RynnVLA-002: A Unified Vision-Language-Action and World Model
1. Quick overview of the paper
Difficulty rating: ★★★★☆. Reading requires familiarity with VLA, MLLM tokenization, VQ-GAN image token, discrete action token, continuous action head, world model video prediction indicators, and LIBERO / LeRobot evaluation protocol.
Keywords: Vision-Language-ActionWorld ModelUnified VocabularyAction ChunkingAction TransformerLIBERO
| Reading targeting item | Short answer |
|---|---|
| What should the paper solve? | Standard VLA only places actions on the output side, lacking explicit internal modeling of action dynamics and physical evolution; standard world models can predict future observations but cannot directly output robot actions. The paper attempts to unify action planning and future visual prediction. |
| The author's approach | Based on Chameleon's unified image and text generation architecture, image/text/state/action tokenizers are introduced to mix VLA data and world model data for training; while retaining discrete action token training, and adding a continuous Action Transformer head to solve real robot generalization and speed problems. |
| most important results | In LIBERO, RynnVLA-002-Continuous achieved an average success rate of 97.4% without additional pre-training; on the real LeRobot SO100, after adding world model data, the success rate increased from less than 30% to more than 80% for block tasks. The abstract of the paper stated that the overall success rate increased by 50%. |
| Things to note when reading | "Unification" is not just about sharing backbone names, but organizing VLA queries and world-model queries into the same set of token sequences and shared parameters; however, discrete actions fail on real robots, so the continuous action header is an important patch for this method to be implemented. |
Core contribution list
- RynnVLA-002 is proposed to unify the VLA model and world model into an action world model, share parameters and hybrid training.
- An attention mask for discrete action chunks is proposed to prohibit the current action from relying on previous actions in the same chunk and alleviate the error propagation of autoregressive actions.
- In addition to discrete modeling, a continuous Action Transformer head is added, and L1 regression is used to supervise continuous action chunks, making real robot movements smoother, reasoning faster, and generalization better.
- Verified on LIBERO and a real LeRobot SO100: world model data helps VLA, and VLA data also helps world model generation.
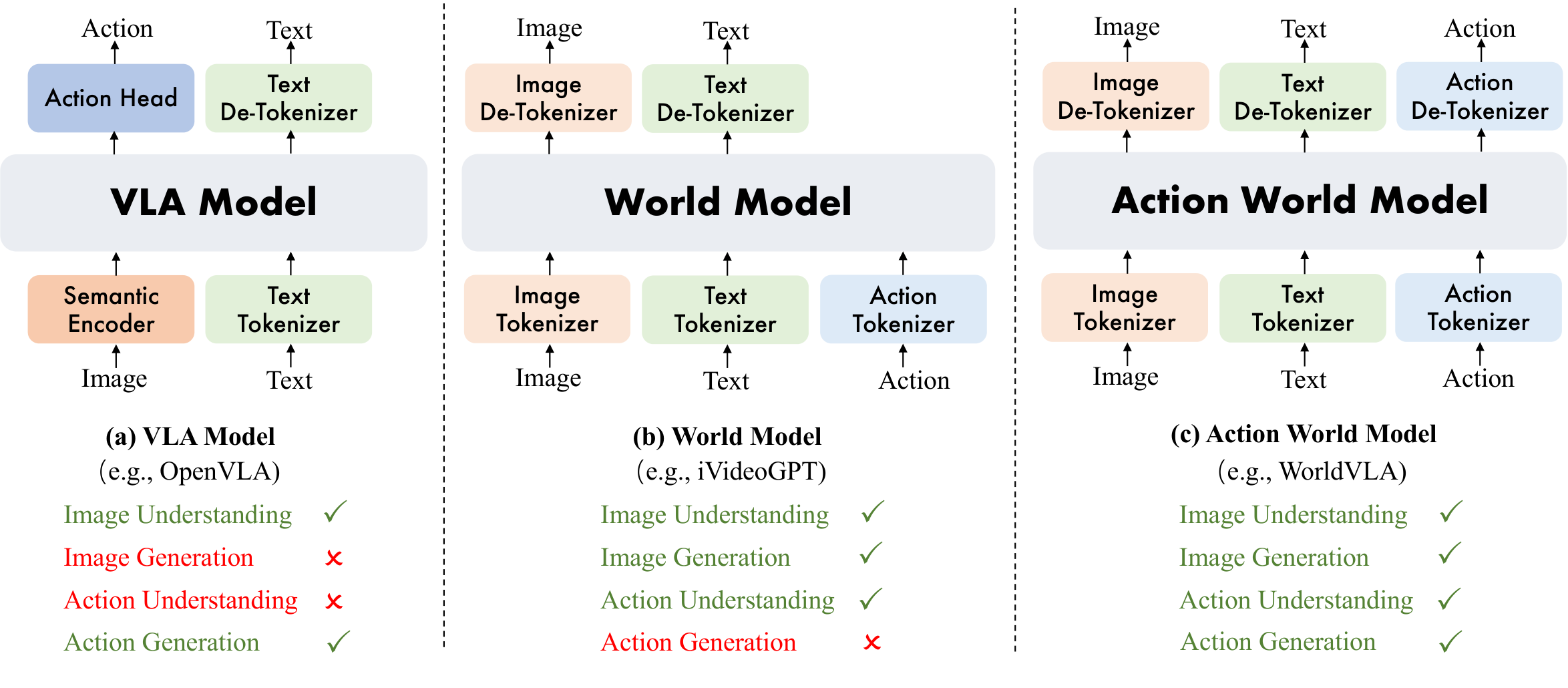
2. Motivation
2.1 What problem should be solved?
The VLA model maps language targets and visual observations to actions and is the mainstream form of current robot foundation policy. The paper believes that this architecture has three flaws: the action is only on the output side, and the model does not have explicit action dynamics representation; the model does not predict "how the world will change if a certain action is performed, " so it lacks imagination and counterfactual capabilities; the model does not directly learn physical dynamics, and it is difficult to internalize laws such as contact, stability, and object interaction.
World model just fills in the other half: it can predict future states based on current images and actions and learn environmental dynamics. However, traditional world models do not directly output actions, so action planning cannot be completed independently. The problem definition of RynnVLA-002 is to put the two into the same queryable model: when asking it "What action should the robot take to...?" it is VLA; when asking it "Generate the next frame..." it is the world model.
2.2 Where are the existing methods stuck?
VLM-based VLA often relies on the visual language understanding capabilities of large-scale MLLM, coupled with action heads or action experts. Discrete action tokens are convenient for cross-entropy training of language models, but there are problems with quantization error and autoregressive error accumulation in fine control. Continuous action heads can output smoother trajectories, but without modeling the evolution of the world, the model may still only learn short-sighted "image to action" correlations.
Visual generation-based VLA and world models can predict future frames, but still often face problems of visual fidelity, cross-domain transfer, computational efficiency, and how to truly translate predicted dynamics into action improvements. The positioning of this article is to use the same MLLM to consume VLA data and world model data at the same time, so that action understanding and visual dynamic prediction can provide training signals to each other.
2.3 Solution ideas of this article
RynnVLA-002 uses unified token vocabulary to organize image/text/action/state into token sequences that can be processed by the same language model. The VLA side generates action chunks from language, status and historical dual-view images; the world model side generates the next frame image from images and action tokens. Discrete actions are trained with cross-entropy, and world image tokens are also trained with cross-entropy; continuous action heads use L1 regression.
4. Detailed explanation of method
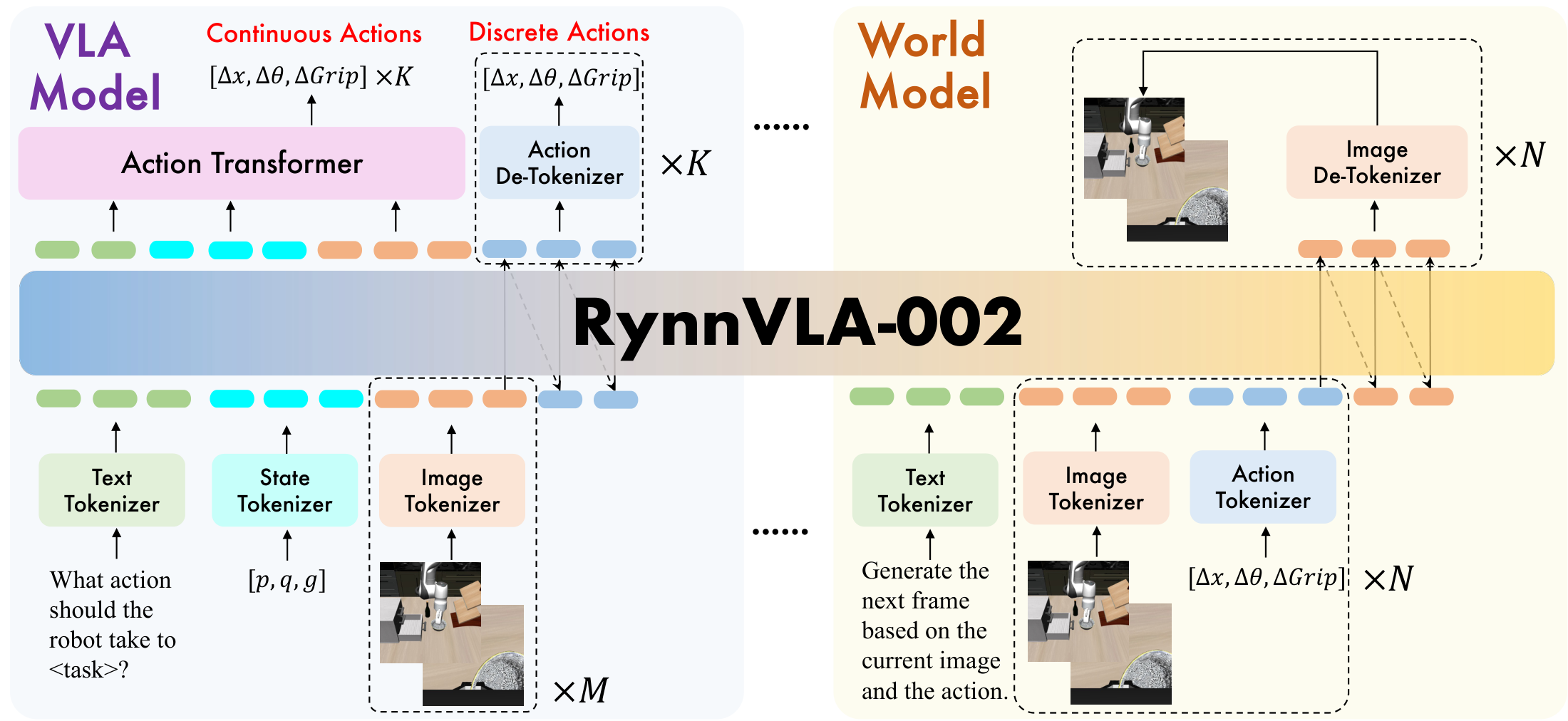
4.1 Unified modeling goals
The paper first writes VLA and world model as two conditional generation problems:
VLA problem: Given language, state, and historical observations, generate actions.
$$a_t \sim \pi(a_t \mid l, s_{t-1}, o_{t-h: t})$$World model problem: Given historical observations and actions, predict the next frame of observations.
$$\hat{o}_t \sim f(o_t \mid o_{t-h: t-1}, a_{t-h: t-1})$$RynnVLA-002 uses a parameter set $\psi$ to support both queries. Different tasks only change the organization method and text prefix of the input token, and the main model is shared.
4.2 Data Tokenization
The model is initialized from Chameleon because Chameleon natively supports unified image understanding and generation. RynnVLA-002 involves four tokenizers:
| Tokenizer | function | key details |
|---|---|---|
| Image tokenizer | Discretize images into visual tokens | VQ-GAN; compression ratio 16; codebook size 8192; $256\times256$ image generates 256 tokens, $512\times512$ generates 1024 tokens. |
| Text tokenizer | Processing language prompt | BPE tokenizer inherited from Chameleon. |
| State tokenizer | discretization proprioceptive state | Each continuous dimension is divided into 256 bins based on the training data range. |
| Action tokenizer | Discretized robot actions | Each continuous action dimension is divided into 256 bins; the continuous Action Transformer outputs raw action without tokenization. |
4.3 VLA Model Data
The sequence structure of the VLA training sample is:
| $M$ | Number of historical image observations. In the experiment, the VLA uses $M=2$. |
| $K$ | action chunk size. LIBERO-Long and LIBERO-Spatial use $K=10$, LIBERO-Object and LIBERO-Goal use $K=5$. |
| $\mathcal{L}_{dis\_action}$ | Cross-entropy loss for discrete action tokens. |
The text prompt is of the form "What action should the robot take to <task>?". Input images include front and wrist cameras, and states include proprioceptive state.
4.4 World Model Data
The sequence structure of the world model is:
All world model samples use the same text prefix. The main text of the paper is "Generate the next frame based on the current image and the action.", and the official README data sample is "Generate the next image based on the provided sequence of historical images and corresponding actions."
| $N$ | Autoregressive prediction rounds. In the experiment, the efficiency is set to $N=1$. |
| $\mathcal{L}_{img}$ | Cross-entropy loss for future image discrete tokens. |
The discrete training objectives are:
This means that action prediction and image prediction are optimized hybridly in the same training phase.
4.5 Attention Mask of Discrete Action Chunk
When autoregression generates multiple actions, if the default causal attention allows subsequent action tokens to see previous action tokens, early action errors will enter the subsequent action conditions, causing error accumulation. The author's attention mask is modified to: the current action only looks at the text / visual / state input, and does not look at the previous actions in the same chunk.

This design turns multiple action tokens into "conditionally independently generated from the visual context" to reduce error propagation. But the cost also appears in the paper: on a real robot, this kind of discrete action chunk is easy to be unsmooth, because the actions in the same chunk are isolated from each other and the trajectory continuity cannot be guaranteed.
4.6 Continuous Action Transformer Head
In order to handle real robot generalization and inference speed, the author adds a small Action Transformer in addition to discrete joint modeling. It reads the complete context, including language, image, and state tokens, and outputs the entire continuous action chunk in parallel using learnable action queries.
The final training goal combines the three types of supervision: discrete action, world image and continuous action.
$$\mathcal{L}=\mathcal{L}_{dis}+\alpha\mathcal{L}_{conti} =\mathcal{L}_{dis\_action}+\mathcal{L}_{img}+\alpha\mathcal{L}_{conti\_action}$$| $\mathcal{L}_{conti\_action}$ | L1 regression loss for continuous actions. |
| $\alpha$ | The weight of continuous action loss is set to 10 in the experiment. |
Training batch construction 1. Sample VLA data: prompt = "What action should the robot take to?" input = text + state + M history images from front/wrist cameras target_discrete = K action tokens target_continuous = K raw actions through Action Transformer 2. Sample world-model data: prompt = "Generate the next frame based on the current image and the action." input = current front/wrist images + action tokens target = next front/wrist image tokens 3. Optimize: L = CE(discrete actions) + CE(image tokens) + alpha * L1(continuous actions)
5. Experiment
5.1 Experimental setup
| experiment | settings | indicator |
|---|---|---|
| LIBERO simulation | Four suites: Spatial, Object, Goal, Long. Remove unsuccessful trajectories and no-operation actions when cleaning data; world model uses 90% / 10% train-val split. | VLA uses the success rate of 50 different initial state rollouts per task; the world model uses FVD, PSNR, SSIM, and LPIPS. |
| LeRobot SO100 real-world | Two types of pick-and-place: block inside circle 248 demos, strawberries into cup 249 demos; both are human teleoperation expert demonstrations. | Each task and each scenario are tested 10 times and the success rate is reported. |
| Ablation | Remove the world model data, action chunking, this article's attention mask, wrist camera, and proprioceptive state respectively, and compare discrete and continuous actions. | LIBERO success rate, real robot success rate, world model generation metrics, Hz inference frequency. |
5.2 LIBERO main results
| method | Pretraining | Action Type | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|---|---|
| UniVLA | Yes | Discrete | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| OpenVLA-OFT | Yes | Continuous | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| RynnVLA-002-Discrete | No | Discrete | 94.2 | 96.8 | 94.6 | 87.6 | 93.3 |
| RynnVLA-002-Continuous | No | Continuous | 99.0 | 99.8 | 96.4 | 94.4 | 97.4 |
The key point emphasized by the author is: RynnVLA-002-Continuous achieves an average success rate of 97.4% without large-scale robot pre-training, which is comparable to or higher than several strong baselines with pre-training. The discrete version also reaches 93.3%, indicating that the unified discrete action/world token scheme is effective in simulation, but the continuous header further improves the overall performance.
5.3 Real robot results

| Task/Scenario | GR00T N1.5 | $\pi_0$ | RynnVLA-002 |
|---|---|---|---|
| Block / Single-target | 90.0 | 100.0 | 90.0 |
| Block / Multi-target | 60.0 | 70.0 | 90.0 |
| Block / w/ Distractors | 50.0 | 50.0 | 80.0 |
| Strawberries / Single-target | 50.0 | 80.0 | 80.0 |
| Strawberries / Multi-target | 50.0 | 70.0 | 80.0 |
| Strawberries / w/ Distractors | 70.0 | 40.0 | 50.0 |
Real robot evaluation can better expose the limitations of discrete actions. The text of the paper states that RynnVLA-002 is highly competitive in cluttered environments, especially in multi-target and distractor scenarios in block tasks, which is 10% to 30% higher than the baseline. However, GR00T N1.5 in the strawberry + distractors scenario is still higher than RynnVLA-002, which shows that the real robot results in this article are not overwhelmingly leading in the entire scenario.
5.4 World Model Benefits VLA
| Discrete action settings | World Model | Action Chunking | This article Attention Mask | Average |
|---|---|---|---|---|
| VLA only | No | No | No | 62.8 |
| + World Model | Yes | No | No | 67.2 |
| + Chunking, default mask | No | Yes | No | 54.0 |
| + Chunking + proposed mask | No | Yes | Yes | 76.6 |
| complete discrete model | Yes | Yes | Yes | 78.1 |
This ablation table illustrates two points: adding only world model data can raise the value from 62.8 to 67.2; if action chunking is used with the default causal mask, it will drop to 54.0, but with the mask in this article, it will increase to 76.6. The full discrete model achieves 78.1.

5.5 Ablation of Continuous Action
| settings | World Model | Wrist Camera | Proprioceptive State | Goal | Object | Spatial | Long | Average |
|---|---|---|---|---|---|---|---|---|
| Basic continuous VLA | No | No | No | 90.2 | 92.4 | 88.4 | 67.0 | 84.5 |
| + Wrist Camera | No | Yes | No | 91.4 | 95.4 | 98.2 | 81.4 | 91.6 |
| + World Model | Yes | Yes | No | 96.0 | 97.4 | 99.0 | 85.8 | 94.6 |
| complete continuous model | Yes | Yes | Yes | 96.4 | 99.8 | 99.0 | 94.4 | 97.4 |
The strongest evidence for the continuous model is: the wrist camera rises from 84.5 to 91.6, the world model data rises from 91.6 to 94.6, and the proprioceptive state pulls Long from 85.8 to 94.4. Real robot ablation is stronger: the success rate is 0 when wrist camera or proprioceptive state is missing; Single / Multi / Distractors is only 30.0 / 10.0 / 0 when world model is missing, while the complete continuous model reaches 80.0 / 80.0 / 50.0.
5.6 VLA Enhances World Model
| Suite | model | FVD ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
|---|---|---|---|---|---|
| Goal | World Model | 370.0 | 22.25 | 77.84 | 19.70 |
| Goal | Action World Model | 336.8 | 22.13 | 78.13 | 19.43 |
| Object | World Model | 1141.6 | 20.31 | 59.59 | 27.30 |
| Object | Action World Model | 877.2 | 22.18 | 65.03 | 22.60 |
| Spatial | World Model | 405.4 | 22.32 | 79.15 | 20.28 |
| Spatial | Action World Model | 373.1 | 23.88 | 82.41 | 16.33 |
| Long | World Model | 557.73 | 18.24 | 69.16 | 31.60 |
| Long | Action World Model | 427.86 | 19.36 | 72.19 | 27.78 |
The world model metrics show that the Action World Model mixed with VLA data outperforms the world model alone in most metrics.Supplementary material / World Model Visualization Further explanation: in two examples, the baseline world model cannot predict successful capture from the front camera perspective, but the Action World Model can generate videos containing successful captures; the baseline also has the problem of inconsistent predictions from the front/wrist perspectives.

5.7 Efficiency and action form
The efficiency ablation table of the paper gives a clear trend: parallel generation of continuous actions is much faster than discrete autoregressive actions. For example, the continuous model without wrist and history is 24.94 Hz at chunk size 5 and 48.20 Hz at chunk size 10; after adding wrist and history, there is still 7.75 / 15.78 Hz. The discrete model, even with action chunking, is only about 2.74 to 3.69 Hz. The paper also reports that discrete action tokens will accelerate the convergence of continuous action generation, especially in the early stages of training.
6. Repeat audit
6.1 Code and model resources
Already published: The official GitHub is alibaba-damo-academy/RynnVLA-002. README annotation 2025-11-10 releases models, training code, and evaluation code, covering LIBERO simulation benchmark and real-world LeRobot experiments.
Model Zoo: README provides four LIBERO checkpoints of VLA Model 256×256, and suite checkpoints of World Model / Action World Model 512×512. The values in the table are consistent with the main table of the paper.
Dependency cost: You need to install this warehouse, flash-attn, LIBERO, and download the Chameleon tokenizer, base-model and starting point weights. reproducibility involves two training pipelines, pretokenize and no-pretokenize.
6.2 Key hyperparameters
| item | Paper setting |
|---|---|
| VLA history images | $M=2$, front + wrist camera historical observation. |
| Action chunk size | LIBERO-Long / Spatial uses $K=10$; LIBERO-Object / Goal uses $K=5$. |
| World model prediction round | $N=1$, for computational efficiency only predicts the next frame in one round. |
| Continuous action loss weight | $\alpha=10$. |
| image tokenization | VQ-GAN, compression ratio 16, codebook size 8192. |
| state/action discretization | 256 bins per dimension, range determined by training data min/max. |
| Data cleaning | Removed unsuccessful trajectories and no-operation actions, following OpenVLA style. |
6.3 Official reproducibility path
- Install dependencies:
pip install -r requirements.txt, installflash-attn,pip install -e ., and install LIBERO. - Download the Chameleon tokenizer, base-model, and starting point weights and put them into the ones specified in README
rynnvla-002/ckpts/...path. - Filter LIBERO data no-op actions: run
regenerate_libero_dataset_filter_no_op.py. - Choose Pretokenize or NoPretokenize. Pretokenize needs to save the image/action/state first, then generate VLA conversations and world model conversations, and finally tokenize the conversation and splice the records.
- Configuration
rynnvla-002/configs/libero_goal/...data path in, runexps_pretokenizeorexps_nopretokenizeThe training script below. - EVALUATING LIBERO: AT
evals_libero/Medium settingscheckpoint_path, runs a continuous or discrete evaluation script. - Real LeRobot: README provides data generation, state/action min-max calculation, tokenization, training and
eval_solver_lerobot_action_head_state.pyReasoning entrance.
6.4 Recurrence risk
- The real robot data is the SO100 teleoperation demonstrations newly collected by the author. The paper does not indicate the complete degree of disclosure in the text; even if the code is made public, the reproducibility of the real robot form still relies on data, hardware and operating protocols.
- The main table of the paper emphasizes "without pretraining", but the model initialization relies on Chameleon and starting point weights. "without pretraining" here should be understood as pre-training without additional robot tasks, rather than training the entire MLLM from random initialization.
- The world model indicator relies on the cleaned LIBERO 90/10 split. When reproducing, the no-op filtering, task division and image resolution need to be consistent.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
According to the paper's own evidence, the most valuable part is to change "action as output" to "action as a modality". Discrete action tokens allow actions to enter the same autoregressive vocabulary as images and text; world model training requires the model to predict visual consequences from actions. So instead of just learning a supervised mapping from images to actions, the VLA is forced to learn how actions change objects and perspectives. Both LIBERO and real robot ablation show that world model data improves VLA, and the supplementary material visualization also shows that VLA data improves world model generation for the grasping process.
7.2 Why the results hold up
The claims of the paper are mutually supported by several types of evidence: the main table shows that continuous RynnVLA-002 reaches 97.4% on LIBERO; the discrete ablation table shows that world model, action chunking, and attention mask each contribute; the continuous ablation table shows that wrist camera, state, and world model are critical to Long and real robots; the world model indicator table shows that Action World Model improves FVD/SSIM/LPIPS; the real robot ablation shows that there is no world model, wrist camera, or proprioceptive state will fail significantly. This evidence covers both directions of "unified models mutually reinforcing each other".
7.3 Author's statement and limitations of experimental exposure
- Discrete action chunks rarely succeed on real robots. The author attributes the reason to the overfitting of the large autoregressive model under limited real data. The attention mask in this article isolates the actions within the chunk and cannot ensure the continuity of the trajectory, resulting in jittery and unsmooth actions.
- The real robot experiments were narrow in scope: just two pick-and-place tasks on the LeRobot SO100, with 10 tests per scenario. The results can prove that the method is effective in this setting, but it is not enough to cover complex long-range real tasks.
- The paper does not provide large-scale cross-embodiment real robot deployment results. When compared with pretrained baselines such as $\pi_0$ / GR00T, the advantages of RynnVLA-002 mainly appear in specific finetune data and scenarios.
- The world model is currently a single-round future frame prediction of $N=1$, which is mainly used as a training signal and visual verification; the paper does not show the use of the world model to explicitly rollout multi-step candidate actions or perform planning searches.
7.4 Applicable boundaries
RynnVLA-002 is more suitable for operational tasks where there are pairs of images, actions, and status data, and the future visual status can reflect the progress of the task. It requires stable interfaces for image tokenizers, action/state discretization scopes, front/wrist cameras, and proprioceptive state. For tasks with strong contact, force control, severe occlusion, visual status that is difficult to express task success, or tasks that require high-speed closed-loop control, the evidence in this article is not sufficient.