Act2Goal: From World Model To General Goal-conditioned Policy
1. Quick overview of the paper
| What should the paper solve? | Visual goals can express object layout and final state constraints more accurately than language. However, existing goal-conditioned policies often directly predict single-step actions and lack explicit task progress representation. Long-term tasks and OOD scenarios can easily deviate from the goal. |
|---|---|
| The author's approach | Act2Goal introduces Goal-Conditioned World Model (GCWM) to generate an intermediate visual trajectory from the current observation to the target image; proposes Multi-Scale Temporal Hashing (MSTH) to split the trajectory into near-end dense frames and far-end sparse frames; Action DiT uses world-model features through layer-by-layer cross-attention. |
| most important results | In Robotwin 2.0 and real AgiBot Genie-01 tasks, Act2Goal is significantly higher than DP-GC, $\pi_{0.5}$-GC and HyperGoalNet on most ID/OOD settings; real OOD Plug-In is improved from offline 0.30 to 0.90 through online self-improvement; MSTH is improved from near failure to whiteboard writing long words/OOD long words. 0.88-0.90. |
| Things to note when reading | The key to this article is not "the video generated by the world model looks good", but how the generated visual trajectory is temporally sampled into a control-available representation: the near-end frame is used for closed-loop fine control, and the far-end frame is used to maintain long-range target consistency. |
Difficulty rating: ★★★★☆. Requires understanding of visual goal-conditioned policy, flow matching, Video DiT/3D VAE world model, action expert, hintsight goal relabeling, LoRA finetuning, and real robot evaluation.
Keywords: Goal-conditioned policy, visual world model, Multi-Scale Temporal Hashing, flow matching, action expert, HER, LoRA, online autonomous improvement.
2. Motivation
2.1 Why use visual targets instead of language targets?
Robotic operation requires task descriptions that are both flexible and precise. Language can express a variety of tasks, but it is often not specific enough in fine-grained operations: such as "arrange the dessert like this", "write this word", "put the insert in the hole", the spatial relationship, shape, orientation and final state details of the target are difficult to completely describe in natural language without ambiguity. Visual goal images directly encode object configurations, spatial relationships, and final state constraints and are therefore more suitable for goal-conditioned manipulation.
2.2 Core shortcomings of existing GCP
Many visual goal-conditioned policies map the current observation and goal image directly to actions. This works for short-term tasks, but long-term tasks require the strategy to continuously know "where am I now from my goal?" If the model has no intermediate representation of progress, it is easy to match only local state-action patterns in the training data, accumulating bias in OOD objects, layouts, or long control chains.
The diagnosis of the paper is that GCP needs an explicit visual dynamics model to predict plausible intermediate states from the current state to the target state. In this way, action expert not only looks at the end point, but also gets a visual route from thick to thin.
2.3 Why is MSTH still needed?
Generating an entire future video is still not enough. If long trajectories are all intensively predicted, the calculation cost is high and the remote details may not be reliable; if you only look at the short term, the strategy will be responsive but it is easy to lose sight of the long-term goal. The role of MSTH is to split the time scale: the near end uses dense frames to provide local closed-loop control, and the far end uses logarithmic sparse frames to maintain global direction.
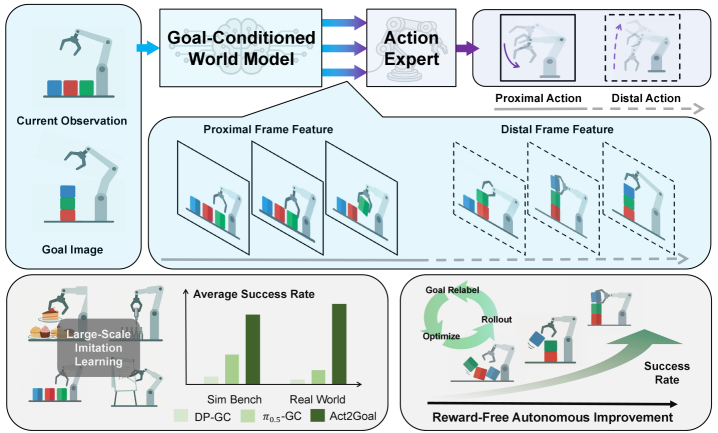
4. Detailed explanation of method
4.1 Overall process: three-stage learning
Act2Goal's learning process is divided into three stages:
- Stage 1 joint training: Fine-tune the pre-trained world model to generate MSTH-distributed multi-view transition videos under the current observation and target image conditions, while jointly training the action generation task.
- Stage 2 action adaptation: Use behavior cloning to fine-tune the complete model end-to-end, using only action flow matching loss to make the visual representation more suitable for action planning.
- Stage 3 online autonomous improvement: After deployment, collect its own rollout, relabel the next observation that actually arrives as goal, and only update the LoRA layer.
4.2 Model architecture: GCWM + Action DiT
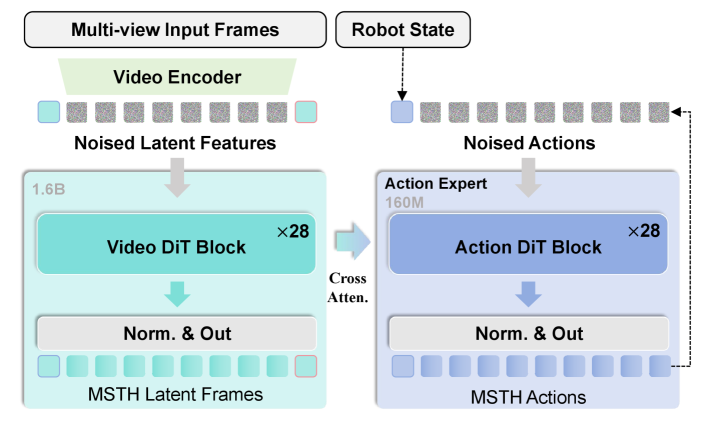
The Goal-Conditioned World Model is modified based on Genie Envisioner: it retains the video generation capability, removes language conditions, and adds visual goal conditions. The current observation latent is recorded as $z_t$, the target image latent is recorded as $z_g$, the random noise is $\epsilon$, and the world model generates intermediate latent frames:
Use flow matching's deterministic integral update during inference:
$$z^{(n+1)} = z^{(n)} + \frac{1}{N}v_{\theta}(z^{(n)}, z_t, z_g).$$Intuition: GCWM learns "what intermediate states should be visually passed from the current picture to the target picture." These intermediate states are not directly performed actions, but become conditions for action experts.
Action expert is architecturally isomorphic to world model, but smaller in width. It receives the proprioceptive state $c_p$ and the hierarchical transition features $c_w=\{h_{\mathrm{world}}^1, \ldots, h_{\mathrm{world}}^L\}$ of the world model, and generates actions:
Intuition: Actions are not decoded from the target image alone, but executable controls are "read" from multiple layers of intermediate features in the world model.
4.3 Multi-Scale Temporal Hashing (MSTH)
MSTH is the core mechanism of this paper. Given the total imagined trajectory length $K$, the near-end horizon $P$, and the visual sampling stride $r$, MSTH splits the future visual state into two segments.
Near-end dense segment:
$$\{s_{t+kr}\}_{k=1}^{P/r}.$$Remote sparse segment:
$$\{s_{t+d_m}\}_{m=1}^{M}, \quad d_m = P + \left\lfloor \frac{K-P}{\log(M+1)}\log(m+1)\right\rfloor.$$Intuition: The closer to the present, the more high-frequency details are needed; the closer to the distant target, the more coarse-grained target anchors are needed. Log spacing causes the remote frame interval to gradually increase.
The actions also adopt the same multi-scale structure, but there is a key difference: the near-end action is predicted at every time step, $\{a_{t+1}, \ldots, a_{t+P}\}$, for actual execution; the remote action $\{a_{t+d_m}\}_{m=1}^M$ is only used for long-range guidance and is not executed at deployment time. The appendix gives the specific implementation: the world model predicts 4 latent frames, including 2 proximal and 2 distal, which are decoded by 3D VAE into 9 proximal and 9 distal visual frames; the action expert outputs 54 proximal actions, of which 50 are executed, and the other 9 distal actions are output only for guidance Appendix A.1.
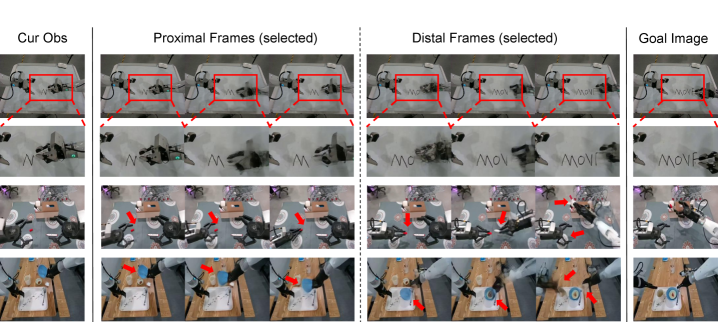
4.4 Two-stage offline training objectives
Stage 1 jointly optimizes visual generation and action generation. The visual part uses flow matching loss:
The action part is:
$$\mathcal{L}_a = \mathbb{E}_{t, a_0, a_1, c_w, c_p} \left[\left\|u_{\phi}(t, \psi_t(a), c_w, c_p)-(a_1-a_0)\right\|^2\right].$$Joint goals:
$$\mathcal{L}_{\mathrm{stage1}}=\mathcal{L}_v+\lambda\mathcal{L}_a, \quad \lambda=0.1.$$Stage 2 only uses $\mathcal{L}_{\mathrm{stage2}}=\mathcal{L}_a$ for end-to-end behavioral cloning.
The meaning of this design is: the first stage makes the generated visual trajectory "look reasonable and useful for the action"; the second stage aligns the entire pipeline to expert actions.
4.5 Online self-improvement: HER + LoRA
The online stage does not require external rewards, nor does it require manual marking of success/failure. The robot executes the strategy and stores each transition in the replay buffer: $(o, c_p, a, o')$. Then the actually reached $o'$ is used as the new goal $g'$, and a supervision sample is constructed as "$g'$ can be reached by executing $a$ under $o$". After the buffer reaches the threshold, only the LoRA layer is fine-tuned using these relabeled transitions, and the base model is frozen.
Act2Goal online autonomous improvement: 1. initialize replay buffer B and LoRA parameters 2. execute policy for one episode and store transitions (o, c_p, a, o') 3. for each transition, relabel achieved observation o' as goal g' 4. when B reaches threshold: sample batches from B optimize action prediction toward stored action a under relabeled goal g' update only LoRA parameters clear B 5. repeat rollout -> relabel -> optimize until performance converges
Appendix implementation details: Deployed on AgiBot Genie-01 + NVIDIA RTX 4090; LoRA rank 64; replay buffer size 20; 10 epochs per round, including rollout, backpropagation and environment reset of about 5 minutes; inference latency of 50 executable actions is about 200 ms Appendix A.1.
5. Experiment
5.1 Experimental questions
The experiment revolves around three questions: whether offline imitation training can be generalized to ID/OOD scenarios; whether online autonomous improvement is effective; and whether MSTH is a key component of long-term tasks.
5.2 Robotwin 2.0 simulation generalization
The author selects four tasks from Robotwin 2.0: Move Can Pot, Pick Dual Bottles, Place Empty Cup, Place Shoe. Easy mode is the seen/no-noise setting and Hard mode is the unseen/noisy setting. The target image is passed through a fixed environment seed, and the final state is extracted from the successful trajectory as the goal condition.
| Mode | Model | Move Can | Pick Bottles | Place Cup | Place Shoe |
|---|---|---|---|---|---|
| Easy | DP-GC | 0.18 | 0.04 | 0.03 | 0.04 |
| $\pi_{0.5}$-GC | 0.54 | 0.13 | 0.16 | 0.30 | |
| HyperGoalNet | 0.11 | 0.08 | 0.08 | 0.01 | |
| Act2Goal | 0.62 | 0.80 | 0.64 | 0.52 | |
| Hard | DP-GC | 0.00 | 0.00 | 0.00 | 0.00 |
| $\pi_{0.5}$-GC | 0.42 | 0.06 | 0.04 | 0.06 | |
| HyperGoalNet | 0.00 | 0.00 | 0.00 | 0.00 | |
| Act2Goal | 0.13 | 0.43 | 0.13 | 0.15 |
Act2Goal is best in all Easy tasks; best in Hard mode except Move Can. This result supports the paper's claim that world model + MSTH is helpful for OOD long-term scenarios, but it also shows that not all hard scenarios beat $\pi_{0.5}$-GC.
5.3 Generalization to real robots

| Setting | Model | Whiteboard Word Writing | Dessert Plating | Plug-In Operation |
|---|---|---|---|---|
| ID | DP-GC | 0.00 | 0.10 | 0.00 |
| $\pi_{0.5}$-GC | 0.23 | 0.18 | 0.00 | |
| HyperGoalNet | 0.00 | 0.08 | 0.00 | |
| Act2Goal | 0.93 | 0.75 | 0.45 | |
| OOD | DP-GC | 0.00 | 0.00 | 0.00 |
| $\pi_{0.5}$-GC | 0.20 | 0.05 | 0.00 | |
| HyperGoalNet | 0.00 | 0.00 | 0.00 | |
| Act2Goal | 0.90 | 0.48 | 0.30 |
Three types of tasks respectively test different abilities: whiteboard writing requires long-range stroke combinations, and OOD is training unseen words; dessert plate placement requires fine-grained spatial arrangement according to the target image, OOD introduces dessert types, plate styles, and background changes; Plug-In ID requires inserting metal artifacts seen in training, and OOD involves inserting cylindrical beverage bottles into cup holders.
The appendix adds details of real tasks: when writing/painting, the marker is first manually placed in the clamping claw. During long writing trials, the marker will slide, so it is fixed with tape; in bearing insertion, the bearing exceeds 2 kg, the diameter of the bottom is about 1 cm, and the diameter of the hole is about 1.5 cm; the dessert plate uses silicone toy desserts to ensure repeatability Appendix A.2.
5.4 Online self-improvement

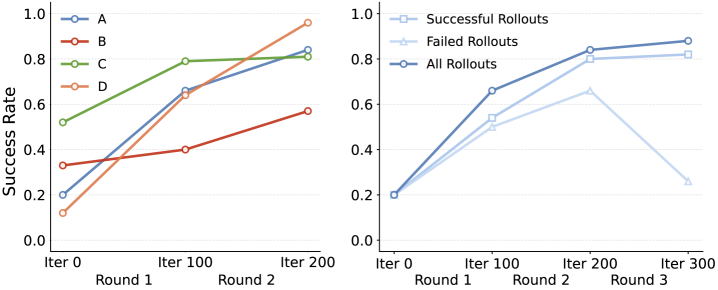
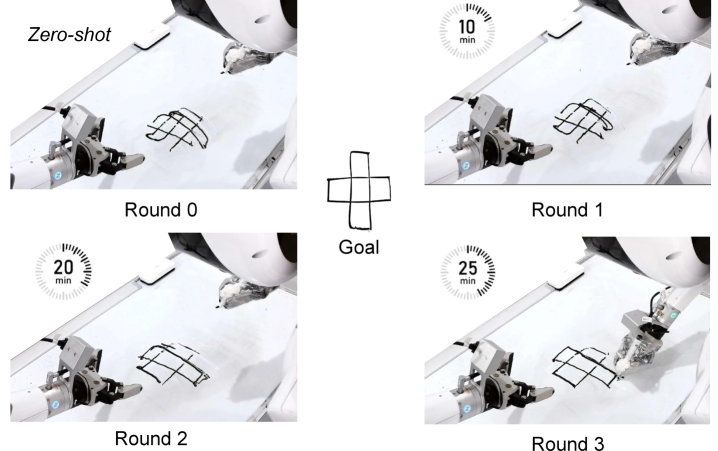
In the simulation, the author selected one scenario from each of the four hard-mode tasks to perform multiple rounds of online training. The text of the paper gives a qualitative conclusion: it converges after about 3 rounds, and the maximum success rate can be increased up to 8 times that of the pre-training baseline; using all rollouts is better than using only successful or failed rollouts. This result is consistent with HER logic: failure trajectories also contain learnable achieved-goal transitions.
5.5 MSTH ablation
| Setting | Model | Short (≤3 letters) | Medium (4-6 letters) | Long (≥7 letters) |
|---|---|---|---|---|
| ID | w/o MSTH | 0.95 | 0.35 | 0.10 |
| w/ MSTH | 0.95 | 0.90 | 0.90 | |
| OOD | w/o MSTH | 0.60 | 0.20 | 0.00 |
| w/ MSTH | 0.93 | 0.90 | 0.88 |
This table is the strongest evidence supporting MSTH: fixed horizon chunking is okay for short words, but it collapses quickly when the words become longer, especially OOD long words, which is 0.00; MSTH still maintains 0.90/0.88 for long words in ID/OOD. The explanation is that the fixed horizon is more prone to goal confusion as the sequence becomes longer, while the distal sparse anchors of MSTH maintain the goal direction.
6. Reproducible auditing
6.1 Data, training resources and model scale
| Project | Paper/Appendix Information | recurring meaning |
|---|---|---|
| training data | AgiBot World dataset + small proprietary dataset. | The core real data is not fully disclosed, and it is difficult to strictly reproduce the experiment. |
| world model initialization | Pre-trained 1.6B parameter Genie Envisioner. | Requires available Genie Envisioner weights or equivalent video world model. |
| Stage 1 | Fine-tuning pre-trained world model, 7×24 hours, 16×A800. | The amount of calculation is huge and cannot be easily reproduced with a single card. |
| Stage 2 | End-to-end behavioral cloning, 48 hours, 16×A800. | Offline training resources are still high. |
| deploy | AgiBot Genie-01 + RTX 4090; 50 executable actions with 200 ms latency. | Inference deployment gives a clearer hardware caliber. |
| online learning | LoRA rank 64, buffer size 20, 10 epochs per round, about 5 minutes. | The online stage is relatively lightweight and can be used as the first module to be reproduced. |
6.2 Evaluation Caliber
- Real-world success rates are manually annotated with 40 model rollouts per experiment.
- The simulation success rate is automatically calculated with 90 rollouts per experiment.
- In the online self-improvement experiment, the author saves the model weights after each round of training, and evaluates these checkpoints separately after the online process is completed.
6.3 Minimum recurrence route
- First implement the visual goal-conditioned policy baseline in simulation: current image + goal image + proprio state → action chunk.
- Connect to a pre-trained video/world model, change it to current observation + goal image condition, and output transition latent frames.
- Implement MSTH: near-end dense frames, far-end log-spaced distal frames; action-end prediction of dense proximal actions + sparse distal guidance actions.
- Use Stage 1 $\mathcal{L}_v + 0.1\mathcal{L}_a$ for joint training, and then use Stage 2 $\mathcal{L}_a$ for action adaptation.
- First, reproduce the four tasks of Robotwin 2.0; reproducibility on a real machine requires a robot platform, target image acquisition and a safe reset pipeline.
- Finally, online HER + LoRA is implemented: train for 10 epochs after buffering to 20, only update LoRA, and compare all/success/failure rollout strategies.
6.4 Main recurring risks
| risk | Reason | Suggestions |
|---|---|---|
| Data not fully available | Training relies on AgiBot World and proprietary data. | First use public simulation data to verify MSTH/online adaptation instead of pursuing absolute values. |
| world model cost is high | 1.6B Genie Envisioner + 16×A800 training. | Use a smaller video latent diffusion/world model to reproduce the structure. |
| Real machine setup details affect the results | Marker fixation, bearing size, and silicone desserts all affect experimental reproducibility. | Document end-effector/tool mounting, object material, initial position and reset strategy. |
| Online learning safety | Self-collecting rollouts may cause collisions or incorrect behavior. | Deploy replay relabeling in simulation first, and then migrate to low-risk real tasks. |
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
The most valuable part of this article is that it concretizes the long-term problem of visual goal strategy: instead of just letting the policy see the goal image, it first constructs a visual intermediate route that "evolves toward the goal", and then compresses this route into a control-friendly multi-scale representation. The idea of MSTH is simple but effective: it should be dense near and sparse far away; proximal actions are executed, and far-end actions are only constrained.
The second value point is that the online self-improvement process is sufficiently engineered. HER-style relabeling + LoRA is very practical on real robots: no reward function is required, and no manual labeling is required at each step. Failure trajectories can also be converted into training signals through achieved-goal relabeling.
7.2 Why the results hold up
- There are levels of task coverage: Simulation Robotwin 2.0, real writing, dessert plating, and insertion operations cover different difficulties.
- OOD settings are explicit: Unseen words, visual changes to desserts/plates/backgrounds, migration from bearing insert to cup holder insert.
- MSTH ablation is strong: Writing long words on the whiteboard w/o MSTH almost fails, while w/ MSTH maintains a high success rate, directly supporting the core of the method.
- The evidence for online training is consistent: Simulation multi-round improvement, real unseen drawing improvement, Plug-In OOD from 0.30 to 0.90, in the same direction.
7.3 Limitations and points that need to be questioned
| question | influence |
|---|---|
| Insufficient training data and code availability | The paper is given to the project page, but the arXiv/project page does not show the public code; the core training data contains a proprietary dataset, making complete reproducibility difficult. |
| Part of the source code still contains the author's internal comments | There are many modification comments and comments in the LaTeX source code, indicating that the paper may still be in a state of rapid iteration; readers should refer to the final PDF result. |
| Real-world evaluation sample size is limited | 40 rollouts per real experiment is enough to show trends, but more statistical confidence intervals are still needed for high variance real machine tasks. |
| Whether the world model is truly causally controllable has not yet been fully proven. | The generated intermediate visual trajectory looks reasonable, but its specific contribution to action success is mainly reflected through overall ablation, lacking more detailed representation/attention analysis. |
| Online self-improvement dependent environment reset | Each round takes about 5 minutes and includes rollout, backpass, and reset; the cost of reset may become a bottleneck in a real open environment. |
7.4 Questions that can be asked in group meetings
- How to choose MSTH's $K, P, r, M$? Do different tasks require adaptive time scales instead of fixed log spacing?
- Remote actions are not executed, but only serve as guidance. Where does their supervision come from, and is it possible that it may conflict with the near-end execution of actions?
- Stage 2 only optimizes action loss, but the gradient is also passed back to the world model. Will this reduce the realism of the video generated by the world model and only retain action-useful features? Is this an advantage or a risk?
- HER relabeling treats $o'$ as goal, but if the action results in a collision or meaningless state, will this relabeling reinforce bad behavior? all rollouts best illustrates that the model may be able to absorb noise, but where are the boundaries?
- Compared to directly using goal image + transformer memory for long context control, is the additional generation cost of GCWM necessary for all tasks?
Attachment: This report covers inspections
Covered: Abstract, Introduction, Related Works, Methods, Experiments, Conclusion, and implementation details, real task settings, and test metrics in the appendix.
Chart processing: The PNG image rendered using arXiv HTML is saved in figures/; Key tables have been rebuilt into HTML.
Residual risk: No official code repository was found; the training data part is proprietary, and the reproducibility route in the report is a structural-level reproducibility suggestion, which is not equivalent to a complete numerical reproducibility.