Dual-Stream Diffusion for World-Model Augmented Vision-Language-Action Model
1. 论文速览
| 论文要解决什么 | 世界模型增强 VLA 往往要同时预测动作序列和下一状态视觉表征。动作是低维、时间平滑的控制序列;未来视觉状态是高维、空间结构化的视觉 token。统一 diffusion 容易产生模态冲突,纯 causal 分离又限制双向信息流。 |
|---|---|
| 作者的方法抓手 | 提出 DUST:MMDiT 双流架构、按模态独立采样噪声时间步 $(\tau_A,\tau_o)$、解耦 flow matching 损失,以及推理时 action/vision 异步采样。 |
| 最重要的结果 | 在 RoboCasa 和 GR-1 上相对 FLARE/GR00T-N1.5 有稳定增益;真实 Franka Research 3 平均成功率 0.677,高于 GR00T-N1.5 的 0.547 和 FLARE 的 0.557;BridgeV2 action-free video 预训练后 RoboCasa 100 demos 平均成功率从 0.501 提升到 0.585。 |
| 阅读时要注意的点 | 这篇文章的核心不是“加一个未来图像预测头”,而是用双时间步和双流结构让动作与未来观测在训练时互相约束,同时避免把两种统计结构差异很大的变量压进一个共享 latent space。 |
难度评级:★★★★☆。需要理解 diffusion policy、flow matching、VLA、VLM feature conditioning、world modeling、MMDiT/AdaLN,以及机器人 benchmark 的成功率评估。
关键词:Vision-Language-Action, world model, multimodal diffusion transformer, decoupled flow matching, asynchronous sampling, RoboCasa, GR-1, BridgeV2。
核心贡献清单
- 双流 MMDiT:action tokens 与 future observation tokens 在大部分计算中保持各自通道,只在 shared attention 中交换信息。
- 按模态独立加噪:训练时分别采样 $\tau_A$ 和 $\tau_o$,让模型看到“干净动作 + 噪声未来状态”“噪声动作 + 干净未来状态”等组合,显式学习前向与逆向的跨模态依赖。
- 解耦 flow matching 损失:把 joint diffusion 的目标写成 action loss 与 world-modeling loss 的加权和,避免为两种模态设计统一速度场。
- 异步 test-time scaling:推理时固定 $N_A$,增加 $N_o$,只让视觉 token 更细粒度地去噪;附录显示同步增加两者反而伤害性能。
2. 动机
2.1 为什么 VLA 需要 world model
标准 VLA 通常把当前图像、机器人状态和语言指令编码成语义条件,再由 action expert 直接生成动作 chunk。它们可以很好地利用 VLM 的视觉和语言理解能力,但弱点是对“动作如何改变环境”没有显式建模。对于机器人控制,这个缺口很重要:抓取是否对齐、夹爪未来会到哪里、目标物是否可能被推开,这些都不是只看当前帧就稳定解决的问题。
世界模型增强 VLA 的想法是同时预测动作和未来视觉状态。这样模型不只拟合专家动作分布,还要解释动作对应的视觉后果。论文把这个目标表述为学习动作 $A_t$ 和未来观测嵌入 $\tilde{o}_{t+k}$ 的联合分布。
2.2 为什么“直接 joint diffusion”不够
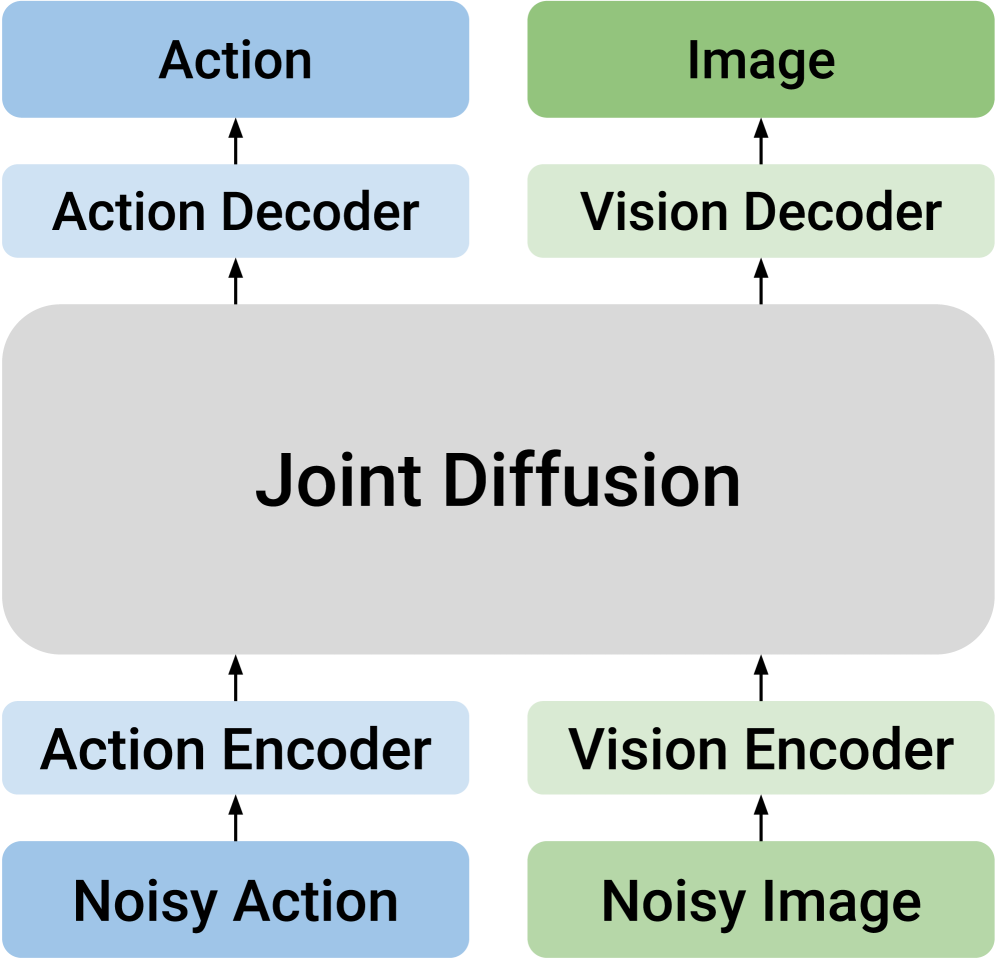
已有 unified joint diffusion 把动作 token 和未来视觉 token 拼在一起,用同一个 diffusion model 统一生成。这个设计隐含一个强假设:动作与视觉可以被一个共享 latent space 共同承载。论文指出这会造成模态冲突:动作是低维、连续、平滑的控制轨迹;未来视觉 embedding 是高维、含空间结构的语义对象。它们需要不同的噪声日程、不同的去噪粒度和不同的归一化条件。
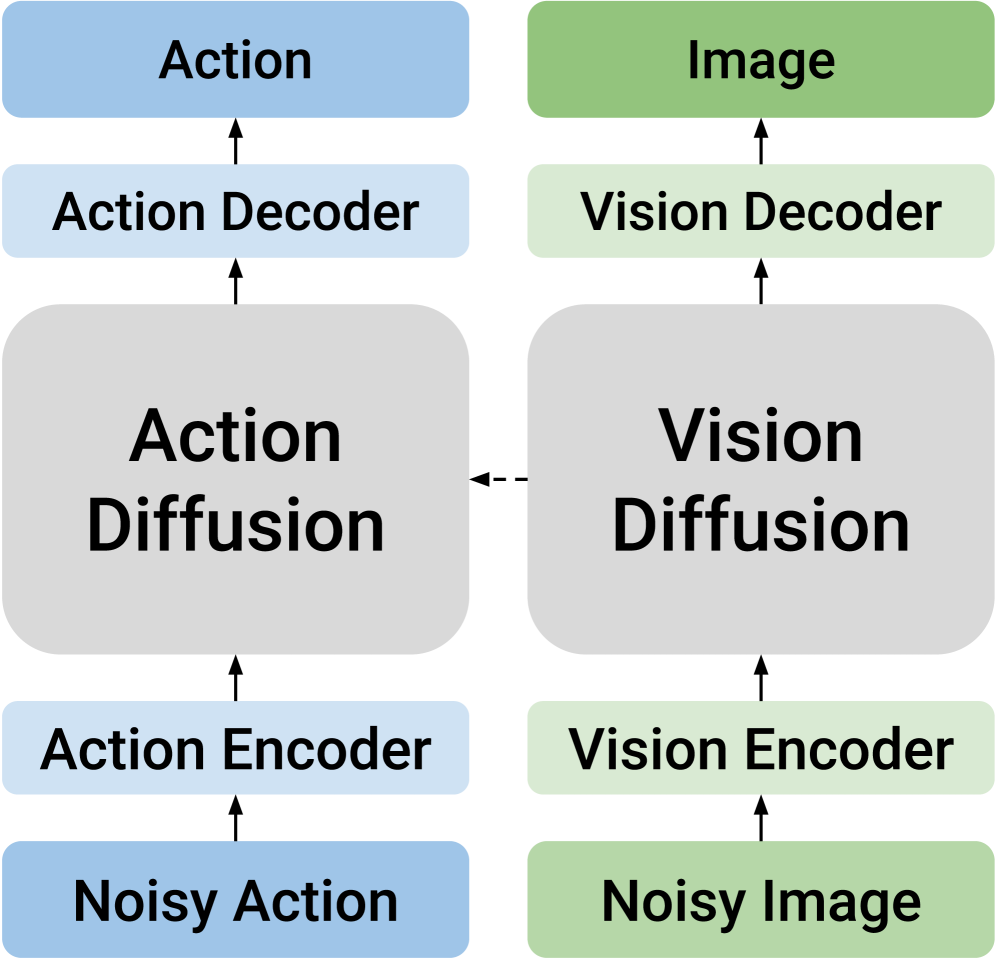
另一类 causal design 把两种模态分成不同模型,用单向条件连接。例如先预测未来视觉,再生成动作,或先生成动作,再预测未来状态。这样保留了模态专门性,却牺牲了双向知识传递。DUST 要解决的正是这个 trade-off:既要保留各自结构,又要允许双向交互。
2.3 这篇论文的核心假设
核心假设:动作与未来视觉状态不应该共享同一条去噪路径,但应该共享同一个跨模态注意力接口。训练时,如果动作和视觉被独立加噪,模型就会被迫在不同噪声组合下学习“动作导致什么未来状态”和“什么动作能解释这个未来状态”。
4. 方法详解
4.1 问题设定与 baseline VLA
数据集由专家轨迹组成:$\mathcal{D}=\{T_1,T_2,\ldots\}$。每条轨迹含任务指令 $I$、观察 $O_t=(o_t^v,o_t^s)$ 和动作 chunk $A_t=(a_t,\ldots,a_{t+k-1})$。目标是在当前视觉观察、机器人本体状态和语言指令条件下预测动作 chunk。
标准 diffusion action expert 先构造 noisy action:
$$A_t^\tau = \tau A_t + (1-\tau)\epsilon,\qquad \epsilon\sim\mathcal{N}(0,I).$$然后训练速度网络预测线性路径的速度:
$$\mathcal{L}_{\mathrm{FM}}(\theta)=\mathbb{E}\left[\left\|V_\theta(\Phi_t,A_t^\tau,o_t^s)-(A_t-\epsilon)\right\|^2\right].$$直觉:$\tau=0$ 时是纯噪声,$\tau=1$ 时是真实动作;网络学的是“从当前 noisy action 往真实 action 走”的方向。
世界模型目标不是预测像素,而是预测执行动作 chunk 后的未来图像 embedding $\tilde{o}_{t+k}$。这个 embedding 来自 VLM 中的视觉编码器,论文实验中使用 Eagle-2 相关的 SIGLIP-2 表征。
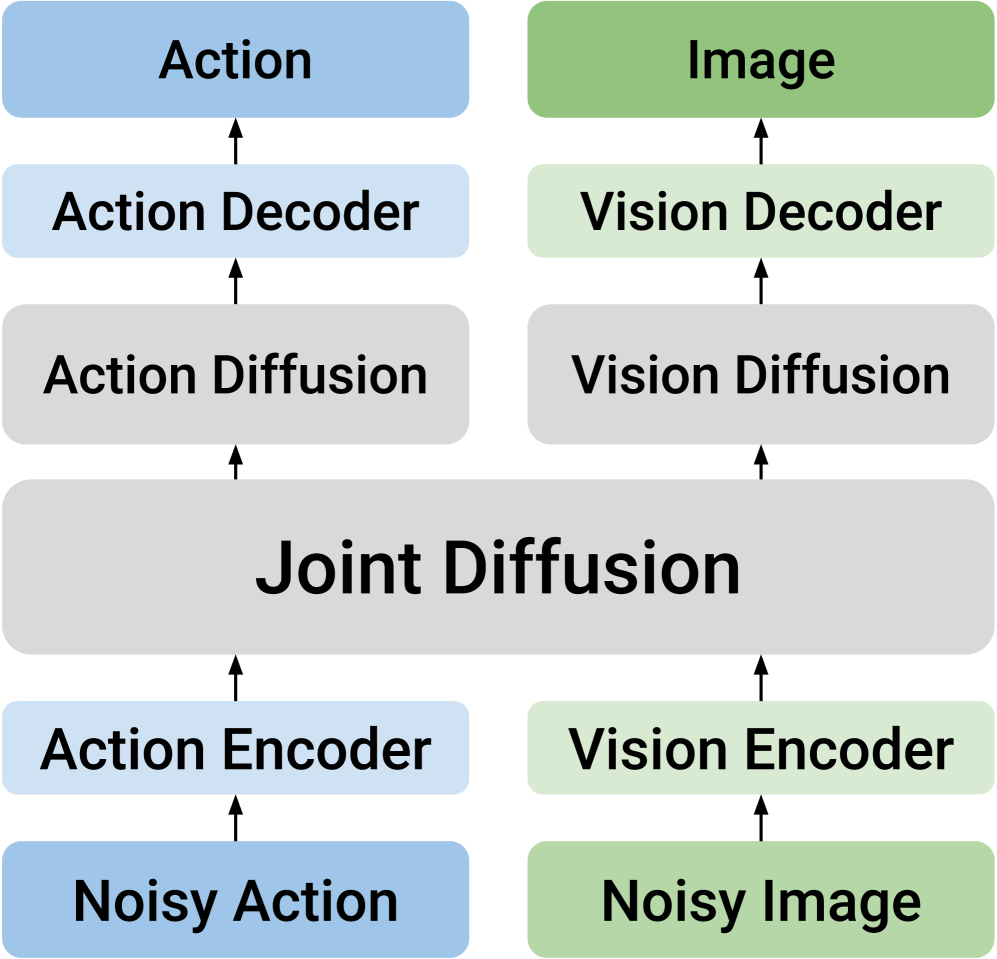
4.2 DUST 架构:双流但共享注意力
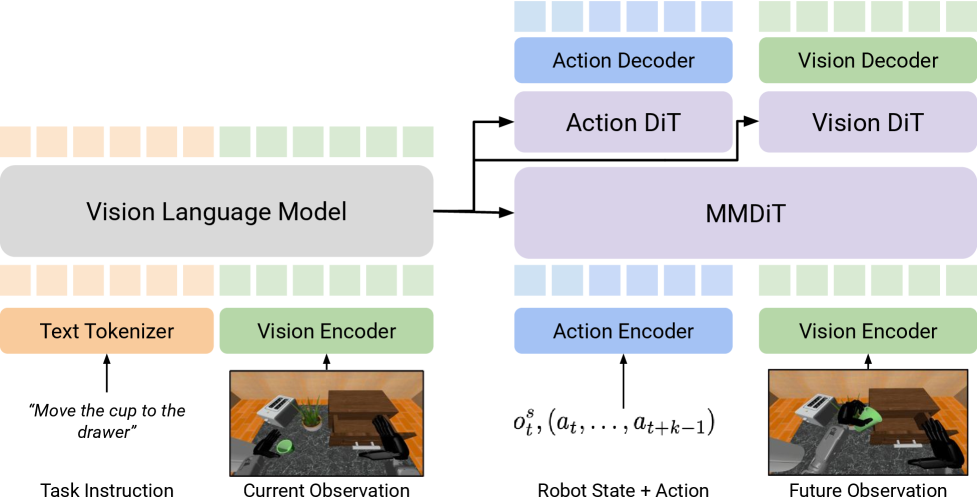
DUST 的核心输入是三元组 $(o_t^s,A_t^\tau,\tilde{o}_{t+k}^\tau)$。动作 token 和未来视觉 token 进入 MMDiT block 后,大部分操作保留两条独立通道;只有在 shared cross-modal attention 层中临时合并,以便 action stream 与 vision stream 交换信息,随后立刻分回各自 stream。
每个 stream 有自己的 timestep embedding,并通过 AdaLN 注入。这一点非常关键:如果 action 与 vision 使用同一个 timestep 条件,就没法表达“动作已经很干净但视觉仍很 noisy”这类训练样本。附录进一步说明,论文实现是在原始 MMDiT block 上做轻量修改,让每个模态 stream 的 AdaLN 接受独立时间步 embedding 附录 A.2 / Figure 6。
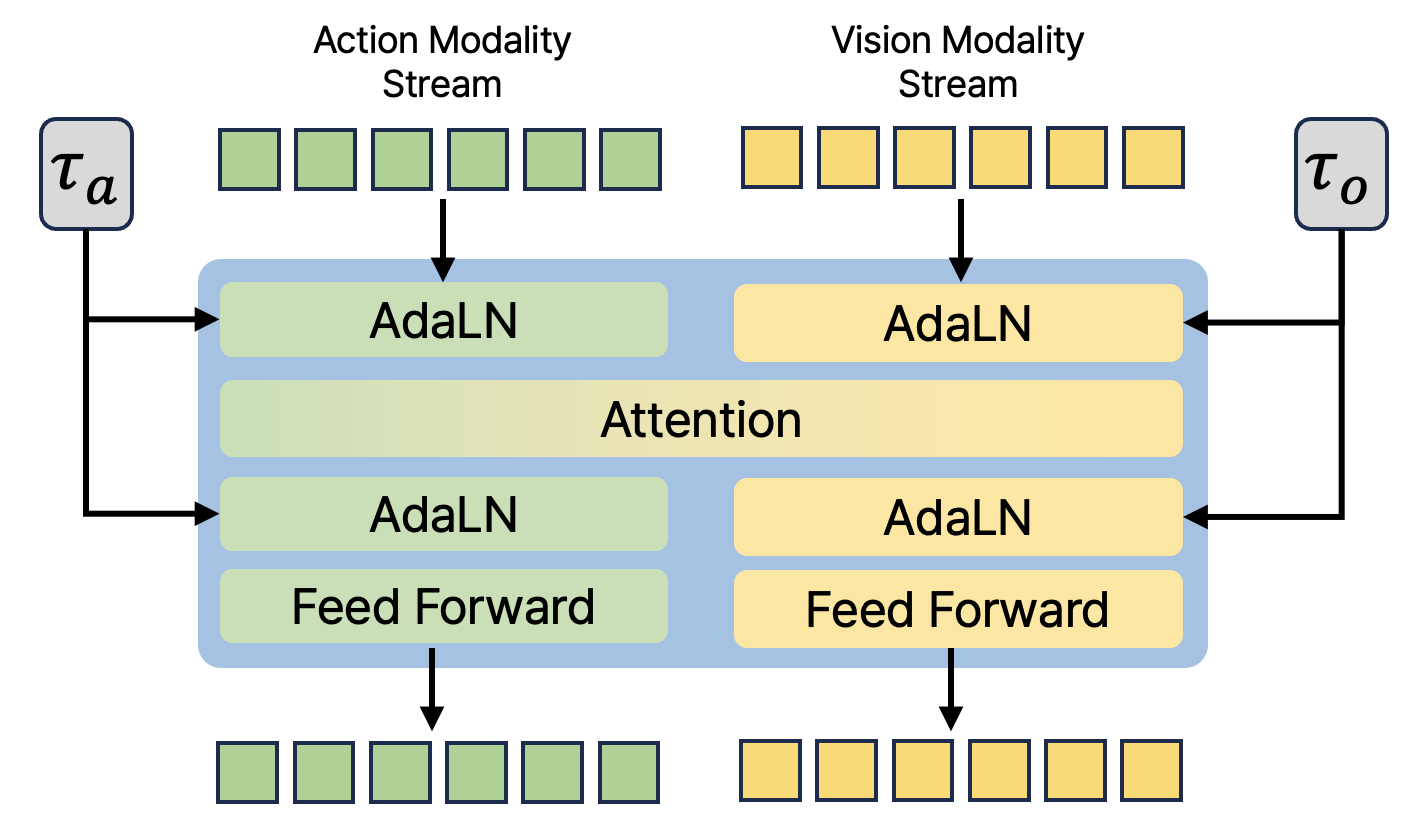
经过若干 shared MMDiT block 后,DUST 再把两个 stream 分别送入 modality-specific DiT blocks。论文主实验使用 12 个 MMDiT blocks,再接 4 个 action-side DiT blocks 和 4 个 vision-side DiT blocks。这个设计的含义是:前段尽量学习跨模态依赖,后段让每个模态各自完成精细去噪。
4.3 解耦加噪与 flow matching 损失
DUST 训练时不是只采样一个 $\tau$,而是分别采样动作时间步 $\tau_A$ 与视觉时间步 $\tau_o$:
模型输出两个速度场:
$$V_\theta(\Phi_t,A_t^{\tau_A},\tilde{o}_{t+k}^{\tau_o},o_t^s)=[V_\theta^A,V_\theta^o].$$对应两个 flow matching loss:
$$\mathcal{L}_{A}=\mathbb{E}\left[\|V_\theta^A-(A_t-\epsilon_A)\|^2\right],$$ $$\mathcal{L}_{\mathrm{WM}}=\mathbb{E}\left[\|V_\theta^o-(\tilde{o}_{t+k}-\epsilon_o)\|^2\right].$$总损失为:
$$\mathcal{L}_{\mathrm{Joint}}=\mathcal{L}_{A}+\lambda_{\mathrm{WM}}\mathcal{L}_{\mathrm{WM}}.$$直觉:动作和未来视觉各学自己的“去噪方向”,但网络在 shared attention 中看到彼此的当前 noisy/clean 状态,所以联合关系仍然被学习。
这个设计让训练样本覆盖多种跨模态条件。例如 $\tau_A\approx1,\tau_o\approx0$ 时,模型要根据较干净动作推断未来视觉;$\tau_A\approx0,\tau_o\approx1$ 时,模型要根据较干净未来视觉反推可解释它的动作。这是 DUST 声称能学习 bidirectional joint distribution 的机制基础。
4.4 推理:异步 vision-action joint sampling
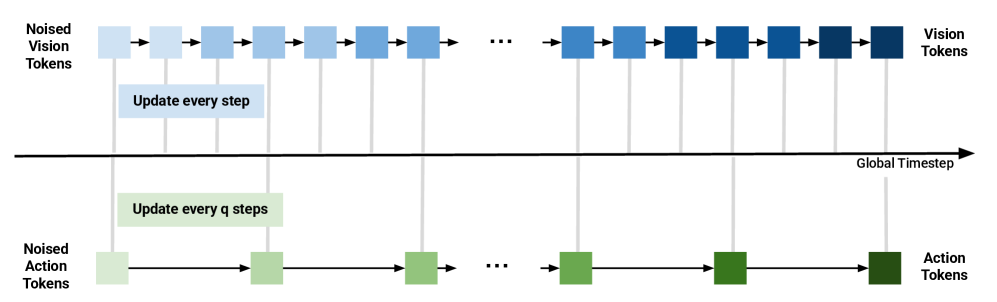
推理阶段从两个噪声变量开始:$A_t^0\sim\mathcal{N}(0,I_A)$、$\tilde{o}_{t+k}^0\sim\mathcal{N}(0,I_v)$。设 action diffusion steps 为 $N_A$,vision diffusion steps 为 $N_o=qN_A$。全局小步长为 $\Delta\tau_o=1/N_o$,视觉每一步更新;动作每 $q$ 步更新一次,对应 $\Delta\tau_A=1/N_A=q\Delta\tau_o$。
直觉:动作低维,过多步数可能过度积分或引入误差;未来视觉 embedding 高维,更多去噪步数通常有利。DUST 的结构把这个不对称性暴露成一个推理时旋钮。
4.5 训练与推理伪代码压缩版
训练 DUST:
1. sample batch (o_t^v, o_t^s, I, A_t, o_{t+k}^v)
2. Phi_t = frozen VLM(o_t^v, I)
3. future embedding tilde{o}_{t+k} = VLM_img(o_{t+k}^v)
4. independently sample tau_A, tau_o and Gaussian noises
5. construct noisy action and noisy future embedding
6. encode action/state tokens and vision tokens separately
7. run MMDiT blocks with shared attention and modality-specific AdaLN
8. run modality-specific DiT blocks
9. decode V_theta^A and V_theta^o
10. optimize L_A + lambda_WM L_WM with AdamW
异步采样:
1. initialize action and vision tokens from Gaussian noise
2. choose N_A and N_o = q N_A
3. update vision every small step
4. update action only every q small steps
5. return final denoised action chunk and future observation embedding
5. 实验
5.1 统一实验设定
- VLM backbone:冻结 Eagle-2,用第 12 层语义特征作为 diffusion 模块条件。
- 世界模型目标:未来图像经 SIGLIP-2/Eagle-2 视觉表征得到 256 tokens,再经 $2\times2$ average pooling 降到 64 future image tokens。
- diffusion token 组成:1 个 state token、16 个 action tokens、64 个 future image tokens。
- 主模型结构:12 MMDiT blocks + 4 modality-specific DiT blocks。
- loss weight:$\lambda_{\mathrm{WM}}=1.0$,来自消融实验。
- baselines:GR00T-N1.5;以及作者复现的 GR00T-N1.5 + FLARE loss。FLARE 无官方代码或 checkpoint,作者用相同 VLM backbone 和相同 SIGLIP-2 未来 embedding target 复现 FLARE loss 附录 A.2。
5.2 主结果:RoboCasa、GR-1、真实 Franka
| RoboCasa | 100 demos | 300 demos | 1000 demos | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | PnP | OP/CL | Other | Avg. | PnP | OP/CL | Other | Avg. | PnP | OP/CL | Other | Avg. |
| GR00T-N1.5 | 0.215 | 0.603 | 0.468 | 0.417 | 0.272 | 0.660 | 0.466 | 0.450 | 0.323 | 0.757 | 0.508 | 0.508 |
| + FLARE | 0.230 | 0.648 | 0.498 | 0.446 | 0.380 | 0.767 | 0.562 | 0.553 | 0.459 | 0.837 | 0.682 | 0.646 |
| + DUST | 0.295 | 0.760 | 0.510 | 0.501 | 0.423 | 0.807 | 0.581 | 0.585 | 0.483 | 0.863 | 0.686 | 0.663 |
RoboCasa 结果显示,DUST 在 100/300/1000 demos 三个数据规模上都高于 FLARE。尤其 100 demos 场景下,DUST 平均成功率 0.501,相比 GR00T-N1.5 的 0.417 提高 0.084,相比 FLARE 的 0.446 提高 0.055,说明显式 dual-stream world modeling 对低数据量更有帮助。
| GR-1 | 300 demos | 1000 demos | ||||
|---|---|---|---|---|---|---|
| Method | PnP | Art. | Avg. | PnP | Art. | Avg. |
| GR00T-N1.5 | 0.176 | 0.283 | 0.203 | 0.307 | 0.310 | 0.308 |
| + FLARE | 0.340 | 0.330 | 0.337 | 0.393 | 0.324 | 0.363 |
| + DUST | 0.358 | 0.367 | 0.360 | 0.422 | 0.413 | 0.420 |
GR-1 是更高维的 humanoid manipulation 场景,action space 有 29 DoF。DUST 在 1000 demos 平均成功率 0.420,高于 FLARE 的 0.363。论文强调 GR-1 训练对 batch size 敏感,需要较大规模训练 附录 A.2/A.3。




| 真实 Franka | Task 1 | Task 2 | Task 3 | Task 4 | Avg. |
|---|---|---|---|---|---|
| GR00T-N1.5 | 0.583 | 0.750 | 0.500 | 0.354 | 0.547 |
| + FLARE | 0.625 | 0.729 | 0.500 | 0.375 | 0.557 |
| + DUST | 0.833 | 0.792 | 0.625 | 0.458 | 0.677 |
真实机实验使用 7-DoF Franka Research 3,两台 ZED 摄像头,一台腕部相机、一台侧视相机 附录 A.4 / Figure 7。训练数据为每个任务 60 条 teleoperation demonstrations。每个 object-task 配置评估 6 次,每个任务共 24 trials;若物体部分进入目标容器但重心在外,计 0.5 success。

5.3 BridgeV2 action-free video 预训练
DUST 的双流结构天然支持只用视频训练 world-modeling stream。预训练阶段使用 BridgeV2 的视频部分,只优化 $\mathcal{L}_{\mathrm{WM}}$,action tokens 随机初始化;然后在 RoboCasa 100 demos 上 finetune。
| Method | Video Pretrain | PnP | OP/CL | Other | Avg. |
|---|---|---|---|---|---|
| GR00T-N1.5 | No | 0.215 | 0.603 | 0.468 | 0.417 |
| DUST | No | 0.295 | 0.760 | 0.510 | 0.501 |
| DUST | Yes | 0.423 | 0.807 | 0.581 | 0.585 |
这个实验是论文最有扩展意义的部分:如果 action-free human/robot videos 可以只训练未来视觉建模,再迁移到少量带动作的 robot demos,那么 DUST 就不仅是一个策略改造,也可以作为大规模 VLA 预训练的接口。
5.4 Test-time scaling:只给 vision 更多步
| $N_o$ | RoboCasa 100 Avg. | RoboCasa 1000 Avg. | GR-1 1000 Avg. |
|---|---|---|---|
| 4 | 0.501 | 0.663 | 0.420 |
| 16 | 0.504 | 0.668 | 0.451 |
| 32 | 0.508 | 0.686 | 0.471 |
| 64 | 0.518 | 0.697 | 0.450 |
异步采样整体有效:RoboCasa 100 demos 从 0.501 到 0.518,RoboCasa 1000 demos 从 0.663 到 0.697,GR-1 1000 demos 在 $N_o=32$ 时达到 0.471。论文解释为视觉 embedding 的高维结构更需要细粒度 refinement。
附录做了关键对照:如果同步增加 $N_A=N_o$,性能会下降。例如 RoboCasa 100 demos 平均成功率从 0.501 降到 0.425/0.424/0.397;GR-1 也从 0.420 降到 0.416/0.406/0.401 附录 A.1 / Table 7。这说明收益不是“更多 diffusion steps”本身,而是“给需要更多步的模态更多步”。
5.5 消融实验:结构和训练都不能少
| Arch. | Noise | PnP | OP/CL | Other | Avg. |
|---|---|---|---|---|---|
| DiT | Joint | 0.240 | 0.633 | 0.340 | 0.380 |
| DiT | Decoupled | 0.248 | 0.613 | 0.454 | 0.425 |
| MMDiT | Joint | 0.160 | 0.677 | 0.382 | 0.382 |
| MMDiT | Decoupled | 0.295 | 0.760 | 0.510 | 0.501 |
消融结论很干净:只做 decoupled noising 但没有双流 MMDiT,平均成功率 0.425;只做 MMDiT 但使用 joint noise,平均成功率 0.382;两者一起才到 0.501。
MMDiT depth
总层数固定为 16,MMDiT 层数为 6/10/12/14 时平均成功率分别为 0.474/0.483/0.501/0.493。12 MMDiT + 4 DiT 最优。
$\lambda_{\mathrm{WM}}$
$\lambda_{\mathrm{WM}}=0.2/0.5/1.0/2.0$ 时平均成功率为 0.343/0.489/0.501/0.496。动作和世界模型目标需要相对均衡。
6. 可复现审计
6.1 数据与评估任务
| Benchmark | 任务与数据 | 观察/动作空间 | 训练规模 |
|---|---|---|---|
| RoboCasa | 24 个厨房 manipulation tasks:8 个 pick-and-place、6 个 open/close、10 个 miscellaneous;数据由 MimicGen 在 MuJoCo 中生成。 | 3 个视角:left、right、wrist;Franka Panda 7 DoF,包括末端位置/旋转和二值夹爪。 | 每任务 100、300、1000 demos;global batch size 32,2 A100;60k/420k/600k steps。 |
| GR-1 | 24 个 tabletop tasks:16 个 pick-and-place、8 个 articulated tasks;数据来自 GR00T-N1.5/DexMimicGen。 | 单个 head egocentric view;GR-1 humanoid + Fourier dexterous hands,总 29 DoF。 | 每任务 300、1000 demos;global batch size 960,8 H200,60k steps。 |
| 真实 Franka | 4 个 pick-and-place 指令模板,每个含 Teddy Bear、Blue Cube、Blue Cup、Sponge。 | 7-DoF Franka Research 3,joint position + binary gripper;两台 ZED 相机。 | 每任务 60 teleop demos;global batch size 32,2 A100,60k steps。 |
| BridgeV2 transfer | 预训练只用 BridgeV2 的 action-free video component。 | 只优化 future observation embedding 的 world-modeling loss。 | 2 A100,batch size 32,120k pretrain steps;再在 RoboCasa 100 demos 上 finetune 60k steps。 |
6.2 优化与模型细节
- AdamW,base learning rate $1e-4$,$\beta_1=0.95$,$\beta_2=0.999$,$\epsilon=1e-8$。
- weight decay $1e-5$,bias 和 LayerNorm weights 例外。
- cosine decay schedule,5% warmup。
- vision token encoder:3-layer MLP + 2D sinusoidal positional encoding + SiLU;vision decoder:2-layer MLP + ReLU。
- action token 使用 GR00T-N1.5 原代码中的 linear encoder-decoder pair,加 1D sinusoidal positional encoding。
- FLARE baseline 因无官方代码/checkpoint,作者复现 FLARE loss,并使用与 DUST 相同的 SIGLIP-2 future embedding target。
6.3 复现风险点
| 风险点 | 为什么重要 | 论文给出的缓解信息 |
|---|---|---|
| GR-1 batch size 敏感 | 作者明确说 GR-1 需要 large-scale training 才有 meaningful results;小 batch 复现可能掉很多。 | global batch size 960,8 H200,60k steps。 |
| FLARE baseline 非官方实现 | 结果依赖作者复现的对齐模块和 target choice,不能等同于官方 FLARE。 | 作者说明使用同一 VLM backbone、同一 future embedding target,alignment module 是 small MLP。 |
| 真实机评估随机性 | 真实桌面场景中物体初始位置、朝向和接触动力学影响很大。 | 作者预先固定 varied configurations;每个 object-task 配置 6 次,半成功计 0.5。 |
| 代码可用性 | 论文源码包含 LaTeX 与图表,但未在 arXiv 页面标出官方 GitHub。 | 复现需要依赖 GR00T-N1.5 codebase 和论文附录超参自行实现 DUST。 |
6.4 最小复现路线
- 从 GR00T-N1.5 codebase 启动,冻结 Eagle-2 VLM,并确认能训练原始 diffusion action expert。
- 增加 future image embedding target:提取 $o_{t+k}^v$ 的 SIGLIP-2/Eagle-2 image tokens,并做 $2\times2$ average pooling 到 64 tokens。
- 实现 action stream 与 vision stream 的 encoder/decoder,以及 MMDiT block 中的双 AdaLN timestep conditioning。
- 训练时独立采样 $\tau_A,\tau_o$,分别构造 noisy action 和 noisy future embedding。
- 优化 $\mathcal{L}_A+\lambda_{\mathrm{WM}}\mathcal{L}_{\mathrm{WM}}$,先用 $\lambda_{\mathrm{WM}}=1.0$,主实验默认 $N_A=N_o=4$。
- 复现实验优先跑 RoboCasa 100 demos:成本最低,且消融和主结果都在这里最有区分度。
- 最后评估异步采样,把 $N_A$ 固定为 4,尝试 $N_o=16,32,64$;不要同步增加 $N_A$。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
我认为最有价值的是它把“世界模型辅助动作生成”拆成了一个很清晰的工程和建模问题:动作和未来视觉确实应该互相约束,但它们不应该被迫使用同一条 diffusion 时间轴。DUST 的双流结构、独立噪声、解耦损失和异步推理四件事互相咬合,形成了一个比“加辅助 loss”更完整的设计。
另一个亮点是 BridgeV2 action-free video 预训练实验。虽然规模不算巨大,但它展示了一个有吸引力的路径:未来视觉 stream 可以从无动作视频中学习环境动力学,再在少量 robot action 数据上迁移成策略。
7.2 结果为什么站得住
- 横跨三种设置:单臂厨房 RoboCasa、humanoid GR-1、真实 Franka,都有增益。
- baseline 合理:GR00T-N1.5 是强 diffusion VLA baseline;FLARE 代表 implicit world-modeling baseline,且作者尽量用相同 VLM 和 target 对齐。
- 消融指向清楚:MMDiT/decoupled noising 单独都不够,二者组合最好;$\lambda_{\mathrm{WM}}$ 和 MMDiT depth 也给了稳定性证据。
- 附录验证异步采样:同步增加两种模态步数会下降,支持“视觉需要更多步、动作不需要”的解释。
7.3 局限与读者应保留的疑问
| 问题 | 具体影响 |
|---|---|
| 未来视觉目标仍是 embedding,而非可解释物理状态 | SIGLIP-2/Eagle-2 embedding 比像素更贴近语义,但它是否真正捕获可控物理变量,仍需更细分析。 |
| 真实机任务范围较窄 | 四个 pick-and-place templates 证明了 sim-to-real 之外的有效性,但不足以说明长时序、多阶段、接触复杂任务的鲁棒性。 |
| 计算成本较高 | GR-1 使用 8 H200、batch size 960;RoboCasa 1000 demos 需 600k steps。DUST 不是轻量小模型改造。 |
| 未看到官方代码链接 | 附录给了伪代码和超参,但真正复现还要处理 GR00T-N1.5/Eagle-2 接口、MMDiT 修改、数据 pipeline。 |
| 异步采样增加推理开销 | $N_o=64$ 时成功率更高,但会增加 inference time;实际机器人闭环频率可能限制可用步数。 |
7.4 组会可追问的问题
- 为什么 MMDiT + joint noise 比 DiT + decoupled noise 还差?是否因为双流结构在没有独立时间步时反而更难优化?
- future embedding target 选择 SIGLIP-2/Eagle-2 是否最优?换成 DINOv2、V-JEPA 或 robot-specific encoder 会怎样?
- BridgeV2 预训练只优化 $\mathcal{L}_{\mathrm{WM}}$,action tokens 随机初始化;是否可以额外加入 latent action 或 inverse dynamics proxy?
- 异步采样中 action token 在 inner loop 里保持不变,但 $\tau_A$ 的推进在论文公式与伪代码表述上略有实现细节空间;实际代码中如何同步 condition timestep 需要小心。
- 未来状态预测是辅助训练目标,但推理最终执行只依赖 action chunk 还是也用未来 embedding 做闭环检查?论文主要是前者,后者可能是下一步扩展。
附:本报告覆盖检查
已覆盖:Abstract、Introduction、Related Works、Preliminaries、Method、Experiments、Conclusion,以及附录的同步采样消融、实现细节、训练超参、benchmark 细节、真实机设置、伪代码和 rollout 图说明。
图表处理:使用 arXiv HTML 渲染出的 PNG 图像保存在 figures/;关键定量表格已重建为 HTML 表格。
残余风险:arXiv 页面未标注官方代码仓库;报告中的复现路线基于论文附录和源码,不等同于已验证代码运行。