mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
1. 论文速览
| 阅读定位 | 内容 |
|---|---|
| 论文要解决什么 | 主流 VLA 依赖静态图文预训练,语义知识强,但物理动态、时序因果和操作过程仍要从昂贵机器人 demonstrations 中学习。论文要解决的是:如何把视频预训练中的动态先验直接用于机器人控制,降低动作数据需求。 |
| 作者的方法抓手 | 用 Cosmos-Predict2 这类 flow matching 视频模型作为 frozen video backbone,经 partial denoising 得到 noisy latent visual plan;动作解码器作为 Inverse Dynamics Model,cross-attend 到视频模型中间层表示,输出 action chunk。 |
| 最重要的结果 | SIMPLER-Bridge 平均成功率:mimic-video scratch 为 46.9%,高于 $\pi_{0.5}$-style VLA scratch 的 35.4%;task-specific $\tau_v$ 调优后为 56.3%。LIBERO 平均为 93.9%,高于 $\pi_{0.5}$-style VLA 的 85.9%。真实双臂灵巧手上,Packing 为 72.0、Package handover 为 93.0,均高于多视角 DiT-Block Policy 的 42.6 和 74.1。 |
| 阅读时要注意的点 | 本文和上一类“先完整生成未来视频再从像素中解动作”的方法不同,重点是 partial denoising 和中间 hidden states;作者甚至发现最佳策略性能常出现在高噪声 $\tau_v=1$ 附近,也就是说高保真视频重建不是必要条件。 |
核心贡献清单
- 提出 Video-Action Model (VAM):把预训练视频模型和 flow matching 动作解码器耦合,视频模型承担动态/视觉规划,动作头承担低层控制。
- 提出高效 action sampling:通过 partial denoising 停在中间 flow time $\tau_v$,避免每个控制步完整生成未来视频。
- 与 VLA 做等价动作头比较:$\pi_{0.5}$-style baseline 使用 PaliGemma 3B 和相同动作解码器,尽量把差异归因到视频表征 vs. 图文表征。
- 给出数据效率结论:在 LIBERO 上,视频先验条件下的动作解码器用 10% 数据即可达到 VLM-conditioned decoder 的最高成功率;1 episode/task 时仍有 77% 平均成功率。
2. 背景与问题设定
2.1 VLA 的瓶颈
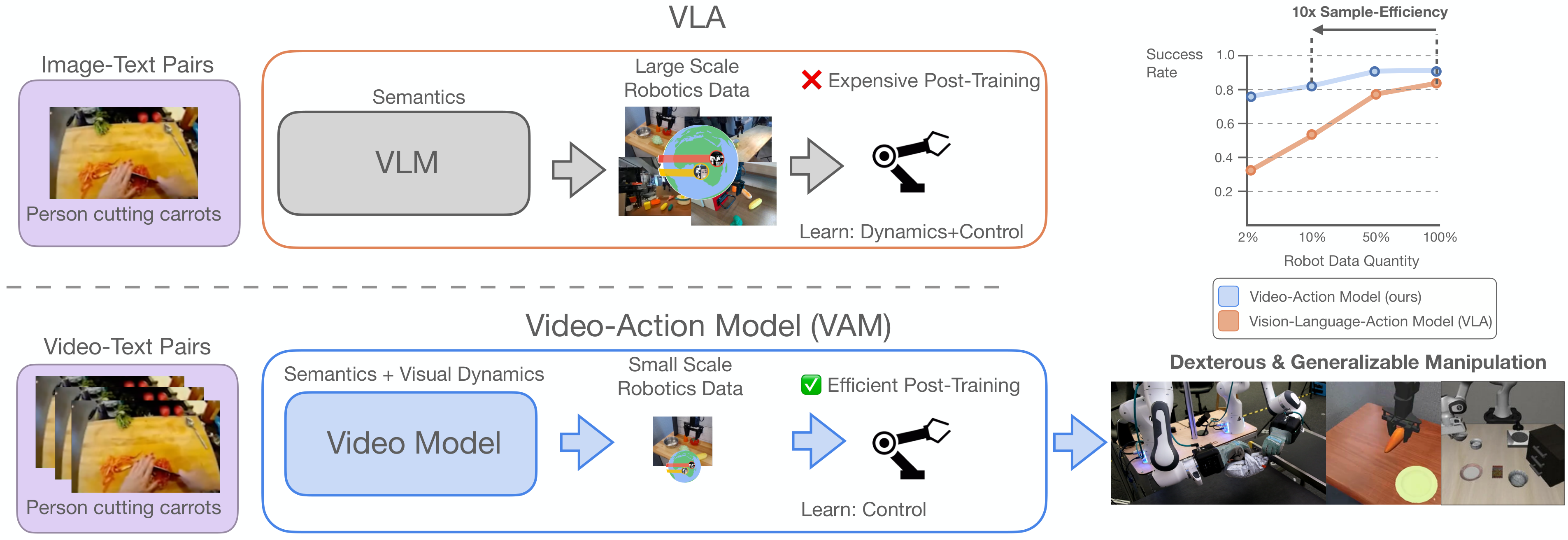
VLA 把 VLM 的语义知识迁移到机器人控制中,优势是能理解语言、物体和环境概念;但 VLM 的预训练数据主要是静态图文,缺少“动作导致什么变化”的时间信息。因此,真实物理动态、接触、形变、长程程序性操作,仍要在机器人 post-training 中从示教轨迹里学习。
作者认为这带来了不可持续的数据负担:如果 backbone 对物理因果是“盲”的,后续动作数据就必须承担语义、动态和控制三件事。mimic-video 的目标是把动态和视觉动作计划交给视频 backbone,动作 decoder 只做从 latent plan 到 motor command 的转换。
2.2 为什么不完整生成视频
已有视频策略方法常学习视频和动作的联合分布,或者先合成未来像素,再通过 tracking/IDM 得到动作。问题是完整视频合成在每个控制步都很贵,而且像素级未来可能有伪影,给动作解码带来分布外输入。本文的做法是直接使用视频模型中间表示,尤其是 partial denoising 后的 latent state。
2.3 作者的核心假设
如果视频模型已经学到了“任务会如何在视觉上展开”,那么动作解码器就不需要建模复杂的未来分布,只需要做逆动力学:给定当前 proprioception 和视觉计划,把它翻译成低层动作序列。作者把这种建模称为 Video-Action Model。
3. 相关工作脉络
| 技术线 | 论文定位 | 本文差异 |
|---|---|---|
| Imitation Learning | Diffusion Policy、flow matching decoder、$\pi_0/\pi_{0.5}$ 等用生成式框架建模多模态动作分布。 | mimic-video 继承 flow matching 动作 decoder,但把条件表示换成视频模型 latent plan。 |
| Vision-Language-Action Models | RT-2、OpenVLA、$\pi_0$ 系列依靠图文预训练语义迁移。 | 作者认为 VLA 的静态图文预训练缺少物理动态,本文用视频预训练补这个缺口。 |
| Video Models for Policy Learning | Dreamitate、Video Policy、world model 等使用视频预测辅助控制或规划。 | 本文不依赖完整像素重建,也不使用 heuristic tracking,而是从中间 noisy video latents 采样 marginal action distribution。 |
4. 方法细节
4.1 Case Study:控制难点被拆成“预测未来”和“执行未来”
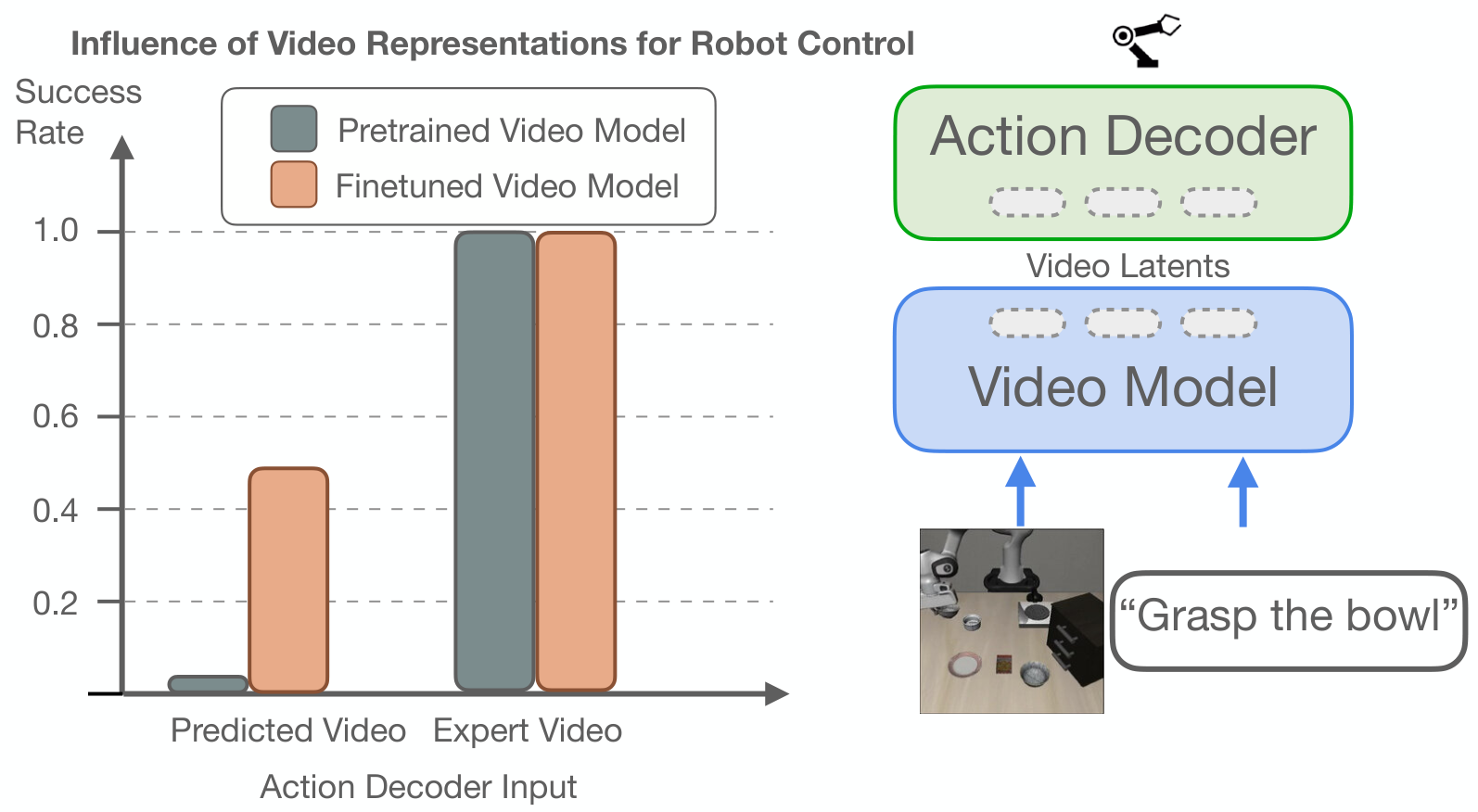
作者先做一个 oracle study:动作 decoder 条件输入可以是预测视频 latents,也可以是 ground-truth future video 的 oracle latents;视频 backbone 可以是标准预训练模型,也可以是机器人视频微调后的模型。结果显示,用 oracle latents 时成功率接近完美,无论 backbone 是否 finetune。这支持一个关键判断:一旦未来视觉计划是对的,低层动作解码相对简单;难点主要转移到视频模型预训练和视频域适配。
4.2 Flow Matching 基础
flow matching 把干净数据和高斯噪声之间的路径学成一个向量场,采样时从噪声积分回数据。
$$ x^\tau=(1-\tau)x^0+\tau\varepsilon,\quad \tau\in[0,1] $$$\tau=0$ 是干净数据,$\tau=1$ 是纯噪声。条件向量场为:
$$ u_\tau(x^\tau\mid x^0)=\frac{d}{d\tau}x^\tau=\varepsilon-x^0 $$模型 $v_\theta$ 通过回归这个向量场训练:
$$ \mathcal{L}_{\mathrm{CFM}}= \mathbb{E}\left\|v_\theta(x^\tau,\tau)-u_\tau(x^\tau\mid x^0)\right\|^2 $$采样时从 $\tau=1$ 积分到 $\tau=0$。本文利用连续时间参数 $\tau$,故意不走完整条路径,而是停在中间 $\tau_v$,形成 partial denoising。
4.3 模型结构
策略目标是预测 action chunk $\mathbf{A}_t=[\mathbf{a}_t,\dots,\mathbf{a}_{t+H_a-1}]$,条件包括多张 RGB 图像、语言指令 $l$ 和 proprioceptive state $\mathbf{q}_t$。模型由两个 flow matching 模块组成:
其中 $\mathbf{h}^{\tau_v}=v_\phi^{(k)}(\cdot)$ 是视频模型第 $k$ 层的 hidden states,动作 decoder 通过 cross-attention 使用这些表示。
视频模型实例为 Cosmos-Predict2,一个开源 2B latent Diffusion Transformer,使用 3D-tokenizer 编码视频帧。输入包括 5 帧 clean context prefix 和 noisy future latent patches;每个 transformer layer 包含 full-sequence self-attention、对 T5 语言指令的 cross-attention、以及两层 MLP。
动作 decoder 也是 DiT:分别用 MLP 编码 proprioception 和未来动作 token,拼成序列后加入 learned absolute positional encodings。每层包含对视频中间表示的 cross-attention、动作序列 self-attention 和 MLP;模块输出通过 AdaLN 调制,AdaLN 输入包含 $\tau_v$ 和 $\tau_a$ 的低秩 bilinear-affine 编码。
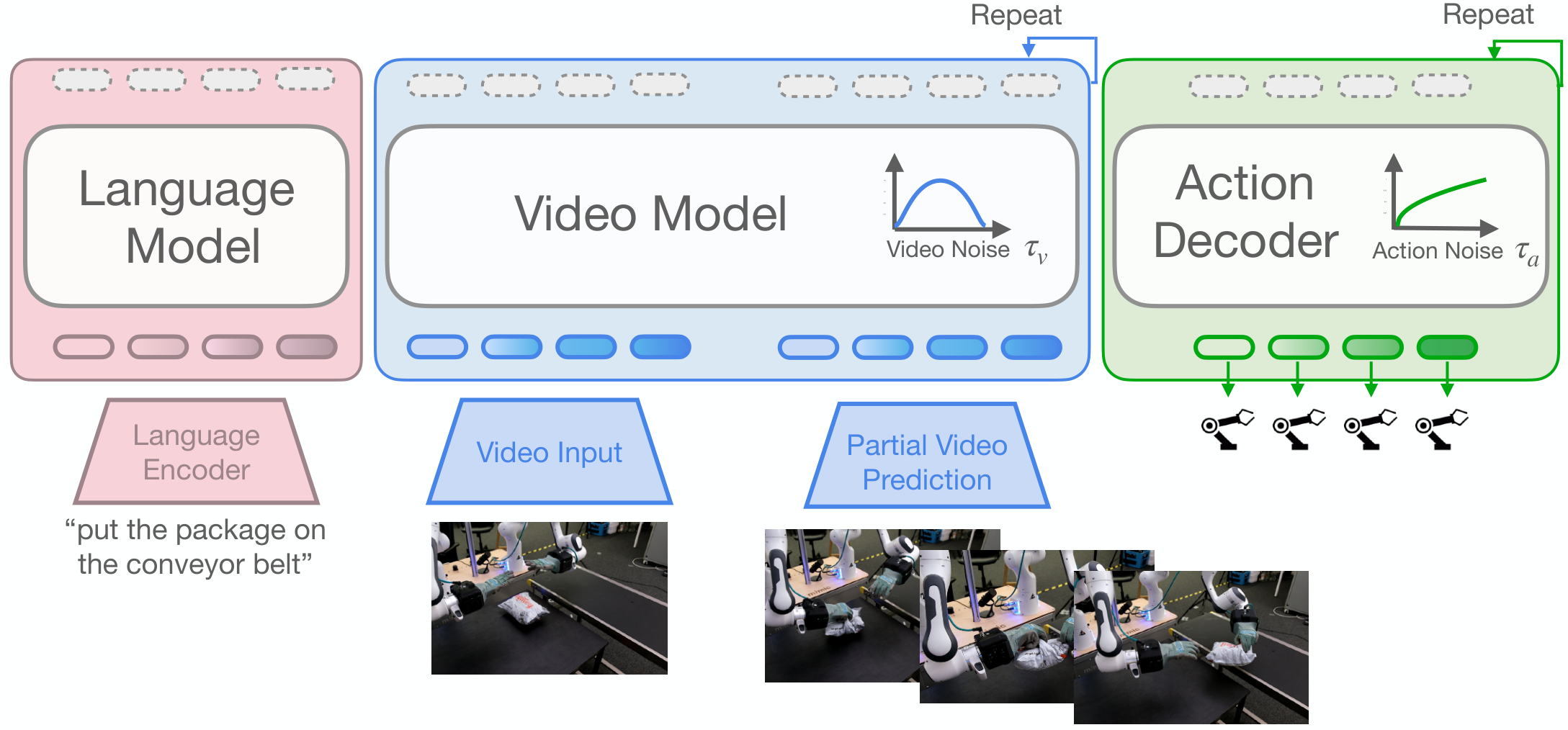
4.4 Action Sampling
推理时先采样 future video noise 和 action noise。视频流从 $\tau=1$ 积分到指定的 $\tau_v$,得到 partially denoised future latent;然后取视频模型前 $k$ 层表示 $\mathbf{h}^{\tau_v}$,动作 decoder 再从 $\tau_a=1$ 完整积分到 0,输出干净 action chunk。
4.5 训练流程
- Stage 1:视频 backbone 适配。用 LoRA 在机器人视频数据上 finetune 视频模型,使其适应目标视觉域和机器人动态,同时保持预训练时序推理能力。
- Stage 2:动作 decoder 训练。冻结视频 backbone,从零训练 $\pi_\theta$ 回归 action flow field,条件是冻结 backbone 提供的 $\mathbf{h}^{\tau_v}$。
- 独立采样 flow times。每次训练同时采样 $\tau_v$ 和 $\tau_a$,视频端 $\mathcal{T}_v$ 使用匹配视频预训练的 logit-normal,动作端 $\mathcal{T}_a(\tau_a)\propto\sqrt{\tau_a-0.001}$。
5. 实验与结果
5.1 评估设置
- SIMPLER-Bridge:使用 BridgeDataV2 训练的 Widow-X embodiment,测试现实视觉域偏移下的任务泛化。
- LIBERO:聚焦 LIBERO-Goal、Object、Spatial,每个 suite 10 个任务、每任务 50 条 expert demos,用于精密多任务桌面操作。
- 真实双臂灵巧手:两只 Franka Panda 手臂搭载 16-DoF mimic humanoid hands,观察包含 workspace view、4 个 wrist cameras 和 proprioception;评估 Package Sorting 和 Tape Stowing 相关任务。动作 decoder 的任务数据很少:sorting 为 1h33m/512 episodes,stowing 为 2h14m/480 episodes;视频 backbone 在更广的 200 小时语料上 finetune。
5.2 SIMPLER-Bridge 主结果
| 模型 | Put Carrot on Plate | Put Spoon on Towel | Stack Blocks | Eggplant | Average SR |
|---|---|---|---|---|---|
| OpenVLA finetuned | 4.2 | 8.3 | 0.0 | 45.8 | 14.6 |
| Octo finetuned | 8.3 | 12.5 | 0.0 | 43.1 | 16.0 |
| ThinkAct pretrained | 37.5 | 58.3 | 8.7 | 70.8 | 43.8 |
| FLOWER finetuned | 13.0 | 71.0 | 8.0 | 88.0 | 45.0 |
| $\pi_{0.5}$-style VLA scratch | 25.0 | 29.2 | 20.8 | 66.7 | 35.4 |
| mimic-video scratch | 37.5 | 37.5 | 12.5 | 100.0 | 46.9 |
| mimic-video scratch, per-task $\tau_v$ tuning | 54.2 | 41.7 | 29.2 | 100.0 | 56.3 |
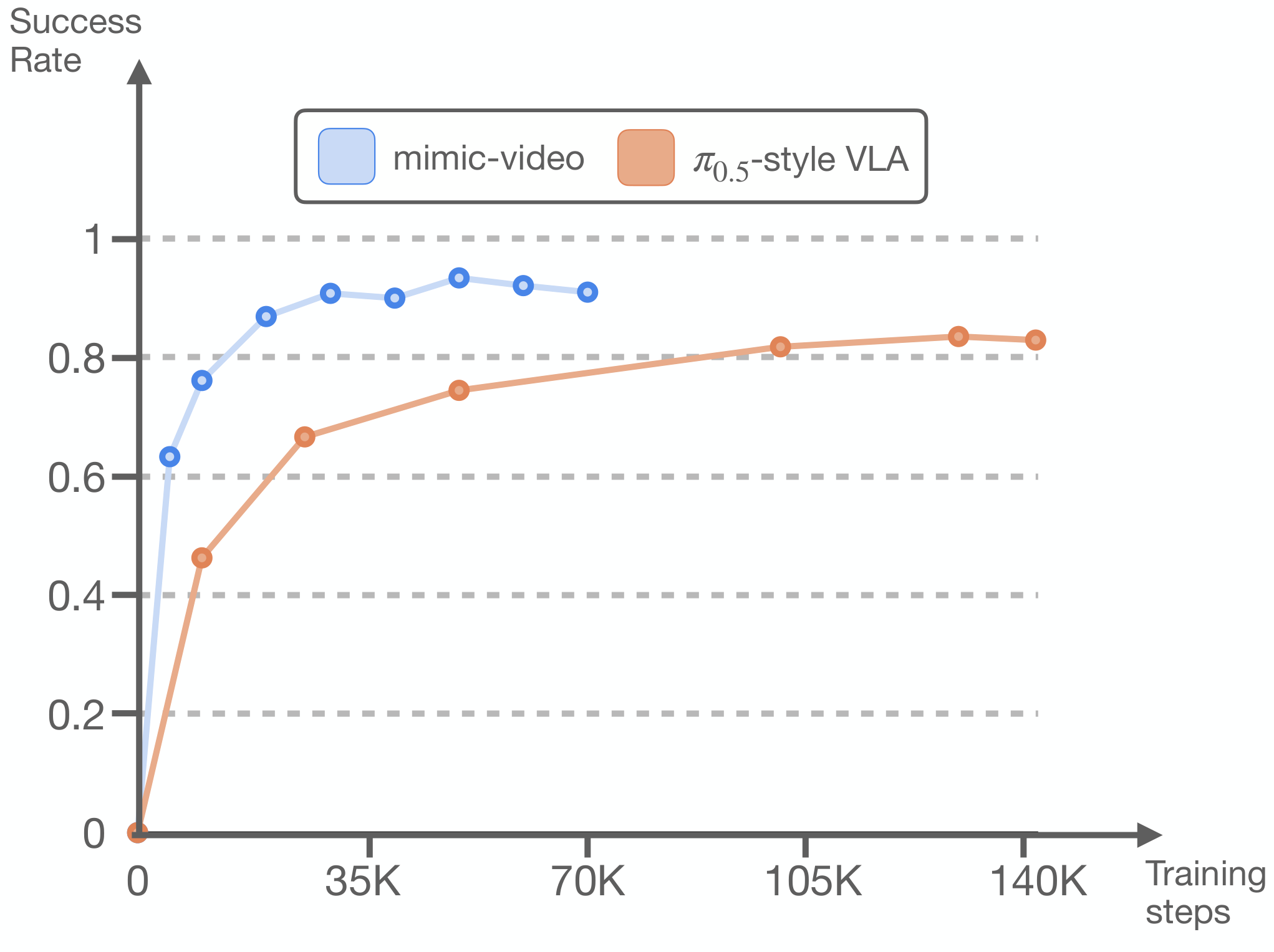
这里的关键比较是 scratch vs scratch:mimic-video 和 $\pi_{0.5}$-style VLA 使用等价动作 decoder 和相同目标数据条件,但前者用视频 backbone 表征,平均成功率高 11.5 个百分点。per-task $\tau_v$ 调优进一步把平均值推到 56.3。
5.3 LIBERO 主结果
| 模型 | Spatial | Object | Goal | Avg |
|---|---|---|---|---|
| Diffusion Policy scratch | 78.3 | 92.5 | 68.3 | 79.7 |
| Octo finetuned | 78.9 | 85.7 | 84.6 | 83.1 |
| DiT Policy finetuned | 84.2 | 96.3 | 85.4 | 88.6 |
| OpenVLA finetuned | 84.7 | 88.4 | 79.2 | 84.1 |
| OpenVLA-OFT finetuned | 96.2 | 98.3 | 96.2 | 96.9 |
| $\pi_{0.5}$-style VLA scratch | 79.2 | 94.0 | 84.4 | 85.9 |
| mimic-video scratch | 94.2 | 96.8 | 90.6 | 93.9 |
mimic-video scratch 已超过多数 finetuned generalist baselines,仅低于 OpenVLA-OFT finetuned 的 96.9。相比 $\pi_{0.5}$-style VLA scratch,平均提升 8.0 个百分点,Spatial suite 提升最大。
5.4 真实双臂灵巧手结果
| 模型 | Packing | Package handover |
|---|---|---|
| DiT-Block Policy | 11.0 | 30.0 |
| DiT-Block Policy + wrist cams | 42.6 | 74.1 |
| mimic-video | 72.0 | 93.0 |
这个结果的读法很重要:mimic-video 只条件于单个 workspace camera view,却超过了加入 wrist cams 的 DiT-Block Policy。作者解释为,视频生成先验的预测能力能在一定程度上弥合抓取遮挡带来的视觉不确定性。

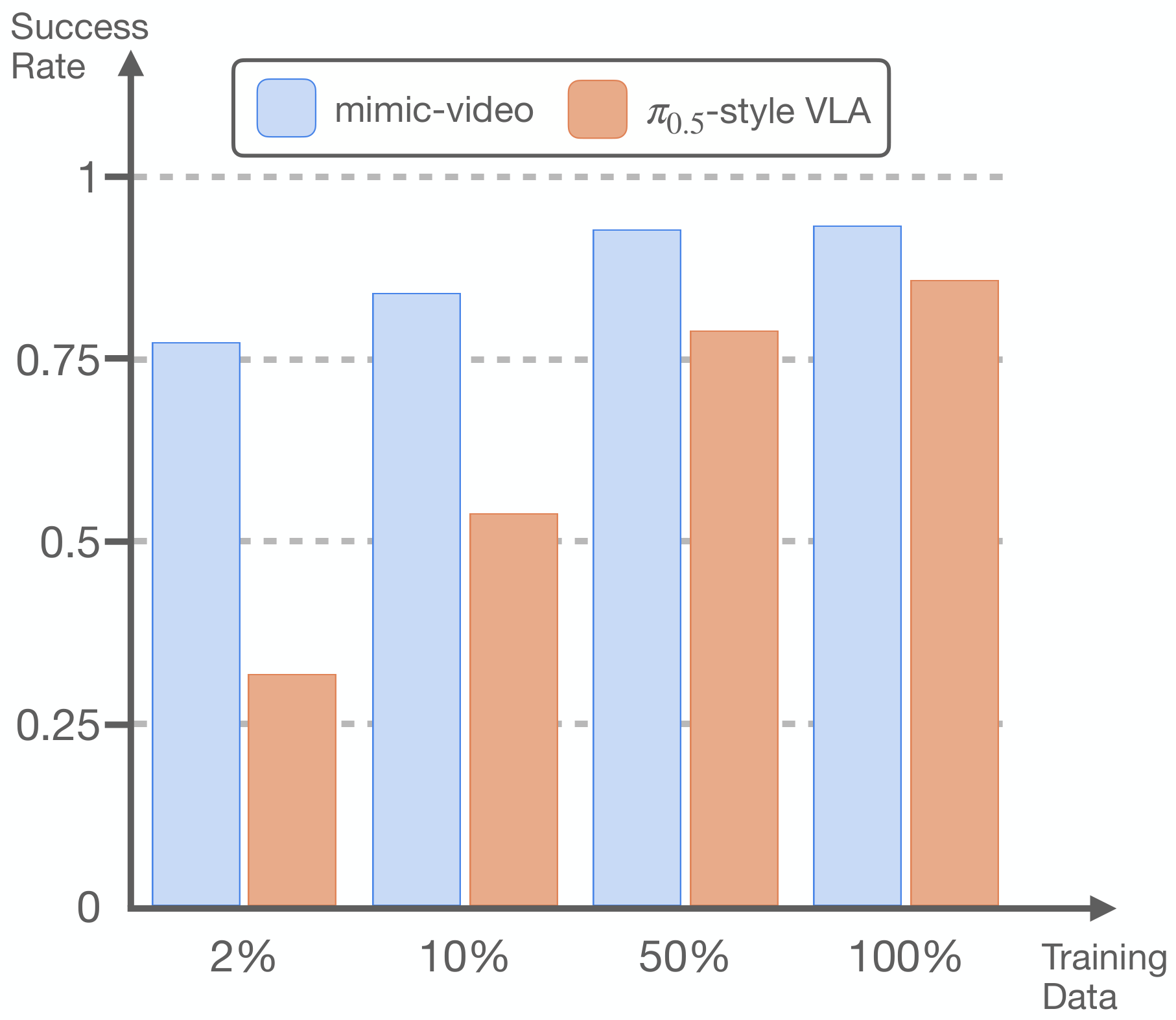
5.5 数据效率和收敛速度
作者在 LIBERO-Goal、Spatial、Object 上改变动作 decoder 训练数据规模。结果显示:mimic-video action decoder 只用 10% 训练数据,就能达到 VLM-conditioned decoder 的最高成功率;即使每个任务只用 1 个 episode,相当于减少 98% 动作数据,仍有 77% 平均成功率,接近 Diffusion Policy baseline。
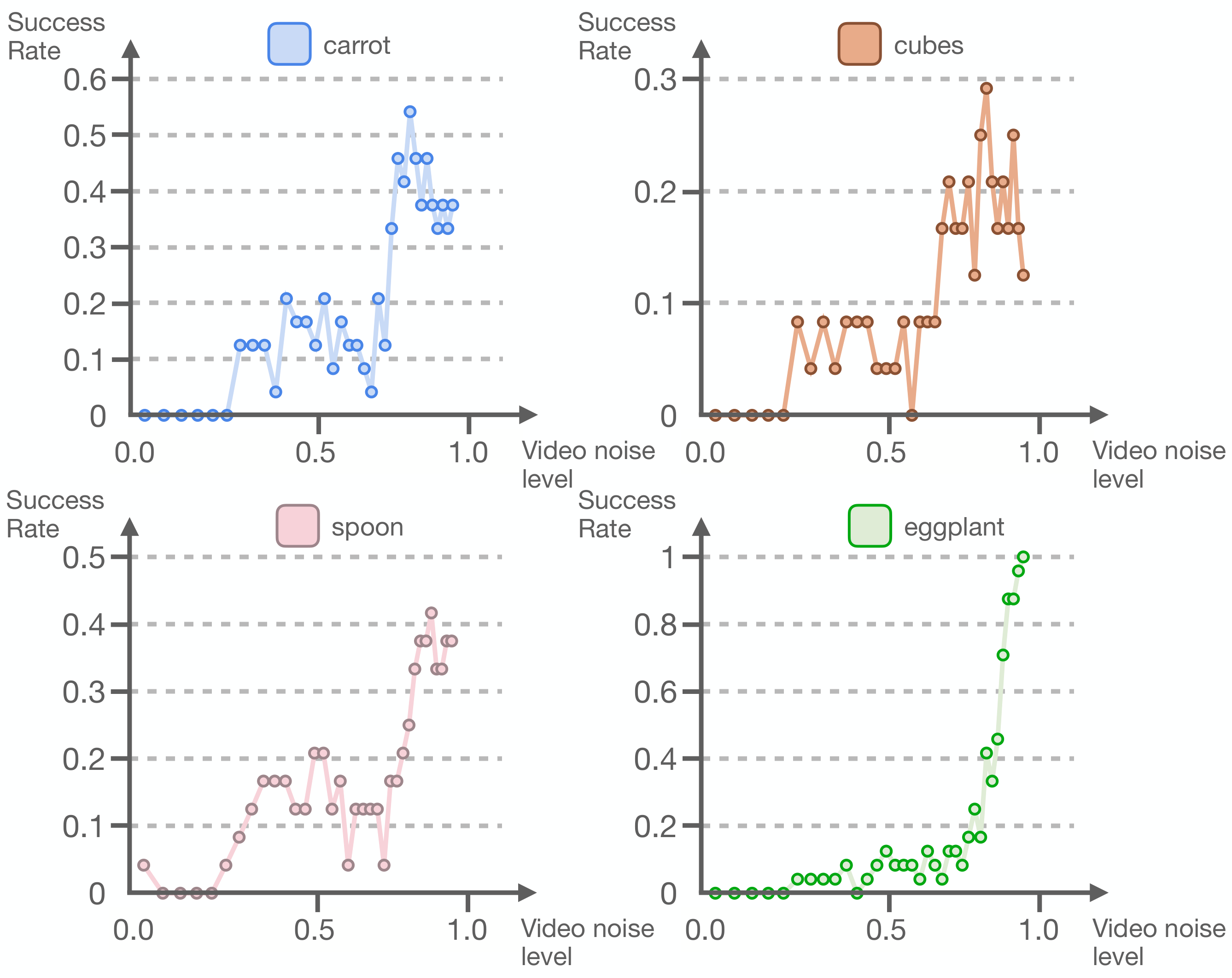
5.6 视频保真度和动作性能的权衡
作者扫 $\tau_v\in[0,1]$,研究完整视频重建是否必要。直觉上,更低 $\tau_v$ 代表更完整、更高保真的视频 latent,应该更好;但 SIMPLER 实验中,最佳 autonomous policy performance 出现在最高 flow time $\tau_v=1$。这说明动作 decoder 并不需要完全去噪的视频,只需要足够有用的中间表示。
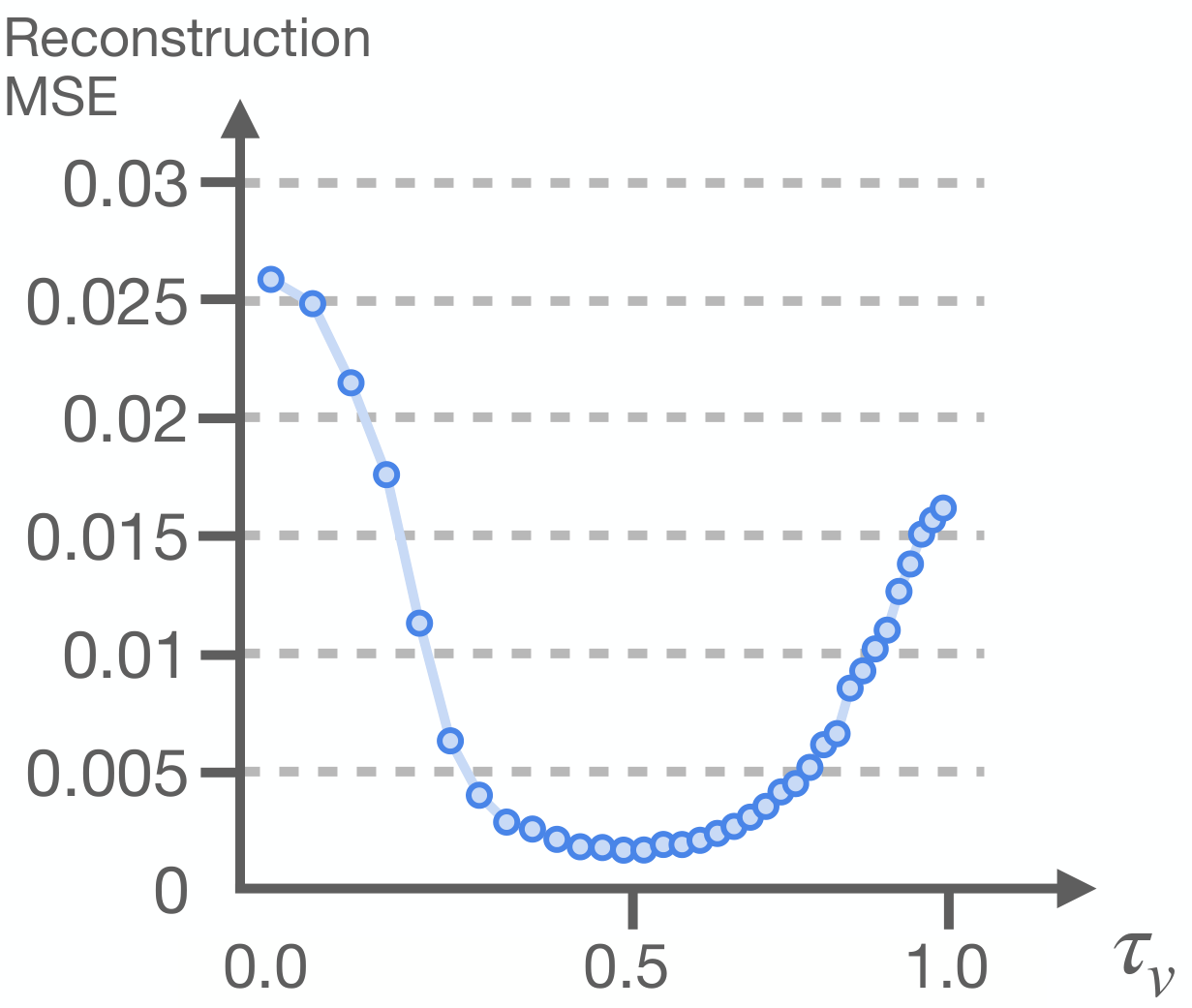
为隔离视频生成错误,作者又用 noisy ground-truth video latents 做 sweep,测 BridgeDataV2 上动作重建 MSE。最低 MSE 出现在 $\tau_v\approx0.4$,而向 $\tau_v=0$ 接近完整重建时误差反而上升。论文将此归因于中间 hidden states 的信息形态:接近 clean target 时,模型层可能趋向近似 identity mapping,反而对下游动作更少信息。
6. 复现与实现要点
6.1 训练超参数
| 超参数 | Video finetuning: BridgeDataV2 | LIBERO | mimic | Action decoder: BridgeDataV2 | LIBERO | mimic |
|---|---|---|---|---|---|---|
| Learning Rate | 1.778e-4 | 1e-4 | ||||
| Warmup Steps | 1000 | |||||
| Training Steps | 70043 | 7k-8k | 27300 | 14112 | 50k | 26k |
| LR Scheduler | Constant | Linear | ||||
| Weight Decay | 0.1 | |||||
| Gradient Clip | 10.0 | |||||
| Batch Size | 256 | 128 | 32 | 256 | 128 | 128 |
| Optimizer | AdamW | |||||
6.2 数据预处理
- 通用:所有 orientation 表示为旋转矩阵前两行对应的 6D vector;图像以 480×640 分辨率抽取或渲染。
- BridgeDataV2:Observation 是绝对末端位姿和连续 gripper joint state;Action 是未来末端位姿,相对于 proprioceptive pose 表示整个 action chunk,以及连续 gripper action。作者移除 3046 个 non-informative language labels,并删除每个 episode 的第一个 state 和 null-action。
- LIBERO:Observation 是绝对末端位姿和连续 gripper joint state;Action 是相对 proprioceptive pose 的末端动作和 binary gripper action。作者按 OpenVLA-OFT 的流程移除 replay 失败 episodes。
- mimic:Observation 包括绝对末端位姿、连续 hand joint states、两端执行器相对位姿、前一时刻末端和 hand actions;Action 是相对 proprioceptive pose 的末端位姿动作和绝对 hand joints action。
6.3 附录中的经验结论
- Video model source layer $k$:中间层 $k=19$ 带来最强策略性能,靠近初始层或最终层时成功率明显下降;作者认为理想情况下这个层选择应当可学习。
- Video observation horizon $H_o$:使用 5 帧历史观察优于只使用当前 1 帧。
- $\pi_{0.5}$-style VLA baseline:SIMPLER-Bridge 上 cross-attend 到 FAST-pretrained VLM 的第 11 层最好;decoder 训练 2-3 epochs 后继续训练提升不明显。
6.4 复现实验时最容易踩的点
- 不要把视频 backbone 解冻到动作数据上训练。论文的关键设计是 LoRA video finetuning 后冻结 backbone,再训练 action decoder。
- $\tau_v$ 是推理超参,不是固定必须完整去噪。默认 $\tau_v=1$ 反而可能最快、平均最好。
- 比较 VLA baseline 时,动作 decoder 架构应保持一致,否则无法判断提升来自视频表征还是解码器容量。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
最有价值的地方在于它没有只说“视频模型有物理先验”,而是把这个先验变成一个可控变量:同样的 flow matching action decoder,分别条件在视频 backbone 表征和 VLM backbone 表征上,再比较样本效率、收敛速度和成功率。再加上 oracle latent case study 和 $\tau_v$ sweep,论文把 VAM 的核心机制拆得比较清楚:性能不是来自完整像素生成,而是来自视频模型中间表示对动态和视觉计划的编码。
7.2 结果为什么站得住
- 比较设计较干净:$\pi_{0.5}$-style VLA baseline 使用 PaliGemma 3B 和与 mimic-video 相同的动作 decoder,并在等价数据条件下训练,使差异更集中在 conditioning representation 上。
- 任务覆盖多样:结果覆盖 SIMPLER-Bridge、LIBERO 三个 suite,以及真实双臂灵巧手高维接触任务。
- 机制实验直接:oracle future video latents 接近完美成功,说明动作解码确实可由视频计划表征支持;数据效率曲线显示 10% 数据达到 VLA decoder 最高成功率;$\tau_v$ 和 MSE 分析解释为什么 partial/noisy denoising 可优于完整重建。
- 附录给出实现细节:超参数、数据预处理、source layer、observation horizon 和 VLA baseline 调参经验都列出,便于判断复现边界。
7.3 作者明确给出的局限
- 单视角 video backbone:当前依赖 single-view video backbone,把策略限制在固定单 workspace view。作者认为原生 multi-view video architecture 可能改善空间推理和遮挡鲁棒性。
- 尚未形成统一跨 embodiment 大模型:论文没有把 VAM recipe 扩展到统一的大规模 cross-embodiment 模型,而作者认为这一步是释放视频 foundation model 泛化能力的关键。
- 真实任务范围有限:真实世界只覆盖聚焦的一组双臂灵巧手任务;更广泛操作行为还需要扩展。
- $\tau_v$ 仍是敏感推理超参:虽然 $\tau_v=1$ 是好默认值,但作者也报告 task-optimized $\tau_v$ 可进一步提升 SIMPLER 平均成功率,说明实际部署可能仍需任务级调优。
7.4 适用边界
从论文证据看,mimic-video 适合视觉动态能表达任务意图、而动作数据稀缺的机器人操作设置,尤其是需要泛化到视觉域偏移或遮挡较重的任务。它当前不等价于通用机器人 foundation policy:单视角、非统一跨 embodiment、真实任务范围有限,仍限制了直接外推。
7.5 组会阅读提醒
- 优先理解 $\tau_v$:它决定视频流停在多“噪”的 latent plan,论文的反直觉点就在于高保真重建不等于好策略。
- 把 Figure 2 和 Figure 7/8 连起来看:前者说明“未来视觉计划足够好时动作好解码”,后者说明“模型预测的完整未来未必是最佳条件”。
- 读主结果时区分 scratch、finetuned、pretrained 数据制度;论文最有力的比较是 mimic-video scratch 对 $\pi_{0.5}$-style VLA scratch。