Unified Video Action Model
1. Reading orientation and group meeting guide
| Introductory items | What does this paper answer? | Where do you focus on when reading? |
|---|---|---|
| Research object | A unified model supports robot policy, video generation, forward dynamics, inverse dynamics, and policy + planner simultaneously. | Don't just think of it as a video generation policy; its core selling point is "same latent + different mask/objective". |
| core contradiction | Action prediction requires high temporal frequency and low latency; video generation requires high spatial quality and heavy computation. | See how decoupled video-action diffusion unpacks these two requirements between training and inference. |
| Main contributions | Unified video-action latent, two lightweight diffusion heads, and masked training support multi-tasking capabilities. | Focus on "UVA-action" ablation, speed decomposition, and action-free human video supplementary experiments. |
| Relationship with CoVAR | UVA is one of the methods often used as joint-model baseline in CoVAR papers. | UVA emphasizes sharing latent and decoupling heads; CoVAR emphasizes retaining pre-trained video DiT and paralleling action DiT. |
This paper is suitable to be placed in the discussion of "Can the video world model be turned into an efficient robot policy?" The author's position is not that "video generation replaces policy learning", but that "video generation serves as additional supervision to help latent learn dynamics; when the action is actually executed, the action head can independently and quickly decode". This is different from many two-stage methods that first generate the video and then obtain the action through inverse dynamics.
2. Background: Why should we unify video and action?
2.1 Problems with action-only policy
Action-only or VLA policies such as Diffusion Policy and OpenVLA can directly derive actions from observations, with fast reasoning and clear goals. However, the paper points out that this type of model is prone to overfitting the action history or local visual cues in the training data; when visual disturbances, long histories, and multi-task sharing dynamics occur, additional video prediction supervision may help the model understand scene changes instead of just remembering action patterns.
2.2 Problems with video-generation policy
Methods like UniPi first generate a future video and then drive actions from the video. It has two obvious costs: first, generating high-resolution video is inherently slow; second, video errors are passed on to motion prediction. Real robot control requires frequent output of fine-grained actions, so full video generation cannot be on the main path of policy inference.
2.3 UVA trade-off
During UVA training, videos and actions are jointly optimized, allowing latent representation to learn the relationship between visual dynamics and actions; when reasoning is used as policy, the video diffusion head is skipped and only the action diffusion head is run. This way the video still provides training supervision but does not slow down slow-motion inference.
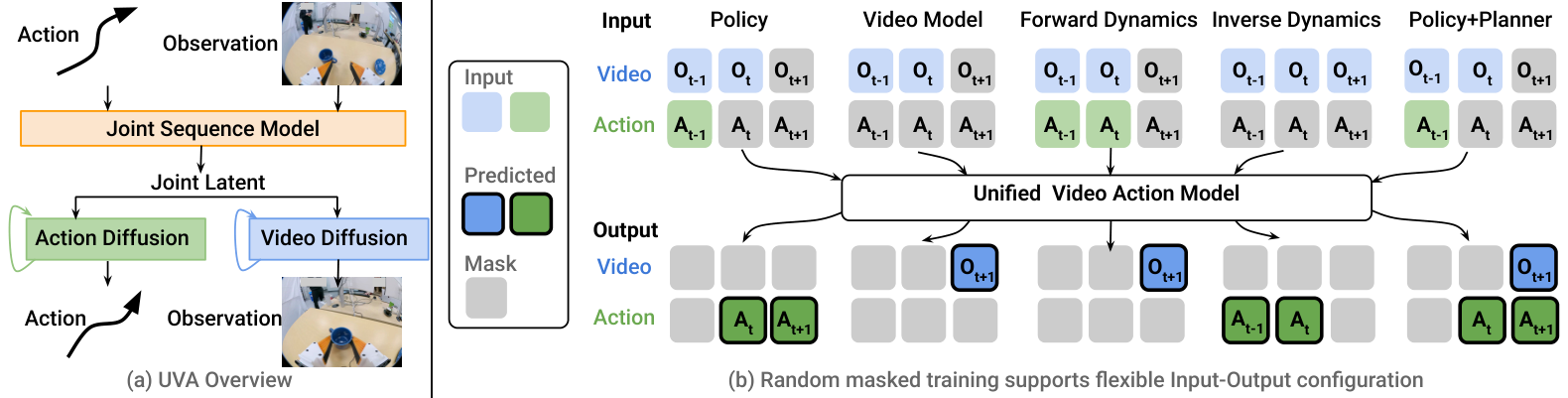
3. Detailed explanation of method: joint latent + decoupled diffusion + masked training
3.1 Problem definition
Given historical image observation $\{\mathbf{O}_{t-h+1}, \ldots, \mathbf{O}_t\}$ and historical action chunk $\{\mathbf{A}_{t-h}, \ldots, \mathbf{A}_{t-1}\}$, the goal is to predict future actions $\{\mathbf{A}_t, \ldots, \mathbf{A}_{t+h-1}\}$ and future observations $\{\mathbf{O}_{t+1}, \ldots, \mathbf{O}_{t+h}\}$. Each action chunk $\mathbf{A}_t\in\mathbb{R}^{L\times m}$ contains $L$ high-frequency actions, and each action has a dimension of $m$. In the experiments of this paper, the historical horizon and the future horizon are assumed to be the same.
| $h$ | History/future horizon, the paper makes them the same for simplicity. |
| $\mathbf{O}_t$ | Image observation $t$. |
| $\mathbf{A}_t$ | The $t$ action chunk contains $L$ high-frequency actions. |
| $N$ | The number of visual tokens encoded for each image. |
| $\mathbf{Z}_{t+i}$ | The joint video-action latent tokens output by the Transformer are used to decode future images and actions. |
3.2 Encode History: Align image token with action token
Historical images are first pre-trained VAE encoder (paper writing kl-f16) to obtain latent map $\mathbb{R}^{w\times h\times c}$ is then flattened and projected into $N$ $d$ dimensional visual tokens through the FC layer. The action frequency is usually higher than the camera frame rate, so each image corresponds to an action chunk. UVA repeats the action chunk $M$ times to match the number of visual tokens, and then obtains $N$ $d$-dimensional action tokens through the FC layer.
3.3 Masked Autoencoder for Observation Prediction
Future observations are also first converted into tokens through the VAE encoder and FC layer. During training, part of future observation tokens are randomly masked, and the model learns to reconstruct these tokens. To reduce cross-frame leakage, the paper uses the same mask position on all future video frames. Subsequently, historical visual tokens, historical action tokens and masked future observation tokens are combined into a sequence, input to Transformer, and output $\{\mathbf{Z}_{t+1}, \ldots, \mathbf{Z}_{t+h}\}$.
For language tasks such as Libero10, UVA uses CLIP text encoder to encode language instructions into $d$-dimensional tokens, and repeatedly attaches them to $N\times h$ video-action tokens $M$ times before sending them to the Transformer. The first $N\times h$ tokens output by Transformer are used as joint video-action latent.
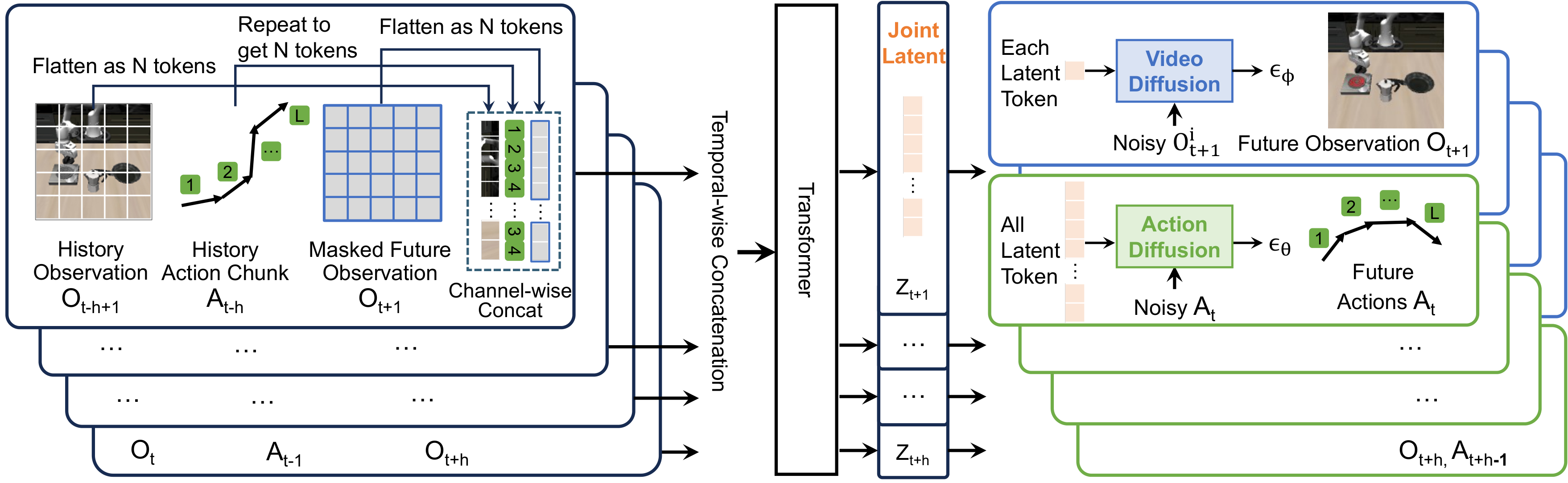
3.4 Decoupled Video and Action Diffusions
Decoupling of UVA occurs during the decoding phase. After sharing the Transformer latent $\mathbf{Z}$, video and motion each went into two lightweight diffusion heads. During training, both heads are supervised; during policy inference, only the action head can be run; during video generation, only the video head can be run, and more autoregressive steps can be used to improve visual quality.
Action diffusion loss:
$$ \mathcal{L}_{\text{action}}(\mathbf{Z}, \mathbf{A}) = \mathbb{E}_{\epsilon, k} \left[ \|\epsilon-\epsilon_\theta(\mathbf{A}^{(k)}\mid k, \mathbf{Z})\|^2 \right]. $$Meaning:
The action head predicts noise on noisy action chunks; $\mathbf{Z}$ is the condition and $k$ is the diffusion timestep.
Video diffusion loss:
$$ \mathcal{L}_{\text{video}}(\mathbf{Z}, \mathbf{O}) = \mathbb{E}_{\epsilon, k} \left[ \frac{1}{N}\sum_{i=1}^{N} \|\epsilon_i-\epsilon_\phi(\mathbf{O}^{i, (k)}\mid k, z_i)\|^2 \right]. $$Meaning:
The video head is denoised by visual token/patch; each latent token $z_i$ is conditioned on the diffusion decoder of the corresponding patch, and then the image is restored through the VAE decoder.
The total loss is $\mathcal{L}=\mathcal{L}_{\text{action}}+\mathcal{L}_{\text{video}}$ and summed over time horizon $h$. This design has a very practical benefit: diffusion iteration only occurs in the lightweight head, rather than repeated denoise on the entire large network like a partial diffusion policy.
3.5 Autoregressive Video Generation
Supplementary material explains that UVA's video generation draws on MaskGIT and MAR: starting from an empty mask, it gradually generates visual tokens according to several autoregressive steps. If step=1, the entire video is generated at once; if there are more steps, subsequent tokens are conditionalized with the already generated tokens, which usually improves the details. UVA is built on the MAR-B pre-trained model, but has been significantly modified for video-action joint modeling.
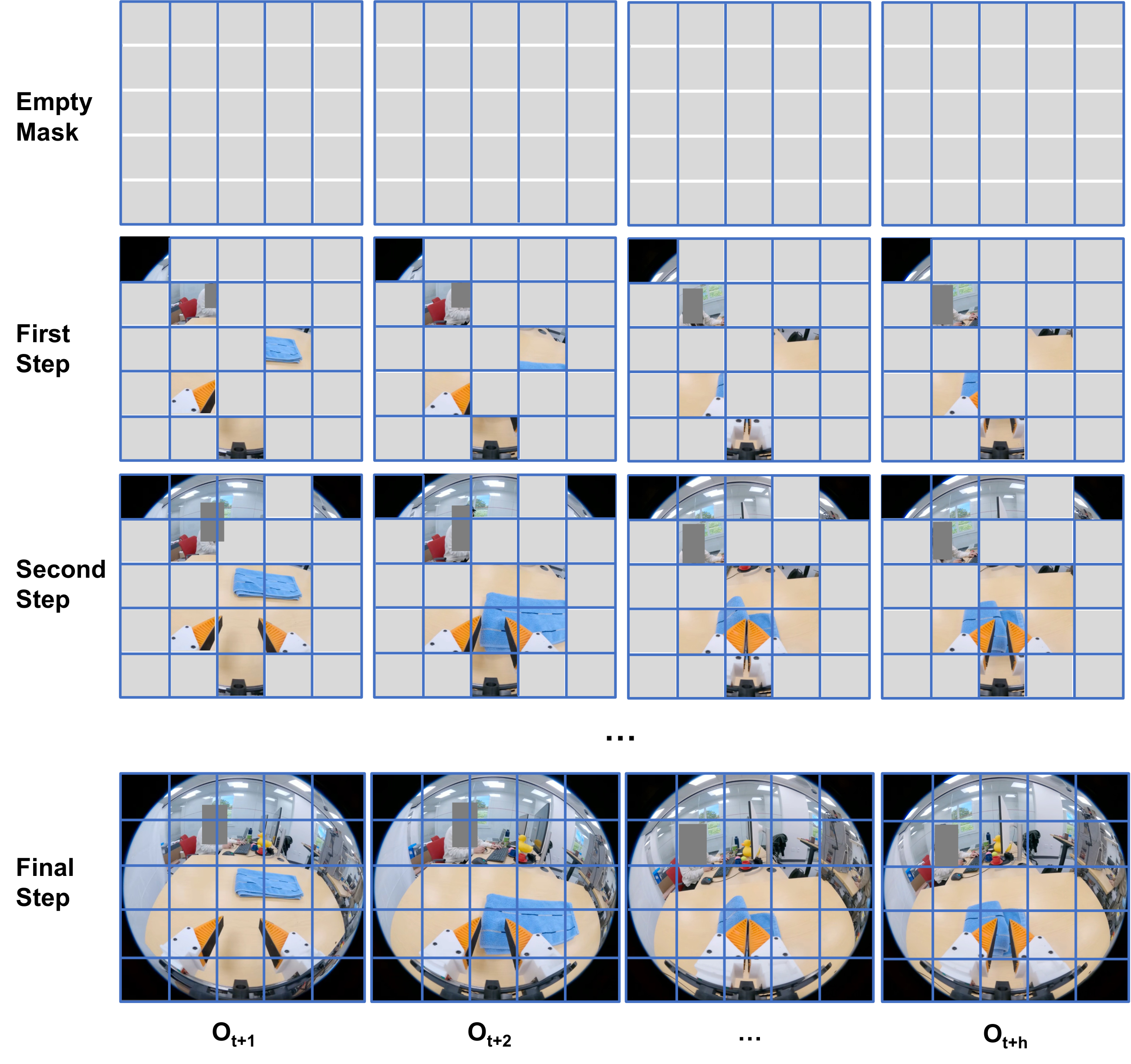
3.6 Five types of functions of Masked Training
UVA not only trains the task of "history to future actions/videos", but trains a unified model through different input and output masks. The paper uses it for five categories of functions:
- Robot policy: Given historical observations/actions, predict future actions; skip video generation during inference.
- Video model: Given historical observations, generate future videos; multi-step autoregressive generation can be used.
- Forward dynamics: Given observations and actions, predict future observations.
- Inverse dynamics: Given adjacent/future observations, predict actions that will cause visual changes.
- Policy + planner: Simultaneously predict actions and videos, and use video results to assist in planning/screening actions.
训练阶段:
for each trajectory:
encode history images with VAE + FC into visual tokens
encode history action chunks into action tokens aligned with visual tokens
encode future images, randomly mask future visual tokens
optionally append repeated CLIP language tokens
Transformer produces joint latent Z
video diffusion head predicts future visual-token noise
action diffusion head predicts future action-chunk noise
apply video/action losses according to the current masked objective
policy 推理阶段:
encode current history images/actions
use Transformer to obtain Z
skip video diffusion
run lightweight action diffusion head
output 16 action steps and execute the first chunk4. Experimental results: policy, video, forward/inverse dynamics
4.1 Policy: simulation task
The simulation experiments cover single-task PushT and Toolhang, as well as multi-task PushT-M and Libero10. Most methods reason about 16 actions at a time and execute the first 8, except OpenVLA; OpenVLA outputs one action at a time and therefore runs 8 times to align the number of executed actions.
| method | PushT ↑ | Tool ↑ | PushT-M ↑ | Libero10 ↑ | Speed ↓ |
|---|---|---|---|---|---|
| DP-C | 0.91 | 0.95 | 0.68 | 0.53 | 0.50s |
| DP-T | 0.78 | 0.76 | 0.63 | 0.58 | 0.36s |
| OpenVLA | 0.35 | 0.18 | 0.22 | 0.54 | 1.52s |
| UniPi | 0.42 | 0.00 | 0.19 | 0.00 | 24.07s |
| $\pi_0$ | - | - | - | 0.85 | 0.09s |
| $\pi_0$-FAST | - | - | - | 0.60 | 0.09s |
| UVA-action | 0.45 | 0.62 | 0.46 | 0.86 | 0.22s |
| UVA | 0.98 | 0.88 | 0.88 | 0.90 | 0.23s |
The most critical comparison is UVA vs. UVA-action. UVA-action removes video generation supervision and only retains action policy; it degrades significantly on PushT, Tool, and PushT-M, indicating that joint video-action training does play a role in policy learning, rather than just adding additional model complexity.
4.2 Policy: Real UMI OOD multitasking
The real experiment uses public UMI data and does not collect additional training data. The training tasks include Cup Arrangement, Towel Folding, and Mouse Arrangement, and the test is performed on the ARX X5 robotic arm. Multi-task testing is OOD: includes unseen environments, objects, backgrounds, robot/gripper colors, etc.
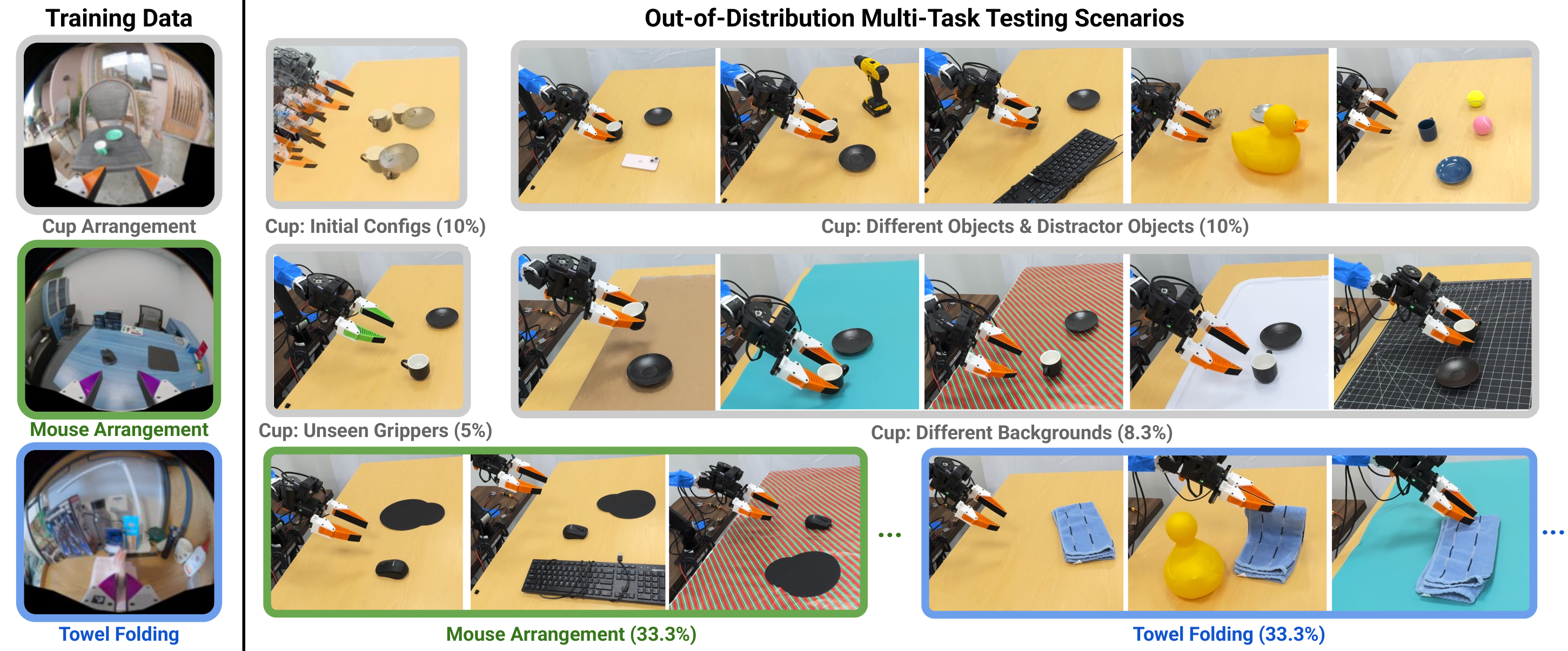
| method | Single Task Cup ↑ | OOD Cup ↑ | OOD Towel ↑ | OOD Mouse ↑ | Speed ↓ |
|---|---|---|---|---|---|
| DP-UMI | 0.95 | 0.50 | 0.70 | 0.40 | 70ms |
| UVA | 0.85 | 0.65 | 0.70 | 0.80 | 95ms |
DP-UMI is stronger on single-task Cup. The author explains that there are many failure recovery fragments in the data, which is more suitable for short history recovery policies. UVA is stronger under multi-task OOD, especially Mouse, which improves from 0.40 to 0.80, supporting the claim that "video supervision learns a more shared dynamic structure".
4.3 Visual disturbance and history length
In PushT's visual perturbation experiments, video generation methods such as UVA and UniPi were more stable than action-only baselines. UVA reaches 0.64 when goal color changes, while DP-C only has 0.17 and OpenVLA is 0.32. This supports the authors' argument that video supervision enhances visual robustness.
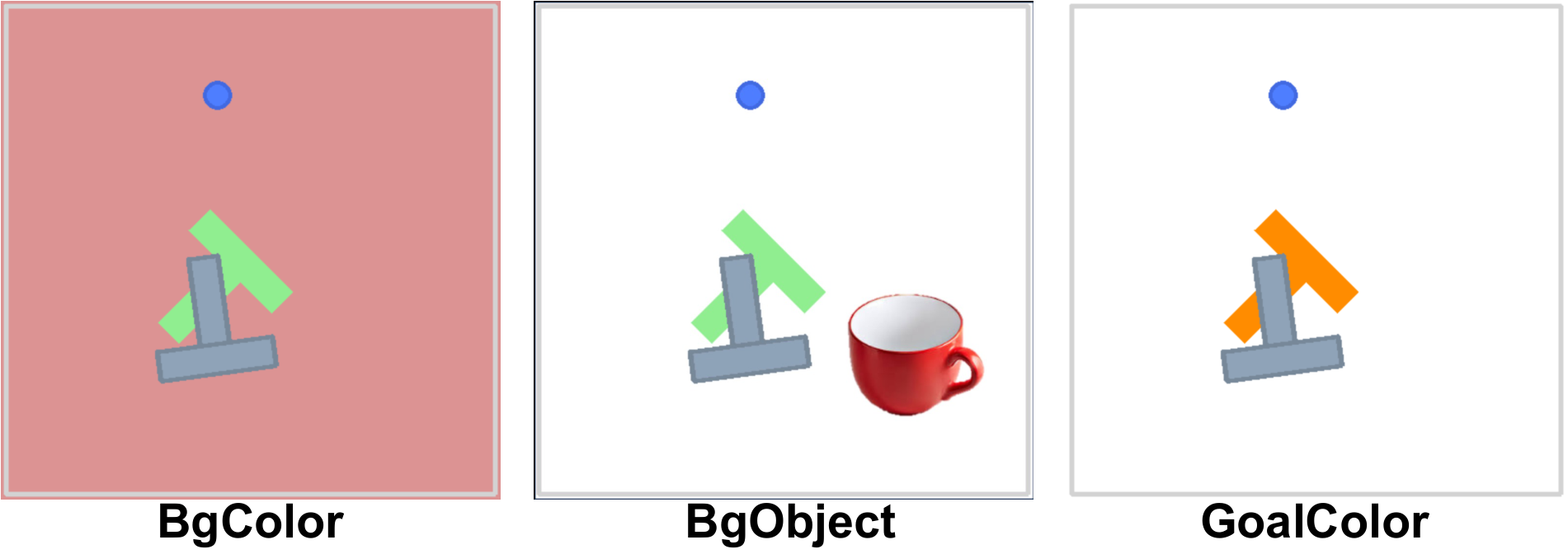
| method | Normal ↑ | BgColor ↑ | BgObject ↑ | GoalColor ↑ |
|---|---|---|---|---|
| DP-C | 0.91 | 0.12 | 0.21 | 0.17 |
| DP-T | 0.78 | 0.22 | 0.17 | 0.28 |
| OpenVLA | 0.35 | 0.17 | 0.13 | 0.32 |
| UniPi | 0.42 | 0.31 | 0.36 | 0.40 |
| UVA | 0.98 | 0.35 | 0.31 | 0.64 |
4.4 Video Generator
UVA skips action head when acting as a video generator. FVD is reported in the table, lower is better. The 1-step UVA on Libero10 is worse than UniPi, but the 8-step UVA is the best; even the 1-step UVA on Cup Arrangement is significantly better than UniPi, and the 8-step is further improved.
| method | Libero10 FVD ↓ | CupArrange FVD ↓ |
|---|---|---|
| UniPi | 56.55 | 71.37 |
| UVA (1 step) | 89.36 | 51.34 |
| UVA (8 steps) | 51.10 | 29.72 |

4.5 Forward Dynamics for Planning
The forward dynamics experiment is conducted in a block pushing environment: DP-C samples 100 16-step action trajectories, UVA predicts future images based on the actions, then calculates rewards based on the predicted images, and selects the trajectory with the highest reward to execute the first 6 steps. The success rate of DP-C alone is 0.38; after using UVA future observations for trajectory selection, it increases to 0.60; the upper bound of the ground-truth simulator is 0.75.
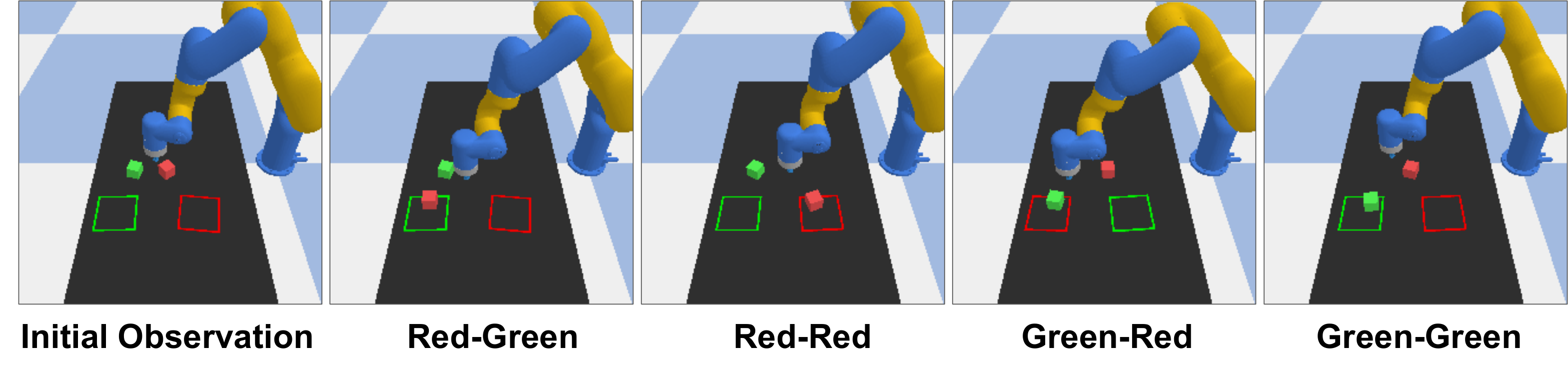
| method | R-R ↑ | R-G ↑ | G-R ↑ | G-G ↑ | Avg. ↑ |
|---|---|---|---|---|---|
| DP-C | 0.20 | 0.50 | 0.60 | 0.20 | 0.38 |
| UVA-guided | 0.80 | 0.70 | 0.50 | 0.40 | 0.60 |
| GT-Dynamics | 0.80 | 0.80 | 0.70 | 0.70 | 0.75 |
4.6 Inverse Dynamics
The Inverse dynamics task uses UMI Cup Arrangement data to predict camera/robot motion from observation changes and compare with Mocap ground truth. UVA has a position error of 0.75 cm and a rotation error of 1.11 degrees, which is significantly better than UniPi inverse dynamics; SLAM is still the most accurate, but requires additional mapping and calibration.
| method | Position ↓ | Rotation ↓ |
|---|---|---|
| UniPi Inverse Dynamics | 1.92 cm | 2.21° |
| UVA | 0.75 cm | 1.11° |
| Visual Inertial SLAM | 0.41 cm | 0.30° |
4.7 Additional experiments: action-free video and mask strategies
In the supplementary material, the author tried to use 3, 175 human-only videos of the Human Video data set: first do video generation pre-training, and then combine finetune with LIBERO-10 through masked training. On Libero10, the 30-test increased from 0.93 to 0.97, and the 500-test increased from 0.90 to 0.91. This is the most direct evidence in the paper that supports "action-free video can help robot strategies", but the scale is still small.
| model | 30 test ↑ | 500 test ↑ |
|---|---|---|
| UVA | 0.93 | 0.90 |
| UVA + Human Data | 0.97 | 0.91 |
Masking strategy experiments show that different task preferences have different masking strategies: application-dependent 25% is better for video generation and forward dynamics; application-independent 50% is better for policy and inverse dynamics. This reminds us that masked training is not a mindless trick. Mask proportion and semantics will significantly affect the trade-off of multi-functional models.
5. Intensive reading of charts
5.1 Fig. 1: The "unification" of UVA is actually latent unification, not output unification.
Figure 1 can easily be misinterpreted as a model that outputs video and action simultaneously every time. More precisely, UVA unifies the intermediate latent and training framework; the output end is selectively enabled through mask/objective and diffusion head. This distinction is important because it explains why UVA can be used as a fast policy: policy inference does not require video pixels.
5.2 Fig. 2: Aligning action chunks with visual tokens is the key point for reproducibility
The architecture diagram shows how action chunks and image tokens enter the same Transformer. If you only use the action as a global condition when reproducing, you may not be able to get the token-level video-action latent claimed in the paper. The report recommends focusing on checking the repeat, FC projection, temporal concatenation and conv+MLP aggregation of action tokens in the official code.
5.3 Table 1: UVA-action is the most valuable ablation
In Table 1, UVA-action still has a score of 0.86 in Libero10, indicating that the action-only version is not weak; but it degrades significantly on PushT/Tool/PushT-M, supporting "video prediction supervision does help certain policy scenarios". This illustrates the design gain of UVA better than simply comparing it to UniPi or OpenVLA.
5.4 Speed decomposition: Fastness comes from "diffusion only on the head"
| Module/Task | Time ↓ |
|---|---|
| VAE Image Encoder | 40 ms |
| Transformer Attention | 40 ms |
| Transformer Flash Attention | 30 ms |
| Action Diffusion (16 steps) | 15 ms |
| Action Diffusion (100 steps) | 93 ms |
| Video Diffusion (16 steps) | 100 ms |
| Video Diffusion (100 steps) | 625 ms |
| UVA policy (16 steps) | 95 ms |
| Policy + Planner (16 steps) | 195 ms |
The most important thing to remember here is: video diffusion is much more expensive than action diffusion. UVA's policy speed is not because video generation is fast, but because the policy path bypasses video generation.
6. reproducibility list and project details
6.1 Direct reproducibility clues given by the official code
The official GitHub provides PyTorch implementation, installation environment, pre-training checkpoints, PushT Colab, and simulation/real evaluation scripts. The README states that the environment consists of conda_environment.yml Create, simulation test script includes eval_sim.py, the real test script includes eval_real.py. It is recommended to use at least 4 GPUs for training; the project page adds that the UMI task uses 500 trajectories per data set, and the video generation phase on 8 H100 takes about 2 days, and the joint video-action training takes another 2 days.
| Recurring items | Information given by the paper/code |
|---|---|
| base model | Pretrained VAE encoder (kl-f16) and MAR-B related pretrained models. |
| training phase | Two stages are better: video generation first, then joint video-action finetune. |
| action output | Predict 16 action steps at a time; simulation usually executes the first 8 steps, and the real task is expressed as a single 16-action trajectory. |
| Diffusion steps | The simulation action prediction uses 100 denoise steps; the real policy uses 16 steps for real-time deployment. |
| language conditions | Libero10 uses a CLIP text encoder, where text tokens are repeated and appended to a sequence of video-action tokens. |
| real data | Cup/Towel/Mouse three public UMI data sets; multi-task training collects 500 episodes each, totaling 1500 episodes. |
| Hardware speed test | Simulation speeds are on NVIDIA L40; real deployment speeds are measured on RTX 3080. |
6.2 Code locations that should be checked first when reproducing
- tokenization: The specific value of $w, h, c, N, d$ of VAE latent, and the implementation of action chunk repeated $M$ times.
- masking: Whether future frames have the same position mask; how to configure the mask pattern of different applications.
- Transformer input: The splicing dimensions and order of historical vision, historical actions, masked future obs, and language tokens.
- decoders: Whether the video head diffuses patch/token one by one; how the conv+MLP aggregation of the action head combines $N$ latent tokens into action conditions.
- Training schedule: Checkpoint transfer, learning rate, selected_training_mode, and predict_action switches of video-only stage and joint stage.
- Real deployment: UMI/ARX X5 controls interface, safety limiting, action normalization and execution chunk length.
6.3 Differences from CoVAR/other joint models
UVA learns a joint video-action latent and uses two lightweight diffusion heads for decoding; CoVAR retains the pre-trained video DiT, then connects the Action DiT in parallel, and uses Bridge Attention for cross-modal communication. The strength of UVA is a unified model that is versatile and can skip videos during inference; the strength of CoVAR is to more explicitly protect the pre-trained video backbone and handle the video/action generation process as two dedicated DiT branches.
7. Critical discussion and group meeting questions
7.1 Strong points of the paper
- The problem is clearly defined: Address the contradiction of "video generation is useful but policy inference cannot be too slow" head-on.
- Very practical in engineering: Skip video generation during inference and only diffuse on the lightweight action head. This is a deployable design.
- Wide functional coverage: The same framework shows policy, video generation, forward dynamics, and inverse dynamics.
- There are real OOD reviews: Testing includes unseen environment/object/background/gripper colors using public UMI data.
- Code disclosure: The reproducibility entry is more complete than many embodied video models.
7.2 Points to be cautious about
- The trade-off brought about by "unification" has not been fully unfolded: Different tasks may prefer different mask strategies and diffusion steps, and a unified model may not always be optimal.
- Real single tasking is no better than dedicated policy: Cup single-task DP-UMI is 0.95 and UVA is 0.85, indicating that dedicated data and dedicated architecture may still prevail.
- Evidence for action-free video is still limited: Human Video only brings a small improvement to Libero10, and web-scale video has not been proven to steadily improve real robot generalization.
- The relationship between video quality and action success rate is still non-linear: Better FVD does not necessarily lead to better action. The value of UVA mainly comes from latent supervision rather than just generating pictures.
- Hardware closed loop details are limited: The actual deployment speed and success rate strongly depend on the control interface, delay, security policy and data distribution.
7.3 Group meeting discussion question 1: What exactly does video supervision help?
UVA-action ablation shows that removing video generation supervision will reduce some task performance, but it does not fully answer whether video supervision helps visual robustness, dynamic prediction, regularization, or multi-task shared representation. A stronger follow-up is to put the video loss weight, video generation quality, latent probing, and visual perturbation success rate in the same analysis table to observe whether they are really related.
7.4 Group meeting discussion question 2: Should the unified model unify all tasks?
Mask strategy experiments imply that the optimal mask strategies are different for different functions. So is UVA's "five functions in one model" a long-term direction, or is it just proof that the same architecture can be adapted to multiple functions? If the goal is the strongest policy, perhaps it is better to specifically adjust the policy mask/objective; if the goal is a general robotics foundation model, multi-functional unification is more valuable. This question can lead to discussions of model size, task sampling ratio, and objective balancing.
7.5 Follow-up research directions
- Expanded action-free video pretraining: Verify whether web-scale or egocentric human video can significantly improve real robot OOD.
- Stronger task balancing Affiliations: Automatically adjust the loss weight and task sampling of video/action/forward/inverse objectives.
- Faster inference module: Flash Attention, fewer-step diffusion, flow matching head or consistency head.
- More detailed latent analysis: Demonstrate which dimensions/attention heads in the joint latent are responsible for encoding geometry, contact, and motion direction.
- Combined with 3D/force/audio modal: The author also mentions that it can be extended to sound and force; it is especially worth doing for contact-rich tasks.