目标位置,本文通过 language + gesture 进行定向视频生成,并通过 BC 架构直接引用视频计划。
4. 问题形式化
4.1 视频生成目标
模型从初始帧 $I_0$ 出发,生成 $T$ 个未来帧,条件包括语言 $C_{\text{text}}$ 和手势 $C_{\text{gest}}$:
这个分布表示:在给定当前图像、文本和指向手势时,未来视频应该如何变化。
$$p_{\theta}(I_0,\ldots,I_T \mid I_0, C_{\text{text}}, C_{\text{gest}})$$| $I_0$ | 初始图像,也作为 image conditioning。 |
| $C_{\text{text}}$ | 任务文本,可以是常规描述,也可以是 deictic prompt,如 “put this to there”。 |
| $C_{\text{gest}}$ | 稀疏手势图像,通常由 pick 点和 place/release 点构成。 |
| $I_{1:T}$ | VDM 生成的机器人未来视觉计划。 |
4.2 DiVA 动作条件分布
DiVA 学习从实时观测、机器人状态和视频计划中预测下一个 action chunk:
| $a_{t:t+k}$ | 从时间 $t$ 开始要执行的动作片段。实验中 action chunk size $k=10$。 |
| $o_t$ | 当前 live image observation。 |
| $s_t$ | 机器人 end-effector pose。 |
| $\tau$ | 视频计划 $\mathcal{I}=[I_0,\ldots,I_T]$ 的子集,作为 dense visual goals。 |
5. 方法详解
5.1 系统总览
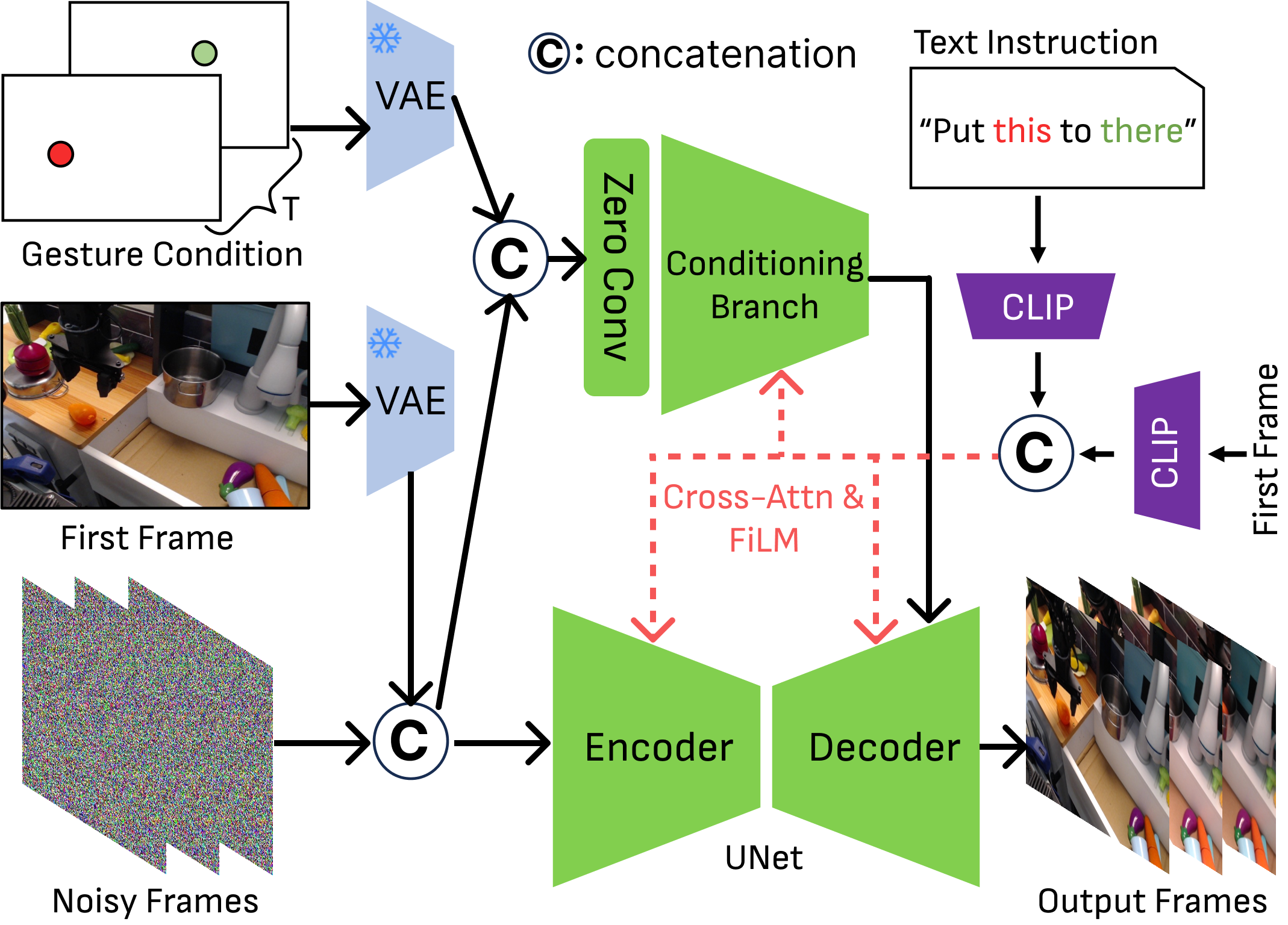
This&That 包含两个模块:language-gesture conditioned video generation 和 video-conditioned behavioral cloning。前者用简短文本和手势生成视觉计划;后者将视觉计划和实时观测映射为机器人动作。

5.2 Language-conditioned finetuning
作者以 Stable Video Diffusion (SVD) 为基础。SVD 是 latent VDM,利用 encoder $\mathcal{E}$ 和 decoder $\mathcal{D}$ 在像素空间和 latent space 之间转换。由于开域 SVD 并不适合机器人任务,作者先用 Bridge 机器人视频对 SVD 的核心结构做 initial finetuning。
文本 $C_{\text{text}}$ 和初始帧 $I_0$ 通过 CLIP encoder 提取 token,再通过 cross-attention 和 FiLM 生成调制参数,作用于 UNet 中间特征。训练时对 $I_{0:T}$ 加 Gaussian noise,并优化 noise reconstruction loss。
5.3 Gesture-conditioned branch
标准 ControlNet 式稀疏点条件在这里不够,因为两个 2D 点太稀疏,直接输入容易被网络忽略。作者在 gesture conditioning branch 的第一层卷积前,将三个 latent 级别输入 channel-wise concatenate:
其中 $\mathcal{E}(I_0)$ 是初始帧 latent,$\epsilon_t$ 是 denoising step 的 noisy video latent,$\mathcal{E}(C_{\text{gest}})$ 是 gesture image latent。补充材料给出形状:三者都是 $\mathbb{R}^{(B\times T)\times4\times H\times W}$,拼接后为 $\mathbb{R}^{(B\times T)\times12\times H\times W}$。
两阶段训练中,第二阶段初始化 conditioning branch,并接入 zero convolution;gesture branch 的输出加到 UNet decoder,类似 ControlNet。手势点会被 2D Gaussian dilation 或 10x10 pixel block 扩展,降低稀疏性。
5.4 自动手势标注
Bridge 数据没有人工 gesture labels。作者用 robot metadata 找到 gripper close/open 的关键时刻,再定位 pick/release 目标点。具体流程:
- 用 450 张人工标注图训练 YoloV8 gripper detector,检测 gripper bounding box。
- 根据关键帧恢复 gripper 与物体交互位置。
- 用 TrackAnything 跟踪物体运动,尤其处理物体被中途释放后继续移动的情况。
- 过滤 tracking 失败、过短或超过目标帧数 5 倍的视频。
这个流程让真实 Bridge 数据可用于自监督训练语言-手势 VDM。
5.5 DiVA: Diffusion Video to Action
DiVA 是 Transformer encoder-decoder BC 模型。它不是把视频逐帧做 inverse dynamics,而是把视频计划当作参考目标,与 live observation 做 cross-attention。
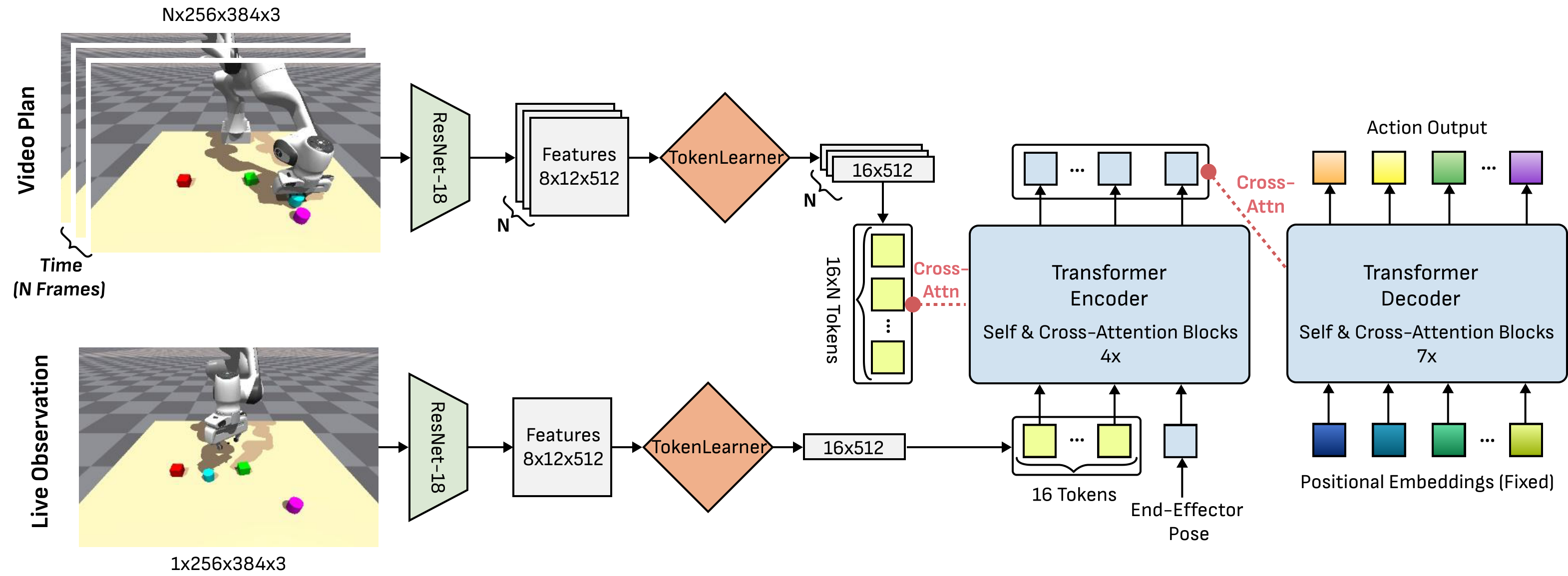
关键设计:
- ResNet-18 embedding。每张 $256\times384\times3$ 图像变成 $8\times12\times512$ latent embedding。
- TokenLearner 压缩。将每张图的 96 个空间 token 压到 16 个动态 token,避免视频帧过多导致 token 爆炸。
- Observation-token 与 goal-token cross-attention。当前观测和 end-effector pose 形成 $O\in\mathbb{R}^{17\times512}$,Transformer encoder 通过 4 层 self/cross-attention 引用 goal tokens。
- Decoder 输出动作 chunk。Transformer decoder 使用 7 层 self/cross-attention,将固定 positional embeddings 转为 $k=10$ 个动作。
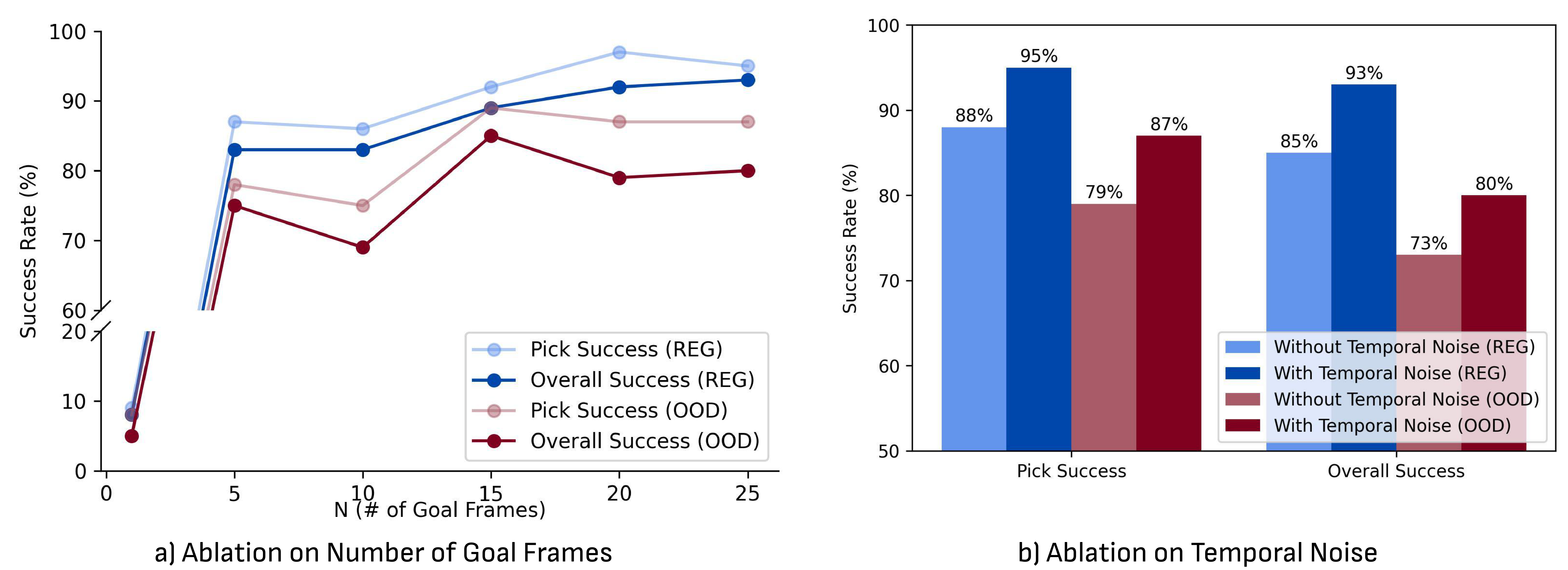
- Temporal noise。训练时从 $N$ 个连续 observation groups 中随机采样目标帧,使 DiVA 对生成视频和真实轨迹之间的小时间错位更鲁棒。
作者曾尝试 inverse dynamics,但因为 VDM 固定输出帧数,而真实 demonstration 长度变化,导致固定帧到动作插值困难;DiVA 避免了额外 temporal interpolation diffusion model。
5.6 附录训练细节
| 模块 | 配置 | 来源 |
|---|---|---|
| Bridge VDM stage 1 | 8 Nvidia L40S GPUs,每张 48GB;UNet 训练 99K iterations;batch size 1/GPU;默认 SVD 14-frame 权重。 | 补充材料 VDM Training Details |
| Bridge VDM stage 2 | 4 GPUs,gesture conditioning 训练 30K iterations。 | 补充材料 VDM Training Details |
| Isaac Gym VDM | stage 1 用 8 GPUs 训练 30K iterations;stage 2 用 4 GPUs 训练 15K iterations;初始权重是 SVD-XT 25-frame version。 | 补充材料 VDM Training Details |
| 优化器 | AdamW;两阶段 constant learning rate 分别为 $1e^{-5}$ 与 $5e^{-6}$;使用 8-bit Adam 降低显存;无 EMA。 | 补充材料 VDM Training Details |
| DiVA 训练 | 900 training instances,100 heldout testing;每个 demo 约 75-100 observation-action pairs;单张 Nvidia RTX 6000 Ada GPU;2000 epochs;batch size 8;learning rate $1e^{-5}$;weight decay $1e^{-4}$;action chunk size 10。 | 补充材料 DiVA Training Details |
| 数据增强 | horizontal flip 概率 0.45;若 prompt 包含 left/right 等位置词,则不翻转。 | 补充材料 VDM Training Details |
6. 实验与结果
实验验证三件事:视频是否真实并对齐用户意图;语言-手势 conditioning 是否必要;生成视频是否能帮助下游机器人动作学习。
6.1 Bridge 视频质量评估
作者在 Bridge V1/V2 上训练,前视角数据经过长度筛选。用于 initial finetuning 的视频为 25,767 条,用于 gesture-conditioned training 的视频为 14,735 条。评估使用 Bridge test videos,其中主表使用 646 个 gesture label filtering 后的 Bridge V1 视频。
| Method | FID ↓ | FVD ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|---|---|
| SVD | 29.49 | 657.49 | 12.47 | 0.334 | 0.391 |
| StreamingT2V | 42.57 | 780.81 | 11.35 | 0.324 | 0.504 |
| DragAnything | 34.38 | 764.58 | 12.76 | 0.364 | 0.466 |
| AVDC | 163.93 | 1512.25 | 20.23 | 0.663 | 0.507 |
| Ours | 17.28 | 84.58 | 21.71 | 0.787 | 0.112 |
该结果说明:开域视频模型直接用在机器人场景上不够,AVDC 虽然是 robotics VDM 但分辨率和视觉质量较差;本文 VDM 在视觉质量、时序质量和 perceptual loss 上都显著更好。补充材料还在 AVDC 原生低分辨率 $48\times64$ 下比较,Ours resized 到 $48\times64$ 仍优于 AVDC。
6.2 用户意图对齐实验
用户研究由 3 名有 robotics 经验的参与者完成。测试集 24 个 Bridge cases:8 个 pick-and-place、5 个 stacking、6 个 folding、5 个 open/close。参与者看到初始图、非 deictic prompt 和 gesture points,判断生成视频是否正确完成意图。使用文本的方法同时测试 regular text 和 deictic text。
| Modality | Pick&Place | Stacking | Folding | Open/Close | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Reg | Deic | Reg | Deic | Reg | Deic | Reg | Deic | Reg | Deic | |
| Vision | 0.0 | - | 6.6 | - | 11.1 | - | 60.0 | - | 16.7 | - |
| AVDC (V.+Lang.) | 8.3 | 8.3 | 0.0 | 0.0 | 5.6 | 5.6 | 40.0 | 40.0 | 12.5 | 12.5 |
| V.+Lang. | 37.5 | 4.2 | 26.7 | 6.6 | 50.0 | 33.3 | 100.0 | 66.7 | 51.4 | 25.0 |
| V.+Gesture | 58.3 | - | 66.7 | - | 55.6 | - | 100.0 | - | 68.1 | - |
| V.+Lang.+Gesture | 95.8 | 91.6 | 80.0 | 66.7 | 88.9 | 94.4 | 100.0 | 93.3 | 91.7 | 87.5 |
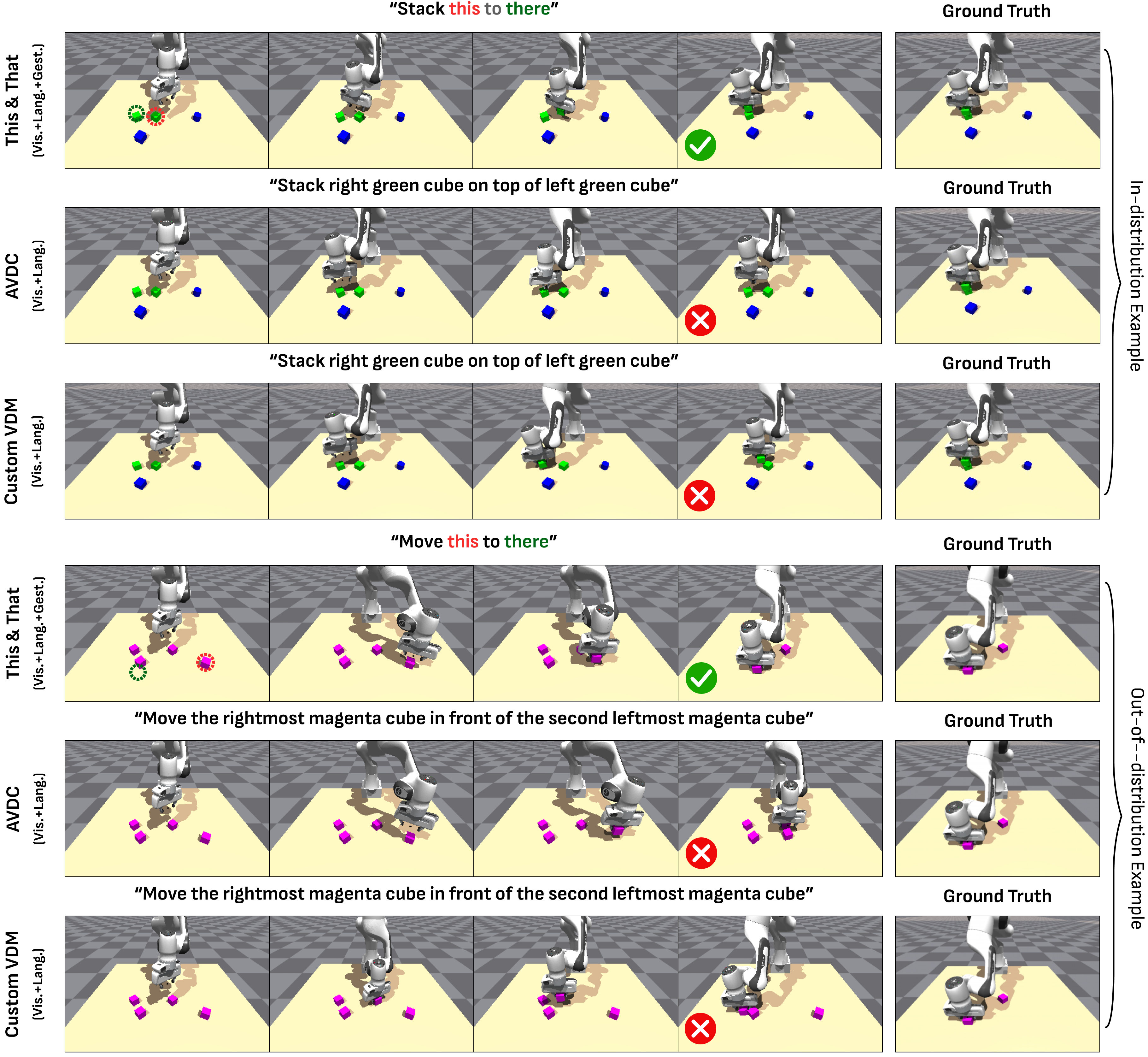
最关键的观察是:deictic text 下,language-only 平均只有 25.0%,而 language+gesture 仍有 87.5%。这正对应论文要解决的“this/that/there 指令需要手势消歧”。Open/Close 任务歧义较低,所以 language-only 也较强。
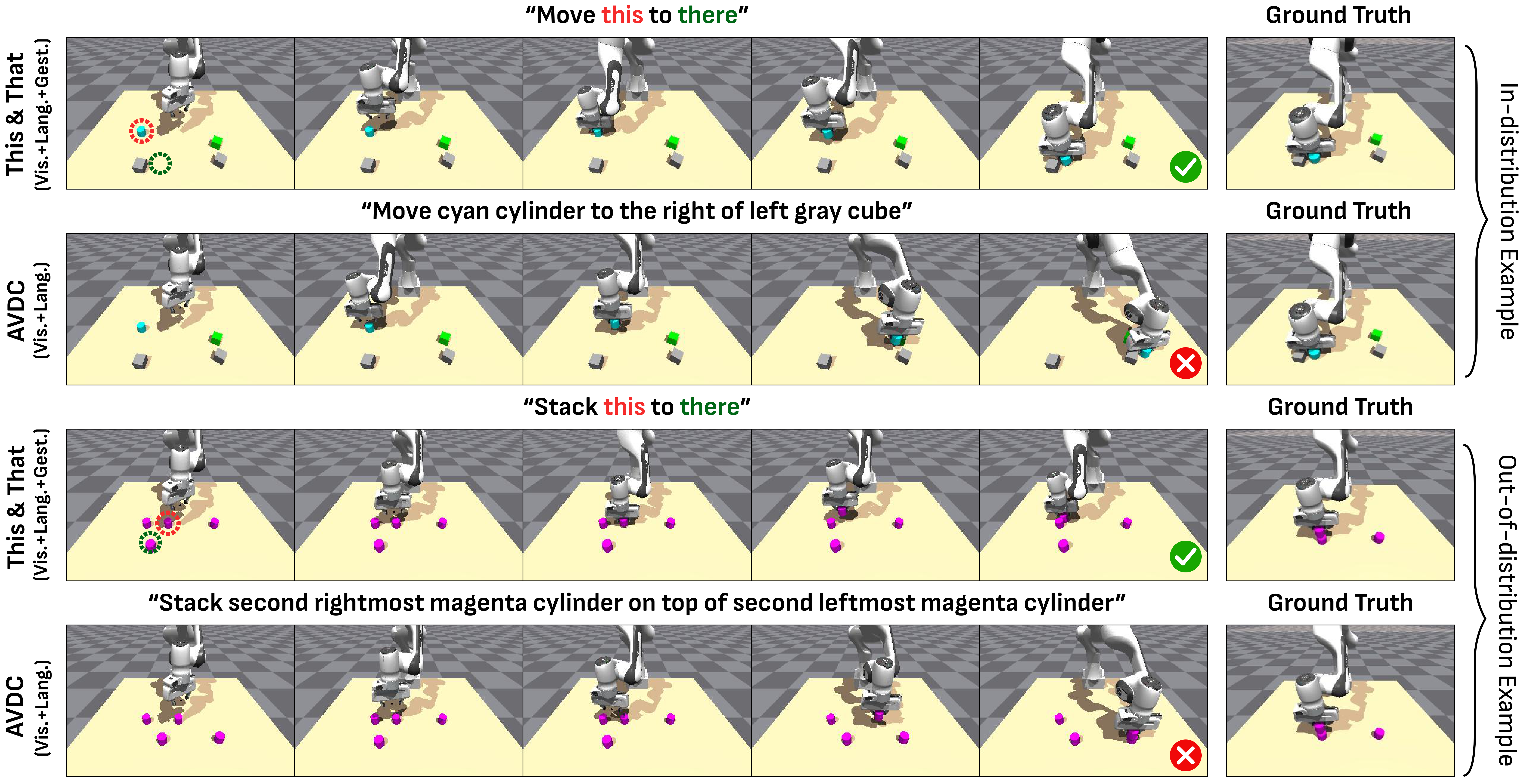
6.3 Isaac Gym rollout 实验
模拟环境中桌面上有四个 blocks,形状为 cube/cylinder,颜色 8 种。任务通过两个随机物体和五种关系构造:in front of、behind、to the right of、to the left of、on top of。动作是 7D command:end-effector frame 下的 delta pose,加一个连续 gripper open/close 标量。
| Goal Conditioning | Pick Success ID/OOD (%) | Place Success ID/OOD (%) |
|---|---|---|
| ACT (Vision-only) | 5 / 3 | 0 / 1 |
| ACT (V.+Lang.) | 3 / 3 | 0 / 0 |
| ACT (V.+Lang.+Gesture) | 57 / 56 | 35 / 35 |
| AVDC-retrain (V.+Lang.) | 67 / 40 | 46 / 14 |
| Video-based (V.+Lang.) | 93 / 60 | 82 / 26 |
| Video-based (V.+Lang.+Gesture) | 95 / 87 | 93 / 80 |
这个表说明两层结论:第一,video-based planning + DiVA 明显优于直接 ACT,即视频计划作为中间表示是有用的;第二,在 OOD identical blocks 场景中,gesture 极大提升 place success,从 language-only 的 26% 到 language+gesture 的 80%。
6.4 VDM ablation
| Method | FID ↓ | FVD ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|---|---|
| Regular ControlNet | 22.158 | 124.710 | 19.975 | 0.758 | 0.134 |
| With SAM Segmentation Mask | 17.922 | 88.757 | 21.554 | 0.785 | 0.115 |
| No LayerNorm on CLIP Embeddings | 17.566 | 92.527 | 21.559 | 0.786 | 0.114 |
| Larger Gesture Conditioning | 18.844 | 96.794 | 21.180 | 0.778 | 0.122 |
| Smaller Gesture Conditioning | 19.813 | 106.953 | 21.506 | 0.782 | 0.119 |
| Ours | 17.278 | 84.580 | 21.716 | 0.787 | 0.112 |
ablation 支持三点:普通 ControlNet conditioning 不适合极稀疏 gesture;用 SAM mask 增加空间信息不一定更好,因为 segmentation 可能圈出桌面等无关区域;gesture 区域太大或太小都会变差。
6.5 DiVA ablation
补充材料中 DiVA ablation 研究了 goal frame 数量 $N$ 和 temporal noise。只用最后一帧 $N=1$ 几乎无法成功;随着目标帧数增加,表现大致线性提升,在 $N=15$ 到 $N=25$ 附近趋于平台期。加入 temporal noise 后,DiVA 更准确、更鲁棒。
6.6 补充定性结果

7. 分析、局限与边界
7.1 这篇论文最有价值的地方
这篇论文最有价值的地方是把“人类自然指令”里的指向行为系统性地接入视频规划。它没有把用户要求变成越来越长的语言描述,而是承认日常指令中手势和 deictic words 是一体的:语言提供任务语义,手势提供空间参照。这个接口设计比单纯提高语言模型空间推理能力更直接。
第二个价值是 DiVA 的执行设计。许多视频规划论文把视频转动作留给 inverse dynamics,但本文发现固定帧数视频和变长 demonstration 不好对齐,于是把视频计划作为 dense goal tokens 放进 BC Transformer。这个设计把视频计划和模仿学习更自然地接了起来。
7.2 结果为什么站得住
首先,论文的三个实验层次对应三项主张:Bridge 定量指标证明视频生成质量,用户研究证明语言+手势对齐意图,Isaac Gym rollout 证明视频计划能帮助动作执行。不是只在一个指标上好看。
其次,关键对照覆盖了不同替代路线:开域 SVD、StreamingT2V、DragAnything,机器人 VDM AVDC,直接 ACT 变体,language-only video-based baseline。完整方法在视频质量、用户对齐和 rollout 都优于这些 baseline,尤其 OOD identical blocks 场景中手势带来的提升非常明显。
第三,补充 ablation 支持具体设计选择:regular ControlNet、SAM mask、去掉 CLIP LayerNorm、改变 gesture area 都不如最终 VDM;DiVA 中增加 goal frames 和 temporal noise 也有明确趋势。因此结果不仅是“多模态更多所以更好”,而是几个实现细节都被拆开验证过。
7.3 论文明确给出的结果解释
- 语言-only 在空间歧义和相同物体场景中不足,加入 gesture 能显著消歧。
- 视频计划作为 dense sequence of images 比单张 goal image 更适合下游策略学习。
- DiVA 的成功来自 TokenLearner 压缩、observation-goal cross-attention、temporal noise 三个因素。
- gesture-only 也不完美,因为 2D 手势点无法唯一确定 3D 点;简单语言 cue 可以补足这种 3D ambiguity。
7.4 作者自述局限
| 局限 | 论文中的说明 | 影响范围 |
|---|---|---|
| 物体形状随时间变化 | 模型有时生成高保真视频但 object shape 会改变,作者认为可能来自缺少 3D geometry constraints。 | 需要精确几何、姿态或接触状态的执行任务。 |
| 短模块化任务 | 预测目前限制在 short, modular tasks;扩展到 cooking 等长任务仍是机会。 | 长程多阶段任务、需要 memory 和 replanning 的任务。 |
| gesture-only 的 3D ambiguity | 2D image-plane coordinate 不完全决定 3D point,图中展示 gesture-only 可能失败,语言 cue 可以解决。 | 有深度歧义、遮挡、多物体重叠的场景。 |
| 真实机器人执行未测试 | 视频生成在 Bridge 真实数据上评估,但 video-based BC rollout 目前限于 simulation,原因是缺少 WidowX 250 arm。 | 真实闭环机器人部署结论仍需进一步验证。 |
7.5 适用边界
This&That 最适合单步或短模块化 manipulation,尤其是用户能通过指向手势明确对象和目标位置、但语言描述会冗长或歧义的场景。它不适合纯语言即可无歧义的简单任务,也不适合需要精确 3D 几何、强接触物理、长程多阶段规划或已要求真实机器人闭环验证的任务。
8. 可复现性审计
8.1 数据
- 已给出:Bridge V1/V2 前视角数据;initial finetuning 25,767 videos;gesture-conditioned training 14,735 videos;test split 使用 10% 数据,主 VDM 表用 646 Bridge V1 videos。
- 已给出:Isaac Gym 数据生成方式:四个 blocks,2 shapes、8 colors、5 spatial relations,scripted policy 收集 demos。
- 部分缺失:完整训练/测试样本 ID、自动过滤阈值细节和全部 prompt 脚本未在报告源码中完整列出。
8.2 模型与训练
- VDM 以 SVD/SVD-XT 为初始权重,两阶段训练,给出 GPU 数、iteration 数、学习率、优化器和 batch size。
- DiVA 给出 ResNet-18 embedding shape、TokenLearner tokens、Transformer encoder/decoder 层数、action chunk size、训练样本量、epoch、batch size、learning rate、weight decay。
- 手势自动标注给出 YoloV8 gripper detector、450 manual images、TrackAnything tracking 和过滤规则。
8.3 评估
- 视频质量指标包括 FID、FVD、PSNR、SSIM、LPIPS;FID 从 generated/GT frames 中随机采样 9000 images。
- 用户研究包含 3 名有 robotics 经验参与者、24 cases、regular/deictic prompts、多个 modality conditions。
- rollout 评估给出 pick/place 成功规则、250 timesteps、成功后 5 timesteps 终止、block diameter 5cm。
8.4 最小复现路径
最现实的复现可从 Isaac Gym 开始:构建四块积木 pick-place 数据,训练一个 SVD-XT 初始化的低成本 language-only 和 language-gesture VDM,再训练 DiVA。核心验证是 OOD identical blocks 中,手势是否显著改善生成视频与 rollout success;不必一开始复现完整 Bridge 训练和用户研究。