Causal World Modeling for Robot Control
1. 论文速览
| 论文要解决什么 | 现有 VLA 多是从当前图像直接反应式地输出动作,视觉理解、物理动态和运动控制被挤在一个监督信号里,容易样本效率低、泛化差;已有世界模型又常用 open-loop 或 chunk-based bidirectional diffusion,难以持续接入真实反馈。 |
|---|---|
| 作者的方法抓手 | 用 Wan2.2-5B 视频扩散骨干做 video stream,增加较窄 action stream,通过 Mixture-of-Transformers 交互;把视频 token 和 action token 按时间交错成单一 causal 序列,用 flow matching 同时训练 visual dynamics 和 inverse dynamics。 |
| 最重要的结果 | RoboTwin 2.0 50 任务平均 SR 达 92.93% Easy / 91.55% Hard;LIBERO 平均 SR 达 98.5%;真实世界 6 个任务仅用每任务 50 demos 适配,平均 progress score 约 79.2%,平均 success rate 约 59.2%,均高于 $\pi_{0.5}$ 的约 65.4% / 39.2%。 |
| 阅读时要注意的点 | 论文正文称真实世界两项指标均整体更好,但附录逐项表显示 Fold Clothes 的 progress score 上 $\pi_{0.5}$ 高于 LingBot-VA;报告以下按表格原数值客观呈现。 |
World Model Flow Matching Autoregressive Diffusion Mixture-of-Transformers Inverse Dynamics Asynchronous Control
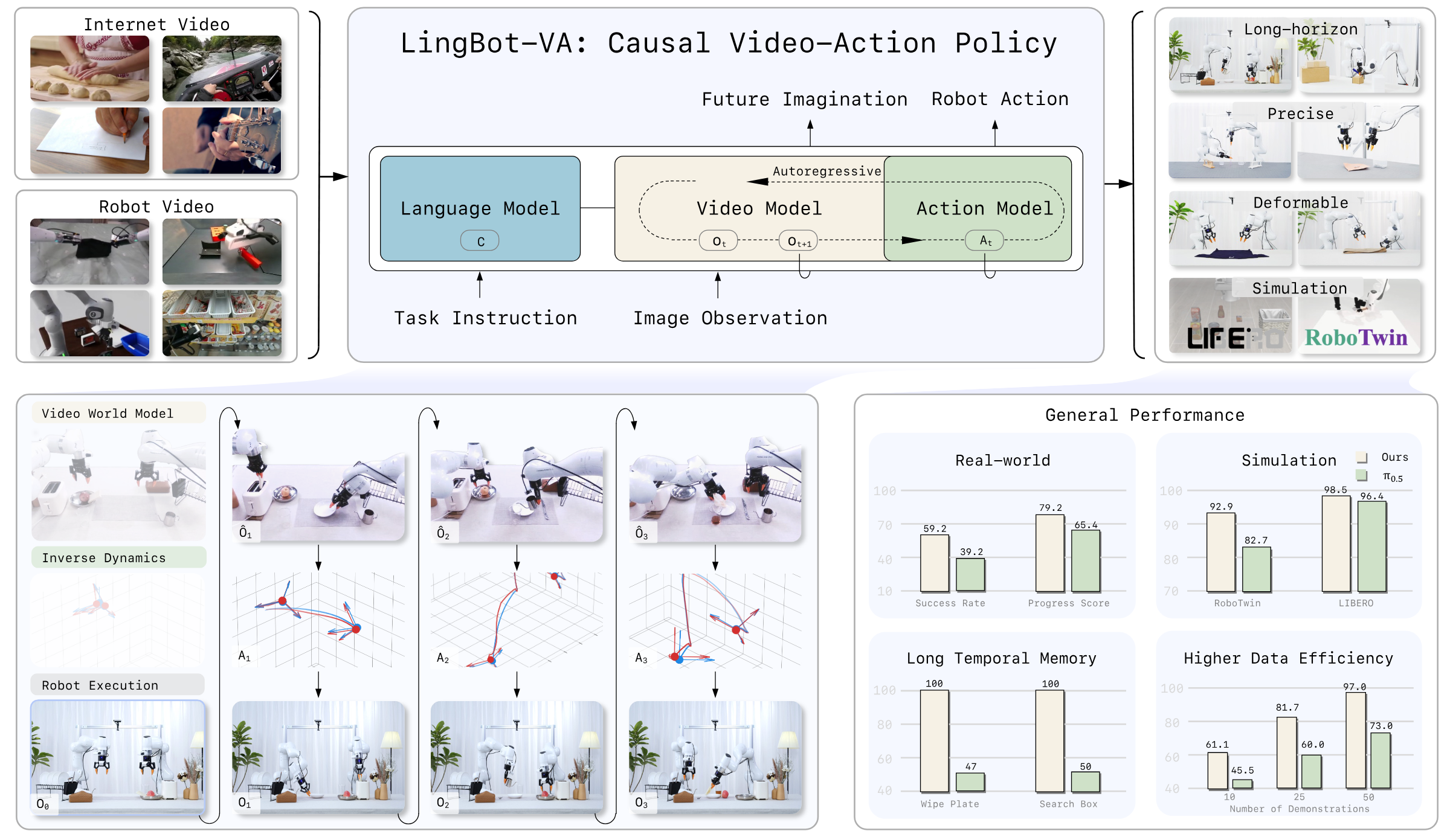
核心贡献
- Autoregressive Video-Action World Modeling。把视频动态预测与动作推断架构上统一到一个交错序列里,同时概念上保持“世界动态”和“动作 inverse dynamics”的分工。
- MoT + 非对称双流。视频流继承 Wan2.2-5B,动作流同层数但更窄,用跨模态 attention 融合,避免 action 与 video 特征空间完全混在一起。
- 闭环部署机制。用 KV cache 保存历史,使用 real observation 持续刷新上下文;异步推理把动作执行和下一段预测并行化,减少控制延迟。
- 实验覆盖面较广。同时给出 RoboTwin、LIBERO、真实世界任务、少样本、时序记忆和泛化实验;附录给出 50 个 RoboTwin 任务和真实世界逐 trial 评分细节。
2. 动机与相关工作
2.1 现有 VLA 的 representation entanglement
论文认为,当前 VLA 常采用 feedforward policy:把当前视觉观测和语言指令直接映射到 action sequence。这种方法把视觉语义、物理动态和低层运动控制都压进同一个表示和同一个动作监督信号里。作者称其为 representation entanglement,并指出这会导致两个问题:样本效率不高,以及对新场景、新物体、长时序任务泛化有限。
2.2 现有 world model / video policy 的三类限制
- Reactivity gap。open-loop 或 chunk-based 生成通常一次 rollout 较长片段,不易在执行中吸收真实反馈。
- Limited long-term memory。chunk-wise generation 每个 chunk 相对独立,长 horizon 中容易出现跨 chunk 漂移。
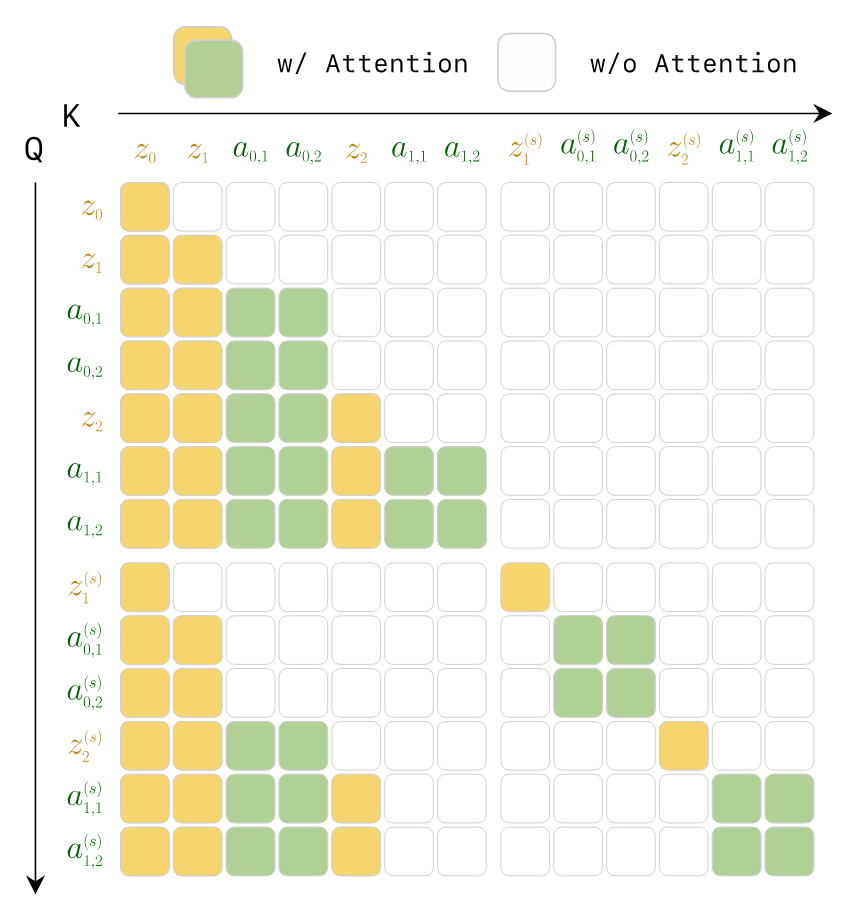
- Causality mismatch。许多 diffusion video-action 方法在一个片段内部使用双向 attention,未来 token 会影响过去 token 的预测;这和真实物理中“当前只依赖过去”的因果结构不一致。
2.3 与相关工作的关系
| 方向 | 论文中的定位 | LingBot-VA 的差异 |
|---|---|---|
| Vision-Language-Action Policies | $\pi_0$、$\pi_{0.5}$、GR00T-N1、OpenVLA 等利用 VLM/VLA 预训练并通过机器人 demonstrations 微调。 | 不只学习 observation-to-action reactive mapping,而是显式训练 video dynamics 与 inverse dynamics,并在执行时维护 causal history。 |
| World Models for Robotic Control | latent-space、3D point cloud、2D pixel/video 三类;论文聚焦可在执行中预测未来帧并条件化动作生成的 video/world model。 | 使用 KV cache 与 causal mask 持续接入真实观测,且通过 partial denoising 避免等待完整高质量视频生成。 |
| Video-action generative policies | UVA、UWM、Motus、Gen2Act、Act2Goal 等展示 video-action 联合或视频子目标思路。 | 强调 causal autoregressive sequence 和 persistent memory,而不是 bidirectional chunk generation 或离线视频子目标。 |
3. 方法详解
3.1 从 reactive policy 到 world-model-first policy
普通 VLA 用 $\pi_\theta(\cdot \mid o_t)$ 直接预测动作。LingBot-VA 把控制拆成两个阶段:先预测未来视觉状态,再根据当前状态和预测未来状态反推动作。这个分解允许 Stage 1 借助大规模视频数据学习物理先验,而 Stage 2 用机器人数据把视觉变化落到可执行动作上。
3.2 Flow Matching 预备知识
论文使用 continuous latent diffusion / flow matching。给定数据样本 $x_1$ 和噪声 $\epsilon \sim \mathcal{N}(0,I)$,模型学习一个连续时间向量场,把噪声沿路径推到数据分布。
直观理解:模型不是一步预测最终样本,而是学习每个噪声状态该往哪个方向移动。
$$\frac{dx^{(s)}}{ds}=v_s(x^{(s)}), \quad x^{(0)}=\epsilon$$ $$\mathcal{L}_{\text{FM}}=\mathbb{E}_{s,\epsilon,x_1}\left[\|v_\theta(x^{(s)},s)-\dot{x}^{(s)}\|^2\right]$$常用线性插值 $x^{(s)}=(1-s)\epsilon+s x_1$,因此真实速度 $\dot{x}^{(s)}=x_1-\epsilon$。推理时从噪声出发积分到 $s=1$。
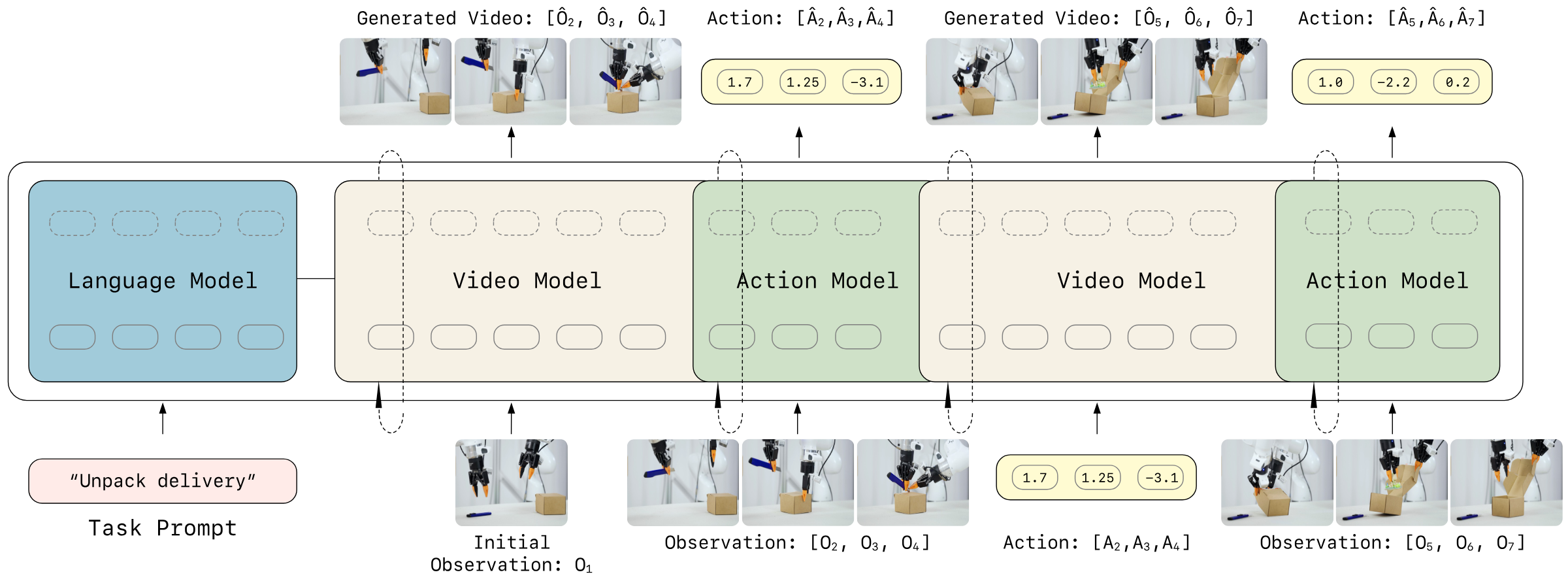
3.3 Autoregressive Video-Action World Modeling
核心思想是把视觉 latent 和动作 token 放进一个按时间展开的 causal 序列。每个 autoregressive step 预测一个视频 chunk,同时解码对应动作 chunk;chunk 内部可以并行生成,chunk 与 chunk 之间保持 causal dependency。
视觉动态预测:下一段视频 latent 由过去视觉和过去动作决定。
$$z_{t+1:t+K} \sim p_\theta(\cdot \mid z_{\leq t}, a_{动作解码:给定预测未来视觉状态,反推出实现该视觉转移的动作。
$$a_{t:t+K-1} \sim g_\psi(\cdot \mid \hat{z}_{t+1:t+K}, z_{\leq t}, a_{3.4 统一架构:非对称双流 MoT
| 模块 | 论文设置 | 设计目的 |
|---|---|---|
| Video stream | 初始化自 Wan2.2-5B,hidden dimension $d_v=3072$,30 层 Transformer。 | 继承大规模视频生成模型中的视觉动态先验。 |
| Action stream | 同样 30 层,但宽度 $d_a=768$,比视频流小 4 倍;额外约 350M 参数,总模型约 5.3B。 | 动作分布比视频更低维,不需要同样容量;保留动作专用特征空间。 |
| MoT fusion | video/action 分别计算 QKV,action token 先投影到 video dimension 参加 joint self-attention,再投回 action dimension。 | 允许跨模态交互,同时减少不同模态表示互相污染。 |
| Video sparsification | 视频时间降采样 $\tau=4$,每个视频帧关联 $\tau$ 个连续动作。 | 减少视频 token 数,同时保留动作高频控制。 |
| Action initialization | 用 pretrained video weights 插值初始化 action stream,并用 $\alpha=\sqrt{d_v/d_a}$ 缩放。 | 稳定 early training,避免 action token 分布与 video token 分布差距过大破坏 joint attention。 |
3.5 Teacher Forcing 与 causal attention mask
训练时,整条 episode 被看作 interleaved video-action sequence。模型在每个 token 位置预测下一个 token,但上下文使用 ground-truth 历史 token,而不是模型自己生成的历史。作者强调这在机器人中合理,因为部署时也会不断接收真实世界观测。
3.6 Noisy History Augmentation 与 partial denoising
视频 token 生成是推理瓶颈,因为视觉 token 数量大且每个 token 需要多步 denoising。作者的观察是:动作预测未必需要完全去噪后的像素级视觉,部分去噪的 latent 已能提供 action-relevant structure。因此训练时随机把历史视频 latent 加噪,迫使 action decoder 适应 noisy visual states。
推理时视频 token 不必完整积分到 $s=1$。正文理论处写可积分到 $s=0.5$;实验实现中使用 Euler solver 3 steps 并积分到 $s=0.6$,动作 token 仍用 10 steps 积分到 $s=1.0$。
3.7 KV Cache 与异步推理
同步推理会让机器人等待模型生成未来视频和动作;异步推理则让机器人执行当前 action chunk 的同时,模型预测下一段。问题在于 naive async 会基于 stale predicted video 继续生成,造成漂移。LingBot-VA 加入 Forward Dynamics Model grounded step:用最近真实观测和当前正在执行的动作重新想象当前结果,再预测后续视觉和动作。

4. 数学形式与训练目标
4.1 训练 loss
视觉动态 loss:监督模型在给定历史、动作和语言条件下预测下一视觉 latent 的 flow velocity。
$$\mathcal{L}_{\mathrm{dyn}} = \mathbb{E}_{t,s,z_{t+1},\epsilon} \left[ \left\| v_\theta(z_{t+1}^{(s)},s,\tilde{z}_{\leq t},a_{动作 inverse dynamics loss:从当前/下一视觉 latent 与历史动作中恢复 action flow。
$$\mathcal{L}_{\mathrm{inv}} = \mathbb{E}_{t,s,a_t,\epsilon} \left[ \left\| v_\psi(a_t^{(s)},s,\tilde{z}_{\leq t+1},a_{4.2 异步 post-training 的 forward dynamics loss
5. 实验与结果
5.1 数据与训练设置
| 项目 | 设置 |
|---|---|
| 预训练数据 | 聚合 Agibot、RoboMind、InternData-A1、OpenVLA subset of OXE、UMI Data、RoboCOIN,以及内部采集 demonstrations;总计约 16K 小时机器人操作数据。 |
| 通用 action 表示 | 双臂统一为每臂 7 维 EEF pose、最多 7 维 joint angles、1 维 gripper;双臂共 $(7+7+1)\times2=30$ 维,不足维度补零。 |
| 视频编码 | Wan2.2 causal VAE,压缩比 $4\times16\times16$,再 patchify 使空间维度再减半,多视角沿宽度拼接,每帧 $N=192$ spatial tokens。 |
| 预训练 | 1.4T tokens;AdamW,peak LR $1\times10^{-4}$,weight decay 0.01,cosine annealing + linear warmup,bf16,gradient clipping 2.0,text dropout 0.1,uniform SNR sampler。 |
| post-training | 少量任务数据适配;正文称 50 demos 可有效部署;推荐 LR $1\times10^{-5}$ 训练 3K steps,也可 LR $1\times10^{-4}$ 训练 1K steps。真实世界实验处写 500 steps、LR $1\times10^{-4}$、sequence length 150,000。 |
| 推理 | video Euler solver 3 steps 到 $s=0.6$,action 10 steps 到 $s=1.0$;video CFG 5.0,action CFG 1.0;部署 chunk size $K=4$。 |
5.2 真实世界部署
作者在真实双臂平台上评估 6 个任务,按 long-horizon、precision、deformable 三类组织。每个任务只用 50 条真实 demonstrations 做训练/适配;附录说明每个方法每任务 20 trials,并交替测试两个方法以减少顺序偏差。Progress Score 是平均步骤得分除以最大步骤数,Success Rate 是全步骤成功 trial 占比。
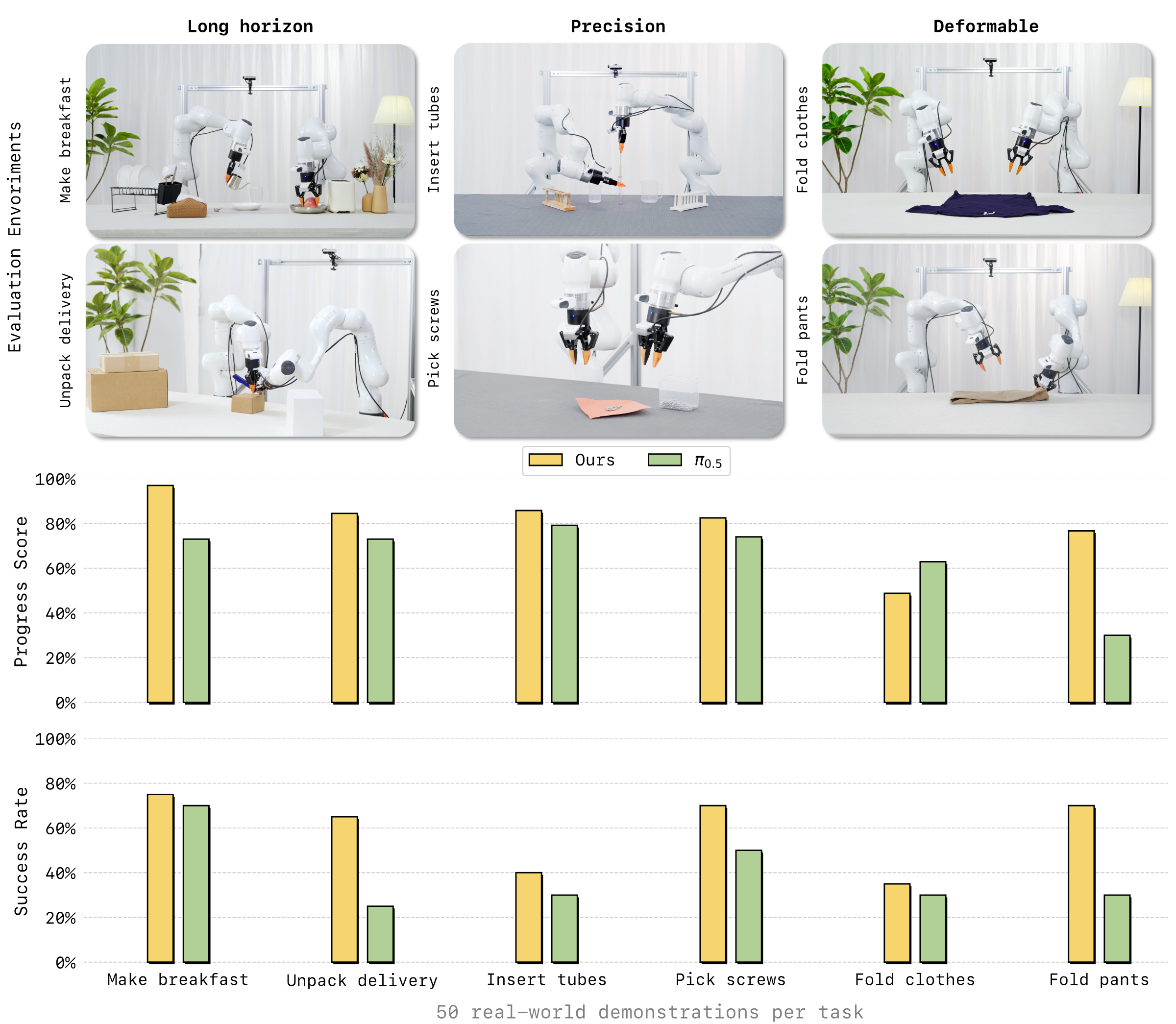
| 任务 | 类别 | LingBot-VA PS | $\pi_{0.5}$ PS | LingBot-VA SR | $\pi_{0.5}$ SR | 备注 |
|---|---|---|---|---|---|---|
| Make Breakfast | Long-horizon | 97.0 | 73.0 | 75.0 | 70.0 | 10 steps;LingBot-VA 主要失败在 pour、serve 或中间放置。 |
| Pick Screws | Precision | 82.5 | 74.0 | 70.0 | 50.0 | 5 steps;LingBot-VA 在倒螺丝与逐个插入上整体更稳。 |
| Insert Tubes | Precision | 85.8 | 79.2 | 40.0 | 30.0 | 3 个 grasp + 3 个 insert;grasp 接近满分,insert 是主要瓶颈。 |
| Unpack Delivery | Long-horizon | 84.5 | 73.0 | 65.0 | 25.0 | 切封条和开盖是 $\pi_{0.5}$ 的主要失败点。 |
| Fold Clothes | Deformable | 48.8 | 62.9 | 35.0 | 30.0 | LingBot-VA 完整成功率略高,但 progress score 低于 $\pi_{0.5}$。 |
| Fold Pants | Deformable | 76.7 | 30.0 | 70.0 | 30.0 | LingBot-VA 在三步折叠任务上提升明显。 |
| 平均 | - | 79.2 | 65.4 | 59.2 | 39.2 | 按 6 个任务简单平均。 |

5.3 RoboTwin 2.0 仿真
RoboTwin 2.0 是双臂 manipulation benchmark。论文采用多任务训练:50 个任务,每任务 clean scenes 50 demonstrations,加 heavily randomized scenes 500 demonstrations;视频从 50 Hz 降到 12.5 Hz,动作频率保持 50 Hz;训练 50K steps,LR $1\times10^{-5}$。
| Metric | X-VLA Easy | X-VLA Hard | $\pi_0$ Easy | $\pi_0$ Hard | $\pi_{0.5}$ Easy | $\pi_{0.5}$ Hard | Motus Easy | Motus Hard | Ours Easy | Ours Hard |
|---|---|---|---|---|---|---|---|---|---|---|
| Horizon = 1 | 81.6 | 82.5 | 66.5 | 61.6 | 85.1 | 80.2 | 91.0 | 90.6 | 94.18 | 93.56 |
| Horizon = 2 | 59.3 | 55.9 | 66.1 | 54.7 | 79.3 | 73.0 | 85.2 | 80.9 | 90.35 | 86.95 |
| Horizon = 3 | 61.2 | 66.0 | 61.6 | 50.2 | 78.6 | 67.4 | 85.0 | 84.2 | 93.22 | 93.28 |
| Average 50 Tasks | 72.9 | 72.8 | 65.9 | 58.4 | 82.7 | 76.8 | 88.7 | 87.0 | 92.93 | 91.55 |
附录提供 50 个任务逐项结果。按任务看,LingBot-VA 并非每个子任务都第一,例如 Hanging Mug、Turn Switch 等仍有明显空间;但平均值在 Easy/Hard 与各 horizon 分组上均超过第二名。
5.4 LIBERO 仿真
LIBERO 使用 Spatial、Object、Goal、Long 四个 suite,每个 suite 10 tasks、每任务 50 demos。论文过滤失败 demonstrations,finetune 4K steps,LR $1\times10^{-5}$,sequence length $10^5$。每个 suite 报告 3 个随机 seed,每 seed 500 trials,共 1500 trials。
| Method | Spatial | Object | Goal | Long | Avg |
|---|---|---|---|---|---|
| OpenVLA | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| $\pi_0$ | 96.8 | 98.8 | 95.8 | 85.2 | 94.1 |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| X-VLA | 98.2 | 98.6 | 97.8 | 97.6 | 98.1 |
| LingBot-VA | 98.5 ± 0.3 | 99.6 ± 0.3 | 97.2 ± 0.2 | 98.5 ± 0.5 | 98.5 |
5.5 Ablation
| Ablation | Setting | Easy all | Horizon 1 | Horizon 2 | Horizon 3 | 解释 |
|---|---|---|---|---|---|---|
| Baseline | LingBot-VA | 92.9 | 94.2 | 90.4 | 93.2 | 完整方法。 |
| Deployment | FDM-grounded Async | 90.4 | 92.5 | 87.7 | 85.6 | 异步加 FDM grounding,速度提升但 SR 略降。 |
| Deployment | Naive Async | 74.3 | 83.3 | 70.3 | 32.9 | 不做真实反馈校准,长 horizon 明显崩塌。 |
| Pretrain | WAN init | 80.6 | 84.9 | 76.3 | 67.6 | 只用 Wan2.2 初始化再微调,缺少 video-action 预训练。 |
正文还指出异步方法任务完成速度约为同步的 2 倍;表中 FDM-grounded async 与 baseline 接近,而 naive async 尤其在 Horizon=3 从 93.2 掉到 32.9,直接支持“stale prediction 会导致 drift”的设计动机。
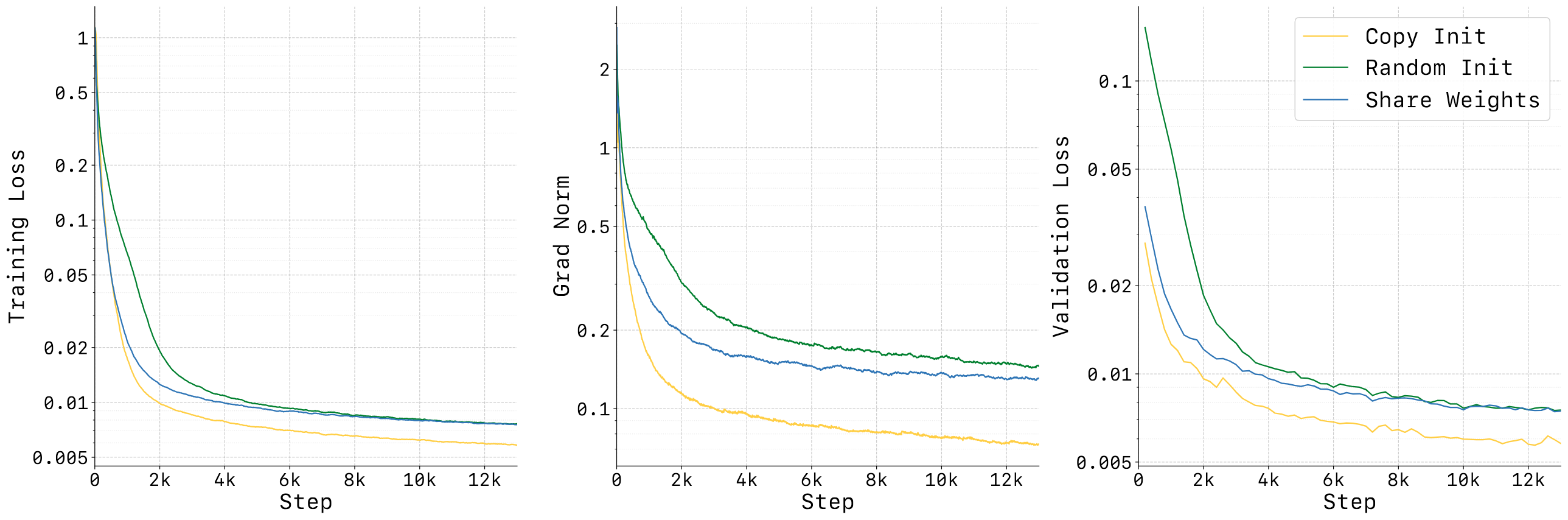
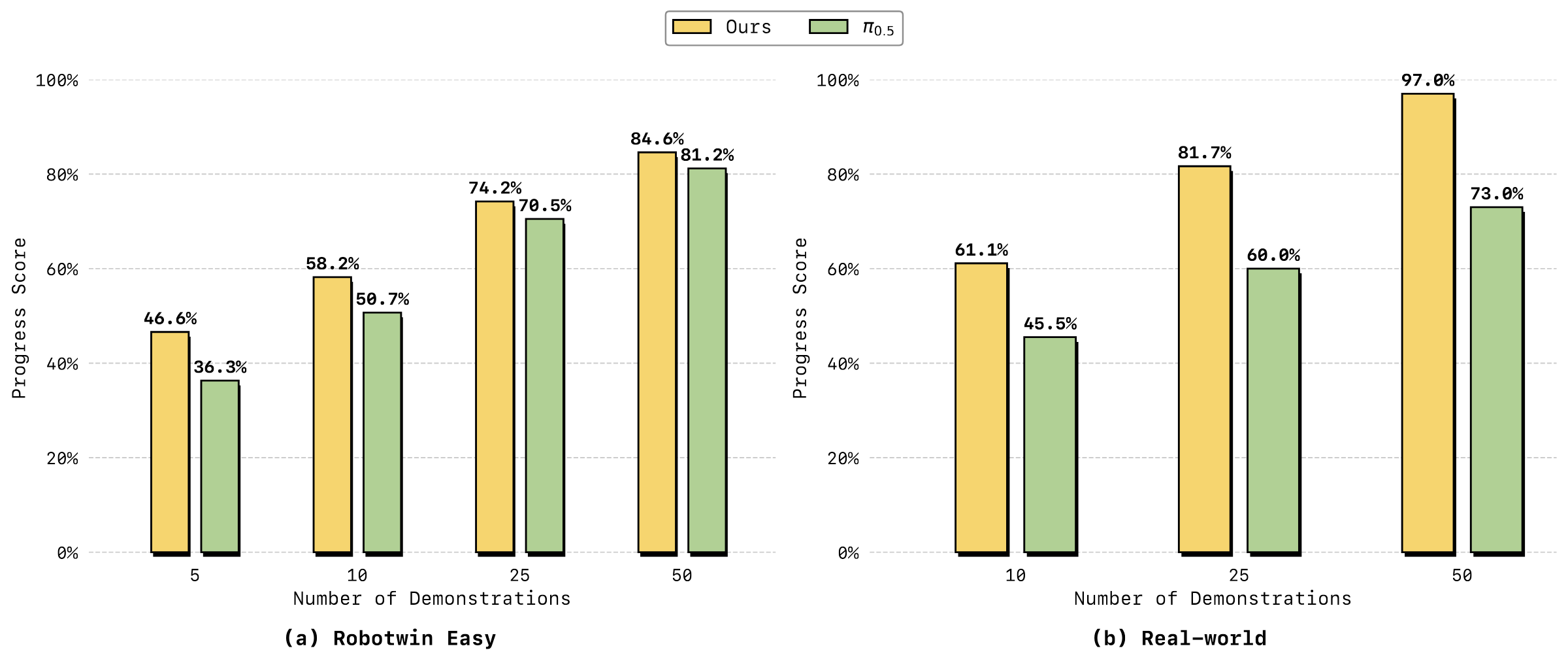
5.6 分析实验:少样本、记忆、泛化

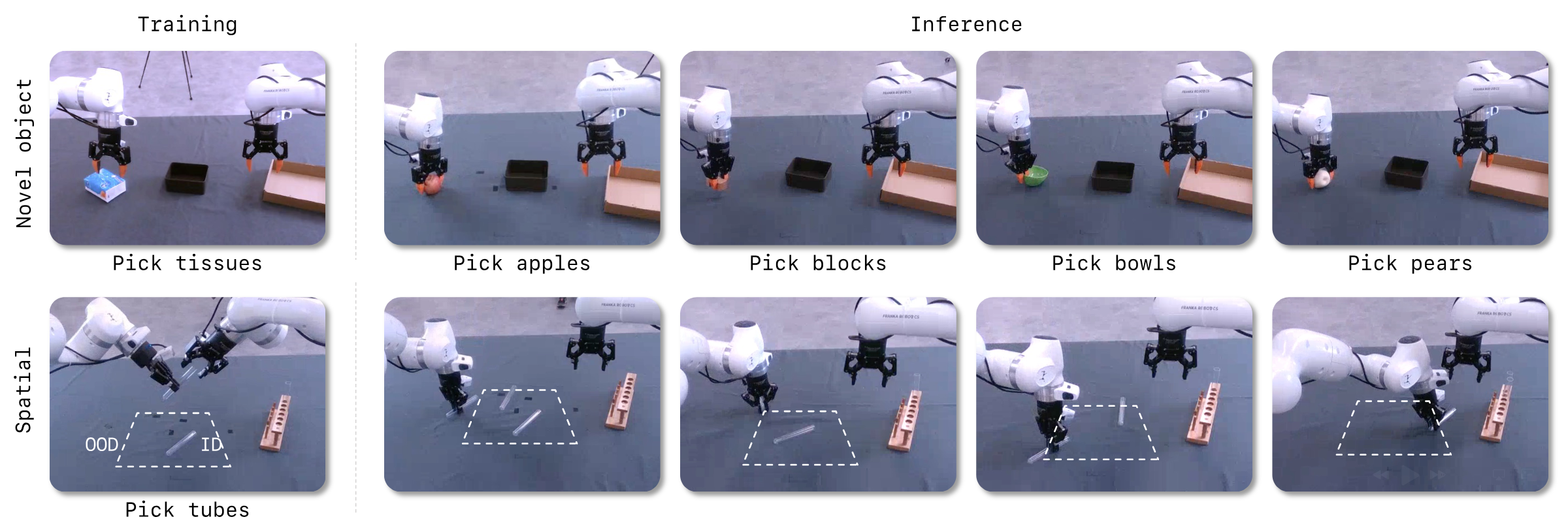
6. 复现审计
6.1 公开资源
代码和模型已公开。arXiv 与源码 metadata 指向 GitHub 仓库 和 项目页。截至本报告生成时,GitHub README 显示已公开 base checkpoint、RoboTwin post-train checkpoint、LIBERO-Long post-train checkpoint,以及 RoboTwin/LIBERO 评测脚本和 post-training 数据说明。
6.2 环境与运行信息
| 项目 | 公开信息 |
|---|---|
| 基础环境 | GitHub README 写明 Python 3.10.16、PyTorch 2.9.0、CUDA 12.6;依赖包括 diffusers 0.36.0、transformers 4.55.2、flash-attn 等。 |
| attention mode | README 强调训练需设 `attn_mode="flex"`,推理/评测需设 `"torch"` 或 `"flashattn"`,否则 eval 会报错。 |
| RoboTwin 推理 | 提供 server-client 结构;单 GPU RoboTwin evaluation offload 模式约需 24GB VRAM;multi-GPU client 将 50 任务 padding 到 56 并分 7 组适配 8-GPU 设置。 |
| Image-to-video-action 推理 | README 给出 `NGPU=1 CONFIG_NAME='robotwin_i2av' bash script/run_launch_va_server_sync.sh`,offload 模式约需 18GB VRAM。 |
| Post-training | 使用 LeRobot dataset format;训练示例为 `NGPU=8 CONFIG_NAME='robotwin_train' bash script/run_va_posttrain.sh` 与 `CONFIG_NAME='libero_train'`。 |
6.3 复现必须抓住的细节
- 动作统一格式是 30 维双臂表示;换机器人或自定义数据时必须映射到 left/right EEF、joint、gripper,并补零缺失维度。
- 数据准备不只是视频和动作,还要为 LeRobot metadata 增加 `action_config`,指定 `start_frame`、`end_frame` 和 `action_text`。
- 需要用 Wan2.2 VAE 抽取视频 latent,放到 `latents/` 目录,命名要与 `episode_{index}_{start_frame}_{end_frame}.pth` 约定一致。
- 推理与训练的 `attn_mode` 设置不同,这是 README 特别标注的易错点。
- 论文正文没有披露预训练使用的 GPU 数、总训练时长、batch size;README 建议 post-training 用更大 global batch size,如 32 或 64,不足时用 gradient accumulation。
6.4 附录整合说明
附录不是可忽略材料:RoboTwin 50 任务完整表、真实世界 6 个任务的逐 trial 成功/步骤得分、PS/SR 计算定义都在附录。报告已将这些附录信息整合进 5.2 与 5.3,而没有把附录作为独立尾巴处理。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
论文最有价值的部分是把“视频世界模型能否成为机器人控制基础”这件事做成了一个可部署的 causal autoregressive 系统,而不是只展示离线视频生成。具体证据包括:RoboTwin 的长 horizon 分组提升、memory task 的 100% vs 47/50%、以及 naive async 在 Horizon=3 大幅退化但 FDM-grounded async 显著恢复的 ablation。
7.2 结果为什么站得住
结果的支撑链条比较完整:主表显示 RoboTwin 和 LIBERO 的平均指标;真实世界任务用 20 trials、逐步骤评分和交替评测协议;ablation 分别拆开 async grounding、video-action pretraining、action stream initialization;分析实验再从少样本、时序记忆和泛化三个角度补充。也就是说,论文不是只靠一个总分表支撑所有主张。
7.3 作者自述的局限与未来方向
- 计算开销仍高。Conclusion 明确提到未来要开发更高效的视频压缩方案,以降低 computational overhead。
- 感知模态仍以视觉为主。作者提出未来可加入 tactile、force、audio 等多模态传感,提高复杂接触任务鲁棒性。
- partial denoising 是效率折中。论文证明可用于动作预测,但这也意味着部署中不追求完整高保真视频重建。
7.4 报告中的保留意见
- 真实世界 Fold Clothes 的 progress score 上,附录表显示 LingBot-VA 为 48.8%,低于 $\pi_{0.5}$ 的 62.9%;因此“所有任务所有指标都更优”的表述不能逐项成立。
- 预训练数据包含内部采集 demonstrations,外部复现者即使有代码和 checkpoint,也未必能从零复现 1.4T-token 预训练。
- 真实世界评估每任务 20 trials,能展示趋势,但对复杂机器人任务的统计置信区间仍有限;论文没有给出真实世界任务的随机种子或误差条。
- RoboTwin/LIBERO 是强 benchmark 证据,但与开放真实家庭或工厂环境之间仍有 domain gap。