CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
1. 论文速览
| 阅读定位项 | 内容 |
|---|---|
| 论文要解决什么 | 现有 VLA 通常从观察和语言直接预测动作,缺少显式中间推理,尤其在复杂操作任务中缺少 temporal planning 或 reasoning 能力。 |
| 作者的方法抓手 | 把未来图像帧作为 visual CoT:先预测 $n$ 步后的子目标图像,再用 full attention 并行生成动作 chunk;视觉推理可用没有动作标注的视频训练。 |
| 最重要的结果 | LIBERO 平均成功率 81.13%,高于 OpenVLA fine-tuned 的 76.5%;摘要称真实机器人任务相对 SOTA VLA 提升 17%,仿真基准提升 6%。 |
| 阅读时要注意的点 | 主要贡献不只是“加一个图像生成模块”,而是把视觉 token 生成、动作 token 离散化、hybrid attention、action chunking 和两阶段训练组合成一个可部署 VLA 系统。 |
难度评级
4/5。读懂大意需要 VLA、imitation learning、离散视觉 token、autoregressive image generation 和 robot benchmark 的背景;复现层面还需要理解动作离散化、动作 chunking、closed-loop deployment 和多数据混合训练。
关键词
Vision-Language-Action Models;Visual Chain-of-Thought;Subgoal Image Generation;Hybrid Attention;Action Chunking;Robot Manipulation
核心贡献清单
- 提出 visual chain-of-thought for VLA。论文把子目标图像定义为动作预测前的中间推理步骤,使机器人策略在像素空间先生成计划状态,再输出动作。
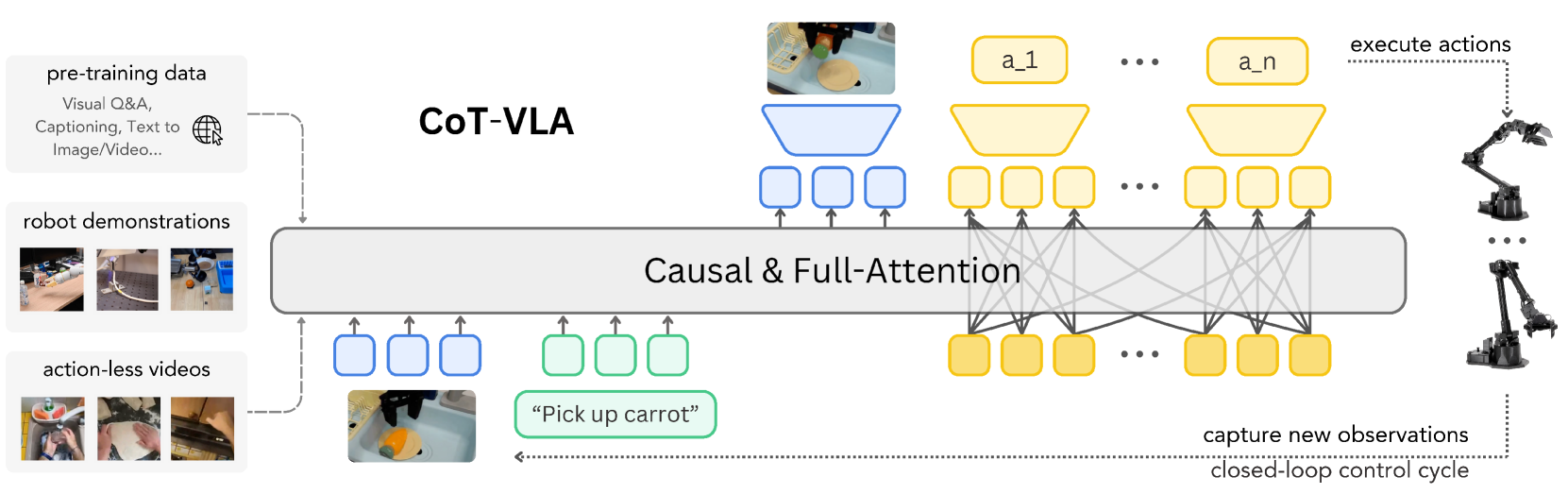
- 构建 CoT-VLA 系统。系统基于 VILA-U 这类可理解/生成图像和文本的统一多模态模型,并加入 hybrid attention:文本/图像生成使用 causal attention,动作预测使用 full attention。
- 利用 action-less videos。子目标图像预测不需要动作标注,因此预训练阶段除 Open X-Embodiment 机器人数据外,还引入 Something-Something V2 和 EPIC-KITCHENS-100 这类视频数据。
- 在仿真和真实机器人上验证。实验覆盖 LIBERO、Bridge-V2 和 Franka-Tabletop,并通过消融分析 action chunking、hybrid attention、visual CoT 和预训练的作用。
2. 动机
2.1 要解决什么问题
论文聚焦 VLA 在机器人操作中的一个结构性问题:许多现有模型把视觉观察和语言指令直接映射到动作,形式上像一个端到端 policy。这样的模型虽然能利用 VLM 的场景理解能力,但中间没有显式计划状态,因而作者认为它们缺少对“下一步应该让场景变成什么样”的 temporal planning 或 reasoning。
在一个长程操作任务里,机器人不只是要知道“抓什么”,还要知道“抓完之后场景应当朝哪个目标状态推进”。CoT-VLA 的选择是让模型在动作前先生成一个未来图像 $\hat{s}_{t+n}$,把“意图”落在可视化的子目标状态上。
2.2 已有方法的局限
论文将已有方法的局限分成两类。第一类是 direct VLA:OpenVLA、RT/PaLM-E 一类方法主要学习 $P(a_t \mid s_t, l)$,缺少显式 intermediate reasoning。第二类是 robotics CoT 或 subgoal 方法:一些方法使用语言计划、keypoints、bounding boxes 或 reward guidance 作为中间表示,但这些表示要么过于抽象,要么需要额外预处理或标注 pipeline。
作者选择 subgoal image 的原因是:图像状态天然存在于机器人 demonstration 和一般视频里,不需要额外人工标出关键点或框;它也比纯文本计划更直接地表达物体位置、接触关系和场景状态。
2.3 本文的解决思路
CoT-VLA 的高层思路是把动作生成拆成两个条件生成问题:
- 根据当前观测 $s_t$ 和语言指令 $l$,生成未来子目标图像 $\hat{s}_{t+n}$。
- 根据当前观测、语言指令和子目标图像,生成长度为 $m$ 的动作序列。
这个设计使模型可以从没有动作标注的视频中学习“未来视觉状态如何变化”,同时仍然用机器人 demonstration 学习“如何用动作达到该状态”。
4. 方法详解
4.1 问题设定与数据形式
论文考虑两类数据:
| 数据 | 形式 | 用途 |
|---|---|---|
| 机器人 demonstration $D_r$ | $D_r=\{(l,\mathbf{a}_{1...T},\mathbf{s}_{1...T})\}$ | 既训练子目标图像生成,也训练动作预测。 |
| 无动作视频 $D_v$ | $D_v=\{(l,\mathbf{s}_{1...T})\}$ | 只训练视觉子目标预测,因为没有动作标签。 |
其中 $l$ 是语言指令,$\mathbf{s}_{1...T}$ 是图像观测序列,$\mathbf{a}_{1...T}$ 是机器人动作序列。
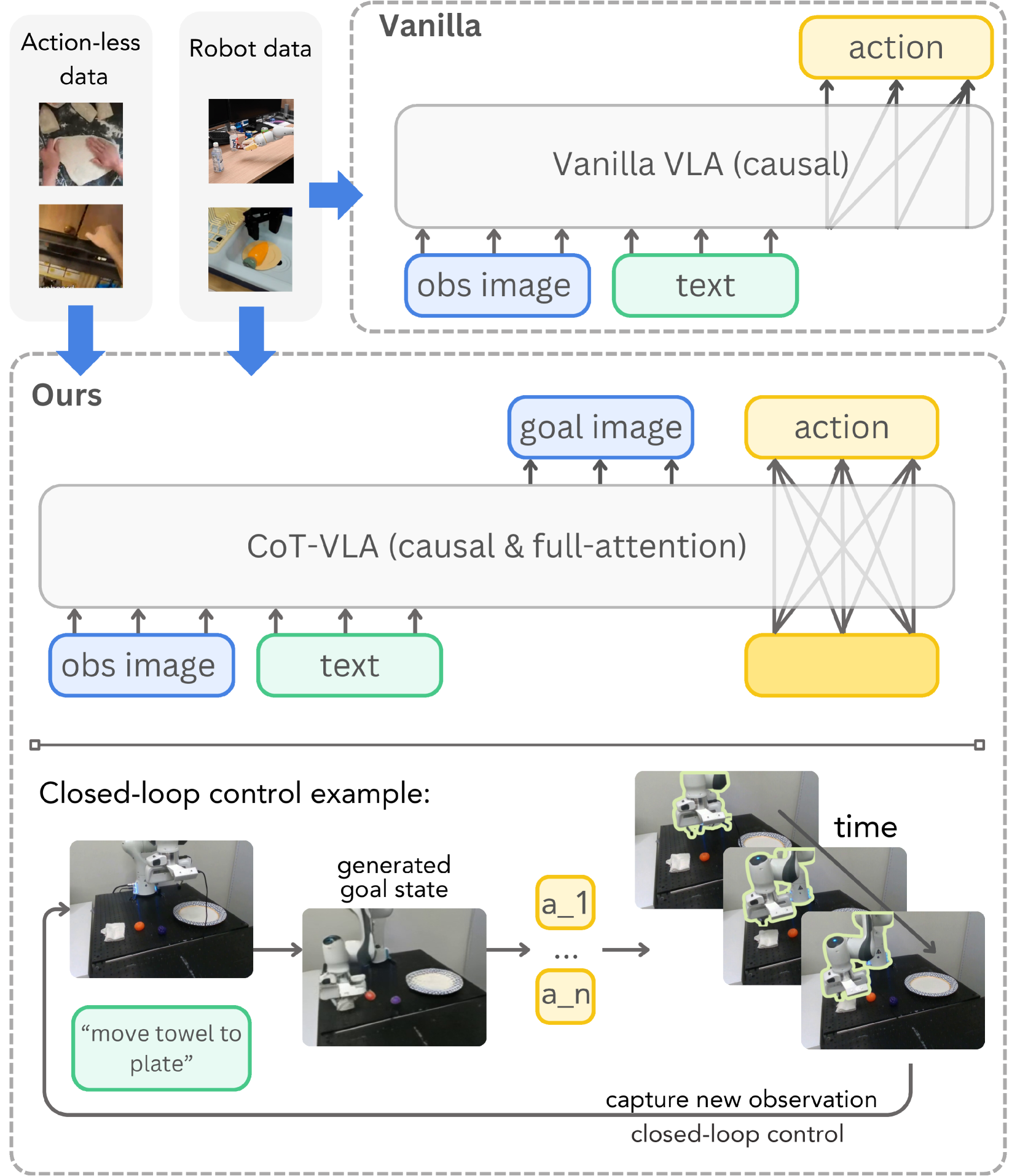
4.2 Vanilla VLA 与 CoT-VLA 的核心差别
Vanilla VLA 直接回答:“当前图像和指令给定时,现在该做什么动作?”
$$\hat{\mathbf{a}}_t \sim P_\theta(\mathbf{a}_t \mid \mathbf{s}_t,l)$$这里没有显式中间状态。若模型误解任务目标,错误会直接进入动作。
CoT-VLA 先回答:“任务成功时,未来图像应当是什么样?”再回答:“为了到达这个图像状态,接下来一小段动作是什么?”
$$\hat{\mathbf{s}}_{t+n} \sim P_\theta(\mathbf{s}_{t+n}\mid \mathbf{s}_t,l)$$ $$\{\hat{\mathbf{a}}_t,\ldots,\hat{\mathbf{a}}_{t+m}\}\sim P_\theta(\{\mathbf{a}_t,\ldots,\mathbf{a}_{t+m}\}\mid \mathbf{s}_t,l,\hat{\mathbf{s}}_{t+n})$$| $\hat{\mathbf{s}}_{t+n}$ | 模型生成的未来子目标图像,论文把它称为 visual CoT reasoning 的中间步骤。 |
| $n$ | 子目标预测 horizon;预训练时按数据集从指定区间采样 补充材料 6.1。 |
| $m$ | 动作 chunk 长度;论文使用 action chunk size 10。 |
| $D_r,D_v$ | $D_r$ 同时支持视觉和动作训练;$D_v$ 只支持视觉子目标训练。 |
4.3 基座模型 VILA-U
CoT-VLA 建在 VILA-U 上。VILA-U 是一个统一多模态生成模型,能够理解和生成文本、图像、视频 token。论文使用的 VILA-U 图像分辨率为 $256\times256$,每张图像被编码成 $16\times16\times4$ 个离散视觉 token,其中 residual depth 为 4。
这个选择很关键:如果基座 VLM 只能理解图像而不能生成图像,就难以直接把未来图像作为 CoT token 生成出来。CoT-VLA 因此优化 LLM backbone、projector 和 depth transformer,但保持 vision tower frozen。
4.4 Hybrid Attention

论文将 attention 设计与输出类型绑定:
- 视觉和文本生成:使用 causal attention,符合自回归 next-token prediction。
- 动作生成:使用 full attention,允许动作 token 之间相互看到彼此;作者认为这有助于并行预测整段动作,而不是像语言一样严格单向展开。
4.5 训练目标
视觉损失训练模型把未来图像拆成离散 residual token 后逐层预测。
$$\mathcal{L}_{\text{visual}}=-\sum_j\sum_{d=1}^{D}\log P_\delta(k_{jd}\mid k_{j,动作损失训练模型在给定当前图像、语言和子目标图像时,生成长度为 $m$ 的动作 chunk。
$$\mathcal{L}_{\text{action}}=-\sum_{i=1}^{m}\log P_\theta(\mathbf{a}_t...\mathbf{a}_{t+m}\mid l,s_t,s_{t+n})$$ $$\mathcal{L}=\mathcal{L}_{\text{action}}+\mathcal{L}_{\text{visual}}$$论文没有引入额外权重系数,最终目标就是视觉 token 预测和动作 token 预测的交叉熵之和。
4.6 两阶段训练与闭环部署
预训练阶段:CoT-VLA 在 Open X-Embodiment 子集和 action-less video 数据上训练。机器人数据遵循 OpenVLA pipeline,只保留第三人称视角和单臂 end-effector control 的 7-DoF 数据;视频数据使用 EPIC-KITCHENS-100 和 Something-Something V2。所有图像处理到 $256\times256$。
下游适配阶段:在目标机器人 setup 的 task-specific demonstrations 上微调 LLM backbone、projector 和 depth transformer,vision tower 仍保持 frozen。
闭环的含义是:模型执行一段动作后重新拍摄当前观测,再生成下一张子目标图像和下一段动作,而不是一次性生成完整轨迹。
5. 实验与结果
5.1 实验设置
| Benchmark / 平台 | 设置 | 评估重点 |
|---|---|---|
| LIBERO | 四个 suites:Spatial、Object、Goal、Long;每个 suite 10 个任务,每任务 50 条 human teleoperation demos。 | 仿真中空间关系、物体交互、目标理解和长程任务。 |
| Bridge-V2 | 6-DoF WidowX;45k language-annotated trajectories;在 Bridge-V2 上继续 task-specific fine-tuning,直到训练 action prediction accuracy 达到 95%。 | visual、motion、semantic、language grounding 四类泛化。 |
| Franka-Tabletop | 7-DoF Franka Emika Panda;预训练未见过该 setup;每个 testing scenario 只有 10 到 150 条 demonstrations。 | 少量数据适配、single-instruction 与 multi-instruction 任务。 |
基线包括 Diffusion Policy、OpenVLA、Octo 和 SUSIE。Diffusion Policy 在 LIBERO 和 Franka-Tabletop 上从头训练;OpenVLA 和 Octo 在 Bridge-V2 用 published checkpoints,在 LIBERO/Franka 上 fine-tune;SUSIE 在 Bridge-V2 使用 published checkpoint。
5.2 LIBERO 主结果
| 方法 | Average | Spatial | Object | Goal | Long |
|---|---|---|---|---|---|
| Diffusion Policy | 72.4 ± 0.7% | 78.3 ± 1.1% | 92.5 ± 0.7% | 68.3 ± 1.2% | 50.5 ± 1.3% |
| Octo fine-tuned | 75.1 ± 0.6% | 78.9 ± 1.0% | 85.7 ± 0.9% | 84.6 ± 0.9% | 51.1 ± 1.3% |
| OpenVLA fine-tuned | 76.5 ± 0.6% | 84.7 ± 0.9% | 88.4 ± 0.8% | 79.2 ± 1.0% | 53.7 ± 1.3% |
| CoT-VLA-7B | 81.13 ± 0.6% | 87.5 ± 1.4% | 91.6 ± 0.5% | 87.6 ± 0.6% | 69.0 ± 0.8% |
CoT-VLA 在平均成功率、Spatial、Goal、Long 上最高;Object suite 中 Diffusion Policy 最高,CoT-VLA 排第二。论文特别解释了 LIBERO-Spatial 的 failure 分析:一些 baseline 会在视觉初始状态相似时忽略语言指令,执行另一个任务;CoT-VLA 通过语言条件下的子目标图像先明确目标状态,因此表现出更好的 instruction following。
5.3 Bridge-V2 结果
| Category | SUSIE | Octo | OpenVLA | CoT-VLA |
|---|---|---|---|---|
| Visual | 30% | 35% | 75% | 65% |
| Motion | 10% | 10% | 45% | 60% |
| Semantic | 20% | 0% | 40% | 50% |
| Language | 40% | 40% | 75% | 70% |
Bridge-V2 每类任务 10 trials。CoT-VLA 在 motion 和 semantic 上最好,在 visual 和 language 上略低于 OpenVLA。论文把 visual 和 language 类别中的差距归因于 action chunking 带来的 grasping failures,而不是视觉推理本身错误;SUSIE 虽能生成更高质量目标图像,但在 novel objects 或复杂 language grounding 场景中成功率更低。
5.4 Franka-Tabletop 结果
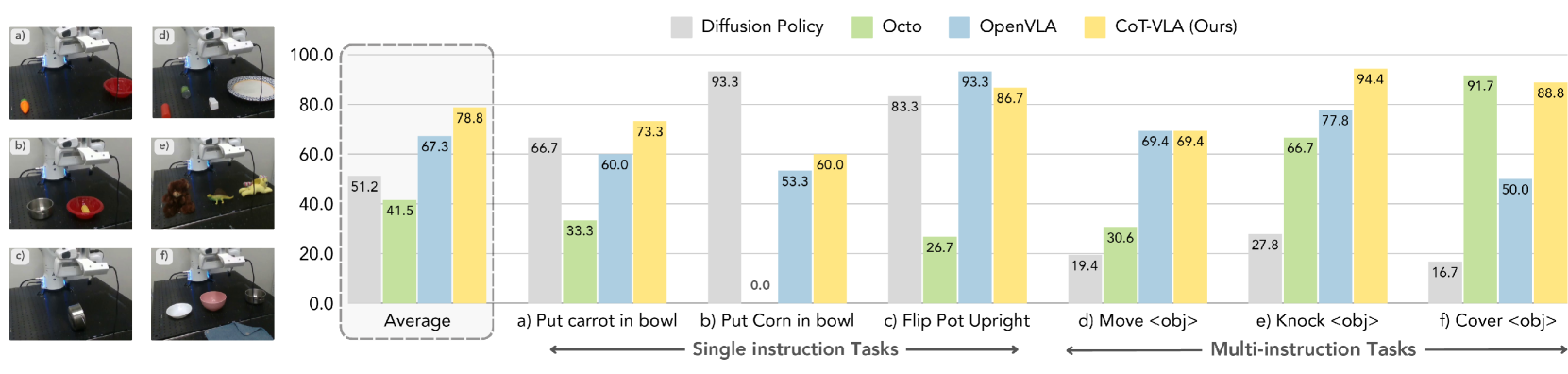
Franka-Tabletop 是预训练未见过的新机器人环境,且每个任务只有 10 到 150 条 demonstrations。论文观察到 Diffusion Policy 在一些 single-instruction task 上很强,但在涉及多物体、复杂语言的 multi-instruction task 上下降;OpenX 预训练的 Octo、OpenVLA、CoT-VLA 在多指令任务中适配更好。CoT-VLA 在作者报告的跨任务平均上最高。
5.5 消融实验
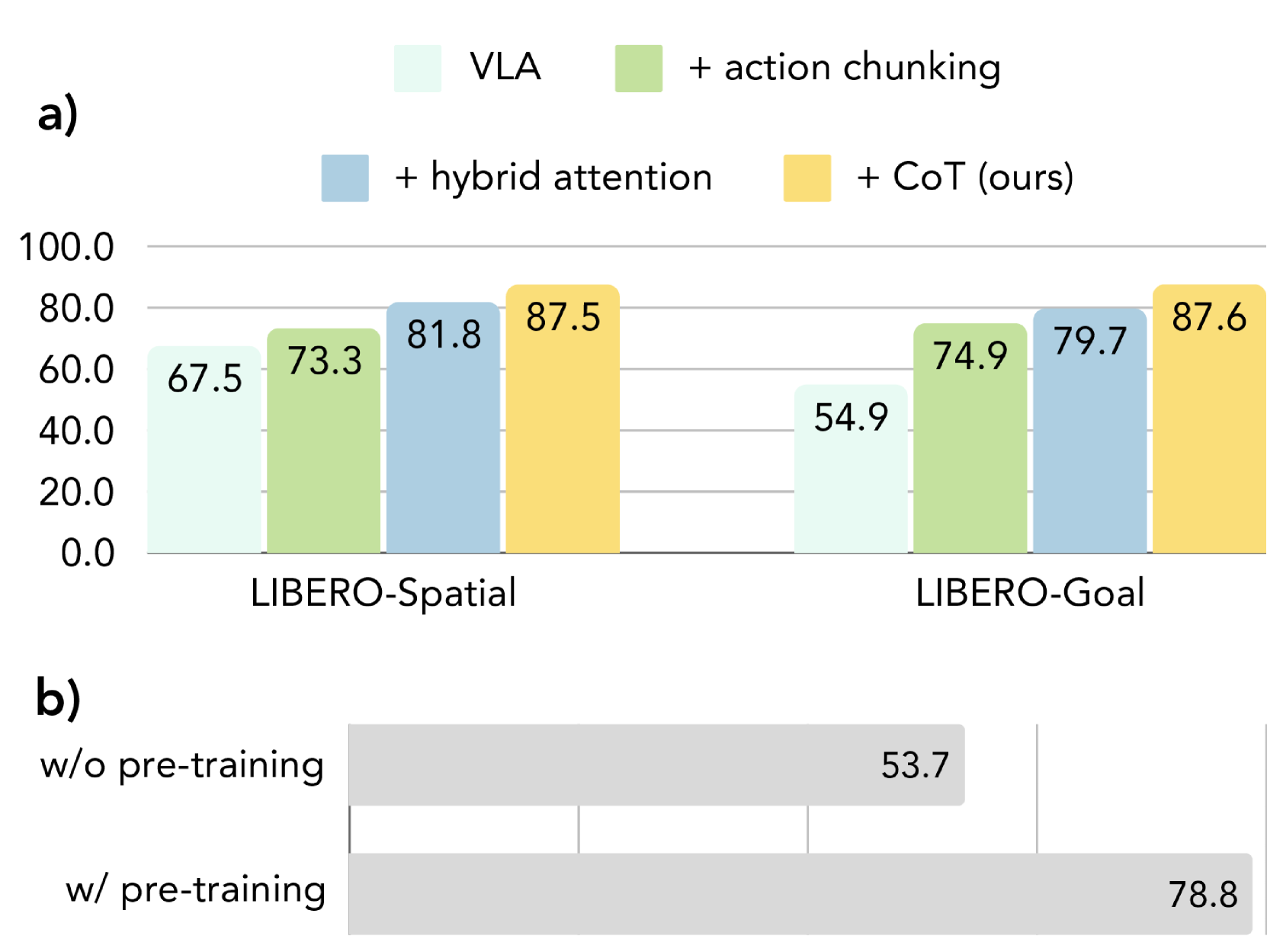
作者在 LIBERO-Spatial 和 LIBERO-Goal 上逐步加入组件:
- VLA:同样的 VILA-U backbone,但没有 CoT reasoning 和 action chunking。
- + action chunking:从单步动作扩展为长度 $m$ 的动作序列。
- + hybrid attention:给动作序列预测加入 full attention。
- + CoT:完整 CoT-VLA,引入视觉子目标图像。
论文给出的结论是:action chunking 和 hybrid attention 都有增益,完整 visual CoT 版本最好。预训练消融显示,在 Franka-Tabletop 上,带预训练的 CoT-VLA 从直接微调 base VILA-U 的 53.7% 提升到 78.8%,相对提升 46.7%。
5.6 Better Visual Reasoning Helps
| 条件 | Sub-task 1 | Sub-task 2 |
|---|---|---|
| Generated Goal Images | 20% | 0% |
| Ground-truth Goal Images | 60% | 40% |
作者设计了两个 out-of-distribution 长程任务,并为每个任务收集一条 demonstration 来获得 ground-truth goal images。与使用模型生成 goal images 相比,使用 ground-truth goal images 在两个任务上都带来 40% 绝对成功率提升。论文用这个实验说明:当视觉推理/子目标生成更好时,动作执行成功率也会随之提高;同时也承认当前模型对新任务的子目标生成仍存在困难。

6. 复现审计
6.1 数据与采样 horizon
补充材料给出了预训练数据 mixture 权重和子目标 horizon 的上下界。这里的 $u_l,u_u$ 对应论文正文中的 $n_l,n_u$,即从哪个未来时间范围采样子目标图像。补充材料 6.1
| Dataset | Weight | $u_l$ | $u_u$ |
|---|---|---|---|
| Bridge | 24.14% | 5 | 10 |
| RT-1 | 6.90% | 5 | 10 |
| TOTO | 10.34% | 20 | 24 |
| VIOLA | 10.34% | 15 | 20 |
| RoboTurk | 10.34% | 1 | 2 |
| Jaco Play | 10.34% | 10 | 15 |
| Berkeley Autolab UR5 | 10.34% | 5 | 10 |
| Berkeley Fanuc Manipulation | 10.34% | 10 | 15 |
| Something-Something V2 | 3.45% | 5 | 7 |
| EPIC-KITCHEN-100 | 3.45% | 5 | 7 |
6.2 训练超参数与算力
| Hyperparameter | Pre-training |
|---|---|
| Learning Rate | 1e-4 |
| LR Scheduler | Cosine decay |
| Global Batch Size | 2048 |
| Image Resolution | 256 × 256 |
| Action Token Size / Chunk Size | 10 |
| Epoch | 10 |
fine-tuning 设置:LIBERO 和 Franka-Tabletop 使用 constant learning rate 1e-5,训练 150 epochs。训练资源:预训练使用 12 个 A100 GPU nodes,每个 node 8 张 GPU,总计约 11K A100 GPU hours;LIBERO 和 Franka-Tabletop fine-tuning 在单个 A100 node 上训练 10 到 24 小时,取决于数据集大小。补充材料 6.2-6.3
6.3 复现 checklist
可直接从论文获得的信息
充分:模型总体 pipeline、核心公式、动作离散化规则、action chunk size、数据 mixture 权重、子目标 horizon、主要训练超参、主要 benchmark 设置、baseline 名称与部分训练/使用方式。
需要补充:完整代码仓库在 arXiv 页面和项目主页中未见显式 GitHub 链接;VILA-U 具体 checkpoint、OpenX 子集筛选脚本、Bridge-V2 fine-tuning 到 95% action prediction accuracy 的精确停止细节、robot deployment controller 低层接口未在正文中完全展开。
复现最小路径
- 准备 VILA-U 7B 生成式多模态 checkpoint,保持 vision tower frozen。
- 按 OpenVLA pipeline 处理 OpenX 第三人称、单臂 7-DoF 数据,并按补充材料权重混合 Bridge、RT-1、TOTO、VIOLA、RoboTurk、Jaco Play、Berkeley Autolab UR5、Berkeley Fanuc。
- 加入 Something-Something V2 和 EPIC-KITCHENS-100,按各数据集 horizon 区间采样未来子目标图像。
- 训练视觉 token loss 和 action token loss;动作维度按第 1 到第 99 百分位区间离散到 256 bins。
- 在 LIBERO、Bridge-V2 或 Franka-Tabletop 上 task-specific fine-tuning,并在 closed-loop 中每次生成子目标图像和长度 10 的动作 chunk。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
从论文自身实验和设计看,最关键的价值在于把“机器人策略的中间推理”具体落到未来图像 token 上,而不是额外人工定义的语言计划、关键点或 bounding boxes。这个选择让中间表示既可视化,又能从普通视频中学习。消融实验也把收益拆开验证:action chunking、hybrid attention、visual CoT 和预训练都不是孤立装饰,而是共同支撑最终结果的组件。
7.2 结果为什么站得住
论文的结果支撑来自三层证据:第一,LIBERO 表格给出多 suite 的定量比较,并且 CoT-VLA 在平均、Spatial、Goal、Long 上领先;第二,Bridge-V2 和 Franka-Tabletop 覆盖真实机器人和不同 embodiment,而不只是在一个仿真环境中报告;第三,消融实验逐步加入 action chunking、full attention、visual CoT,并单独验证预训练对 Franka-Tabletop 的提升。Better Visual Reasoning Helps 实验进一步说明,当子目标图像由 ground truth 替换时,执行成功率上升,支持“视觉推理质量影响动作表现”这一机制解释。
7.3 作者自述局限
- 推理开销:生成中间图像 token 比直接动作生成慢。论文称每次需要生成 256 个图像 token,在 action chunk size 为 10 时平均带来约 $7\times$ slowdown。
- 图像质量:自回归图像生成质量低于 state-of-the-art diffusion-based models。Bridge-V2 讨论中也提到 SUSIE 的 diffusion prior 可生成视觉质量更高的目标图像。
- Action chunking 的控制问题:动作 chunk 之间可能不连续,并且执行 chunk 时缺少高频反馈;论文认为这会造成部分 grasping failures。
- 新任务视觉泛化有限:虽然预训练利用 action-less video data,但作者承认当前计算约束限制了模型对全新任务的 visual-reasoning generalization。
7.4 适用边界
CoT-VLA 更适合那些“子目标图像能清楚表达任务进展”的 manipulation 任务,例如移动、放置、覆盖、翻转或取出物体。若任务成功状态主要由不可见力、触觉、内部状态或长期接触动力学决定,单张未来图像作为中间 CoT 的信息可能不足。
此外,closed-loop action chunking 的频率和 chunk 长度会影响部署稳定性:chunk 过长会降低反馈频率,chunk 过短会增加推理开销。论文当前使用长度 10,并明确指出 image generation 是主要速度瓶颈。