Say, Dream, and Act: Learning Video World Models for Instruction-Driven Robot Manipulation
1. Quick overview of the paper
| What should the paper solve? | Solve the problem of "language can clearly explain the goal, but the strategy is difficult to predict the evolution of the environment" in the operation of command-driven robots. The VLM/VLA model can understand task semantics, but it does not naturally have the ability to stably predict future objects, grippers, and spatial relationships; existing world models often have problems such as short field of view, slow generation, spatial inconsistency, and difficulty in receiving low-level actions. |
|---|---|
| The author's approach | The starting point is to adapt the general video generation model to the robot world model and let it serve the action model. Specifically, it includes: selecting Cosmos-Predict2 that is more suitable for robot scenarios; using domain adaptation and latent adversarial distillation for fast video generation in few steps; compressing arbitrarily long trajectories into fixed key frames; training in-context conditioned action model to use generated videos as examples rather than hard constraints. |
| most important results | On LIBERO, Dream4manip used a 1.22B scale model to achieve a total success rate of 98.1% reported in the table, exceeding baselines such as OpenVLA-OFT, UniVLA, pi0, GR00t N1, DreamVLA, etc.; after world model adaptation, FVD dropped from the original 571.46 of Cosmos-2B to 211.84, and DA+Dis improved in SSIM, PSNR, and LPIPS. This further improves and supports reasoning with fewer denoising steps. |
| Things to note when reading | Don't just read it as "video generation plus robot control". The key is three interface designs: first, the generation model is filtered with spatial consistency indicators; second, the video is compressed into key frames to avoid strict alignment of action steps and video frames; third, the action model looks at the generated future and real historical observations at the same time, and uses real observations to correct the generation errors. Therefore, whether the results are credible depends on the quality of the world model, the conditional method from video to action, and whether the closed-loop execution can truly alleviate the generation error. |
Contribution in one sentence
The author proposes a robot operation framework composed of a video world model and an in-context action model, which allows the strategy to "dream" the future state before execution, and then use the future state as the context to convert it into actions.
method keywords
Video World Model Cosmos-Predict2 Latent Adversarial Distillation Length-Agnostic Keyframes In-Context Action Model
2. Research questions and motivations
2.1 Why robots need "future imagination"
The difficulty of command-driven operations is not just parsing language into targets, but inferring "if I move like this, how will the object, gripper, and target area change" in complex scenarios. Traditional VLA or VLM-based policy tends to map images and language directly to actions, but lacks explicit future state prediction and is prone to errors in spatial relationships, object references, and long task combinations.
The intuition of the world model is to predict the future as an intermediate variable: if the model can generate the future visual state during task completion, the action policy does not have to guess the action based on the current image alone, but can refer to an "expected trajectory". This paper attempts to demonstrate that high-quality video generation models, adapted to the robotics domain, can become future contexts that low-level strategies can exploit.
2.2 Gaps in the existing video world model
There are three main categories of gaps identified by the authors. First, many robot world models can only predict a short horizon or a small number of frames, making it difficult to express the complete task progress. Second, although general video generation models have high visual quality, they are prone to inconsistencies in robot embodiment, gripper morphology, camera perspective, and object interaction. Third, the video generation diffusion model is slow to infer and is not suitable for closed-loop robot control.
Therefore, the technical route of this article is not to train a small world model from scratch, but to select a more usable base for robot scenes from a large-scale video model, then use domain adaptation and distillation to make it faster and more stable, and limit the generation error within a controllable range through the conditional design of the action model.
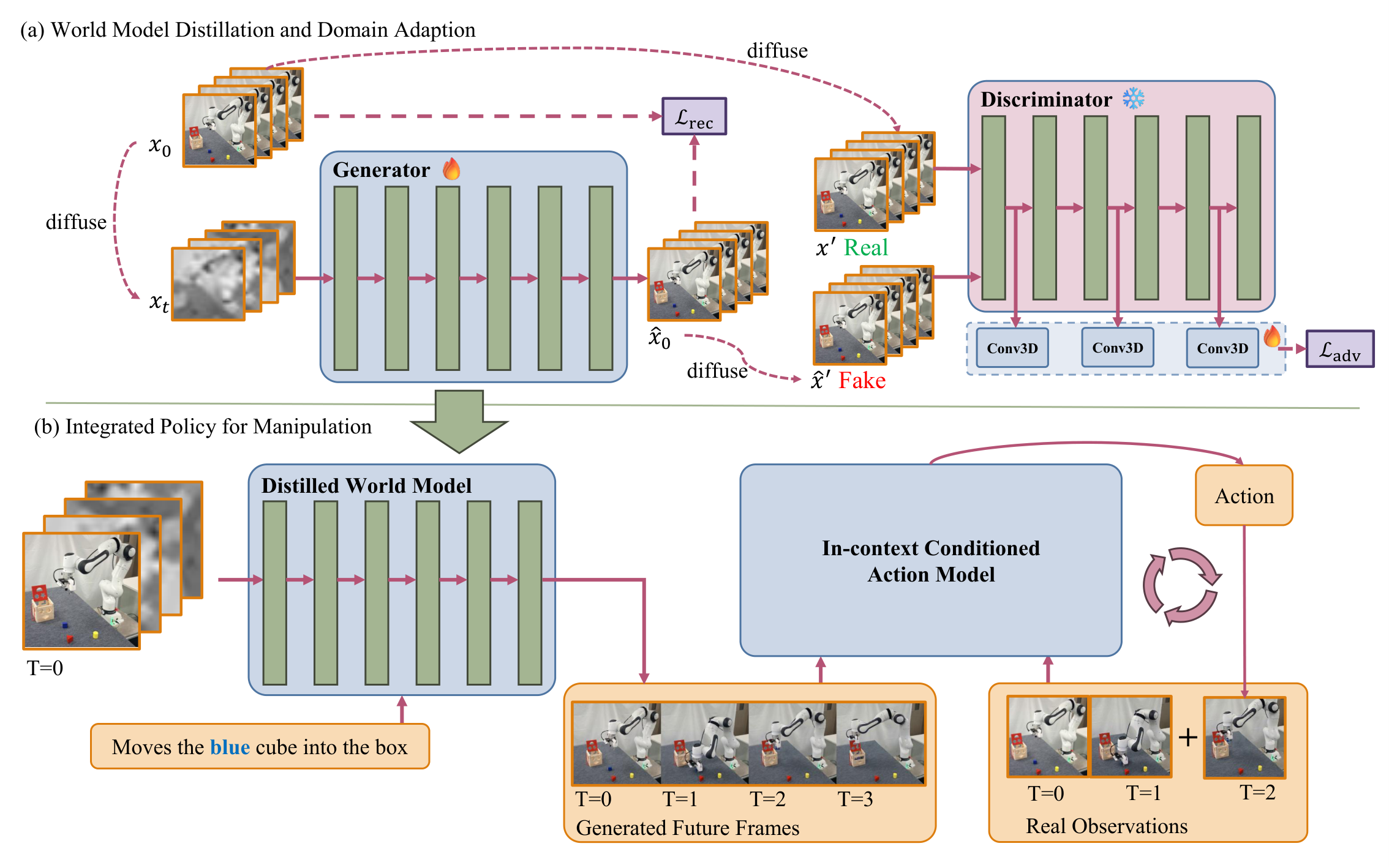
4. Detailed explanation of method
4.1 Overall Framework: Say, Dream, and Act
The structure of Dream4manip can be broken down into three stages:
- Say: World Model. Generate task-relevant future videos based on verbal instructions and current observations. The key here is to choose a more stable base on the robot video and do domain adaptation and distillation.
- Dream: Length-Agnostic World Imagination. Compress any long demonstration track into a fixed number of key frames, so that the video imagination does not need to be aligned with the action execution steps one by one.
- Act: In-Context Conditioned Action Model. The generated future frames are used as context examples, and the action blocks are output based on real historical observations. The responsibility of this action model is to transfer the "imagined state trajectory" to the actual robot action.
4.2 Say: Select and adapt world model
The author first compares multiple image-to-video models. The focus is not on general visual aesthetics, but on the four more critical capabilities in robot operation: emodiment consistency, referring success, interaction success and task completion. Based on these indicators, the paper selects Cosmos-Predict2 as the basic model, especially emphasizing that Cosmos-2B is stable in reference and interaction, and its computational cost is lower than the 14B model.
In the adaptation phase, the diffusion transformer \(T_\theta\) of Cosmos-Predict2 receives the noisy latent \(x_t\) and the conditional \(cond\), and outputs the denoised latent \(\hat{x}_0\). The image-to-video condition is injected into \(x_t^{cond}\) by replacing the first frame with clean latent. The form of denoising used in paper writing is:
The noise schedule used by few-step distillation is:
The default value in the experiment is \(T_g=8\). The function of this formula is to compress the original multi-step denoising trajectory into a small number of generation steps, so that the world model can be closer to the closed-loop control requirements.
4.3 Latent adversarial distillation
The distillation of the paper is not simply to perform regression on pixels, but to introduce adversarial learning in the latent space. The discriminator \(D\) is initialized by the pretrained DiT weights of Cosmos-Predict2, and is connected to the intermediate features with lightweight 3D convolution heads to output a pixel-wise score map. Freezing the DiT backbone during training and optimizing only the convolution head is equivalent to reusing the existing video prior of the base model to determine whether the generated latent resembles the real latent.
The goal of the discriminator is to judge the clean latent \(x_0\) as positive and the \(\hat{x}_0\) obtained by denoising the generator as negative. In order to avoid the discriminator only seeing artifacts that are too easy, the paper adds additional noise before inputting the discriminator: let \(\log(\sigma') \sim \mathcal{N}(0, 1)\), diffuse \(x_0\) and \(\hat{x}_0\) into \(x'\) and \(\hat{x}'\). The discriminator and generator losses are:
While retaining reconstruction loss:
Default \(\lambda=0.1\). The paper highlights that reconstruction loss is also used for domain adaptation in the same training iteration, where \(\log(\sigma)\sim\mathcal{N}(0, 1)\). This means that domain adaptation and few-step distillation are not two completely separate training objectives, but jointly constrain video quality and domain matching in the same generator update.
4.4 Dream: Keyframe imagination for trajectories of arbitrary length
The length of the robot demonstration trajectory will vary with the task and execution strategy. If video frames and action steps are required to be strictly aligned, the world model can easily be dragged down by different task lengths. This article uses a simple but critical compression function \(S(\tau)\) to compress the trajectory \(\tau\) into a fixed number of key frames:
\(n=93\) was used in the experiment. The significance of this step is to let the world model learn a "visual summary of task progress" rather than the precise frames of each step under a fixed control frequency. For the action model, the generated video is more like a future example that can be referenced rather than a trajectory that must be followed frame by frame.
4.5 Act: In-context conditioned action model
The core design of the Action model is to use the generated video as an in-context example. The input includes language instructions, generated future key frames and real historical observations, and the action chunk corresponding to each observation is output. This has two benefits: first, the generated video provides high-level task progress and goal status; second, real historical observations retain the actual robot and scene geometry, which is used to correct the spatial error of the world model.
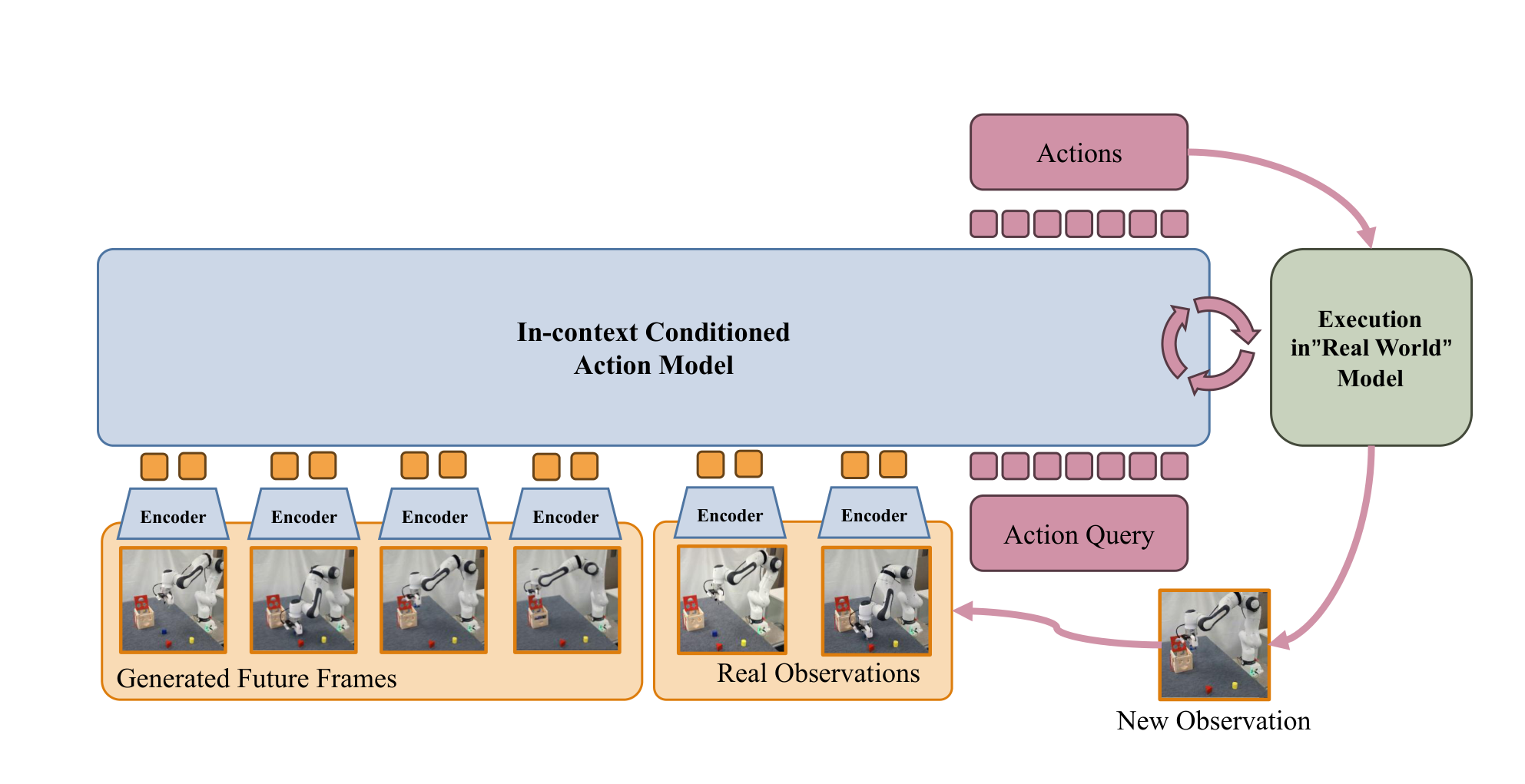
From the perspective of the group meeting, this design is the interface that needs to be explained most clearly in this article: the world model does not directly output actions, nor does it require future videos to be completely real; it gives the visual context of "where the task should go", and the action model then generates actions in a closed loop based on real observations.
5. Experiments and results
5.1 Experimental setup
Simulation experiments are mainly conducted on the LIBERO benchmark, covering four types of tasks: Spatial, Object, Goal, and Long. The paper describes that each task suite has about 500 training samples, and uses 10 test subtask samples for each suite during testing, each executed 50 times, that is, 500 test runs per suite. The real robot experiment uses Franka 7-DoF robotic arm, Intel RealSense D435 third-view camera, and collects teleoperation data through 3Dconnexion SpaceMouse.
[Appendix] The appendix gives detailed definitions of spatial referring indicators, which are important for understanding world model screening: EC looks at whether the embodiment is consistent in all frames; RSR looks at whether the generated robot moves more than half the distance toward the correct color object; ISR looks at whether the correct target is successfully grasped, and excludes non-contact movement, failure to approach the target or serious distortion of the gripper; TCR/TSR looks at whether the target object is finally placed correctly into the wooden box.
5.2 World model quality
The author first evaluates the adapted Cosmos-2B world model on different LIBERO tasks. Indicators cover FVD, SSIM, PSNR, and LPIPS, which measure video distribution, structural similarity, pixel reconstruction quality, and perceptual difference respectively.
| Task | FVD ↓ | SSIM ↑ | PSNR ↑ | LPIPS ↓ |
|---|---|---|---|---|
| L-10 | 104.00 | 0.82 ± 0.10 | 21.44 ± 6.97 | 0.06 ± 0.05 |
| L-Object | 177.04 | 0.89 ± 0.05 | 25.30 ± 5.47 | 0.04 ± 0.03 |
| L-Spatial | 119.32 | 0.85 ± 0.09 | 25.16 ± 6.14 | 0.03 ± 0.03 |
| L-Goal | 127.86 | 0.88 ± 0.07 | 26.12 ± 6.06 | 0.03 ± 0.02 |
More critical is the comparison with other video models and training variants:
| model | FVD ↓ | SSIM ↑ | PSNR ↑ | LPIPS ↓ |
|---|---|---|---|---|
| WAN2.2-14B | 714.24 | 0.63 ± 0.15 | 21.49 ± 3.98 | 0.11 ± 0.05 |
| WAN2.2-14B-Dis | 578.62 | 0.62 ± 0.18 | 21.58 ± 4.46 | 0.09 ± 0.06 |
| C-2B | 571.46 | 0.70 ± 0.10 | 22.09 ± 5.78 | 0.11 ± 0.05 |
| C-14B | 522.66 | 0.67 ± 0.11 | 21.56 ± 5.95 | 0.12 ± 0.05 |
| C-14B-Droid-F.T. | 1098.24 | 0.23 ± 0.04 | 14.73 ± 0.67 | 0.26 ± 0.05 |
| C-2B-DA | 211.84 | 0.82 ± 0.09 | 25.19 ± 5.48 | 0.05 ± 0.03 |
| C-2B-DA+Dis | 238.09 | 0.84 ± 0.11 | 26.82 ± 6.18 | 0.04 ± 0.04 |
One detail should be noted here: the FVD of DA+Dis is slightly higher than that of DA, but SSIM, PSNR, and LPIPS are better, and it supports less-step reasoning. The authors therefore view DA+Dis as a more practical compromise between quality and speed.

5.3 Spatial reference capability screening
The paper uses percentage indicators such as EC, RSR, ISR, TSR/TCR to compare image-to-video models. The purpose of this experiment is not to evaluate the final robot success rate, but to illustrate why the Cosmos series was chosen, especially why it is not simply assumed that large models or DROID fine-tuning are necessarily better.
| model | EC ↑ | RSR ↑ | ISR ↑ | TSR/TCR ↑ |
|---|---|---|---|---|
| Cosmos-2B | 1.58 | 96.00 | 86.00 | 70.00 |
| Cosmos-14B | 1.62 | 90.00 | 82.00 | 76.00 |
| Cosmos-14B-Droid | 1.58 | 78.00 | 58.00 | 34.00 |
| Wan-14B | 1.56 | 54.00 | 44.00 | 20.00 |
[Appendix] The paper also adds the OOD spatial referring test of the selected world model, but this part of the appendix has less details. It is mainly used to supplement the explanation that the world model has additional tests on color/spatial referencing, rather than as the main conclusion pillar.
5.4 LIBERO closed-loop strategy results
The final evaluation looks at the task success rate of Dream4manip as policy. In the table, Dream4manip uses 1.22B scale and achieves a high success rate on all four LIBERO suites.
| method | Parameter scale | Spatial | Object | Goal | Long | Total |
|---|---|---|---|---|---|---|
| OpenVLA | 7B | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| OpenVLA-OFT | 7B | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| CoT-VLA | 7B | 87.5 | 91.6 | 87.6 | 69.0 | 81.1 |
| UniVLA | 7B | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| WorldVLA | 7B | 87.6 | 85.2 | 75.1 | 54.1 | 74.8 |
| 4D-VLA | 4B | 88.9 | 95.2 | 90.9 | 79.1 | 88.6 |
| SpatialVLA | 4B | 88.2 | 95.2 | 90.9 | 79.1 | 88.6 |
| pi0 | 3B | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| pi0-FAST | 3B | 96.4 | 96.8 | 88.6 | 60.2 | 85.5 |
| SmolVLA | 2.25B | 93.0 | 94.0 | 91.0 | 77.0 | 88.8 |
| GR00t N1 | 2B | 94.4 | 97.6 | 93.0 | 90.6 | 93.9 |
| DreamVLA | 0.57B | 97.5 | 94.0 | 89.5 | 89.5 | 92.6 |
| Dream4manip | 1.22B | 99.4 | 99.2 | 98.2 | 95.4 | 98.1 |
You can use this table as the main result in the group meeting: The advantage of Dream4manip does not come from the maximum parameter size, but from the closed-loop conditionalization of the future context of the world model and the action model. In particular, the success rate of 95.4 in the Long task shows that "future imagination" does not just provide visual decoration for long tasks, but may actually help model task progress.

5.5 Denoising steps
The authors also studied the speed and quality of Cosmos-Predict2 2B at different denoising steps. The core conclusion is that 10 steps has reached a relatively reasonable quality-speed trade-off, and continuing to increase to 20 or 35 steps results in limited quality improvement but a significant increase in time.
| D | Time ↓ | FVD ↓ | SSIM ↑ | PSNR ↑ | LPIPS ↓ |
|---|---|---|---|---|---|
| 1 | 10.72s | 1128.10 | 0.54 ± 0.14 | 17.89 ± 6.95 | 0.20 ± 0.07 |
| 5 | 19.43s | 1445.19 | -0.02 ± 0.29 | 12.43 ± 8.43 | 0.30 ± 0.10 |
| 10 | 29.80s | 579.90 | 0.70 ± 0.09 | 22.10 ± 5.78 | 0.11 ± 0.05 |
| 20 | 52.59s | 496.06 | 0.72 ± 0.09 | 22.48 ± 5.67 | 0.10 ± 0.04 |
| 35 | 86.20s | 488.06 | 0.72 ± 0.09 | 22.39 ± 5.70 | 0.10 ± 0.04 |
A point worth asking is: the generation time of 10 steps in the table is still close to 30 seconds, which is not low enough for real high-frequency closed-loop control. Therefore, "fast" in this article is mainly relative to the number of original diffusion generation steps, rather than fully satisfying real-time robot control.
6. reproducibility Key Points
6.1 Data and evaluation
- Simulation data: LIBERO four types of suites, including Spatial, Object, Goal, and Long. The training sample size is approximately 500 per suite as described in the paper, and the test is executed 500 times per suite.
- Real robot: Franka 7-DoF, RealSense D435 third-person perspective, SpaceMouse teleoperation acquisition.
- World model filter: Use EC, RSR, ISR, TSR/TCR, and not just look at general video indicators such as FVD/SSIM.
- Policy evaluation: The key is the closed-loop execution success rate, not offline action prediction loss.
6.2 World model training configuration
The implementation of the paper is based on Cosmos-Predict2, the optimizer is FusedAdamW, the learning rate is \(2^{-14.5}\), \(\lambda\) uses linear scheduler, warm-up is 0, single-cycle length is 1000, \(f_{\max}=0.6\), \(f_{\min}=0\), uses FSDP, context parallel size 2, and enables EMA. The world model is trained on LIBERO for 10, 000 iterations and on real-world data for 1, 000 iterations.
6.3 Action model training configuration
The Action model initializes VLM to Qwen2.5, LoRA rank to 64, uses 8 GPUs, and has a total batch size of 128. During training, future video predictions are used as context, and 8 frames of historical video are uniformly sampled as conditioning. The learning rate is \(2\times 10^{-4}\), and the training is 20, 000 steps.
6.4 Recurrence risk list
- Cosmos-Predict2 base dependencies: reproducibility requires access to equivalent base models and video VAE/DiT implementations, otherwise the world model quality will not be comparable.
- Indicator labeling cost: EC, RSR, ISR, TSR/TCR are not simple script indicators, especially the success of referring and interaction may require manual or additional decision rules.
- Closed loop execution details: The length of the action chunk, the observation history window, and the frequency of regenerating future frames will all affect the final success rate. The main text of the paper only gives the main training configuration.
- Generate video error propagation: The spatial misalignment of the world model may be partially corrected by the action model, but if the generated target state is completely wrong, the policy will still be misled.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
The most valuable part is not a single module, but a relatively complete interface design when connecting the video generation model to robot action learning. The author does not directly let the video world model output control, nor does it assume that the generated video is perfect frame by frame, but uses it as an in-context future example to input the action model together with real historical observations. This makes the world model responsible for "giving a visual prior to the progress of the task" and the action model responsible for "executing and correcting deviations in real scenes."
The second value point is that the evaluation standards are closer to the robot operation needs. The paper does not only use FVD, SSIM, PSNR, and LPIPS to judge the world model, but additionally defines embodiment consistency, referring success, interaction success, and task completion. This makes the question of "what kind of video generation model is suitable for robots" more concrete.
7.2 Why the results hold up
The results are relatively tenable for three reasons. First, the author first uses robot-related indicators to screen the world model, and then uses general video quality indicators to verify the benefits of domain adaptation and distillation to avoid convincing readers with only visual subjective images. Second, the policy results are compared with a large number of VLA/VLM baselines on four LIBERO suites, and the parameter scale of Dream4manip is not the largest, indicating that the improvement cannot be easily attributed to the larger model. Third, the paper provides ablation and qualitative failure comparisons of denoising steps, which can support the argument that "adaptation and distillation affect the quality/speed trade-off".
However, "standing" does not mean that there are no gaps. The strongest evidence comes from LIBERO. The real robot results are more setting instructions and qualitative support in the source code text; if you want to prove the generalization to more embodiments, multiple cameras and complex dynamic environments, larger-scale real-world closed-loop evaluations are needed.
7.3 Method Boundaries
- Speed boundary: Even after distillation, the 10-step generation still takes about 29.80 seconds. For high-frequency real-time control, this is more like a low-frequency planning or periodic replanning module, rather than a model that runs every control tick.
- Long horizon boundary: Keyframe compression reduces length alignment pressure, but the world model's future predictions may still accumulate errors in dynamic, occluded, or crowded scenes.
- Generate dependency boundaries: The action model can correct spatial errors using real observations, but if the world model generates wrong targets, wrong object interactions, or wrong final states, the policy will inherit this misdirection.
- embodiment generalization boundary: The authors acknowledge that scaling to diverse embodiments and complex multi-step tasks requires more extensive pre-training and stronger embodiment-conditioned representations.
7.4 How it can be improved
A natural direction is to turn the future imagination of the world model into a multi-candidate distribution instead of a single video: the action model can make selections or weights based on multiple possible futures, reducing the impact of a single generation error. Another direction is to add online consistency check, such as using real observations and generated key frames to estimate the deviation. When the deviation is too large, trigger regeneration or switch to a conservative strategy.
From a system perspective, a more lightweight local world model can also be studied: global task progress is generated by a large video model at low frequency, and local contact and gripper control are predicted by a small model at high frequency. This may be more consistent with the speed constraints of real robot control.
8. Preparation for group meeting Q&A
Q1: What is the biggest difference between this paper and ordinary VLA?
Most ordinary VLA predicts actions directly from the current visual language input; this article explicitly adds the video world model, first generates future task progress, and then lets the action model use future frames and real historical observations as contextual output actions. The difference lies in the introduction of visual future state intermediate variables.
Q2: Why not just generate a video and do the planning directly?
Because the generated video is not an action sequence, it is not guaranteed to be geometrically accurate. The paper treats generated videos as in-context examples rather than trajectory constraints. The action model actually outputs the action. It also looks at the real observations, so it can correct some generation errors.
Q3: Cosmos-14B is larger, why choose Cosmos-2B for the main line?
From the screening table, Cosmos-14B is slightly better on EC and TSR/TCR, but Cosmos-2B is the best on RSR and ISR, and has lower computational cost. For closed-loop robotic systems, referring, interaction, and inference costs are critical, so 2B is a more practical base choice.
Q4: Why is DA+Dis used when FVD is not the best?
DA has the lowest FVD, but DA+Dis is better on SSIM, PSNR, LPIPS, and serves fast generation with few steps. FVD measures distribution distance and is not necessarily equivalent to robot executability; this article is concerned with the trade-off between quality, speed, and spatial consistency.
Q5: What is the most questionable experimental point?
Mainly real world generalization and latency. LIBERO's success rate is very strong, but real robots, different embodiments, complex occlusions and long horizon dynamic scenes still require more complete closed-loop evaluation; at the same time, the 10-step video generation time is still long, and how to schedule the world model in the real-time system is a key engineering issue.