Flow as the Cross-Domain Manipulation Interface
1. 论文速览
| 阅读定位项 | 内容 |
|---|---|
| 论文要解决什么 | 真实机器人 teleoperation 数据昂贵,且人手视频和机器人动作空间差异大;作者想让机器人在没有真实机器人训练数据的情况下,从真实人类示范视频和仿真探索数据中学到真实操作技能。 |
| 作者的方法抓手 | 使用 object flow 作为跨 embodiment、跨环境接口。flow generation network 从初始图像和任务描述生成完整 task flow;flow-conditioned imitation policy 根据 task flow、当前 keypoint tracking 和 proprioception 输出机器人末端动作。 |
| 最重要的结果 | 真实世界四任务 language-conditioned 成功率为 Pick&Place 90%、Pouring 80%、Drawer 85%、Cloth 70%,平均约 81%;仿真 language-conditioned 为 90%、85%、90%、35%;long-horizon 多物体任务达到 85%。 |
| 阅读时要注意的点 | 方法依赖 2D flow、Grounding DINO、SAM/motion/depth filters、TAPIR online point tracking 和相机视角校准;2D flow 对 3D 动作有歧义,cloth 在仿真 language-conditioned 中只有 35%,是读实验时最该盯住的边界。 |
难度评级:★★★★☆。需要理解 point tracking / object flow 表示、Latent Diffusion / AnimateDiff 条件生成、transformer temporal alignment、Diffusion Policy,以及 sim-to-real 和 cross-embodiment 实验设计。
核心贡献清单
- Object flow 接口:作者把“物体的运动”而不是“机器人动作”作为中间变量,显式排除背景和 embodiment motion,减少人手/机器人外观差异。
- 分离高层任务理解与低层执行:flow generation network 从 cross-embodiment human videos 学高层 task flow;flow-conditioned policy 从 simulated robot exploration data 学低层动作映射。
- 真实机器人无真实训练数据部署:真实 UR5e 任务不使用真实机器人训练数据,依赖人手视频 + 仿真探索,并在刚体、关节物体、柔性物体任务上测试。
- 完整附录验证:附录补充 ATM 对比、long-horizon 多物体任务、initial 3D keypoints ablation、Stable Diffusion 预训练 ablation、真实评估协议和额外局限。
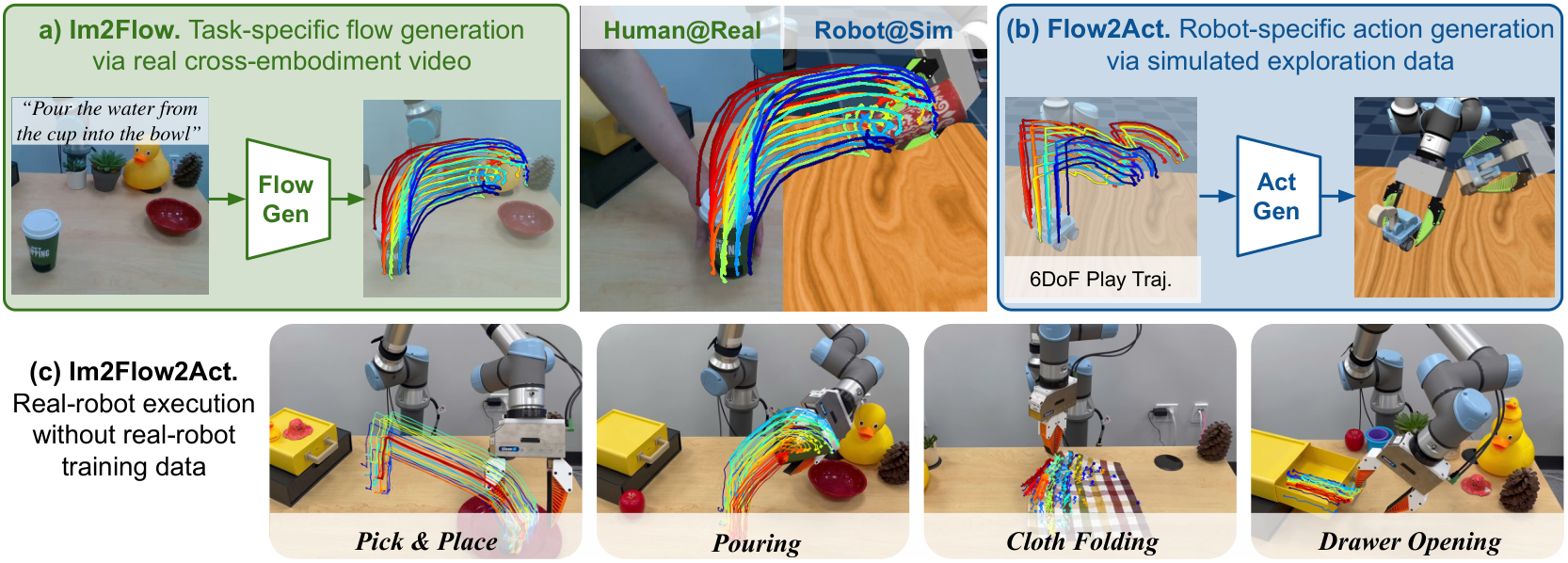
2. 动机
2.1 要解决什么问题
机器人学习要扩展到多任务真实场景,关键困难不是单个任务有没有示范,而是示范数据的来源彼此不兼容。真实机器人数据贵,仿真数据和真实外观/接触动力学不同,人类视频没有机器人动作,并且人手和 UR5e 夹爪的 embodiment 完全不同。作者的出发点是:如果只看“被操作物体应该如何移动”,那么这种信息比关节动作或人手轨迹更容易跨 embodiment 复用。
2.2 已有方法的局限
- Flow-based manipulation 仍常需真实机器人数据:ATM 能用 flow-conditioned BC 做 articulated/deformable 操作,但仍需要真实世界 robot teleportation 数据;Track2Act / General Flow 类启发式方法需要 3D flow、位姿估计或人工放置接触点。
- Cross-embodiment 方法仍难跨动作空间:很多方法从人类视频提视觉表征、奖励、affordance 或手部姿态,但为了弥补 embodiment gap 仍要收集 in-domain robot data。
- Grid flow 会捕捉 embodiment motion:ATM 等 uniform grid flow 会跟踪人手、球形 agent 或机器人臂自身,部署时看到 UR5e 夹爪会出现 visual input out-of-distribution。
- 纯 2D 表示存在 3D 歧义:2D flow 对 z 轴移动、out-of-plane rotation、screwing 这类动作细节不充分,这是作者在主文和附录都承认的限制。
2.3 本文的解决思路
Im2Flow2Act 把系统拆成两个可分别训练的模块。第一,flow generation network 输入初始 RGB 图像、任务描述和初始 object keypoints,输出完整 task flow。第二,flow-conditioned imitation policy 输入 task flow、当前 tracked keypoints 和 proprioception,输出未来 16 步的 end-effector action sequence。部署时只在任务开始生成一次完整 flow,执行过程中通过在线点跟踪和 temporal alignment 找到当前进度对应的剩余 flow,再闭环输出动作。
3. 相关工作梳理
| 技术线 | 论文中的定位 | 本文怎么接上 |
|---|---|---|
| Flow-based manipulation | FlowBot3D、ToolFlowNet 等说明 flow 可用于 articulated objects 或 tool manipulation,但任务较专;RoboTAP/ATM/Track2Act 等仍需要真实机器人数据、启发式动作或 task-specific 条件。 | Im2Flow2Act 只生成 object-centric flow,并用仿真 exploration data 学习 flow-to-action policy,目标是减少真实机器人数据依赖。 |
| Learning from cross-embodiment data | 已有路线包括视觉预训练、奖励学习、affordance 提取、hand pose、domain translation 和 video/flow generation。 | 作者认为人类视频里最可迁移的是被操作物体的 motion;因此不从人手动作直接迁移,而是先抽象成 object flow。 |
| Sim-to-real transfer | 常见方法包括 depth observation、domain randomization、knowledge distillation、system identification,但往往需要 task-specific simulation 或 reward design。 | 本文的 policy 不依赖任务特定仿真奖励,而从预定义 primitive 生成的 task-less simulated exploration data 中学习。 |
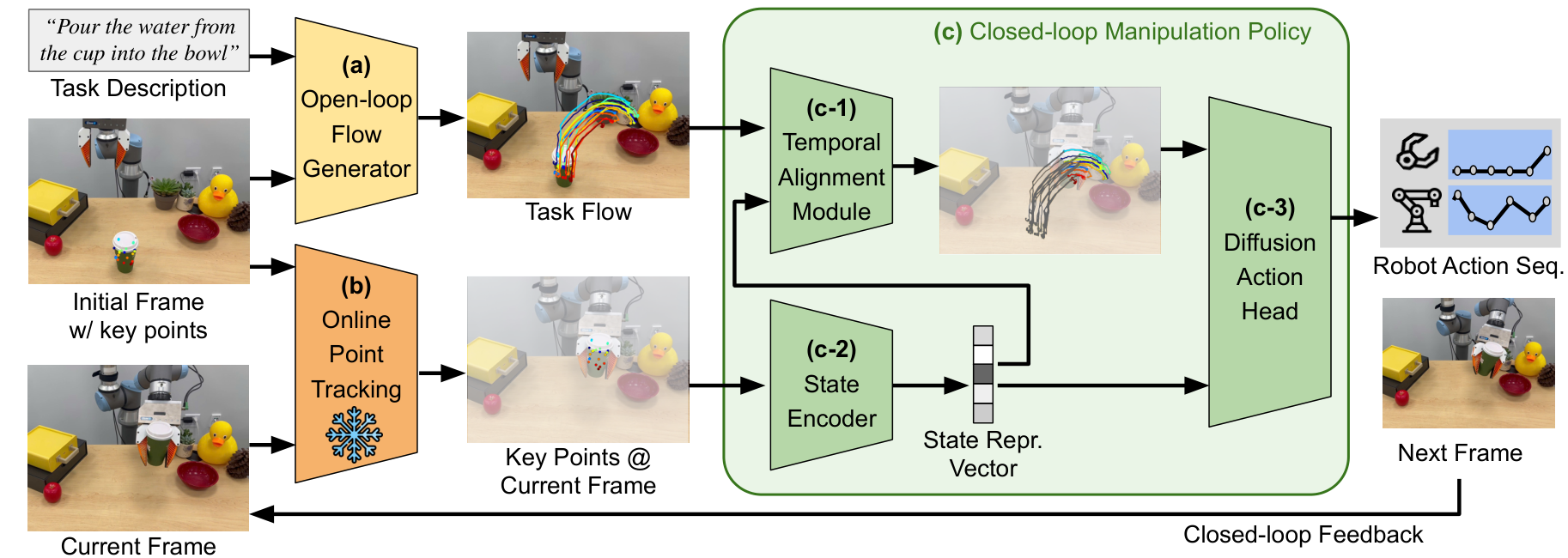
4. 方法详解
4.1 整体 pipeline
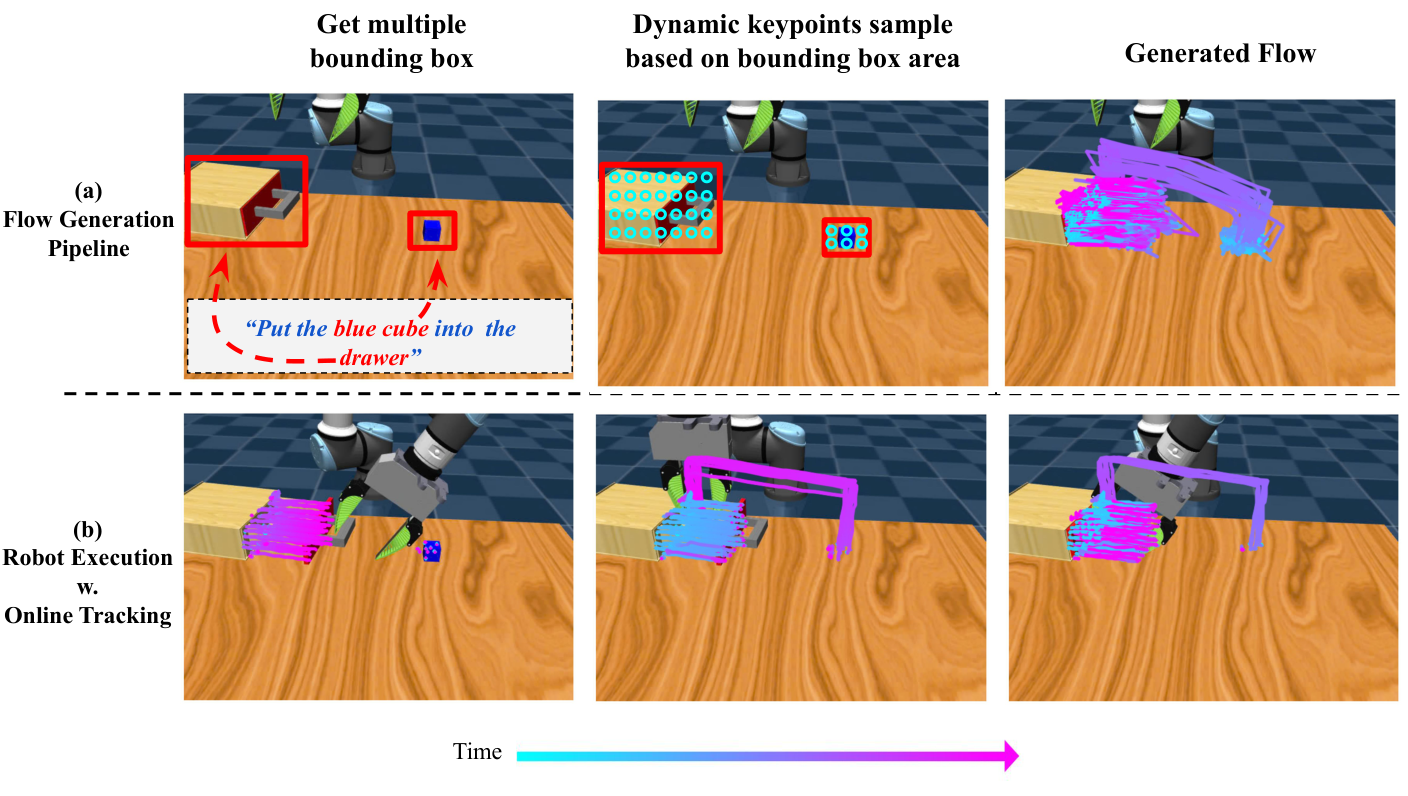
- 确定目标物体:用 Grounding DINO 根据人工给定关键词检测物体 bounding box。真实任务关键词包括 “green cup”、“yellow drawer”、“checker cloth” 附录: Grounding DINO。
- 形成矩形 flow 图像:在物体框内均匀采样 keypoints,构成 $\mathcal{F}_0\in\mathbb{R}^{3\times H\times W}$。三个通道分别为 image-space 的 $u,v$ 坐标和 visibility。
- 生成完整 task flow:用 TAPIR 从人手视频得到 $\mathcal{F}_{1:T}\in\mathbb{R}^{3\times T\times H\times W}$ 训练 flow generator;部署时由 AnimateDiff-style 模型根据初始帧和语言生成未来 flow。
- 过滤 object-centric flow:motion filters、SAM filter 和 depth filters 去掉背景点、过大 segment 上的点和缺失深度的点;随后随机选择 $N=128$ 个 keypoints 作为 policy 输入 附录: Motion Filters。
- 闭环执行:在线用 TAPIR 以 5Hz 跟踪当前 keypoints;policy 根据当前 progress 对齐 remaining flow,并输出 16 步动作序列。

4.2 Flow generation network
作者的关键表示选择是把 permutation-invariant object keypoints 组织成结构化的 rectangular flow image。这样可以复用图像/视频生成模型的卷积和 attention 结构,而不是直接处理无序点集。
直觉:flow generator 不是生成 RGB 视频,而是生成“这些物体点在未来 32 个时间步应该到哪里”。
$$ \mathcal{F}_0 \in \mathbb{R}^{3\times H\times W},\qquad \mathcal{F}_{1:T}\in \mathbb{R}^{3\times T\times H\times W}. $$| $H=W=32$ | 附录训练细节给出的 flow image 空间分辨率,对应 1024 个 keypoints。 |
| $T=32$ | flow generation network 和 task flow horizon 的时间步数。 |
| 3 channels | 每个 keypoint 的 $u$ 坐标、$v$ 坐标、visibility。 |
| $E_\phi, D_\theta$ | Stable Diffusion autoencoder 的 encoder/decoder;encoder 固定,decoder fine-tune 以适配 flow images。 |
为了降低高分辨率 flow 生成成本,作者把 flow image 压缩到 Stable Diffusion 的 latent space:$x_{1:T}=\{E_\phi(\mathcal{F}_i)\mid i\in[1,T]\}$,空间维度相对输入 flow 下采样 8 倍。训练 AnimateDiff 时,在 Stable Diffusion U-Net 中插入 rank=128 的 LoRA,并从头训练 motion module。
4.3 Flow-conditioned imitation policy
policy 的条件概率写为:
动作 $a_t$ 包含 6-DoF end-effector Cartesian pose 和 1-DoF gripper open/close。$s_t$ 由当前 tracked keypoint image locations $f_t$ 与初始 3D coordinates $x_0$ 编码得到,$\rho_t$ 是机器人 proprioception。
policy 包含三个模块:
| 模块 | 输入/输出 | 作用 |
|---|---|---|
| State encoder $\phi$ | 输入 $N=128$ 个当前 2D keypoints 和对应初始 3D 坐标;输出 384-d state representation。 | 把当前物体状态压缩成 permutation-invariant 表示。实现为 4 层 transformer encoder + CLS token 附录: Policy training。 |
| Temporal alignment $\psi$ | 输入完整 task flow、当前 state、proprioception;输出剩余任务 flow 的 latent $z_t$。 | 估计当前执行进度,避免 policy 总是条件在完整 flow 上;也是支持 demonstration-conditioned execution 的关键模块。 |
| Diffusion action head | 输入 $z_t,s_t,\rho_t$;输出动作序列。 | 使用 Diffusion Policy,DDIM scheduler,50 training diffusion steps,16 inference steps。 |
Temporal alignment 为什么必要
训练数据来自 unstructured simulated exploration。完整 task flow 只描述从起点到终点的目标运动,但 policy 执行到中途后需要知道“还剩哪段 flow 没完成”。因此作者先用 encoder $\xi$ 把 ground-truth remaining flow $f_{t:T'}$ 编成监督目标 $\hat{z}_t$,再训练 $\psi(\mathcal{F}_{0:T},s_t,\rho_t)$ 预测 $z_t$,用 $L_2$ loss $\|\hat{z}_t-z_t\|^2$ 监督。主文和真实实验都显示去掉 alignment 后执行会更不平滑,真实 Pick&Place 和 Pouring 下降尤其明显。
4.4 实现要点
5. 实验
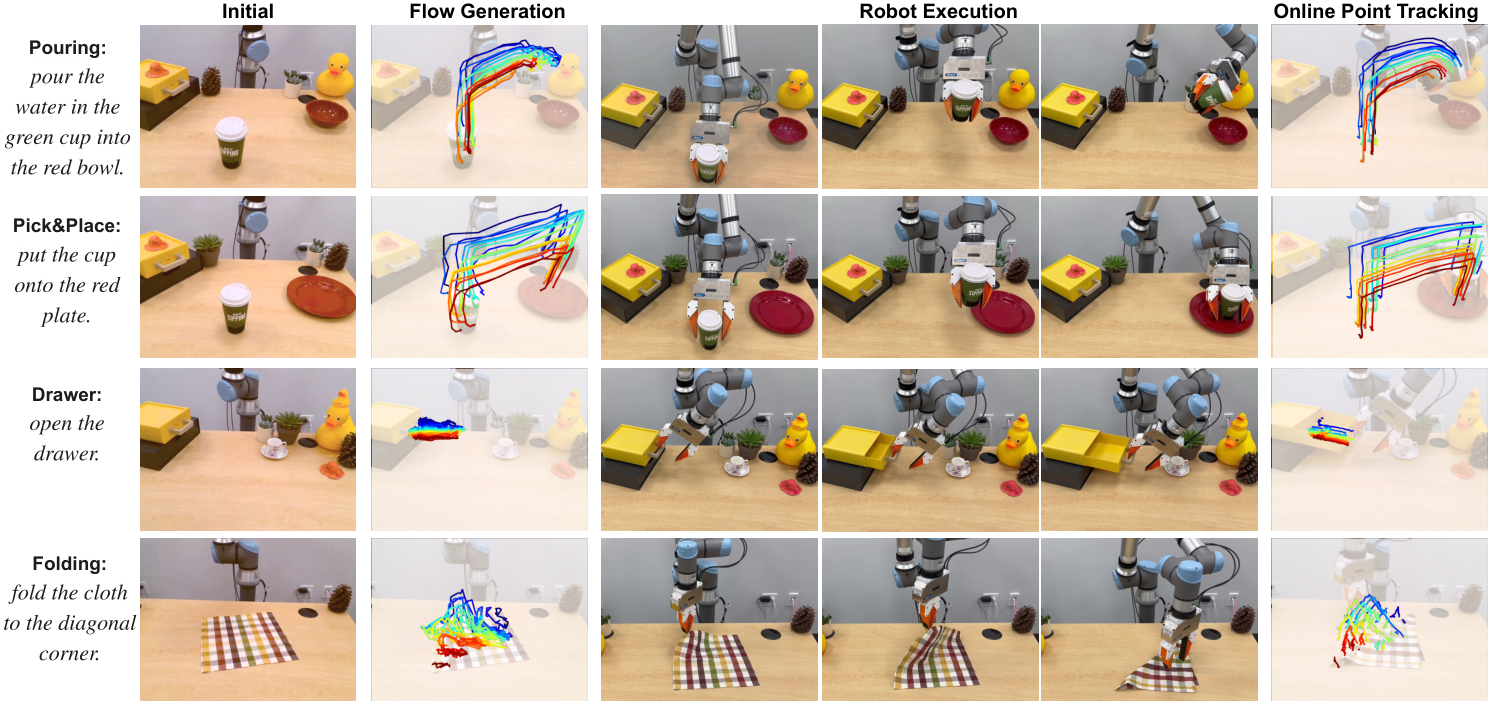
5.1 实验设置
作者评估 4 类任务:Pick&Place、Pouring、Drawer Opening、Cloth Folding,覆盖刚体、关节物体和柔性物体。训练数据分两部分:仿真中用 UR5e 和预定义 random heuristic primitives 收集 robot exploration data;真实世界中为每个任务收集人手 demonstration videos,用于训练 flow generation model。评估包含 demonstration-conditioned execution 和 language-conditioned execution 两种模式。
| 评估模式 | 含义 | 它隔离了什么问题 |
|---|---|---|
| Demonstration-conditioned execution | policy 使用单条人类示范视频或仿真球形 agent 示范抽出的 object flow。 | 主要检验低层 flow-to-action policy 是否能跟随给定 flow,尽量排除 flow generation 误差。 |
| Language-conditioned execution | 完整系统先根据任务描述和初始图像生成 flow,再由 policy 执行动作。 | 检验 flow generator + policy 的端到端能力。 |
5.2 Baselines
| Baseline | 设计目的 | 公平性/额外信息 |
|---|---|---|
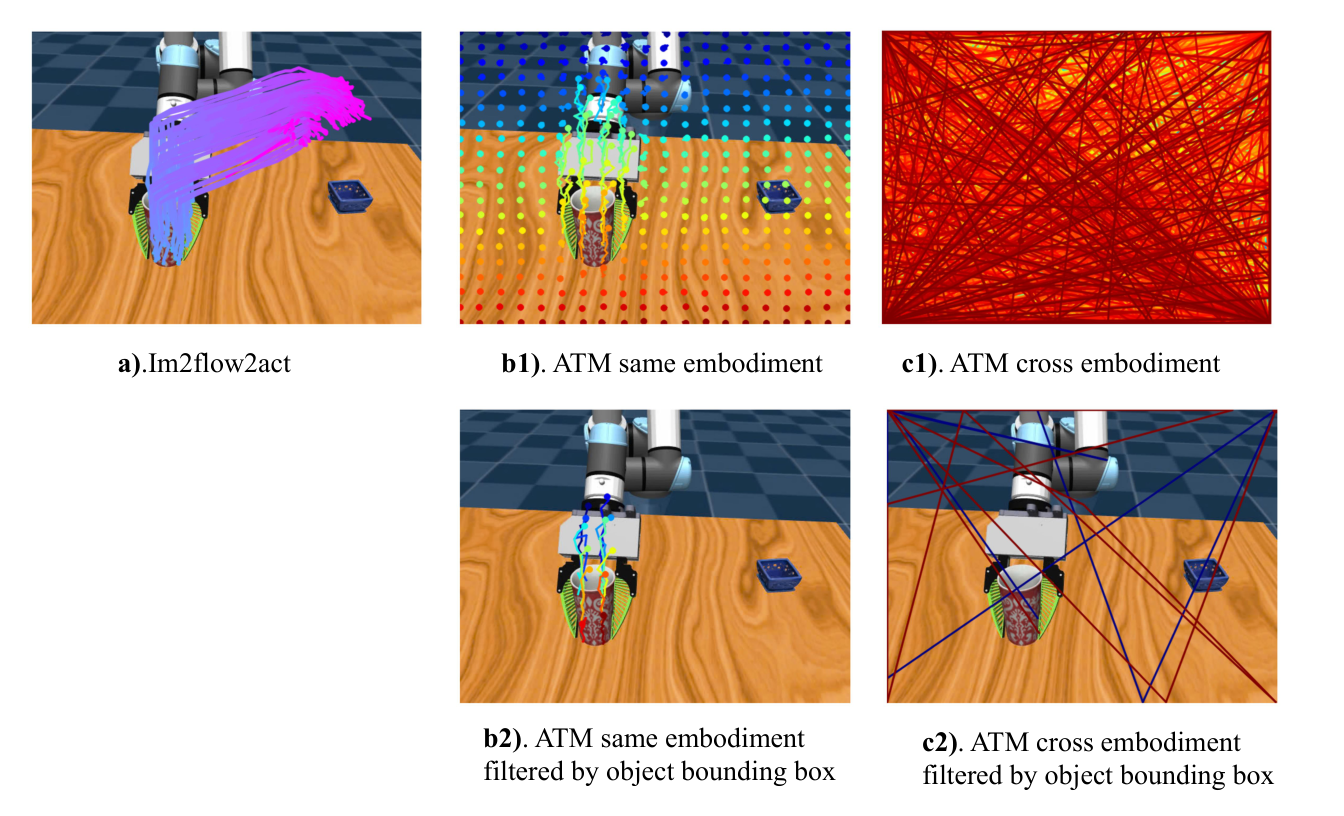
| ATM | 闭环 grid flow generation,只预测 immediate next few steps。 | 测试完整 object-centric task flow 是否比 grid flow 更适合 cross-embodiment。 |
| Heuristic | 选择 contact point 并用 RANSAC / pose estimation 从 future object flow 推动作。 | 作者给它 ground-truth 3D flows 和 optimal grasp pose;用于检验 learned policy 是否必要。 |
| GridFlow | 把 Im2Flow2Act 的 object keypoints 换成 uniform grid keypoints。 | 检验 object-centric keypoint sampling 的作用。 |
| No alignment | 去掉 temporal alignment model $\psi$ 和完整 task flow 条件。 | 检验 alignment 是否帮助从 unstructured exploration data 中找到当前进度对应动作。 |
5.3 Simulation results
| 方法 | Demonstration-conditioned | Language-conditioned | ||||||
|---|---|---|---|---|---|---|---|---|
| Pick&Place | Pouring | Drawer | Cloth | Pick&Place | Pouring | Drawer | Cloth | |
| Im2Flow2Act | 100 | 95 | 95 | 90 | 90 | 85 | 90 | 35 |
| ATM | / | / | / | / | 50 | 30 | 85 | 30 |
| Heuristic | 70 | 50 | 30 | 0 | / | / | / | / |
| GridFlow | 30 | 25 | 35 | 45 | / | / | / | / |
| No alignment | 80 | 85 | 90 | 90 | / | / | / | / |
作者的解读是:object flow 能连接不同数据源;Heuristic 虽然拿到 ground-truth 3D flows 和 optimal grasp pose,在 rigid tasks 上还能工作,但在 drawer / cloth 上失败明显,说明 flow-to-action 需要学习式 policy;GridFlow 明显低于 object flow,说明排除 embodiment/background motion 很关键。
5.4 Real-world results
| 方法 | Demonstration-conditioned | Language-conditioned | ||||||
|---|---|---|---|---|---|---|---|---|
| Pick&Place | Pouring | Drawer | Cloth | Pick&Place | Pouring | Drawer | Cloth | |
| Im2Flow2Act | 95 | 80 | 90 | 70 | 90 | 80 | 85 | 70 |
| Heuristic | 70 | 50 | 30 | 0 | / | / | / | / |
| No alignment | 55 | 0 | 80 | 60 | / | / | / | / |
真实世界 average success rate 约为 81%。作者指出从仿真到真实平均只下降 15%,并把原因归结为 flow 更关注 motion 而非 appearance,从而降低 sim-to-real gap。No alignment 在真实 Pick&Place / Pouring 上下降明显,支持 temporal alignment 的设计。

5.5 附录:ATM、long-horizon 与 keypoint ablation
| 附录实验 | 结果 | 结论 |
|---|---|---|
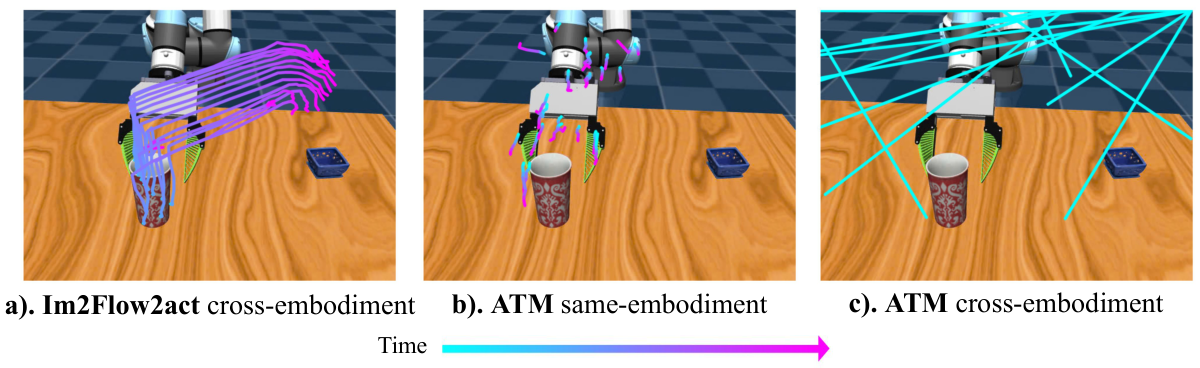
| ATM 对比 | Pick&Place/Pouring/Drawer 中,Im2Flow2Act language-conditioned 为 90/85/90;ATM cross embodiment 为 50/30/85;ATM same embodiment 为 90/90/95。 | ATM 在 same embodiment 下可强,但 cross-embodiment 时 visual input OOD;object-centric flow 对 UR5 出现在画面中更鲁棒。 |
| Long-horizon 多物体任务 | 任务为 open drawer -> pick blue cube -> place into drawer -> close drawer。Im2Flow2Act demonstration-conditioned 90%,language-conditioned 85%;ATM language-conditioned 45%。 | 完整 task flow + temporal subsampling 可压缩长时程多物体任务。 |
| Initial 3D keypoints | 无 3D 时 demo-conditioned 为 100/90/90,完整为 100/95/95;language-conditioned 无 3D 为 85/85/80,完整为 90/85/90。 | 初始 3D keypoints 对 generated flow 输入下的 noisy keypoints 判别有帮助,尤其 drawer handle 一类位置。 |
5.6 附录:预训练、仿真 flow 和 deformable failure
| 实验 | 数值/现象 | 解释 |
|---|---|---|
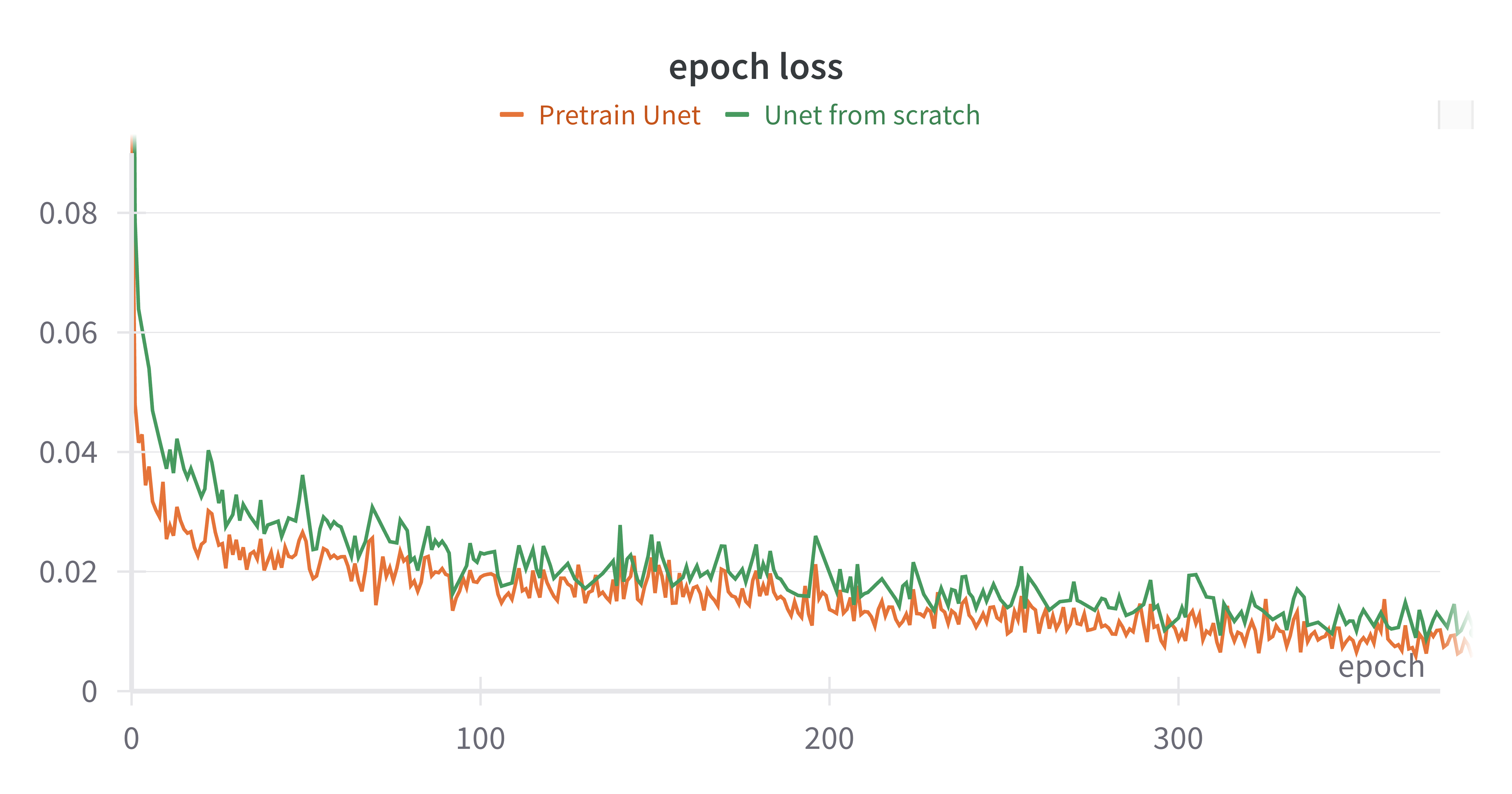
| Stable Diffusion 预训练 ablation | Pretrain U-Net: 90/85/90/35;U-Net from scratch: 90/90/95/30。 | 预训练对最终成功率影响较小,但 LoRA + pretrained SD 提供训练效率;AE latent space 仍可能帮助 diffusion learning。 |
| Generated flow in simulation | 仿真中用球形 agent 替代 UR5 收集 cross-embodiment demonstrations,并用 motion filter 可视化高方差 flow。 | 验证 flow generator 不只在真实人手视频上工作,也能从仿真跨 embodiment 示范中学习。 |
| Deformable failure | cloth folding 仿真中为了让机器人抓布,在布角附加 1cm x 1cm x 9cm 小方块;policy 常能到达角点但不能精确抓住小方块。 | 解释仿真 cloth language-conditioned 只有 35%;真实中可沿布角任意处抓取,因此成功率反而较合理。 |

6. 复现信息汇总
6.1 数据收集
| 数据源 | 如何收集/使用 |
|---|---|
| Simulated exploration data | 在仿真中使用 UR5e 和一组预定义 random heuristic primitives,覆盖 rigid、articulated、deformable objects。训练一个多任务 flow-conditioned policy。 |
| Real-world human demonstrations | 四个任务:pick & place、pouring、opening drawer、folding cloth。RealSense 30 FPS 记录,训练 flow generation model。 |
| Simulation cross-embodiment demos | 用 sphere agent 模拟人类示范,用相同 primitive 收集;long-horizon 任务收集 150 条 sphere trajectories 和 100 条 UR5 demonstrations。 |
6.2 真实评估协议
- 初始状态:真实评估时背景不与人类示范视频完全匹配,用于测试 flow generator 的泛化;物体初始位置大致服从人类示范中的分布。
- Pick&Place:杯子稳放到红盘上,红盘移动不超过 5cm。
- Pouring:杯子旋转超过 30 度并表现完整倾倒动作,且杯子至少一半在世界坐标 x 轴方向上与红碗重叠。
- Drawer Opening:完全打开抽屉,夹爪不能严重撞击抽屉表面,不能把抽屉推回超过 5cm。
- Cloth Folding:按生成 flow 折布,完成后两角距离低于阈值;因 deformable sim-to-real gap,阈值设为 7cm。
6.3 关键超参
| 模块 | 配置 |
|---|---|
| Flow image | $H=W=32$,$T=32$,1024 keypoints,3 channels: $u,v,visibility$。 |
| Flow generator | Stable Diffusion AE encoder 固定;decoder fine-tune 400 epochs, lr $5e-5$;AnimateDiff U-Net 插入 LoRA rank 128;motion module 从头训练 4000 epochs, lr $1e-4$,AdamW weight decay $1e-2$。 |
| CLIP 条件 | 文本用 CLIP text encoder;初始图像用 CLIP image encoder 的最后 ViT layer patch embeddings;openai/clip-vit-large-patch14 权重冻结。 |
| Policy sample | $(\rho_t,f_t,\mathcal{A}_{t:t+L},F_{0:T})$;task flow horizon 32;action sequence length 16;训练时每样本随机选 $N=128$ keypoints。 |
| State encoder | 初始 3D 坐标投影为 192-d,2D keypoint location 编码为 192-d,拼接成 384-d descriptor;4-layer transformer encoder + CLS token。 |
| Temporal alignment | remaining task flow encoder $\xi$ 为 4-layer transformer;alignment model 为 8-layer transformer;用 fixed 1D sinusoidal positional encoding 和 CLS token。 |
| Action head | Diffusion Policy;DDIM scheduler;50 training diffusion steps,16 inference steps;policy 训练 500 epochs, lr $1e-4$,AdamW weight decay $1e-2$。 |
6.4 推理感知模块
| 模块 | 配置/阈值 |
|---|---|
| Grounding DINO | grounding-dino-base,输入 480x640;关键词:green cup、yellow drawer、checker cloth。 |
| Moving filter | 去掉 256x256 图像空间中移动低于阈值的点;Pick&Place/Pouring/Drawer 阈值 20,Cloth 阈值 10。 |
| SAM filter | 初始帧 resize 到 256x256,用 finest segmentation;过滤点所在 segment 面积超过阈值的点,阈值 10,000。 |
| Depth filter | 去掉深度缺失,即 depth value 为 0 的 keypoints。 |
| Online tracking | TAPIR online point tracking,视觉观测 resize 到 256x256,5Hz。 |
tmp/arxiv_source_2407.15208/;PDF 在 tmp/2407.15208.pdf;源压缩包在 tmp/arxiv_source_2407.15208.tar.gz;报告图表在 Report/2407.15208/figures/。这些临时材料暂未删除,便于继续核对。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
按论文自己的主张和实验,最有价值的是把跨域机器人学习拆成一个相对清晰的接口问题:用 object flow 表达任务知识,让人类示范只负责提供“物体如何移动”,让仿真探索只负责学习“机器人如何实现这种移动”。这个拆法避免了直接从人手动作迁移到 UR5e,也避免了为每个真实任务收集 robot teleoperation。
7.2 结果为什么站得住
实验支撑主要来自三类对照。第一,Heuristic baseline 获得 ground-truth 3D flow 和 optimal grasp pose 仍在 drawer / cloth 上差,说明 flow-to-action 不是简单位姿估计就够。第二,GridFlow 和 ATM cross-embodiment 的下降说明“object-centric complete flow”比包含 embodiment motion 的 grid flow 更适合跨 embodiment。第三,No alignment 在真实任务中显著下降,说明 temporal alignment 对从 unstructured exploration data 学来的 policy 落地到真实人类 flow 有实际作用。
7.3 作者自述局限
- 2D flow 的 3D 歧义:pouring 中常见失败来自机器人相机坐标 z 轴移动不够精确;2D flow 难表达 screwing 等 out-of-plane rotation,作者认为 3D flow 可能缓解。
- 仿真与真实 object dynamics 假设:框架假设 simulation 和 real world 的 object dynamics 相对一致;deformable object simulation 仍困难,导致 folding 从仿真到真实有明显性能差异。
- 视角校准假设:附录指出系统假设仿真和测试环境相机 viewpoint calibrated,且动作从相机视角可见。
- 动作细节被 flow 抽象掉:flow abstraction 忽略一些 action details,对 dexterous tasks 如 in-hand manipulation 有限制。
- 依赖 object detection:flow generation 依赖准确 object detection;Grounding DINO / segmentation 错误会传递到后续 policy。
- 任务范围限制:作者聚焦“通过交互改变物体状态”的 manipulation;如果目标状态变化不体现在 object motion 中,例如触摸屏按钮,方法可能不适用。
7.4 适用边界
| 适合使用的情况 | 不适合或需要额外模块的情况 |
|---|---|
| 目标任务可用物体点运动来描述,例如 pick/place、pour、open drawer、fold cloth。 | 关键成功因素是力、触觉、隐状态或非视觉反馈,而不是可见 object motion。 |
| 目标物体可被 Grounding DINO/SAM/深度过滤稳定定位,且可在线跟踪。 | 严重遮挡、透明/反光物体、无深度或 tracking 易丢失的场景。 |
| 仿真能生成足够覆盖动作-物体运动关系的 exploration data。 | 真实接触动力学与仿真差异很大,尤其 deformable、granular 或高精度力控任务。 |
| 相机视角能看到动作和目标物体,并且仿真/真实视角可校准。 | 多视角大幅变化、手眼遮挡强、动作发生在相机不可见区域。 |