Video Generators are Robot Policies
1. 论文速览
| 阅读定位 | 内容 |
|---|---|
| 论文要解决什么 | 当前 visuomotor policy 在新物体、新背景、新任务等感知或行为分布偏移下泛化不足,同时真实机器人动作示教昂贵。论文希望利用大规模视频生成模型中学到的动态世界先验,减少对带动作标签示教数据的依赖。 |
| 作者的方法抓手 | 让视频生成模型先生成机器人完成任务的未来多视角视频,再把视频 U-Net 中间层特征送入动作 U-Net 预测未来机器人动作。关键训练选择是两阶段训练:先调视频生成,再冻结视频 U-Net 训练动作头,并阻断动作损失回传到视频网络。 |
| 最重要的结果 | 在 RoboCasa 上,Video Policy 使用 50 demos 达到平均成功率 0.63,高于 DP-VLA 0.57、GR00T 0.50、UVA 0.50;300 demos 时到 0.66。在 Libero10 上平均成功率 0.94,高于 UVA 0.90 和 $\pi_0$ 0.85。两阶段训练消融为 0.63,联合训练为 0.57,不调视频模型仅 0.09。 |
| 阅读时要注意的点 | 不要把它简单理解成“视频模型直接控制机器人”。动作仍由专门的动作扩散头输出,视频生成模型主要提供面向未来动态的中间表征。还要注意它的高计算成本:附录给出 8 张 A100 约两周训练,A100 上 25 帧视频一次生成约 9 秒。 |
核心贡献清单
- 提出 Video Policy 框架:把 Image-to-Video Stable Video Diffusion 改造成闭环机器人策略,联合生成未来视频和动作。
- 系统分析视频目标与动作目标的关系:消融显示先学会生成机器人执行视频,再训练动作解码头,比端到端联合训练更好。
- 验证 action-free video 的价值:视频生成模型可用所有任务的视频进行训练,而动作头只在一半任务上训练时,仍能迁移到未提供动作监督的任务。
- 覆盖模拟和真实机器人:实验包括 RoboCasa、Libero10 以及 5 个真实任务,真实任务测试了物体位置、未见物体和未见背景三类泛化。

2. 背景与问题设定
2.1 要解决的核心矛盾
机器人行为克隆已经能在许多操作任务上工作,但常见弱点是分布偏移:训练时见过的物体、背景、位置、任务组合有限,测试时稍微改变就可能失败。计算机视觉和 NLP 可以靠更大数据集覆盖长尾,但机器人动作示教收集成本高,尤其是真实世界 demonstrations 更贵。
作者把视频生成模型视为一个可利用的中间资源:互联网和机器人视频中存在大量没有动作标签的视频,它们可以帮助模型学习“从当前场景到未来任务执行过程”的动态先验。论文的问题不是单纯提高视频质量,而是证明这种像素级未来预测是否能稳定地服务于动作生成。
2.2 前作卡在哪里
- 纯行为克隆:直接从图像到动作,强依赖带动作标签的 demonstrations,对新物体和新背景的泛化有限。
- 把视频模型当世界模拟器:可以生成未来场景,但若靠手工跟踪或后处理把视频变成动作,表达能力受限。
- 学习动作解码器:如果动作解码器承担了太多策略学习,它本身又会受限于动作示教数据规模。
- 联合视频-动作生成的并行工作:作者认为已有工作缺少一致 benchmark 和详细消融,难以判断成功来自视频目标、动作目标,还是架构细节。
2.3 本文的高层思路
本文把策略拆成两个角色:视频生成器 $f$ 负责“想象”任务执行过程,动作模型 $g$ 负责把 $f$ 的中间特征解码成机器人动作。作者的核心假设是:只要视频生成模型能准确合成机器人执行任务的未来视频,那么动作解码器可以比较小,主要承担接口转换,而不是重新学习完整任务策略。
3. 相关工作脉络
| 技术线 | 论文中的定位 | 与本文的区别 |
|---|---|---|
| Behavior Cloning | 从 demonstrations 监督学习动作,近年来常用 diffusion policy 处理多模态动作。 | 本文不是只从视觉编码到动作,而是显式训练视频扩散模型预测未来像素,再用动作扩散头解码。 |
| Visual Pretraining for Policy Learning | 视频预测、对比学习、MAE 等用于获得更稳健的视觉表征。 | 本文把视频预测作为策略学习的代理目标,并通过成功率、预测 horizon、action-free video 消融验证作用。 |
| Video Models for Decision-Making | 视频生成模型可用于世界模拟、长程规划或联合像素-动作生成。 | 本文强调在同一框架内系统比较视频/动作训练目标,并给出 RoboCasa、Libero10、真实机器人评估。 |
4. 方法细节
4.1 整体形式化
输入是初始场景图像 $v_0$ 和语言任务描述 $c$。模型要输出一段机器人末端动作 $a_t \in \mathbb{R}^k$。论文把策略写成:
直觉:先生成未来执行视频,再从视频生成器的中间表征中读出动作。
$$ \{\hat v_t\}=f(v_0,c), \qquad \{a_t\}=g(\psi_0,\ldots,\psi_i), \quad \psi_i=f_i(v_0,c) $$其中 $f$ 是视频生成器,$f_i$ 表示视频生成器第 $i$ 层隐藏特征;$g$ 是动作解码模型。这里的关键不是最终像素本身,而是视频生成过程中形成的 spatiotemporal features。
4.2 架构:Video U-Net + Action U-Net
作者基于 Image-to-Video Stable Video Diffusion。视频 U-Net $\mu_\theta$ 接收两类条件:一类是任务文本 $c$ 的 CLIP embedding $\phi(c)$,通过 cross-attention 注入;另一类是输入图像 $v_0$ 经 SVD 冻结 VAE 得到的 latent $z_0=\mathrm{VAE}(v_0)$,与未来 noisy frames 的 latent 按 channel 拼接。
动作端是一个 adapted Diffusion Policy 的 1D CNN U-Net $\alpha_\theta$。在每个 denoising step $i$,从视频 U-Net decoder 的 5 个层取隐藏特征,论文给出层号为 9、14、17、20、23;这些 spatiotemporal features 经过 CNN adapter 压成向量 $h_i$,作为动作 U-Net 的 global conditioning。
动作生成不是看最终视频帧后再做后处理,而是在每个去噪步与视频生成同步发生。
$$ \{a_t\}=\alpha_\theta(a_i,i,h_i) $$$a_i$ 是带噪动作,$i$ 是 diffusion denoising step,$h_i$ 是视频 U-Net 的中间特征。这个设计让动作头依赖视频模型正在构建的未来动态表征。
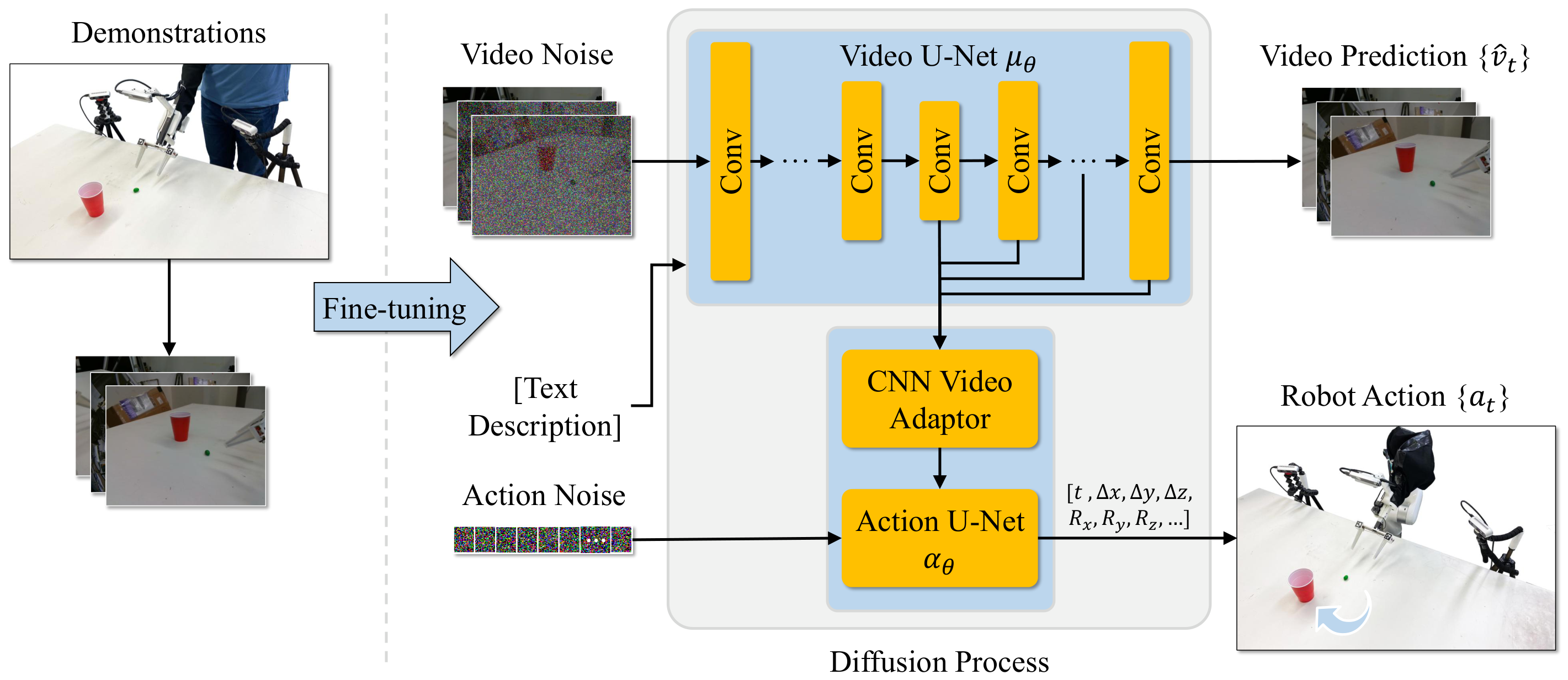
4.3 训练目标
训练数据 $D=\{d_1,\ldots,d_n\}$ 中,每个 demonstration 包含视频观察 $\{v_t\}$、任务文本 $c$ 和动作 $\{a_t\}$。视频模型训练目标为标准 diffusion 噪声预测:
$z_i$ 是带噪视频 latent,$z_{i,0}$ 是第一帧对应的 noisy latent embedding,目标是让视频 U-Net 预测噪声 $\epsilon$。
动作头同样以 diffusion 噪声预测训练。作者明确阻断 $L_{\mathrm{action}}$ 对视频 U-Net $\mu_\theta$ 的梯度回传,让视频网络主要由像素未来预测目标驱动。
4.4 两阶段训练为什么重要
论文比较了 joint training 和 2-stage training。两阶段版本先用 RoboCasa 训练集微调 SVD 做视频生成,再冻结视频 diffusion U-Net,训练动作 denoising head。实验显示两阶段平均成功率 0.63,高于 joint 的 0.57;不微调视频模型、只用 vanilla SVD 特征时仅 0.09。这支持作者的解释:像素空间中的未来视频生成目标比动作生成目标更一般,视频模型需要先对“机器人执行策略的视频”完成任务域适配。
5. 实验与结果
5.1 实验设置
模拟实验覆盖 RoboCasa 和 Libero10,共 34 个操作任务。两个 benchmark 每个任务提供 50 条 human demonstrations。RoboCasa 遵循官方协议,每个任务在 5 个 RoboCasa scenes 中评估 50 次 rollout;Libero10 遵循 UVA 使用的评估协议。
动作空间为 $a_i\in\mathbb{R}^7$,包括 6-DoF gripper pose 和一个开合标量。输入视觉包括三路相机:gripper-mounted camera 以及左右侧相机。训练时每个相机预测 8 帧,总共 24 帧;为了适配 SVD 的 25 帧输入格式,在序列起始 pad 一帧。
5.2 RoboCasa 主结果
| 方法 | 平均任务成功率 | 备注 |
|---|---|---|
| 3DA | 0.06 | 显式 3D 表征基线 |
| DP3 | 0.23 | 3D diffusion policy 相关基线 |
| DP-ResNet | 0.41 | 本文复现实验,ImageNet 预训练 ResNet |
| DP-CLIP | 0.43 | CLIP 视觉语言表示变体 |
| GR00T | 0.50 | 使用 300 demos |
| FPV | 0.51 | 前视/3D 类强基线 |
| DP-VLA | 0.57 | 使用 3000 MimicGen 自动 demonstrations |
| UVA | 0.50 | 联合视频动作生成并行工作 |
| Video Policy, 50 demos | 0.63 | 本文主模型,50 demos/任务 |
| Video Policy, 300 demos | 0.66 | 更多 MimicGen demonstrations 后进一步提升 |
最值得读的细节是 Pick and Place 类任务。作者指出这类任务训练和测试之间有明显物体位置/类别分布偏移,而 Video Policy 在该类任务上提升尤其明显。例如 PnPStoveToCounter 在 50 demos 下为 0.64,PnPSinkToCounter 为 0.64,显著高于 GR00T 300 demos 的 0.29 和 0.33。
5.3 Libero10 主结果
| 模型 | DP-C | DP-T | OpenVLA | UniPi | $\pi_0$ | $\pi_0$-FAST | UVA | Ours |
|---|---|---|---|---|---|---|---|---|
| 平均成功率 | 0.53 | 0.58 | 0.54 | 0.00 | 0.85 | 0.60 | 0.90 | 0.94 |
附录给出逐任务结果,Video Policy 在 10 个 Libero10 任务上的平均为 0.94,其中 4 个任务达到或接近 1.00,最低的 KITCHEN SCENE8 任务为 0.80。
5.4 消融:视频目标到底有没有用
| 变体 | RoboCasa 平均成功率 | 解释 |
|---|---|---|
| Joint | 0.57 | 视频与动作目标端到端联合训练 |
| 2-Stage | 0.63 | 先训练视频生成,再冻结视频 U-Net 训练动作头 |
| No Video Tuning | 0.09 | 不把 SVD 微调到机器人执行视频,仅训练动作头 |
| Half Tasks | 0.41 | 动作头只在一半任务上训练,但视频模型可看所有任务视频 |
| DP Half Tasks | 0.21 | ResNet Diffusion Policy 只在一半任务上训练 |
这个表是论文论证链的关键。No Video Tuning 的 0.09 说明“直接拿预训练 SVD 特征”不足够;2-Stage 的 0.63 说明视频模型必须先适配到机器人执行轨迹,并且动作头最好作为冻结视频表征上的解码器。
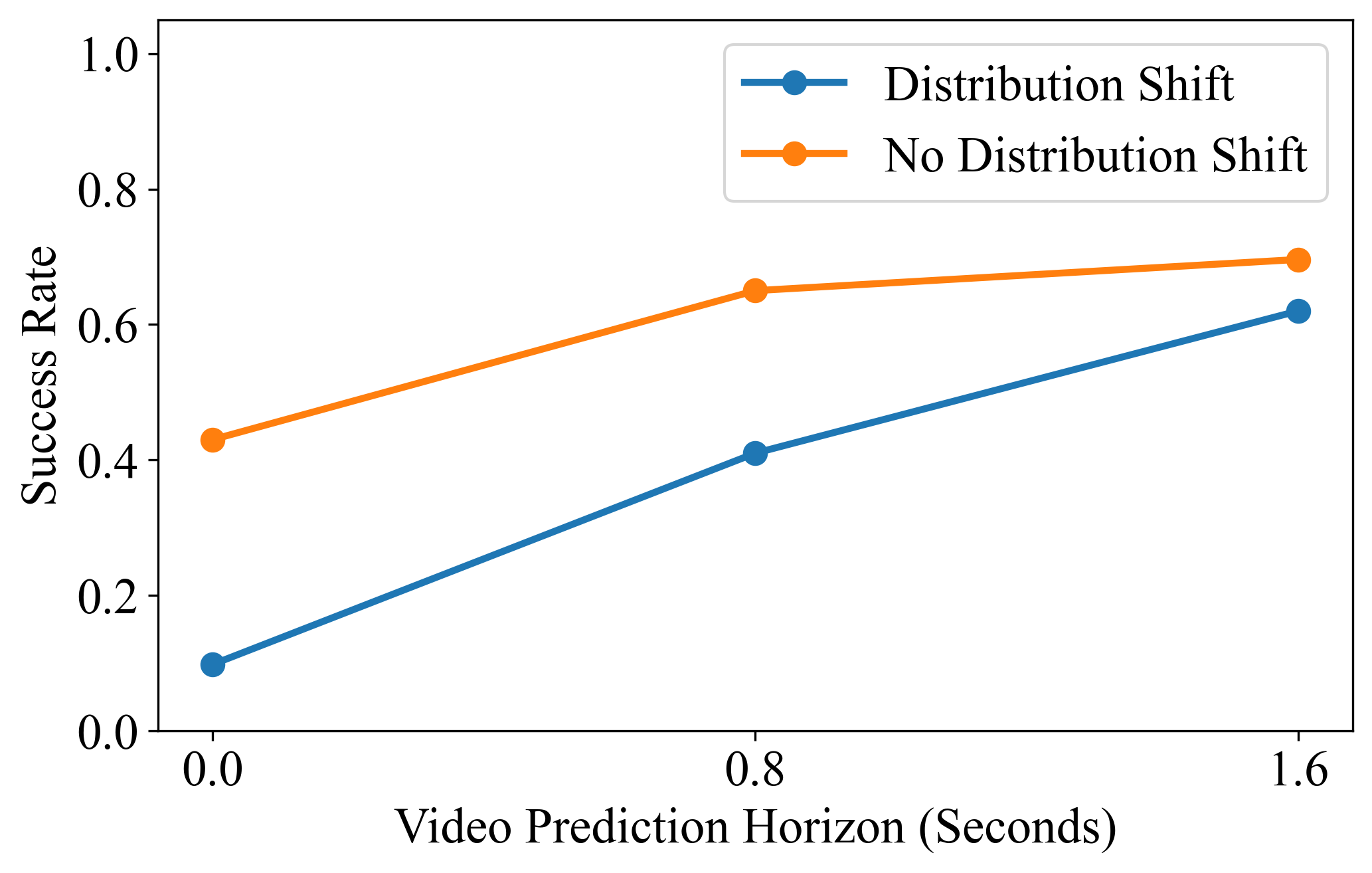
5.5 预测 horizon 与 action-free video
作者固定动作预测为未来 1.6 秒,改变视频预测 horizon。附录中用于 horizon 分析的协议不同于标准 RoboCasa:作者采样 MimicGen 环境,以隔离分布偏移影响。逐任务表显示 32-step 视频 horizon 平均 0.67,16-step 为 0.55,0-step 为 0.30;在 pick-and-place 这类分布偏移任务上差距更明显。
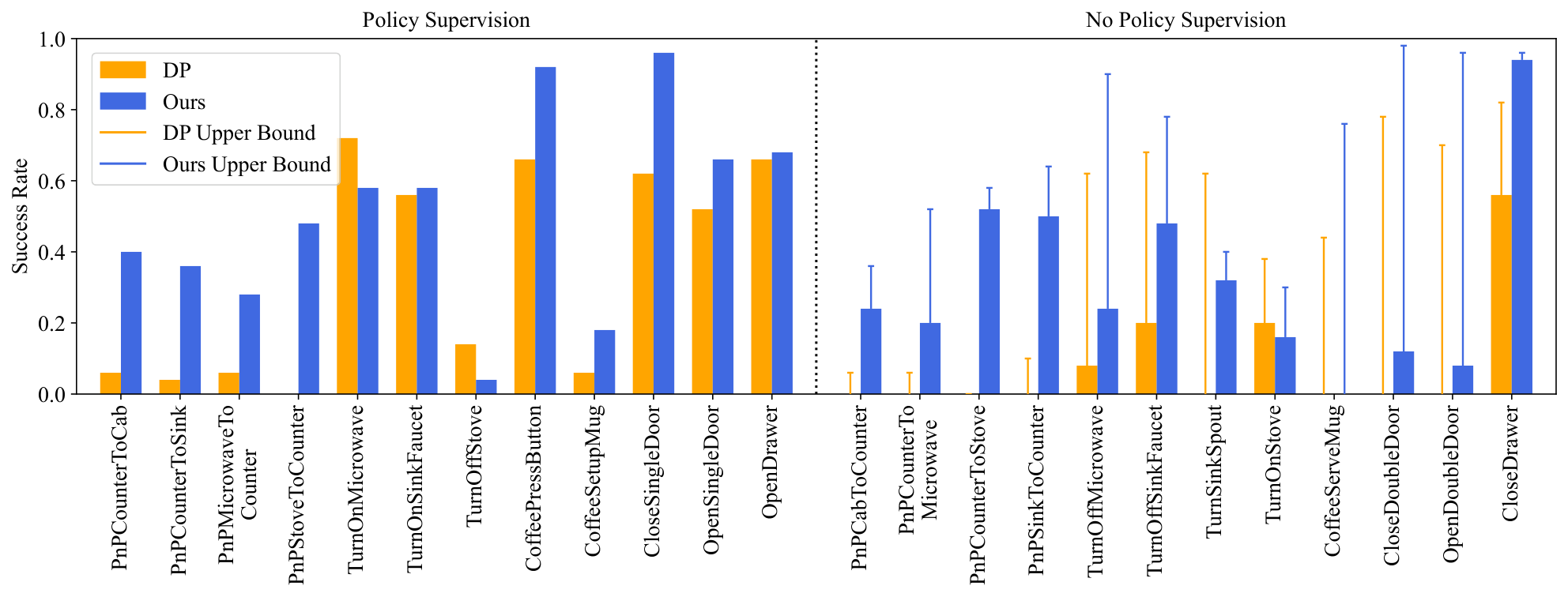
5.6 真实机器人结果
真实实验包含 5 个任务:Open Drawer、Pick and Place、M&Ms to Cup、Upright Object、Stack Cups。每个任务收集 200 条 demonstrations,并测试三类泛化:物体位置变化、未见物体、未见背景。每个条件用 10 次 rollouts 计算成功率。
| 任务 | Vary Object Location | Unseen Objects | Unseen Background |
|---|---|---|---|
| Open Drawer | 0.8 | 1.0 | 0.9 |
| Pick and Place | 1.0 | 0.9 | 0.8 |
| M&Ms to Cup | 0.8 | 0.9 | 0.2 |
| Upright Object | 0.3 | 0.7 | 0.8 |
| Stack Cups | 0.3 | 0.2 | 0.2 |
真实实验的失败也很有信息量。作者明确指出 Upright Object 和 Stack Cups 的失败常来自不现实的视频预测,例如未能生成正确竖立放置,或生成了 gripper 导致杯子倾倒的轨迹。M&Ms to Cup 在未见背景下降到 0.2,原因是背景颜色变化影响了对小物体的精确定位。

6. 复现与实现要点
6.1 视频模型实现
- 基础模型:预训练 Image-to-Video Stable Video Diffusion,生成 25 帧视频序列。
- 多视角编码:RoboCasa 中第 1 帧是 padded frame,第 2-9 帧为 gripper view,第 10-17 帧为 left camera,第 18-25 帧为 right camera;作者修改 per-frame image embedding 表示相机视角。
- 动作 horizon:默认生成每个视角 8 帧,并表示 32-step prediction horizon;视频以 stride 4 subsample。
- 推理设置:30 denoising steps,classifier-free guidance scale 为 2.0;A100 上 256×256、25 帧、30 diffusion steps 约 9 秒。
6.2 训练超参数
| 模型 | 分辨率 | 学习率 | Batch | Steps | Precision |
|---|---|---|---|---|---|
| Joint Training | 256×256 | 1e-5 | 32 | 368866 | 16-mixed |
| 2-Stage Training | 256×256 | 1e-5 | 32 | 368866×2 | 16-mixed |
| No Video Tuning | 256×256 | 1e-5 | 32 | 368866 | 16-mixed |
| 2-Stage Libero10 | 256×256 | 1e-5 | 32 | 170000+140000 | 16-mixed |
| Real World | 256×192 → 448×320 | 1e-5 | 32 | 331500+92960 | 16-mixed |
6.3 Baseline 复现细节
- UVA baseline:初始化使用预训练 VAE 和 MAR image generation model,修改为三张图像条件输入,并生成三路相机视角的 256×256 视频。
- Diffusion Policy baseline:使用 UMI 实现,训练 ResNet18 和 CLIP-Base 两种变体;任务名称用同一 CLIP text encoder 编码后与图像 embedding 拼接为 global context。
- DP baseline 也使用三路相机分别编码。ResNet 输入 256×256,CLIP 输入 224×224,batch size 为 768,预测未来 32 steps,在模拟中 rollout 16 steps。
6.4 真实机器人设置
真实 demonstrations 由人用改造手持 gripper 收集。左右侧相机是 Intel RealSense D435,gripper-mounted camera 是 Basler fisheye camera;gripper pose 由 RealSense T265 追踪,开口由 ArUco marker 估计,夹持力由单轴力传感器测量,所有传感器运行在 30 Hz。
模型输入三路 RGB 图像,预测未来 32 步相对 gripper pose、相对夹爪位置和绝对抓取力。部署时机器人使用 impedance control 执行其中 24/32 步。若预测夹持力比实际测量值高 300g 以上,系统会加入小的 gripper closing correction,防止抓取力不足。

7. 分析、局限与边界
7.1 这篇论文最有价值的地方
最有价值的地方是把“视频生成能否作为策略学习代理目标”变成了可检验的工程问题,而不是只给出定性演示。论文用同一架构同时比较 joint、2-stage、no video tuning、half tasks、不同 video horizon,并把结论落在成功率上:2-stage 高于 joint,不调视频模型几乎失效,长视频 horizon 更好,action-free videos 能帮助未见动作监督任务。这些消融直接服务于核心命题。
7.2 结果为什么站得住
- 多个 benchmark:模拟实验覆盖 RoboCasa 和 Libero10,共 34 个任务,不只是一两个 demo。
- 比较对象强:RoboCasa 中和 DP-ResNet、DP-CLIP、GR00T、DP-VLA、UVA 等比较;Libero10 中和 $\pi_0$、$\pi_0$-FAST、UVA 等比较。
- 消融围绕因果链:No Video Tuning 0.09 排除了“随便拿 SVD 特征就够”的解释;2-Stage 0.63 高于 Joint 0.57 支持“让视频目标主导表征”的设计;32-step horizon 0.67 高于 16-step 0.55 和 0-step 0.30,说明未来动态预测长度与策略泛化相关。
- 真实机器人验证边界:真实实验不是只展示成功案例,还给出失败任务和失败原因,例如 Stack Cups、M&Ms to Cup 在某些分布偏移下失败。
7.3 作者给出的局限
- 规模边界:作者承认研究限制在有限规模的 simulation benchmarks 和单一真实机器人 embodiment 上。更广泛任务、环境和机器人形态还需要验证。
- 模型族边界:本文只探索了 Stable Video Diffusion 这一种视频生成模型实例。结论是否对其它视频模型家族稳定成立,需要更大范围测试。
- 计算成本:视频扩散模型推理和训练成本高。附录的 A100 训练时间和单次视频生成耗时说明它离实时低成本部署还有距离。
- 真实物理先验不足:真实实验中 Upright Object 和 Stack Cups 的失败被归因于不现实视频预测,说明 SVD 预训练并不自动拥有足够强的真实接触物理先验。
7.4 适用边界
从论文证据看,Video Policy 更适合视觉分布偏移明显、但任务仍可通过短期未来视频表达的操作任务,例如 pick-and-place、开关门、按按钮等。对于需要极精确小物体定位、强接触物理、实时响应或跨 embodiment 迁移的场景,论文当前证据较弱。
7.5 组会阅读提醒
- 读方法时关注“视频模型是策略”这句话的技术含义:它不是输出动作,而是提供动作解码依赖的未来动态表征。
- 读实验时优先看 Table 1、Table 3、Figure 3、Figure 4,它们分别对应主结果、训练目标消融、预测 horizon、action-free video。
- 读局限时不要忽略计算成本和真实失败案例。论文的 claim 是视频生成能显著正则化策略学习,不是已经解决实时机器人控制。