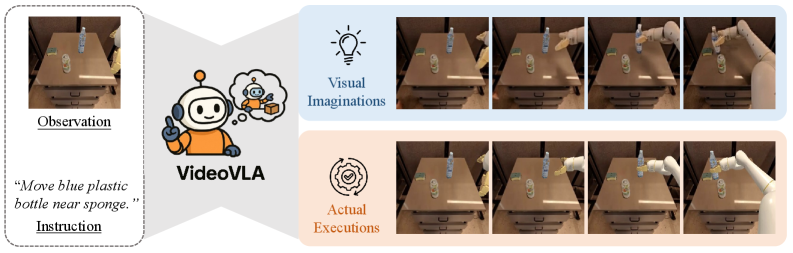
VideoVLA: Video Generators Can Be Generalizable Robot Manipulators
1. Quick overview of the paper
| What should the paper solve? | Existing VLA mostly relies on pre-trained understanding models, which can complete tasks within the training distribution, but the generalization to new tasks, new objects, and new embodiment skills is still limited; the author attempts to transfer the physical imagination and future state prediction capabilities of the video generator to robot operations. |
|---|---|
| The author's approach | Unify video generation and action generation into a diffusion denoising problem: language token and current image latent are used as conditions, and future video latent and 7-D action sequence are used as common denoising targets. |
| most important results | The average SIMPLER in-domain task average is 63.0, slightly higher than CogACT 62.6; SIMPLER novel objects average 65.2, new skills average 48.6; real Realman in-domain average 64.6, novel objects 50.6, cross-embodiment skills 58.0, all are the best in the table. |
| Things to note when reading | The core is not to generate an additional video for display, but to use video-action dual prediction as a training constraint. Ablation shows that removing video loss or only predicting actions will significantly reduce in-domain and generalization performance. |
Difficulty rating: ★★★★☆. Need to understand VLA, Diffusion Transformer, CogVideoX/causal video VAE, action chunking, SIMPLER evaluation, and robot cross-embodiment generalization.
Keywords: VideoVLA, video generation, VLA, Diffusion Transformer, visual imagination, action chunk, CogVideoX, SIMPLER, Realman robot.
Core contribution list
- Paradigm Shift: From "using a visual language understanding model as a VLA backbone" to "using a video generation model as a VLA manipulator".
- Unified modeling: Put language, current visual latent, future visual latent, and action vectors into the same DiT sequence to jointly predict action and visual consequences.
- Generalization evidence: Demonstrates stronger average performance than OpenVLA, SpatialVLA, $\pi_0$, CogACT in novel objects and unseen skills.
- Imagine - perform correlation analysis: Using motion similarity and human judgment to demonstrate that better visual imagination is associated with higher execution success rates.
2. Motivation
2.1 What problem should be solved?
The long-term goal of robotic manipulation is to generalize to tasks, objects, and environments not seen during training. Existing VLA reduces task-specific robot data requirements through large-scale vision, language or visual language understanding models, but the author believes that this route is still difficult to fully achieve true generalization, especially on novel objects and unseen skills.
The video generation model shows strong generalization under novel text/image conditions and generates physically plausible future videos. The authors observe that this is highly aligned with robotic operations: robots also need to predict physical consequences from new instructions and new visual observations, and organize actions accordingly.
2.2 Key assumptions
If a model can generate "visual imagery" that is consistent with actual execution, then it is more likely to predict actions that will accomplish the task. In other words, future visual outcomes are not additional by-products but implicit supervisory and diagnostic signals of action reliability.
4. Detailed explanation of method
4.1 Formalization of the problem
The input is text instruction $\mathcal{T}$ and current visual observation $\mathcal{O}$, and two types of future quantities are output:
Action output: action chunk that can be executed sequentially in $K$ steps in the future.
$$\mathcal{A}=\{\boldsymbol{a}_i\in \mathbb{R}^{7}\}_{i=1}^{K}$$| $\boldsymbol{a}_i[1: 3]$ | wrist rotation. |
| $\boldsymbol{a}_i[4: 6]$ | wrist translation. |
| $\boldsymbol{a}_i[7]$ | gripper state, 0 is closed, 1 is open. |
Visual output: Future video frames expected after the action is performed, but the implementation predicts latent.
$$\mathcal{F}=\{\boldsymbol{F}_j\}_{j=1}^{N}$$Action frequency and video frame frequency are not required to be the same: each action may correspond to multiple future frames. After executing an action chunk, the robot obtains new observations and repeatedly predicts the next action chunk.
4.2 Overall architecture
VideoVLA mainly consists of two encoders and a DiT backbone. The T5 text encoder converts language commands into fixed-length 226 tokens; CogVideoX's 3D-causal VAE encoder encodes video clips into frame latents. Since the VAE is causal, the first frame latent $\boldsymbol{V}_1$ only encodes the first frame, which is the current observation.
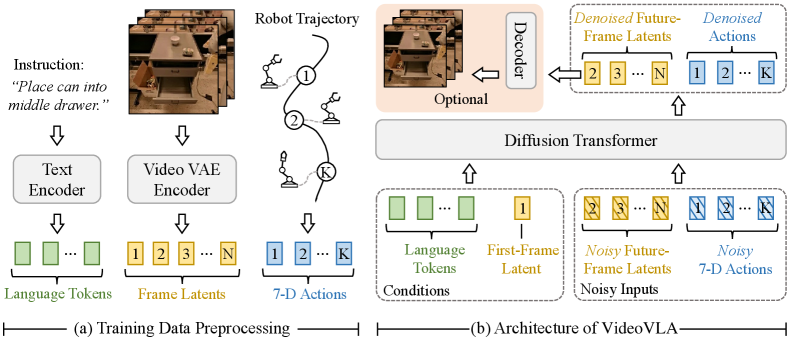
During training, the complete video clip enters the video encoder, so the model can obtain the current latent $\boldsymbol{V}_1$ and the future target latents $\{\boldsymbol{V}_j\}_{j=2}^{n}$; during inference, only the current observation is encoded to obtain $\boldsymbol{V}_1$.
4.3 Data preprocessing and token sequence
For each visual latent, VideoVLA flattens the spatial dimensions in raster order. Let $\boldsymbol{V}'_1$ be the flattened version of the current observation latent, and $\{\boldsymbol{V}'_j\}_{j=2}^{n}$ be the flattened version of future frame latents. Multimodal sequences are spliced from the following parts:
All modes are first projected to a common embedding dimension; future video latents and actions are added with Gaussian noise, and the model uses DDPM diffusion loss to learn denoise. Noise timestep embedding is injected via adaptive LayerNorm as DiT. The backbone is initialized from pretrained CogVideoX.
4.4 Unified Future Modeling
VideoVLA's unified future modeling refers to treating "future action" and "future visual consequences" as two modalities of the same future process, modeled simultaneously in one transformer. Different from modular video planning, VideoVLA does not first generate a video and then take actions through inverse dynamics, but allows action tokens and visual tokens to interact directly in denoising.
Training goal: apply diffusion denoising loss to action and future video latent simultaneously.
$$\mathcal{L}_{dual}=\mathcal{L}_{video\ denoise}+\mathcal{L}_{action\ denoise}$$The main text of the paper does not write the total loss as a separate formula, but it clearly states in the dual-prediction ablation that default uses denoising losses for both modes at the same time.
The appendix further compares attention direction and diffusion schedule: both default bidirectional interaction and synchronous diffusion schedule are better than causal mask or asynchronous schedule.Appendix More Analysis
4.5 Training and inference details
| Project | The settings given in the paper |
|---|---|
| Pre-training data | Open X-Embodiment subset, 22.5M frames; OXE originally included 60 datasets, 22 robot embodiments, and more than 1M real-world robot trajectories. |
| Real robot fine-tuning data | Realman robot teleoperation, 5824 samples, covering three types of tasks: pick, stack, and place. |
| backbone | CogVideoX-5B. |
| Default horizon | Inference predicts 13 future frame latents, or 49 frames, at each step, and predicts 6 future actions. |
| Deployment execution | Predict 6 actions each time, but only execute the first 3. |
| training | Pre-training 100K iterations; real fine-tuning 15K iterations; 32 AMD MI300X GPUs; batch size 256. |
| optimizer | AdamW, learning rate 1e-5, weight decay 1e-4. |
| sampling | DDIM sampling; write inference in the main text using 50 denoising steps; write 10 denoising steps in the appendix real deployment limitations, 1.1s/H100, about 3Hz. |
| Efficiency settings | The simulation predicts 13 latents/49 frames; the real experiment predicts the efficiency of 4 latents/13 frames. |
5. Experiment
5.1 Experimental scope and evaluation protocol
The paper does both simulation and real-world, and includes in-domain and generalization respectively. Generalization focuses on two types of abilities: performing learned skills on novel objects, and transferring skills learned by other embodiments and unseen by the target embodiment to the target robot.
| Review category | Number of tasks/trials |
|---|---|
| Google Robot SIMPLER-VM | Pick Up Coke Can 300; Move Near 240; Open/Close Drawer 216; Open Top Drawer and Place Apple 108. |
| Google Robot SIMPLER-VA | Pick Up Coke Can 825; Move Near 600; Open/Close Drawer 378; Open Top Drawer and Place Apple 189. |
| WidowX SIMPLER-VM | Four tasks with 24 trials each. |
| Novel objects / new skills simulation | 25 trials per novel object; 20 trials per new skill. |
| Real-world | Pick Up 24; Stack 48; Place 24; 12 for each novel object; 16 for each new skill. |
5.2 SIMPLER in-domain
In SIMPLER, Google robot has Visual Matching (VM) and Variant Aggregation (VA), and WidowX only has VM. VideoVLA is highest on WidowX VM average, Google VA average, and all 12 task global averages, with Google VM average being second.
| method | WidowX VM Avg | Google VM Avg | Google VA Avg | Avg All |
|---|---|---|---|---|
| RT-1-X | 1.1 | 42.7 | 30.5 | 24.8 |
| OpenVLA | 4.2 | 34.3 | 39.4 | 26.0 |
| SpatialVLA | 34.4 | 54.6 | 52.4 | 47.1 |
| $\pi_0$ | 53.1 | 53.5 | 43.4 | 50.0 |
| CogACT | 51.3 | 75.2 | 61.4 | 62.6 |
| VideoVLA | 53.1 | 73.1 | 62.8 | 63.0 |
5.3 SIMPLER novel objects
Google robot's Pick Up skill evaluated on 10 unseen objects from YCB and GSO. VideoVLA averages 65.2, which is significantly higher than SpatialVLA 50.8 and CogACT 42.4, and is best on 8/10 objects.
| method | Avg | Main points |
|---|---|---|
| OpenVLA | 6.4 | Several objects are close to 0. |
| SpatialVLA | 50.8 | Second highest; highest on cleaner bottle is 56.0. |
| $\pi_0$ | 28.8 | Moderate, but 0 for toy airplane. |
| CogACT | 42.4 | green cube 84.0, carrot 72.0, but several objects are lower. |
| VideoVLA | 65.2 | green cube 96.0, carrot 84.0, eggplant 88.0, plum 80.0, tennis ball 68.0. |
5.4 SIMPLER new skills / cross-embodiment transfer
The new skills come from the WidowX robot training data, but are not in the Google robot training set. VideoVLA was best across all skills with an average of 48.6, 28.2 points higher than second place CogACT at 20.4.
| method | Put Spoon | Put Carrot | Stack Block | Take Out Apple | Flip Cup | Pour Coke | Slide | Avg |
|---|---|---|---|---|---|---|---|---|
| OpenVLA | 0.0 | 12.5 | 0.0 | 26.7 | 0.0 | 4.0 | 0.0 | 6.2 |
| CogACT | 20.8 | 41.7 | 5.0 | 43.8 | 4.0 | 20.0 | 8.0 | 20.4 |
| VideoVLA | 56.3 | 58.3 | 20.0 | 93.8 | 20.0 | 52.0 | 40.0 | 48.6 |
5.5 Real Realman Experiment
The real robot is a Realman 7-DoF arm + gripper. All models are first pre-trained in OXE and then fine-tuned using the Realman data collected by the author. In-domain includes pick, stack, and place. Place needs to be picked up first and then placed, so the success rates of the two stages are reported respectively.
| method | Pick Up Avg | Stack Avg | Place Avg | Task Avg |
|---|---|---|---|---|
| OpenVLA | 8.3 | 6.3 | 14.6 | 9.7 |
| SpatialVLA | 37.5 | 20.8 | 10.4 | 22.9 |
| $\pi_0$ | 66.7 | 54.2 | 31.3 | 50.7 |
| CogACT | 75.0 | 64.6 | 35.5 | 58.4 |
| VideoVLA | 70.8 | 66.7 | 56.3 | 64.6 |
Among real novel objects, VideoVLA has a non-zero success rate for all 12 unseen objects, with an average of 50.6; CogACT is second, with an average of 26.9. In real cross-embodiment skill transfer, VideoVLA averages 58.0, which is significantly higher than CogACT 35.1.
| Real generalization setting | OpenVLA | SpatialVLA | $\pi_0$ | CogACT | VideoVLA |
|---|---|---|---|---|---|
| Novel objects Avg | 9.6 | 14.1 | 21.8 | 26.9 | 50.6 |
| New skills Avg | 8.3 | 13.5 | 28.5 | 35.1 | 58.0 |
5.6 Ablation experiment
| Backbone | Pick Up Coke Can | Move Near | Open/Close Drawer | Avg |
|---|---|---|---|---|
| OpenSora-1.1 | 67.7 | 57.1 | 25.9 | 50.2 |
| CogVideoX-5B trained from scratch | 18.6 | 10.8 | 9.2 | 12.6 |
| CogVideoX-5B pretrained | 92.3 | 82.9 | 66.2 | 80.4 |
| Future frames | Pick Up Coke Can | Move Near | Open/Close Drawer | Avg |
|---|---|---|---|---|
| 13 frames | 88.7 | 75.4 | 61.6 | 75.2 |
| 25 frames | 90.0 | 79.2 | 63.0 | 77.4 |
| 49 frames | 92.3 | 82.9 | 66.2 | 80.4 |
| Dual-prediction variant | In-domain Avg | Novel Objects | New Skills |
|---|---|---|---|
| Default | 80.4 | 65.2 | 48.6 |
| No video loss | 27.0 | 12.7 | 4.4 |
| Action only | 25.5 | 11.3 | 2.1 |
| appendix ablation | Pick Up | Move | Open/Close | Avg |
|---|---|---|---|---|
| Default bidirectional | 92.3 | 82.9 | 66.2 | 80.4 |
| Causal mask | 89.3 | 76.2 | 61.1 | 75.5 |
| Async train, sync inference | 87.3 | 74.1 | 60.2 | 73.8 |
| Async train, async inference | 84.7 | 70.8 | 57.4 | 71.0 |
These ablations support three points: pre-trained video generation backbones are critical; longer future video horizons facilitate action consequence inference; and bidirectional, simultaneous joint denoising of action and video is better than staged or unidirectional information flow.Appendix More Analysis
5.7 Imagination-Execution Correlation
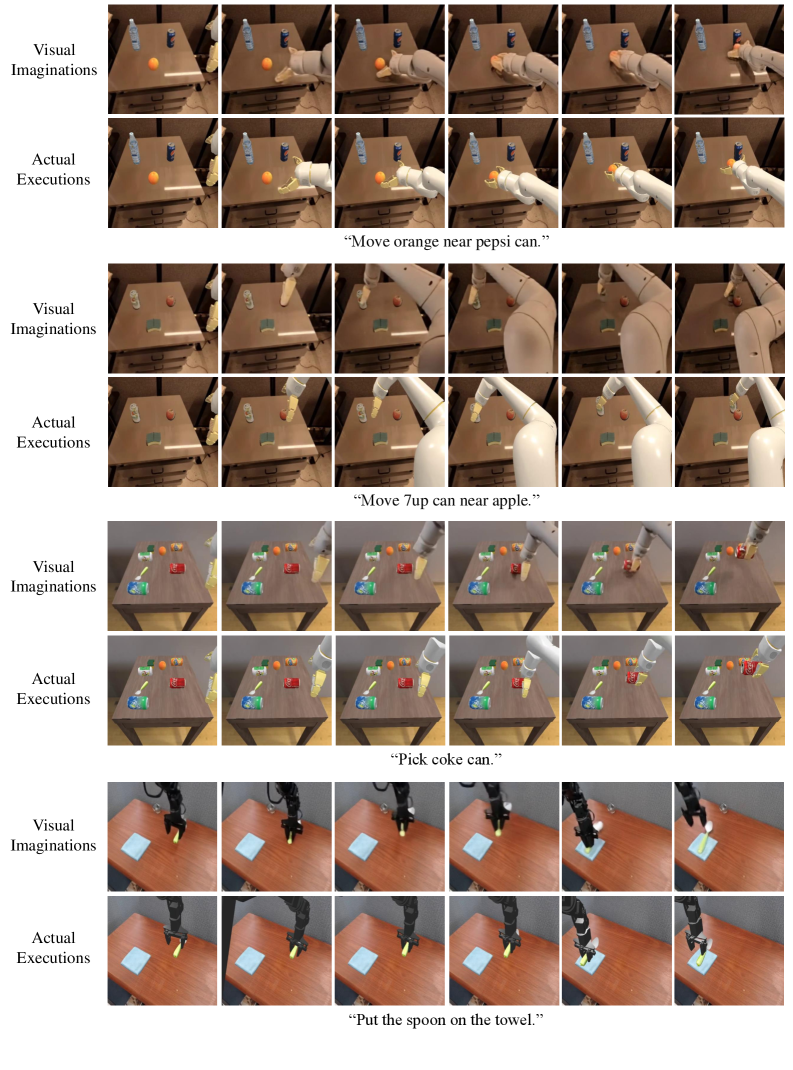
The author records the real video frames when performing the predicted action, and passes the predicted video latents through VAE decoder to obtain imagination frames. Then use SIFT to extract keypoints in the first frame, use SAM to segment the foreground, retain only the robot and object areas, and then use SAM-PT to track the keypoint trajectory. After aligning the imagination and execution trajectories through Hungarian matching, the normalized cosine similarity of the trajectory vectors is calculated, and the robot motion similarity is obtained after averaging.
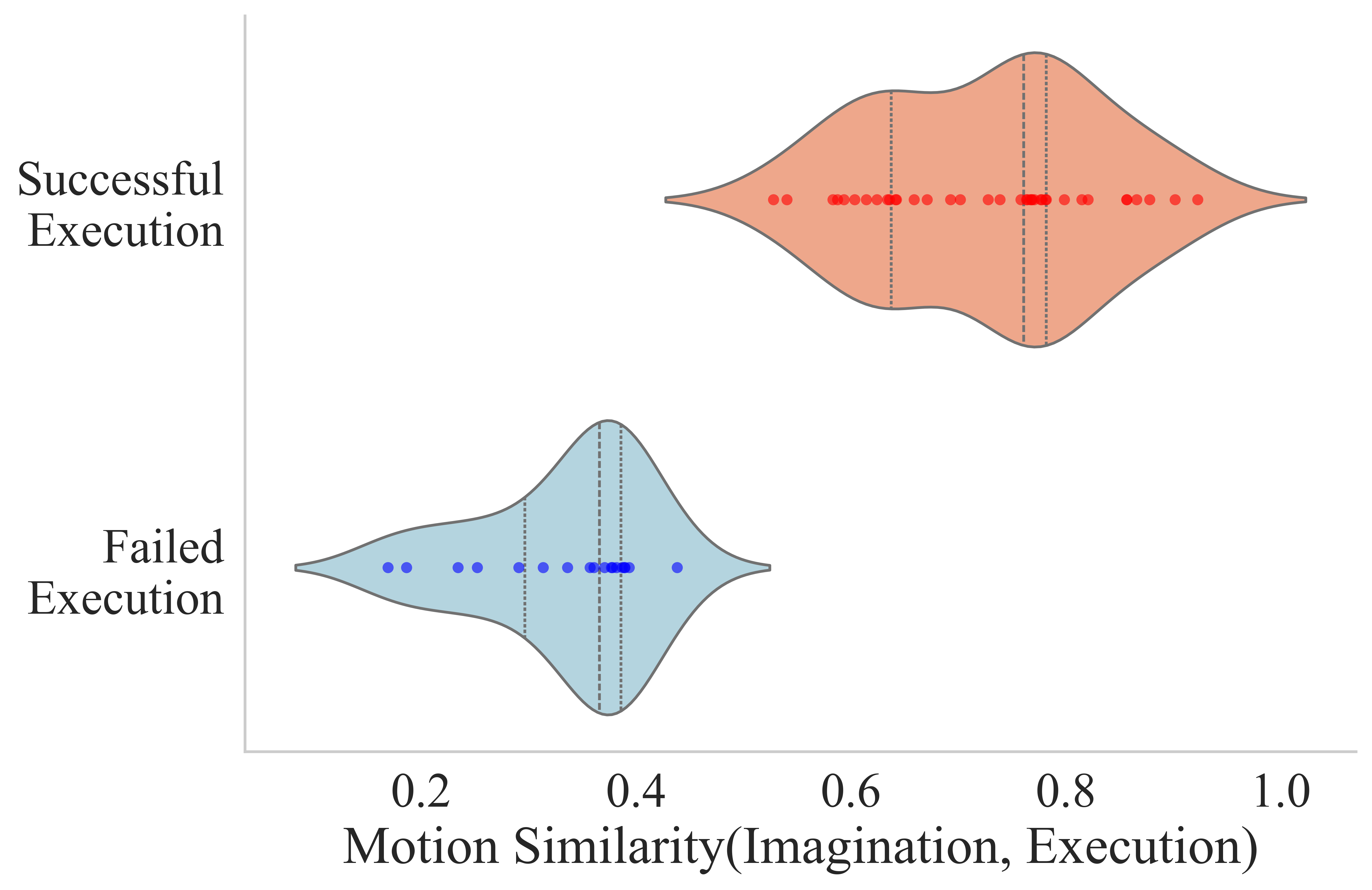
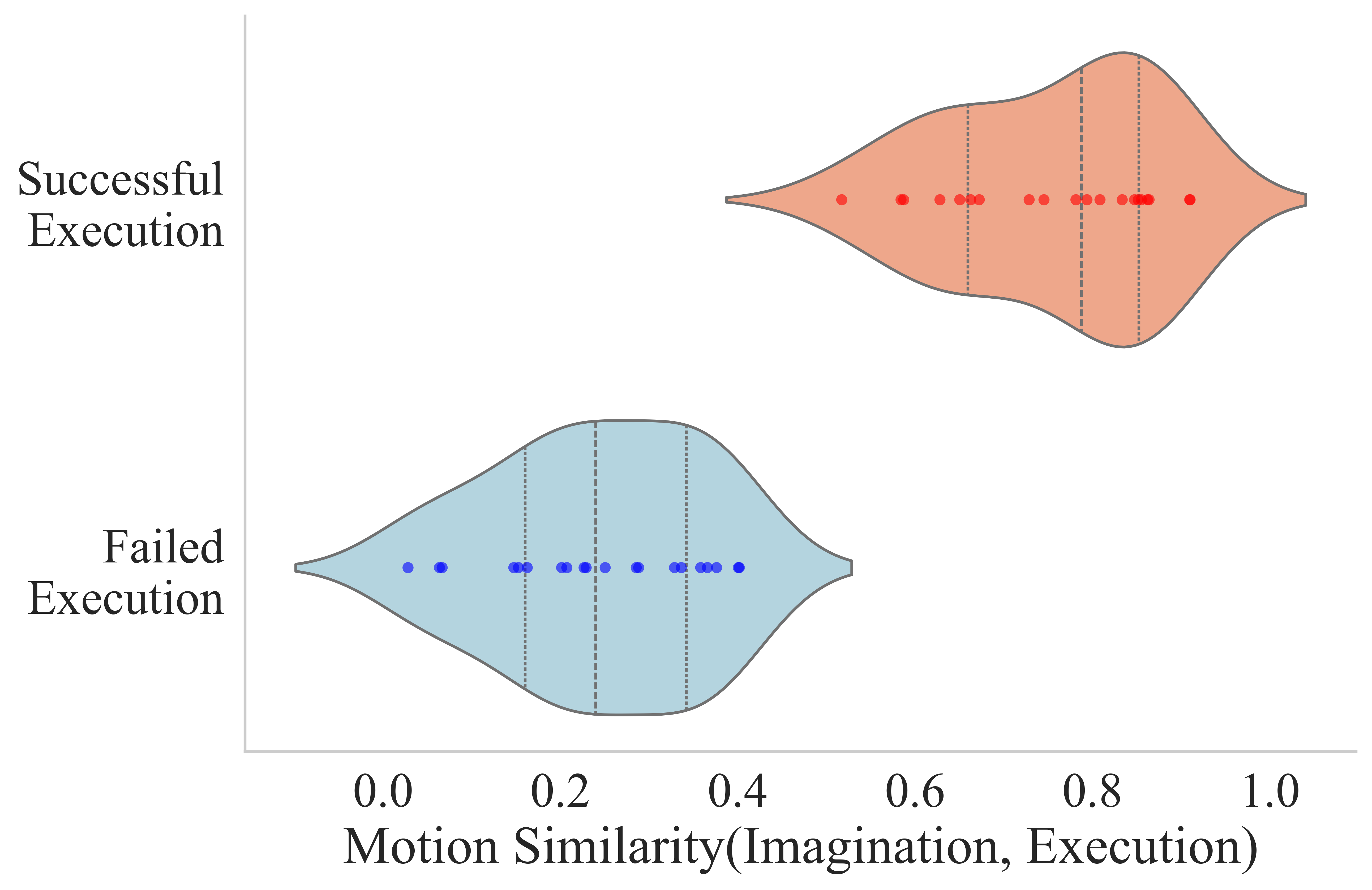
| Metric | Novel Objects | New Skills |
|---|---|---|
| Visual Imagination Success Rate | 84.0 | 63.4 |
| Actual Execution Success Rate | 65.2 | 48.6 |
Visual imagination is judged manually: success requires satisfying semantic following instructions without significant geometric distortion or violation of physical plausibility. Actual execution is lower than imagined, which the authors attribute to the additional difficulty of precise physical grounding, activation noise, and perception errors.


6. Reproducible auditing
Code and models
There is an official code entrance: VideoVLA-Project/VideoVLA. README provides `build.sh` environment preparation, CogVideo T5/VAE checkpoint configuration, and `sample_video_action.py` inference commands. The project page provides model links to Hugging Face.
| Recurring items | Information given in the paper/project | Status |
|---|---|---|
| Model structure | CogVideoX-5B backbone; T5 text encoder 226 tokens; 3D-causal VAE video encoder; 7-D action vector; DiT unified token sequence. | relatively sufficient |
| Training hyperparameters | 100K pretraining, 15K finetuning, 32 AMD MI300X, batch 256, AdamW, LR 1e-5, WD 1e-4, DDIM sampling. | relatively sufficient |
| data | OXE subset 22.5M frames; real Realman 5824 samples. Whether the real data is public is not made clear in the README. | Public reproducibility limited |
| Evaluation Agreement | The main text and appendix give SIMPLER/real-world trial counts, task list and main results. | fully |
| Full training cost | 32 AMD MI300X and large CogVideoX backbone. | High cost |
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Based on the paper's own evidence, the most valuable part is to convert the "future visual modeling capabilities of the video generator" into robot strategy training signals, rather than using the video generator as an external planner. Dual-prediction ablation shows: only retaining action or removing video loss, in-domain and generalization are significantly reduced, which directly supports that "visual imagination participates in training" is the core factor.
7.2 Why the results hold up
Results span simulation and reality, in-domain and generalization, and strong contrasts are reported in both novel objects and cross-embodiment skill transfer. Backbone ablation, future frames ablation, dual-prediction ablation, causal mask ablation, and diffusion schedule ablation jointly constrain alternative explanations: it is not that the simple model is large, nor is it simple action diffusion, but the pre-trained video generation backbone plus joint future modeling work together.
7.3 Limitations clearly stated by the author
The appendix states that the main limitation is inference speed. In a real deployment, VideoVLA predicts 4 future latents (13 frames) and 6 future actions (execute the first 3), using 10 DDIM denoising steps, in about 1.1 seconds on a single H100, so the effective control frequency is about 3 Hz. The author believes that the bottleneck comes from the large pre-trained video generator CogVideoX-5B, and proposes that it can be accelerated by robot-directed small video generators, one-step denoising (such as ShortCut) and distillation in the future.Appendix Limitations and Broader Impacts
7.4 Applicable boundaries
- The method is suitable for desktop operation tasks that require predicting visual consequences; for high-frequency closed-loop, fast contact, and fine force control tasks, the current 3 Hz control frequency may be insufficient.
- The complete training relies on large-scale OXE data, CogVideoX-5B and 32 MI300X, and ordinary laboratories are more likely to reproduce the inference or small-scale fine-tuning.
- The size of the real robot data set is 5824 samples, and the tasks are concentrated in pick, stack, and place; the generalization of the real open world still needs to be verified on a larger scale.
- Imagination success relies on manual judgment, which shows that the quality of visual imagination currently lacks fully automated and standardized evaluation indicators.