Geometry-Aware 4D Video Generation for Robot Manipulation
This paper proposes a 4D video generation model for robot operation: given two-channel RGB-D initial observations, future multi-view RGB-D / pointmap sequences are generated, and through cross-view pointmap alignment, the video is temporally continuous and geometrically consistent across views.
1. Quick overview of the paper
| What should the paper solve? | Solve the "dilemma" of video generation in robot operation: RGB video generation models are usually temporally continuous but lack 3D geometric consistency; 3D-aware generation methods can constrain geometry but are often limited to simple objects or static backgrounds. The authors hope to generate future RGB-D videos that are both temporally smooth and geometrically consistent across camera views and extract robot tip trajectories from them. |
|---|---|
| The author's approach | Add a pointmap generation branch to the Stable Video Diffusion backbone, and use DUSt3R-style cross-view pointmap alignment for geometric supervision; then add multi-view cross-attention to the U-Net decoder to allow the reference perspective and the second perspective to share geometric information. The generated 4D RGB-D video is converted into robot motion using FoundationPose to track the gripper 6DoF pose. |
| most important results | In terms of multi-view 4D video generation, this method achieves higher cross-view consistency, better RGB FVD and lower depth error on both simulation and real data sets; in three simulated robot operations, the average success rate reaches 0.64, which is significantly higher than Dreamitate 0.12, Diffusion Policy 0.12 and DP3 0.25. |
| Things to note when reading | This article does not directly train an end-to-end policy, but treats 4D video generation as a world model that can be used for pose extraction. The key is to see clearly: geometric consistency comes from pointmap alignment and cross-view attention; actions come from 6DoF pose tracking on generated RGB-D videos, rather than the model directly outputting actions. |
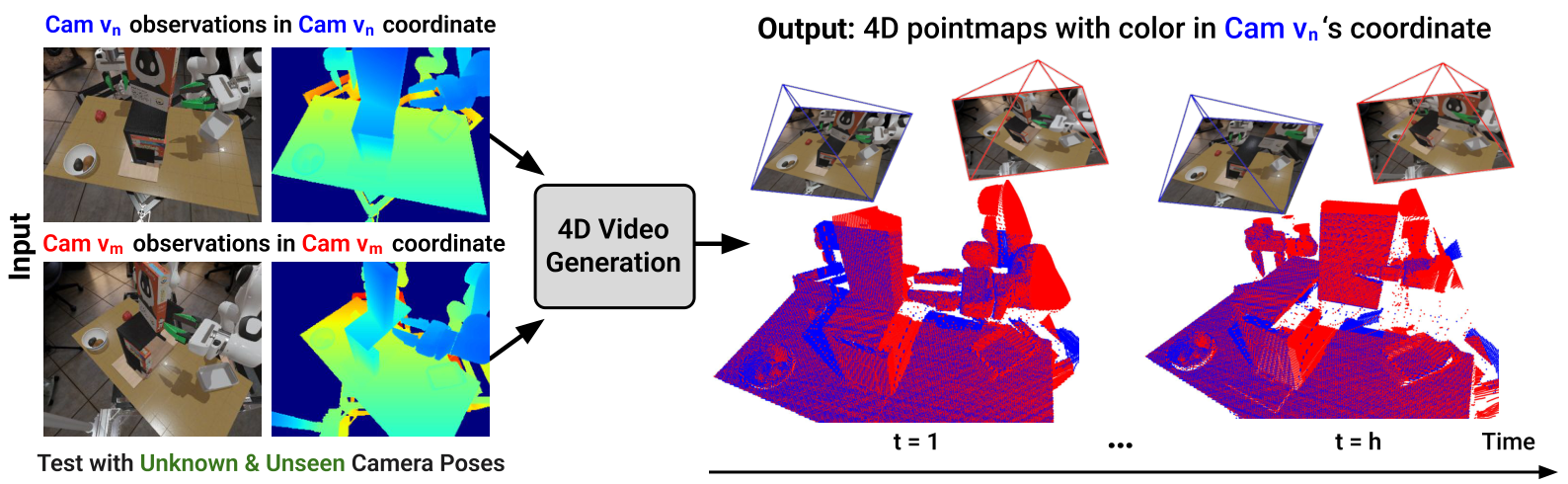
2. Problem setting and motivation
Robots need to predict how the environment will change with interaction when operating, especially dealing with occlusions, long-term object motion, and changes in camera perspective. The video generation model looks like a natural "visual world model", but if the video is inconsistent across perspectives, subsequent tracking of the robot end or object pose from the video will be very unstable.
The author points out that the core contradiction of existing methods is that temporal coherence and 3D consistency often cannot have both. Pure RGB video models may suffer from problems such as flickering, deformation, and object disappearance; 4D/3D-aware methods are often limited to simple single-object scenes. Robotic manipulation scenarios are more difficult because of multiple objects, robotic arm occlusion, precise grasping, and cross-camera generalization.
3. Related job positioning
3.1 Video Generation
Traditional video generation has evolved from RNN and GAN to diffusion and latent diffusion. Models such as Stable Video Diffusion have strong short-term visual prediction capabilities, but they mainly optimize RGB sequences and lack clear 3D spatial constraints. This article inherits the temporal modeling capabilities of SVD and adds the geometric supervision of RGB-D/pointmap.
3.2 Multi-view and 4D Video Generation
There are already camera-conditioned video generations that improve spatial consistency through camera poses; there are also 4D generation efforts that optimize video models and novel-view synthesis separately. The positioning of this article is to put temporal consistency and spatial consistency into the same video diffusion framework, and directly train multi-view 4D prediction through cross-view pointmap alignment.
3.3 Generative Models for Robot Planning
Generated models can be used as input to dynamics models, inverse dynamics, policy conditions, or action-video joint models. This article does not train inverse dynamics, nor does it directly generate actions. Instead, it allows the 4D video to generate trackable RGB-D trajectories, and then uses the ready-made 6DoF pose tracker to extract the end effector trajectory.
4. Intensive reading of methods
4.1 Overall structure
The input is RGB-D historical observations from two camera views, and the output is a future RGB video and a future pointmap sequence. Pointmap is a 3D coordinate map corresponding to each pixel, so it carries geometric structure more directly than ordinary depth map. The model generates a pointmap of this perspective in the reference perspective $v_n$, and at the same time predicts the pointmap of another perspective $v_m$ into the coordinate system of $v_n$.
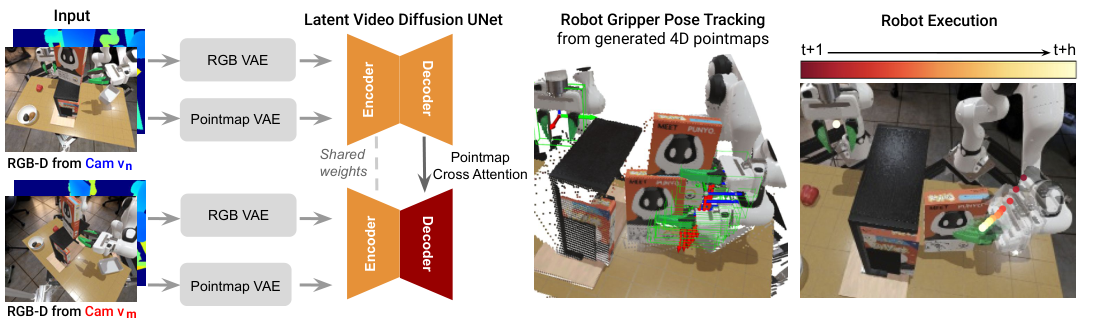
4.2 RGB video diffusion backbone
Model features Stable Video Diffusion. Historical frames are first cast to latent space by the pretrained VAE encoder, U-Net diffusion model predicts future latent, and then decoded into future RGB frames by VAE decoder. Use a target similar to DDPM during training to directly predict clean latent:
This part provides temporal prior: the model can take advantage of the motion smoothness and visual prior brought by large-scale video pre-training.
4.3 Geometry-consistent pointmap supervision
The core innovation is in 3D pointmap supervision. Given historical pointmaps of perspective $v_n$, Pointmap VAE encodes them into latent space, and then uses diffusion to predict future pointmaps. At the same time, the model also predicts future pointmaps from the second perspective $v_m$, but these points are not expressed in $v_m$'s own coordinate system, but are projected into the coordinate system of the reference perspective $v_n$, denoted as $X^{m \rightarrow n}_{t+1: t+h}$.
During training, diffusion loss is applied to both the pointmap latent of this perspective and the pointmap latent of the projected perspective. The camera pose is used to define this projection relationship during training; during inference, the model can generate future pointmaps in the reference coordinate system based only on the initial RGB-D observations of each perspective, without the need for camera pose as input.
4.4 Multi-view cross-attention
RGB video allows each view to be generated in its own coordinate system; however, pointmap predictions must explicitly align the cross-view geometry. To this end, the author uses two independent U-Net decoder branches, and adds cross-attention after each decoder block of the view $v_m$ branch, so that the middle feature of $v_m$ attends to the corresponding feature of the reference view $v_n$.
Appendix explains that a total of 12 new cross-attention layers have been added. Query comes from the feature map tokens of the decoder block of the $v_m$ branch, and the key/value comes from the feature map tokens of the corresponding block of the $v_n$ branch. This step is the direct cause of the obvious deterioration of "OURS w/o MV attn" in Table 1.
4.5 Joint temporal and 3D consistency objective
The complete loss is RGB diffusion loss plus pointmap 3D consistency loss over all future time steps and both views:
Experimental $\lambda = 1$. The Appendix also adds gripper-region reweighting: Use the gripper mask to downsample 8 times to latent resolution, weight the gripper region loss, and make the model pay more attention to the most critical regions for subsequent pose tracking.
4.6 Recovering robot motion from 4D video
After generating the future RGB-D, the author used FoundationPose to do 6DoF pose tracking. The input includes single-view RGB-D, initial frame target object mask, camera intrinsic parameters and gripper CAD model. The gripper pose is estimated from the two perspectives, and the result with a higher confidence score is selected, and then the reference perspective extrinsics is used to transfer to the global frame as the robot execution trajectory.
Gripper open/close is not output directly by the model, but the left and right gripper fingers are segmented from the generated RGB-D, projected into a 3D point cloud and the distance between the two finger centroids is calculated. Thresholds are set per task: 0.10 m for StoreCerealBoxUnderShelf, 0.06 m for PutSpatulaOnTable, and 0.12 m for PutAppleFromBowlIntoBin.
5. Experiments and results
5.1 Datasets and tasks
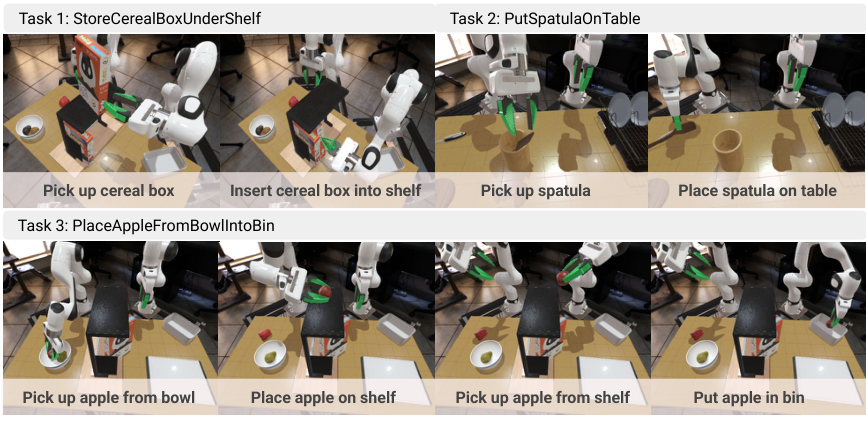
The simulation uses Toyota Research Institute's LBM simulation, based on Drake. The three desktop operation tasks are StoreCerealBoxUnderShelf, PutSpatulaOnTable, and PlaceAppleFromBowlIntoBin. There are 25 demonstrations per task, and each demo has RGB-D observations of 16 camera poses, so there are a total of 400 videos per task; 12 viewing angles for training and 4 viewing angles for testing, corresponding to 300 training camera angles and 100 test camera angles.
The real dataset contains 4 tasks collected by two Franka Panda arms: AddOrangeSlicesToBowl, PutCupOnSaucer, TwistCapOffBottle, PutSpatulaOnTable. 20 teleoperation demonstrations per mission, using two FRAMOS D415e cameras to simultaneously capture RGB-D sequences.
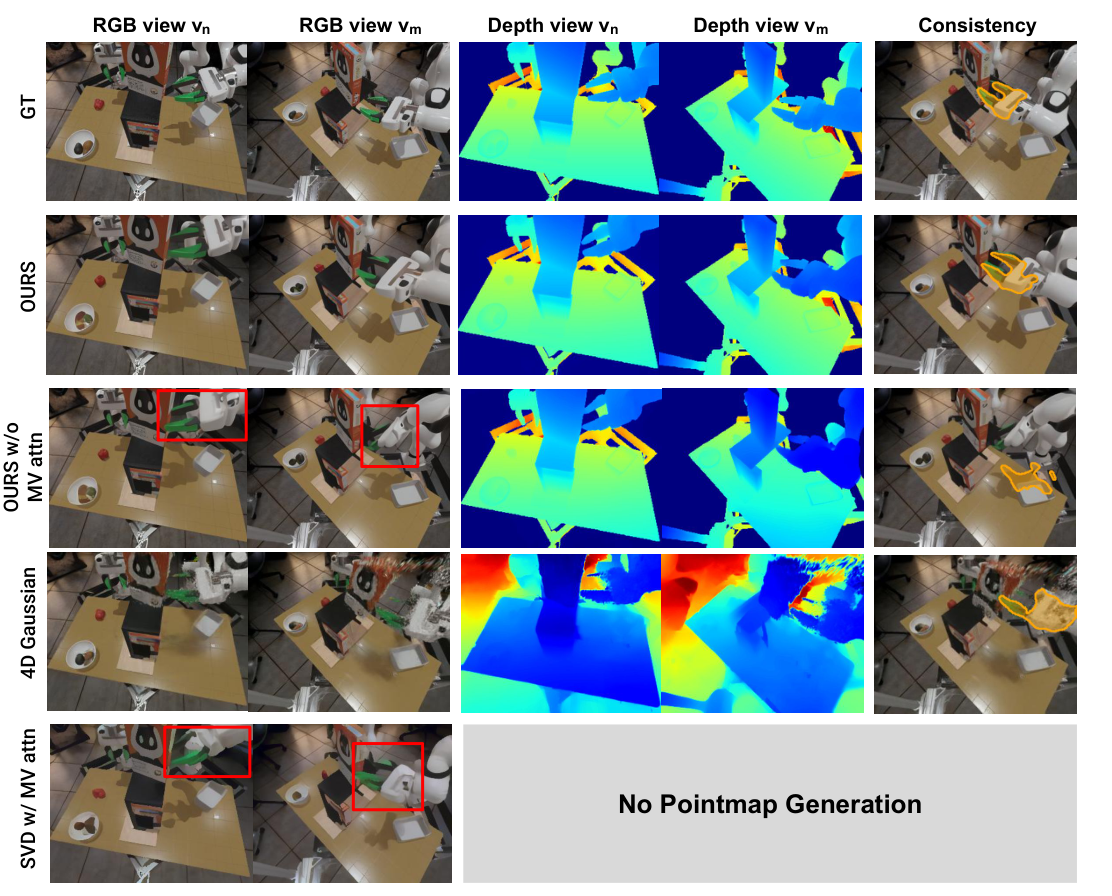
5.2 4D video generation indicators
| Assessment Dimensions | indicator | meaning |
|---|---|---|
| RGB video quality | FVD-n, FVD-m | Measure the Fréchet Video Distance of the reference view and second view generated video from the real video respectively, the lower the better. |
| Depth quality | AbsRel-n/m, δ1-n/m | Take the z value from predicted pointmaps as depth and compare it with the true depth; the lower AbsRel, the better, and the higher δ1, the better. |
| Cross-view 3D consistency | mIoU | Use SAM2 to track the gripper mask, lift the reference perspective mask to 3D and reproject it to another perspective, and calculate IoU with the original gripper mask box. The higher the IoU, the stronger the cross-view alignment. |
Baselines include OURS w/o MV attn, 4D Gaussian, SVD, SVD w/ MV attn. All models are trained on the same multi-view RGB-D video dataset and tested on novel viewpoints.
5.3 4D video generation main results
Table 1 shows that the method in this article achieves the highest cross-view consistency overall on three simulation tasks and real multi-task data sets, and is overall better than baselines in RGB FVD and depth AbsRel / δ1. Several representative values are as follows:
| Setting | OURS mIoU | OURS w/o MV attn mIoU | 4D Gaussian mIoU | Brief interpretation |
|---|---|---|---|---|
| StoreCerealBoxUnderShelf | 0.70 | 0.41 | 0.39 | Cross-view attention is critical for severe occlusion tasks. |
| PutSpatulaOnTable | 0.69 | 0.44 | 0.46 | OURS maintains low FVD and high depth accuracy simultaneously. |
| PlaceAppleFromBowlIntoBin | 0.64 | 0.26 | 0.44 | After removing MV attention in the long-duration dual-arm task, the consistency obviously collapsed. |
| Real-world multi-task | 0.56 | 0.32 | 0.00 | The cross-view consistency of 4D Gaussian in real scenes almost breaks down. |
5.4 Robot strategy results
Robot strategy evaluation was performed on three simulation tasks. Each task is tested 30 times rollouts, the initial object pose has not been seen, and the camera perspective is also from the novel viewpoints of the test set. The generative model inputs the RGB-D of two novel camera views, generates 10 future frames, and FoundationPose extracts the dual-arm gripper 6DoF trajectory. Execution is a piecewise open-loop: after executing a piece, re-inference with updated RGB-D.
| Method | Task 1 | Task 2 | Task 3 | Avg |
|---|---|---|---|---|
| Dreamitate | 0.10 | 0.17 | 0.10 | 0.12 |
| Diffusion Policy | 0.10 | 0.27 | 0.00 | 0.12 |
| DP3 | 0.23 | 0.27 | 0.00 | 0.25 |
| OURS | 0.73 | 0.67 | 0.53 | 0.64 |
Dreamitate does not predict depth and lacks geometric consistency supervision, resulting in poor quality of extracted poses. Even with multi-view training, Diffusion Policy is difficult to generalize to novel viewpoints because it does not explicitly model cross-view geometric correspondence. Task 1 is slightly better after DP3 uses RGB-D point cloud input, but it has limited help in grabbing small objects. The method in this paper generates RGB-D and explicitly tracks the gripper pose, resulting in higher motion accuracy.
5.5 Resources and Efficiency
| Method | Inference Time | Training Memory | Trainable Parameters |
|---|---|---|---|
| OURS | 30.0 s | 47 G | 2.4 B |
| OURS w/o MV attn | 29.3 s | 46.5 G | 2.38 B |
| 4D Gaussian | 2 s | 2813 M | 856, 774 |
| SVD (Dreamitate) | 13.4 s | 45.8 G | 1.54 B |
| SVD w/ MV attn | 15.1 s | 46.3 G | 2.4 B |
OURS is significantly slower, but in exchange for RGB-D quality and geometric consistency. The author also admits that generating 10 frames in 30 seconds is still too slow for a closed-loop reactive policy.
6. reproducibility and implementation details
Model input
Actually use the latest observation and repeat $h=10$ times to match the number of future frames to predict. Both RGB VAE and pointmap VAE produce $h \times c \times w' \times h'$ latent, among which $h=10$, $c=4$, $w'=32$, $h'=40$.
U-Net input
The RGB / pointmap condition latent is concatenated with the future noisy latent along the channel to form the $h \times 16 \times 32 \times 40$ input tensor.
Cross-attention
Cross-attention is added after each decoder block of the $v_m$ branch, a total of 12 layers; the query comes from $v_m$, and the key/value comes from the reference perspective $v_n$.
Gripper reweighting
Use simulation segmentation or real scene SAM2 to obtain the gripper mask, downsample 8 times to latent resolution, and weight the gripper area loss to improve the quality of the area required for pose tracking.
training
Each task is trained individually for about 60 epochs, using 4 NVIDIA RTX A6000 48GB. Full U-Net fine-tune, learning rate is $1 \times 10^{-5}$, AdamW, batch size 4; image and pointmap VAE encoders frozen.
reasoning
Using EulerEDMSampler, 25 denoising steps. Generating model and pose tracker in robot deployment ran on a single NVIDIA GeForce RTX 4090; 10 future frames in ~30 seconds.
camera sampling
The camera sampling in the Appendix uses a hemispherical shell: the inner radius is $r_1=0.7$m, the outer radius is $r_2=1.2$m, and the center is the desktop world coordinate origin; the limit range is $0.2 \le x \le 0.6$m, $-0.5 \le y \le 0.5$m, and $0.7 \le z \le 1.2$m. Each episode randomly samples 16 camera poses, with separate training and testing perspectives.

tmp/pdf_text_2507.01099.txt, pictures from Report/2507.01099/figures/.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
The most valuable aspect is advancing "robot-usable video generation" from RGB appearance to the geometric consistency of RGB-D/pointmap. Many video world models are successful as long as they look coherent, but robots need to extract executable trajectories from videos; this article explicitly takes cross-view 3D alignment as a training goal and proves that this can improve the success rate of FoundationPose's task after extracting end trajectories.
The second value is that it gives a very clear robot pipeline: 4D generation is not the end point, followed by pose tracking, gripper state inference and segmented open-loop execution. In this way, the paper can answer the question of "how does the generated video become action", rather than just showing beautiful future frames.
7.2 Why the results hold up
The results hold up, first of all because the evaluation is split into two layers: build quality and downstream robot success rate. Table 1 uses FVD, AbsRel, δ1, and mIoU to simultaneously evaluate RGB, depth, and cross-view consistency; Table 2 further verifies whether these improvements can be converted into robot task success rates. Secondly, ablations directly hit the key design: after removing multi-view cross-attention, the mIoU and depth indicators dropped significantly, indicating that the improvement did not simply come from an increase in the number of parameters.
The robot results are also convincing: baselines include the video generation route Dreamitate, the RGB behavioral cloning route Diffusion Policy, and the RGB-D point cloud route DP3, all tested on novel camera viewpoints. OURS average 0.64 vs. 0.12/0.12/0.25, the difference is large enough, consistent with the argument that "explicitly modeling geometric correspondence can improve perspective generalization".
7.3 Limitations
- High data requirements: Training requires RGB-D video data with multiple camera views. Easily generated in simulation, real-world acquisition will be limited by hardware, calibration and depth quality.
- True depth quality is the bottleneck: RGB-D cameras will have noise in reflective, transparent, occlusion, and small object scenes, which directly affects pointmap supervision and pose tracking.
- Reasoning is slow: The current generation of 10 frames takes about 30 seconds, which is much slower than the end-to-end BC policy and is not suitable for high-frequency closed-loop control.
- Still relies on external pose tracker: The quality of the motion depends not only on the generated video, but also on FoundationPose's tracking capabilities of the gripper CAD and the quality of the mask.
- Main robot strategy experiments in simulation: Real data demonstrates 4D generation quality, but downstream robot success rates are mainly reported in simulated tasks, and real closed-loop deployment still needs further validation.
7. 4 Boundary conditions
This method is suitable for tasks where multi-view RGB-D data is available, the target geometry can be represented by a pointmap, and the end effector can be stably tracked by a 6DoF tracker. It is not suitable for real-life scenarios that require high-frequency tactile feedback, strong contact dynamics, dynamic camera movements, or without reliable depth/camera calibration.
8. Preparation for group meeting Q&A
Q1: Why not directly use SVD to generate RGB video and then do pose tracking?
SVD only generates RGB, lacking depth and cross-view geometric consistency. Robot end pose tracking requires stable RGB-D and alignable geometries. In the experiment, the average success rate of the Dreamitate/SVD route was only 0.12, indicating that RGB video alone is not enough to support novel-view manipulation.
Q2: Why is pointmap more suitable here than depth map?
Depth only gives the distance along the camera ray of each pixel; pointmap gives the 3D coordinates of each pixel. When aligning across perspectives, pointmap can directly express "where the point in another perspective is after being projected to the reference coordinate system", and is more suitable for cross-view 3D supervision.
Q3: Camera pose is required during training, but why is it not required during inference?
During training, the camera pose is used to construct the supervision signal, that is, the pointmap of $v_m$ is projected into the $v_n$ coordinate system. During inference, the model has learned the mapping from RGB-D observations to reference coordinate system pointmaps, so it can predict aligned future pointmaps without taking camera pose as input.
Q4: How do robot movements come from generated videos?
After generating the RGB-D video, use FoundationPose to perform 6DoF pose tracking on the gripper CAD model. The two perspectives are tracked independently, the result with the highest confidence is taken, and then transferred to the global frame. Gripper opening and closing is judged by the 3D centroid distance threshold of the left and right fingers.
Q5: What is the relationship between this article and Dream2Flow/NovaFlow?
Dream2Flow / NovaFlow mainly distills the generated video into object flow, using object motion as the control interface; this article focuses more on the multi-view RGB-D geometric consistency of the generated video itself, and tracks the robot gripper pose from the generated video. All three are solving "how video generation becomes robot action", but the interface layer is different: object flow vs. gripper 6DoF pose trajectory.