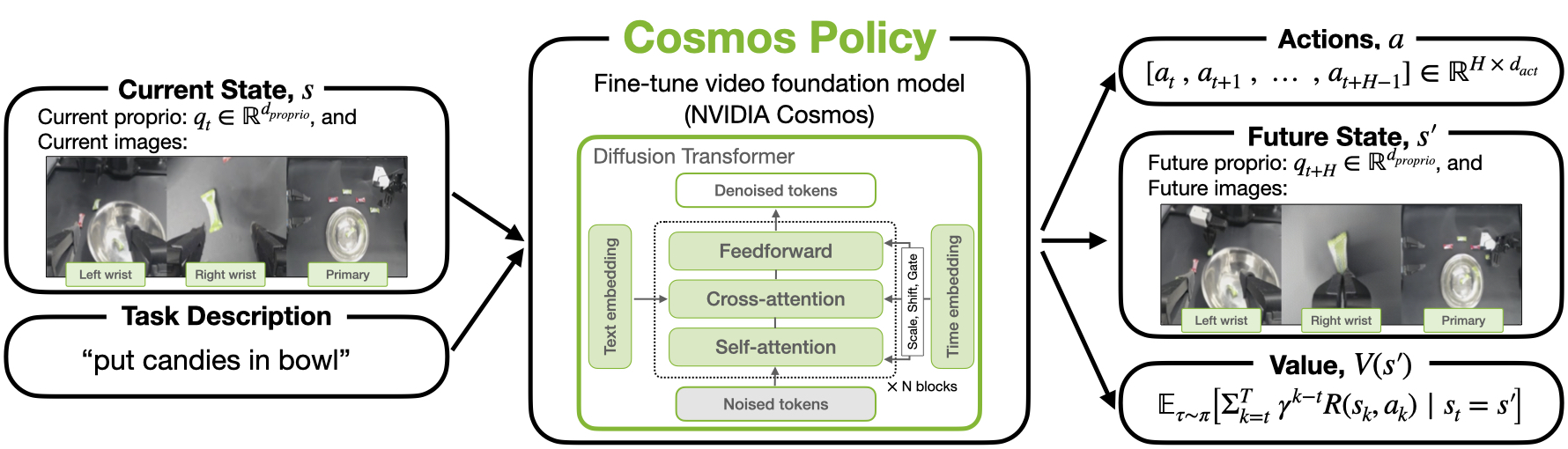
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Contents
1. Quick overview of the paper
Cosmos-Predict2-2B Directly fine-tune the robot strategy without changing the model structure. It only relies on a unified interface that "encodes actions, future states and value functions into latent variable frames", and supports both direct control and model-based planning.
difficulty rating: ★★★★☆
You need to be familiar with diffusion models, latent video models, imitation learning, world model / value function, and robot strategy evaluation.
keywords
Core contribution list
- propose
Cosmos Policy: Single-stage post-training, which directly adapts the pre-trained video model to the robot control strategy without additional design of action head, inverse dynamics or separate action diffuser. - propose
latent frame injection: Represent actions, robot body states, future states and value functions as "frames" in the video latent space, allowing the same diffusion model to simultaneously assume the three roles of policy, world model and value function. - A dual-model deployment is proposed: the basic checkpoint is responsible for taking actions, and the checkpoint fine-tuned using rollout is responsible for predicting future states and values, and doing best-of-N planning during testing.
- Achieve strong results on LIBERO, RoboCasa and real-arm ALOHA; where LIBERO averages 98.5%, RoboCasa averages 67.1%, and ALOHA four-task average score is 93.6.
2. Motivation
2.1 What problem should be solved?
The paper is concerned about: the basic video model has learned temporal causality, implicit physics and motion patterns. Can these priors be used directly for robot control, instead of just using VLA pre-trained with static images and text as the backbone. The author hopes to obtain a unified strategy model that can output actions, imagine future states, and evaluate whether the future is worth executing.
The specific pain point here is not as general as "the robot control is not strong enough", but two things exist at the same time: first, the action distribution of many tasks is multi-modal, for example, when grabbing candy, you can start with the left hand and then the right hand, or vice versa; second, many tasks are extremely sensitive to accuracy, such as zipper bag sliders, and millimeter-level differences will lead to failure. The author believes that the video model has natural advantages in modeling complex, high-dimensional, multi-modal time series distribution, so it is worth directly migrating to control.
2.2 Limitations of existing methods
- The video strategy route is usually multi-stage: first adapt the video model to the robot data, then train the action module separately, or add inverse dynamics / action diffuser. In this way, the training chain is longer, there are more modules, and there are more sources of errors.
- Although the unified video-action model avoids a multi-module structure, it is often not initialized from a large-scale pre-trained video model, but a custom structure is trained from scratch, and the spatio-temporal prior learned from Internet videos is not available.
- VLAs are powerful, but they are mainly built on static image and text pre-training. The author's judgment is that this type of backbone is more semantic than the dynamic physical process itself, so it may not be the most natural inductive bias for high multi-modality, long time series, and fine control.
- In terms of planning, if you only look at demonstration, world model and value function, you will see mostly successful trajectories; once the actual execution enters a state of failure or deviation from the distribution, their generalization will become worse. The author emphasizes both in the text and in the planning experiment: for planning to be useful, rollout experience must be introduced.[Text §4.3]
2.3 Solution ideas of this article (high level)
The author's core idea is "Don't add a new head to the video model, but put everything needed for the robot's task back into its most familiar latent sequence." The specific method is: arrange the current observation $s$, action block $a$, future observation $s'$, and future value $V(s')$ into a latent variable frame sequence, and let the diffusion model continue to do what it is most familiar with: recovering these frames from noise.
In this way, the same model can learn three conditional distributions through different condition masks during training: policy $p(a, s', V(s')\mid s)$, world model $p(s', V(s')\mid s, a)$, and value function $p(V(s')\mid s, a, s')$. You can use it only as a direct policy during testing, or you can connect it to a best-of-N planner after fine-tuning the rollout.
3. Summary of related work
3.1 Related work of the thesis self-description
- Video-based robot policies: One type first fine-tunes the video model and then trains the independent action module; the other type directly trains the joint video-action model. The author positions himself as the third line: still retaining unified generation, but initializing directly from the large video model without structural modifications.
- Vision-language-action models: RT-2, OpenVLA, π0.5, UniVLA, and CogVLA represent the large backbone + robot fine-tuning route. The difference in the paper is not that "there is also a large backbone", but that the backbone is a video generation model rather than a static graphic and text model.
- World models and value functions: Traditional Dyna/MBPO/TD-MPC/Dreamer to recent FLARE, SAILOR, and Latent Policy Steering all show that planning is valuable, but policy/world model/value must usually be built separately. The distinguishing point of this article is that the same pre-trained video model assumes the three functions at the same time.
3.2 Direct comparison with previous works
| Dimensions | Video Policy / UVA Class | UWM-like unified video action model | VLA(OpenVLA / π0.5) | Cosmos Policy |
|---|---|---|---|---|
| Pre-trained backbone | Video models often require additional action modules | Customize the unified model and usually do not directly inherit the large video model | Static graphic model | Cosmos-Predict2-2B video diffusion model |
| Structural changes | usually required | The model itself is designed for action | Action head/nudge strategies vary by method | The structure is not changed, only the content organization of the latent sequence is changed. |
| action expression | Individual action modules or inverse dynamics | United Video-Action Output | Direct return or other action header | Action blocks are encoded into latent frames |
| Whether to uniformly model future state/value | Usually not uniform | Does not necessarily contain value | Usually no explicit world model/value | Unified modeling of actions, future states and values |
| planning ability | Often requires additional modules | Not necessarily supported | Usually model-free | After rollout fine-tuning, best-of-N planning can be directly performed |
| Representative results given in the paper | Video Policy in RoboCasa 66.0, LIBERO Long 94.0 | UWM in RoboCasa 60.8 | OpenVLA-OFT in LIBERO 97.1; π0.5 Average in ALOHA 88.6 | LIBERO 98.5, RoboCasa 67.1, ALOHA 93.6 |
4. Detailed explanation of method
4.1 Method overview
The entire pipeline can be understood by "Input Organization -> Unified Training -> Two Deployment Methods":
- Input: multi-view images at the current moment, robot proprioception, text task description.
- Presentation side: The image will be transformed into a latent frame through VAE; the author then copies, normalizes and writes the action block, current/future robot state and value function into certain latent frame positions.
- Training end: Different batch samples use different condition masks, corresponding to three condition generation tasks: policy, world model, and value function.
- Deployment side: If you only do direct policy, generate $(a, s', V)$ in parallel and then only execute the action; if you do planning, take the action first, then the future state, then the value, and use best-of-N to select the action.
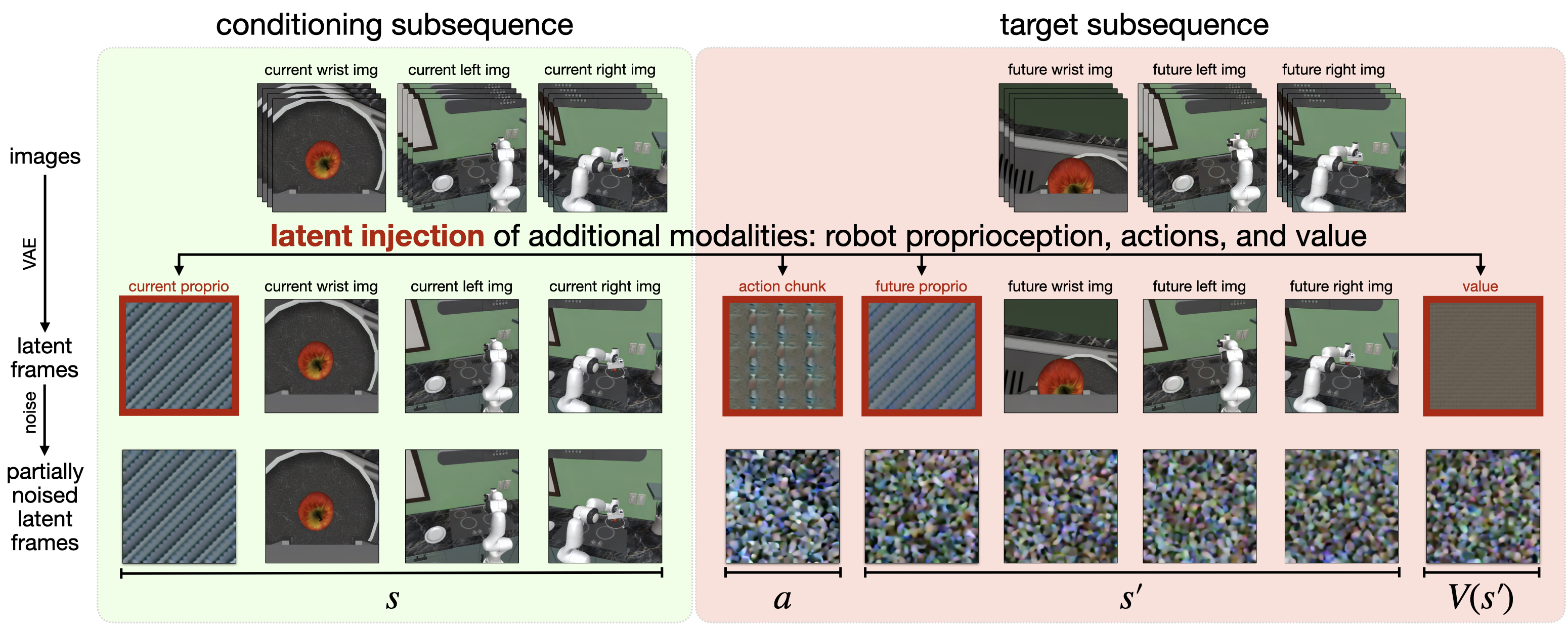
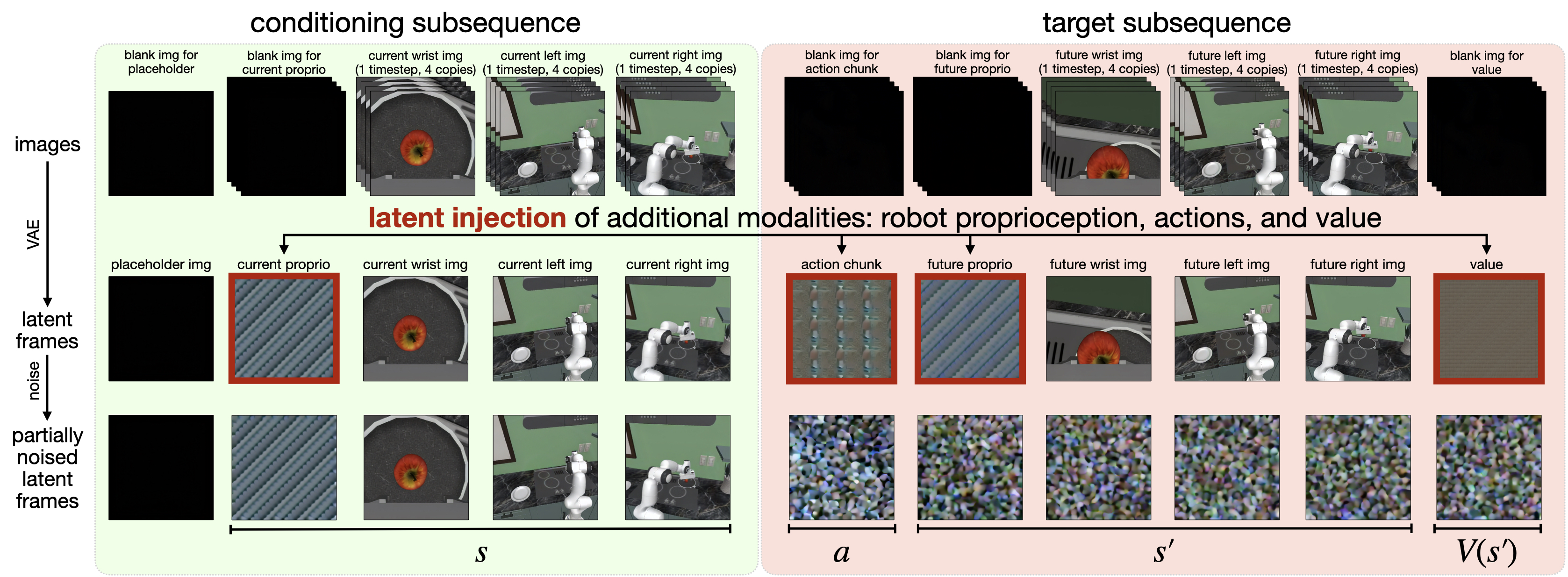
4.2 Method evolution
4.3 Core design and mathematical derivation
What Formula 1 is doing: retaining the original video diffusion training goal, the difference is that the "clean sample" is no longer just a video frame, but a joint latent sequence of actions, states, and values inserted.
$$ \mathcal{L}(D_\theta, \sigma) = \mathbb{E}_{\mathbf{x}_0, \mathbf{c}, \mathbf{n}} \left[ \left\| D_\theta(\mathbf{x}_0 + \mathbf{n}; \sigma, \mathbf{c}) - \mathbf{x}_0 \right\|_2^2 \right] $$
| $\mathbf{x}_0$ | Clean latent sequence. This can contain both image latent frames and injected action/state/value latent frames. |
| $\mathbf{c}$ | Text conditions, provided by T5-XXL embedding in the paper. |
| $\mathbf{n}$ | Gaussian noise, $\mathbf{n}\sim\mathcal{N}(0, \sigma^2 I)$. |
| $D_\theta$ | Diffusion transformer denoiser for Cosmos-Predict2. |
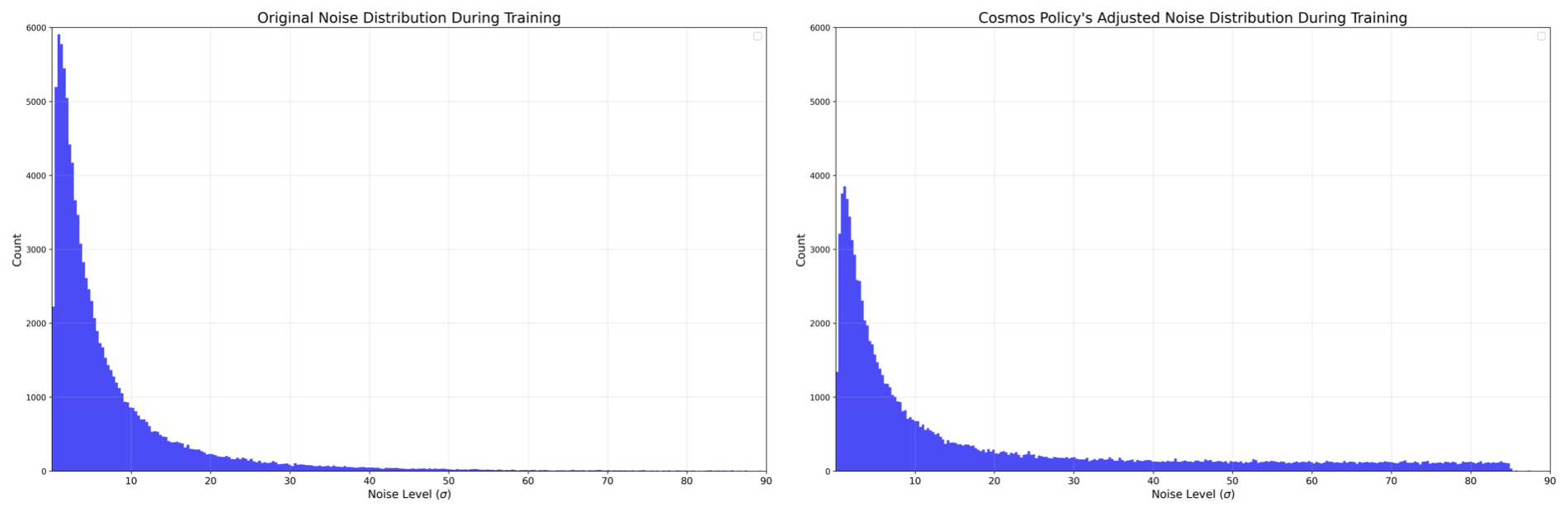
| $\sigma$ | Noise intensity; the author will specifically change its sampling distribution later.[Appendix A.2.1] |
What Equation 2 does: Define the value function under sparse reward and label each rollout transition with Monte Carlo return.
$$ V^\pi(s)= \mathbb{E}_{\tau\sim\pi}\left[\sum_{k=t}^{H}\gamma^{k-t}R(s_k, a_k)\mid s_t=s\right] = \mathbb{E}_{\tau\sim\pi}\left[\gamma^{H-t}R(s_H, a_H)\mid s_t=s\right] $$
| $s_t, a_t$ | The status and actions at time $t$. |
| $H$ | episode length of time domain. |
| $\gamma$ | The discount factor spreads the final rewards forward. |
| $R(s_H, a_H)$ | End point reward; use sparse reward for tasks in the text. |
Although the formula is not written as a total loss, the text actually defines three types of conditional distributions, which correspond to three working modes of the same network.
| $p(a, s', V(s')\mid s)$ | Strategy training: given the current state, jointly generate actions, future states and values. |
| $p(s', V(s')\mid s, a)$ | World model training: given the current state and actions, predict future states and values. |
| $p(V(s')\mid s, a, s')$ | Value function training: given the complete prefix, predict future values. |
Why this joint targeting might work
If you only train $p(a\mid s)$, the model only needs to output an action block that can complete the task; but the joint objective requires it to generate future states and values at the same time, which is equivalent to using "behavior consequences" as auxiliary supervision, forcing the hidden representation to be more sensitive to environmental dynamics. This is supported by both LIBERO and RoboCasa ablations in the paper.
Latent frame injection has not been written into a formal formula, but the implementation logic is very clear: first normalize, then copy, and then reshape to the single-frame latent variable volume.
| input | For example, if the action block size is $K\times d_{act}$, first flatten it into a vector of length $K d_{act}$. |
| normalization | Non-image modes are uniformly scaled to $[-1, +1]$. |
| Copy | Repeat $\frac{H'W'C'}{K d_{act}}$ times until the length matches the volume of a latent frame.[Appendix A.1] |
| Decode | After generation, these copied blocks are averaged and then denormalized to obtain action/state/value predictions; non-image modalities do not require VAE decoding. |
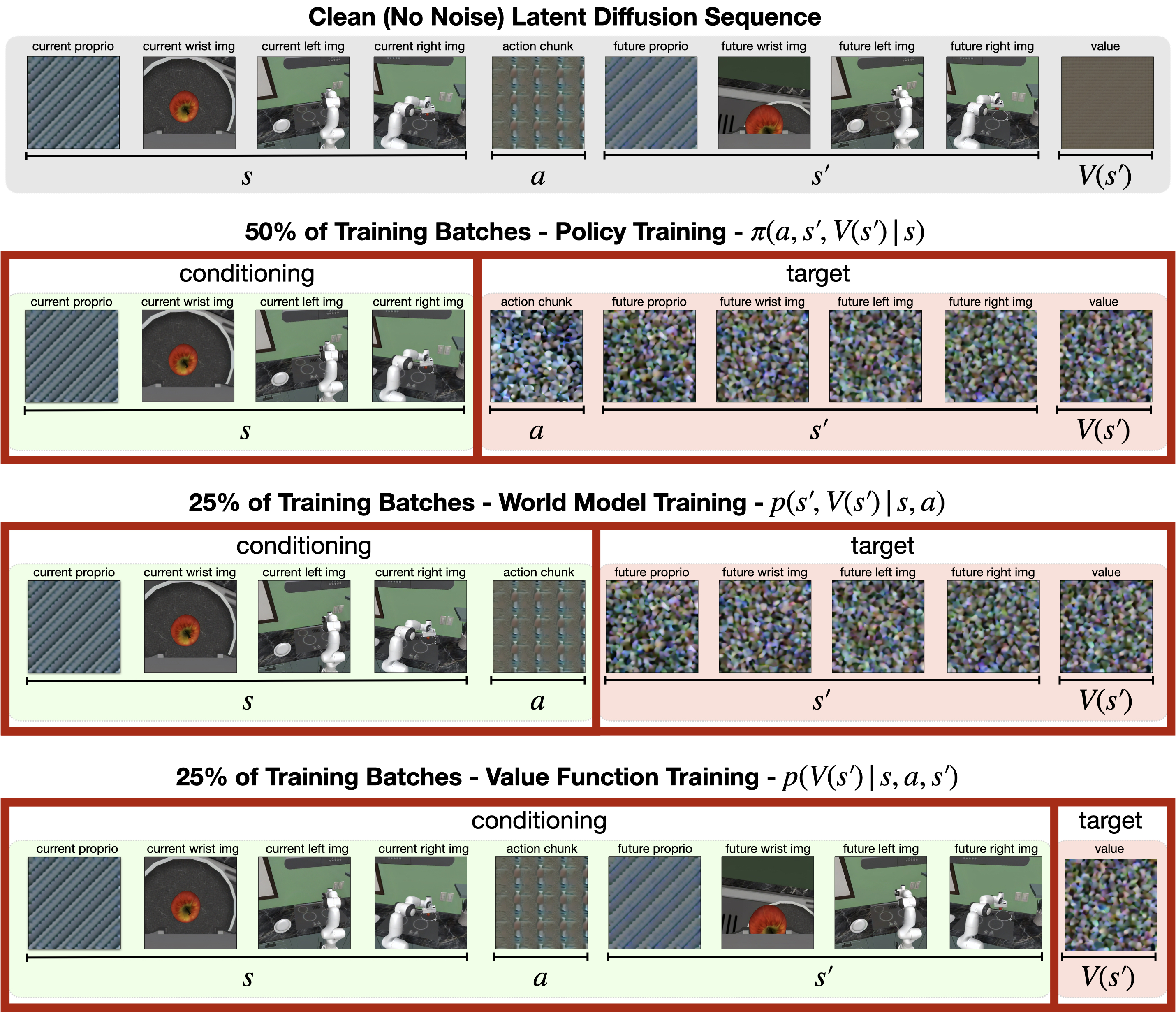
4.4 Implementation points
5. Experiment
5.1 Experimental setup
Datasets and tasks
| platform | tasks/data | training data | Observation and action | Additional details |
|---|---|---|---|---|
| LIBERO | Spatial / Object / Goal / Long Four sets of tasks, one-arm Franka Panda | 500 demonstrations per set (10 tasks × 50) | action chunk 16, test execution complete chunk | Policy training filtering fails demonstrations; world model/value uses unfiltered data |
| RoboCasa | 24 kitchen tasks with one arm Franka Panda | Use only 50 human teleoperation demonstrations per mission | action chunk 32, check again after executing 16 steps | The evaluation uses 5 scenes, 50 trials × 3 seeds per task, a total of 3600 times; only unseen objects are tested, and some styles have never appeared in training. |
| ALOHA | Four real-arm tasks: put X on plate / fold shirt / put candies in bowl / put candy in ziploc bag | Total 185 demonstrations | 14-dimensional joint angle + 3-way camera + text; chunk 50 (2 seconds), recheck after complete execution | 101 fixed initial condition evaluations, including IID and OOD |
baseline method
The paper compares the diffusion policy (Diffusion Policy, Dita) trained from scratch, the video model route (UVA, UWM, Video Policy), and the VLA route (π0, π0.5, OpenVLA-OFT, CogVLA, UniVLA, DP-VLA, GR00T-N1.5). Focus on comparing Diffusion Policy, OpenVLA-OFT+, and π in real ALOHA0 and π0.5.
Evaluation index
- LIBERO / RoboCasa: success rate.
- ALOHA: Staged completion scores on a scale of 0-100, rather than binary success. The scoring details are given in detail in the appendix. For example, "put candy in ziploc bag" is divided into five 20-point stages: grabbing the zipper, grabbing the corner of the bag, opening the mouth of the bag, grabbing the candy, and putting it in the bag.[Appendix A.3.2]
Training configuration and hardware
| platform | Number of training steps | GPU | global batch | Time consuming | Main loss after training |
|---|---|---|---|---|---|
| LIBERO | 40K | 64 × H100 | 1920 | 48 hours | action 0.012; future proprio 0.007; future wrist latent 0.068; future third-person latent 0.036; value 0.007 |
| RoboCasa | 45K | 32 × H100 | 800 | 48 hours | action 0.016; future proprio 0.007; future wrist latent 0.084; future third-person latent 0.048; value 0.007 |
| ALOHA | 50K | 8 × H100 | 200 | 48 hours | action 0.010; future proprio 0.008; future wrist latent 0.097; future third-person latent 0.085; value 0.007 |
All non-image modalities are normalized to $[-1, +1]$. The basic models are all fully parameter fine-tuned.[Appendix A.2.2-A.2.4]
Code repository and reproducibility
The paper clearly states that model checkpoints, training data and code will be released; the public entrance is the project page research.nvidia.com/labs/dir/cosmos-policy/. The Reproducibility Statement also states that training and evaluation scripts will be provided with the release.
5.2 Main results
LIBERO main results
| method | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|
| Diffusion Policy | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Dita | 97.4 | 94.8 | 93.2 | 83.6 | 92.3 |
| π0 | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| UniVLA | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| π0.5 | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| CogVLA | 98.6 | 98.8 | 96.6 | 95.4 | 97.4 |
| Cosmos Policy | 98.1 | 100.0 | 98.2 | 97.6 | 98.5 |
Interpretation: Cosmos Policy is not the first in all items, Spatial is π0.5 Higher, but it gets the best values in the Object, Goal, and Long columns, so the final average is the highest. In particular, Long mentioned OpenVLA-OFT from 94.5 to 97.6, indicating that the advantages of timing modeling emphasized by the author are mainly reflected in long-term tasks.
RoboCasa main results
| method | Number of training demonstrations per task | Average SR |
|---|---|---|
| GR00T-N1 | 300 | 49.6 |
| UVA | 50 | 50.0 |
| DP-VLA | 3000 | 57.3 |
| GR00T-N1 + DreamGen | 300 (+10000 synthetic) | 57.6 |
| GR00T-N1 + DUST | 300 | 58.5 |
| UWM | 1000 | 60.8 |
| π0 | 300 | 62.5 |
| GR00T-N1.5 | 300 | 64.1 |
| Video Policy | 300 | 66.0 |
| FLARE | 300 | 66.4 |
| GR00T-N1.5 + HAMLET | 300 | 66.4 |
| Cosmos Policy | 50 | 67.1 |
Interpretation: RoboCasa The most important information in this table is not that 67.1 is only 0.7 higher than 66.4, but that it only uses 50 real-person demonstrations per task. The paper uses this table to emphasize data efficiency, not just absolute accuracy.
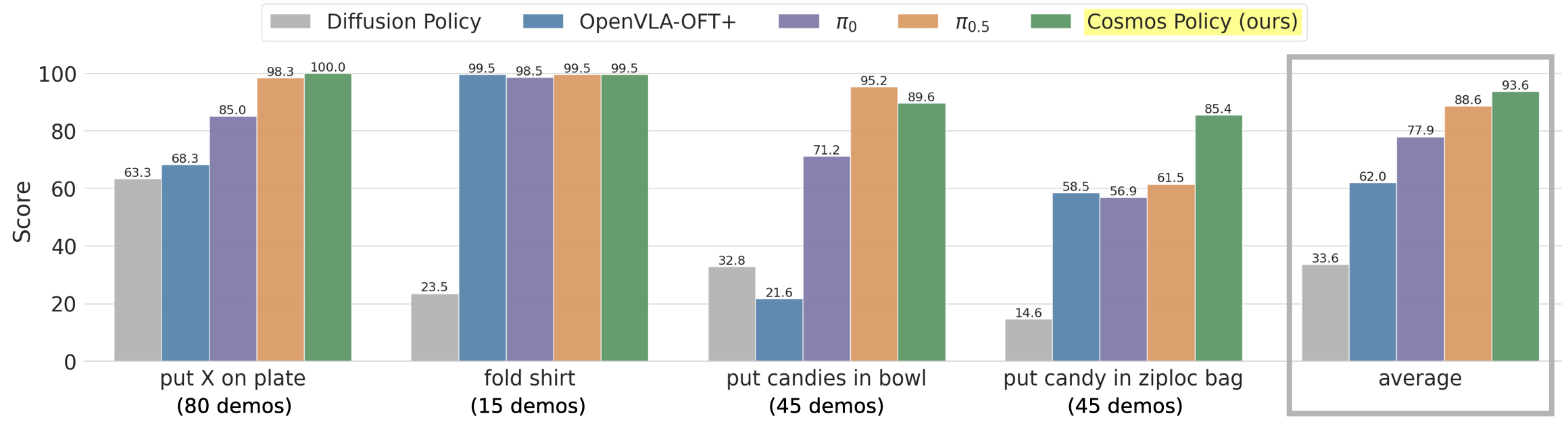
REAL ALOHA MAIN RESULTS
| method | put X on plate | fold shirt | put candies in bowl | put candy in ziploc bag | Average |
|---|---|---|---|---|---|
| Diffusion Policy | 63.3 | 23.5 | 32.8 | 14.6 | 33.6 |
| OpenVLA-OFT+ | 68.3 | 99.5 | 21.6 | 58.5 | 62.0 |
| π0 | 85.0 | 98.5 | 71.2 | 56.9 | 77.9 |
| π0.5 | 98.3 | 99.5 | 95.2 | 61.5 | 88.6 |
| Cosmos Policy | 100.0 | 99.5 | 89.6 | 85.4 | 93.6 |
Interpretation: The average score advantage of Cosmos Policy mainly comes from the last and most difficult ziploc bag task: 85.4 compared to π0.5 of 61.5, a huge advantage. candies in bowl on π0.5 It is higher, but ziploc bag has higher requirements for fine control. The paper uses it as a representative case of "the video model is better at high-precision control a priori".


IID / OOD Segmentation Results for ALOHA
| method | IID average | OOD average | observe |
|---|---|---|---|
| OpenVLA-OFT+ | 67.1 | 51.7 | The shirt has almost full marks, but the OOD of candies and put-on-plate has dropped significantly. |
| π0 | 81.3 | 71.7 | Overall stable, but no significant advantages at mission level |
| π0.5 | 87.8 | 92.5 | OOD average highest |
| Cosmos Policy | 96.3 | 89.3 | The overall average is the highest, but the paper also gives it honestly: when looking at the OOD average alone, π0.5 slightly higher |
This is important: 93.6 in the main results table does not mean that Cosmos Policy is the strongest in every generalization subscenario. The appendix clearly states that when broken down to the average OOD score, π0.5 Slightly higher.[Appendix A.3.2]


5.3 Ablation experiment
LIBERO ablation
| version | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|
| Complete Cosmos Policy | 98.1 | 100.0 | 98.2 | 97.6 | 98.5 |
| Remove auxiliary losses | 97.6 | 99.8 | 96.7 | 94.0 | 97.0 |
| No need to pre-train the video model, train it from scratch | 94.7 | 98.9 | 96.3 | 88.6 | 94.6 |
Interpretation: auxiliary supervision brings 1.5 points; video prior brings 3.9 points. The biggest drop is still in the Long column, which once again shows that the timing prior mainly helps long-time tasks.
RoboCasa ablation and additional experiments
| version | Average SR |
|---|---|
| Complete Cosmos Policy (5 denoising steps) | 67.1 |
| Remove value function training samples | 66.6 |
| Remove world model + value function training samples | 64.0 |
| Then remove the auxiliary value supervision during policy training | 62.5 |
| Then remove the auxiliary future state + value supervision during policy training, leaving only the pure action strategy | 44.4 |
| Only use 1 denoising step | 66.4 |
There are two conclusions from this table. First, the pure action strategy dropped from 67.1 to 44.4, indicating that "letting the policy predict the future state at the same time" is not the icing on the cake, but a key component. Second, using only one denoising step can still maintain 66.4, which is almost unchanged, indicating that the number of diffusion inference steps has obvious room for compression in this task.[Appendix A.4.1]
5.4 Supplementary experiments (from appendix)
Plan an experiment
The authors only conduct planning evaluations on two more difficult ALOHA tasks: put candies in bowl and put candy in ziploc bag. The rollout data pool consists of two parts: 505 rollouts accumulated during the previous direct policy evaluation, plus an additional 143 rollouts collected for the ziploc bag, for a total of 648 rollouts. The author believes that additional ziploc data is critical because this task has severe self-occlusion, high environmental randomness, and millimeter-level motion differences that will affect the results.
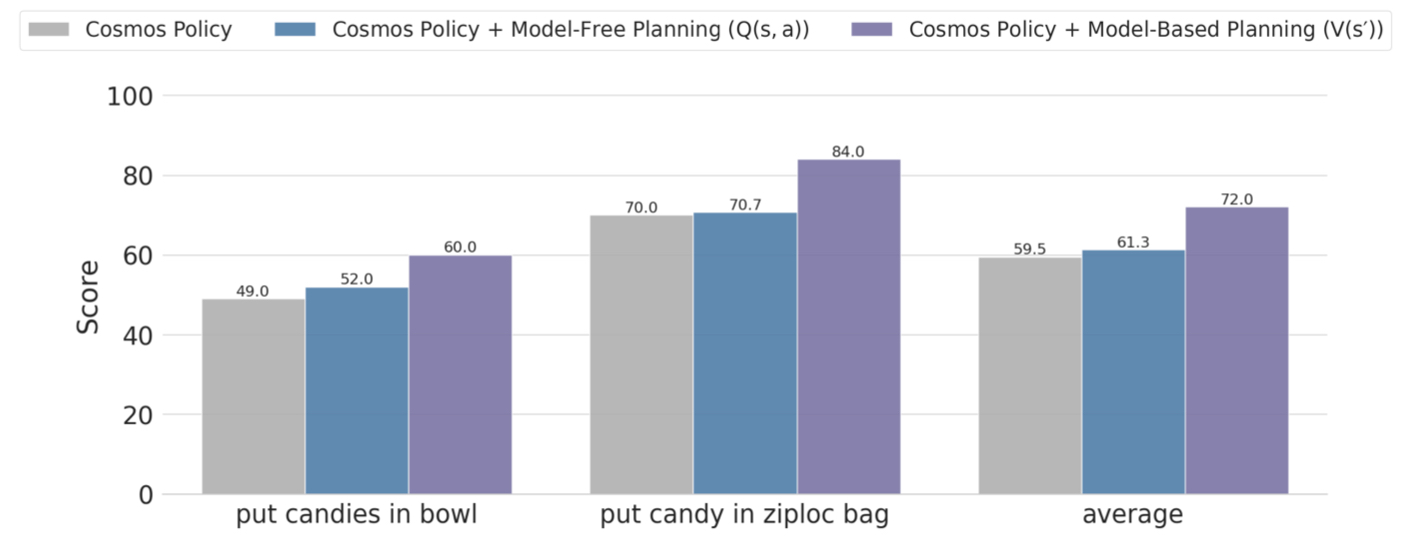
The author compares two forms of value training:
- $V(s')$: The world model first predicts the future state, and then scores the future state. This is the model-based version.
- $Q(s, a)$: Score the current state and actions directly, without the need for an explicit world model. This is the model-free version.
The result is that $V(s')$ is better. The author's own explanation is: when the rollout data is very limited, explicitly using future states and environmental dynamics is more sample efficient than directly learning high-dimensional Q functions, and is less likely to overfit.
Reasoning delay
| settings | delay | Description |
|---|---|---|
| direct policy, 5 denoising steps | 0.61 s / action chunk | LIBERO / RoboCasa |
| direct policy, 10 denoising steps | 0.95 s / action chunk | ALOHA |
| direct policy, 1 denoising step | 0.16 s / action chunk | RoboCasa still has 66.4% SR |
| ALOHA model-based planning | 4.9 s | 8 H100s in parallel, N=8, each candidate action is performed 3 times for future state and 5 times for value ensemble |
This is also the most realistic cost of the paper: planning is useful, but very slow. The author lists this as the primary limitation in the Discussion.
6. Analysis and Discussion
6.1 Analysis and explanation of the results given in the paper
- The authors argue that the video model prior is an efficient initialization and thus can outperform partially strong VLA on real robots even without additional large-scale action labels. The text directly attributes this to the video model learning spatiotemporal dynamics and implicit physics, not just static semantics.
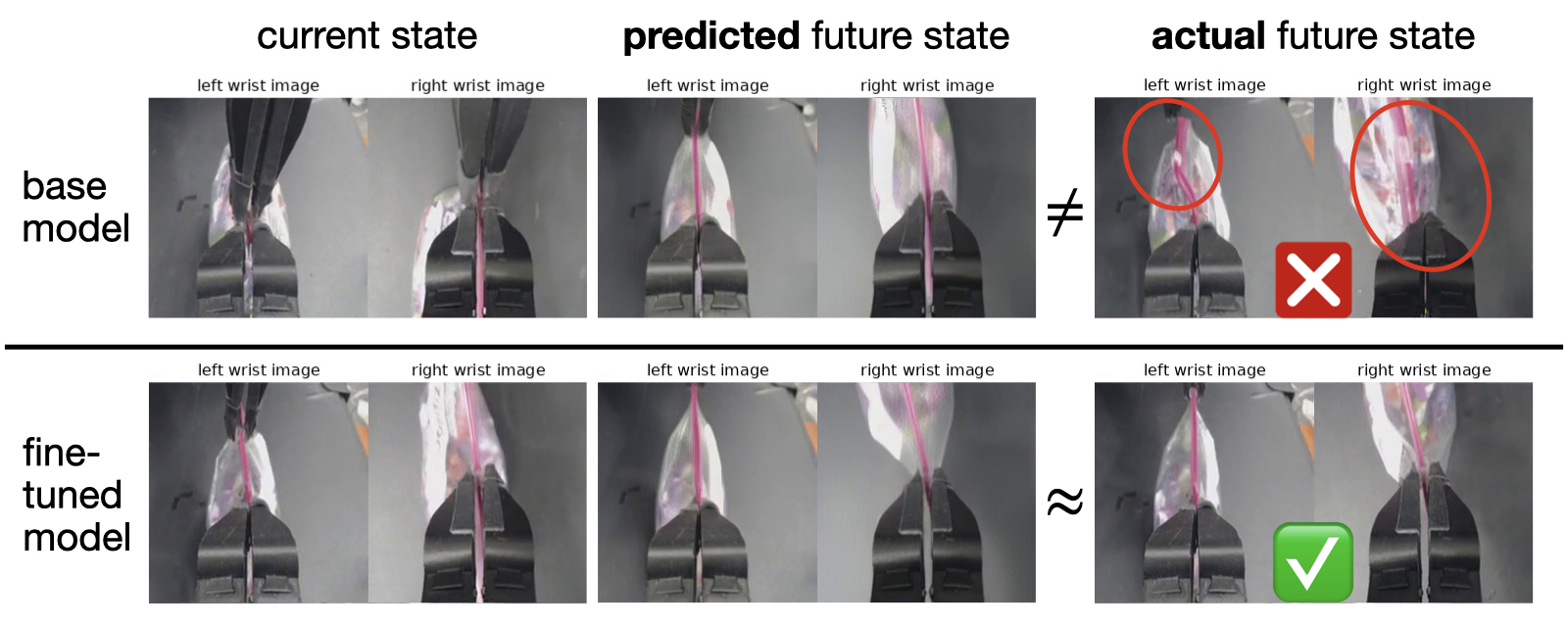
- The author uses the failure case in Figure 5 to explain why high multi-modality and high-precision tasks are a watershed: a deviation will pull the action between the two targets, or miss in millimeter-level grasping.
- The author uses Figure 6 to illustrate that the planning model after rollout fine-tuning can better predict the consequences of failure, so the planning stage can avoid mistakes that are easy to make with basic strategies, such as the slipper of a zipper bag.
- The value of auxiliary supervision and joint objective is clearly verified in ablation: not all modules are equally important, but "letting policy predict future states together" is very critical.
6.2 Limitations of the author's statement
Limitation 1: Planning reasoning is slow. The paper clearly states that model-based planning takes about 5 seconds to produce an action chunk, which is not friendly to dynamic tasks.
Limitation 2: Planning relies on rollout data. A sufficiently accurate world model/value function cannot be learned by demonstration alone; if there are few rollouts, the planning quality will be significantly limited.
Limitation 3: The current search tree has only one level. The paper only performs best-of-N single-layer search and does not extend the prediction horizon of the world model to deeper planning.
6.3 Applicable boundaries and discussions clearly stated in the paper
- The "state" in this article is actually closer to observation, because the real environment is not completely observable; the author specifically states this in Preliminaries for the sake of simplicity. In other words, the world model predicts future observations, not the complete state in the strict sense.
- The benefits of planning are mainly shown in difficult tasks where the basic direct policy still has obvious room for error; for the first two easier tasks of LIBERO or ALOHA, the paper does not emphasize further planning gains.
- Both RoboCasa and ALOHA embody methods that can do multi-perspective input, but do not build in the input history; the state only takes the current moment, and only predicts $t+K$ in the future, so the model is not a long horizon autoregressive world model.
- The future work given at the end of the paper also strictly focuses on the original method: accelerating search, reducing rollout requirements, and extending deeper planning depth.