Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
Reading Report: RIGVid attempts to answer a very direct but bold question: Can a robot complete operating tasks in the real world without watching real human/robot demonstrations, but only by watching a task video synthesized by a video generation model?
1. Quick overview of the paper
| What should the paper solve? | Traditional robot imitation from video methods rely on real human videos, robot demonstrations, or offline robot data. RIGVid wants to verify: given only the initial RGB-D scene and language commands, it is possible to use a generated video as the sole supervision to allow real robots to perform operational tasks such as pouring water, lifting lids, placing spatulas, and sweeping garbage. |
|---|---|
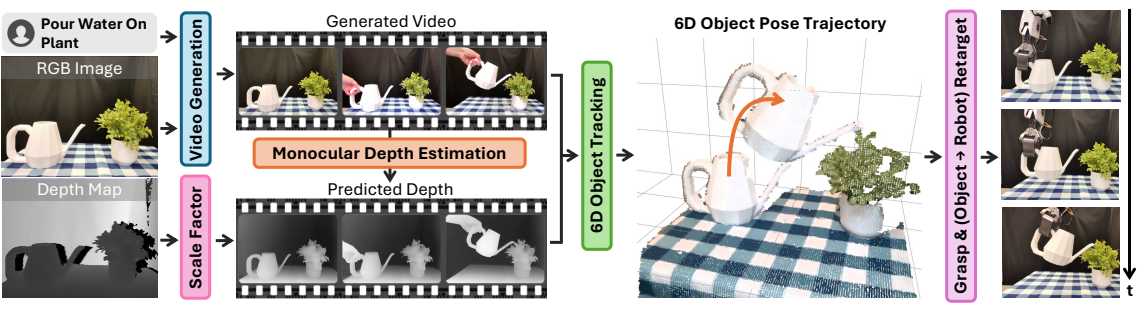
| The author's approach | Convert "generate video" into "executable 6D object pose trajectory". The process is: generate task video, VLM filtering fails to generate; estimate the depth of each frame and do scale/offset alignment with the initial true depth; use FoundationPose to track the 6D pose of the active object; after grabbing the object, redirect the object pose trajectory to the end effector trajectory, and perform closed-loop tracking to recover the disturbance. |
| most important results | The filtered Kling v1.6 generated videos achieve performance similar to real human videos on four real tasks; RIGVid has an average success rate of 85%, which is higher than ReKep's 50%, Gen2Act's 67.5%, AVDC's 32.5%, 4D-DPM's 35.0% and Track2Act's 7.5%. |
| Things to note when reading | The key to the success of the result is not that "the video generation model directly understands robots", but that the author compressed the generated video into an object-level SE(3) trajectory, and added a lot of engineering support with real RGB-D, object mesh, 6D tracking, VLM filtering and closed-loop execution. Don't interpret this article as pure prompt-to-action, and don't ignore the two main bottlenecks of depth estimation and mesh pre-construction. |
2. Background and problem setting
core issues
The core problem of the paper can be written as: given the initial scene image \(I_0\), the initial depth \(D_0\) and the language command \(c\), directly predict the robot 6DoF end trajectory \(\{\mathbf{T}^{WE}_t\}_{t=1}^T\) without real demonstration or training task strategy. The intermediate representation chosen by the author is not the action token or key point constraints, but the 6D pose trajectory \(\{\mathbf{T}^{WO}_t\}_{t=1}^T\) of the object in world coordinates.
This changes the problem from "generating robot movements" to "recovering how objects move from generated videos". This transformation is critical because current video generation models can generate rich visual sequences but do not output executable actions; robot execution requires geometrically consistent trajectories.
Differences from existing work
- Relatively real video imitation: RIGVid does not require the collection of human demonstration videos in the target scene, nor does it require robot teleoperation.
- Relative offline video learning: It does not learn generalization strategies from large-scale Internet videos, but generates a customized video for the current scene and current command.
- Relative to Gen2Act / Track2Act: It does not use point trajectories as the final geometric representation, but restores the complete 6D pose of the object, making it more stable under occlusion, rotation, and depth changes.
- Relative ReKep: ReKep generates sparse keypoint relational constraints and RIGVid preserves continuous visual and temporal details in videos.
3. Method details
3.1 Video generation and VLM filtering
The inputs are initial RGB images, corresponding depths, and free language commands. The authors use an image-to-video generative model to generate candidate task videos. Since the generated video may not execute commands, change objects, violate physics, or remain stationary, the author uses GPT-4o/o1 class VLM for automatic filtering: uniformly sample 4 frames from the video, vertically splice them into a video summary, and let the VLM determine whether there are visible hands in the video to complete a given action. If it fails, it will be regenerated, and a maximum of 5 attempts will be made; if all fails, the last generated one will be used.
3.2 Depth estimation and scale alignment
The generated video is RGB only, and RIGVid requires depth per frame to recover the 3D pose. The author uses a monocular depth estimator to predict depth, but there are scale and translation ambiguities in monocular depth. Therefore, they fit an affine transformation to the predicted depth \(\hat{D}^{mono}_0\) using the true initial depth \(D_0\) in the active object area of the first frame:
$$D_t = a \hat{D}^{mono}_t + b$$
This \(a, b\) is applied to the entire video after the first frame is aligned. This design uses the real RGB-D initial observation as a "scale anchor", otherwise the three-dimensional motion in the generated video cannot fall into the real robot coordinates.
3.3 Active object recognition and 6D pose trajectory
The system needs to know "which object is being manipulated". The author first lets GPT-4o determine the active object category according to the command, then uses Grounding DINO to give the frame, and uses SAM-2 to refine it into a mask. Then use FoundationPose combined with depth tracking to track the 6D pose trajectory of the object.
FoundationPose is a model-based tracker that requires object mesh. The author uses BundleSDF to pre-acquire a short RGB-D video of an object rotating to reconstruct the mesh. Appendix Note: BundleSDF can also do mesh-free joint reconstruction and tracking, but the official implementation takes about 30 minutes to process a video and is not suitable for real-time closed loop.
3.4 Trajectory redirection to robot
Scraping is done by AnyGrasp. After grasping the object, the authors assume that the rigid body transformation between the end effector and the object remains unchanged. If \(\mathbf{T}^{WO}_t\) is the pose of the object in world coordinates, and \(\mathbf{T}^{EO}\) is the fixed transformation from the end to the object after grabbing, then the target end trajectory can be understood as:
$$\mathbf{T}^{WE}_t = \mathbf{T}^{WO}_t(\mathbf{T}^{EO})^{-1}$$
The specific coordinate convention may vary depending on the implementation, but the core is not to predict the action, but to use a fixed grasp transform to convert the object trajectory into a terminal trajectory. This is why it can be migrated to an ALOHA or dual-arm setup: when changing robots you mainly change the end-to-object transformation.
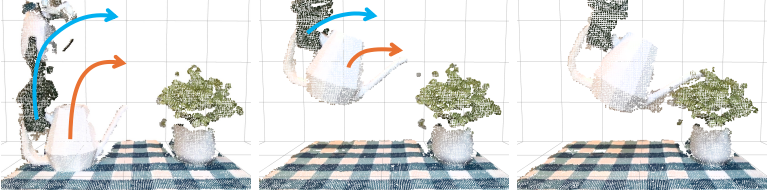
3.5 Closed-loop execution and disturbance recovery
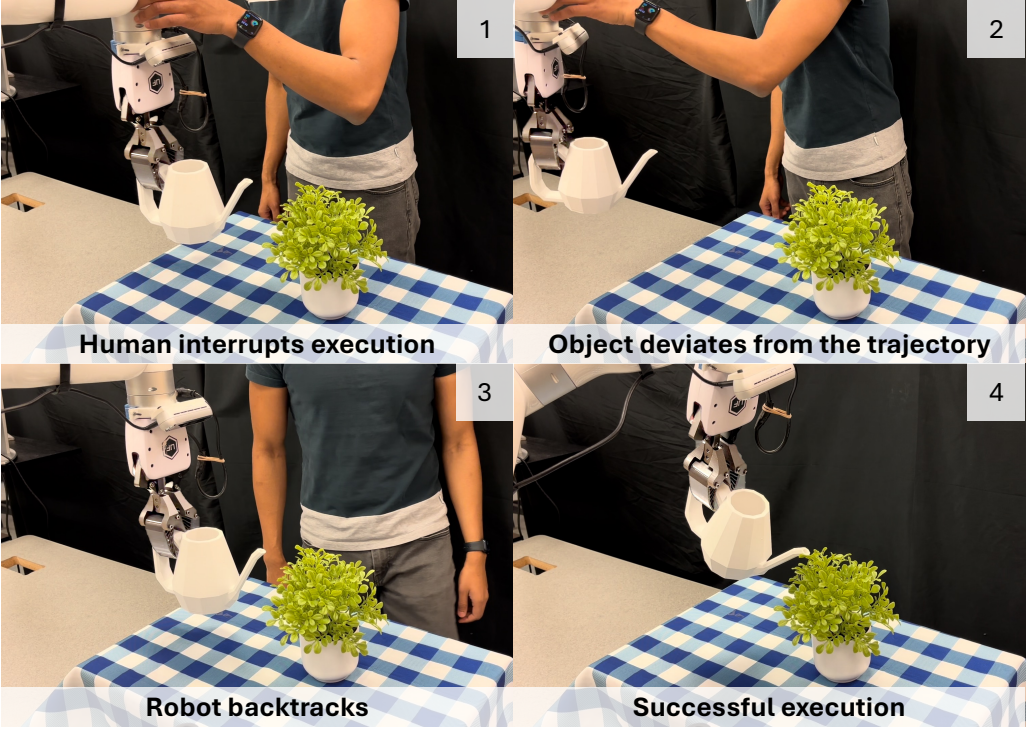
During execution, the system continues to track the object's 6D pose in real time. If the current object pose deviates from the precalculated trajectory by more than 3 cm or 20 degrees, the robot will return to the previous successful trajectory point and continue execution. This closed-loop mechanism allows RIGVid to handle real-life disturbances such as people pushing the robot and slipping after grabbing.
4. Experiments and results
4.1 Task settings
The experiments used an xArm7 robotic arm and a fixed Orbbec Femto Bolt RGB-D camera. The four main tasks cover different difficulties: pouring water, lifting the pot lid, putting the spatula into the pot, and sweeping the garbage into the dustpan. The evaluation is manually judged based on the task success criteria, and all baselines use the same batch to generate videos.

4.2 Video generation quality and filtering
| video source | Author's observation | Impact on robot execution |
|---|---|---|
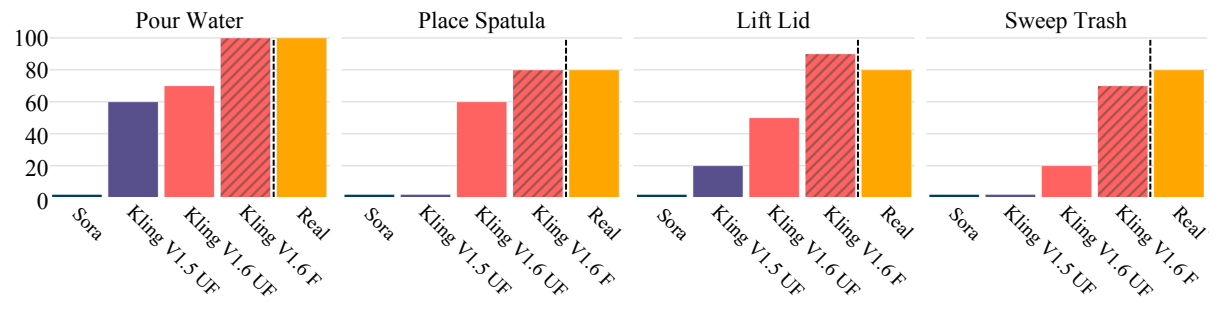
| Sora | The picture is beautiful but the camera, object size, object identity and scene layout are often changed; the pass rate of the four task filters is 0%. | Not suitable for direct imitation, unfiltered execution success rate is 0%. |
| Kling v1.5 | More consistent with language and scenes, but still with physical implausibility, such as water flowing out of the top of a pot or actions not happening. | Better than Sora, but less stable the harder the mission. |
| Kling v1.6 | The command following and physical rationality are the best; the filter pass rate is 83% for pouring water, 66% for lifting the lid, 55% for placing the spatula, and 45% for sweeping the garbage. | After VLM filtering, the generated video can achieve an effect close to the real demonstration video. |

4.3 Can generated videos replace real videos?
The authors compare unfiltered Sora, unfiltered Kling v1.5, unfiltered Kling v1.6, filtered Kling v1.6 and real human videos. Filtration significantly increases the execution success rate of Kling v1.6: pouring water from 80% to 100%, lifting lid from 60% to 80%, placing spatula from 50% to 90%, sweeping garbage from 20% to 70%. The key conclusion of the paper is that after filtering, the current strong video generation model can already be used as an effective visual demonstration source.
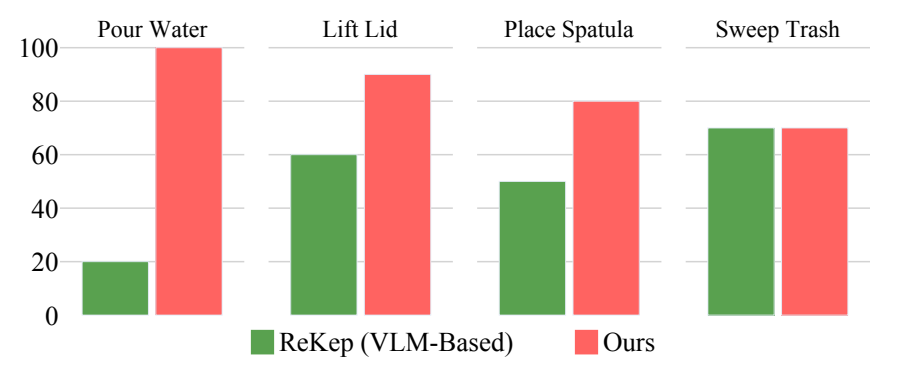
4.4 Comparison with VLM keypoint/constraint method
ReKep represents the "let the VLM directly generate sparser keypoint relationship constraints" route. The average success rate is 85% for RIGVid and 50% for ReKep. The author's explanation is that although video is expensive, it retains continuous visual details during the task; compact representations such as ReKep are prone to errors in local details such as grab points, movement constraints, and dumping constraints.
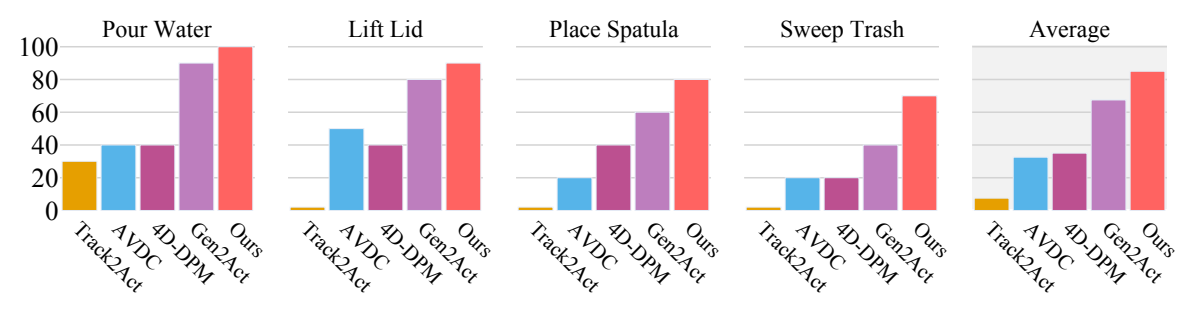
4.5 Comparison with trajectory extraction baseline
| method | intermediate representation | average success rate | Main failure modes |
|---|---|---|---|
| Track2Act | 2D point tracks between initial image and target image | 7.5% | Trajectory prediction does not follow the movement of real objects, and the initial and final images are not enough to restore the complete process. |
| AVDC | optical flow of the entire video | 32.5% | Frame-by-frame flow errors accumulate, causing object position drift. |
| 4D-DPM | 3D feature field / Gaussian field | 35.0% | Tracking is unstable and jittery, especially with large rotations of a single object. |
| Gen2Act adapted | Generate sparse tracks + PnP on video | 67.5% | Occlusion and large-angle rotation cause visible points to be lost, making PnP unstable. |
| RIGVid | FoundationPose object-level 6D pose trajectory | 85.0% | The main remaining failures come from monocular depth estimation and individual grasp slippage. |
4.6 Generalization and extension
The author demonstrated three categories of generalization: first, the success rate of pouring water on ALOHA is 80%, while the default xArm setting is 100%. The performance degradation mainly comes from the difficulty of ALOHA camera calibration; second, the two-arm ALOHA can put a pair of shoes into a box; third, it is extended to wipe, stir, iron, right the ketchup bottle, unplug the charger, rotate the spoon to pour beans, and more operations. These results are more qualitative or preliminary, but illustrate that object-centric retargeting does have potential across embodiments.

5. Appendix key information
Video generation practice
The appendix summarizes the conditions for more reliable video generation: clean background, few distractors, large enough objects, perspective close to the natural human perspective, single and clear task, and concise prompts; use relevance factor 0.7, and add negative prompt "fast motion". These details illustrate that the results are not straightforward for any desktop scenario.
Filter prompts and filter indicators
The author uses GPT o1/4o to determine whether the video has completed the command on the 4-frame spliced image. Compared with VBench++'s video-text consistency and I2V subject consistency, VLM filtering has the highest correlation with human judgment: the four task correlation coefficients are 0.91, 0.91, 0.91, 0.66, with an average of 0.84. The VBench++ indicator can only roughly reflect the video quality and cannot reliably determine whether the task is actually completed.

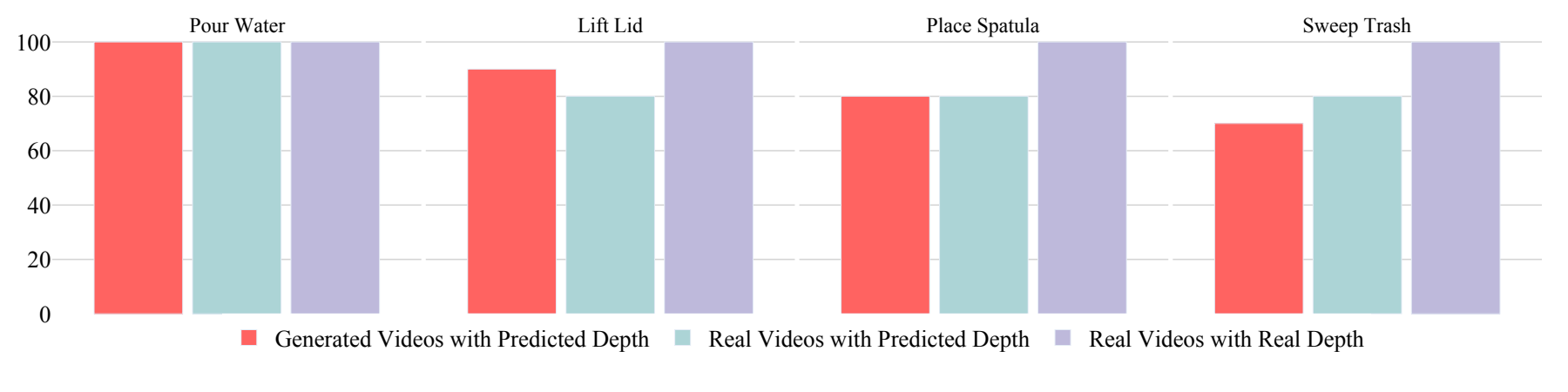
Depth estimation error is the main bottleneck
On filtered Kling v1.6 videos, failures mainly come from monocular depth estimation, except for one grab slip. The appendix further isolates the factors: real video + real depth is 100% successful; real video + predicted depth is 85%; Kling generated video + predicted depth is also 85%. This shows that generating the video itself is not the only bottleneck, and the depth estimation error will directly contaminate the 6D pose trajectory.
MegaPose vs FoundationPose
The author compares pose trajectory jitter: MegaPose average translation RMS jitter is 0.0045 m and rotation RMS jitter is 37.47 degrees; FoundationPose is 0.0029 m and 14.31 degrees. FoundationPose is smoother and performs in real time, making it the primary method choice.
Why does the point trajectory method fail?
The appendix shows that even if Gen2Act uses BootsTAP or CoTracker, visible surface points will be obscured when encountering large rotations, 2D-3D correspondence is insufficient, and PnP will drift or jump. RIGVid relies on complete object models and SE(3) trajectory filtering, so it is more stable in scenes with large rotations, thin objects, and occlusions.
6. Key points of reproducibility and implementation
Inputs and dependencies
- Hardware: xArm7, fixed RGB-D camera, stable calibration workspace.
- Generating model: The paper compares Sora, Kling v1.5, and Kling v1.6. The main results rely on Kling v1.6 plus VLM filtering.
- Perception module: GPT-4o/o1 filtering and active object recognition, Grounding DINO, SAM-2, RollingDepth-like monocular depth estimation, FoundationPose, BundleSDF pre-built mesh, AnyGrasp.
- Control module: object-end fixed transformation after grabbing, trajectory smoothing, 3 cm / 20 degree deviation threshold trigger rollback recovery.
Minimum recurrence path
- Fixed the task scene, collected the initial RGB-D image, and pre-built mesh for the active object.
- Use language commands and initial images to generate less than 5 candidate videos, and VLM filters out successful videos.
- Depth is estimated for the generated video and affine aligned with the true depth within the active object mask of the first frame.
- Use FoundationPose to estimate the 6D pose of the object in each frame and perform pose smoothing.
- AnyGrasp grabs the active object and records the fixed transformation from the end to the object at the moment of grabbing.
- Redirect the object trajectory to the end trajectory, track the object in real time and perform deviation recovery during execution.
7. Analysis, Limitations and Boundaries
The most valuable part of this paper
It takes the problem of "can generated videos be used as robot supervision", which is easy to stay at the conceptual level, and falls on real robots, real tasks and multiple groups of baselines. The most valuable thing is not to prove that Kling v1.6 is good alone, but to prove an executable decomposition: the generative model is responsible for providing visual priors of the task process, VLM is responsible for filtering out obvious failure samples, 6D tracking is responsible for converting the visual process into geometric trajectories, and closed-loop control is responsible for handling real-world disturbances. This link allows the visual knowledge of the generative model to be more solidly connected to the physical execution for the first time.
Why does the result stand?
- The comparison objects cover multiple routes: ReKep's VLM key point constraints, Track2Act's initial and final image point trajectories, AVDC's dense flow, 4D-DPM's feature field, and Gen2Act's generated video point trajectories.
- All baselines use the same generated video, which reduces the deviation caused by "different video sources".
- The paper not only reports the final success rate, but also analyzes video quality, filtering accuracy, depth estimation, point trajectory occlusion, and trajectory jitter of FoundationPose vs MegaPose.
- The main failure mode is consistent with the appendix analysis: when the filtered video is reasonable, the remaining problems mainly come from monocular depth and tracking, rather than a vague "generating model is not good enough".
Main limitations
- Requires object mesh: FoundationPose's main process relies on pre-built object models, which limits full open world deployment.
- Rely on high-quality video generation and filtering: Sora is completely unusable in this article's setup; Kling v1.6 also requires multiple builds and VLM filtering.
- Monocular depth is a hard bottleneck: Scale errors in predicted depth and time flickering will directly lead to trajectory errors.
- The task is still partial to tabletop, single active object: Long-term interaction with multiple objects, flexible objects, strong contact force control, and tasks requiring heavy finger grasping have not yet been fully verified.
- higher cost: The combination of video generation, VLM filtering, mesh pre-construction, and 6D tracking is not lightweight.
- Assessment scale is limited: Four main tasks, 10 videos per source per task, enough to support the paper's claims, but still far from large-scale general-purpose robot operations.
Questions to ask during reading group meetings
- If there is no real initial depth and only generated video and monocular depth, can the trajectory scale be stable?
- VLM filtering is mainly false negative, so is the computational cost and latency of retrying 5 times acceptable?
- Will FoundationPose's mesh pre-building become a new data collection step that's more cumbersome than a real demonstration?
- Most of the current task success criteria are that the final state geometry is satisfied. If the task involves forces, contact sequences or material changes, is it enough to generate video supervision?
- If the future video generation model can directly output depth/3D/4D scenes, which modules of RIGVid will be replaced, and which ideas will be retained?