Prediction with Action: Visual Policy Learning via Joint Denoising Process
1. Quick overview of the paper
In one sentence: This paper proposes PAD, which puts "future image prediction" and "robot action generation" into the same diffusion denoising process for joint learning, instead of following the two-stage route of "first generate the target map, and then train the low-level strategy".
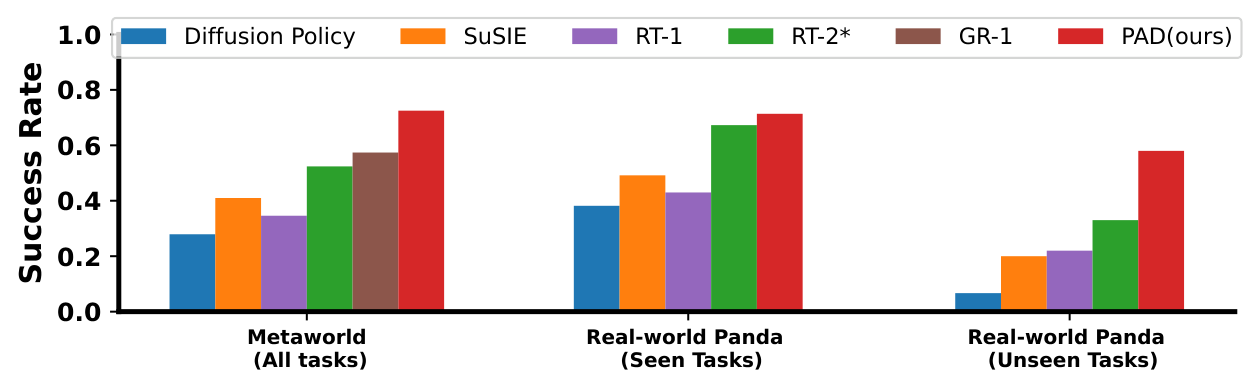
Core conclusion: Joint denoising allows the action heads to directly share physical representations in the visual prediction model; coupled with large-scale video data co-training such as BridgeData-v2, PAD is significantly better than Diffusion Policy, SuSIE, RT-1, RT-2*, and GR-1 in both MetaWorld and real Panda operation tasks.
What should the paper solve?
Visual imitation learning data is expensive and small, and Internet videos contain a lot of physical priors on how objects move. The problem is that previous methods usually only treat the video generation model as an external tool, first synthesize the target image, and then hand it over to a separate strategy to learn actions. The coupling between prediction and control is too weak.
The author's approach
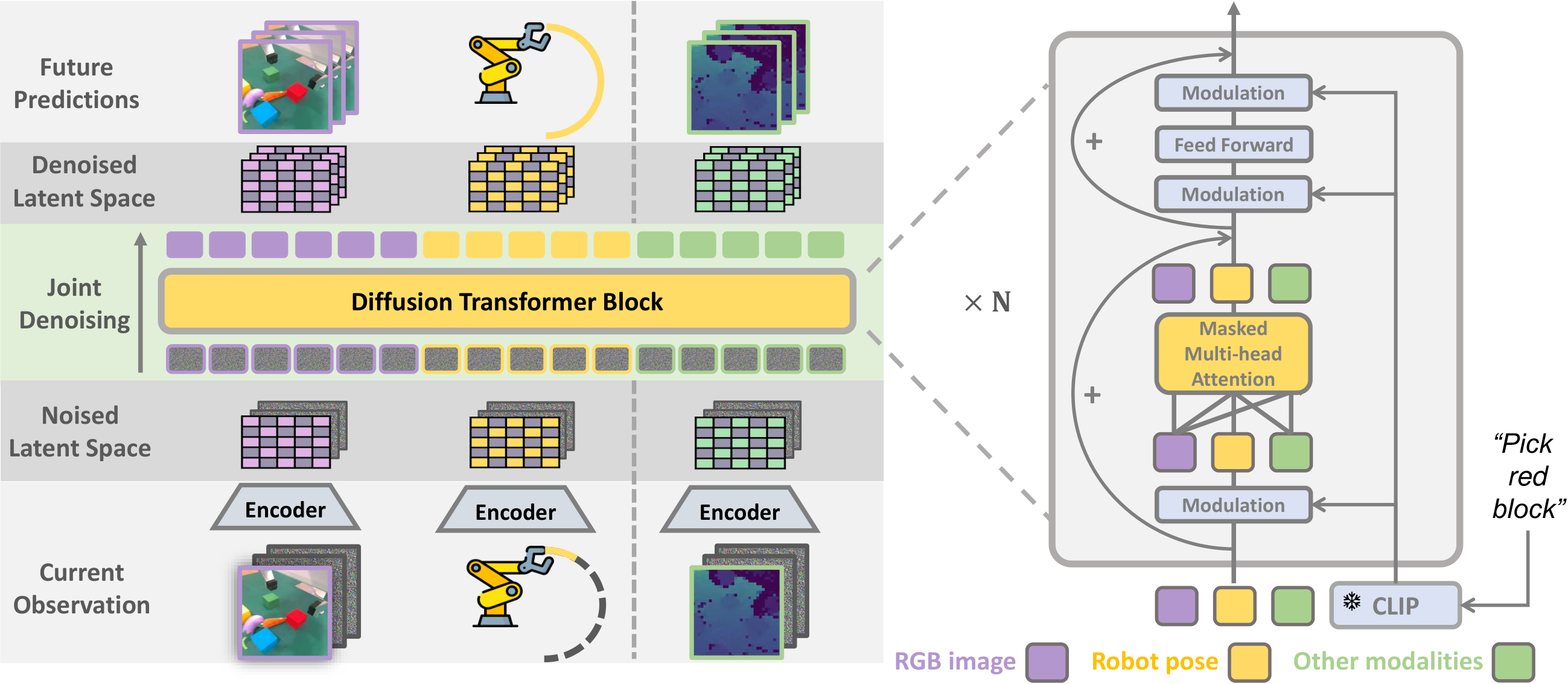
Use Diffusion Transformer to encode the current RGB, robot status, text instructions, and optional depth into tokens; the model simultaneously predicts future images, future actions, and future depth, and is trained under the same latent diffusion objective.
most important results
MetaWorld 50-task average success rate reaches 72.5%, relative to the strongest baseline GR-1 57.4% There is a significant improvement; the average success rate PAD of real tasks seen-task is 0.72, after adding depth to 0.78.
Things to note when reading
The abstract says "single policy solve 41 tasks", but the text and tables always read MetaWorld 50 tasks Statistics; additional explanations in the appendix handle-pull-side-v2 and handle-pull-v2 No details are listed because the original experts themselves have a low success rate. This is an area where the caliber within the paper is not entirely consistent.
2. Motivation
The author's starting point is straightforward: prediction and action essentially share the same set of physical laws. A model that can predict "what will happen next" from an image should also be better suited for deciding "what to do now." The problem is that most of the existing robotics work separates these two things. The prediction model can only provide target images to the strategy without directly exposing the physical representations it has learned to the action generation process.
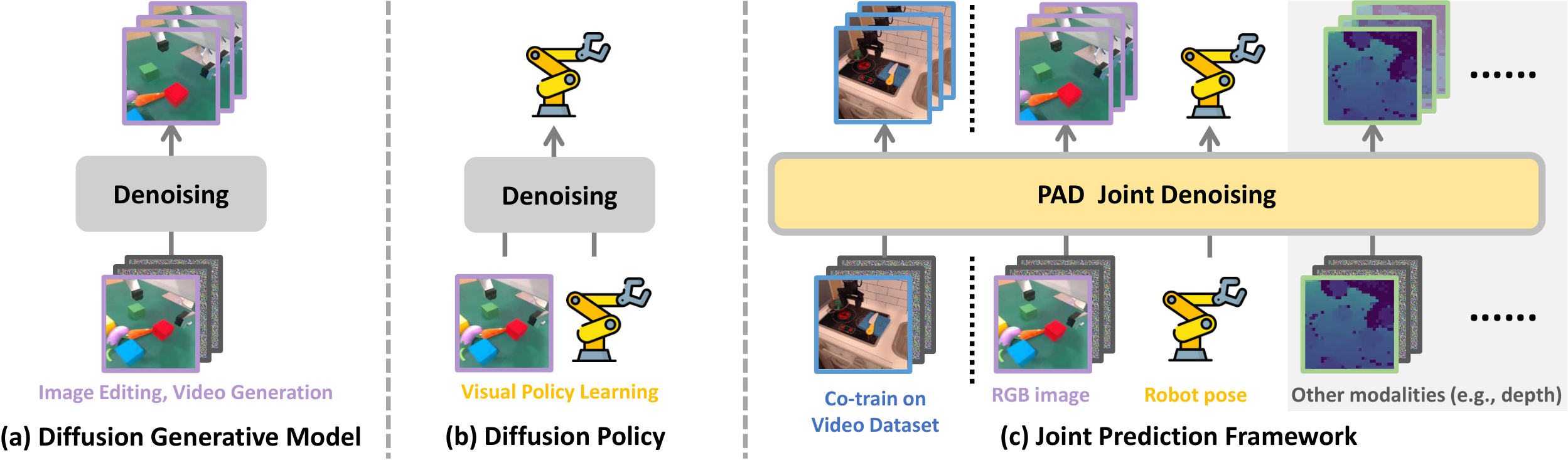
Why two stages are not enough
Methods such as SuSIE and UniPi first generate future images and then learn inverse dynamics or low-level strategies. This interface is too narrow, and the action head can only see an intermediate result, and cannot get the physical priors encoded in the intermediate layer of the diffusion model.
Why choose DiT
The author believes that U-Net is more focused on pure image generation, while DiT's use of token splicing is more suitable for joint modeling of images, actions, depth, and text in a self-attention sequence, and it is also more convenient to handle missing modalities.
3. Summary of related work
The paper places related work behind the experiments, but logically it can be organized into three main lines in advance.
| direction | Representation method | core idea | The difference between PAD |
|---|---|---|---|
| Pre-trained models can be used directly as robots | RT-1, RT-2* | Directly adapt the visual language backbone into an action predictor | PAD does not directly rely on very large VLM, but uses "future prediction" as a structured auxiliary signal for action learning. |
| diffuse action strategy | Diffusion Policy | Denoising generated control sequences in action space | PAD not only denoises actions, but also simultaneously denoises future images and optional depth, providing stronger supervision. |
| Future image-assisted control | SuSIE, UniPi, GR-1 | Use generation or autoregression to predict the future, and then indirectly help actions | PAD is not a serial two-stage, but a joint denoising within a single DiT; compared to GR-1, the authors emphasize that the diffusion generation map is more refined. |
The technical position the author wants to occupy
PAD tries to stand between "diffusion action strategy" and "future visual prediction": it not only retains the multi-modal action modeling capability of diffusion policy, but also injects the physical change patterns learned from Internet videos into the strategy through joint loss.
4. Detailed explanation of method
4.1 Problem Definition
The robot data is recorded as D_robot, each sample contains the current image sequence, language instructions and trajectory; the video data is recorded as D_video, only images, no robot actions. The goal of PAD is to improve the visual strategy learning effect by co-training with video data when robot data is scarce.
4.2 Input, output and tokenization
| symbol | meaning |
|---|---|
| $c_I, c_A, c_E, l$ | Current RGB, current robot status, current depth, text commands |
| $x_I^{1: k}, x_A^{1: k}, x_E^{1: k}$ | RGB, motion, depth targets for future $k$ steps |
| $\varepsilon_I, \varepsilon_A, \varepsilon_E$ | Different modal encoders; image is frozen VAE, action is MLP, depth is downsampling+tokenize |
| $t_I, t_A, t_E$ | Token sequences mapped by different modalities |
At the implementation level, PAD-XL/2 pairs 256×256 The image is first compiled using frozen VAE 32×32×4 latent, press again 2×2 patchify into 256 image tokens; The future sequence of actions is encoded as 1 action token. If there is depth, put 32×32×1 Depth map button 8×8 cut into 16 depth tokens. Text was encoded by frozen CLIP.
4.3 Joint conditional denoising
Instead of predicting a future picture and then finding actions, PAD constructs a spliced input of "conditional latent + noise latent" for each future modality. For example, in image mode, the current observation latent εI(cI) and future k frame noise zI_t In channel dimension splicing, the same applies to movement and depth.
key mathematical objects
The inverse process of diffusion is distributed conditionally
$$ p(z_{t-1}\mid z_t, c)=\mathcal{N}\left(z_{t-1}; \sqrt{\bar{\alpha}_{t-1}}\mu_\theta(z_t, t, c), (1-\bar{\alpha}_{t-1})\mathbb{I}\right) $$
Among them
$$ \mu_\theta(z_t, t, c)=\frac{z_t-\sqrt{1-\bar{\alpha}_t}\, \epsilon_\theta(z_t, t, c)}{\sqrt{\bar{\alpha}_t}}. $$
Simultaneously minimize the three diffusion losses of image, action, and depth during training:
$$ \mathcal{L}(\theta)=\lambda_I\mathcal{L}_{diff}^{I}+\lambda_A\mathcal{L}_{diff}^{A}+\lambda_E\mathcal{L}_{diff}^{E}. $$
Intuitively, PAD forces the same DiT to simultaneously explain "what the scene will look like next" and "how the robot will move next". This is the source of the structural bias of the paper.
4.4 Why is DiT compatible with missing modes?
Video data has no motion, real robot data may have depth, and MetaWorld has no depth. What PAD does is to unify the lengths of all modal tokens to the total length, and then use self-attention mask to mask the padding position, retaining only valid output. In this way, the same set of parameters can be eaten at the same time D_video and D_robot.
4.5 Training and execution details
λI Maintain 1.0 throughout; λA and λE Linearly pull from 0 to 2.0 within 100k steps to avoid the head rush at the beginning and destroy the existing image prior.k=3, the interval between adjacent future frames is 4; each round uses 75 steps of DDIM sampling, and obtains 3 steps of future images and actions at the same time. Only the first step of action is executed before entering the next round of closed loop.5. Experiment
5.1 Experimental setup
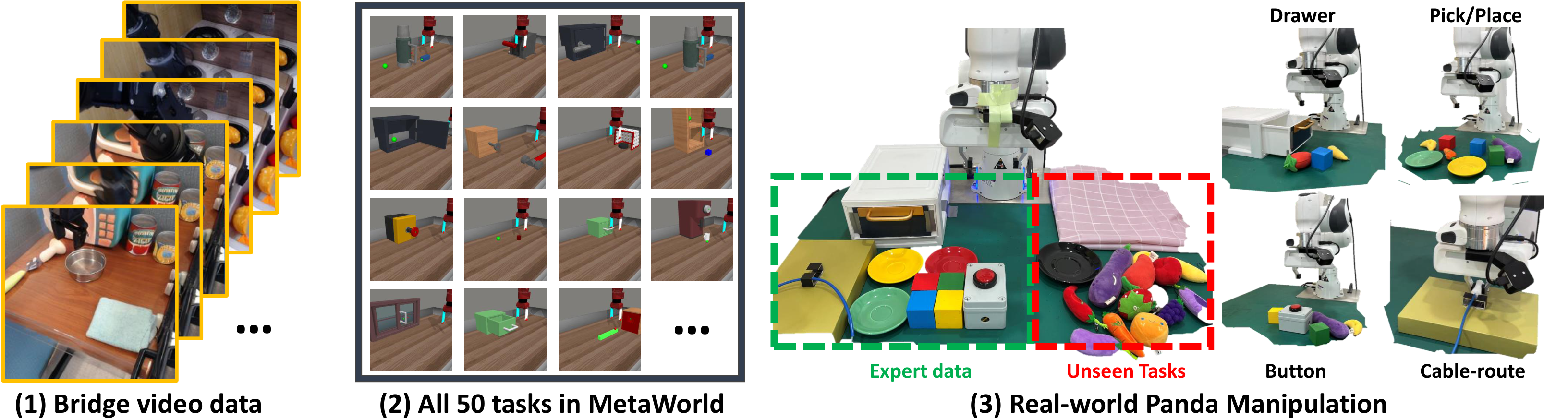
MetaWorld
Each task collects 50 trajectories, using only corner2 Viewing angle, state is 4D end position + gripper state; depth is not used. The author emphasizes that unlike the previous "one strategy per task" setting, a single text conditional strategy is trained here.
Real Panda
The tasks cover pressing buttons, managing cables, grabbing, placing, opening and closing drawers, etc.; each task collects 200 trajectories, using a wrist camera, and the robot state is 7-dimensional. The author also did OOD testing, adding unfamiliar fruit and vegetable toys and new backgrounds.
Comparative methods include Diffusion Policy, SuSIE, RT-1, RT-2* (reproduced by the author as per InstructBLIP-7B), and GR-1. All methods are trained according to the caliber of "a single text conditional visual strategy covers the entire task domain".
5.2 Main results
| scene | indicator | Strongest baseline | PAD | Gain Interpretation |
|---|---|---|---|---|
| MetaWorld | 50-task average success rate | GR-1: 57.4% | 72.5% | 15.1 points higher than the strongest baseline; a relative improvement of about 26.3% |
| Real Panda seen tasks | average success rate | RT-2*: 0.69 | 0.72 | The pure RGB version is slightly higher than RT-2*; if depth is added, PAD-Depth reaches 0.78 |
| Real Panda generalization | Unseen task/object generalization | Graphical comparison | PAD is the strongest | The abstract claims a 28.0% improvement in success rate relative to the strongest baseline |
| MetaWorld represents difficult tasks | GR-1 | RT-2* | PAD |
|---|---|---|---|
| assembly-v2 | 0.64 | 0.24 | 0.88 |
| basketball-v2 | 0.08 | 0.08 | 0.84 |
| coffee-pull-v2 | 0.52 | 0.68 | 0.80 |
| stick-push-v2 | 0.60 | 0.12 | 0.96 |
| door-lock-v2 | 0.60 | 0.40 | 0.88 |
5.3 Generalization, co-training and multi-modal extension

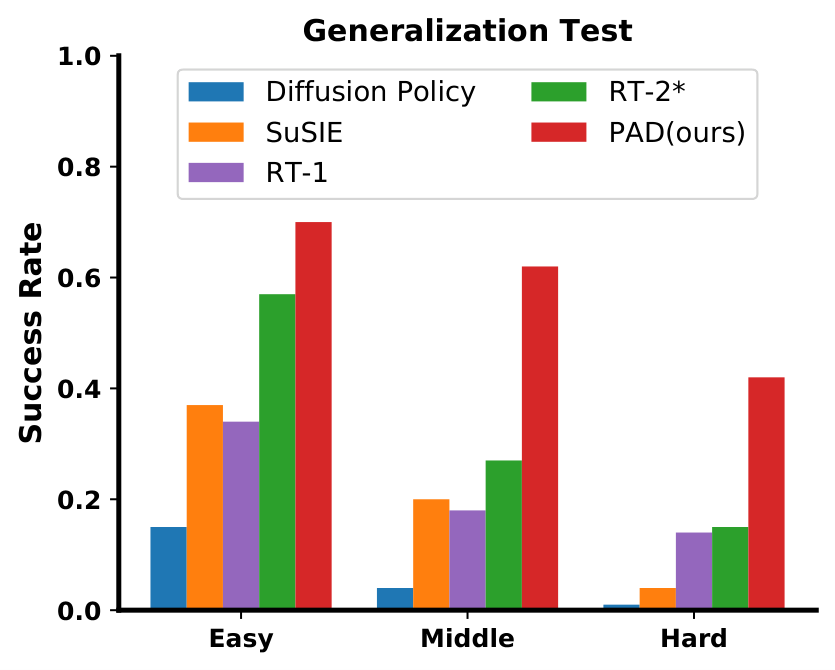
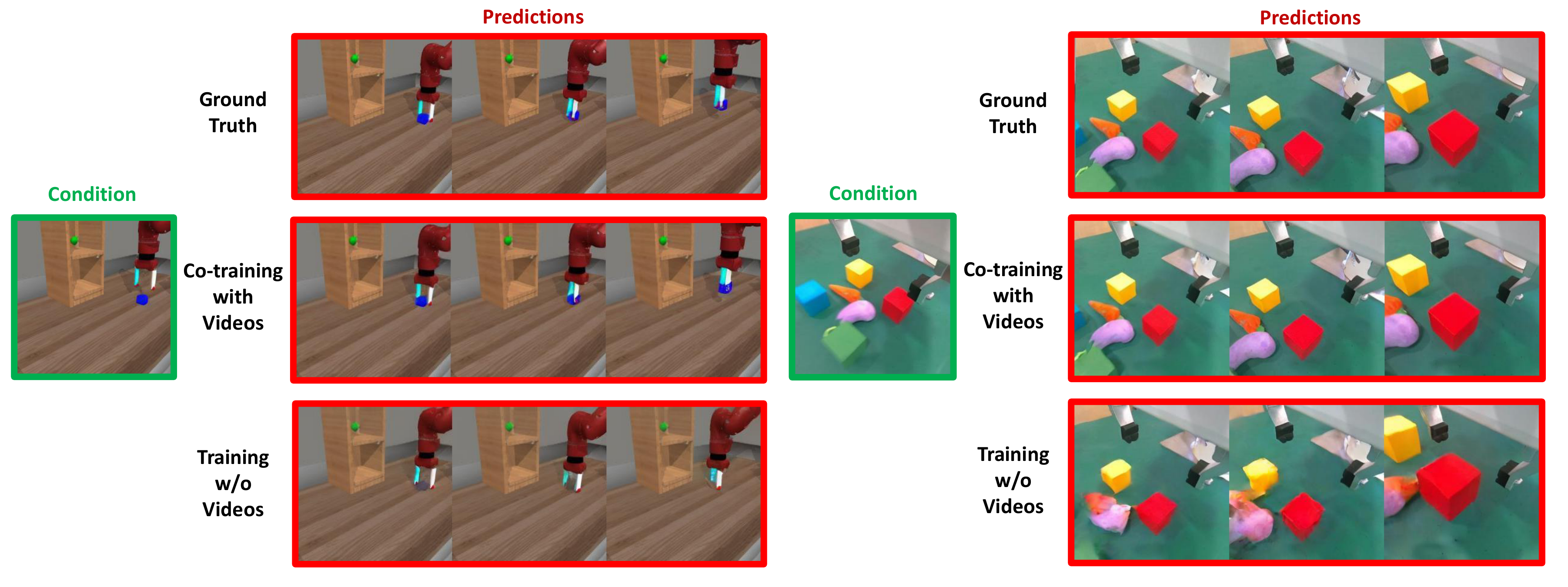
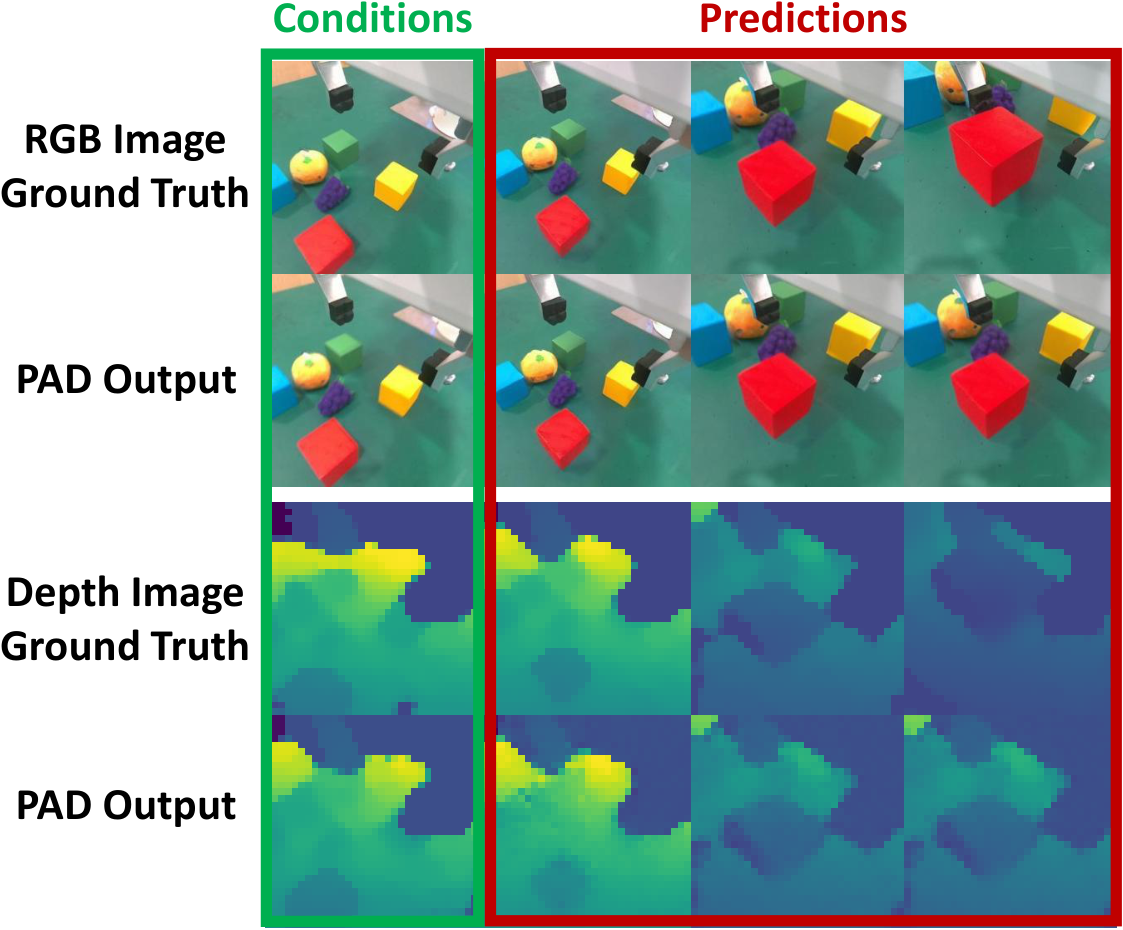
5.4 Scaling analysis
| model | Parameter quantity | Gflops | MetaWorld average success rate |
|---|---|---|---|
| PAD-B/2 | 128M | 22.5 | 62.4% |
| PAD-L/2 | 449M | 79.1 | 68.4% |
| PAD-XL/4 | 661M | 29.5 | 64.5% |
| PAD-XL/8 | 661M | 7.7 | 48.2% |
| PAD-XL/2 | 661M | 119.1 | 72.5% |
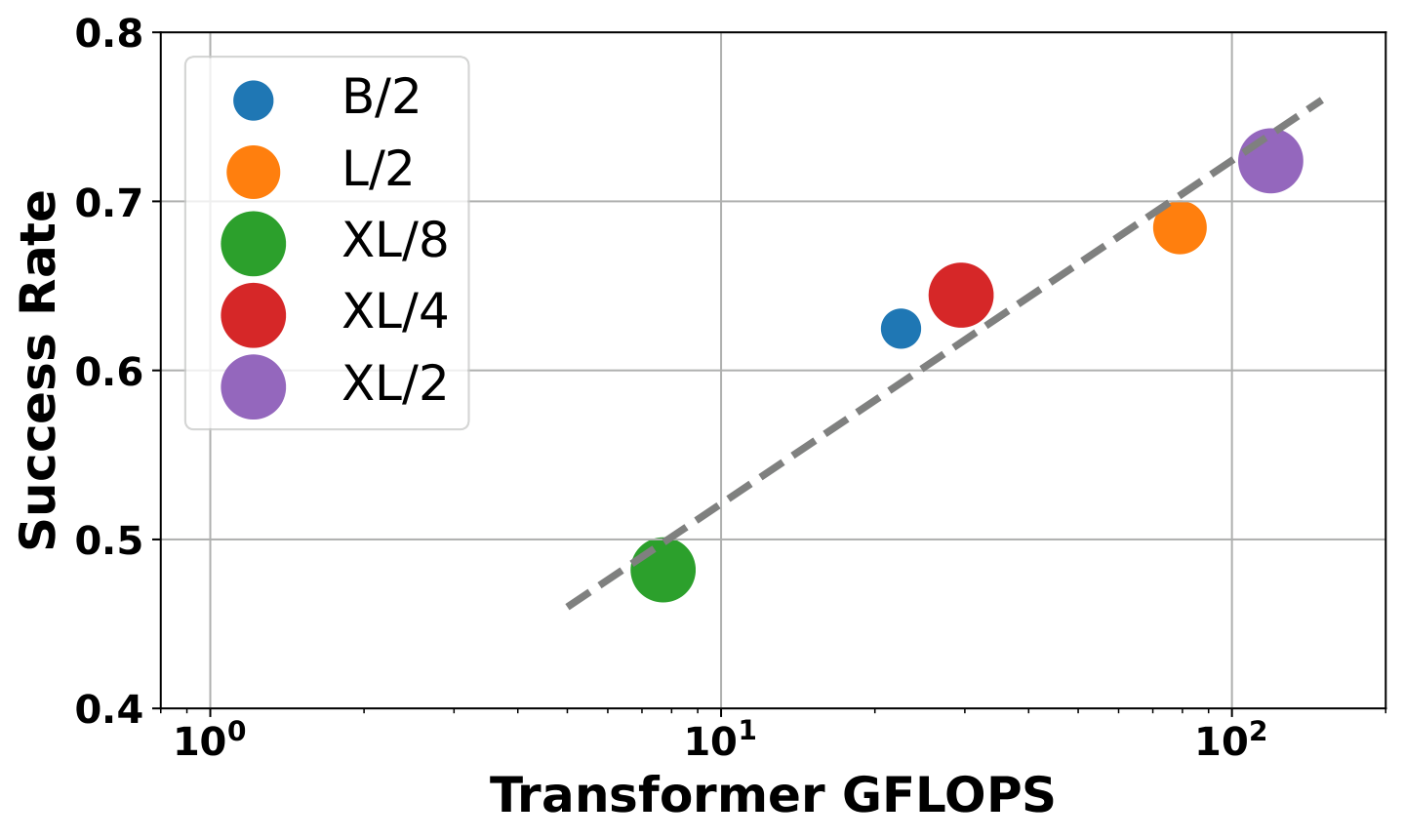
6. Analysis and Discussion
6.1 The most valuable part of this paper
Transform "forecasting" from an external tool to an internal oversight
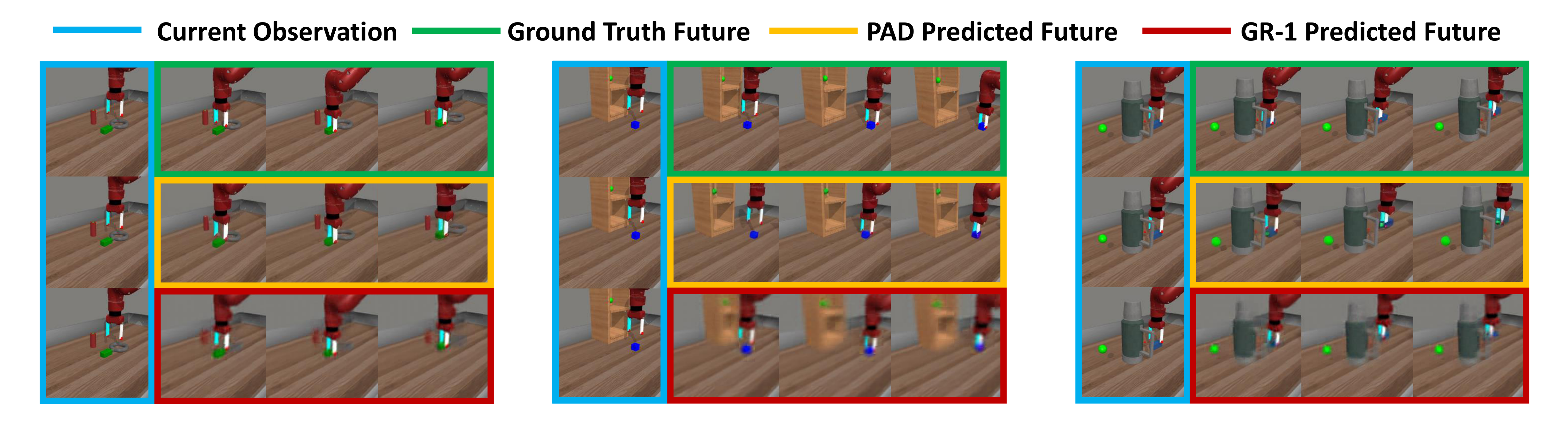
In the past, many methods only treated future images as intermediate products; the value of PAD is to allow action heads to share the latent variables of visual future modeling in the same denoising network. This is more like true multi-task representation learning than "generate first, control later".
Video data finally has a clear access point
Robot data lacks large-scale videos other than action labels, and it has been difficult to directly feed the control model. PAD uses attention mask to solve the problem of missing modalities, allowing pure videos to have training value for strategies.
6.2 Why the results hold up
The persuasiveness of this paper mainly comes from three sets of interlocking evidence:
| evidence | observe | supporting arguments |
|---|---|---|
| PAD vs baseline | MetaWorld and real tasks are both ahead | The joint denoising structure itself is effective |
| PAD w/o img | MetaWorld average dropped from 72.5% to 43.6% | Future image predictions are not decoration, but a key source of supervision |
| PAD w/o co-train | MetaWorld dropped to an average of 59.2% | Internet video co-training does provide additional help |

6.3 Limitations and doubtful points
Reasoning overhead is not low
Each control requires 75 steps of DDIM, while also generating future images and actions. The author himself also admitted in the conclusion that the control frequency is not high, which will be a hard constraint for high-speed closed-loop control.
The causal chain is not completely closed yet
The paper attributes the gains to "better future image predictions leading to better actions." This explanation is reasonable, but the current evidence is still mainly correlation. If further intermediate representation or teacher forcing experiments can be conducted, the causal relationship will be more solid.
The mission caliber is slightly inconsistent
Write 41 tasks in the abstract and 50 tasks in the main body. The appendix also explains that there are two handle-pull tasks without giving details. This does not affect the main trend, but it will affect the reader's first impression of "how many tasks are counted."
Real world scale is still limited
The real experiment is a single Panda platform, multi-class desktop operation. Although the effect is good, it is still far from a generalized robot in open scenarios, especially without testing complex contact and high-frequency dynamics tasks.
6.4 Information worth retaining in appendices
Appendix The appendix does not have additional theoretical derivation, but provides several details that are critical to judgments about reproducible experiments: image latent shape, number of depth tokens, various model sizes, complete MetaWorld baseline details, and sample images of expert / unseen tasks in real tasks. This information has been absorbed into the "Methodological Details" and "Experimental Analysis" above.



My overall judgment
The key contribution of PAD is not "making a larger diffusion policy", but binding future visual prediction and action generation into the same training goal, and providing a very natural interface for video co-training. To the question "How to inject Internet video prior into robot control", the structural answer given in this paper is clear and convincing. Its main shortcomings are inference cost and real-world verification scale.