VILP: Imitation Learning with Latent Video Planning
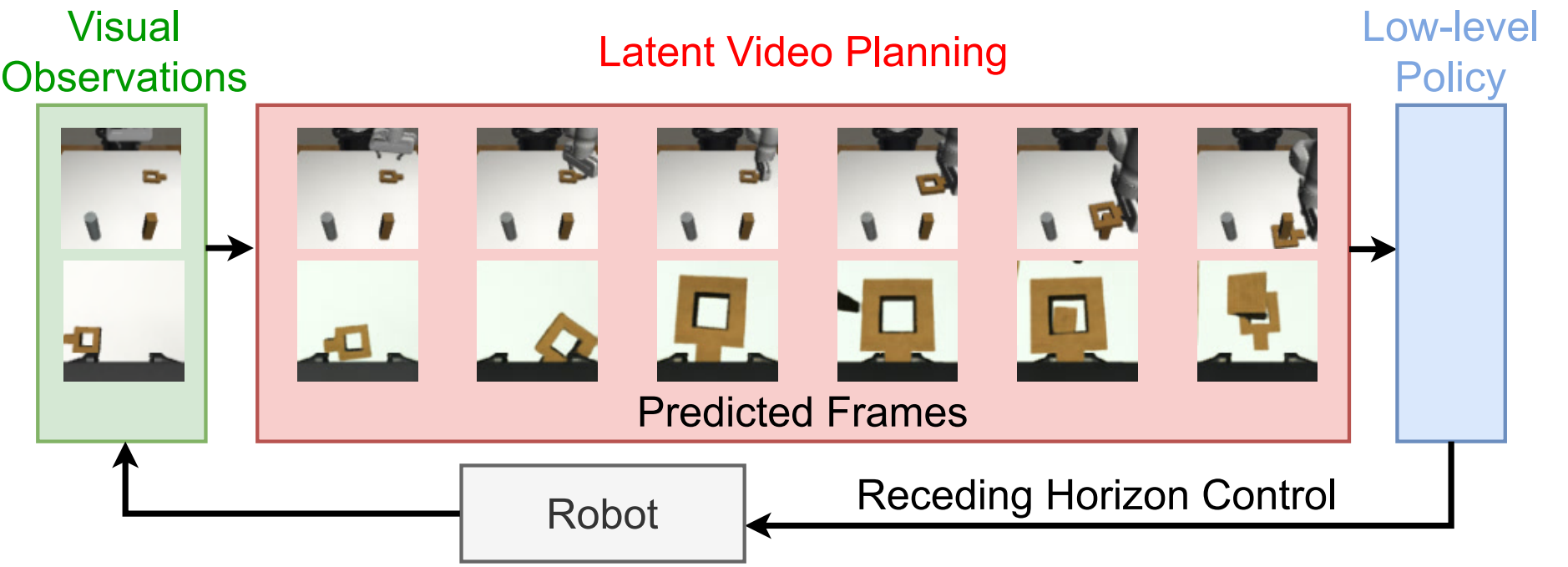
Reading Report: VILP puts the video generation model into the imitation learning policy, but the focus is not on generating larger RGB videos, but on quickly generating future robot videos in latent space, and converting video plans into actions in real time to achieve receding horizon planning.
1. Quick overview of the paper
| What should the paper solve? | Existing video planning robot methods usually generate videos in pixel space, which is slow and difficult to replan in real time; long horizon open-loop execution is easy to accumulate errors. What VILP wants to solve is: how to use video generation as part of the robot strategy, while being fast enough to support receding horizon, and using video data to reduce reliance on high-quality action annotation data. |
|---|---|
| The author's approach | Use VQGAN to compress multi-view/RGBD images into latent space, train the 3D-UNet DDIM video diffusion model in latent; use visual observation to encode through ResNet-18 and use cross-attention to globally condition video generation; then use goal-conditioned low-level policy to map adjacent prediction frames into action sequences, only execute the first \(N_e\) step and repeatedly re-plan. |
| most important results | Compared with UniPi, VILP significantly reduces training memory and inference time, and maintains or improves video quality and strategy success rate on multiple tasks. For example, VILP-8 in Arrange-Blocks-Hybrid achieves a max/mean success rate of 84.0/80.4, while UniPi-16 only achieves 18.0/13.2; in real Real-Arrange-Blocks, VILP-16 completes two block arrangements in 7/15, UniPi-4/16 is 0/15, and the VILP inference time is 0.238s faster than 1.422s for UniPi-16. |
| Things to note when reading | The advantages of VILP mainly come from the speed of latent planning, cross-attention condition mechanism, multi-view alignment and receding horizon; however, it is not a completely action data-free method, and low-level strategy training is still required from video to action. When reading the experiment, you must distinguish between the FID/FVD/speed experiment of "evaluating video planning only" and the success rate experiment of "complete policy rollout". |
2. Background and problem setting
Why video planning is suitable for robots
Video generative models naturally learn temporal consistency and future evolution: given current observations, it can "imagine" future frames after the robot performs a task. If these future frames can be converted into actions, a video planning policy is formed. Video is easier to collect and expand than motion data, so video generation may help robots move into a more scalable data paradigm.
Three key questions raised by the author
- Receding horizon planning: When the video generation is too slow, long videos can only be executed in open-loop, and errors accumulate seriously. The question is whether video planning can be accelerated to near real-time.
- Bridging video and action: Video models can be trained with motion-free videos, but ultimately the robot needs motion. The question is whether video-to-action mapping can be established with less or not identically distributed action data.
- Robotic data uniqueness: Robot data often has multi-view, RGBD, and multi-modal action distribution. Video planning strategies must adapt to these characteristics rather than copy single-view generic video generation.
3. Method details
3.1 Video data format
The paper writes the video data as \(\mathcal{D}^{v}=\{(o_0^i, o_1^i, \ldots, o_{T_d^i}^i)\}_{i=1}^{E}\). Where \(o\) is the combination of multi-view or RGBD images: \(o=\{f^j\}_{j=1}^{M}\), \(M\) is the number of views. That said, VILP handles multi-camera input as a common robotic data format from the beginning.
3.2 VQGAN compressed into latent space
Given an image \(f\in\mathbb{R}^{\tilde{H}\times\tilde{W}\times\tilde{C}}\), VQGAN encoder \(\mathcal{E}\) compresses it into \(z=\mathcal{E}(f)\in\mathbb{R}^{H\times W\times C}\), and decoder \(\mathcal{D}\) can reconstruct the image from \(z\). Both RGB images and depth images can be compressed; VQGAN is fixed after training and is not updated with diffusion training.
3.3 Latent video diffusion planner
Sample the future \(N\) frame from the video:
$$\mathbf{f}_t=[f_{t+\Delta t}, f_{t+2\Delta t}, \ldots, f_{t+N\Delta t}]$$
Compress to get latent sequence:
$$\mathbf{z}_t=[z_{t+\Delta t}, z_{t+2\Delta t}, \ldots, z_{t+N\Delta t}]$$
The video diffusion model is trained on latent sequences with the goal of:
$$\mathcal{L}(\theta)=\mathbb{E}_{\mathbf{z}_t^0, \epsilon^k, k}\left[\|\epsilon^k-\epsilon_\theta(\mathbf{z}_t^k, k)\|^2\right]$$
The network uses UNet with 3D convolution to capture both spatial and temporal features. In order to make it a planner, we also need to condition the current observation \(o_t\) and learn \(p(\mathbf{z}_t|o_t)\).
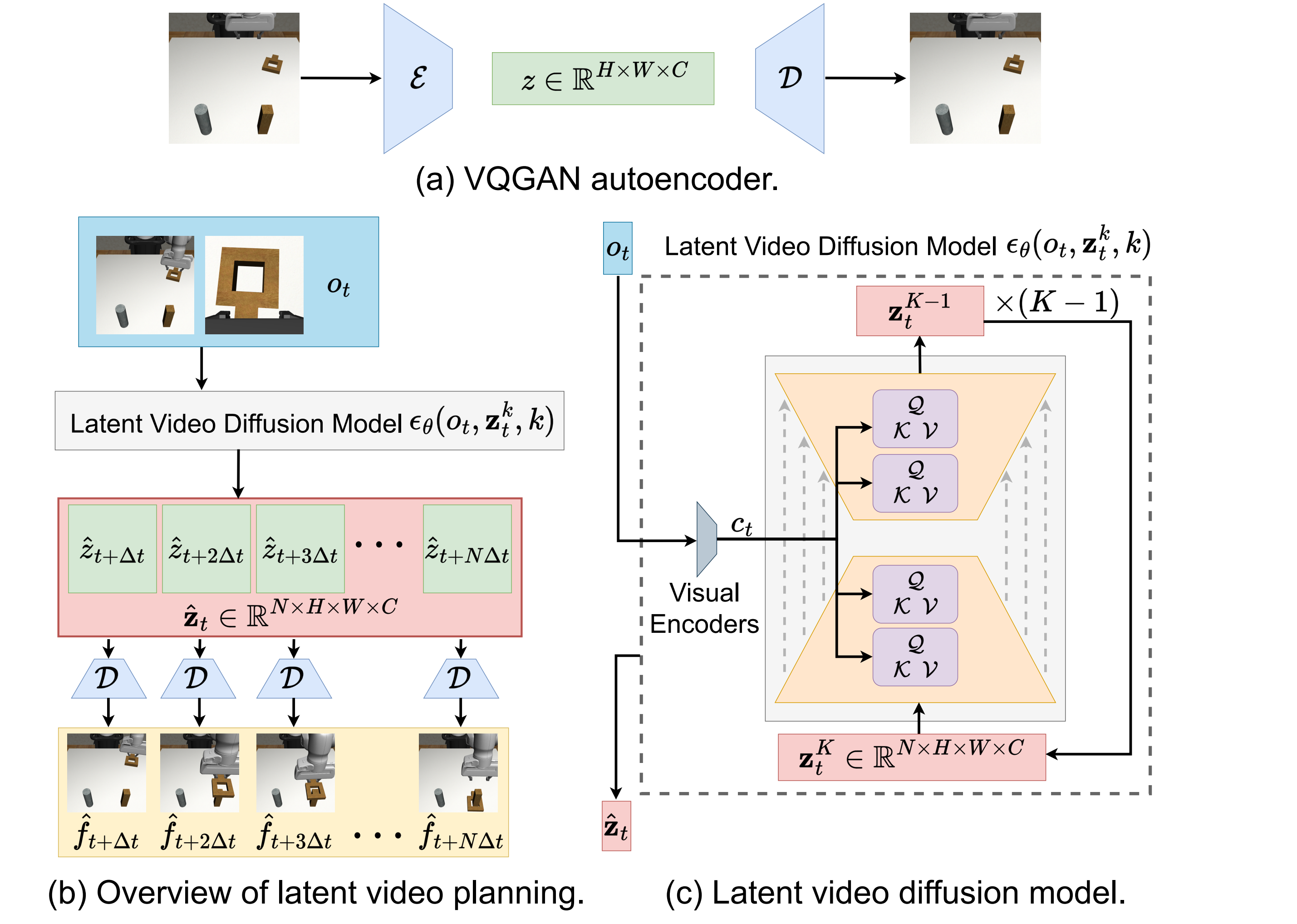
3.4 Observation conditioning and multi-view generation
VILP conditioning is divided into three steps:
- Use modified ResNet-18 to encode each view observation into a low-dimensional vector; use different encoders for different views, and the depth map is repeated three times as a three-channel input.
- Splice all perspective embeddings into \(c_t\), and inject the 3D UNet middle layer through cross-attention: \(\text{Attention}(Q, K, V)=\text{softmax}(QK/\sqrt{d})V\).
- Each perspective trains a diffusion model to generate a video from that perspective, and simultaneously integrates multi-view observation embedding to align the generated videos from different perspectives in time.
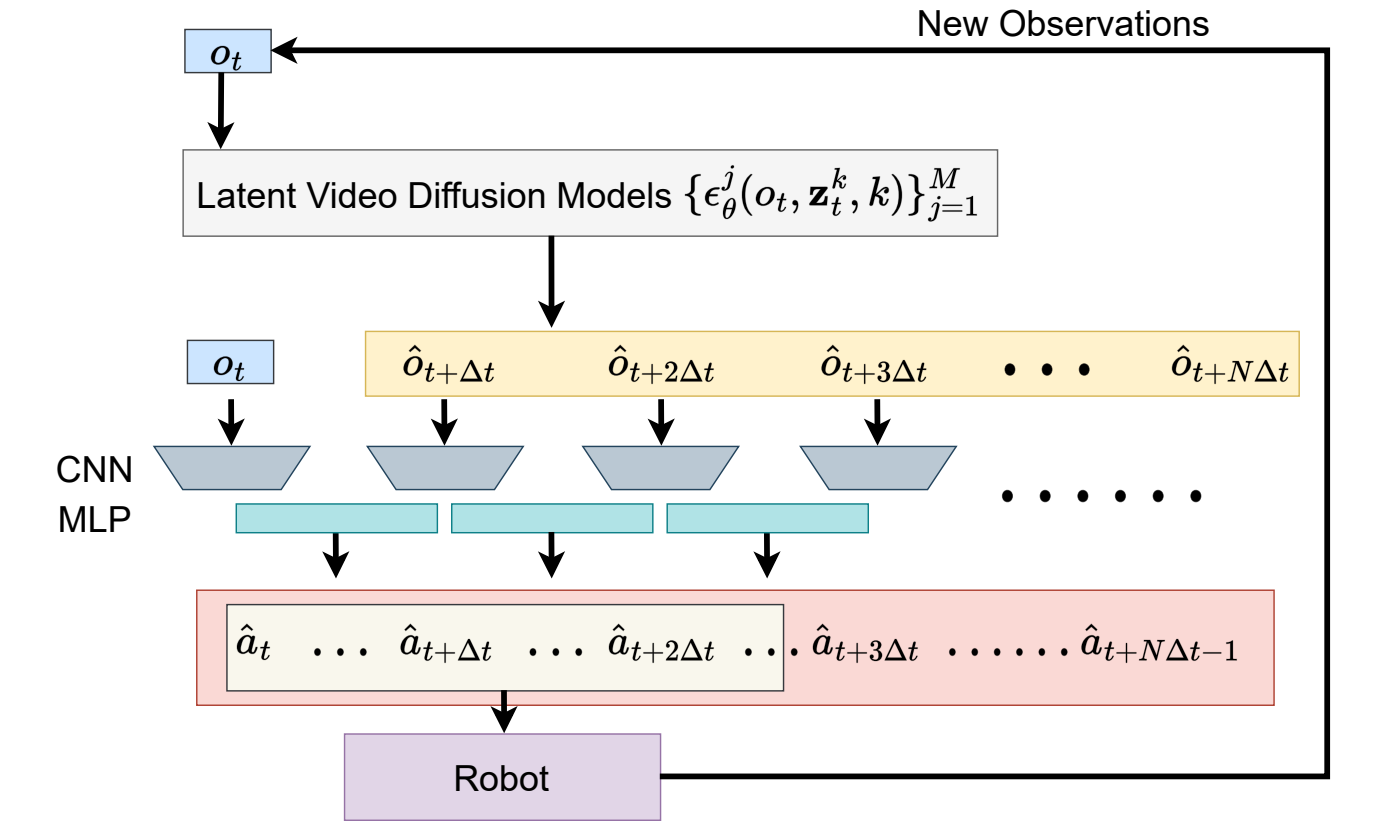
3.5 From predicted videos to actions
A low-level strategy uses adjacent predicted frames to generate action sequences:
$$\hat{\mathbf{a}}_{t+n\Delta t}=\pi(\hat{o}_{t+n\Delta t}, \hat{o}_{t+(n+1)\Delta t}), \quad n=0, \ldots, N-1$$
\(\pi\) consists of two CNN encoders and an MLP head. It maps two adjacent prediction observations into a continuous action segment \([a_{t+n\Delta t}, \ldots, a_{t+(n+1)\Delta t-1}]\). During execution, all generated actions are not executed, but only the first \(N_e\) step is executed, and then re-observed, re-generated, and re-action decoded. This is receding horizon control.
4. Experiments and results
4.1 Video planning experiment
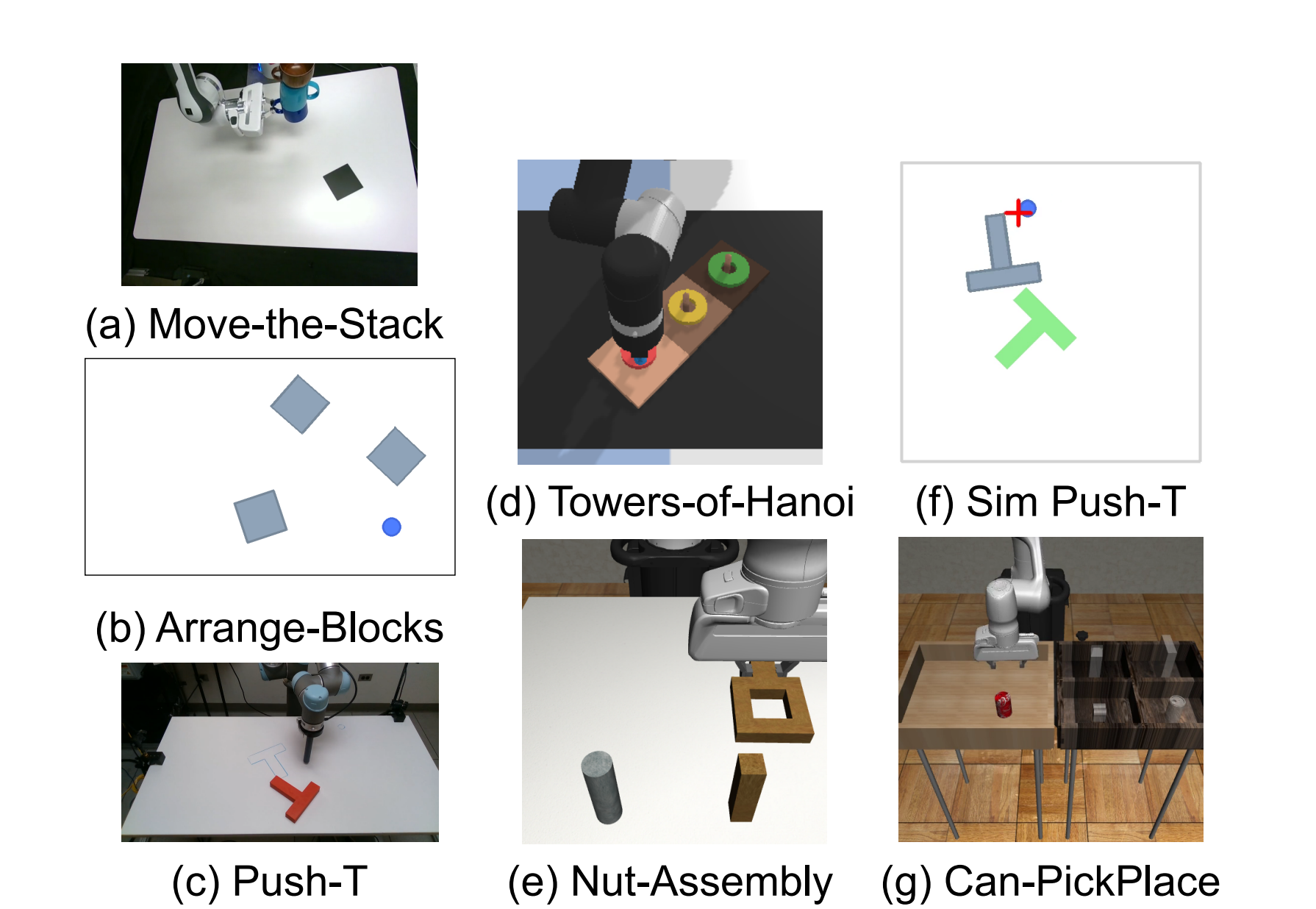
The authors only evaluate video planning on Move-the-Stack, Push-T, and Towers-of-Hanoi, without involving policy rollout. Using 9: 1 episode split, 90% training, 10% unseen testing, indicators include FID, FVD, single inference time. Both VILP and UniPi use DDIM, and the number after the method name represents denoising steps.
| Task | Key observations |
|---|---|
| Move-the-Stack | UniPi-64 achieves the best FID/FVD, but at 2.5s; VILP-4 at 0.058s is of similar quality and much faster. |
| Push-T | VILP significantly outperforms UniPi at a small number of steps, with VILP-8 FID 14.65, VILP-16 FVD 447.56, and UniPi-16 FVD 744.06. |
| Towers-of-Hanoi | VILP-8/16 has better FID/FVD than UniPi, maintaining a better quality/speed trade-off for long-structured tasks. |
4.2 Training memory and speed
VILP is generated in latent space, and the training memory is much lower than UniPi. For example, VILP in Arrange-Blocks only requires 10.0GB to generate 5 frames of 96x160, while UniPi requires 82.5GB for the same setting; VILP in Towers-of-Hanoi requires 8.7GB and UniPi 68.2GB. In terms of inference speed, VILP can reach levels from 0.058s to 0.231s in multiple settings, supporting near-real-time/real-time replanning.
4.3 Complete strategy rollout: Nut-Assembly and Arrange-Blocks
| Task | Diffusion Policy | VILP | UniPi | Conclusion |
|---|---|---|---|---|
| Nut-Assembly-Small | 28.0/24.3 | 26.7/23.3 | 20.0/17.6 | When it comes to small action data, VILP is close to Diffusion Policy and is better than UniPi. |
| Nut-Assembly-Hybrid | 48.0/43.1 | 56.7/53.2 | 35.3/27.2 | VILP is the strongest after adding off-target/hybrid action data. |
| Arrange-Blocks-Small | 8.9/5.9 | 46.0/40.4 | 14.7/8.9 | Video data provides a wealth of information about task structure. |
| Arrange-Blocks-Hybrid | 22.7/17.1 | 84.0/77.6 | 18.7/16.2 | VILP has the greatest advantage in this setting. |
The values in the table are max/mean success rate. This experiment supports the author's claim that VILP can leverage task knowledge in video generation models when there is a lot of video data but limited or complex high-quality action annotations.
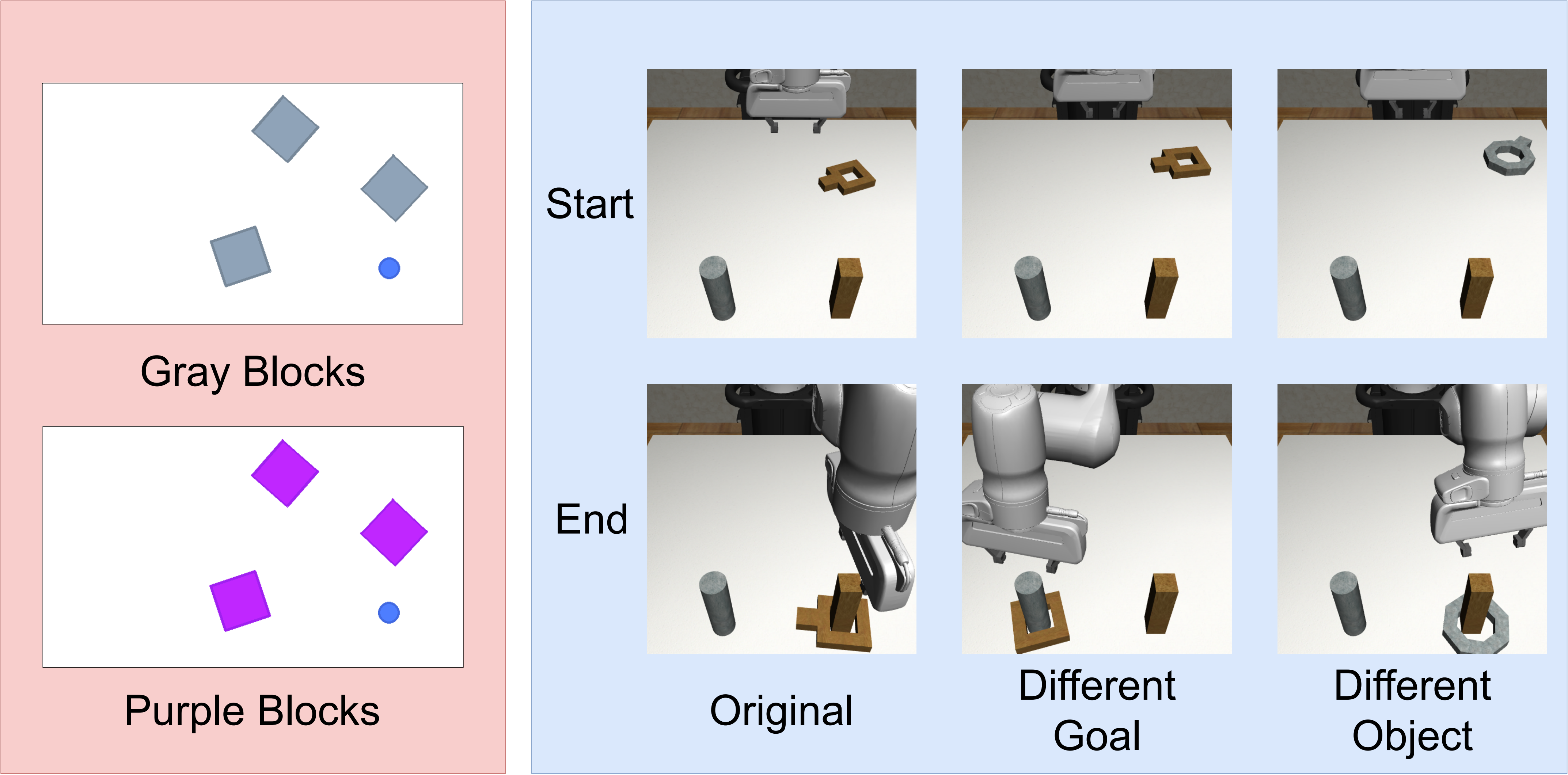
4.4 Comparison with other imitation learning methods
| Task | UniPi | DiffusionPolicy-C | DiffusionPolicy-T | LSTM-GMM | IBC | VILP w/o low dim. | VILP w/ low dim. |
|---|---|---|---|---|---|---|---|
| Sim Push-T | 82.0 | 84 | 66 | 54 | 64 | 82.6 | 88.0 |
| Can-PickPlace | 37.4 | 97 | 98 | 88 | 1 | 95.7 | 92.2 |
VILP is best on Sim Push-T, which the author believes shows that it can represent multi-modal action distribution; it is close to Diffusion Policy-C/T on Can-PickPlace, which shows that video planning routes are not only meaningful in low-data scenarios.
4.5 Module ablation and horizon ablation
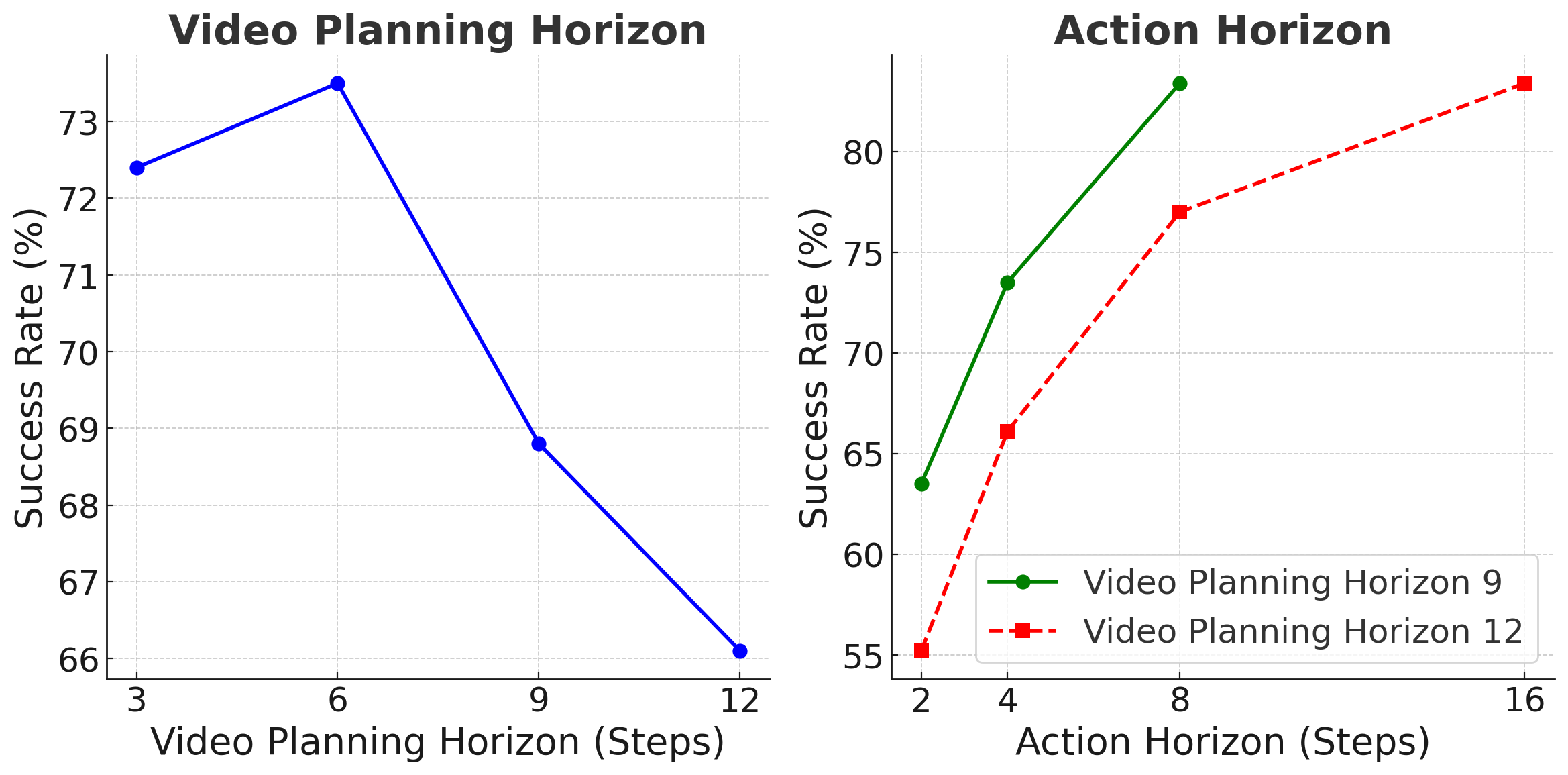
Module ablation shows that conditional concatenation is significantly weaker than VILP's cross-attention/global conditioning; multi-view fusion is critical to Can-PickPlace. Horizon ablation shows that the video planning horizon and action horizon cannot be blindly increased: too short to see enough of the future, too long to train and infer, which is expensive and more difficult to generate. The author's empirically preferred combination is video horizon 6 + action horizon 8, or video horizon 12 + action horizon 16.
4.6 Real Real-Arrange-Blocks
The real task asked Franka Panda to line up the L block and T block in the "LT" configuration on the blue line. The initial position and orientation are random, the action space is delta motion in the x/y direction, and it is trained using 220 human demonstrations. Results: VILP-16 completed two block arrangements 7/15, and another 6/15 completed one block; UniPi-4 and UniPi-16 both completed two blocks/one block 0/15. The inference time is 0.238s for VILP-16 and 1.422s for UniPi-16.

5. Key points of implementation and diagrams
Key implementation choices
- Video generation uses DDIM; VILP-4, VILP-8, and VILP-16 represent 4/8/16 denoising steps respectively.
- Video planner's UNet captures spatiotemporal relationships with 3D convolution.
- The observation encoder has different responsibilities than the VQGAN compression encoder: the former is used for conditionalization, the latter is used for low-variance, reconstructable latent representations.
- Multi-view generation uses an independent diffusion model for each view, while ensuring time alignment through multi-view embedding fusion.
- In the UniPi comparison, the author implemented the same low-level policy to compare the video planner differences as fairly as possible.
The paper has no independent appendix
There are no additional appendix files in the arXiv source code; all methods, experiments, and discussions are in `vilp.tex`. This report has integrated all major charts and experimental tables in the source code.
6. Key points of reproducibility and implementation
Minimum recurrence path
- Prepare multi-view/RGBD video data \(\mathcal{D}^{v}\), and a small amount of data with action tags for low-level policy.
- Train VQGAN autoencoder to compress each frame to latent; freeze after training.
- Samples a sequence of future frames from the video by \(N, \Delta t\) and encodes it as \(\mathbf{z}_t\).
- Training conditional latent video diffusion: input current observation \(o_t\), noisy latent video, denoising step, and predict noise.
- Different viewpoint observations are encoded with modified ResNet-18 and injected into 3D UNet via cross-attention.
- Train the low-level goal-conditioned policy \(\pi(\hat{o}_t, \hat{o}_{t+\Delta t})\rightarrow\hat{\mathbf{a}}\).
- When deployed, the future video latent is generated, decoded or directly used for adjacent frame action prediction, only the first \(N_e\) steps are executed and the cycle is re-planned.
7. Analysis, Limitations and Boundaries
The most valuable part of this paper
It advances "video generation as a robot planner" from a slower conceptual route to an engineering form that can be re-planned in real time. There are two most valuable points: first, latent video diffusion makes video planning fast enough to support receding horizons instead of long open-loops; second, it clearly demonstrates that video data and action data can be partially decoupled, with the video model responsible for learning the future evolution of the task, and a small amount/mixed action data responsible for bridging video to action.
Why does the result stand?
- The author separately evaluated the video planning quality, training memory, inference speed and final strategy success rate, covering the two-level issues of "whether the generation is good" and "whether the control is effective".
- The comparison with UniPi uses the same low-level policy and U-Net basic settings as much as possible to highlight the differences in latent planning and conditioning.
- Strategy rollout is not only verified in simulations, but also in real Real-Arrange-Blocks; the speed difference in real tasks directly affects the quality of closed-loop control.
- Ablation experiments support the core design: conditional concatenation is weaker, multi-view fusion is useful, and horizon selection exists to explain trade-off.
Main limitations
- action tag still required: VILP reduces reliance on high-quality task-specific action data, but the video-to-action low-level policy is not obtained unsupervised.
- Mission horizon is still limited: The experiments are mainly short to medium length operations; longer task-level multi-modal planning remains future work.
- Per-view training diffusion increases complexity: Multi-view alignment is effective, but training the model separately for each view will increase system maintenance costs.
- Generation artifacts not fully resolved: The authors pointed out that small artifacts did not significantly affect the experiment, but artifacts may mislead low-level strategies in complex contact tasks.
- Strong dependence on specific resolution and task settings: Real-time performance is obtained at lower resolutions such as 96x160, 80x80, etc., and needs to be re-evaluated when moving to higher resolutions or more viewing angles.
Questions to ask while reading
- How much does the low-level policy learn from predicting videos, and when is it worth training an extra video planner compared to direct diffusion policy?
- How sensitive is VILP to predicting the visual quality of videos? Which artifacts affect motion and which don't?
- A complete success rate of 7/15 on real missions suggests it is doable, but far from a stable deployment, what are the main failure modes?
- If a stronger pretrained video model is used instead of latent diffusion trained from scratch, can video data requirements be further reduced?
- Is it possible to train a unified video-to-action mapper across tasks, robots, and perspectives to truly achieve the more general route discussed by the author?