Large Video Planner Enables Generalizable Robot Control
1. 论文速览
| 阅读定位 | 内容 |
|---|---|
| 论文要解决什么 | 现有 VLA 主要从静态图文预训练迁移到动作输出,但机器人动作数据稀缺,导致任务级泛化弱。论文要探索另一条路线:把视频作为机器人 foundation model 的主模态,用互联网规模视频中的时空动作轨迹来学习通用规划。 |
| 作者的方法抓手 | 训练 14B LVP 视频模型,输入一张或几张场景图和任务文本,输出 3 秒左右的视频计划;再用 HaMeR、MegaSAM、Dex-Retargeting、GraspNet、cuRobo 等模块把生成视频中的手/夹爪运动转为机器人 wrist trajectory、finger joint 或 gripper action。 |
| 最重要的结果 | 在 100 个第三方 in-the-wild manipulation prompts 上,LVP 的 Level 3 Task Complete 平均成功率为 59.3%,Best@4 为 82.0%,Level 4 Perfect 为 44.0%,明显高于 Wan 2.1、Cosmos-Predict 2、Hunyuan。真实机器人上,LVP 在 Franka+gripper 的多项任务中超过 $\pi_0$ 和 OpenVLA,并在 G1+Inspire dexterous hand 上完成开门、擦桌、扫球、撕胶带等 VLA baseline 不适用的任务。 |
| 阅读时要注意的点 | 这不是端到端闭环策略,而是“视频生成计划 + 开源重建/重定向 + 开环执行”的 pipeline。论文的强项是任务级零样本泛化和视频计划能力,弱项是实时性、重建误差、retargeting 失败和缺少闭环反馈。 |
核心贡献清单
- LVP 模型:一个面向 embodied planning 的 14B 视频 foundation model,基于 Wan I2V 14B 权重继续训练。
- LVP-1M 数据集:1.4M action-centric clips,来自 4 个机器人数据源和 4 个人类活动数据源,并配有多样化动作 caption。
- 视频到动作 pipeline:把生成的人手视频通过 4D hand trajectory、finger retargeting、gripper grasp extraction 转成真实机器人动作。
- 任务级泛化评估:使用第三方自由提出的 100 个野外任务,并用真实机器人验证视频计划能被执行。
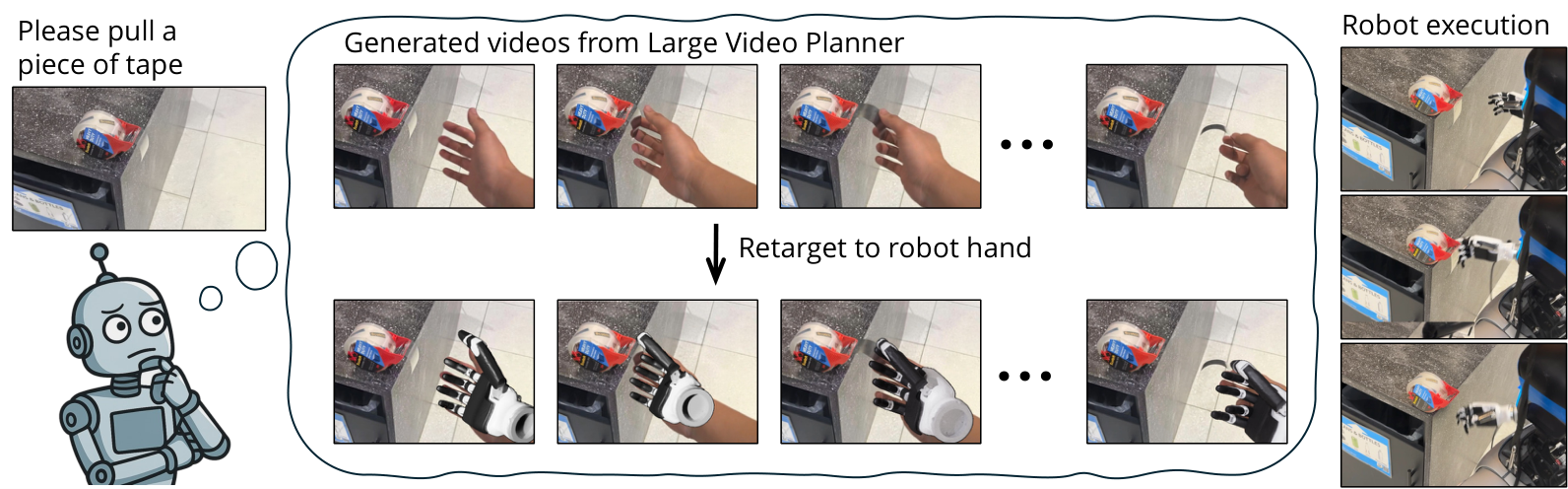
2. 背景与问题设定
2.1 任务级泛化比物体级泛化更难
论文区分了三种泛化:物体级泛化、配置级泛化、任务级泛化。很多机器人 foundation model 的评估仍接近训练分布,例如“pick”或“fold”这类动词在训练中大量出现,只是对象或位置变化。作者关心的是更强的 zero-shot task-level generalization:模型能否在没有见过的场景中完成完全不同的任务动词,例如 flush the toilet、tear the tape、grab gas nozzle。
2.2 为什么选择视频作为主模态
文本和静态图像提供语义与视觉识别,但不直接包含动作如何展开。视频天然记录状态随时间变化,包含物体接触、移动、形变和人类动作程序。因此,作者把视频看成更接近机器人规划的数据模态:视频生成模型可以在像素空间中“想象”任务完成过程,再由动作抽取模块执行。
2.3 与 VLA 的核心差异
VLA 通过 MLLM 的静态图文知识初始化,然后在少量机器人数据上学习 vision+language 到 action 的映射。LVP 则先在大量人类和机器人动作视频上学习 image/text 到 future video 的映射,再把生成视频作为 action plan。它的迁移不是“图文语义到动作”,而是“视频动态到机器人动作”。
3. 相关工作脉络
| 技术线 | 论文中的定位 | LVP 的区别 |
|---|---|---|
| Video Diffusion | Wan、Sora、Hunyuan 等视频生成模型擅长内容生成,但不一定能遵守机器人初始观察和物理动作约束。 | LVP 针对 embodied planning 继续训练,并引入 Diffusion Forcing 与 History Guidance 改善图像条件和时序一致性。 |
| Robot Foundation Models / VLA | RT-2、OpenVLA、$\pi_0$ 等从视觉语言模型扩展到动作输出。 | LVP 不直接预测动作 token,而是生成可解释的视频计划,再经后处理变成动作。 |
| Learning from Video Demonstration | 已有工作用视频生成指导控制、用 world model 做预测或评估。 | LVP 追求 foundation-model scale 的开放视频规划模型和大规模 action-centric 数据集,并在真实机器人上重定向执行。 |
4. 方法细节
4.1 总体 pipeline
整体是两阶段设计:第一阶段 LVP 在视频空间中生成视觉动作计划;第二阶段 action extraction 把视频计划转为具体机器人动作。论文用“开门”作为例子:机器人看到门把手并接收 “Open this door” 指令,LVP 生成手伸向把手、旋转、推门的视频;然后动作抽取模块把这个视觉计划转成五指灵巧手或平行夹爪可执行的轨迹。
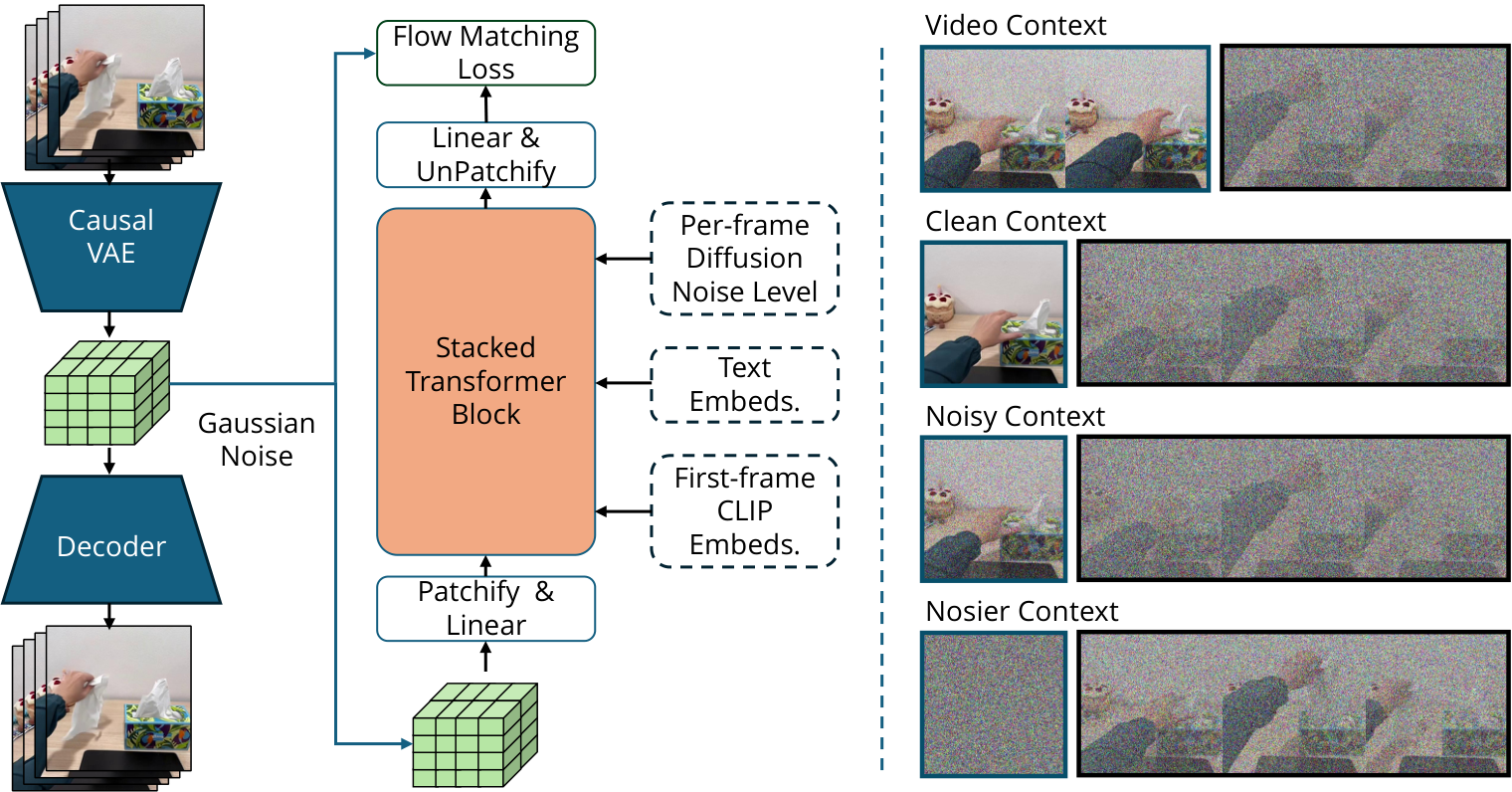
4.2 Latent Video Diffusion
LVP 使用 temporally causal 3D VAE 将像素视频压缩为 3D latent。VAE 将 $8\times8\times4$ 的时空 patch 编码为 16-channel embedding,把输入 $[1+T,3,H,W]$ 压到 $[1+\lceil T/4\rceil,16,\lceil H/4\rceil,\lceil W/4\rceil]$。第一帧会重复 4 次,使模型可同时处理单帧图像条件。
训练目标是 flow matching:在 clean latent 和高斯噪声之间插值,让模型预测从 noisy latent 回到 clean latent 所需的 flow。
$$ z_k=(1-k)z_0+k\epsilon,\qquad \epsilon\sim\mathcal{N}(0,1) $$ $$ \mathcal{L}= \| f_\theta(z_k,c,k)-k(\epsilon-z_0)\|_2 $$其中 $c$ 包含输入图像和文本指令,$k$ 是噪声水平。模型从 Wan I2V 14B 初始化,在压缩 latent 空间训练视频 DiT。
4.3 Diffusion Forcing Transformer
标准视频 diffusion 对所有帧施加统一噪声,而 LVP 使用 Diffusion Forcing:对历史 segment 和未来 segment 施加不同噪声水平。训练时随机选择历史长度 $\{0,1,\ldots,6\}$ 个 latent frames,把视频分成 history 与 future;history segment 有 50% 概率设为零噪声。这样同一模型可统一学习 I2V 和 V2V。
这个设计有两个好处:一是无需给可变长度 context frames 额外设计 cross-attention;二是在 sampling 时可以灵活设定历史帧为 clean context,从而做单帧 image-to-video 或多帧 video-to-video extension。
4.4 History Guidance
LVP 用 History Guidance 增强对初始图像/历史帧的遵循。若 $x_k$ 是未来 segment,$x_{\mathrm{hist}}$ 是历史条件帧,文本为 $c_{\mathrm{text}}$,则模型可分别估计有历史条件和无历史条件的 score:
最终 sampling 还叠加 text CFG,使生成视频同时遵循文本和初始图像。作者认为这能显著提升 plan quality,尤其是物理可行性和 instruction following。
4.5 Autoregressive Extension
由于模型支持最多 24 帧,即 6 个 VAE latent frames 作为 context,可以反复把已生成视频的末尾作为历史条件,迭代生成多阶段视频计划。论文给出三阶段例子,例如先移动鼠标,再堆叠黄色物体,再移动到桌上。

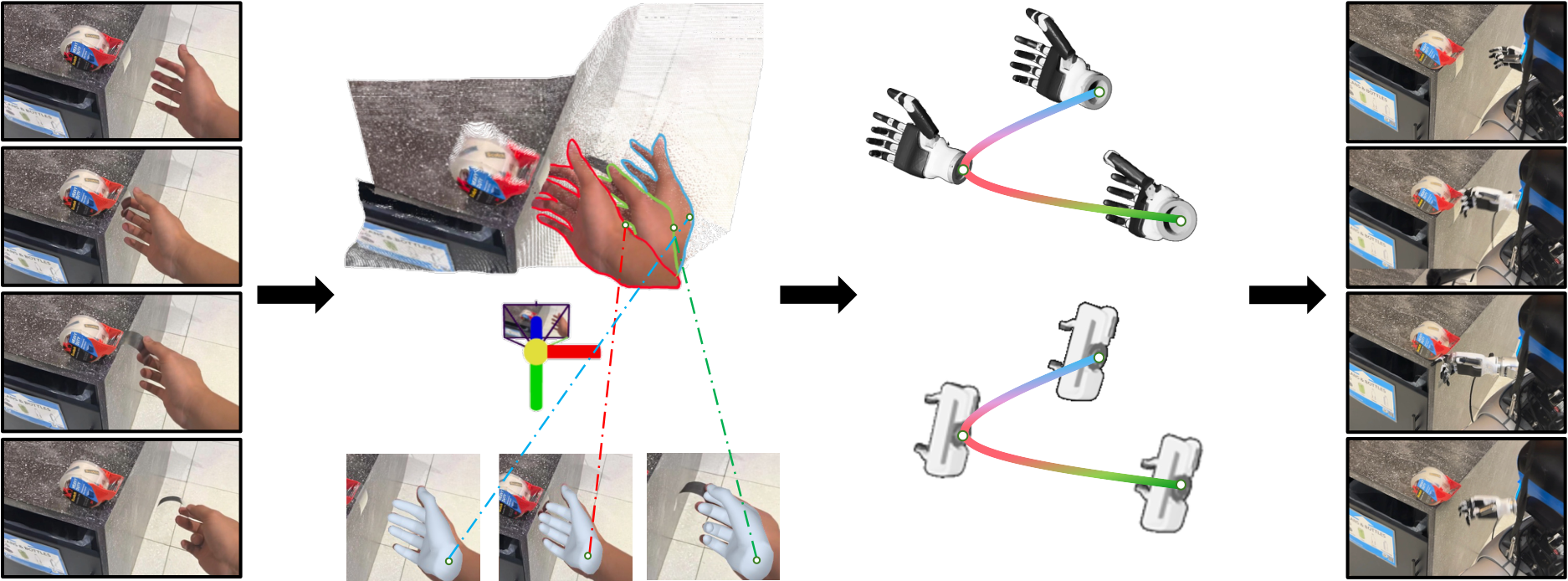
4.6 Video Plan 到 Robot Action
对人手视频,LVP 的动作抽取流程如下:
- HaMeR:逐帧估计 MANO hand vertices $\mathbf{V}_t$ 和 wrist orientation $\mathbf{R}_t$。
- MegaSAM:估计深度、相机内参和外参,用 4D reconstruction 解决单目尺度歧义和时间漂移。
- 4D alignment:用 wrist pixel 和 depth backprojection 得到 wrist trajectory,保留 HaMeR orientation,用 Savitzky-Golay 和 SLERP 做平滑。
- Dex-Retargeting:将人手关键点映射到灵巧手关节配置 $\mathbf{q}^R_t$。
- Robot execution:将 wrist pose 从相机坐标变换到机器人坐标,cuRobo 解 arm IK,finger joints 直接驱动 hand controller。
对平行夹爪,附录说明五指到两指是欠约束问题,因此用 GraspNet 预测候选 grasp poses,并用人手动作中的 grasp intent heuristic 触发夹取。
5. 实验与结果
5.1 第三方任务选择
作者让第三方参与者从日常环境中自由提出操作任务:拍摄包含手和目标物体的照片,写下 3-5 秒可完成的短任务,并鼓励场景和任务多样、困难。初始收集约 200 个任务,包括加油站、冲厕所、撕胶带等 OOD 场景和任务。另一批 annotators 过滤低质量、模糊或与常见 tabletop pick-and-push 过近的样本,最终保留 100 个高质量任务,并用 Gemini 改写成更详细的 task descriptions。
5.2 视频计划评估
模型输入 observation image 和重写后的 instruction,生成视频计划。对比对象包括 Wan 2.1 I2V 14B、Cosmos-Predict 2 14B、Hunyuan I2V 13B。每个 prompt 每个方法生成 4 个视频,第三方 annotators 按四级标准评分:
- Level 1 Correct contact:手是否接触正确物体和正确位置。
- Level 2 Correct end state:最后一帧是否达成目标。
- Level 3 Task complete:正确接触和正确终态,同时动作连续可行,允许小物理瑕疵。
- Level 4 Perfect:任务完成且物理和视觉无明显伪影。
| 方法 | L1 Avg | L1 Best@4 | L2 Avg | L2 Best@4 | L3 Avg | L3 Best@4 | L4 Avg | L4 Best@4 |
|---|---|---|---|---|---|---|---|---|
| Wan 2.1 I2V 14B | 83.9 | 99.0 | 47.0 | 80.0 | 39.3 | 76.0 | 20.5 | 53.0 |
| Cosmos-Predict 2 14B | 45.3 | 81.0 | 11.9 | 35.0 | 7.5 | 24.0 | 2.5 | 9.0 |
| Hunyuan I2V 14B | 68.7 | 96.0 | 27.3 | 65.0 | 13.5 | 42.0 | 7.2 | 27.0 |
| LVP | 87.3 | 100.0 | 63.2 | 85.0 | 59.3 | 82.0 | 44.0 | 71.0 |
最关键的是 Level 3/4。Wan 在 Level 1 还很高,说明能接触对物体,但在终态和完整动作上下降明显;LVP 在 Level 3 达到 59.3%,说明它更能生成连续、可行、语义正确的动作计划。


5.3 真实机器人执行
真实实验覆盖两个平台:Franka Emika Arm + parallel-jaw gripper,以及 Unitree G1 Arm + Inspire dexterous hand。VLA baseline $\pi_0$ 和 OpenVLA 只适用于平行夹爪任务,不支持多指灵巧手设置。
| 任务 | LVP | $\pi_0$ | OpenVLA |
|---|---|---|---|
| Pick Objects | 5/10 | 3/10 | 0/10 |
| Pick A into B | 3/10 | 1/10 | 0/10 |
| Open Drawer | 2/10 | 1/10 | 0/10 |
| Press Button | 4/10 | 0/10 | 0/10 |
| Pick Objects (OOD Object) | 4/10 | 0/10 | 0/10 |
| Pick A into B (OOD Object) | 2/10 | 0/10 | 0/10 |
| Pick Objects (OOD Scene) | 6/10 | 1/10 | 0/10 |
| Pick A into B (OOD Scene) | 1/10 | 0/10 | 0/10 |
| G1 + Inspire dexterous hand 任务 | LVP 成功率 |
|---|---|
| Pick Objects | 4/10 |
| Press Elevator Button | 4/5 |
| Sweep Tennis Ball into Bucket | 5/5 |
| Open Box | 2/10 |
| Open Door | 6/10 |
| Wipe Table | 8/10 |
| Scoop Coffee Beans | 3/5 |
| Tear off Clear Tape | 2/5 |
结果显示 LVP 在平行夹爪任务上总体优于 $\pi_0$ 和 OpenVLA,但成功率绝对值并不高,说明 pipeline 仍很脆弱。灵巧手结果更体现任务级泛化:开门、擦桌、扫球、撕胶带这类任务不在常见 pick-and-place 分布内,baseline 也无法直接适配多指手。

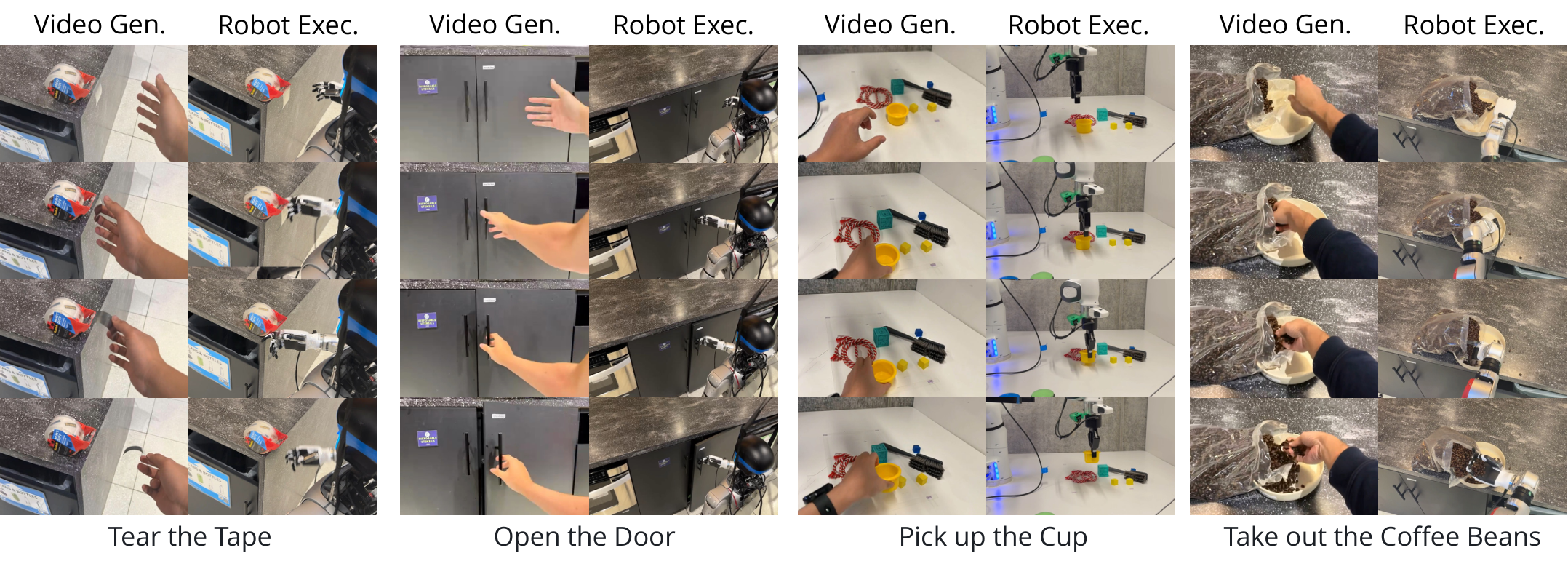
6. 复现与实现要点
6.1 数据集 LVP-1M
| 来源 | 过滤后 clips | 机器人? | 视角 | 形态 | in-the-wild | 双手/双臂 |
|---|---|---|---|---|---|---|
| Bridge | 25k | Yes | Third-person | Gripper | No | No |
| DROID | 192k | Yes | Third-person | Gripper | No | Yes |
| Language-Tables | 71k | Yes | Third-person | Gripper | No | No |
| AgiBot-World | 863k | Yes | Third-person | Gripper | No | Yes |
| Ego4D | 39k | No | Egocentric | Human Hand | Yes | Yes |
| Epic-Kitchens | 7k | No | Egocentric | Human Hand | No | Yes |
| Something-Something | 93k | No | Third-person | Human Hand | Yes | Yes |
| Panda-70M filtered | 196k | No | Third-person | Human Hand | Yes | Yes |
处理流程包括质量过滤、动作中心 caption、时间频率对齐。机器人数据往往动作慢、帧率不一,作者不是简单统一 FPS,而是把 clips 对齐到“人类完成同类原子动作的速度”,例如 3 秒动作 clip。
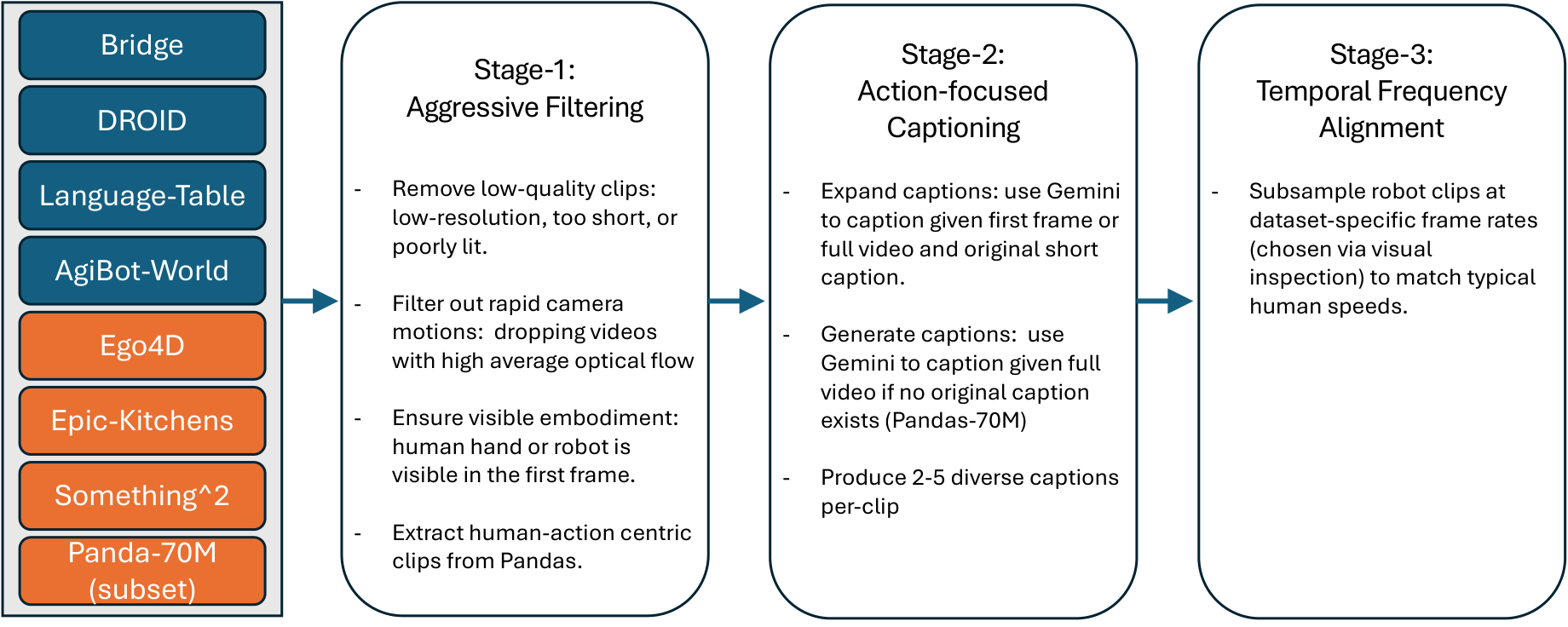
6.2 训练配置
- 训练样本:49-frame video clip,分辨率 832×480。
- VAE latent shape:104×60×13。
- Continue pretraining:batch size 128,60,000 iterations,warmup 1000 steps 后学习率 $1\times10^{-5}$。
- Low camera motion finetuning:batch size 128,10,000 iterations,学习率 $2.5\times10^{-6}$。
- 总训练:128 张 H100 SXM5 GPU,约 14 天。
- 第一阶段数据 reweighting:AgiBot-World 0.375、DROID 0.75、Ego4D 1.5、Pandas 0.5、Something-Something 0.5、Bridge 1.0、Epic-Kitchens 2.0、Language Table 0.05。
6.3 Panda-70M 子集抽取
附录给出 Panda-70M hand interaction 子集的提取流程:先用 108 个白名单关键词和 84 个黑名单关键词做 caption 过滤,下载约 692K videos;再切成 4 秒 clips,并在 768×1024 resize frames 上以 1 FPS 跑 human pose detection;最后用 Gemini-2.0 Flash 评估是否有丰富手部运动、是否有有意义动作、是否正常速度、是否没有镜头切换,只有 True/True/True/False 的样本保留,最终得到 196K clips。
6.4 真实机器人设置
| 任务集 | 机器人 | 控制频率 |
|---|---|---|
| Task Set 1 | Franka Panda Arm + Parallel-Jaw Gripper | 15 Hz |
| Task Set 2 | Unitree G1 Arm + Inspire Hand (DH56DFX) | 5 Hz |
G1 与 Inspire hand 通过 flange 机械连接,基于 Unitree teleoperation 框架做同步 arm-hand control。dex-retargeting 输出的关节角还要重映射到 Inspire Hand 的有效电机命令范围,才能实时执行。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
最有价值的地方是把“视频模型作为机器人规划器”的路线推到了 foundation-model scale,并配套开源数据和真实执行 pipeline。相比只在模拟任务上报告策略分数,论文让第三方自由提出任务、用视频模型生成计划、再把其中一部分计划转成真实机器人动作。这让读者能更清楚地看到视频预训练的任务级泛化潜力,以及它与传统 VLA 的差异。
7.2 结果为什么站得住
- 测试任务不是作者自选小集合:100 个 in-the-wild prompts 来自第三方参与者,且经过独立过滤,避免完全按模型能力设计评估。
- 四级评分细分了失败类型:Level 1 到 Level 4 区分接触、终态、完整动作和物理完美性,可以看出基线常能接触目标,但难以完成连续可行 motion plan。
- 对比模型强且同尺度:视频评估对比 Wan 2.1 I2V 14B、Cosmos-Predict 2 14B、Hunyuan I2V 13B,均是强视频生成模型。
- 有真实机器人闭环外验证:虽然执行是开环 pipeline,但它确实把生成视频转成 Franka 和 G1 灵巧手动作,并和 $\pi_0$/OpenVLA 在平行夹爪任务上比较。
- 附录披露了工程细节:数据过滤、Panda 子集抽取、训练超参、MegaSAM/HaMeR 对齐、gripper retargeting 和机器人控制频率都有说明。
7.3 作者明确给出的局限
- 实时性不足:单个视频计划在单张 A100 上生成需要数分钟,无法直接实时部署。
- 动作抽取链路会出错:4D reconstruction 和 hand pose estimation 都依赖开源模型,任何一步出错都会导致任务失败。
- Retargeting 有形态瓶颈:五指人手到灵巧手尚可,但转到低自由度平行夹爪时严重欠约束。
- 开环执行:整体机器人执行框架是 open-loop,不足以处理长程、动态或需要反馈纠错的灵巧任务。
7.4 适用边界
LVP 更适合生成“人类可以在几秒内完成、视觉上可观察、动作程序清楚”的短时 manipulation plan。它当前不适合需要实时闭环控制、强触觉反馈、精确力控或长程动态交互的任务。真实机器人表格中的低成功率也说明,这条路线的计划能力已很有启发性,但执行可靠性仍远未解决。
7.5 组会阅读提醒
- 不要只看 Level 1,真正说明规划能力的是 Level 3 Task Complete 和 Level 4 Perfect。
- 读方法时把“视频模型训练”和“视频到动作重定向”分开:前者是 foundation model 贡献,后者是工程 pipeline。
- 读真实机器人结果时同时看绝对成功率和任务类型。LVP 胜过 baseline 重要,但 1/10、2/10 这类结果也说明系统仍非常不稳定。