RoboEnvision: A Long-Horizon Video Generation Model for Multi-Task Robot Manipulation
1. 论文速览
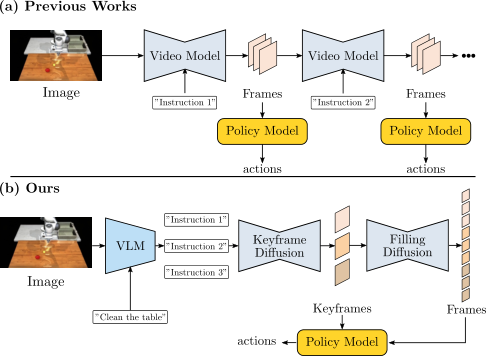
| 论文要解决什么 | 现有机器人视频扩散方法多生成短时段视频;要做长程任务时通常把短视频 autoregressive 串起来,导致视频中物体数量、形状、位置和任务语义逐步漂移,执行动作也会累积错误。论文要解决的是:给定一个高层长程指令和初始图像,如何一次性生成语义一致、对象稳定、可用于动作回归的长程机器人操作视频。 |
|---|---|
| 作者的方法抓手 | RoboEnvision 把长程任务拆成“计划锚点 + 局部补帧 + 动作回归”:先用 GPT4-o1/DeepSeek/人工将高层指令分解为原子指令;keyframe diffusion 生成每个子任务结束状态的关键帧;filling diffusion 在相邻关键帧之间补齐短视频;最后用轻量 spatio-temporal Transformer policy model 从生成视频回归机器人关节和夹爪状态。 |
| 最重要的结果 | 在视频质量上,RoboEnvision 在 LHMM 数据集五项指标均最优:LPIPS 0.1282、SSIM 0.5820、PSNR 17.27、FVD 205.78、CLIP 23.99;在 LanguageTable 上除 CLIP 外四项最优。动作执行上,LHMM 45 个长程任务成功率达到 67.4%,明显高于 UniPi 23.5%、RDT1B 34.1%、Ours-Autoregressive 27.0%。 |
| 阅读时要注意的点 | 不要只看“长视频生成更好”这句话,要追问三个环节:VLM 分解是否可靠;keyframe diffusion 是否真的按每条子指令生成对应结束状态;policy model 的成功率提升来自长程视频分布、decoder 架构,还是 MuJoCo/LHMM 数据设置。另一个重点是该方法仍是 open-loop 执行,不是闭环纠错。 |
2. 动机与问题定义
2.1 为什么短视频串接不够
机器人视频生成已经被用于规划、验证、策略学习和模拟数据生成,但多数工作处理的是短期动作,例如一个 pick 或一个 place。长程任务如“清理桌子”或“做一道菜”包含多个子目标、对象状态跨阶段变化、操作顺序约束和大范围运动。若每一段只根据上一段最后一帧继续生成,误差会沿时间累积:物体可能消失、形状变形、数量变化,后续视频也会越来越偏离高层目标。
作者认为长程机器人视频不只是“帧数更多”,而是“多个任务阶段的语义和空间状态必须同时稳定”。因此他们引入 keyframes 作为全局锚点,而不是逐段滚动生成。
2.2 问题定义
长程视频生成任务输入初始图像 $x^0$ 和高层指令 $l_{HL}$,后者可分解为 $K$ 个原子指令 $l^i$。目标是生成完整视频:
其中 $x\in\mathbb{R}^{N\times3\times H\times W}$。关键不是直接让一个模型吃下很长 prompt 和生成 $N$ 帧,而是先生成 $K$ 个关键帧:
再对相邻关键帧补帧:
2.3 贡献定位
- 提出面向机器人长程操作的 hierarchical video generation pipeline,结合 VLM、keyframe diffusion、filling diffusion 和 policy model。
- 设计 keyframe-instruction cross-attention,让每个关键帧只关注对应原子指令,增强指令-关键帧对齐。
- 提出 3D attention 与 semantics preserving attention,用初始图像 VAE 特征增强关键帧对象形状、位置和数量一致性。
- 提出轻量 transformer-based policy model,从生成的长程视频中回归机器人关节和夹爪状态,并在 LHMM 长程任务中超过 UniPi、RDT1B 等基线。
4. 方法详解
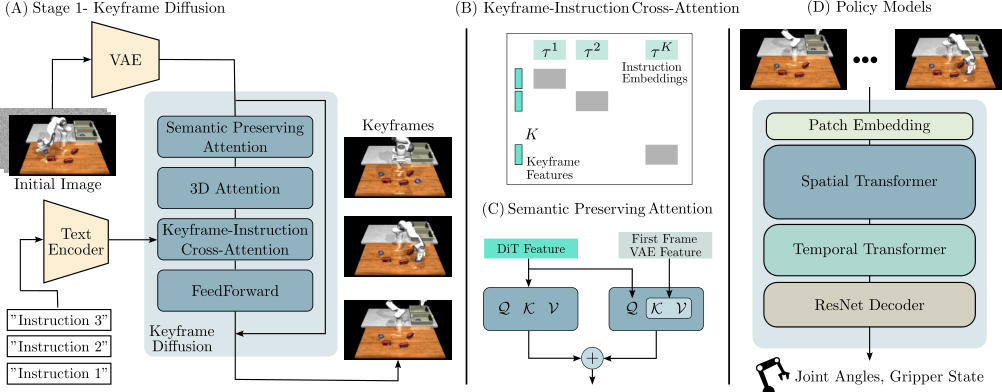
4.1 总体框架
RoboEnvision 的流程是:
- 用 VLM 或 reasoning model 将高层任务拆成低层原子指令。
- Keyframe diffusion 根据初始图像和原子指令链生成关键帧,每个关键帧对应一个子任务结束状态。
- Filling diffusion 在每对相邻关键帧之间生成短视频,所有段可并行补帧。
- Policy model 从关键帧和部分插值帧回归机器人 joint states 和 gripper states。
4.2 VLM 子任务分解
高层指令如“place all objects in the box”或“push all blocks to the left”会先被拆成 $K$ 个低层指令。论文说 GPT4-o1 在空间推理上优于传统 VLM,且可通过 in-context template 提高稳定性,例如 LanguageTable 中使用类似 pick the {color} {object} 或 push the {color} {shape} block at the {top,bottom,left,right} of {color} {shape} block 的模板。
这一步是整条 pipeline 的任务规划入口。若原子指令顺序或空间关系错了,后续视频生成和动作回归都会跟着错。
4.3 Keyframe Diffusion
Keyframe diffusion 接收 $B$ 个 batch、$K$ 个关键帧的视频 $x_k\in\mathbb{R}^{B\times K\times3\times H\times W}$。VAE 将其压缩到 latent:
forward diffusion 添加高斯噪声:
训练目标是标准噪声预测:
base architecture 来自 OpenSora 的 Diffusion Transformer,包括 spatial attention、temporal attention、text cross-attention 和 FFN。
4.4 Keyframe-Instruction Cross-Attention
普通 cross-attention 会让所有 keyframe token 同时看所有文本 token,容易出现“第 2 个关键帧跟第 3 条指令混在一起”的情况。作者用 diagonal block mask $\mathcal{M}$,让第 $i$ 个 keyframe 的 feature 只和第 $i$ 条 instruction embedding cross-attend:
$\mathcal{M}$ 对角块为 0,非对角块为 $-\infty$。这使关键帧序列更像“子任务结束状态列表”,而不是一个模糊的长 prompt 视频。
4.5 3D Attention 与 Semantics Preserving Attention
即使有 keyframe 和 instruction 对齐,机器人视频仍会出现小物体消失、形状变形和位置漂移。作者认为原因是相邻关键帧间隔大、物体运动幅度大,超出了普通短视频 temporal attention 的训练分布。
3D attention 将 attention 从仅时间维或空间维扩展到所有 spatio-temporal tokens:$(B,KH_zW_z,C)$。它更贵,但更适合建模跨帧大运动。
Semantics Preserving Attention, SPA 在每个 transformer block 的 spatial attention 中重新注入初始图像的 VAE feature。相比 CLIP hidden state,VAE feature 保留更细粒度空间细节,且与 DiT latent 在同一特征空间。公式为:
这里 $z^0$ 是初始图像 VAE feature。直觉上,它不断提醒模型:“初始场景里有哪些物体,它们长什么样”。
4.6 Filling Diffusion
Filling diffusion 以两帧相邻关键帧 $(x^{k_{i-1}},x^{k_i})$ 和对应原子指令 $l^i$ 为条件,生成两帧之间的短视频:
由于每个 gap 的条件都已确定,阶段 2 可以并行运行,比 autoregressive 一段段等待前一段生成更利于推理加速,也降低了误差传递。
4.7 Robot Policy Model
Policy model 是一个 spatio-temporal transformer-based 架构,用生成视频回归机器人 joint states 和 gripper state。它与视频模型独立训练,训练数据来自 simulator 的 ground truth。作者强调,训练时选取 ground-truth keyframes 和部分 interpolated frames,而不是只用短程连续帧;原因是长程关键帧之间机器人关节变化更大,更接近 long-horizon distribution。
架构包含 spatial attention、temporal attention 和 FFN 的 transformer blocks;decoder 使用 ResNet 下采样到关节空间,而不是 MLP 或 global average pooling。推理时生成长程视频后,policy model 输出关节状态,再在 MuJoCo 中 open-loop 执行。
5. 实验与结果
5.1 数据集与训练设置
| 项目 | 设置 |
|---|---|
| LanguageTable | 作者将短程 video clips 通过 optical flow consistency check 拼成长程视频;每个 clip 的最后帧作为 keyframe。 |
| LHMM | Long-Horizon Manipulation in MuJoCo,新建仿真数据集,包含 grocery/tool 相关长程任务;keyframe annotation 由 simulator 中 grasp detection 得到。 |
| 数据规模 | LanguageTable 50k;LHMM 90k;instruction 数量从 3 到 18。 |
| 训练分辨率 | LanguageTable: $360\times640$;LHMM: $180\times320$。 |
| 代码和模型 | 基于 OpenSora 开发;video diffusion 模型约 800M 参数。 |
| 视频评估样本 | LanguageTable 124 个生成视频;LHMM 100 个生成视频。 |
5.2 长程视频质量结果
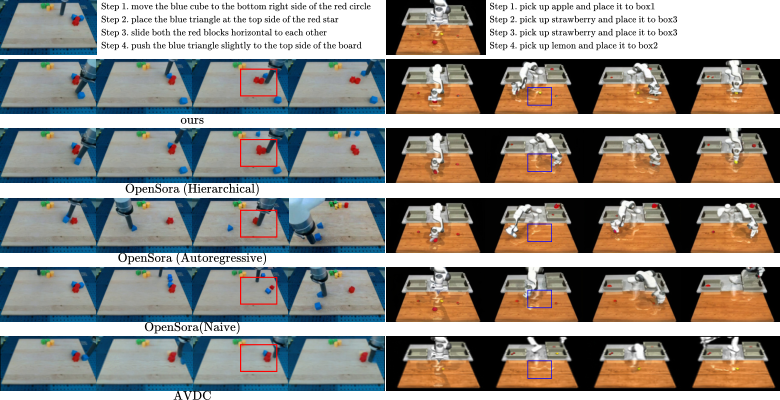
评估指标包括 LPIPS、SSIM、PSNR、FVD 和 CLIP Score。基线包含 OpenSora 的 hierarchical、autoregressive、naive 版本,以及 AVDC。
| Dataset | Method | LPIPS ↓ | SSIM ↑ | PSNR ↑ | FVD ↓ | CLIP ↑ |
|---|---|---|---|---|---|---|
| LanguageTable | OpenSora Hierarchical | 0.1445 | 0.8269 | 22.82 | 147.37 | 24.57 |
| OpenSora Autoregressive | 0.1795 | 0.7839 | 21.77 | 176.61 | 24.15 | |
| OpenSora Naive | 0.1723 | 0.8053 | 21.77 | 138.31 | 25.49 | |
| AVDC | 0.1857 | 0.7687 | 21.32 | 189.64 | 23.32 | |
| Ours | 0.1324 | 0.8273 | 23.12 | 136.75 | 24.45 | |
| LHMM | OpenSora Hierarchical | 0.1564 | 0.5257 | 16.61 | 231.02 | 23.51 |
| OpenSora Autoregressive | 0.1701 | 0.5232 | 16.46 | 241.35 | 23.58 | |
| OpenSora Naive | 0.2086 | 0.4983 | 15.52 | 274.85 | 22.55 | |
| AVDC | 0.2343 | 0.4729 | 15.33 | 267.93 | 21.37 | |
| Ours | 0.1282 | 0.5820 | 17.27 | 205.78 | 23.99 |
结果说明:hierarchical alone 不够,RoboEnvision 的 attention 设计进一步提升一致性;LanguageTable 的 CLIP 最高是 Naive,但其视觉质量和一致性差,说明 CLIP 不能单独代表机器人视频可用性。
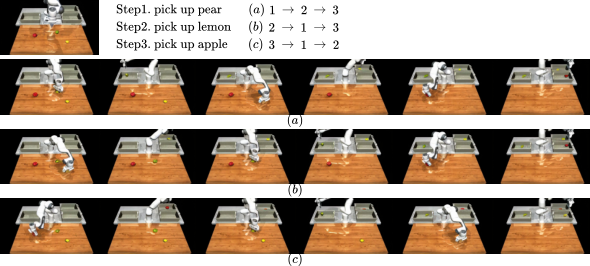
5.3 指令顺序重排与数据增强潜力
作者展示了改变原子指令顺序后,keyframe diffusion 可以生成不同顺序的长程执行视频。这一点被用来支持“数据增强”潜力:在已有视频数据基础上,通过打乱任务顺序可以生成更多视觉观察与机器人 joint states 的配对数据,扩展 VLA 预训练分布。
5.4 Policy Model 成功率
作者在 LHMM 的 45 个长程任务上评估动作执行,任务是 pick/place 多个 grocery 和 tool objects。长程视频先由模型生成,policy model 将视频逐帧转为 joint control commands,并导入 MuJoCo 执行。
| Method | Success Rate |
|---|---|
| UniPi | 23.5% |
| RDT1B | 34.1% |
| Ours | 67.4% |
| Ours (short-horizon) | 49.4% |
| Ours (Autoregressive) | 27.0% |
关键解读:Ours short-horizon 仍比 UniPi/RDT1B 高,但比完整模型低 18 个点,说明 policy model 需要在长程关键帧分布上训练;Ours-Autoregressive 只有 27.0%,说明只换更好 decoder 并不能解决长程问题,生成范式本身很关键。
5.5 VLM 长程规划
论文定性展示了 GPT4-o1 作为 subtask director 的效果。它根据初始观察和模板知识分解高层指令,keyframe diffusion 再根据 instruction chain 生成长程视频计划。
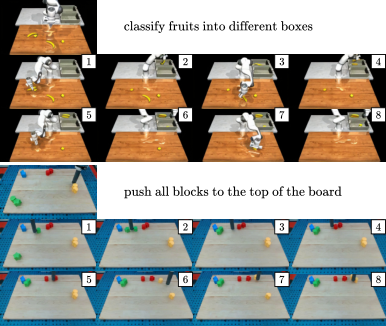
5.6 Ablation: 3D Attention 与 SPA
| Model | LPIPS ↓ | SSIM ↑ | PSNR ↑ | FVD ↓ | CLIP ↑ |
|---|---|---|---|---|---|
| base | 0.1498 | 0.6924 | 20.07 | 184.71 | 24.10 |
| w/o SPA | 0.1415 | 0.7032 | 20.36 | 169.50 | 24.19 |
| w/o 3D | 0.1430 | 0.7102 | 20.11 | 168.83 | 24.21 |
| ours | 0.1305 | 0.7178 | 20.51 | 167.57 | 24.24 |
定量和定性都支持两个组件互补:3D attention 更有助于物体数量和位置一致;SPA 更有助于小物体形状和语义细节保持。
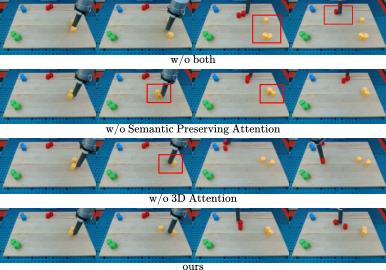
6. 复现要点
6.1 数据准备
- LanguageTable: 需要短程 clips,并通过 optical flow consistency check 拼接成长程视频。
- 每个短 clip 的最后帧作为 keyframe,形成 keyframe diffusion 的监督。
- LHMM: 需要 MuJoCo 长程任务数据、关键帧标注和机器人 joint states;论文用 grasp detection 产生 keyframe annotation。
- 高层指令需要可分解为 3 到 18 条原子指令。
6.2 模型训练
| 模块 | 训练/实现要点 |
|---|---|
| Keyframe diffusion | 基于 OpenSora DiT;输入初始图像和 instruction chain;引入 keyframe-instruction cross-attention。 |
| 3D attention | 替换 temporal attention,使 attention 覆盖所有 spatio-temporal tokens。 |
| SPA | 每个 transformer block 中将初始图像 VAE feature 投影为 key/value,参与 spatial attention。 |
| Filling diffusion | 条件为相邻关键帧和对应低层指令;各段可并行补帧。 |
| Policy model | 独立训练;输入 keyframes 和部分 interpolated frames;输出 joint states 和 gripper states。 |
6.3 评估指标
- 视频质量:LPIPS、SSIM、PSNR、FVD、CLIP Score。
- 动作执行:LHMM 45 个长程任务成功率。
- 定性检查:物体数量是否保持、形状是否变形、关键帧是否对齐子指令、改变指令顺序是否改变执行顺序。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
这篇论文最有价值的地方是它把机器人长程视频生成拆成了更符合任务结构的中间表示:关键帧不是均匀抽样的视频帧,而是每个子任务结束状态的语义锚点。这样一来,长程生成不再是“从上一帧往后滚”,而是先确定整条任务链的全局结构,再局部补齐动态。
第二个价值点是把视频质量和动作可执行性放在一起检验。论文不只报告 LPIPS/FVD/CLIP,还训练 policy model 从视频回归关节并在 MuJoCo 中执行。这让“生成视频能不能用于机器人”有了更接近控制的证据。
7.2 结果为什么站得住
- 视频评估覆盖两个数据集,且 LHMM 中五项指标全部最优,说明不是单数据集偶然提升。
- 与 OpenSora naive、hierarchical、autoregressive 都比较,能区分“层级范式本身”和“本文新增 attention 设计”的贡献。
- policy model 成功率包含多个 ablation:short-horizon training 和 autoregressive inference 都明显下降,支持长程训练和长程生成都重要。
- Ablation 表中 base、w/o SPA、w/o 3D、ours 逐步对比,并有定性图展示小物体形状/数量/位置问题。
- 改变 instruction order 的定性实验说明模型不是只记固定轨迹,而能根据子任务顺序调整生成。
7.3 主要局限
- 依赖 VLM 分解:如果高层指令被分解错,关键帧生成会从第一步就偏离真实目标。论文主要给定性展示,没有系统评估 VLM decomposition accuracy。
- 执行仍是 open-loop:生成视频和关节轨迹后在 MuJoCo 中开环执行,没有在线视觉反馈纠错;真实机器人长程任务中误差可能更严重。
- 真实机器人验证不足:动作成功率在 LHMM/MuJoCo 上评估,并非真实硬件长程执行。
- 数据集构造依赖模拟器和规则:LHMM keyframes 由 grasp detection 得到,LanguageTable 由 optical flow 拼接,和真实长程演示分布仍有差距。
- 物理一致性仍间接:LPIPS/FVD/CLIP 与真实可执行性不完全等价;policy model 成功率提供补充,但仍可能受模拟器和训练分布影响。
- 计算成本与参数细节不完整:模型约 800M,但论文没有给出完整训练资源、epoch、优化器等细节,复现难度偏高。
7.4 边界条件
| 适用条件 | 需要谨慎的条件 |
|---|---|
| 任务可自然分解为若干原子子任务,每个子任务有明确结束状态。 | 任务需要连续反馈、没有清晰 keyframe,或中间状态难以用图像锚定。 |
| 场景中关键物体可见,且 simulator 能提供 keyframe/joint supervision。 | 真实环境强遮挡、可变形物体、接触状态不可见。 |
| 目标是生成长程视觉计划或仿真训练数据。 | 要求安全闭环执行的真实机器人部署。 |
| 可接受 VLM 作为上游 planner,并能调 prompt/template。 | 高层指令模糊,或 VLM 空间推理容易出错的任务。 |
8. 组会问答准备
Q1: RoboEnvision 和 autoregressive long video 最大区别是什么?
Autoregressive 是逐段用上一段最后帧继续生成,错误会传递;RoboEnvision 先生成所有子任务关键帧作为全局锚点,再局部补帧。它牺牲了一些单段自由度,但换来更好的长程结构和对象一致性。
Q2: keyframe-instruction cross-attention 解决什么问题?
它让第 $i$ 个关键帧只看第 $i$ 条原子指令,避免所有关键帧混合关注整条 prompt。这样关键帧更明确地对应每个子任务的完成状态。
Q3: 3D attention 和 SPA 分别管什么?
3D attention 更偏向跨时空建模,帮助维持物体数量和位置;SPA 用初始图像 VAE feature 提供细粒度语义和形状信息,帮助小物体不变形、不丢失。ablation 显示两者组合最好。
Q4: 为什么 policy model 要在长程 keyframes 上训练?
长程关键帧之间关节变化更大,分布比短程连续帧更丰富。只用 short-horizon frames 训练,即使用长程视频推理也会掉到 49.4%;autoregressive 生成再执行更低,只有 27.0%。
Q5: 最强的结果是哪一个?
LHMM 成功率 67.4% 是最贴近机器人控制的结果;视频指标则以 LHMM 五项全优最有说服力。二者合在一起说明它不只是生成图像更像,也更能支持关节轨迹回归。
Q6: 最可能被质疑的地方是什么?
真实机器人验证不足、VLM 分解没有系统量化、以及 open-loop 执行。论文证明了仿真长程视频计划和动作回归有价值,但距离真实长程机器人闭环部署还有明显距离。