NovaFlow: Zero-Shot Manipulation via Actionable Flow from Generated Videos
这是一篇把“生成式视频”转成“可执行 3D 物体流”的机器人操作论文。它的核心主张不是训练一个新的 VLA 策略,而是把视频模型里的常识动作先蒸馏成物体运动,再交给传统几何、抓取和轨迹优化模块执行。
1. 论文速览
| 论文要解决什么 | 让机器人在没有任务演示、没有目标机器人专用训练数据、没有预定义技能库的情况下,根据语言指令和初始图像完成真实世界操作任务,包括刚体、关节物体和可变形物体。 |
|---|---|
| 作者的方法抓手 | 先用大规模视频生成模型产生“人类视角下任务应如何发生”的视频,再通过深度估计、3D 点跟踪、物体分割和 VLM 拒绝采样,把视频蒸馏为 actionable 3D object flow;随后用抓取提议、Kabsch 位姿估计、模型规划和轨迹优化把物体流变成机器人动作。 |
| 最重要的结果 | NovaFlow 在真实 Franka 桌面任务上整体超过零样本基线 AVDC、VidBot,也超过使用 10 或 30 条演示训练的 Diffusion Policy 和 IDM;在 block insertion 消融中,目标图像使 Wan2.1 的 video success 从 15% 升到 46%,task success 从 40% 升到 80%。 |
| 阅读时要注意的点 | 这篇论文的亮点在“表示和系统组合”,不是端到端策略学习。需要特别看清楚:生成视频并不直接控制机器人,真正可执行的是经过 3D 标定、物体过滤和 VLM 选择后的 object flow;最终失败也主要落在抓取和真实执行,而非全部归因于视频生成。 |

2. 问题设定与动机
论文瞄准的是一个非常现实的断点:大模型已经能生成“这个任务大概怎么做”的视频,但机器人策略通常还需要大量本体相关数据。VLA 模型的瓶颈在于 robot-specific data,模块化方法则常常需要预定义 primitive、手写技能或真实演示。
作者把问题重新拆成两层。第一层是“从语言和图像理解任务中的物体应如何运动”,这交给视频生成模型和视觉基础模型。第二层是“机器人如何实现这个物体运动”,这交给几何控制、抓取、模型规划和轨迹优化。这样做的关键是找到一个中间表示:actionable 3D object flow。
3. 相关工作定位
3.1 视频到操作
已有 video-based manipulation 通常要么需要机器人数据和 inverse dynamics,要么依赖从视频中学一个策略或 affordance 模型。NovaFlow 的不同点在于,它不训练一个新的跨本体策略,而是把现成视频模型生成的运动轨迹转成 3D object flow,再通过下游控制模块执行。
3.2 物体中心表示与 flow
6D pose 或 object-centric 方法对刚体很自然,但对绳子、布料这类可变形物体并不够。Flow 表示更通用,可以描述局部点的移动,也能兼容刚体、关节物体和可变形物体。论文的赌注是:3D object flow 足够接近“任务意图”,又足够接近“机器人可执行”。
3.3 与 VLA / 模块化规划的关系
NovaFlow 和 VLA 的差异不是是否使用大模型,而是学习信号来自哪里。VLA 往往需要机器人动作数据;NovaFlow 借用视频模型里的常识运动,再用传统机器人模块补上执行性。它和 LLM/VLM+planner 的模块化路线相近,但把“技能库”替换成了从视频中抽取的任务特定 3D flow。
4. 方法精读
4.1 总体管线
NovaFlow 有两个核心模块:flow generator 和 flow executor。前者负责从语言、初始图像和可选目标图像中产生 3D object flow;后者负责把 object flow 变成真实机器人动作。
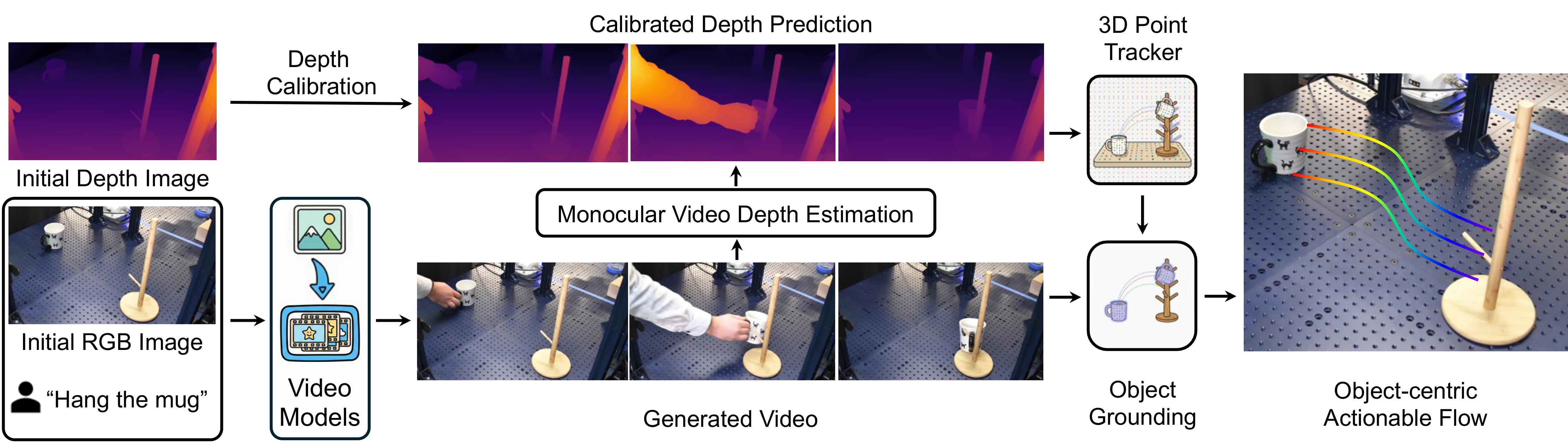
4.2 视频生成:把任务语言变成候选运动
输入包括初始 RGB 图像 I、语言指令 l,以及在精密放置任务中可选的目标图像 I_g。如果没有目标图像,系统使用 image-to-video;如果有目标图像,则使用 first-last-frame-to-video,让生成视频同时满足起点和终点。
实现上,作者使用 Wan2.1 作为开源视频模型,也测试了 Google Veo。Wan2.1 生成 41 帧、1280x720、16 FPS;Veo 生成 8 秒 24 FPS 视频后下采样到 41 帧。appendix 还说明,Wan2.1 官方更推荐中文 prompt,作者也观察到中文 prompt 质量更好。
4.3 3D lifting:从视频像素到 3D object flow
生成视频本身只有像素运动。为了让它可执行,NovaFlow 先用 MegaSaM / MoGe 估计每帧深度,再用初始真实深度图做尺度标定。具体做法是比较第一帧估计深度与初始真实深度的 median depth,得到尺度因子后乘到所有估计深度上。
随后系统使用 TAPIP3D 做 3D 点跟踪。appendix 给出的参数是:在第一帧用 32 x 32 均匀网格采样 query points,tracker iteration 设为 6。这里强调的是 3D XYZ 空间中的点跟踪,而不是只在 2D UVD 空间中跟踪像素。


4.4 Object grounding:只保留目标物体的 flow
密集 3D tracking 会覆盖整个图像,但机器人只需要目标物体的运动。作者使用 Grounded-SAM2 pipeline,即 Grounding DINO 加 SAM2。系统把目标物体名作为 query,提取视频中的物体 mask,然后用 mask 过滤 3D tracks,只保留始终可见且属于目标物体的点。appendix 给出的阈值是 bbox threshold 0.25、text threshold 0.3,并选择 Grounding DINO 得分最高的框作为 SAM2 prompt。
4.5 VLM rejection sampling:处理生成模型幻觉
视频生成模型可能产生不物理、不连续、对象错位或任务不对齐的视频。NovaFlow 不直接相信单个生成结果,而是一次生成多个候选 3D object flow,将 flow 投影回第一帧形成带编号的 2D flow image,再交给 Gemini 2.5 Pro 选择最合理的候选。
VLM 判断标准包括 motion continuity、自然运动、目标物体识别是否正确、是否符合任务要求。论文特别指出,flow image 比原始拼接视频更适合 VLM 选择,因为它把“哪个物体怎么动”显式展示出来。

4.6 Flow executor:刚体、关节物体与可变形物体

对于刚体和关节物体,NovaFlow 先从目标物体点云中用 GraspGen 产生 grasp proposals。给定 object flow 后,系统用 Kabsch algorithm 根据关键点前后位置估计每个时间步的刚体变换 (R_t, t_t)。在“抓牢且不滑移”的假设下,物体位姿变化可以转成末端执行器位姿变化。
对于可变形物体,刚体位姿不再成立。论文使用 PhysTwin 这类粒子动力学模型,把 3D object flow 作为 tracking objective 做 model-based planning。这里 flow 的价值是给出稠密、任务相关的目标运动,而不是把绳子简化成一个刚体 pose。
4.7 轨迹优化
appendix 给出了执行阶段的轨迹优化。系统要找一串关节配置 Q = {q_0, ..., q_{T-1}},目标是平滑、接近 rest pose,并满足起止 IK、关节限制和碰撞安全距离。优化由线性插值初始化,然后用 Levenberg-Marquardt 解非线性最小二乘;实现使用 PyRoki 和 JAX。
权重设置中,joint limit penalty 为 w_l = 100.0,smoothness 为 w_s = 10.0,collision 为 w_c = 15.0,rest position 为 w_r = 0.1。这些细节说明论文不是只停留在“视频理解”,而是认真补了机器人执行层。
5. 实验与结果
5.1 硬件和任务
实验使用 Franka 机械臂加 Robotiq-85 夹爪做桌面操作,并用 Spot 四足移动机器人展示跨本体移动操作。刚体和关节物体任务只用一台 RealSense D455 深度相机;可变形物体因为 PhysTwin 的要求使用三台同步相机,作者也说明单视角设置理论上可行。
任务包括六类:挂杯子、插入黄色方块、把杯子放到碟子上、给植物浇水、打开抽屉、拉直绳子。每个任务 10 次试验,每次随机改变物体放置位置。

5.2 Baselines
| 类别 | 方法 | 对比意义 |
|---|---|---|
| Demo-free / zero-shot | AVDC | 把生成视频中的 2D optical flow 直接用于操作,检验“没有 3D actionable 表示”会损失什么。 |
| Demo-free / zero-shot | VidBot | 从大规模人类交互数据学 affordance flow,检验 learned affordance flow 与 generated video flow 的差异。 |
| Data-dependent | Diffusion Policy, 10 / 30 demos | 每个任务用少量演示训练的模仿学习基线;这是更有利于 baseline 的单任务设置。 |
| Data-dependent | IDM from UniPi, 30 demos | 训练 inverse dynamics,把 Wan2.1 生成的机器人任务视频转成动作,检验“视频到动作”路线是否抗 domain shift。 |
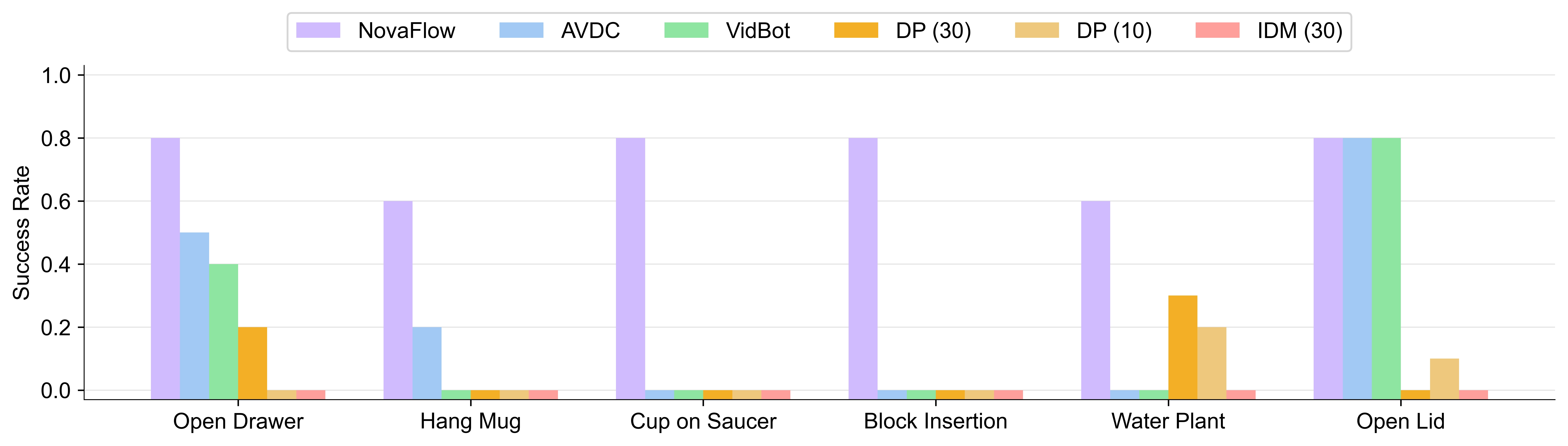
5.3 主结果
论文报告 NovaFlow 在所有任务上取得零样本方法中最高的成功率,并且整体超过使用 10 或 30 条演示训练的数据依赖基线。AVDC 在 affordance 类任务上有一定竞争力,但缺少 3D awareness 和长时一致性,在精确放置和旋转任务上弱。VidBot 对打开抽屉这类 affordance-centric 任务较好,但对 object-object relation 和精确相对位姿不够稳。DP 的问题是少量演示下泛化差;IDM 的问题是训练于真实机器人视频,却要解释生成视频,存在明显 domain shift。
5.4 Goal image 消融
block insertion 是毫米级精度任务,作者比较了是否给目标图像,以及 Wan2.1 与 Veo 的差异。指标有两个:Video Success 表示生成视频中是否能抽取有效 actionable flow;Task Success 表示 VLM 在多个候选中选出 flow 后,机器人真实执行是否成功。
| 条件 | Video Success | Task Success | Time (s) |
|---|---|---|---|
| w/ Goal Image (Wan2.1) | 46% | 80% | 612 |
| w/o Goal Image (Wan2.1) | 15% | 40% | 612 |
| w/o Goal Image (Veo) | 75% | 80% | 20 |
这个表有两个信息。第一,对开源 Wan2.1 来说,目标图像显著提高精密任务可控性。第二,闭源 Veo 在无需目标图像时也能达到很高 video success,但成本和可控性由外部服务决定。
5.5 运行时间
| 模块 | MegaSaM | TAPIP3D | SAM2 | Total (Veo) | Total (Wan) |
|---|---|---|---|---|---|
| Time (s) | 100 | 5 | 8 | 133 | 725 |
在单张 NVIDIA H100 上,Veo 版本完整 flow generation 约 2 分钟。主要耗时来自视频生成和 3D lifting。Wan2.1 慢很多,但开源、可控、没有闭源 API 成本。
5.6 失败分析
作者把失败分成四类:video failure、tracking failure、grasp failure、execution failure。video failure 来自生成视频不物理、不 3D 一致或违背任务;tracking failure 多由纹理少、遮挡重、视频模型不一致导致;grasp failure 是接近方向、漏抓、滑移等;execution failure 包括碰撞、关节限制或轨迹跟踪失败。
6. 复现与实现细节
视频模型
Wan2.1 使用 I2V 和 FLF2V 两种模式,41 帧、1280x720、16 FPS;采样器为 UniPC,40 steps,noise shift 5.0,guidance scale 5.0。Veo 使用 veo-3.0-generate-001,8 秒、1280x720、24 FPS,再下采样到 41 帧。
Prompt 工程
Wan2.1 使用官方 prompt extension 模板,并用 Gemini 2.5 Pro 扩展成中文 prompt。Veo 使用 Vertex AI 的原生 prompt enhancement。
深度与跟踪
MegaSaM / MoGe 估计深度,初始真实深度图做 median scaling。TAPIP3D 在 XYZ 空间跟踪,query grid 为 32 x 32,iteration 为 6。
物体分割
Grounding DINO 加 SAM2。bbox threshold 0.25,text threshold 0.3;取最高分 bounding box 作为 SAM2 的输入 prompt。
执行模块
刚体任务使用 GraspGen、Kabsch 位姿估计和 PyRoki / JAX 轨迹优化;可变形任务使用 PhysTwin,把 object flow 作为 tracking objective。
计算预算
可一次并行生成 8 个候选 flow,再由 VLM 选择。appendix 提到 8 个候选可使用 8 张 H100 并行生成。

7. 分析、局限与边界
7.1 这篇论文最有价值的地方
最有价值的地方是提出并验证了一个很清楚的中间表示:actionable 3D object flow。它把视频生成模型的世界知识和机器人执行模块之间缺失的接口补上了。这个接口比语言计划更贴近几何执行,比低层动作更不依赖具体机器人,也比 2D flow 更能处理遮挡、深度和相对位姿。
另一个价值是系统组合很务实。作者没有声称视频模型已经能直接控制机器人,而是承认视频模型会幻觉、深度会有尺度问题、跟踪会漂、抓取会失败,然后用 depth calibration、object grounding、VLM rejection sampling 和 trajectory optimization 一层层把问题收窄。
7.2 结果为什么站得住
结果比较有说服力,原因有四个。第一,实验是真实机器人而不是纯仿真,并且覆盖刚体、关节物体、可变形物体和移动操作。第二,baseline 包含 zero-shot 方法和少样本数据依赖方法,能回答“是否只是没有和训练策略比”的疑问。第三,论文把关键设计放进消融,例如目标图像对 block insertion 的影响。第四,失败分析没有把所有错误推给下游,而是明确拆分 video、tracking、grasp、execution 四类瓶颈。
不过也要注意,主实验每任务 10 次,规模不算大;很多模块使用强大的现成基础模型和 H100 级计算资源。结果站得住,主要站在“证明路线可行和优于这些对照”这个层面,而不是证明已经能低成本、长期、闭环部署。
7.3 局限
- 开环执行:系统主要从一次生成的 flow 规划执行,遇到滑移、碰撞、物体状态偏移时缺少在线重规划。
- 依赖生成视频质量:如果视频模型无法生成物理合理、目标一致的任务视频,后续 3D flow 再精细也无源可用。
- 依赖感知堆栈:深度估计、3D tracking、SAM2 grounding 都可能失败,尤其在透明、反光、低纹理、强遮挡场景中。
- 抓取假设较强:刚体执行默认抓牢且不滑移,一旦物体在夹爪中转动或接触动力学复杂,Kabsch 到末端位姿的映射会失真。
- 成本和时延:Veo 版本快但闭源且收费;Wan2.1 版本开源但慢。并行 8 候选的 rejection sampling 对实验室资源友好,对实际部署未必经济。
7.4 边界条件
NovaFlow 最适合的场景是:目标物体可被视觉模型稳定识别,任务能通过物体运动描述,初始场景和生成视频之间差异不大,并且机器人有足够可靠的抓取和轨迹执行模块。它不适合需要高频触觉反馈、强接触动力学、长时间闭环纠错或隐含状态估计的任务。
8. 组会问答准备
Q1:为什么不用生成视频直接训练 inverse dynamics?
论文的 IDM baseline 就是在接近这个方向上做对比。问题是 inverse dynamics 训练于真实机器人演示,却要解释生成视频,生成视频的动作和机器人运动学不一定一致,domain shift 很大。NovaFlow 选择把视频转成 3D object flow,再用机器人自己的几何控制执行。
Q2:为什么 flow 比 6D pose 更合适?
6D pose 对刚体很好,但对绳子等可变形物体不自然;flow 可以描述多个点的运动,既能通过 Kabsch 退化成刚体位姿,也能作为可变形规划的 tracking objective。
Q3:VLM rejection sampling 是否只是挑图,不是真正理解物理?
它确实不是物理验证器,更像 execution-time 的候选筛选器。它能过滤明显错对象、错方向、不连续的 flow,但不能保证真实接触可行。所以后面仍需要轨迹优化、抓取检查和真实执行。
Q4:论文最大的下一步是什么?
闭环。当前系统证明了从生成视频到可执行 flow 的开环路线,但失败分析已经显示 last-mile grasp 和 execution 是主要瓶颈。把执行反馈反过来更新 flow、重新选择候选或在线 replanning,是最自然的下一步。
Q5:这篇论文和 VLA 路线是竞争还是互补?
更像互补。VLA 追求从大规模机器人数据中学动作;NovaFlow 追求用视频模型和机器人模块组合出零样本能力。未来可以把 actionable flow 作为 VLA 的辅助监督、规划中间状态,或作为 VLA 失败时的可解释 fallback。