villa-X: Enhancing Latent Action Modeling in Vision-Language-Action Models
Reading Report: villa-X is a paper on latent action modeling in the Vision-Language-Action (VLA) model. Its proposition is that latent actions should not only compress visual changes, but also use robot proprioception to align them with real physical actions; and the strategy model should explicitly plan latent actions first, and then conditionally generate robot actions.
1. Quick overview of the paper
| What should the paper solve? | Existing VLA utilizes motionless video data through latent action, but latent action is often learned only from visual reconstruction, and it is easy to ignore actions with small pixel changes but critical control, such as end rotation and gripper opening and closing. At the same time, many methods only use latent action as an intermediate pre-training task or an independent token, and fail to fully use it for robot action generation. villa-X wants to solve two problems: "How to learn latent action more physically" and "How to connect to VLA policy more effectively". |
|---|---|
| The author's approach | Two starting points: first, add proprioceptive FDM to the Latent Action Model (LAM), so that latent action not only reconstructs future images, but also predicts future robot proprio states and actions, and uses embodiment context to distinguish different robots/control frequencies; second, use joint diffusion in ACT policy to simultaneously predict latent actions and robot actions, and let the robot action expert explicitly condition on the latent action expert's plan. |
| most important results | On SIMPLER, villa-X reaches an average of 77. 7% for Google Robot and 62. 5% for WidowX, which is better than the multi-category VLA/latent-action/visual-trace baseline; the average of LIBERO four suites is 90. 1%, higher than w/o latent's 81. 9%; on the real Realman and XHand platforms, it is also overall better than the GR00T, GR-1 and w/o latent versions. ACT-latent also demonstrates zero-shot latent planning for an unseen Realman arm and open vocabulary symbol cards. |
| Things to note when reading | Don't think of villa-X as simply "adding one more latent token". The key is that the training goal of latent action is physically constrained by proprio-FDM, and the policy structure puts latent action and robot action into the same flow/diffusion generation process. Also note that latent expert's zero-shot demonstration is "planning capability" verified by world/FDM rendering and does not equate to real execution without fine-tuning on all new platforms. |
2. Background and problem setting
Why latent action is important
The VLA model needs to generate robot actions from vision and language, but real robot action annotation is expensive and inconsistent across robot forms. The idea of latent action is to abstract the intermediate token of "what action happened" from adjacent frames or short video clips, and convert a large number of action-free human/robot videos into pseudo-action supervision, thereby helping VLA pre-training.
The problem is: if the latent action only serves image reconstruction, what it learns may be "visually changing things" rather than "controlly important things". For example, the opening and closing of the gripper, the rotation of the end, and the small contact movements do not change much in pixels, but they determine the success or failure of the task.
Two big questions
- How to better learn latent action: From pure visual compression to joint constraints of visual + proprioceptive dynamics.
- How to better use latent action: Instead of just doing pre-training head, teacher forcing or independent planning, we jointly model latent action sequence and robot action chunk within the policy.
3. Method details
3.1 Overall training process
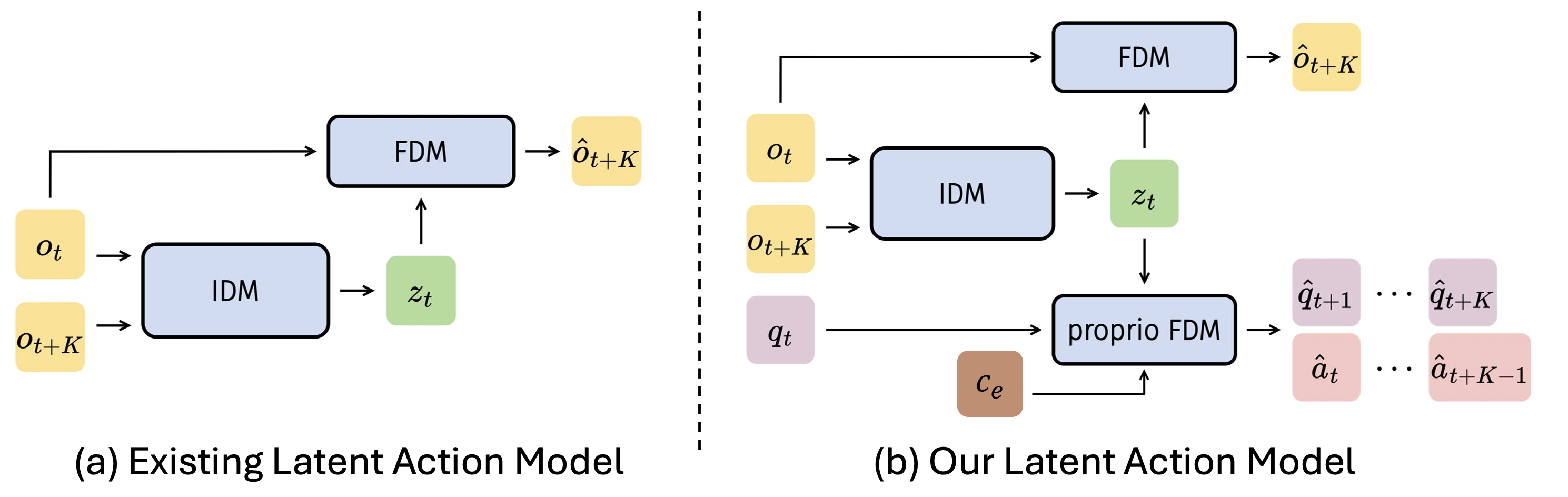
villa-X contains two core modules: LAM is responsible for extracting physically grounded latent actions from observation pairs; ACT is responsible for generating real robot actions based on VLM features, latent actions, proprio state and embodiment context. The training is divided into three stages: LAM pretraining, ACT joint latent-robot pretraining, and embodiment-specific finetuning.
3.2 Latent Action Model (LAM)
Standard LAM usually consists of IDM + visual FDM. IDM predicts latent tokens from two frames, and FDM uses the current frame and latent tokens to reconstruct future frames:
$$z_t=\text{IDM}(o_t, o_{t+K}), \quad \hat{o}_{t+K}=\text{FDM}(o_t, z_t)$$
villa-X joins proprio-FDM, so that the same \(z_t\) must also predict the future K-step robot status and actions:
$$(\hat{q}_{t+1},..., \hat{q}_{t+K}, \hat{a}_{t+1},..., \hat{a}_{t+K})=\text{proprio-FDM}(q_t, z_t, c_e)$$
Among them, \(c_e=f(\text{dataset ID}, \text{control frequency})\), the dataset ID uses learnable embedding, and the control frequency uses sinusoidal features + MLP. The purpose of this is not to stuff the differences between different robots into latent actions, but to hand over the embodiment-specific dynamics to the context and retain a more consistent latent action space.
3.3 LAM implementation details
- IDM is ST-Transformer, input default \(8\times224\times224\) video clip, patch size 14, 12 ST blocks, hidden dim 768, 32 heads.
- The VQ codebook size is 32; discrete tokens are used during training, but the continuous vector of the codebook center is used downstream as latent action.
- Image reconstruction FDM is a 12-layer ViT-base; proprio-FDM is a 2-layer MLP with dual output heads predicting future states/actions.
- LAM batch size 512, learning rate \(1.5\times10^{-4}\), 2000 step warmup, about 128 A100 training for 4 days.
- When human videos do not have proprio labels, proprio-FDM loss is omitted and only the visual FDM target is used.
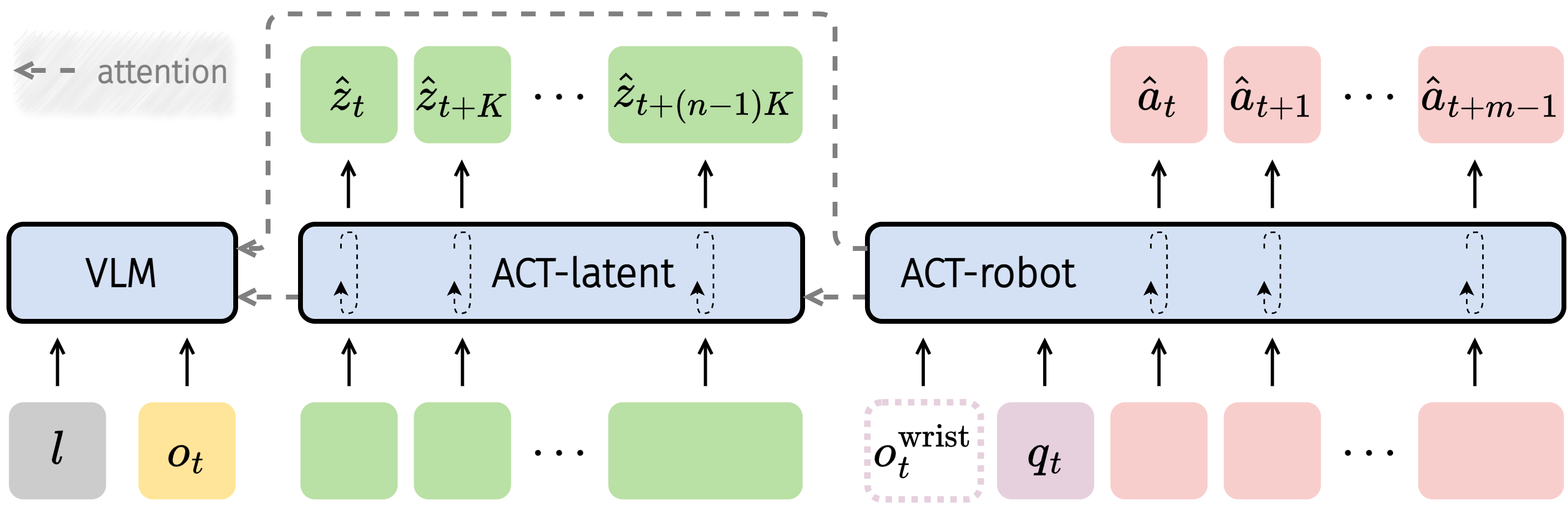
3.4 Actor Module (ACT)
ACT puts latent action and robot action into an explicitly decomposed policy:
$$\pi(a_{t: t+m-1}, z^K_{t: t+(n-1)K}|o_t, l, q_t, c_e)=\pi_{\text{robot}}(a_{t: t+m-1}|z^K_{t: t+(n-1)K}, o_t, l, q_t, c_e)\cdot\pi_{\text{latent}}(z^K_{t: t+(n-1)K}|o_t, l)$$
ACT consists of three parts: VLM encodes visual language input; ACT-latent predicts mid-level latent action plan; ACT-robot generates low-level action chunks based on VLM features, predicted latent actions, proprio state and embodiment context.
3.5 Joint diffusion / flow matching
In terms of implementation, villa-X uses conditional flow matching to model the joint distribution of latent actions and robot actions. The target action group is recorded as \(x_t\), the condition input is recorded as \(O_t=(o_t, l, q_t, c_e)\), and the training goal is:
$$L_\tau(\theta)=\mathbb{E}_{p(x_t|O_t), q(x_t^\tau|x_t)}\|v_\tau^\theta(x_t^\tau, O_t)-u(x_t^\tau|x_t)\|^2$$
Among them, \(x_t^\tau=\tau x_t+(1-\tau)\epsilon\), network prediction denoising vector field \(u(x_t^\tau|x_t)=\epsilon-x_t\). Explicit factorization is implemented via block-wise causal attention mask.
3.6 Prevent latent shortcut masking
If a robot action branch relies too heavily on latent tokens, it may learn vulnerable shortcuts. The author randomly masks robot-to-latent attention during training: 50% of the time, the robot-to-latent attention is completely masked; otherwise, 50% of latent tokens are randomly masked. Appendix ablation shows that both attention mask and embodiment context help.
4. Experiments and results
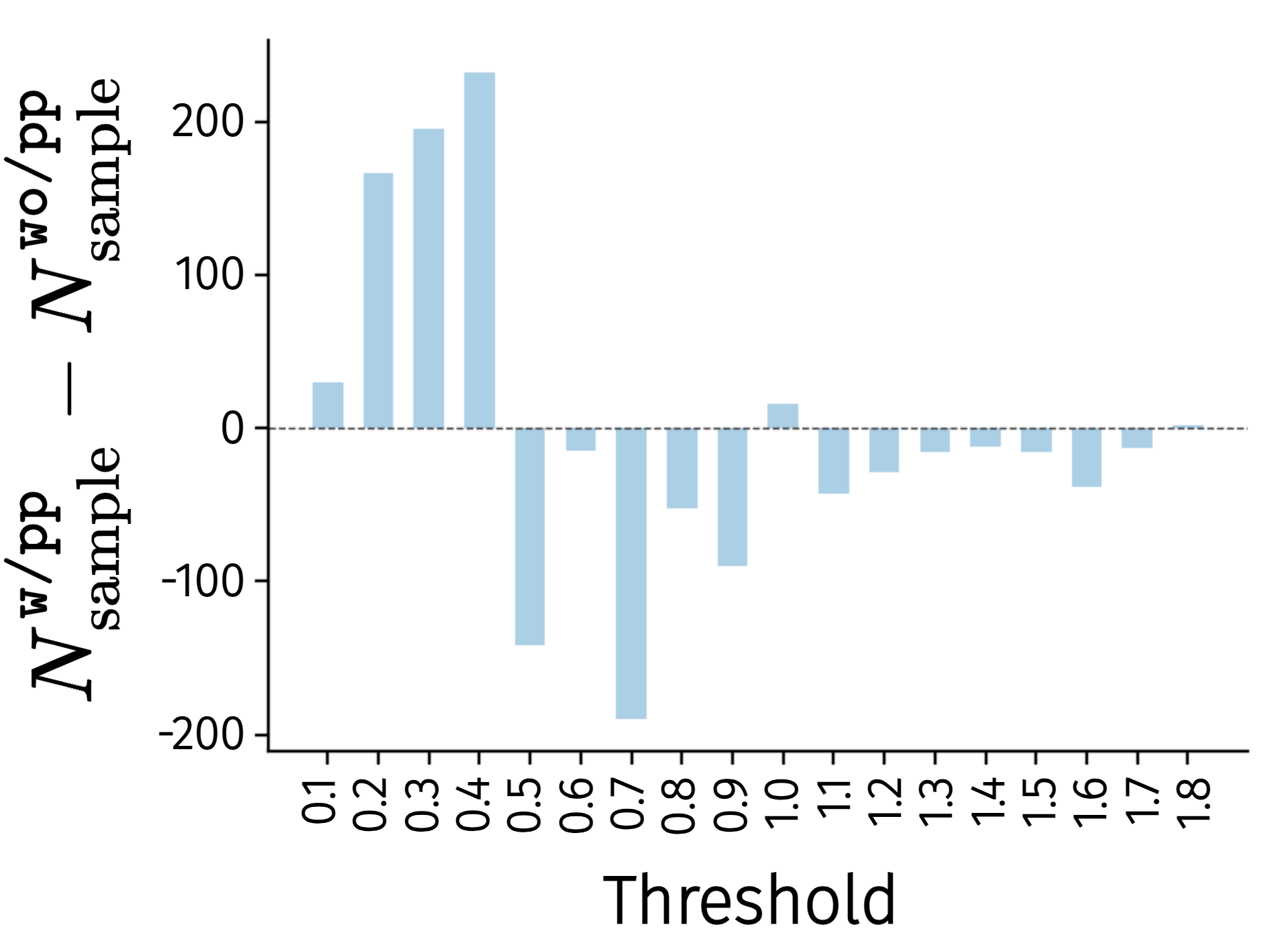
4.1 Does LAM learn better latent actions?
The author compares \texttt{w/pp} with proprio-FDM and \texttt{wo/pp} without. After freezing LAM on LIBERO, use 3-layer MLP to predict robot action from latent action, and count the maximum L1 error. The results show that \texttt{w/pp} has more samples in the small error bin and fewer samples in the high error bin, indicating that proprio-FDM allows latent actions to carry more low-level action information.
4.2 SIMPLER ablation
| method | Google Avg. | WidowX Avg. | meaning |
|---|---|---|---|
| Ours | 58.5 | 40.8 | Complete LAM + ACT design. |
| wo/pp | 57.4 | 32.3 | Without proprio-FDM, the decrease is obvious on WidowX. |
| wo/LAM | 35.0 | 33.1 | Without using latent action, there is a huge drop-off on Google. |
| LAPA-style | 43.8 | 1.0 | Two-stage latent-action pre-training and then changing the action head, the structural transmission is weak. |
| Go-1-style | 32.8 | 14.8 | Independent latent planner + robot action prediction is not as good as joint diffusion. |
This table corresponds to two conclusions: proprio-FDM improves latent action quality; ACT's joint latent-robot modeling is more effective than LAPA/Go-1 style access.
4.3 ACT-latent's zero-shot planning capability
The authors tested ACT-latent on an unseen Realman robotic arm. Given a starting image and a language command such as "touch the corn", ACT-latent first generates a latent action sequence, which is then rendered into a video via a separately trained world/image FDM. The results show that the model can recognize open vocabulary symbol cards and generate reasonable touch/movement plans.

4.4 SIMPLER main results
| method | Google Avg. | WidowX Avg. | Remarks |
|---|---|---|---|
| RT-1-X* | 49.4 | 1.1 | Assessment directly after pretraining. |
| RoboVLMs | 60.8 | 37.5 | VLA baseline. |
| π0-FAST | 61.9 | 32.1 | Strong VLA/action baseline. |
| GR00T-N1.5 | 57.9 | 62.0 | world modeling / future embedding alignment. |
| Magma | 62.3 | 44.8 | visual trace method. |
| MoTo | 59.2 | N/A | latent-action method. |
| LAPA | N/A | 57.3 | latent-action method. |
| Ours w/o latent | 36.5 | 49.0 | Remove latent action expert. |
| Ours | 77.7 | 62.5 | Google/WidowX has the highest average. |
SIMPLER results show that villa-X achieves strong performance on both types of robots, and the gap with w/o latent proves that the latent-action expert makes a substantial contribution to the final strategy.
4.5 Real robot results
There are two real platforms: Realman RM75 + Inspire gripper, and XArm + 12-DoF XHand dexterous hand. Realman uses 375 teleop trajectories for fine-tuning, 75 for each of the five tasks;

| Realman indicator | GR00T | Ours w/o latent | Ours |
|---|---|---|---|
| Pick in | 30 | 40 | 30 |
| Pick out | 70 | 80 | 100 |
| Push | 10 | 30 | 50 |
| Stack | 10 | 60 | 50 |
| Unstack | 60 | 70 | 100 |
| Change block color | 50 | 40 | 60 |
| Change table cover | 30 | 30 | 60 |
| XHand tasks | Ours seen | Ours unseen | Key conclusions |
|---|---|---|---|
| Pick & Place | 84 | 68 | Better than GR-1, GR00T, w/o latent. |
| Stack Cube | 75 | 50 | unseen object/background still maintains its advantage. |
| Place Cup Upright | 60 | 30 | Seen/unseen are both the highest or tied for the highest. |
| Pour Water | 60 | 30 | It is still better than baseline in terms of complex and dexterous operation. |
| Flick Ball | 50 | 40 | unseen lower than baseline. |
4.6 LIBERO results
The appendix is evaluated on four suites, LIBERO-Spatial, Object, Goal, and Long. villa-X averages 90.1%, which is higher than π0-FAST's 85.5%, OpenVLA's 76.5, Octo-base's 75.1, and higher than itself w/o latent's 81.9. The full models in the four suites are Spatial 97.5, Object 97.0, Goal 91.5, and Long 74.5.
5. Appendix key information
Data size
The pre-training data contains a mix of robot data and action-free human videos. Robot data is about 1.6M trajectories / 223.5M frames, mainly from OpenX mixture and AgiBot; human videos are about 3.6M clips, from Ego4D/EgoHOD, EgoPAT3D, EGTEA, EPIC-KITCHENS, HO-Cap, HOI4D, HoloAssist, RH20T, Something-Something V2, etc.
LAM additional visualization
The appendix shows image pairs corresponding to the same latent action, illustrating that similar latent actions in different embodiments (including humans and robots) can correspond to similar low-level behaviors. It also demonstrated how to convert robot/human video demonstrations into SIMPLER robot actions through LAM + proprio-FDM and execute them, verifying that latent actions can be migrated from videos to robot actions.

Embodiment context ablation
Removing embodiment context will increase visual FDM/proprio FDM validation loss. When doing action probing for unseen Realman embodiments, Ours has lower overall probing loss, xyz, rotation, and gripper than w/o context, indicating that context helps the model separate-specific dynamics and improve the generalization of new embodiments.
policy ablation
Appendix policy ablation shows: Ours in Google Avg. 58.5, WidowX Avg. 40.8; w/o mask dropped to 53.2 / 34.0; w/o context dropped to 49.1 / 38.5. Note that attention mask and embodiment context are not decorations, but key designs that affect policy stability.
6. Key points of reproducibility and implementation
Minimum recurrence path
- Prepare robot trajectories and human videos; robot data must include observation, state, action, dataset ID, and control frequency.
- Training LAM: ST-Transformer IDM predicts latent tokens from \(T_{\text{LAM}}=8\) frames; visual FDM reconstructs future images; proprio-FDM predicts future states/actions; human videos skip proprio loss.
- Use VQ codebook centers as continuous latent actions for ACT pretraining.
- Building ACT: PaliGemma 3B VLM encodes visual language; ACT-latent and ACT-robot are 18-layer Transformer experts respectively.
- Use conditional flow matching to jointly train latent action sequence and robot action chunk; set up block-wise causal attention and robot-to-latent stochastic masking.
- Fine-tune state/action projection, action decoder and other modules according to the target embodiment, and add wrist camera feature if necessary.
- Evaluation by task distribution on SIMPLER/LIBERO/real robots.
7. Analysis, Limitations and Boundaries
The most valuable part of this paper
It advances latent action from "pseudo action token compressed from video" to "intermediate action representation calibrated by physical state and action supervision". This is important because robot control is not purely visual prediction: many key actions are hidden in pixels but very explicit in proprio/action space. The second value of villa-X is the policy structure design. It does not use latent action as a bypass auxiliary task, but allows ACT-latent and ACT-robot to form a clear dependency in joint diffusion, truly connecting the middle-level plan to the low-level control.
Why does the result stand?
- The evidence chain is relatively complete: probing proves that latent action is better at predicting robot action; SIMPLER ablation proves that proprio-FDM and latent action expert are effective for policy; the main results prove that it has advantages over multi-class baselines.
- Evaluation area width: SIMPLER covers Google Robot/WidowX embodiment, LIBERO covers Spatial/Object/Goal/Long, and the real world covers both gripper and dexterous hands.
- Ablation such as w/o latent, wo/pp, LAPA-style, Go-1-style, w/o mask, w/o context, etc. can disassemble and verify the main designs one by one.
- The appendix provides more details on data size, architecture, and training, explains performance sources, and exposes reproducibility costs.
Main limitations
- Training costs are extremely high: The threshold for 100-calorie pre-training is high and it is difficult for ordinary laboratories to completely reproduce it.
- The zero-shot of latent expert is not a complete closed-loop execution.: The symbol card experiment mainly checks the latent plan through world/FDM rendering, which is not equivalent to successful execution directly on any unseen robot.
- Still need embodiment-specific finetuning: Realman/XHand both need to be fine-tuned according to the platform data, and cannot be understood as completely free of data generalization across robots.
- proprio grounding relies on robot state/action annotation: Human videos do not have proprio branches and can only participate in LAM training through visual targets.
- Some tasks are still not perfect: Realman Pick in, XHand unseen pour/cup, etc. still have obvious room for failure, indicating that latent action is not a universal bridge.
Questions to ask while reading
- Which actions do the physical grounding learned by proprio-FDM help most: rotation, gripper, contact, or long-distance movement?
- Why are continuous codebook centers more stable than discrete tokens in ACT?
- Can ACT-latent predicted latent plans be individually evaluated, filtered, or corrected using a VLM critic?
- Can we make better use of human videos if we use hand poses and end-effector keypoints instead of proprio state?
- w/o latent isn't bad at some real tasks either, which scenarios does latent action expert really provide the most benefit?