CoVAR: Co-generation of Video and Action for Robotic Manipulation via Multi-Modal Diffusion
1. Reading orientation and group meeting guide
| Introductory items | What does this paper answer? | Where do you focus on when reading? |
|---|---|---|
| Research object | Given an initial image, the robot's initial joint state and language instructions, future videos and frame-by-frame actions are simultaneously generated. | It is not a direct motion regression of traditional VLA, but treats motion as a modality co-generated with the video. |
| core assumptions | The pre-trained video diffusion model already has a useful prior on visual dynamics, and the action branch should exploit but not destroy this prior. | See if the double branch design and Bridge Attention are really more reasonable than a single joint DiT. |
| Main contributions | Parallel Action DiT, Bridge Attention, and Action Refinement Model in low-resolution scenes. | Judge "architectural novelty" and "experimental gain" separately: Which module is really supported by ablation? |
| potential impact | Provides a route for action-free video data to enter robot strategy learning: first learn the video world, and then add action generation. | Note that it currently still relies on expert action data to train the joint model, and it has not been proven that large-scale motion-free videos can directly bring policy improvements. |
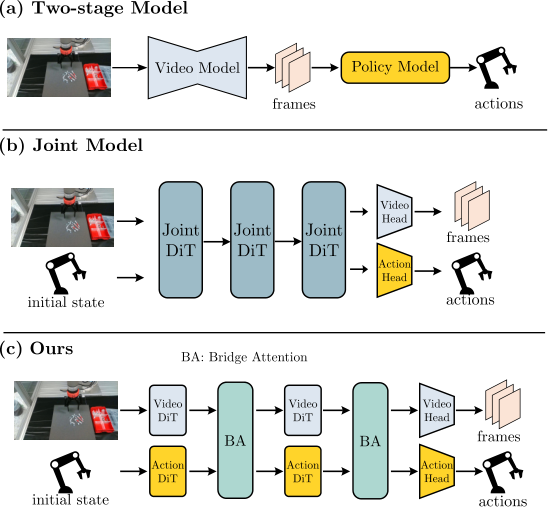
This paper lies at the intersection of embodied video diffusion / world model / robot policy learning. The typical contradiction it faces is: the video diffusion model can learn visual dynamics from a large number of videos without action labels, but the robot strategy requires actions; if the video is generated first and then inverse dynamics is used to push the action, the video error will be passed to the action, and the action inference will become weaker when the robotic arm or end effector is not visible; if the video and action are directly stuffed into a joint DiT, the already learned video generation capability may be sacrificed.
2. Problem background: Why video generation is not equal to robot strategy
2.1 Problems with the two-stage approach
Two-stage methods typically generate future videos based on initial observations and language targets, and then train inverse dynamics or policy networks to convert video plans into actions. This idea is intuitive, but there are two bottlenecks:
- Error cascade: There are slight deviations in the position of the object, the posture of the hand, or the moment of contact in the video, and subsequent motion regression will amplify these deviations.
- Visibility dependencies: If the robot body is blocked or cropped in the video, or the camera perspective is insufficient, it will be difficult to restore real joint control by visual changes alone.
2.2 Problems with early fusion of joint models
Another type of method splices video tokens and action tokens into the same DiT for joint denoising. The advantage is that information sharing is direct, but the disadvantage is that the modalities are very different: video is a high-dimensional spatiotemporal visual latent, and actions are low-dimensional continuous control vectors. The paper believes that when expert demonstration data is limited, allowing a unified DiT to adapt to both modalities at the same time may interfere with the visual knowledge of the pre-trained video model.
2.3 A middle path for CoVAR
The compromise of CoVAR is "dual branches + controlled communication": the video branch follows the pre-trained OpenSora-1.2 video DiT, and the action branch adds a new Action DiT; the two are not completely isolated, but exchange information through Bridge Attention at each location that requires interaction. This avoids pure two-stage posterior motion inference and avoids excessive rewriting of the video prior by a single joint DiT.
3. Method disassembly: Multi-modal Rectified Flow + Double DiT + Bridge Attention
3.1 Input and output definition
The model input includes the initial observation image $v_0 \in \mathbb{R}^{3 \times H \times W}$, the initial robot joint state $a_0 \in \mathbb{R}^{L}$ and the language command $c$. The output is the future video $v \in \mathbb{R}^{T \times 3 \times H \times W}$ and the paired action sequence $a \in \mathbb{R}^{T \times L}$. The action here is not inferred after generating the video, but is co-generated with the video during the diffusion/flow process.
| $v_0$ | Initial RGB observation image. |
| $a_0$ | Initial joint state, dimension is $L$. |
| $c$ | Natural language task instructions. |
| $v$ | The generated future video sequence is of length $T$. |
| $a$ | The generated action sequences are time-aligned with the video frames. |
3.2 Multi-modal Rectified Flow
This paper uses rectified flow to model the generation path of joint modes. Let the joint data sample be $X_0=(x_0^1, x_0^2)\sim \Pi_{data}$, where $x_0^1$ is the video latent and $x_0^2$ is the action. The noise end is $X_1=(x_1^1, x_1^2)\sim(\mathcal{N}(0, I_{d_1}), \mathcal{N}(0, I_{d_2}))$. The ODE corresponding to the linear path is:
Intuition:
Rectified flow hopes to learn a "straight path velocity field" from data to noise, or from noise back to data when sampling. The multimodal version simply treats the video latent and the action together as a joint state.
Neural network $v_\theta=(v_\theta^1, v_\theta^2)$ predicts the vector fields of two modes, and the training loss is:
Reading reminder:
The formula in the paper directly adds the errors of the two modes, without explaining whether the weights, normalization, and time sampling of the two modes are completely shared. To reproduce, this is a detail that needs to be confirmed from the code, but no official code link is currently found.
3.3 Model architecture: retain the video backbone and connect Action DiT in parallel
CoVAR is built on OpenSora-1.2. The video branch retains the pre-trained video diffusion backbone; the action branch uses a parallel Action DiT. The dimensionality of action data is low, so the author did not train VAE for actions, but used a lightweight MLP encoder to obtain action embeddings. Action DiT also receives the text instruction $c$ through cross-attention, forming a conditional generation structure symmetrical to Video DiT.
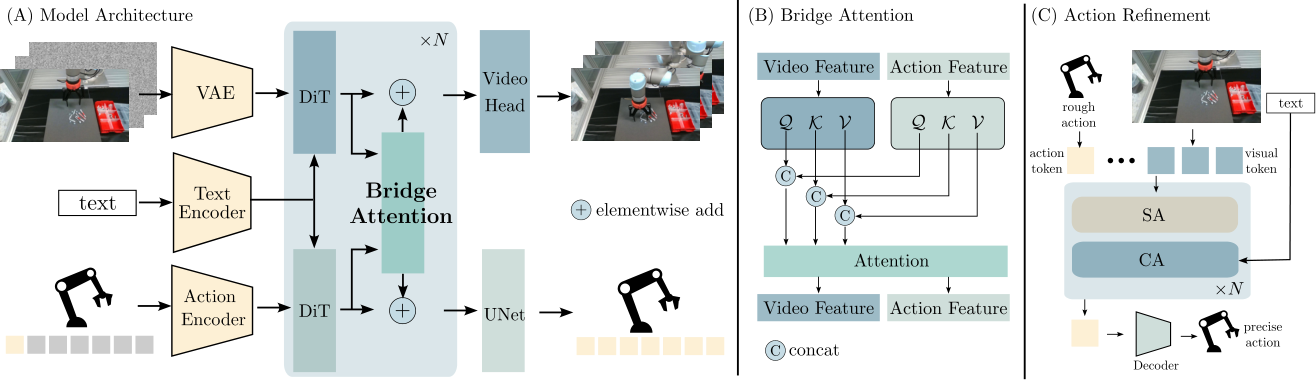
3.4 Bridge Attention
The goal of Bridge Attention is to allow two modalities to interact but retain their respective representation spaces. Let the video characteristics be $f_v \in \mathbb{R}^{B\times N_v\times C}$, the action characteristics are $f_a \in \mathbb{R}^{B\times N_a\times C}$. Unlike standard self-attention, which uses the same set of Q/K/V projections to process spliced tokens, Bridge Attention parameterizes query, key, and value for video and action respectively:
Intuition:
It's like "meeting after each translates into their own Q/K/V language". Projections within modalities remain independent, but the attention matrix still allows video tokens and action tokens to read each other.
The paper compares it with two alternative communication methods: one is direct self-attention to splice all tokens, and the other is bidirectional cross-attention. Ablation shows that Bridge Attention is better in both video quality and real-world task success rate.
3.5 Action decoder and Action Refinement
The author emphasizes that action decoder is critical to action accuracy and training convergence. CoVAR uses UNet as the action decoder instead of the common MLP or ResNet. The explanation of the paper is that UNet's multi-scale processing is more suitable for capturing the hierarchical motion structure in temporal action sequences.
For low-resolution data sets such as Libero90, the paper additionally uses Action Refinement Model. The original CoVAR first generates coarse actions, and then the refinement module receives coarse actions, initial image tokens, and text conditions to turn coarse actions into more refined controls. This module is very critical on Libero90: the success rate without refinement is significantly lower than the full model.

3.6 Training/inference pseudocode
训练阶段:
for each demo (v0, a0, instruction c, future video v, action sequence a):
encode video into video latent x0_video
encode action into action embedding x0_action
sample Gaussian noise x1_video, x1_action
sample time t
interpolate joint state Xt between X0 and X1
Video DiT predicts video flow with text/image conditions
Action DiT predicts action flow with text/joint-state conditions
Bridge Attention exchanges video/action information
optimize video flow loss + action flow loss
推理阶段:
given current observation, current joint state, instruction:
initialize video/action noise
integrate learned rectified flow for 30 sampling steps
decode video frames and actions
if low-resolution setting: refine coarse actions
interpolate generated 35-frame open-loop actions to 100 Hz robot control4. Experiments and results: video quality, action success rate and ablation
4.1 Dataset and training settings
| Dataset | Size/Features | CoVAR settings |
|---|---|---|
| CALVIN | About 20k teleoperated demonstrations, with text instructions, video resolution 200×200. | Training setting ABCD, randomly generate 200 novel test scenes for rollout. |
| Libero90 | 90 tasks, 50 expert demonstrations per task, video resolution 128×128. | Use action refinement; the refinement model is fine-tuned with 450 video-action pairs. |
| Real dataset | 1K demos collected by the author, including bowl stacking, nut/screw/tenon picking and placing, etc. | Resolution 180×320; UR5 platform; generate video-action pair every 35 frames. |
The total number of parameters of the model is about 1.4B, including 1.1B for the video diffusion part and 0.3B for the new module. Training takes about 1 day, using 4 GPUs. During real robot inference, the rectified flow sampling step is set to 30, and it takes about 4 seconds to generate a 35-frame video-action pair; the robot control frequency is 100 Hz, so the generated open-loop action sequence needs to be interpolated.
4.2 Video quality
Video quality is measured with PSNR, SSIM, LPIPS and FVD. CoVAR has an overall advantage over joint-model baselines such as UVA, PAD, and UWM on CALVIN and Libero90, and is close to the pure video model OpenSora-1.2. This supports the author's core claim: adding action modality does not significantly damage the video generation capabilities of the pre-trained video model.
| Dataset | method | PSNR ↑ | SSIM ↑ | LPIPS ↓ | FVD ↓ |
|---|---|---|---|---|---|
| CALVIN | UVA | 19.01 | 0.758 | 0.180 | 97.90 |
| PAD | 18.72 | 0.734 | 0.174 | 83.40 | |
| UWM | 18.04 | 0.730 | 0.181 | 85.85 | |
| OpenSora | 19.60 | 0.768 | 0.171 | 61.00 | |
| CoVAR | 19.95 | 0.766 | 0.156 | 72.42 | |
| Libero90 | UVA | 19.57 | 0.716 | 0.154 | 86.21 |
| PAD | 19.65 | 0.781 | 0.218 | 98.39 | |
| UWM | 19.87 | 0.735 | 0.212 | 87.83 | |
| OpenSora | 20.18 | 0.817 | 0.156 | 63.33 | |
| CoVAR | 20.09 | 0.826 | 0.143 | 70.64 |

4.3 Action success rate
Action evaluation can better reflect the value of the paper. On CALVIN, CoVAR is better than UVA/UWM/PAD/Unipi in five tasks: drawer, cabinet, light, pick, and push. On Libero90, the full CoVAR is significantly better than the version without refinement, indicating that refinement is not a decoration module, but one of the core sources of success rate in low-resolution scenes.
| CALVIN method | Drawer | Cabinet | Light | Pick | Push |
|---|---|---|---|---|---|
| UVA | 0.875 | 0.667 | 0.711 | 0.758 | 0.785 |
| UWM | 0.813 | 0.733 | 0.644 | 0.576 | 0.714 |
| PAD | 0.781 | 0.467 | 0.489 | 0.485 | 0.642 |
| Unipi | 0.469 | 0.267 | 0.289 | 0.182 | 0.452 |
| CoVAR | 1.000 | 0.800 | 0.867 | 0.909 | 0.929 |
| Libero90 method | Pick-and-place | Open/Close | Combination |
|---|---|---|---|
| UVA | 0.676 | 0.640 | 0.489 |
| UWM | 0.606 | 0.600 | 0.400 |
| PAD | 0.625 | 0.480 | 0.355 |
| CoVAR w/o refinement | 0.592 | 0.520 | 0.422 |
| CoVAR | 0.873 | 0.860 | 0.711 |
| Real method | Nut | Screw | Dowel |
|---|---|---|---|
| Unipi | 0.00 | 0.06 | 0.02 |
| RoboEnvision | 0.04 | 0.10 | 0.12 |
| CoVAR | 0.64 | 0.74 | 0.70 |

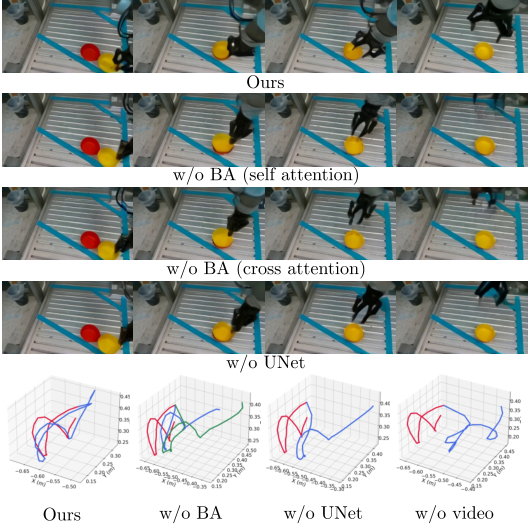
4.4 Ablation experiment
Ablation is performed on real data sets collected by the author. Bridge Attention, UNet action head, and video branch all contribute significantly to the results. Especially after removing the video branch, the action success rate dropped to 0.08, indicating that the action branch does not just learn strategies directly from language and initial images, but strongly relies on the dynamic information and pre-training priors provided by the video branch.
| Variants | PSNR ↑ | SSIM ↑ | LPIPS ↓ | FVD ↓ | Success ↑ |
|---|---|---|---|---|---|
| w/o BA (SA) | 16.83 | 0.693 | 0.255 | 137.66 | 0.32 |
| w/o BA (CA) | 16.56 | 0.645 | 0.263 | 145.26 | 0.20 |
| w/o UNet | 16.85 | 0.690 | 0.255 | 141.62 | 0.24 |
| w/o video | - | - | - | - | 0.08 |
| CoVAR | 17.67 | 0.736 | 0.238 | 133.89 | 0.68 |
5. Intensive reading of charts
5.1 Fig. 1: What the paper really wants to say is not "joint generation" itself
The three-column comparison of Fig. 1 is critical. The problem with the two-stage model is that there is no end-to-end alignment between video and action; the problem with the joint model is that all modalities are mixed prematurely in the same DiT; CoVAR's proposition is that "actions require video priors, but they should not swallow the video trunk". Therefore, the technical center of the paper is not to propose another multi-modal diffusion, but to propose a communication structure for the asymmetric mode of robot video/action.
5.2 Fig. 2: Positioning of Action DiT
Action DiT is not a small inverse dynamics head. It participates in rectified flow denoising and generates a complete action sequence together with the video branch. The action branch can read text, or read video branch information through Bridge Attention. This positioning explains why w/o video has a very low success rate: the video branch not only outputs visualization results, but also assumes the role of an intermediate representation of dynamic priors.
5.3 Fig. 7: Video-action trajectory alignment

This diagram is most suitable for discussing the relationship between "video quality indicators" and "action executability" in group meetings. Just because a video looks reasonable does not automatically mean that the action is executable; the advantage of CoVAR is that it makes action generation directly constrained by video dynamics modeling, rather than just estimating actions from video after the fact.
5.4 How to read tables: Don't just read the bold text
In the video quality table, CoVAR does not always beat OpenSora, especially OpenSora is better on FVD. This is actually reasonable: OpenSora is a pure video generation model, and CoVAR is additionally responsible for action generation. What the paper really needs to prove is that CoVAR is better than joint baselines videos, and the action success rate is also higher. By this standard, the results support the claim.
6. Reproducible list and implementation details
6.1 reproducibility parameters that can be extracted directly from the paper
| Project | The settings given in the paper |
|---|---|
| Basic code/model | OpenSora-1.2 codebase; the video diffusion part is about 1.1B parameters. |
| New module | About 0.3B parameters, including Action DiT, Bridge Attention related parameters, UNet action decoder/refinement, etc. |
| total parameters | About 1.4B. |
| Number of training frames | Each piece of data samples 35 frames. |
| training resources | About 1 day, 4 GPUs. |
| Real data resolution | 180×320 for faster convergence and inference. |
| Real robot reasoning | 35 frames video-action pair; rectified flow sampling step = 30; each segment is about 4 seconds. |
| control execution | UR5 platform; 100 Hz control of the robot, interpolation of open-loop motion sequences. |
| Libero90 refinement | Fine-tuning the action refinement model with 450 video-action pairs. |
6.2 Details still need to be confirmed by code
- The specific VAE/patch/token shape of the video latent, and the depth, width, and attention insertion positions of the Action DiT.
- Whether video loss and action loss are scale normalized, and whether there are additional weights.
- Whether the two modes share the same time step $t$ and noise scheduling; the paper should intuitively share, but the formula is not expanded in detail.
- The specific input arrangement of the UNet action decoder: whether the action token is a 1D/2D structure based on the time dimension, or is it mapped into a similar feature map.
- Action refinement's training goal, learning rate, whether the input coarse action is detachable, and whether it is always enabled during inference.
- The number of trials and failure statistics of each task in real robot experiments.
6.3 Relationship with existing routes
Both CoVAR and UVA/UWM/PAD belong to the "joint video and action modeling" camp, but it places more emphasis on reusing pre-trained video diffusion models. Compared with two-stage methods such as Unipi/RoboEnvision, it avoids completely handing over action learning to posterior inverse dynamics. It can be understood as an architectural choice in embodied diffusion: the video branch retains strong visual priors, the action branch is controlled by independent DiTology, and then coupling is established through controlled attention.
7. Critical discussion and group meeting questions
7.1 Strong points of the paper
- The question is precise: The action label gap between video proliferation and bot strategies is a real problem.
- The architectural motivation is clear: Parallel Action DiT is more consistent with the characteristics of the video/action asymmetric modality than "shocking action into video DiT".
- Ablation is supported by: Bridge Attention, UNet decoder, and video branches all reflect their contributions through ablation.
- Real experiments are convincing: The success rate of real small object operations is much higher than that of the second-stage baseline, which shows that the accuracy of movements is not only effective in simulation.
7.2 Points to be cautious about
- Exploitation of large-scale action-free video has not yet been fully demonstrated: The motivation of the paper is that CoVAR helps to utilize large-scale video data, but the experiments are still mainly on data sets with action demonstrations.
- Reasoning speed is slow: The real robot generates 35 frames per segment for about 4 seconds, which is suitable for open-loop chunking, but it is still far from high-frequency closed-loop control.
- The generalization boundary of Action refinement is unclear: Libero90 has greatly improved, but it itself uses 450 pairs of video-action data to fine-tune, and whether it can be migrated to more complex real scenes still needs to be verified.
- Missing 3D geometry: The author also admits that currently only monocular videos are used, and the understanding of spatial geometry is limited.
- Real data is smaller: 1K demos are enough to demonstrate proof-of-concept, but not enough to demonstrate robustness in large-scale real operations.
7.3 Group meeting discussion question 1: Where does Bridge Attention's revenue come from?
It allows you to compare three information exchange methods: direct self-attention, bidirectional cross-attention, and Bridge Attention. The key question is: does the improvement in Bridge Attention come from "modality-specific Q/K/V projection", or does it come from a larger number of parameters and better initialization paths? If further proof is needed, the ideal experiment should control the number of parameters, make the self-attention baseline the same size, and report the attention map or inter-modal token reading strength.
7.4 Group meeting discussion question 2: Is CoVAR a world model, a policy, or a data generator?
CoVAR generates future videos and actions at the same time, so it can be interpreted as a world model, can also be used as an open-loop policy, and can also add action labels to video data. The three positionings will lead to different evaluation criteria: the world model looks at the long-term prediction consistency, the policy looks at the closed-loop success rate and safety, and the data generator looks at whether the generated samples can improve the downstream strategy. The strongest evidence currently in the paper is the policy success rate; the evidence of the "scalable data generator" also needs to be supplemented by downstream data enhancement experiments.
7.5 Follow-up research directions
- Add 3D representation: Combined with depth, point cloud or 3D foundation model, extend monocular video priors to more reliable spatial inference.
- Closed loop: Change the 35-frame open-loop chunking to receding horizon, and use real-time observations to correct the deviation.
- Verify action-free video scaling: Pre-train the video branch with a large number of motionless robot videos or human operation videos, and then align it with a small amount of motion data.
- More stringent action refinement ablation: Test the help of refinement on other baselines to confirm whether it is a CoVAR-specific advantage or a general post-processor.