Dream2Flow: Bridging Video Generation and Open-World Manipulation with 3D Object Flow
This paper proposes Dream2Flow: Distill the video of "how the task should happen" generated by the text conditional video generation model into 3D object flow, and then let the robot track the movement of this object through trajectory optimization or reinforcement learning.
1. Quick overview of the paper
| What should the paper solve? | Solving the interface problem between video generation models and robot control. The video model can generate reasonable human/object interaction videos, but the robot requires low-level actions; directly imitating human hand movements will encounter an embodiment gap, so the author wants to decouple "how objects in the world should move" from "which robot implements it." |
|---|---|
| The author's approach | Use 3D object flow as the video-control interface: first recover the 3D point trajectory of the task-related object from the generated video through depth estimation, segmentation and point tracking, then write the operation as object trajectory tracking, and use trajectory optimization, particle dynamics planning or SAC reward to generate actions. |
| most important results | Dream2Flow is better than AVDC and RIGVID in three real robot tasks: Bread in Bowl is 8/10, Open Oven is 8/10, and Cover Bowl is 3/10; in Open Door RL, 3D object flow reward reaches Franka 100/100, Spot 100/100, and GR1 94/100, which is close to manual object-state reward. |
| Things to note when reading | Note the similarities and differences between it and NovaFlow: both use the interface to generate video to 3D flow, but Dream2Flow emphasizes 3D object flow as a unified reward/target, which can serve random shooting planning, real robot rigid grasping trajectory optimization, and cross-embodiment reinforcement learning. |
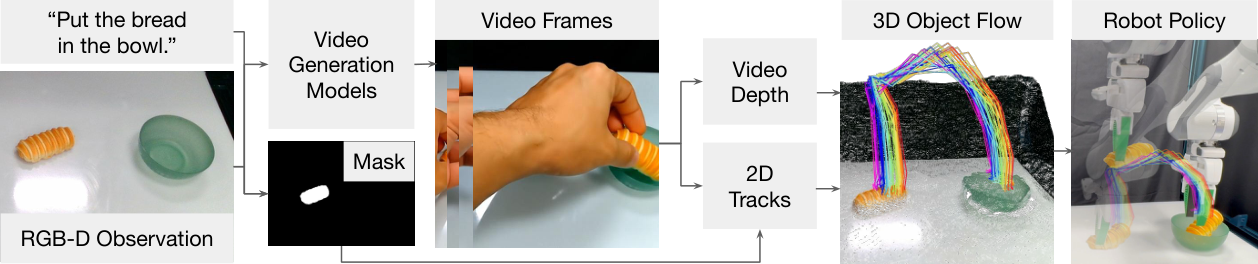
2. Problem setting and motivation
The motivation of the paper is straightforward: the video generation model can already imagine "how objects are manipulated" in open scenes, but these videos usually use human hands as the interacting subjects, and the action spaces, kinematics, and contact methods of robots and human hands are different. The author believes that the human hand movements in the video should not be directly imitated, but the 3D motion of task-related objects in the video should be extracted.
Therefore, Dream2Flow converts the task into object trajectory tracking: the video model is responsible for giving "what state changes should occur", and the robot module is responsible for determining "how the ontology implements this state change". This allows the same 3D object flow to be implemented by Franka, Spot or GR1 using different action strategies.
3. Related job positioning
3.1 Task specifications of Manipulation
Task specifications can come from symbolic planning, language conditional policies, target images, keypoint constraints, 3D value maps, affordance maps, etc. Dream2Flow belongs to the object-centric specification: language instructions are first interpreted by the video model as object motion and then executed by the robot.
3.2 2D/3D Flow in Robotics
Dense motion fields, point tracks and 3D scene/object flow can all be used as embodiment-agnostic mid-level interfaces. This article follows the object-centric route to recover the desired object motion from the video and then track it under robot constraints. Compared with 2D optical flow or rigid body pose, 3D object flow can cover more deformation, occlusion and non-rigid scenes.
3.3 Video Models for Robotics
Video models can be used as auxiliary training objectives, reward models, policies, visual simulators, or data generators. Dream2Flow's position is: it does not treat the video model as an action strategy, nor does it directly use it to train imitation policy, but uses it as an "object motion generator" for open-world tasks.
4. Intensive reading of methods
4.1 Problem Formulation
The inputs are the task language $\ell$, the initial RGB-D observation $(I_0, D_0)$, and the camera projection to the robot coordinate system $\Pi$. The output is the action sequence $u_{0: H-1}$. The action space is not fixed, it can be a pushed skill primitive, a terminal pose, or a low-level control.
The core representation extracted from the video is $P_{1: T} \in \mathbb{R}^{T \times n \times 3}$, which is the 3D trajectory of $n$ task-related object points at $T$ time steps. Action inference is written with the following optimization:
That is to say, the robot only needs to find a series of actions to make the predicted object point position as close as possible to the target point position in the video flow, while satisfying constraints such as control smoothness and accessibility.
4.2 Extracting 3D Object Flow
In the video generation stage, only images and task language are given, the robot is not included in the initial image, and the robot is not mentioned in the prompt. The author observed that if the current image-to-video model is required to generate fine-grained robot interactions, it is more likely to generate physically unreasonable trajectories; making the model more stable in generating videos of "human hands completing tasks".
After generating the video, the system uses SpatialTrackerV2 to estimate the depth of each frame. Since the monocular video depth has scale-shift ambiguity, Dream2Flow uses the first frame to align the true initial depth $D_0$, find the global $s^\star, b^\star$, and obtain the calibrated depth $Z_t = s^\star\tilde{Z}_t + b^\star$.
The system then uses Grounding DINO to locate task-relevant objects from the initial image and language, uses SAM 2 to obtain a binary mask, samples pixels from the mask area, and uses CoTracker3 to track 2D trajectories and visibility in the generated video. Finally, the visible point is lifted to the 3D object flow in the robot coordinate system based on the calibrated depth and internal and external parameters of the camera.
4.3 Action Inference: Three execution domains
| domain | Action/Kinetics | How to use 3D object flow |
|---|---|---|
| Simulated Push-T | push skill primitive: starting position, push direction, push distance; learn particle dynamics model | Random shooting samples multiple pushes and selects the action whose predicted particle position is closest to the flow subgoal; replan after each push. |
| Real World | Absolute end pose; rigid-grasp dynamics model | First use AnyGrasp to grab the target object or movable part, and then optimize the end pose to make the point motion of the grabbed part close to the 3D flow. |
| Simulated Open Door | SAC learns sensorimotor policy; different embodiments have different action spaces | Write the 3D object flow as reward to encourage the door/handle particles to move along the flow generated by the video. |
4.4 Particle dynamics and planning of Push-T
Push-T is a non-crawl push task. appendix explains that the particle dynamics input is $\tilde{x}_t \in \mathbb{R}^{N \times 14}$. Each particle contains position, RGB, normal vector and push parameters, and the next position increment of each particle is output. The architecture is a small Point Transformer V3 backbone, followed by MLP for dimensional projection.
The training data comes from 500 random pushing transitions. The scene is synthesized from 4 virtual RGB-D cameras to point clouds, removing points outside the board range, and then downsampling with 1.5 cm voxel, retaining 1 particle for each voxel. When planning, Dream2Flow re-plans after each push, using lookahead subgoal; the lookahead given by appendix is $L = 20$. This avoids only chasing the final state, resulting in a small translation error but a large rotation error of the T-block.
4.5 Real Robot: Grasping Selection, Movable Parts Filtering and Trajectory Optimization
In real tasks, the system uses AnyGrasp to propose up to 40 top-down grasps: 20 from the real camera coordinate system point cloud, and 20 from a virtual camera coordinate system looking from top to bottom to increase vertical grasp candidates. For objects with moving parts, such as an oven door, where you grab is critical. Dream2Flow uses HaMer to detect the thumb position of the human hand in the generated video. If a candidate grasp is within 2 cm of the thumb, the earliest grasp that meets the conditions is selected; otherwise, it falls back to the heuristic "closest to the movable part point".
Movable part filtering is also very useful: if some 2D track moves more than 1 pixel per frame on average, it is considered a movable flow; then the positive/negative point prompt of SAM 2 is used to constrain the movable part mask. This can reduce the possibility of incorrectly lifting backgrounds or fixed components to 3D, resulting in execution failures.
The real trajectory optimization is carried out on the 7-dimensional Franka joint angle. The control items are composed of three parts: reachability, pose smoothness and manipulability. The weights are $w_r=100$, $w_s=1$ and $w_m=0.01$ respectively; the flow task weight is $w_f=10$. The optimized end trajectory is fitted and sampled with B-spline, and the sampling condition is that adjacent poses are at least 1 cm or 20 degrees apart. Implemented using PyBullet IK and Deoxys joint impedance controller.
View appendix grasp selection original image PDF
4.6 Open Door RL Reward
Open Door uses SAC to train cross-embodiment policies. The SAC super parameters given by appendix include: learning rate $3 \times 10^{-4}$, discount $0.99$, batch size 256, buffer size $10^6$, target update rate $0.005$, hidden layers 2, hidden units 256, training iterations 5000, episode horizon 500; GR1 has a larger action space, so training 10, 000 iterations.
3D object flow reward includes particle progress items and end-close object items:
Among them, $t^\star$ is the time step at which the current object particle state is closest to the reference 3D flow. The meaning of this reward is: there is no need to hand-write the status reward of "how much to turn the door handle and how much to open the door hinge", but to directly reward the robot for making the object move along the object trajectory in the generated video.
5. Experiments and results
5.1 Tasks
Experiments cover simulated and real robots. Push-T was evaluated in OmniGibson, and the success criteria were a translation error of less than 2 cm and a rotation error of less than 15 degrees from the T-block to the target position. Real tasks include Put Bread in Bowl, Open Oven, Cover Bowl; Open Door is evaluated in Robosuite, requiring the door handle to rotate and open the door at least 17 degrees without timeout.

5.2 Intermediate representation comparison on real robots
The comparison methods are AVDC and RIGVID. AVDC takes the dense optical flow from the generated video and then finds the rigid body transformation; RIGVID is based on the 6D pose / rigid transform idea, which is transformed here to estimate the rigid body transformation using Dream2Flow's 3D points. The result is as follows:
| Task | AVDC | RIGVID | Dream2Flow |
|---|---|---|---|
| Bread in Bowl | 7/10 | 6/10 | 8/10 |
| Open Oven | 0/10 | 6/10 | 8/10 |
| Cover Bowl | 2/10 | 1/10 | 3/10 |
AVDC is okay for simple rigid body movements like bread, but the optical flow on the oven cannot keep up with the movement of the door, resulting in insufficient range of motion. RIGVID and AVDC have very noisy rigid body transformation estimates when there are few visible points, which can easily make the optimization execution unstable. Cover Bowl is difficult for all methods because scarf is deformable and rigid body transform itself is not suitable.
5.3 3D object flow as RL reward
| Reward Type | Franka | Spot | GR1 |
|---|---|---|---|
| Object State | 99/100 | 99/100 | 96/100 |
| 3D Object Flow | 100/100 | 100/100 | 94/100 |
This result is critical: 3D object flow reward is almost the same as manual object-state reward, but there is no need to design explicit state reward for each task. What's more interesting is that different embodiments have learned different strategies: Spot will move the chassis to gain better accessibility, while GR1 uses the area between the fingers and the palm to pull the door to improve stability.

5.4 Video generator selection
| Video Generation Model | Push-T | Open Oven |
|---|---|---|
| Wan2.1 | 52/100 | 2/10 |
| Kling 2.1 | 31/100 | 4/10 |
| Veo 3 | - | 8/10 |
Wan2.1 was best on Push-T because that task required target image cues and Veo 3 did not support end-frame conditioning at the time. Veo 3 is the best in Open Oven; Wan2.1 is more likely to generate camera motion, violating the static camera assumption, and Wan2.1 and Kling will also generate wrong opening and closing axes.
5.5 Dynamics model ablation
| Dynamics Model Type | Success Rate |
|---|---|
| Pose | 12/100 |
| Heuristic | 17/100 |
| Particle | 52/100 |
This ablation shows that 3D object flow itself is not omnipotent; the downstream dynamics model must also be sufficient to express the rotation and contact effects required by the task. In Push-T, neither the pose model nor the heuristic model can adequately handle rotation, and particle dynamics is significantly stronger.
5.6 Failure Analysis
The paper provides a failure decomposition of 60 real robot experiments: 12 video generation failures, half of which came from object morphing or hallucination; 4 flow extraction failures, mainly due to severe rotation or objects leaving the field of view, resulting in the final tracks being invisible; 4 robot execution failures all occurred in the Cover Bowl, due to incorrect grabbing points or insufficient movement range.
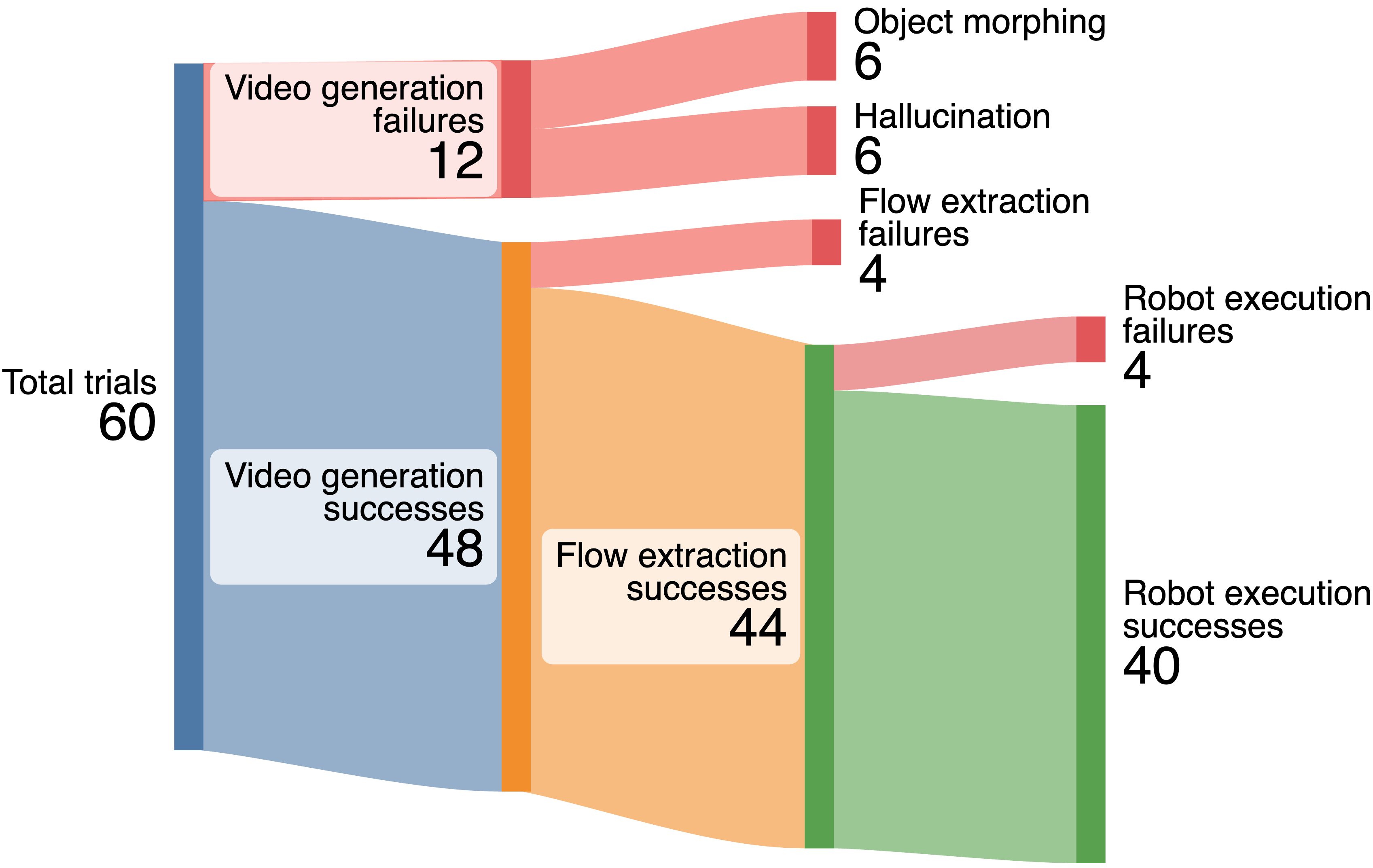
6. reproducibility and implementation details
Prompt
The real task prompt template is: <TASK> by one hand. The camera holds a still pose, not zooming in or out.. "by one hand" is used to help HaMer find hand/thumb position, and "camera holds a still pose" is used to reduce camera movement.
Real-world tasks
Put Bread in Bowl, Open Oven, Cover Bowl, and in-the-wild Pull Out Chair, Open Drawer, Sweep Pasta, Recycle Can.
Push-T planning
Replan after each push; perform nearest neighbor matching between currently tracked particles and feature-augmented particles in the entire scene; subgoal uses $t^\star + L$, among which $L=20$.
Particle dynamics
4 virtual RGB-D cameras synthesized point clouds, 1.5 cm voxel downsample; 500 random pushing transitions to train small Point Transformer V3.
Real-world optimizer
PyRoki optimizes joint angles, B-spline fits the end trajectory, PyBullet IK finds the target joint angle, and Deoxys joint impedance controller executes it.
Failure modes
Morphing/hallucination of the generated video, occlusion and leaving the field of view cause tracking dropout, and insufficient grab points or movement range cause real execution failure.
tmp/source_tex_dump_2512.24766.txt with tmp/pdf_text_2512.24766.txt Check; image source comes from Report/2512.24766/figures/.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
The most valuable part is to improve "generating object movement in videos" into a reusable control interface, instead of just using videos as visualization results or training data. 3D object flow can not only drive real robot trajectory optimization, but also become RL reward, and can span different embodiments such as Franka, Spot, and GR1. This makes the contribution of the paper not just a pipeline, but a more general presentation layer.
The second value is that the experiment is clearly broken down: it asks whether the intermediate representation is better than 2D flow / rigid transform, whether the flow reward is close to the handwritten reward, whether the video generator affects the results, and whether the dynamics model is critical. These questions just correspond to the links in the system that are most likely to be questioned.
7.2 Why the results hold up
The results hold up, first of all because the comparison is not only with the weak baseline. AVDC and RIGVID are both drop-in alternatives for extracting trajectories from video, testing the value of 3D object flow compared to optical flow or rigid transform. Secondly, RL reward results are evaluated on three embodiments, each with 100 random gate positions, indicating that 3D object flow is not only applicable to a single robot.
Furthermore, the authors do not shy away from system dependencies: video model selection, dynamics model selection, and failure types are all reported separately. In particular, the gap between particle dynamics 52/100, pose 12/100, and heuristic 17/100 in Push-T shows that success is not "just having flow", but is determined by flow and the downstream dynamics model.
7.3 Limitations
- The real world relies on rigid-grasp assumptions: The real robot part mainly assumes that the grasped part moves rigidly with the end, which limits strong deformation, slipping and complex contact tasks.
- Real-world particle dynamics has not yet been extended: Push-T uses particle dynamics, but training and scaling such models in the real world is still difficult.
- It takes a long time: It takes 3 to 11 minutes to generate and process a 3D object flow. The main bottleneck is video generation and lack of real-time interactivity.
- Single-view video generation is easily affected by occlusion: If the human hand covers most of the area of a small object, 2D tracking and lifting will be unstable; the paper recommends considering 3D point trackers or full 4D representations in the future.
- Generated video artifacts are propagated to the execution: Morphing, hallucination, wrong articulation axis or camera motion will directly pollute the flow.
7. 4 Boundary conditions
Dream2Flow is most suitable for scenarios where the target object is visible, the task can be expressed by object point motion, the video model can generate a video of reasonable interaction under a still camera, and the robot has a reliable grasping/planning module. It is not suitable for tasks requiring high-speed closed-loop control, strong tactile feedback, complex multi-object contacts, or long-term invisible state estimation.
8. Preparation for group meeting Q&A
Q1: What is the difference between Dream2Flow and NovaFlow?
Both use routes to generate video to 3D flow. NovaFlow emphasizes actionable flow to zero-sample execution of robot actions and VLM rejection sampling; Dream2Flow emphasizes 3D object flow as a unified interface, which can be used for real trajectory optimization, Push-T particle planning and RL reward.
Q2: Why not directly control the robot using the hand trajectory in the video?
Because there is an embodiment gap between human hands and robots, the action space and accessibility are different. Hand trajectories may also not be appropriate for the robot. Dream2Flow only uses hand information to assist in grasping selection, such as using thumb position to select movable parts, but what is really tracked is the movement of the object.
Q3: What is the difference between 3D object flow and rigid transform?
Rigid transform assumes that the target is a rigid body and the visible points are sufficiently stable; 3D object flow is a point-level trajectory that can express finer motion in occlusion, non-rigid, granular or local movable part scenes. In the experiment, Cover Bowl showed that rigid transform is not suitable for deformable objects.
Q4: Why can flow reward be close to manual object-state reward?
Because flow reward encodes task-related object state changes, not robot actions. As long as the object trajectories given by the generated video are reasonable, the strategy can learn feasible implementation methods for different embodiments from the reward.
Q5: What is the main source of failure?
The upstream is video morphing, hallucination, camera motion and wrong joint axes; the midstream is tracking dropout caused by occlusion; the downstream is the actual grasp point error or insufficient movement range. The failure analysis of the paper shows that the current bottleneck is not a single module, but the chain error from open world video to real execution.