FRAPPE: Infusing World Modeling into Generalist Policies via Multiple Future Representation Alignment
1. Quick overview of the paper
| Reading targeting item | content |
|---|---|
| What should the paper solve? | Explicit world models need to predict future pixels, so it is easy to focus too much on pixel-level reconstruction, and relying on predicting future observations during inference will accumulate errors; a single latent alignment may be limited by the inductive bias of a single vision task. |
| The author's approach | Use learnable future prefix to align VFM embedding of future observations; mid-training uses Theia-style distilled encoder single-stream full parameter adaptation, post-training uses Mixture-of-Prefix-and-LoRA to align multiple VFMs in parallel, and then the router aggregates actions. |
| most important results | The eight-task average of RoboTwin 2.0: Easy 57.5%, Hard 25.5%, both are the highest; unseen settings perform well in the real-arm AgileX task, the long-range three-stage task RDT is 0%, and FRAPPE is 20%. |
| Things to note when reading | FRAPPE is similar to FLARE but emphasizes multiple future representation alignment and parallel progressive expansion; it uses multiple teacher VFMs during training and no longer calls these VFMs during inference, but retains the parallel expert calculation graph. |
difficulty rating
4/5. Need to understand diffusion/DiT policy, RDT, LoRA, MoE/router, future representation alignment, visual foundation model teacher, and mixed training of robot data and human egocentric data.
keywords
VLA; RDT; Implicit World Modeling; Future Representation Alignment; Prefix Tuning; LoRA; Mixture of Experts; Human Egocentric Videos; RoboTwin
Core contribution list
- Multiple future representation alignment. Instead of just aligning one future visual representation, three VFM representations of CLIP, DINOv2, and ViT are aligned in parallel in post-training to reduce the inductive bias of a single representation.
- Parallel progressive expansion. First use mid-training to adapt the model to the world-modeling goal, and then use Prefix+LoRA to expand in parallel with multiple experts to avoid slow convergence and poor performance in direct parallel training.
- Parameter efficient post-training.The frozen RDT backbone is shared, each expert has its own future prefix and LoRA, and the actions are aggregated by the router.
- Motionless human video available.Omit action loss for action-free samples and only optimize future representation alignment loss so that human egocentric data can participate in training.
- Simulation and real verification.Covers RoboTwin Easy/Hard, RDT-1B and RDT-130M, small data training, real two-arm mobile robotic arm and long-range missions.
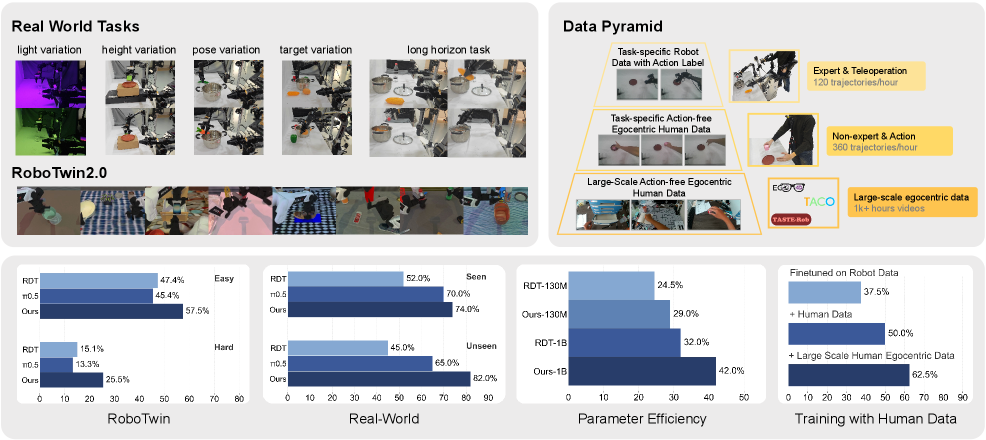
2. Motivation
2.1 What problem should be solved?
VLA and diffusion policy can already learn multi-modal action distribution, but robots still need to understand the dynamics of the environment when performing complex tasks, that is, world modeling. Existing methods often specify world modeling as "predicting future images", and then use this prediction for action generation or auxiliary training.
The paper points out that there are two problems with this approach: first, future pixel prediction spends a lot of calculations on redundant texture and background details instead of task-related object information; second, the inference stage relies on future observations generated by the model, and prediction errors will accumulate along time, affecting actions.
2.2 Limitations of existing methods
Explicit future image methods, such as models that jointly generate future frames/actions, may produce poor image quality in OOD scenarios. Implicit alignment methods, such as FLARE/VPP/representation alignment, avoid explicit generation, but if they only align a single visual representation, they may inherit the bias of the visual task and may not be suitable for all robot tasks.
The core motivation of FRAPPE is that world modeling does not have to predict the image itself, nor should it be limited to a single representation; the model can be aligned to future representations of multiple visual base models at the same time, and gain scaling benefits through multi-stream parallel computing during inference.
2.3 The solution ideas of this article
FRAPPE uses a two-stage recipe:
- Mid-training: Single-stream, full-parameter fine-tuning, adding future prefix, aligning a Theia-style tiny teacher encoder obtained by multi-VFM distillation, so that RDT can adapt to the world-modeling goal.
- Post-training: Freeze the shared backbone and only train multiple future prefixes and corresponding LoRA; each expert is aligned with an independent teacher encoder, and finally the router aggregates the expert output to generate actions.
4. Detailed explanation of method
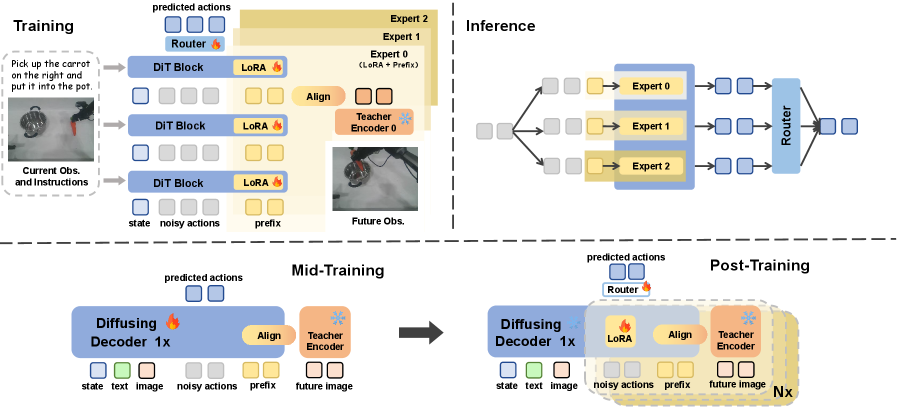
4.1 Preliminaries: RDT
RDT modeling conditional action sequence distribution $p_\theta(\mathbf{a}_t|\mathbf{o}_t, l)$. Given language $l$, observation $\mathbf{o}_t$, noisy action $\tilde{\mathbf{a}}_t$, and diffusion timestep $k$, DiT denoising network $f_\theta$ predicts clean action chunk.
The original goal of RDT: denoise noisy action chunks into real action chunks.
$$\mathcal{L}_{action}=\mathrm{MSE}\left(\mathbf{a}_t, f_\theta(l, \mathbf{o}_t, \tilde{\mathbf{a}}_t, k)\right)$$ $$\tilde{\mathbf{a}}_t=\sqrt{\bar{\alpha}_k}\mathbf{a}_t+\sqrt{1-\bar{\alpha}_k}\epsilon, \quad \epsilon\sim\mathcal{N}(0, I)$$| $\mathbf{o}_t$ | Current visual observation. |
| $l$ | Language instructions. |
| $\tilde{\mathbf{a}}_t$ | Noisy action chunk at diffusion timestep $k$. |
| $f_\theta$ | DiT backbone for RDT, conditional SigLIP visual tokens and T5 language tokens. |
4.2 Future Prefix Alignment
FRAPPE adds learnable future prefix $\mathbf{p}\in\mathbb{R}^{n\times d}$ to the RDT input sequence. The model not only outputs actions, but also outputs future representation predictions corresponding to prefix:
The future prefix allows the RDT, which was originally only responsible for action denoising, to learn the future state representation internally.
$$\mathbf{a}_t, \mathbf{p}_t=f_\theta(l, \mathbf{o}_t, \tilde{\mathbf{a}}_t, k)$$ $$\mathbf{e}_{t+h}=\Phi(o_{t+h}), \quad \mathcal{L}_\Phi=\cos(\mathbf{p}_t, \mathrm{sg}(\mathbf{e}_{t+h}))$$| $\Phi$ | pretrained VFM teacher encoder. |
| $h$ | future horizon; the optimal appendix ablation is $h=8$. |
| $\mathrm{sg}$ | stop-gradient, do not update teacher encoder. |
| $\mathbf{p}_t$ | A future-prefix representation of the RDT output, used to align future observation embeddings. |
4.3 Parallel Scaling: Mixture-of-Prefix-and-LoRA
To leverage knowledge from multiple vision base models, FRAPPE builds multiple future-prefix + LoRA experts on a shared RDT backbone. Each expert corresponds to a teacher encoder, the paper setting is $M=3$, and the teachers are CLIP 400M, DINOv2 142M, and ViT 300M.
Among them, $\mathcal{L}_{\Phi_i}$ is the future representation alignment loss of the $i$th VFM teacher.
During inference, multiple experts will give latent action representations, the router will generate gating weights, and then aggregate the output.
| $z_i$ | The latent action representation output by the $i$th expert. |
| $w_i$ | The weight given by router to the $i$ expert. |
| MLP | Sharing action heads maps weighted latent representations into executable action chunks. |
4.4 Load Balance and Label Smoothing
The authors observed mode collapse: a certain stream may dominate learning, and other experts rarely update. Add load-balancing loss and gating label smoothing to this.
Appendix A $\lambda_1$ ablation shows that $\lambda_1=0.05$ is optimal; if it is too large, it will interfere with the main task of action prediction.
4.5 Why are Mid-training and Post-training separated?
The paper emphasizes that parallel post-training cannot be done directly on base RDT because the architecture and goals deviate too much from the original RDT pre-training distribution. Mid-training first uses single-stream future prefix and Theia-style 86M distilled encoder to do full-parameter fine-tuning to adapt the model to the world-modeling objective; then post-training freezes the backbone and uses LoRA/prefix to efficiently align multiple teachers.
5. Experiments and results
5.1 Simulation Setup
The simulation experiment uses RoboTwin 2.0, which is a real-to-sim bimanual benchmark. Each task has two settings: Easy and Hard; Hard includes domain randomization such as scene clutter, background texture, lighting, desktop height, etc. All simulation experiments cover 8 tasks, and each model uses 100 evaluation trials to report the average performance.
Training settings: Starting with RDT-1B official pretrained weights; training data limited to 50 trajectories per task in Easy setting; two H100 training 20, 000 steps, batch size 32.
5.2 RoboTwin 2.0 Main Results
| Method | Average Easy | Average Hard | Remarks |
|---|---|---|---|
| DP | 31.3% | 0.0% | train-from-scratch visuomotor baseline. |
| VPP | 35.8% | 4.0% | implicit world model baseline. |
| RDT | 47.4% | 15.1% | FRAPPE's base model. |
| $\pi_0$ | 57.1% | 14.1% | RoboTwin SOTA baseline. |
| $\pi_{0.5}$ | 45.4% | 13.3% | $\pi_0$ successor. |
| FRAPPE | 57.5% | 25.5% | Easy has the highest average, and Hard has the significantly highest average. |
The improvement of Hard setting is more critical: FRAPPE increases from 15.1% of RDT to 25.5%, which also exceeds $\pi_{0.5}$. The author explains that the model better learns the low-level dynamics behind multiple visual observations instead of relying on spurious visual correlations.
5.3 Training Paradigm Ablation
| No. | Method | Steps | Easy | Hard | Average |
|---|---|---|---|---|---|
| 0 | RDT | 20k | 59.0 | 20.5 | 39.8 |
| 1 | mid-train full ft | 20k | 63.0 | 27.5 | 45.3 |
| 2 | mid-train prefix & LoRA ft | 20k | 48.0 | 8.5 | 28.3 |
| 3 | post-train prefix ft | 20k | 25.0 | 4.0 | 14.5 |
| 4 | post-train prefix & LoRA ft | 20k | 46.0 | 9.0 | 27.5 |
| 5 | mid full ft + post prefix ft | 15k + 5k | 68.0 | 21.5 | 44.8 |
| 6 | mid full ft + post prefix & LoRA ft | 15k + 5k | 73.5 | 32.0 | 52.3 |
The conclusion is clear: mid-training must be done first, and full-parameter fine-tuning is required; post-training alone is very ineffective; the final best recipe is 15k full-parameter mid-training + 5k prefix&LoRA post-training.
5.4 Inference Efficiency
| Metric | RDT 5 steps | mid-train 5 steps | post-train 5 steps | post-train 3 steps |
|---|---|---|---|---|
| Inference Memory | 3.7 GB | 3.7 GB | 8.0 GB | 8.0 GB |
| Latency | 0.214 s | 0.228 s | 0.235 s | 0.173 s |
| Success Rate | 39.8% | 45.3% | 52.3% | 48.5% |
Post-training parallel experts increased the video memory from 3.7GB to 8.0GB, but the delay of the same 5 steps only increased by about 20ms. After reducing to 3 denoising steps, the delay is lower than RDT 5 steps, and the success rate is still higher than the baseline.
5.5 Smaller-scale Policy Model

The author uses RDT-130M to illustrate that this training paradigm does not only rely on the 1B parameter size. RDT-130M's original hard-task generalization is weak, but FRAPPE significantly improves hard tasks and can approach the level of naive RDT-1B fine-tuning.
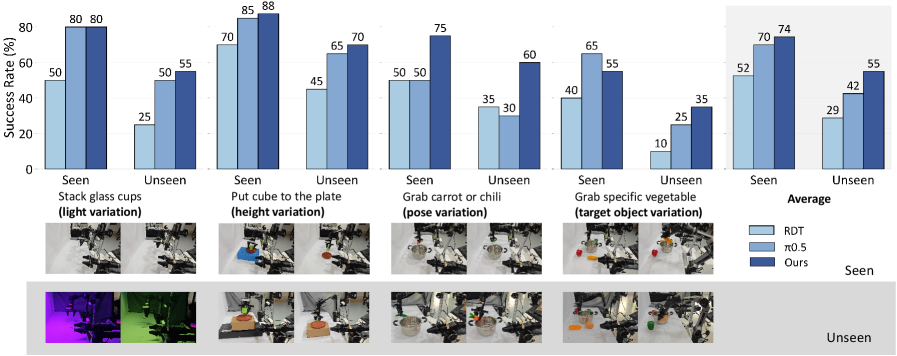
5.6 Real-world Experiments
Real experiments use bimanual AgileX mobile manipulator, 6-DoF per manipulator and parallel gripper. The vision system consists of a high-mounted third-person main camera, and two wrist-mounted ego-centric cameras. Training data: 25 demonstrations per variation for basic tasks, 100 demonstrations for long-horizon tasks. Assessment: 40 trials each for basic tasks, 20 trials each for long-horizon tasks.
5.7 Human Egocentric Co-training
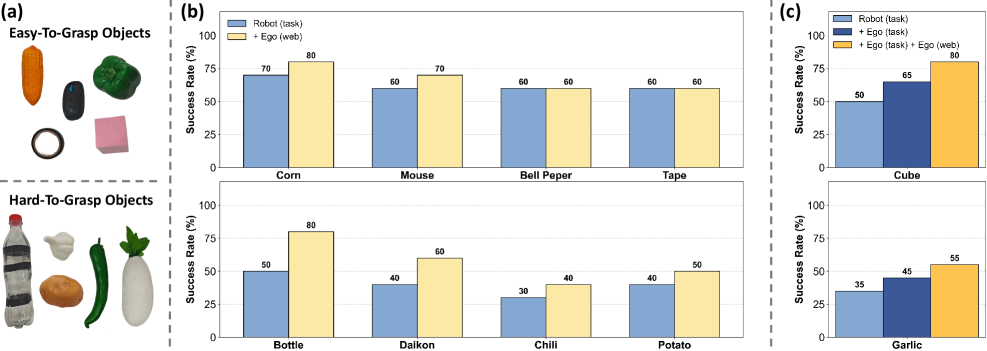
FRAPPE proposed a data pyramid: the bottom layer is large-scale action-free human egocentric data, the middle layer is task-specific human egocentric data, and the top layer is task-specific robot teleoperation data. The author emphasizes that task-specific human data does not use GoPro/VR, but uses a static third-person camera consistent with the robot data; in this way, a novice human operator can exceed 360 trajectories/hour, while a skilled robot teleoperation is usually about 120 trajectories/hour.
The co-training experiments used 5 robot action trajectories per object, 50 task-specific human egocentric trajectories, and 10k task-irrelevant human egocentric videos. For action-free samples, action loss is omitted and only alignment loss is optimized.
6. Repeat audit
6.1 Key training configurations
| Project | Configuration |
|---|---|
| Base model | official RDT-1B pretrained weights; small model verification is RDT-130M. |
| Simulation data | RoboTwin Easy setting, 50 task-specific trajectories per task. |
| Training budget | 2 NVIDIA H100 GPUs; 20, 000 steps; batch size 32. |
| FRAPPE schedule | 15, 000 mid-training steps + 5, 000 post-training steps. |
| Post-training trainable params | future prefixes + LoRA + router/action aggregation related lightweight modules; shared RDT backbone frozen. |
| Teacher encoders | Mid-training: 86M Theia-style distilled encoder; Post-training: CLIP 400M, DINOv2 142M, ViT 300M. |
| Evaluation | 100 trials each for RoboTwin; 40 trials each for real basic tasks; 20 trials each for real long-horizon. |
6.2 Appendix Hyperparameter Ablation
| $\lambda_1$ | 0 | 0.001 | 0.02 | 0.05 | 0.1 | 0.5 |
|---|---|---|---|---|---|---|
| SR | 14.0% | 18.5% | 26.4% | 32.5% | 22.0% | 23.5% |
| Alignment depth | 7 | 14 | 21 | 28 |
|---|---|---|---|---|
| SR | 14.5% | 18.0% | 23.5% | 16.0% |
| Future horizon $h$ | 8 | 16 | 32 |
|---|---|---|---|
| SR | 35.3% | 35.0% | 29.7% |
Appendix A Using layer 21 of the RDT-1B 28-layer DiT for future prefix alignment, it is approximately 3/4 of the total depth; this is consistent with the observation that deeper alignment is more effective in FLARE.
6.3 Human Egocentric Co-training Details
Appendix B Using TASTE-Rob as Ego(web): 100, 856 video sequences, ~9M frames, with high quality language alignment. This phase trains for 1 epoch, which takes about 96 hours on 8 H100s. The reason why the author chose TASTE-Rob is that the fixed egocentric viewpoint is closer to the mainstream VLA camera setting and helps to migrate to downstream robot action prediction.
6.4 reproducibility checklist
Papers and resources give relatively sufficient information
Fully: The code and model links have been made public; the core formulas, teacher encoders, two-stage training steps, batch size/GPU, RoboTwin data volume, real robot data volume, hyperparameter ablation, and inference efficiency tables are relatively clear.
Still needs practical confirmation: The specific LoRA target modules/rank, future prefix token length $n$, router architecture details, specific checkpoint of Theia variant, RoboTwin task configuration and real robot control stack need to be further confirmed from the code repository.
Minimum recurrence path
- Load RDT-1B pretrained weights, keeping the original SigLIP/T5 conditional interface and action decoder.
- Add future prefix to DiT input and take prefix representation at layer 21.
- Use future observation embedding of Theia-style 86M distilled encoder to do single-stream full-parameter mid-training, 15k steps.
- Build 3 Prefix+LoRA experts, align CLIP, DINOv2, and ViT respectively, freeze the shared backbone, and train for 5k steps.
- Implement router aggregation latent action representation, and add load balance loss and $\epsilon=0.1$ gating smoothing.
- Trained on $\lambda_1=0.05$, $h=8$, batch size 32, 2 H100, and evaluated on RoboTwin Easy/Hard 8 tasks with 100 trials/task.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Judging from the paper's own claims, the most valuable thing about FRAPPE is that it combines "implicit world modeling + parallel scaling + parameter efficient finetuning" into a clear recipe. It does not simply add a future representation loss, but uses mid-training to first solve the target distribution mutation, and then uses MiPA to absorb the future representations of multiple VFM teachers in parallel. The training paradigm table shows that if you skip mid-training directly or only use prefix post-training, the performance will decrease significantly.
7.2 Why the results hold up
The chain of evidence is relatively complete: the RoboTwin table covers 8 tasks, two settings of Easy/Hard and multiple SOTA baselines; the training paradigm ablation directly compares the combination of mid/post/full/LoRA/prefix; the efficiency table shows that parallel expansion does not cause unacceptable delays; the RDT-130M experiment shows that the method is not only suitable for large models; the real two-arm task and human egocentric co-training further support the claims of data efficiency and generalization.
7.3 Limitations of explicit or indirect presentation by the author
- Hard setting The absolute success rate is still low.FRAPPE has the highest average on Hard, but 25.5% still shows that visual generalization under strong domain randomization is not completely solved.
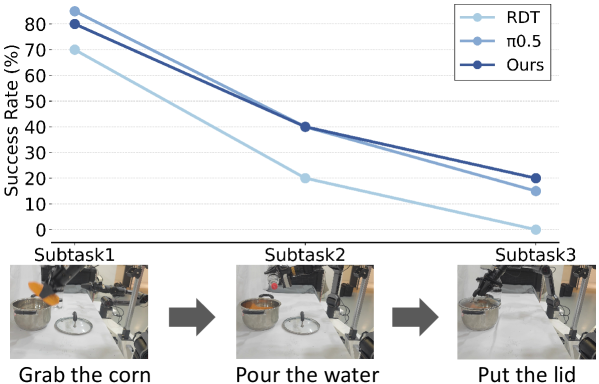
- The success rate of real long-range missions is limited.RDT is 0% and FRAPPE is 20%, which reflects an improvement, but long-range missions are still far from stable.
- Engineering complexity increases.Post-training requires multiple teacher encoders, multiple prefix/LoRA experts, routers, load balance and label smoothing; the recurrence complexity is higher than a single alignment loss.
- Video memory increased.Post-training inference memory increases from 3.7GB to 8.0GB, which is still within the range of common inference GPUs, but the deployment resource requirements increase.
- Real data settings rely on a fixed perspective.task-specific human egocentric data actually uses a static third-person camera instead of GoPro/VR, indicating that the pipeline still relies on the consistency of camera settings.
7.4 Applicable boundaries
FRAPPE is suitable for scenarios that already have pretrained diffusion/VLA backbone and hope to improve generalization with a small amount of robot data and a large amount of motionless videos, especially for double-arm manipulation, visual perturbation, object changes, and small data fine-tuning. It is less suitable for systems that need to explicitly visualize future trajectories for human review because it learns latent future representations rather than generating images of the future.
The other boundary is teacher indicating selection. The core benefit of FRAPPE comes from multi-VFM alignment; if the task domain is very different from the visual semantic coverage of CLIP/DINOv2/ViT, teacher selection and mid-training teacher distillation may become key bottlenecks.