AdaWorldPolicy: World-Model-Driven Diffusion Policy with Online Adaptive Learning for Robotic Manipulation
1. 论文速览
| 论文要解决什么 | 机器人在动态真实环境和 contact-rich 任务中会遇到视觉扰动、物体/力学变化和物理接触分布偏移;仅靠离线 imitation 或 VLA-style reactive policy 很难在测试时用真实反馈自我修正。 |
|---|---|
| 作者的方法抓手 | 把 world model 从“离线预测器/验证器”变成 active supervisor:先生成动作,再用同一网络的 Future Imagination 模式预测执行后未来观测,把预测和真实反馈的差异作为 test-time adaptation 信号。 |
| 最重要的结果 | LIBERO-10 full multimodal success 0.96;Variant PushT 在 texture / random light / random color OOD 下 AWP(ol) 达 0.51 / 0.77 / 0.66,均高于 AWP;CALVIN ABC→D 平均完成长度 AWP(ol) 为 3.54;真实任务 in-domain 平均 ablation 表中 full method 为 76.3%。 |
| 阅读时要注意的点 | AdaOL 是在线更新 LoRA 参数,不是简单重规划;真实世界结果主要以柱状图呈现,没有逐 trial 表格,但附录补充了评测协议、成功标准、TTA 两阶段流程和关键超参。 |
World Model Diffusion Policy Flow Matching Test-Time Adaptation Force Feedback LoRA
核心贡献
- 统一多模态 diffusion 框架。世界模型、动作模型、力预测器都实现为 Flow Matching DiT,并通过 MMSA 交换信息。
- AdaOL 测试时在线适应。模型根据真实反馈与 imagined future 的差距自监督更新少量 LoRA 参数,以降低视觉和物理 domain shift。
- 接入 force-torque feedback。Force Predictor 预测未来力读数,用于处理 contact-rich 任务中的 dynamic force shift。
- 多 benchmark 验证。覆盖 LIBERO-10、Variant PushT、CALVIN 和 4 个真实机器人任务,并在附录补充 sampling step、MMSA、未来帧可视化和实现细节。
2. 动机与相关工作
2.1 为什么普通 VLA 不够
论文指出,VLA 模型虽然能把语言、视觉和动作结合起来,但通常依赖大量 human demonstrations,并且在未见过或动态变化的 contact-rich 场景中泛化受限。根本原因是它们多半是离线训练的 reactive mapping:当前观测进来,直接输出动作,缺少显式预测物理后果并利用真实反馈修正自身的机制。
2.2 为什么要把 world model 放进闭环
已有 world model 在机器人中常被用作 “digital twin” 或离线 validator;也有 WorldVLA、UVA 等把 action generation 与 world prediction 统一。但作者认为这些方法大多仍是离线训练策略,部署时面对视觉和动力学变化时不能快速适应。AdaWorldPolicy 的核心动机是:world model 的 prediction error 本身就是一个自监督信号,可以在测试时不断校正 action model、world model 和 force predictor。
| 相关方向 | 已有方法的定位 | AdaWorldPolicy 的差异 |
|---|---|---|
| World Models for Robotic Control | Dreamer、Cosmos、Dino-WM 等用于 dynamics prediction、planning 或 policy validation。 | world model 不只是预测或验证,而是主动产生 online adaptation loss。 |
| Diffusion Models for Decision Making | Diffusion Policy 等把动作轨迹建模成扩散过程,擅长多模态动作分布。 | 在 diffusion policy 中加入 future outcome modeling 与 force prediction,以约束动作物理一致性。 |
| Online Adaptation for Robotics | TTA、LoRA、confidence maximization 等在测试时调整模型参数。 | 用 world-model prediction error 和 force discrepancy 作为机器人特定的自监督更新信号。 |
3. 方法详解
3.1 问题设定
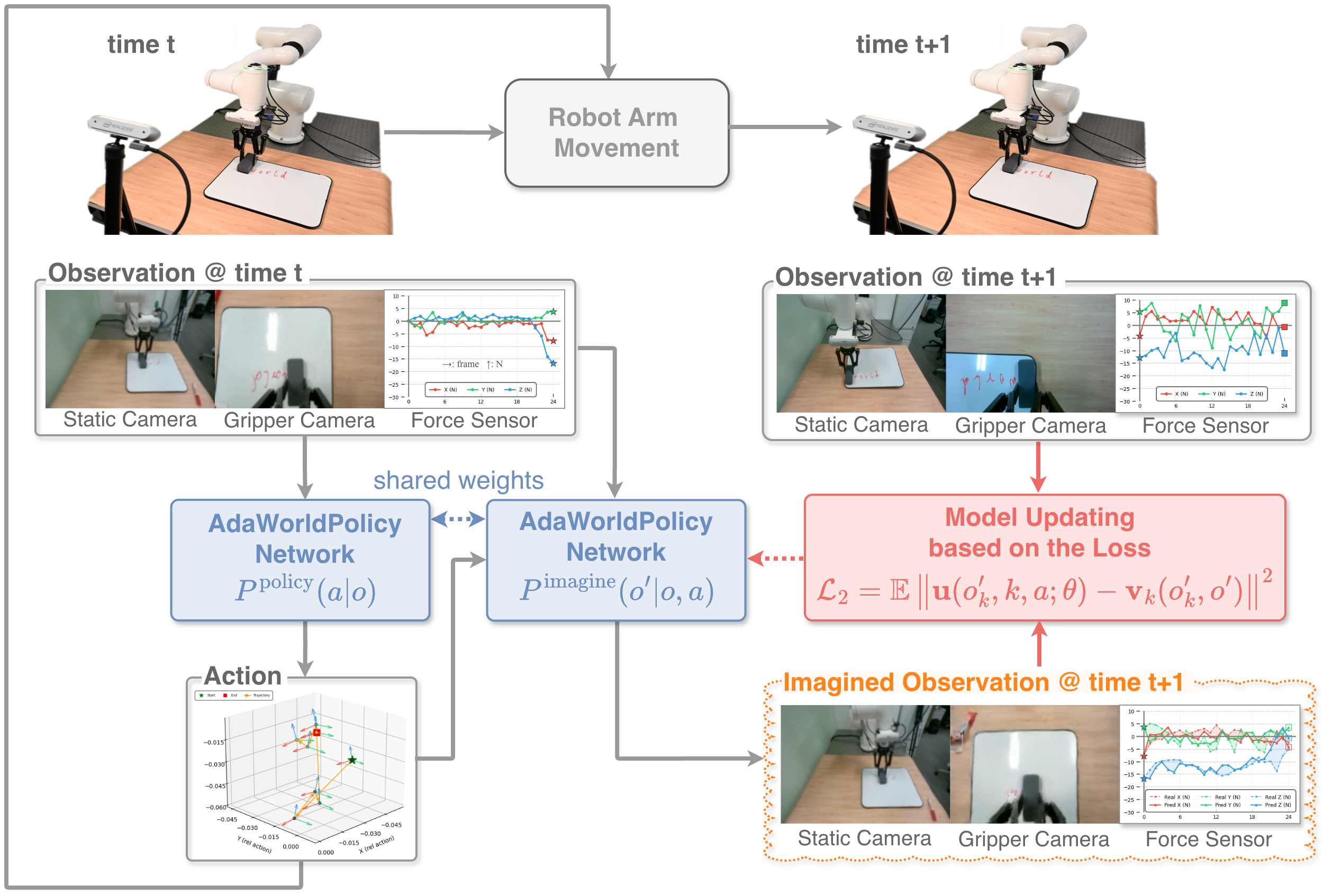
每个时刻输入多模态历史观测 $o=\{x_{\text{static}}, x_{\text{gripper}}, f\}$,包括静态相机序列、gripper camera 序列和 force-torque 读数,三者共享 context length $T_c$。模型输出未来 action sequence $a=a_{t:t+T_a-1}$,目标是在不新增人工标注或 demonstration 的测试环境中,利用自身交互数据 $\{(o_t,a_t,o_{t+1})\}_{t=0}^{T}$ 从参数 $\theta_t$ 更新到 $\theta_{t+1}$。
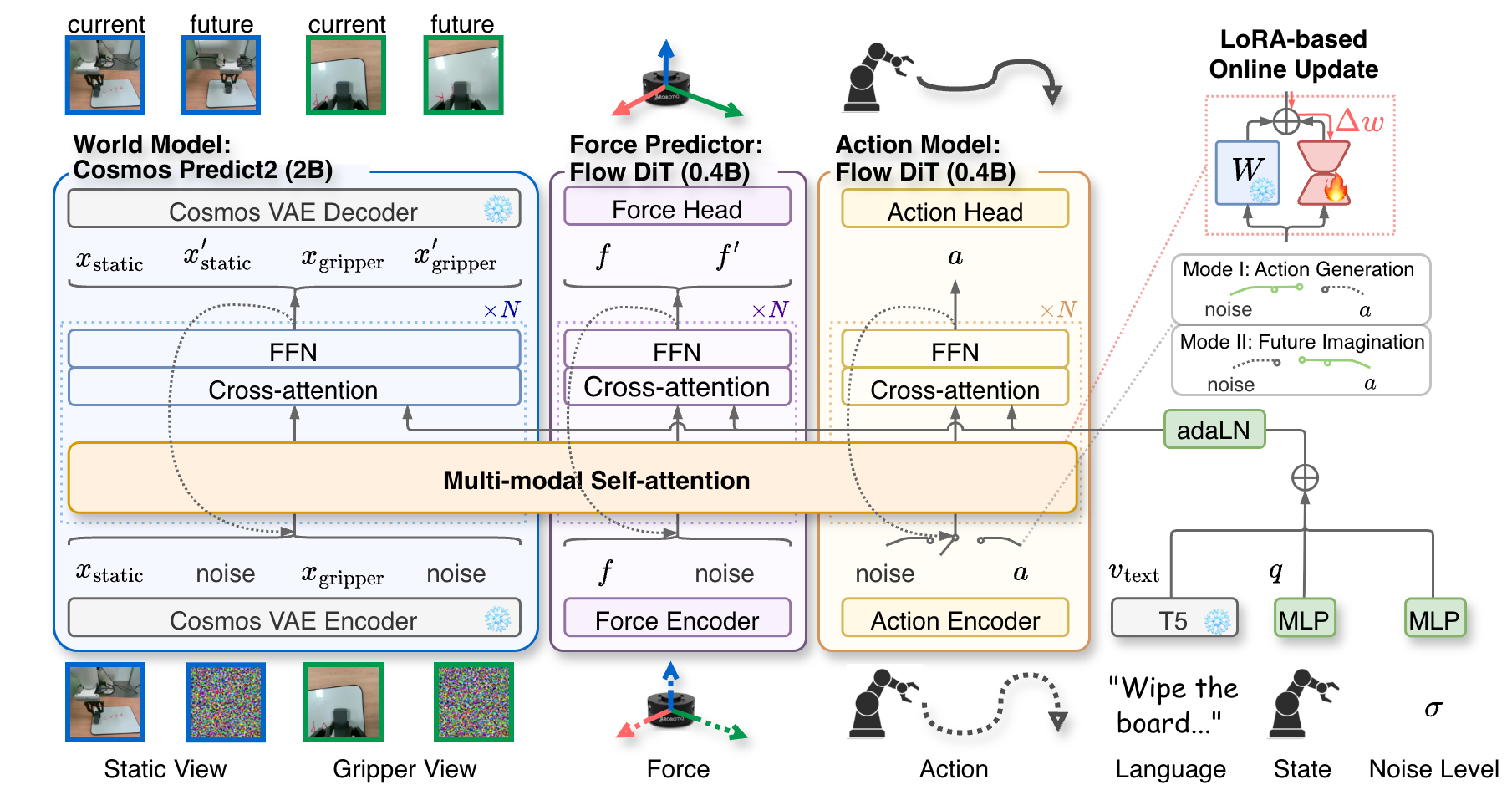
3.2 三个模块
| 模块 | 输入/输出 | 作用 | 规模 |
|---|---|---|---|
| World Model | 输入当前静态/夹爪视角、动作条件;输出未来视觉状态 $x'_{\text{static}}, x'_{\text{gripper}}$。 | 预测动作造成的视觉后果,并提供 AdaOL 自监督信号。 | Cosmos-Predict2 2B。 |
| Force Predictor | 输入当前状态与动作;输出未来 force-torque 读数 $f'$。 | 补充视觉世界模型看不到的 contact dynamics,减轻 force shift。 | 真实世界 0.4B;仿真无 force 时移除。 |
| Action Model | Mode I 输入噪声 action token 并 denoise;Mode II 输入已知 action 作为条件。 | 生成动作;或在 Future Imagination 中成为 action-conditioned 条件。 | 真实世界 0.4B;仿真可增至 0.6B。 |
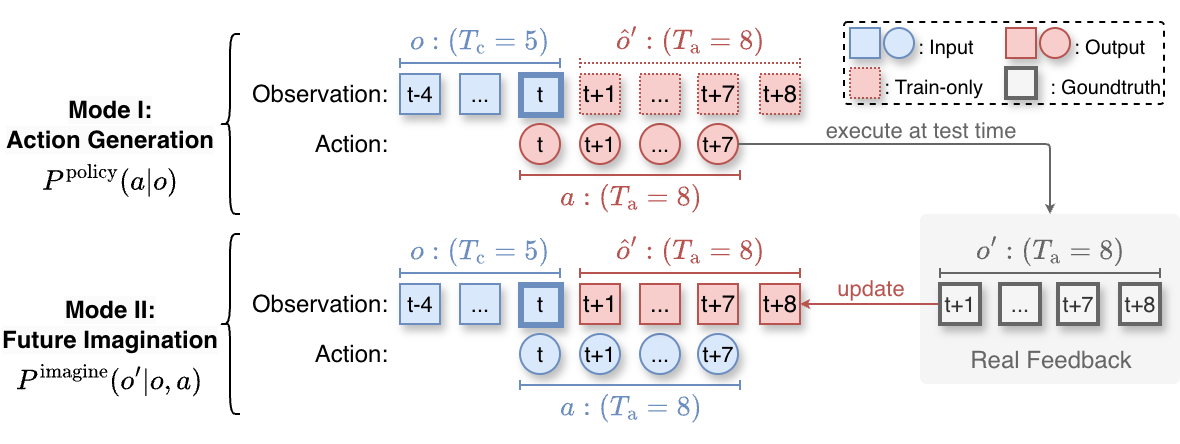
3.3 双模式:同一网络,两个角色
3.4 World Model 的多视角扩展
论文把 Cosmos-Predict2 从单视角视频预测扩展到多视角输入:每个相机视角先经过 Cosmos VAE 得到 token,再沿 temporal dimension 拼接;不同视角使用独立 RoPE,以保持跨视角的空间和时间结构。输入 token 还配有 binary mask,1 表示已知条件,0 表示预测目标;最终 denoising 后,条件部分会被原始输入替换,以保证条件观测不被模型生成结果污染。
3.5 Multi-modal Self-Attention
MMSA 是三个模块之间的桥。它不是简单 concat,也不是单向 cross-attention,而是让 world / force / action 各自生成 QKV,再在 token 维度拼接后进行 self-attention。这样三者可以互相查询信息,同时保留各自专用表示空间。
MMSA 在做:把世界、力、动作三个专家的注意力请求放到同一个注意力场里互相通信。
$$\text{MMSA}(Q,K,V)=A([Q_x,Q_f,Q_a],[K_x,K_f,K_a],[V_x,V_f,V_a])$$| $x$ | World Model / visual tokens。 |
| $f$ | Force Predictor / force tokens。 |
| $a$ | Action Model / action tokens。 |
| $A$ | 标准 self-attention 操作。 |
3.6 AdaOL 在线适应循环
AdaOL 在每次执行后运行一个闭环:生成动作、执行、接收真实反馈、想象同一动作的未来结果、计算误差、用 LoRA 更新少量参数。作者强调只更新低秩矩阵,比例低于 0.1%,在线更新开销可控。
AdaOL loss 比较的是:模型以为动作会造成什么结果,真实世界实际发生了什么。
$$\mathcal{L}_{\text{AdaOL}}=\|E(o_{t+1})-E(\hat{o}_{t+1})\|_2^2$$$E(\cdot)$ 是 Cosmos VAE encoder。该误差产生校正梯度 $\Delta w$,用于 LoRA 在线更新。
4. 数学形式与训练目标
4.1 Action Generation loss
这里 $a_k$ 是 noised action,$\mathbf{u}_\theta$ 是模型预测的 flow vector field,$\mathbf{v}_k$ 是 Flow Matching 目标向量场。这个 loss 训练模型从当前观测 $o$ denoise 出动作 $a$。
4.2 Future Imagination loss
$o'_k$ 是 noised future observation;这里动作 $a$ 是已知条件。它训练 world/force/action 共享系统预测“执行该动作之后会发生什么”。
4.3 Joint objective
训练时随机切换两种模式:以概率 $p_a$ 训练动作生成,否则训练未来想象。这个设计使模型同时学会当 policy 和当 action-conditioned world model。
5. 实验与结果
5.1 实验设置
| 设置 | 内容 |
|---|---|
| 仿真 benchmark | LIBERO-10 测长程组合技能;Variant PushT 测 texture、随机光照、随机颜色 OOD;CALVIN 使用 ABC→D cross-domain protocol,每条序列连续完成 5 个任务。 |
| 真实机器人 | 6-DoF 机械臂,gripper camera、wrist-mounted force-torque sensor 和 third-person static camera;任务包括 Sweep Beans、Pick-and-Place Eggs、Pour Water、Wipe Whiteboard。 |
| 离线训练 | PyTorch + Cosmos-Predict2;8 张 A100 80GB;AdamW;global batch size 64 到 256;LR $1\times10^{-4}$,loss plateau 后最多 20k steps 线性衰减到 1%。 |
| 在线学习 | 单张 NVIDIA RTX 5880 48GB;LoRA rank 16,只放在每个 backbone 前 4 层;每个 incoming sample 做 2 个梯度步,LR $5\times10^{-7}$;平均 TTA 推理速度仅比无适应慢约 5%。 |
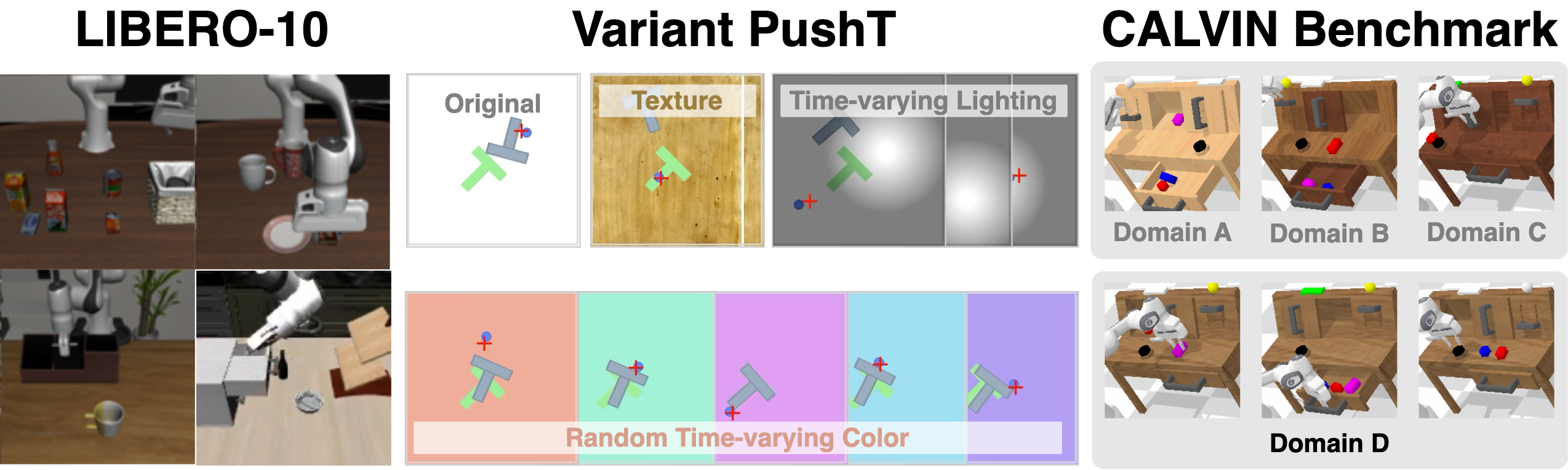
5.2 LIBERO-10
| Setting | Method | Static Camera | Gripper Camera | Joint States | Success |
|---|---|---|---|---|---|
| Static only | UVA | Yes | No | No | 0.89 |
| Static only | AWP | Yes | No | No | 0.91 |
| Full multimodal | OpenVLA | Yes | Yes | Yes | 0.54 |
| Full multimodal | MODE | Yes | Yes | Yes | 0.94 |
| Full multimodal | OpenVLA-OFT | Yes | Yes | Yes | 0.94 |
| Full multimodal | AWP | Yes | Yes | Yes | 0.96 |
LIBERO-10 结果证明 AWP 架构本身在无在线适应时已较强:static-only 超 UVA,full multimodal 超 MODE 与 OpenVLA-OFT。
5.3 Variant PushT:OOD robustness
| Method | Original | Texture | Rand Light | Rand Color |
|---|---|---|---|---|
| Diffusion Policy | 0.78 | 0.18 | 0.14 | 0.11 |
| OpenVLA | 0.35 | 0.22 | 0.20 | 0.14 |
| UniPi | 0.42 | 0.35 | 0.33 | 0.18 |
| UVA | 0.94 | 0.11 | 0.54 | 0.13 |
| AWP | 0.97 | 0.47 | 0.71 | 0.61 |
| AWP (ol) | 0.98 | 0.51 | 0.77 | 0.66 |
这里最能体现 AdaOL:AWP 已经强于大多数基线,但 online learning 在所有 OOD 变体上继续带来提升,尤其随机光照从 0.71 到 0.77,随机颜色从 0.61 到 0.66。
5.4 CALVIN ABC→D
| Method | Len 1 | Len 2 | Len 3 | Len 4 | Len 5 | Avg. Len. |
|---|---|---|---|---|---|---|
| OpenVLA | 91.3 | 77.8 | 62.0 | 52.1 | 43.5 | 3.27 |
| MoDE | 91.5 | 79.2 | 67.3 | 55.8 | 45.3 | 3.39 |
| GR-MG | 91.0 | 79.1 | 67.8 | 56.9 | 47.7 | 3.42 |
| AWP | 91.8 | 79.2 | 68.5 | 62.8 | 48.0 | 3.51 ± 0.03 |
| AWP (ol) | 92.0 | 79.6 | 68.6 | 63.0 | 48.0 | 3.54 ± 0.04 |
CALVIN 上 online learning 的增量较小但一致:平均长度 3.51 到 3.54,长度 5 保持 48.0。作者将其解释为 TTA 能微调已经泛化较好的 policy。
5.5 真实机器人任务
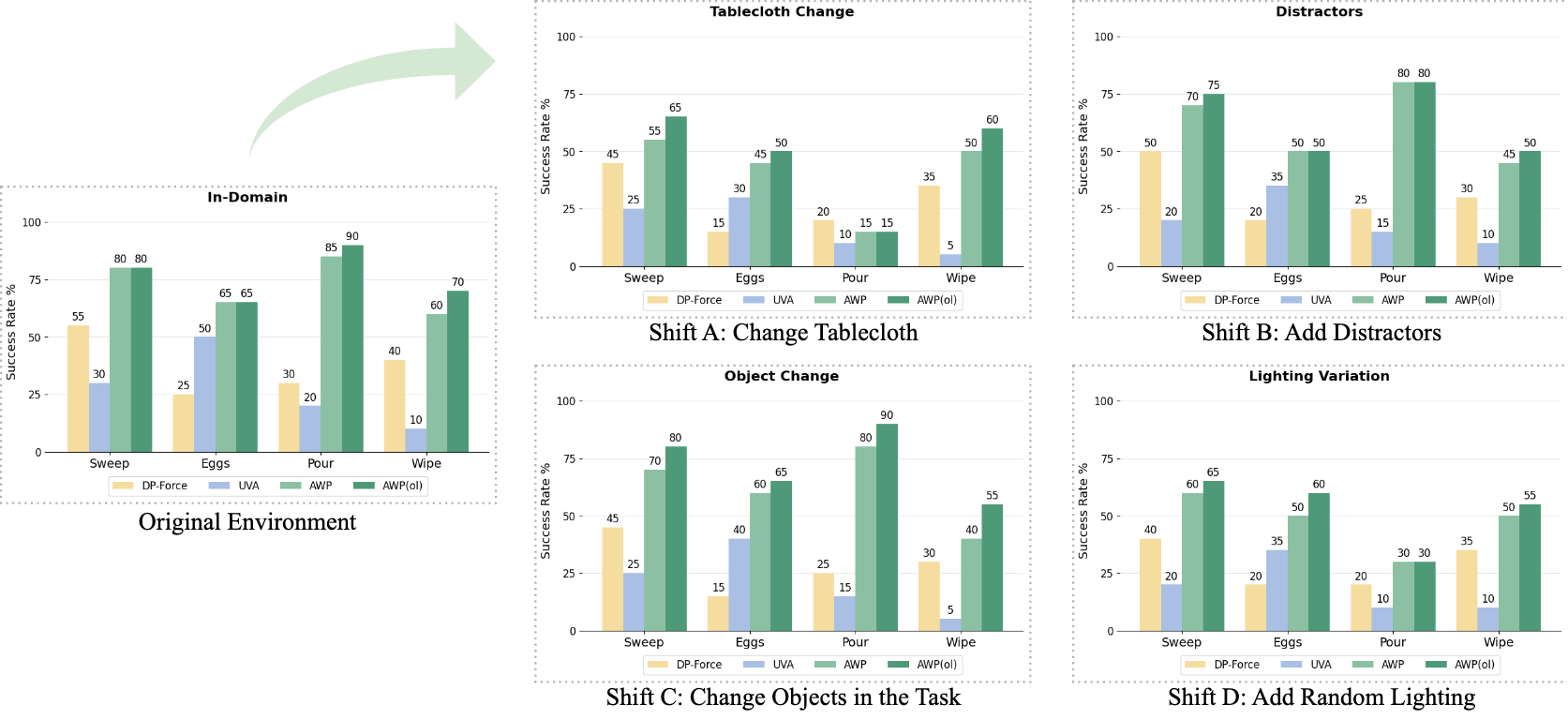
附录补充了真实世界协议:每个任务 in-domain 收集 150 条专家 demonstrations;每个模型配置在每个任务/分布下做 30 trials,最多 1500 execution steps。AdaOL 测试分两阶段:Trials 1-15 持续在线更新,Trials 16-30 冻结更新后的模型,以评估 adapted policy 的稳定性。
5.6 Ablation
| Configuration | Success Rate | 含义 |
|---|---|---|
| AdaWorldPolicy w/ AdaOL | 76.3 | 完整方法,真实 in-domain 四任务平均。 |
| AdaWorldPolicy w/o AdaOL | 72.5 | 无测试时在线更新,下降 3.8。 |
| w/o Force Predictor | 53.8 | 去掉力预测,contact-rich 任务显著退化。 |
| w/o World Model Supervision | 46.3 | 退化成行为克隆式策略,说明 world supervision 是核心。 |
| MMSA → Concatenation | 36.3 | 简单拼接无法有效整合模块。 |
| MMSA → Cross-Attention | 50.0 | 普通 cross-attention 仍弱于 MMSA。 |
5.7 附录补充:sampling steps、imagined future 和超参
| 附录实验 | 关键结果 | 整合位置 |
|---|---|---|
| Sampling steps on LIBERO | AWP 20/10/5/2 steps 分别为 96.33 / 95.53 / 94.67 / 94.00;减少 steps 仅小幅降低性能。 | 复现时可权衡速度和精度。 |
| AdaOL on LIBERO | 10 steps 下从 95.53 提升到 96.05。 | 说明 AdaOL 在轻微分布差异上也有小幅收益。 |
| MMSA fusion | MMSA 95.53,Concat 89.67,Cross-Attention 91.21。 | 补强主文 ablation 中 MMSA 的必要性。 |
| Imagined future visualization | PushT、CALVIN、LIBERO 的 imagined future 与 real observation 基本一致;真实场景中复杂背景和鸡蛋任务会有模糊/伪影。 | 支持 world model 可提供监督,但也揭示视觉生成局限。 |


6. 复现审计
6.1 公开资源状态
源码未随 arXiv 提供完整训练代码。论文只在摘要中给出项目主页 AdaWorldPolicy.github.io,LaTeX 源码里没有 GitHub 或 checkpoint 链接。附录提到 supplementary zip 中包含本地视频网页 `AdaWorldPolicy_Homepage/index.html`,但 arXiv e-print 里没有该文件夹。
6.2 关键超参
| Benchmark | Image Size | History Length | Action Horizon | # Imagined Frames |
|---|---|---|---|---|
| LIBERO10 | 128 × 128 | 5 | 20 | 20 |
| PushT | 256 × 256 | 5 | 20 | 20 |
| CALVIN | 192 × 192 | 1 | 12 | 12 |
| Real-world | 112 × 160 | 1 | 32 | 4 |
真实世界使用 sparse prediction:imagined frames 只有 4,而 action horizon 是 32,用稀疏未来帧覆盖动作时间跨度,以降低视频生成延迟。
6.3 数据处理与力数据
- 真实任务每个 in-domain 环境采集 150 条专家 demonstrations,使用 PS5 controller teleoperation,并把 force sensor 读数映射为手柄震动给操作者反馈。
- force 读数不像像素或相对位姿那样有稳定上下界;附录说明使用 quantile-based normalization,即按 1st 和 99th percentile 缩放,以减轻 outlier/spike 影响。
- DP baseline 也增强为 DP-Force:把 6D force data 与 image observation features concat,再通过 Transformer cross-attention 融合,以保证真实实验对比公平。
6.4 复现缺口
- 未提供完整代码、模型权重和数据下载路径;只能依据论文描述复现框架。
- 真实世界图中数值来自柱状图,主文没有逐 trial 表;附录只给协议和成功标准,没有完整真实 rollout 表。
- Cosmos-Predict2 的具体 fine-tuning 配置依赖原始实现;论文说明“largely follow training recipe”,但未列出所有 scheduler、augmentation、LoRA target module 细节。
- 在线更新在 RTX 5880 上测得约 5% slowdown,但没有给出每步绝对 latency、batch/sequence padding 细节。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
最有价值的点在于把 world model 的误差变成在线学习信号,而不是只把 world model 当作 rollout visualizer 或离线 evaluator。主文的 PushT OOD 表、真实世界 domain shift 图和 ablation 都指向同一个机制:当视觉或物理条件变化时,AWP(ol) 通过真实反馈持续修正,比固定离线 policy 更稳。
7.2 结果为什么站得住
论文的证据链覆盖了“离线能力”和“在线适应”两个层面:LIBERO/CALVIN 表明 base AWP 架构本身强;PushT OOD 和真实 domain shift 展示 AdaOL 带来的增量;ablation 显示去掉 world supervision、force predictor 或 MMSA 都大幅下降。附录中的 sampling-step 和 imagined-future 可视化进一步说明,世界模型生成的未来虽然并非完美照片,但在结构上可用作监督。
7.3 作者自述的局限与未来方向
- world model 的 OOD 泛化仍不完美。附录明确说 Cosmos-Predict2 在显著 domain shift、持续变化光照和复杂真实场景下会出现未来帧质量下降。
- AdaOL 超参固定。作者没有针对每个任务或环境调 AdaOL 超参;未来可用 adaptive 或 meta-learning 自动调节。
- 长程规划失败仍待解决。结论中说未来将进一步处理 long-horizon planning failures,并扩展到更大网络架构。
7.4 适用边界
AdaWorldPolicy 适合有持续观测反馈、能承受少量测试时更新开销、并且 world prediction error 与任务成败相关的场景。对于需要严格安全约束、不能在线更新参数、或视觉未来预测与真实控制目标弱相关的场景,论文没有给出充分验证。