VLA-JEPA: Enhancing Vision-Language-Action Model with Latent World Model
1. Quick overview of the paper
| What should the paper solve? | Internet videos are large-scale but do not have robot action labels; existing latent-action pre-training easily learns pixel differences, camera movements, and background changes, rather than state transfer semantics useful for control. |
|---|---|
| The author's approach | Use leakage-free state prediction: the future frame only passes through the target encoder to generate supervised targets, and the student only looks at the current observation and language; the predicted targets are aligned in the latent space instead of reconstructing pixels. |
| most important results | LIBERO's average success rate is 97.2; LIBERO-Plus is the best in 5 of 7 types of perturbations, with an average of 79.5; SimplerEnv averages 65.2 on Google Robot and 57.3 on WidowX; both real robot ID and object-layout OOD are better than $\pi_0$ and $\pi_{0.5}$. |
| Things to note when reading | The core of this article is not to "add a future prediction head", but to limit the future information to the target, forcing the latent action token to carry the explanatory variables from the current state to the future latent state; at the same time, the action head uses conditional flow matching to generate continuous action trajectories. |
Difficulty rating: ★★★★☆. Need to understand VLA, latent action, JEPA/V-JEPA2, world model, causal attention, conditional flow matching, and robot evaluation such as LIBERO/SimplerEnv.
Keywords: Vision-Language-Action, JEPA, latent world model, latent action, human video pretraining, flow matching, LIBERO, SimplerEnv.
Core contribution list
- Point out the source of mismatch in latent-action pretraining: Pixel targets, real video noise motion, future information leakage, and multi-stage training complexity can cause latent actions to deviate from control semantics.
- Proposed VLA-JEPA: Use latent predictive alignment to learn action-relevant transition semantics, avoid pixel reconstruction and future leakage, and form a simpler pre-training process.
- Verify robustness in simulation and real robots: Covers LIBERO, LIBERO-Plus, SimplerEnv and real Franka desktop operations, and includes human-video ablation, attention map and future horizon analysis.
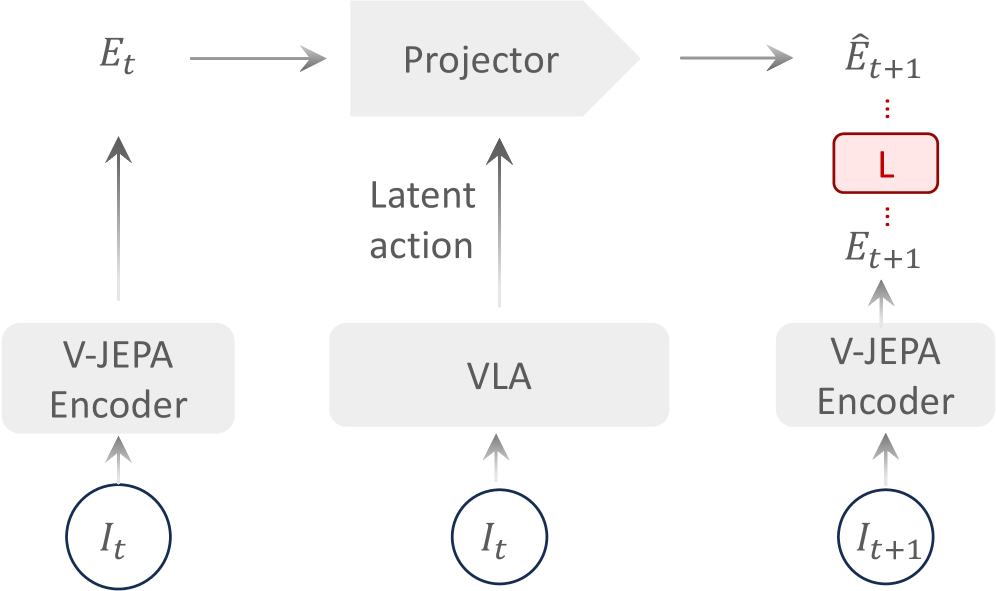
2. Motivation
2.1 What problem should be solved?
VLA models require a large amount of visual, language, and action data, but action-labeled robot data is expensive to collect and has narrow coverage. In comparison, human videos and Internet videos are much larger and contain rich temporal variations. Therefore, many recent works hope to learn latent actions from videos without action tags and then migrate them to robot control.
The paper believes that the problem is that many latent-action objectives learn "compressed representations of visual changes" rather than "how controllable states evolve under interaction." For robots, the value of action does not lie in explaining how each pixel changes, but in explaining the task-related state transitions of objects, hands, tools, robots, etc.
2.2 Four failure modes of existing methods
- Pixel-level objective favors appearance: Future pixel prediction or frame-difference compression is easily dominated by high variance but low control factors such as texture, lighting, background, viewing angle, etc.
- Real-world video amplified noise motion: In human videos and in-the-wild footage, camera motion and non-causal background changes may outweigh state changes caused by interactions.
- Information leakage causes latent action to become shortcut: If the latent action module sees both the current frame and future frames when training, it may encode future images directly instead of learning variables that explain state transitions.
- Multi-stage pipelines are fragile: Multi-stage processes such as representation pre-training, latent-action learning/alignment, and policy learning will introduce engineering complexity and inconsistencies between stages.
2.3 The solution ideas of this article
The principle of VLA-JEPA is to predict the future latent state that reflects the action-relevant transition structure, while prohibiting future information from leaking into the predictor. The advantage of JEPA fits this perfectly: it does not reconstruct pixels, but aligns them at the latent representation level, thus naturally reducing the dominance of low-level noise on the target.
3. Related work context
| Technical line | Representation in the paper | Positioning of VLA-JEPA |
|---|---|---|
| Vision-Language-Action models | RT series, OpenVLA, $\pi_0$, $\pi_{0.5}$, SpatialVLA, CoT-VLA, etc. | These methods have pushed VLA into the mainstream of robot learning, but often rely on large-scale action-labeled robot data; VLA-JEPA attempts to reduce the reliance on explicit action supervision. |
| Multimodal CoT / future prediction | hierarchical planning, subgoal/rollout prediction, object-centric conditioning, latent future embeddings/actions | These methods may still rely on motion data or future reconstruction; VLA-JEPA chooses latent state alignment and does not do pixel reconstruction. |
| Latent action learning | ILPO, LAPO, Genie, LAPA, UniVLA, MotoGPT, villa-X, XR-1, CLAP, VITA, etc. | Previous works often extract discrete/continuous motion tokens from adjacent frames and then map them to real actions; VLA-JEPA focuses on avoiding delta-frame information leakage and pixel shortcuts. |
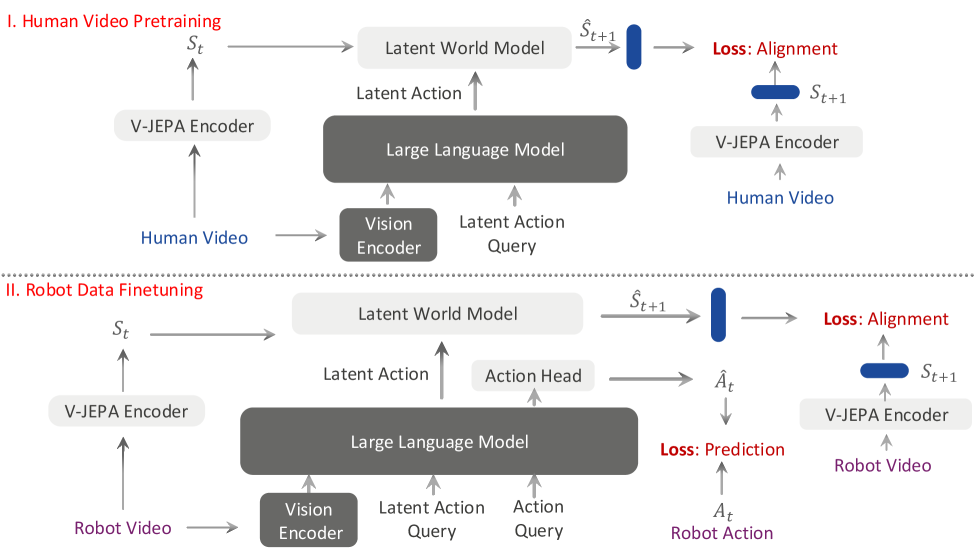
4. Detailed explanation of method
4.1 Overall framework
VLA-JEPA consists of three main parts: Qwen3-VL-2B VLM backbone, V-JEPA2-based latent world model, and conditional flow-matching action head. The pre-training phase learns latent actions from Something-Something-v2 human videos and Droid robot data; the post-training/fine-tuning phase trains downstream controls on LIBERO, SimplerEnv, or real robot data.
The paper states in the text that Qwen3-VL is used as the core VLM, and the visual encoder is SigLIP-2; the appendix clearly implements the use of Qwen3-VL-2B. The world state target comes from the frozen V-JEPA2 encoder, and the predictor is randomly initialized and trained.Appendix Implementation Details
4.2 Model Backbone and latent tokens
In order to allow VLM to output time-aware latent action and embodied action, the author added two types of special tokens to the Qwen3-VL vocabulary: $\langle latent_i \rangle$ and $\langle action \rangle$. Among them, $\langle latent_0 \rangle$ represents the state transition from $s_0$ to $s_1$; $\langle action \rangle$ serves as the condition of the action head on the robot data.
When actually generating latent action tokens, the same $\langle latent_i \rangle$ will be repeated $K$ times to enhance the model's attention to latent action tokens; the appendix gives $K = 24/T$, where $T$ is the future video horizon and 24 is the empirical optimal value.Appendix VLA-JEPA Architecture
4.3 Learn latent world model from human videos
For human videos without action tags, the data is written as $D=\{(O_0, O_1, \dots, O_v, \ell)\}$, $\ell$ is the language description, and $O_v$ is the video frame sequence of the $v$th perspective. The world state encoder first uses V-JEPA2 encoder $F(\cdot)$ for each perspective to obtain a representation, and then splices the multi-view representation into a unified world state:
What this formula does: combine the visual states of different perspectives at the same time into a world-state latent.
$$s_{t_i}=\Vert_v F(I_{v, t_i})$$| $F(\cdot)$ | Single-view video encoder, the paper uses V-JEPA2. |
| $I_{v, t_i}$ | The image frame of the $v$th view at time $t_i$. |
| $\Vert_v$ | Splice representations along the view dimension. |
The student pathway of VLM only inputs multi-view images and language at the initial moment, and does not input future frames. It maps learnable latent tokens into state transition representations:
Here $z_{t_i}$ is the latent representation corresponding to the $i$ latent action token. The key is that there are no future frames on the right, and future frames only appear in the supervision targets generated by the target encoder.
The world model then uses historical world states and corresponding latent action representations to predict future state chunks:
The world model uses time-causal attention: two-way full attention on latent action tokens and image latent tokens within the same time step; strict causality across time steps, and can only look at the present and the past.
4.4 JEPA Objectives and Information Leakage Control
The paper interprets the training target as the ELBO of predictive log-likelihood in semantic space. Since the frozen V-JEPA2 encoder $F(\cdot)$ produces deterministic embeddings, the KL term disappears in practice and the target degrades to latent-space reconstruction/alignment loss.
The original formula of the paper does not write the norm. Combined with the context, it can be understood as aligning the predicted world state and the target world state in the latent space. The report does not assume additional specific distance patterns that are not stated.
This design avoids two common shortcuts: first, it does not allow the model to directly reconstruct pixels, thereby reducing the dominance of background and camera motion; second, it does not feed future frames to the student, so the latent action will not degenerate into future image compression codes.
4.5 Action prediction on robot data
On action-labeled robot data, VLA-JEPA also retains world modeling loss and appends embodied action token. VLM outputs a global action-conditioning representation:
$z_a$ serves as a conditional flow-matching action head condition, constraining action generation together with initial observation, language, and latent action.
The action head uses a DiT-B style Transformer to model the distribution of continuous action trajectories. Given the real action sequence $a_{0: H}$ and Gaussian noise $\epsilon$, define linear interpolation:
The training goal is to let the model predict the velocity field flowing from noise to the real action sequence; during inference, from noise integration to action space, $\hat{a}_{0: H}$ is obtained.
The overall goal on the robot data is:
4.6 Architecture and training hyperparameters
| Latent World Model Configuration | value |
|---|---|
| Transformer Layers | 12 |
| Attention heads | 8 |
| Image token dimension | 2048 |
| Number of image tokens per time step | 256 |
| Action token dimension | 2048 |
| Number of action tokens per time step | 3 |
| Number of views | 2 |
| Future video horizon | 8 |
| Action Head Configuration | value |
|---|---|
| Transformer Layers | 16 |
| Attention heads | 12 |
| Token dimension | 1024 |
| State dimension | 8 |
| Action dimension | 7 |
| Future action horizon | 7 |
| Positional encoding | Learnable |
| Denoising timesteps | 4 |
| training details | Paper/Appendix Information |
|---|---|
| Image size | VLM input resize to 224x224; world-state encoder video clips resize to 256x256. |
| action normalization | Use joint-space delta positions for joint-position control; use delta positions and delta axis-angle for end-effector control; both min-max to [0, 1]; gripper binarized to {0, 1}. |
| Multi-view processing | When there are less than two camera views, copy the world-state representation; when there are more than two views, select two for world-state representation. |
| Training hardware and batch | 8 GPUs parallel, batch size 32, global batch size 256. |
| learning rate | cosine schedule + linear warmup; VLM and latent world model peak LR 1e-5; action head peak LR 1e-4. |
| Number of training steps | SSv2+Droid pre-trains for 50K steps; simulated data continues to train for 30K steps; real data continues to fine-tune for 20K steps. |
5. Experiment
5.1 Experimental setup
The paper uses three types of simulation benchmarks and a real robot environment: LIBERO evaluates simulation in-distribution manipulation; SimplerEnv evaluates real-to-sim gap; LIBERO-Plus evaluates multi-dimensional perturbation robustness; the real robot uses Franka Research 3 desktop pick-and-place. The authors compare the latest VLA baselines, including latent-action VLA, future-prediction VLA and open source VLA.

| data/stage | Usage |
|---|---|
| Something-Something-v2 | 220K human videos; used for action-free human video latent world modeling pretraining. |
| Droid | 76K high-quality demonstration trajectories; used for action-labeled robot data pretraining. |
| LIBERO / LIBERO-Plus | Only the original LIBERO about 2K expert demonstrations are used for fine-tuning, and the LIBERO-Plus augmented dataset is not used. |
| SimplerEnv | Use Fractal and BridgeV2 to correspond to two embodiments of SimplerEnv post-training respectively. |
| Real-world | 100 demonstrations, covering 3 picking-and-placing tasks. |
5.2 LIBERO main results
LIBERO evaluates 50 episodes per task in each task suite, 500 episodes per suite, and reports success rate. VLA-JEPA ranks first in 2 out of 4 suites, with the highest average success rate.
| method | Spatial | Object | Goal | LIBERO-10 | Avg |
|---|---|---|---|---|---|
| LAPA | 73.8 | 74.6 | 58.8 | 55.4 | 65.7 |
| UniVLA | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| $\pi_0$ | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| $\pi_{0.5}$ | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| VLA-JEPA | 96.2 | 99.6 | 97.2 | 95.8 | 97.2 |
| VLA-JEPA w/o human videos | 94.8 | 99.6 | 95.8 | 94.0 | 96.1 |
The author specifically points out that strong baselines such as OpenVLA-OFT and $\pi_{0.5}$ rely on a large number of robot datasets pretraining; VLA-JEPA uses less data to achieve higher averages. Compared with latent-action / human-video methods such as LAPA, UniVLA, villa-X, and CoT-VLA, the results of VLA-JEPA support its judgment of pixel shortcut and leakage problems.
5.3 SimplerEnv results
SimplerEnv contains two sets of visual matching settings for Google Robot and WidowX Robot. VLA-JEPA averages 65.2 on Google Robot, which is the highest among all listed methods; it averages 57.3 on WidowX Robot, which is the same as LAPA.
| method | Google Pick | Google Move | Google Drawer | Google Place | Google Avg | WidowX Spoon | Carrot | Block | Eggplant | WidowX Avg |
|---|---|---|---|---|---|---|---|---|---|---|
| LAPA* | - | - | - | - | - | 70.8 | 45.8 | 54.2 | 58.3 | 57.3 |
| villa-X | 81.7 | 55.4 | 38.4 | 4.2 | 44.9 | 48.3 | 24.2 | 19.2 | 71.7 | 40.8 |
| RoboVLMs | 77.3 | 61.7 | 43.5 | 24.1 | 51.7 | 45.8 | 20.8 | 4.2 | 79.2 | 37.5 |
| $\pi_0$ | 72.7 | 65.3 | 38.3 | - | - | 29.1 | 0 | 16.6 | 62.5 | 40.1 |
| VLA-JEPA | 88.3 | 64.1 | 59.3 | 49.1 | 65.2 | 75.0 | 70.8 | 12.5 | 70.8 | 57.3 |
| VLA-JEPA w/o human videos | 85.3 | 66.7 | 75.5 | 86.1 | 78.4 | 75.0 | 54.2 | 20.8 | 79.2 | 57.3 |
This table also hints at an important boundary: w/o human videos have a higher Google Avg in SimplerEnv. The author explains that in real-to-sim gap and ID scenarios, the impact of high-quality expert demonstrations may be greater than that of human video.
5.4 LIBERO-Plus Robustness
LIBERO-Plus puts the four original LIBERO suites into seven types of disturbances: Camera, Robot, Language, Light, Background, Noise, and Layout. VLA-JEPA ranks first in the five categories of Robot, Language, Light, Background, and Layout, with an average score of 79.5.
| method | Camera | Robot | Language | Light | Background | Noise | Layout | Avg |
|---|---|---|---|---|---|---|---|---|
| UniVLA | 1.8 | 46.2 | 69.6 | 69.0 | 81.0 | 21.2 | 31.9 | 42.9 |
| OpenVLA-OFT | 56.4 | 31.9 | 79.5 | 88.7 | 93.3 | 75.8 | 74.2 | 69.6 |
| $\pi_0$ | 13.8 | 6.0 | 58.8 | 85.0 | 81.4 | 79.0 | 68.9 | 53.6 |
| $\pi_0$-Fast | 65.1 | 21.6 | 61.0 | 73.2 | 73.2 | 74.4 | 68.8 | 61.6 |
| VLA-JEPA | 63.3 | 67.1 | 85.4 | 95.6 | 93.6 | 66.3 | 85.1 | 79.5 |
| VLA-JEPA w/o human videos | 40.3 | 55.7 | 72.9 | 88.2 | 70.5 | 38.2 | 74.6 | 62.9 |
This table is one of the clearest evidences of the value of human video: VLA-JEPA full model has improved from 62.9 w/o human videos to 79.5, especially in Background, Noise, Language, and Layout. The gap is obvious.
5.5 Real Robot Experiment
The real setup uses a Franka Research 3, Robotiq 2F-85 gripper, three Intel RealSense D435 cameras, two in third person view and one in wrist-mounted view. Training expert demonstrations include placing grapes, apples, mangoes, and oranges from the table into a plate or bowl. Each task was performed 10 independent trials and the average success rate is reported.Appendix Real-world Experiments Details
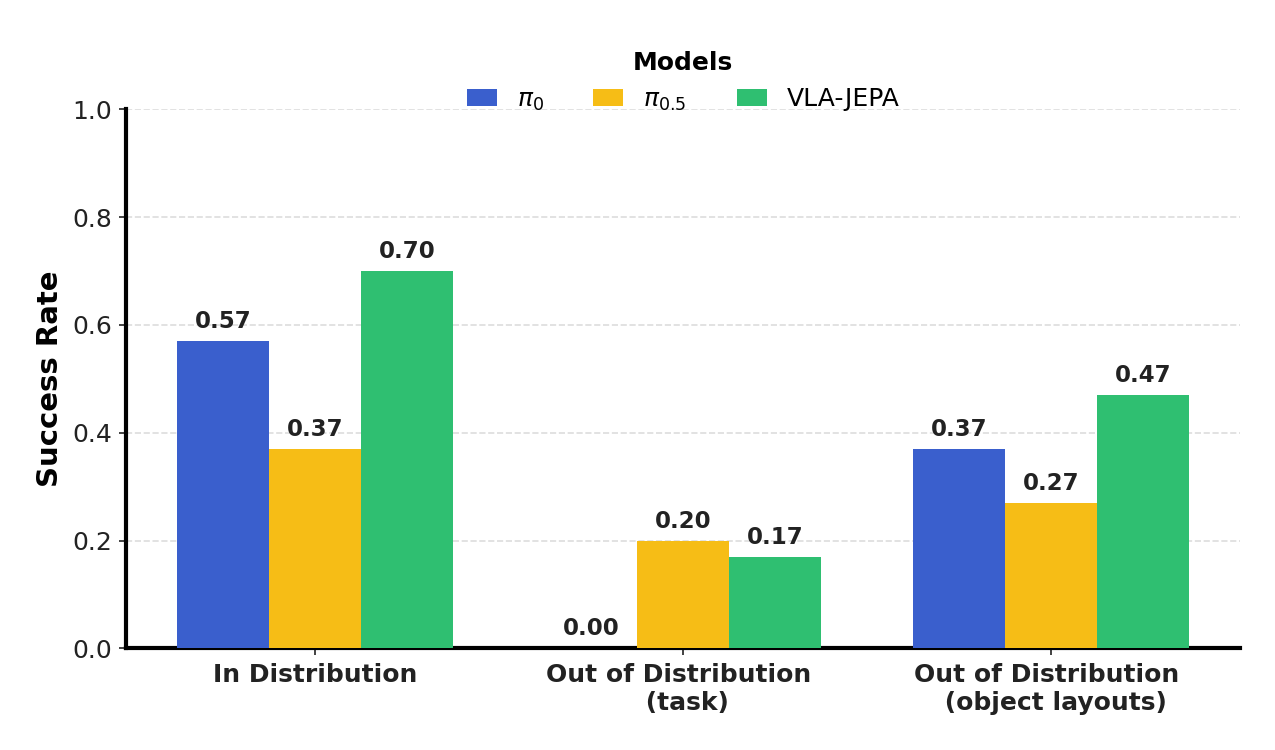
task-level OOD includes: putting bananas in a bowl, peaches on a plate, and grapes on the top shelf. The author observed that: in the banana task, $\pi_{0.5}$ and VLA-JEPA were about 50% successful; in the peach task, the robot often violated the safety boundary due to its irregular shape; in the shelf task, no model successfully placed the end on the top floor, but VLA-JEPA would approach and lift the end from the back of the shelf, while $\pi_0$ and $\pi_{0.5}$ directly collided with the shelf.
In layout OOD, $\pi_0$ and $\pi_{0.5}$ will not reopen the gripper and try again after failing to capture; VLA-JEPA will immediately open the gripper and try again. The author attributes this to the large number of repeated grasping behaviors in human videos.Appendix Real-world Experiments Details

5.6 Further analysis and ablation
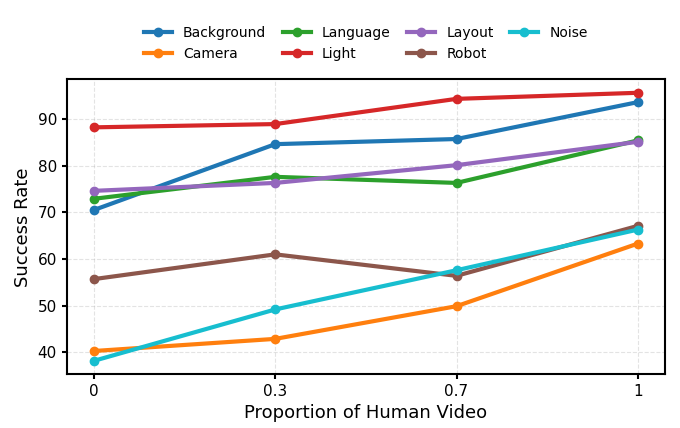
The impact of human video
The analysis of the paper is very restrained: human videos may not necessarily bring significant improvement on LIBERO and SimplerEnv, and even w/o human videos are stronger in some settings of SimplerEnv; but in perturbation robustness scenarios such as LIBERO-Plus, human videos significantly improve stability. The author believes that human videos mainly enhance the robustness/stability of existing skills rather than directly introducing new action execution capabilities.
The impact of Unified pretraining
The author visualizes the attention from latent action token to image token of LAPA, UniVLA, and VLA-JEPA. Paper explanation: LAPA focuses on overly dense visual information and irrelevant desktop objects, which may come from information leakage; UniVLA uses textual semantics to alleviate but will focus on irrelevant semantic backgrounds such as stationary pens and tablecloth textures; VLA-JEPA focuses more on robotic arm, hand and manipulated objects.

Future video horizon
| $T$ | Spatial | Object | Goal | LIBERO-10 | Avg |
|---|---|---|---|---|---|
| 4 | 95.0 | 99.2 | 95.8 | 89.0 | 94.8 |
| 8 | 94.8 | 99.8 | 95.8 | 94.0 | 96.1 |
| 16 | 92.8 | 98.8 | 98.0 | 92.2 | 95.5 |
The author hopes that latent action captures the dynamics between adjacent frames, and the number of latent action tokens is always equal to the number of frames minus one. $T=8$ is the best on average, and the paper explains that it is close to the predefined action horizon; $T$ is too small and lacks information, and $T$ is too large to introduce redundancy.
6. Reproducible auditing
Code and models
There is official code and model entrance: GitHub README shows that partial training code, LIBERO/LIBERO-Plus/SimplerEnv evaluation code, and custom dataset training code have been released; Hugging Face provides checkpoints. README also lists Qwen3-VL-2B, V-JEPA2 encoder, SSv2, Droid, LIBERO, BridgeV2, Fractal and other dependent resources.
| Recurring items | Information given | Status |
|---|---|---|
| Model structure | Qwen3-VL-2B; V-JEPA2 encoder; latent world model and action head configuration tables are complete. | fully |
| Training hyperparameters | Image size, batch, number of GPUs, learning rate, schedule, number of training steps, action normalization, and multi-view processing are all given in the appendix. | relatively sufficient |
| data | SSv2, Droid, LIBERO, BridgeV2, and Fractal provide download links in the README; there is no public complete data description for the 100 demos of real robots. | The simulation is sufficient, but the real experiments are limited. |
| Review | README gives LIBERO, LIBERO-Plus, SimplerEnv environment preparation, checkpoint configuration and eval script. | fully |
| Hardware | The paper training uses 8 NVIDIA A100 GPUs; README description LIBERO 4 GPUs parallel, LIBERO-Plus/SimplerEnv 8 GPUs parallel, can be modified according to the number of GPUs. | higher cost |
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Based on the paper's own evidence, the most valuable point is to change the learning goal of the latent action from "explaining pixel differences" to "explaining the future latent state under no leakage conditions". This makes the role of human-video pretraining closer to "improving the robustness and temporal stability of existing skills" rather than mistaking human videos for directly executable robot action supervision. Repeated grasping observations of LIBERO-Plus and real robots are the most direct support for this point.
7.2 Why the results hold up
The paper does not just report an average value, but tests on four types of settings: LIBERO, SimplerEnv, LIBERO-Plus and real robots, and disassembles human videos, future horizon, and attention map. In particular, the gap between full model and w/o human videos in LIBERO-Plus, and the fact that w/o human videos in SimplerEnv are better, together illustrate that the author does not generalize human videos to universal gain, but positions the gain boundary at robustness/stability.
7.3 Failure phenomena clearly written in the paper
- In real task OOD, the generalization of VLA-JEPA is not as robust as $\pi_{0.5}$; it lacks fine-grained textual instruction reasoning and may grab objects that do not match the instructions.
- $\pi_{0.5}$ contacts the target object more accurately, but position control often violates the safety boundary of the robot and causes failure; VLA-JEPA rarely triggers the safety boundary.
- In the shelf task, all models failed to successfully place the end on the top layer; VLA-JEPA only showed different approach behaviors and did not complete the task.
- Human video does not necessarily bring benefits to ID and real-to-sim gap scenarios; high-quality expert demonstrations may be more critical in these scenarios.
7.4 Applicable boundaries
- VLA-JEPA is suitable for manipulation settings that elicit useful latent dynamics from visual timing; it has not been shown to be effective for all fine-force control, long-range planning, or high-verbal reasoning tasks.
- The method relies on strong VLM, V-JEPA2 encoder, A100-level training resources and multiple large data sets; the cost of completely reproducing the experiment from scratch is high.
- Real robots only cover 100 demonstrations and a small number of desktop tasks; the paper mainly uses real results as evidence of physical deployment, rather than large-scale real-world generalization proof.