Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
1. Quick overview of the paper
| Reading targeting item | compact conclusion |
|---|---|
| What should the paper solve? | Large-scale imitation learning relies on high-quality action demonstrations, while large amounts of video data do not have action annotation; traditional policies do not explicitly learn environment dynamics. |
| The author's approach | Couple action diffusion and video diffusion into the same transformer, but let $t_a$ and $t_{o'}$ independently sample/control; $t=T$ is approximate to "mask/marginalize", and $t=0$ is approximate to "condition". |
| most important results | In the five real robot tasks, UWM is better than DP, PAD, and GR1 in ID/OOD, and action-free DROID video cotraining is further improved; LIBERO's average success rate is 0.79, which is higher than DP 0.71, PAD 0.57, and GR1 0.58. |
| Things to note when reading | UWM is not discrete token diffusion, but continuous latent image/action diffusion; the core innovation is the condition/marginalization control and action-free video training brought by independent modality timestep. |
Difficulty rating: ★★★★☆. Requires understanding of DDPM, conditional diffusion, Diffusion Policy, world model, inverse dynamics, latent diffusion and robotic pre-training/fine-tuning experimental protocols.
Keywords: Unified World ModelAction DiffusionVideo DiffusionIndependent TimestepsAction-Free Videos
Core contribution list
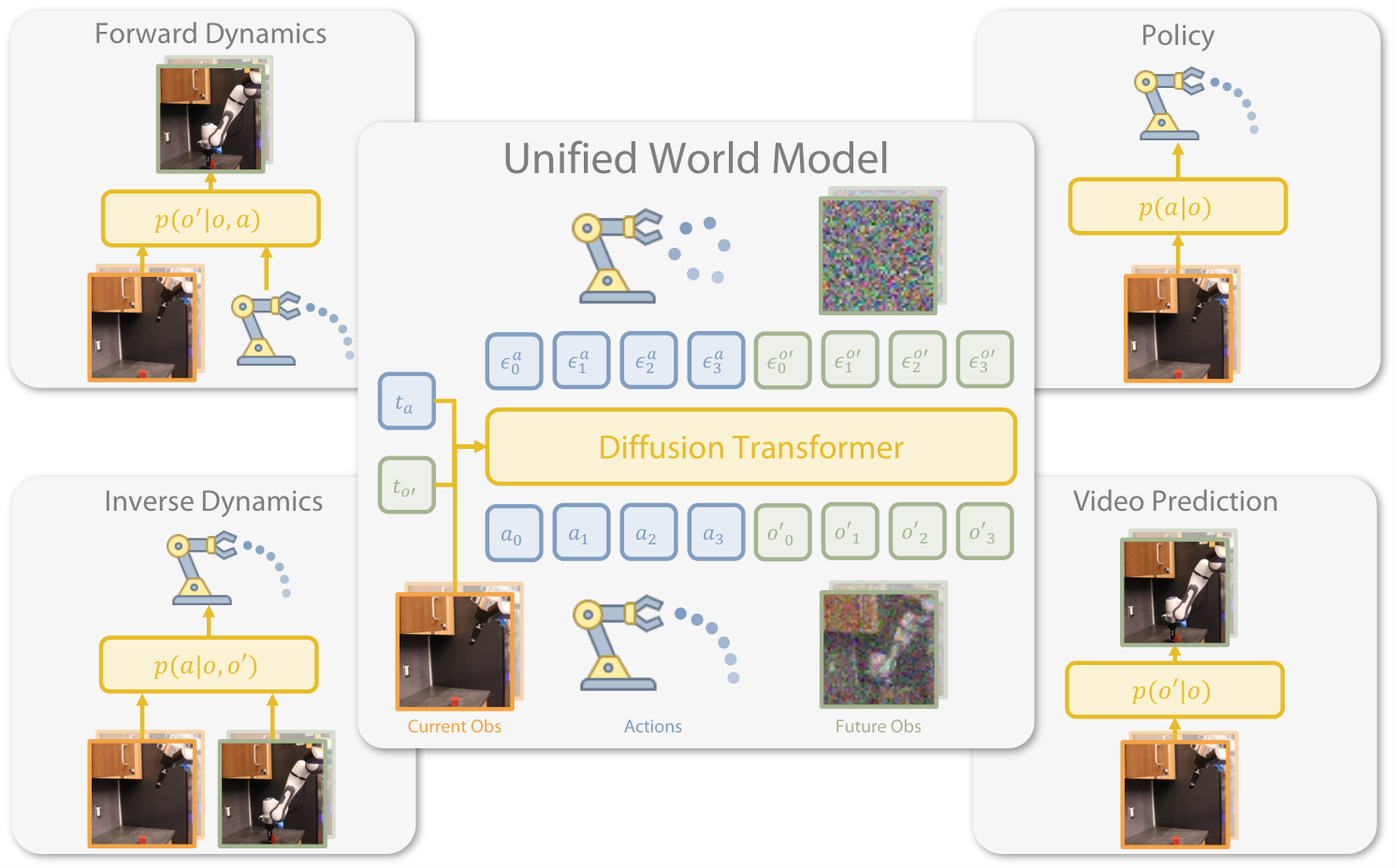
- Unify policy and world modeling.UWM uses a model to cover $p(a|o)$, $p(o'|o, a)$, $p(a|o, o')$, and $p(o'|o)$ to connect the paradigms of imitation learning and world model.
- Independent diffusion timesteps.Different from PAD's shared timestep, UWM independently samples/sets $t_a$ and $t_{o'}$ to achieve conditioning or marginalization of variables.
- Take advantage of action-free video.For the non-action video $t_a=T$, use Gaussian noise to compensate for the action, and still use the same training objective so that the video data can enter policy pretraining.
- Real and simulated verification.The authors validate the design on five real-world tasks of DROID setup, LIBERO OOD task, forward/inverse dynamics, OOD classification evaluation, from-scratch vs pretraining and Internet video cotraining.
2. Motivation
2.1 Problems to be solved
Behavioral cloning and Diffusion Policy have demonstrated that reliable manipulation policies can be learned as long as they are demonstrated by high-quality experts. But robot data collection is expensive, and policies usually only learn the mapping from observations to actions, without explicitly modeling "how actions will change future observations." On the other hand, world models and video models can learn dynamics, but videos often do not have action labels, making it difficult to directly use them to train policy.
2.2 Limitations of existing methods
- General imitation learning: Relying on action-labeled expert demonstrations, it is difficult to use action-free videos; it is easily fragile under OOD conditions.
- Separate world model: It is possible to predict future images, but how this translates into better action policies is not straightforward.
- PAD class joint video-action diffusion: Sharing the same timestep to generate action and video can only be sampled from joint distribution and lacks flexible marginal/conditional inference.
2.3 Solution ideas of this article
The author's key insight is to treat diffusion timestep as a continuous version of masking: the closer $t$ is to $T$, the closer the variable appears to be completely masked; the closer $t$ is to $0$, the closer the variable is to clean input. Therefore, as long as action and future observation are given independent timesteps, a certain variable can be "masked" for marginalization during reasoning, or fixed to a clean value for conditioning.
4. Detailed explanation of method
4.1 Problem setting
There are two types of data: expert data with motion $\mathcal{D}_e=\{(o_i, a_i, o'_i)\}_{i=1}^N$, and video data without motion $\mathcal{D}_{af}=\{(o_i, o_{i+1})\}_{i=1}^M$. The model expects four distributions from the same set of mechanisms:
| mode | Distribution | Purpose |
|---|---|---|
| Policy | $p(a|o)$ | Given the current observation, sample the action to perform. |
| Forward dynamics | $p(o'|o, a)$ | Given an action, predict the next observation. |
| Inverse dynamics | $p(a|o, o')$ | Given the next observation of a target, infer how to reach it. |
| Video prediction | $p(o'|o)$ | Predict future observations without specifying actions. |
4.2 Coupled Video-Action Diffusion
UWM's score/noise prediction network inputs the current observation $o$, the noisy action $a_{t_a}$, the next noisy observation $o'_{t_{o'}}$, the action timestep $t_a$ and the next observation timestep $t_{o'}$, and outputs two noise predictions $\epsilon_a^\theta, \epsilon_{o'}^\theta$.
During training, the model is allowed to see all noise combinations of action and future observation, so it can both "predict actions by looking at pictures" and "predict future images by looking at actions", and can also share information when both are noisy.
$$\ell(\theta)= \mathbb{E}\left[ w_a\|\epsilon_a^\theta-\epsilon_a\|_2^2+ w_{o'}\|\epsilon_{o'}^\theta-\epsilon_{o'}\|_2^2 \right]$$ $$\epsilon_a^\theta, \epsilon_{o'}^\theta=s_\theta(o, a_{t_a}, o'_{t_{o'}}, t_a, t_{o'})$$| $a_{t_a}$ | The noised version of the action chunk, $a_{t_a}=\sqrt{\bar\alpha_{t_a}}a+\sqrt{1-\bar\alpha_{t_a}}\epsilon_a$. |
| $o'_{t_{o'}}$ | The latent noisy version of the next observation, $o'_{t_{o'}}=\sqrt{\bar\alpha_{t_{o'}}}o'+\sqrt{1-\bar\alpha_{t_{o'}}}\epsilon_{o'}$. |
| $w_a, w_{o'}$ | The weight of action loss and image loss; both are 1.0 in the appendix hyperparameter table. |
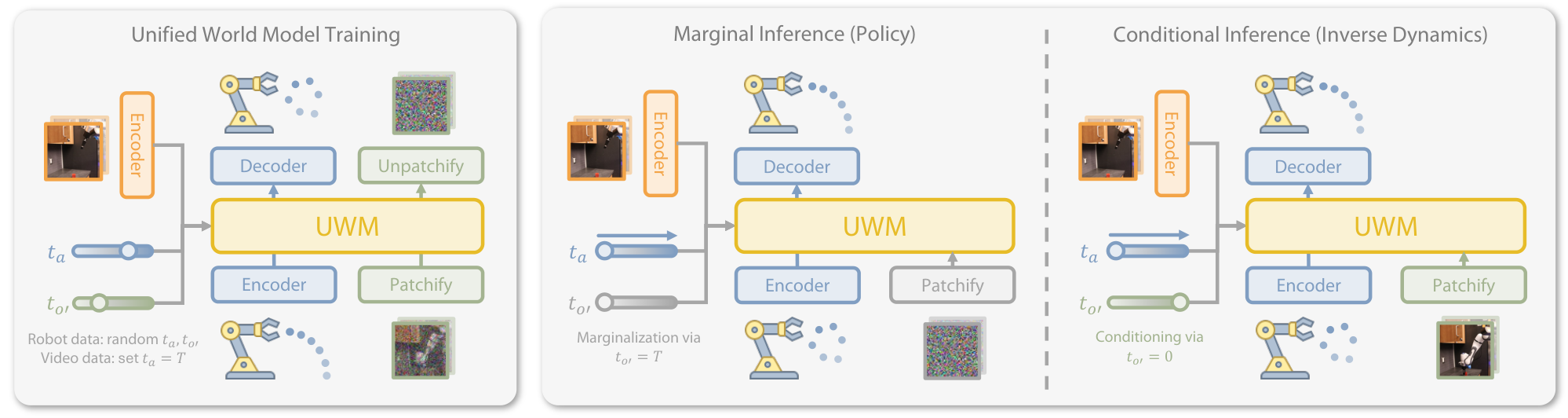
4.3 Four reasoning modes
| reasoning mode | timestep settings | meaning |
|---|---|---|
| Policy $p(a|o)$ | $t_{o'}=T$, $o'_T\sim\mathcal{N}(0, I)$; reverse diffusion to $a$. | Marginalize future observations and only generate actions. |
| Video prediction $p(o'|o)$ | $t_a=T$, $a_T\sim\mathcal{N}(0, I)$; reverse diffusion to $o'$. | Marginalize actions and only predict future videos. |
| Forward dynamics $p(o'|o, a)$ | $t_a=0$, $a_0=a$; reverse diffusion to $o'$. | Use actions as clean conditions to predict the next observation. |
| Inverse dynamics $p(a|o, o')$ | $t_{o'}=0$, $o'_0=o'$; reverse diffusion to $a$. | Use the next observation of the target as a clean condition to generate actions. |
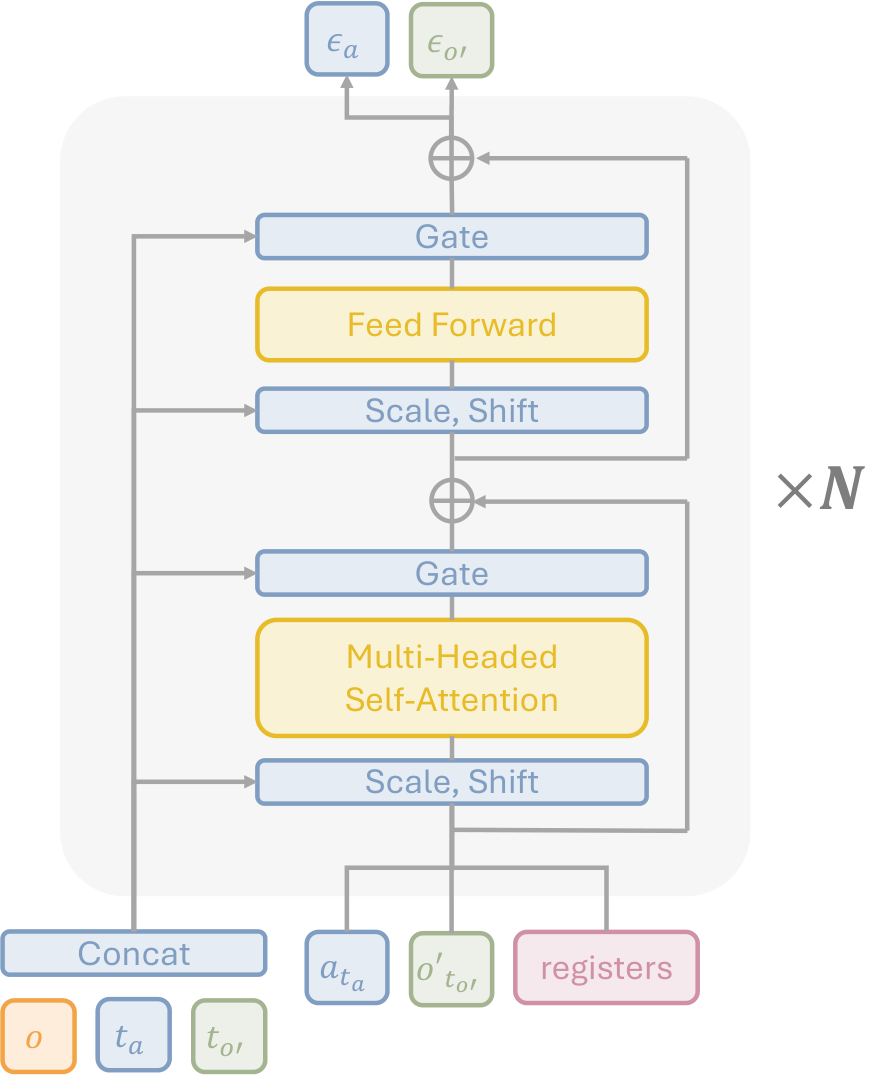
4.4 Architecture
UWM uses diffusion transformer + AdaLN conditioning. The current observation is encoded by ResNet-18; $t_a, t_{o'}$ is encoded with sinusoidal timestep encoder; image diffusion uses latent diffusion. The original $224\times224\times3$ image is encoded into $28\times28\times4$ latent by frozen SDXL VAE, and then cut into patch embeddings using the $(4, 4, 2)$ spatiotemporal patchifier. Each step of the action chunk is encoded with shallow MLP, concatenated with image patch embeddings and learnable register tokens and then input into the transformer.

4.5 Training and implementation details
Appendix Implementation Key hyperparameters are given: observation length $h_o=2$, action length $h_a=16$, rollout length $h'_a=8$, embedded dim 768, 12-layer transformer, 12 heads, 8 registers; training diffusion steps 100, inference steps 10, DDIM sampler; batch size is 36×4 pretraining, 36×2 finetuning; AdamW, learning rate $10^{-4}$, weight decay $10^{-6}$.
Training 100K steps DROID pretraining uses 4 NVIDIA A100s, about 24 hours. When deploying, execute the replan after predicting the first $h'_a=8$ actions.
5. Experiments and results
5.1 Experimental setup
Real robotic experiments using Franka Panda and DROID manipulation platform. The observation includes two scene cameras and a wrist camera, plus an overhead evaluation camera for alignment initialization; the control frequency is 10 Hz; the action space is delta end-effector pose plus continuous gripper state.


The five real tasks are Stack-Bowls, Block-Cabinet, Paper-Towel, Hang-Towel, and Rice-Cooker. The first four tasks evaluate 50 initializations, while Rice-Cooker only evaluates 20 initializations close to the data distribution due to its high difficulty; each initialization gives each method 3 attempts.

5.2 Real Robot Results
| Task | UWM Pretrain / Cotrain | Overview of best baseline performance |
|---|---|---|
| Stack-Bowls ID / OOD | 0.86 / 0.92; 0.76 / 0.84 | GR1 pretrain 0.66/0.48; DP 0.48/0.36; PAD is very low. |
| Block-Cabinet ID / OOD | 0.76 / 0.84; 0.60 / 0.72 | GR1 cotrain 0.74/0.64 closest; DP OOD 0.26. |
| Paper-Towel ID / OOD | 0.78 / 0.86; 0.78 / 0.84 | GR1 pretrain 0.60/0.60; DP 0.52/0.48. |
| Hang-Towel ID / OOD | 0.82 / 0.86; 0.64 / 0.76 | GR1 0.66/0.48; DP 0.64/0.28. |
| Rice-Cooker ID | 0.60 / 0.65 | GR1 pretrain 0.40, cotrain 0.25; DP 0.35; PAD 0. |
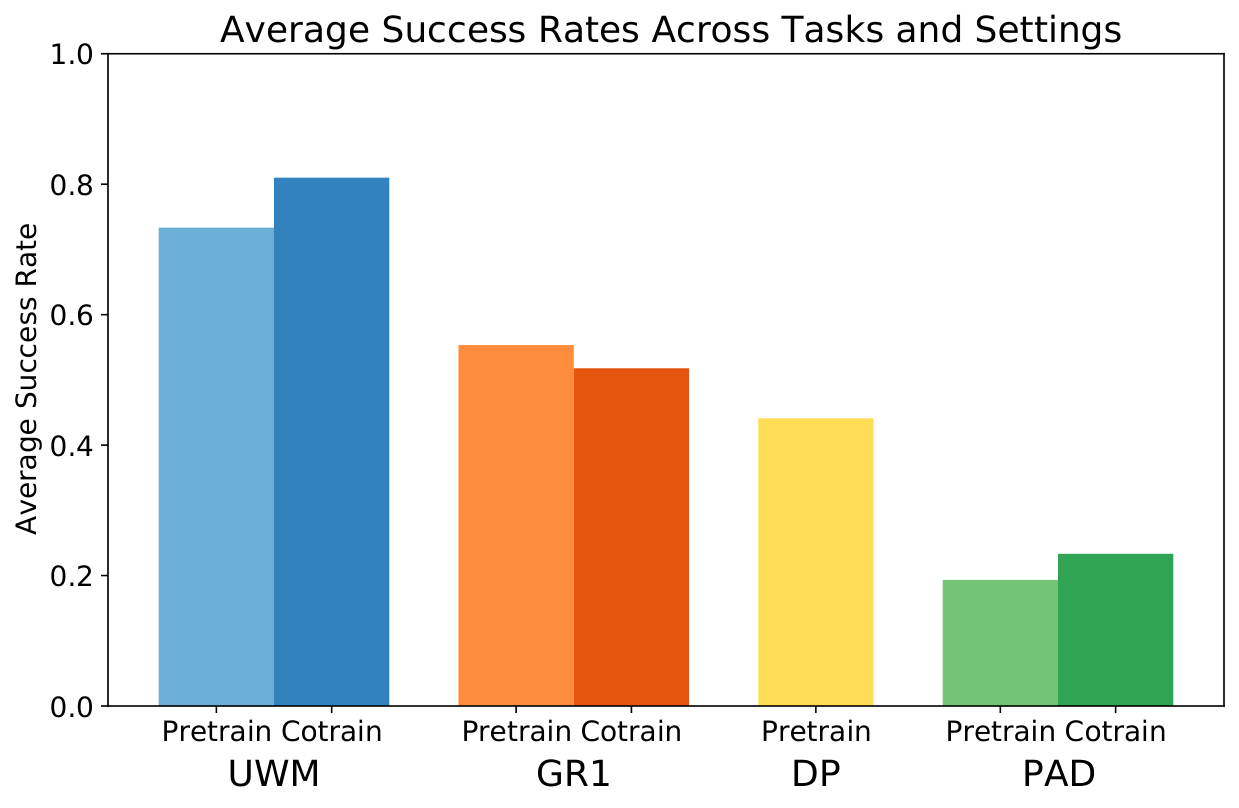
The paper explains the real results as follows: UWM learns the causal relationship between actions and image observations through action/video feature sharing and training of different conditional/marginal distributions. GR1 is a strong regression baseline, but video cotraining sometimes dilutes the action learning signal; the poor performance of PAD is attributed by the author to raw-pixel concatenation conditioning which is difficult under the same model capacity.
5.3 LIBERO Simulation
The simulation experiment uses 4500 trajectories of LIBERO-100 and LIBERO-90 for pre-training. Five tasks in LIBERO-10 are randomly selected for evaluation, and each task is fine-tuned with 50 expert demos. The author expanded the object initialization range to 0.03 and removed the background objects to create OOD.

| method | Book-Caddy | Soup-Cheese | Bowl-Drawer | Moka-Moka | Mug-Mug | Average |
|---|---|---|---|---|---|---|
| UWM | 0.91 ± 0.07 | 0.93 ± 0.01 | 0.80 ± 0.02 | 0.68 ± 0.02 | 0.65 ± 0.01 | 0.79 ± 0.11 |
| DP | 0.73 ± 0.10 | 0.88 ± 0.02 | 0.77 ± 0.02 | 0.65 ± 0.03 | 0.53 ± 0.05 | 0.71 ± 0.12 |
| PAD | 0.78 ± 0.04 | 0.47 ± 0.04 | 0.74 ± 0.05 | 0.59 ± 0.08 | 0.25 ± 0.04 | 0.57 ± 0.19 |
| GR1 | 0.77 ± 0.03 | 0.65 ± 0.05 | 0.62 ± 0.03 | 0.46 ± 0.04 | 0.38 ± 0.05 | 0.58 ± 0.14 |
5.4 Analysis and Ablations
| experiment | settings | Results/Conclusion |
|---|---|---|
| Forward dynamics | Fixed $t_a=0$, uses ground-truth actions, diffuse future observations. | The visualization shows that predicted next obs is close to true next obs, indicating that conditional dynamic modeling is effective. |
| Inverse dynamics tracking | Given expert future observations, action tracking trajectories are generated using inverse dynamics. | Under the limitation of trajectory length, Book-Caddy policy 0.47 vs inverse 0.65; Soup-Cheese policy 0.26 vs inverse 0.55. |
| Categorized OOD | Stack-Bowls / Block-Cabinet lighting, background, clutter. | Stack-Bowls: UWM cotrain 21/30, pre 15/30, DP 12/30; Block-Cabinet: 15/30, 8/30, 6/30. |
| Registers | 8 registers / 4 registers / no registers / cross-attention UWM. | Book-Caddy 0.88 / 0.83 / 0.81 / 0.78; Soup-Cheese 0.90 / 0.86 / 0.85 / 0.86. |
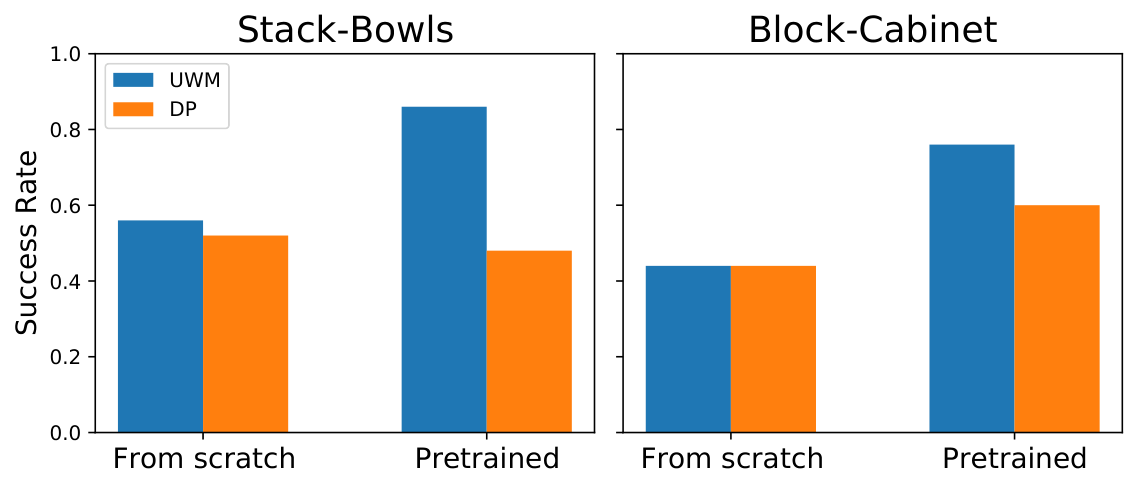
| Learning objective | future obs reconstruction vs current obs reconstruction vs no reconstruction. | Stack-Bowls 0.86/0.70/0.48; Block-Cabinet 0.76/0.66/0.60, proving that dynamic prediction is more useful than pure current image reconstruction. |
| Internet videos | robot data + robot videos / robot data + Internet videos / robot data only. | Stack-Bowls 0.92/0.88/0.86; Block-Cabinet 0.84/0.80/0.76. Internet videos have improved, but not as much as in-domain robot videos. |



6. Analysis and discussion within the paper
6.1 Core explanation given by the author
- Additional supervision comes from the same data.UWM not only learns actions from demonstrations, but also predicts future observations, thus obtaining more dynamic supervision from the same trajectory.
- Independent timesteps allow the model to learn causal relationships.$t_a, t_{o'}$ is randomly combined during training. The model needs to recover actions and future observations under different noise/occlusion conditions, so it is exposed to different marginal/conditional distributions.
- A natural entry into video cotraining.For non-action videos, the action timestep only needs to be fixed to $T$, and no additional architecture or special pseudo-action annotation is required.
- The real-world improvement over simulation is even more obvious.The authors believe that current simulation dynamics are simpler and therefore the OOD improvement is smaller than in the real world.
6.2 Failure modes
Appendix Real-World Failure Modes Point out: Multiple cameras may still have difficult viewing angles where certain objects are only seen by one camera; the behavior of the object itself can also cause failure. For example, the Paper-Towel will fall over after being placed on the wooden platform at a bad angle, and the baseline in Stack-Bowls will confuse the blue bowl with distractors after picking up the pink bowl.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
The most valuable thing is to combine "learning dynamics with videos" and "learning actions with demonstrations" into a controllable continuous diffusion probability model, rather than adding an independent video predictor. Through independent $t_a, t_{o'}$, UWM allows policy, forward dynamics, inverse dynamics, and video prediction to be different inference slices of the same training target. This directly explains why action-free video can enter training: the missing action is a complete noise variable of $t_a=T$ in a diffusion sense.
7.2 Why the results hold up
The evidence chain is relatively complete: real robot tasks cover rigid bodies, deformable objects and long-term tasks; each task has ID/OOD; DROID robot video cotraining and Internet video cotraining are independently verified; LIBERO provides a standard simulation benchmark; forward/inverse dynamics shows that UWM does not only improve policy scores, but can indeed work in different inference modes. Ablation further demonstrates that future obs reconstruction, registers, and AdaLN conditioning all contribute quantitatively.
7.3 Author's statement of limitations
- Human video at scale has not really been exploited yet.The authors explicitly state that the embodiment gap has not been resolved; the Internet videos experiments are only preliminary validation of the Kinetics-400/SSV2 hybrid.
- Forward dynamics reconstruction has artifacts.The author believes that these artifacts may reduce the effectiveness of using models for planning, and new advances in the field of generative models need to be absorbed.
- Dense video prediction is needed.The paper predicts that denser video prediction may further improve performance.
- The real mission is still a controlled platform.DROID setup, Franka Panda, 5 tasks and a limited number of demos support the conclusion, but do not mean that large-scale generalization across embodiments has been proven.
7.4 Applicable boundaries
UWM is suitable for scenarios where you have action-labeled robot trajectories and want to take advantage of additional action-free robot/video data at the same time. It assumes that observation/action/future observations can be modeled by continuous diffusion, and that future images can serve as useful dynamic supervision. The paper does not yet provide sufficient evidence for long-term planning, multi-robot shape transfer, high-precision contact force control, or long-span transfer of human video to robot actions.
8. Reproducibility Audit
| recurring elements | Information given in the paper/project | Audit status |
|---|---|---|
| code | Project page provides official GitHub: WEIRDLabUW/unified-world-model. | Found |
| Source code and diagrams | arXiv provides LaTeX source code and 14 independent PDF images; this report has all been converted to PNG. | Checkable |
| data | DROID, LIBERO, Kinetics-400, and Something-Something-v2 are public data; the real task finetuning demos are self-collected by the author. | Partially reproducible |
| Model structure | ResNet-18, SDXL VAE, DiT/AdaLN, 12 layers 12 heads, 8 registers, action/image latent shapes are given. | more complete |
| training configuration | 100K pretraining, 10K/20K/50K finetuning, DDIM 10 inference steps, AdamW, batch/lr/weight decay are given. | more complete |
| real assessment | Task definition, number of demos, number of evaluation conditions, 3 attempts per initialization, OOD settings and failure modes are given. | more complete |