DiT4DiT: Jointly Modeling Video Dynamics and Actions for Generalizable Robot Control
1. 论文速览
难度评级:★★★★☆。读懂主线需要熟悉 VLA、Diffusion Transformer、flow matching、机器人 imitation learning 和 sim-to-real 评测;难点主要在 tri-timestep 训练设计以及“生成视频特征如何变成动作条件”。
关键词:Video-Action Model, Diffusion Transformer, flow matching, VLA, robot control, generative world modeling。
| 阅读定位 | 内容 |
|---|---|
| 论文要解决什么 | 现有 VLA 多继承静态 image-text 预训练表征,物理动态和时序状态转移主要靠有限 action data 学;作者要检验并实现“视频生成能否作为机器人策略学习的更强 proxy objective”。 |
| 作者的方法抓手 | 用 Cosmos-Predict2.5-2B 初始化 Video DiT,从固定 flow timestep 和指定 transformer 层抽取中间 hidden features;再让 Action DiT 通过 cross-attention 使用这些特征,并用 dual flow-matching 联合训练视频与动作。 |
| 最重要的结果 | DiT4DiT 在 LIBERO 平均 98.6%,RoboCasa-GR1 平均 50.8%;相对参数匹配的 Qwen3DiT 在 RoboCasa-GR1 提升 14.6 个百分点,并在真实 Unitree G1 上展示 7 个任务和零样本分布外泛化。 |
| 阅读时要注意的点 | 方法不是先生成完整未来帧再做 inverse dynamics,而是抽取视频去噪过程中的中间特征;实验中“from scratch”与“pretrained baseline”的数据条件需要分开看,真实机器人部分还引入了 241,450 条 GR1 预训练 episode。 |
核心贡献清单
- 提出 Video-Action Model 的 dual-DiT 架构。视频 DiT 负责未来视觉动态建模,动作 DiT 负责连续控制轨迹生成,两者通过中间去噪特征耦合。
- 提出 dual flow-matching 和 tri-timestep 设计。视频训练 timestep、动作训练 timestep、特征抽取 timestep 被拆开,使生成建模、动作去噪和稳定特征读取各自有合适的噪声尺度。
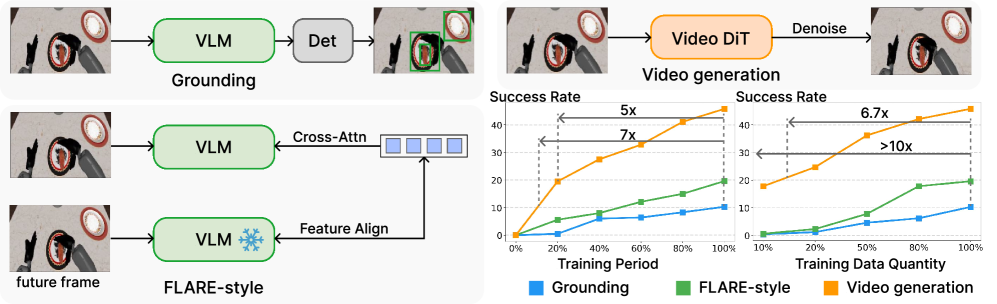
- 系统验证 video generation proxy。作者先比较 Grounding、FLARE-style latent modeling 与 Video generation,报告视频生成在 RoboCasa-GR1 上具有最高数据效率和最快收敛。
- 在仿真与真实 G1 机器人上评估。覆盖 LIBERO、RoboCasa-GR1、真实 Unitree G1、零样本物体/类别/数量变化,以及 layer、denoising step、joint vs. decoupled training 等消融。
2. 动机与相关工作
2.1 要解决的问题
论文的起点是一个很具体的矛盾:VLA 模型已经能把视觉、语言和动作接起来,但它们的骨干多来自静态 image-text 预训练。这样的表征擅长“识别什么物体、理解什么语言”,却没有在预训练阶段被迫学习“物体接下来会怎样运动、手和物体接触后状态如何变化”。因此,低层物理交互和连续时序转移被推迟到下游机器人数据里学习,而机器人 action-labeled 数据昂贵且有限。
作者提出的替代视角是:视频生成模型在预测未来帧时天然要学习时间一致性、运动先验、因果结构与隐式物理动态。与其把它当成外部辅助模型,不如让它成为策略学习的主干之一。
2.2 已有方法卡在哪里
Related Work 将前作分成两条线。第一条是 VLA:RT-2、OpenVLA、UniVLA、CogVLA、GR00T 和 $\pi$ 系列把 VLM 的语义能力迁移到控制上,但共同弱点是底层 backbone 的训练目标主要来自静态图文对。第二条是 video generation in robotics:早期 video prediction 多用于 visual foresight 或 model-based planning;近年的工作开始把 video latents 与 actions 放进共享空间,或用预训练 video backbone 搭配 action decoder。
与本文最接近的是 mimic-video:它也把预训练视频骨干和 flow-matching action decoder 连接起来,并用部分去噪的视频 latent 条件化动作。但 DiT4DiT 的关键差异是 joint training:不是固定或分阶段使用视频模型,而是让视频生成与动作生成在同一目标下共同适配,使动作模块学习在不同视频生成阶段抽取有效特征。
2.3 高层解决思路
DiT4DiT 的高层思路可以概括为“predicting video dynamics - inverse dynamics”。先让 Video DiT 在当前观测和语言目标条件下建模未来视觉动态;但真正供控制使用的不是最终重建的未来帧,而是在某个固定 flow timestep $\tau_f$ 抽出来的中间 hidden states。Action DiT 再以这些 temporally grounded features、机器人 proprioceptive state 和 noisy action trajectory 为条件,通过 flow matching 还原动作序列。
3. 视频生成作为 scaling proxy
论文在正式方法前先做了一个验证实验:比较三种 proxy task 对下游机器人策略学习的作用。
| Proxy task | 训练信号 | 作者关注的局限或优势 |
|---|---|---|
| Grounding | 借鉴 GR00T,训练 VLM 的辅助检测头,学习物体是什么、在哪里。 | 偏语义和目标定位,不能直接学习连续物理动态。 |
| FLARE-style latent modeling | 用 learnable queries 关注 VLM features,并对齐未来观测 latent embeddings;这里去掉 FLARE 的 query diffusion 过程以做近似对照。 | 有 future representation 监督,但仍围绕 VLM latent,作者认为难以捕捉连续 pixel-level physical dynamics。 |
| Video generation | 用 Cosmos-Predict2.5-2B 这类视频骨干预测未来视觉动态。 | 直接以未来视频为无监督信号,迫使模型学习时空动态和物理转移。 |
实验使用 Qwen3-2B 作为 VLM backbone、Cosmos-Predict2.5-2B 作为 Video backbone,并控制 trainable parameters 的规模。评测在 RoboCasa 中 24 个 GR1 tabletop manipulation tasks 上完成。为了让 proxy task 的作用更清楚,作者把 proxy pre-training 与下游 action expert 训练解耦:VLM/Video backbone 先在目标数据上自监督训练,然后在 action expert fine-tuning 阶段冻结。
4. 方法详解
4.1 Flow matching 预备知识
作者用 flow matching 统一视频生成和动作生成。它把干净数据 $x_0$ 与高斯噪声 $z$ 用一条线性概率路径连接起来:
这个公式在构造训练样本:给干净数据加到某个噪声程度 $\tau$,得到中间状态 $x_\tau$。
$$x_{\tau} = (1-\tau)x_0 + \tau z,\quad \tau \in [0,1]$$| $x_0$ | 来自数据分布的干净样本,可以是未来视频 latent 或真实动作序列。 |
| $z$ | 标准高斯噪声,$z \sim \mathcal{N}(0,I)$。 |
| $\tau$ | flow timestep;$\tau=0$ 是干净数据,$\tau=1$ 是纯噪声。 |
由于路径是线性的,目标速度就是对 $\tau$ 求导:
模型学的不是直接输出干净样本,而是在每个噪声位置预测“该往哪个方向流”。
$$v^*(x_\tau,\tau)=\frac{dx_\tau}{d\tau}=z-x_0$$ $$\mathcal{L}_{FM}=\mathbb{E}_{x_0,z,\tau}\left[\left\|v_\theta(x_\tau,\tau)-(z-x_0)\right\|^2\right]$$推理时从噪声出发,沿着预测速度场用 Euler discretization 往 $\tau=0$ 积分:
$$x_{\tau-\Delta\tau}=x_\tau-\Delta\tau\cdot v_\theta(x_\tau,\tau)$$4.2 问题形式化
常见 VLA 直接建模 $\pi_\theta(\mathbf{a}_t\mid \mathbf{o}_t,l)$。DiT4DiT 改写为“先预测未来视觉动态,再从视觉动态反推动作”的范式:
动作不是只看当前帧,而是看当前帧和视频模型关于未来状态的中间生成表征。
$$\mathbf{o}_{t+1}\sim p_v(\cdot\mid \mathbf{o}_t,l)$$ $$\mathbf{a}_t\sim p_a(\cdot\mid \mathbf{o}_t,\mathcal{H}(\mathbf{o}_{t+1}^{\tau_v})),$$ $$\mathbf{o}_{t+1}^{\tau_v}\xrightarrow{\tau_v\to 0}\mathbf{o}_{t+1}$$| $p_v$ | 视频生成分布。 |
| $p_a$ | 动作生成分布。 |
| $\mathcal{H}$ | 从 Video DiT forward pass 中 hook hidden states 的算子。 |
训练目标等价于建模视频和动作的联合分布:
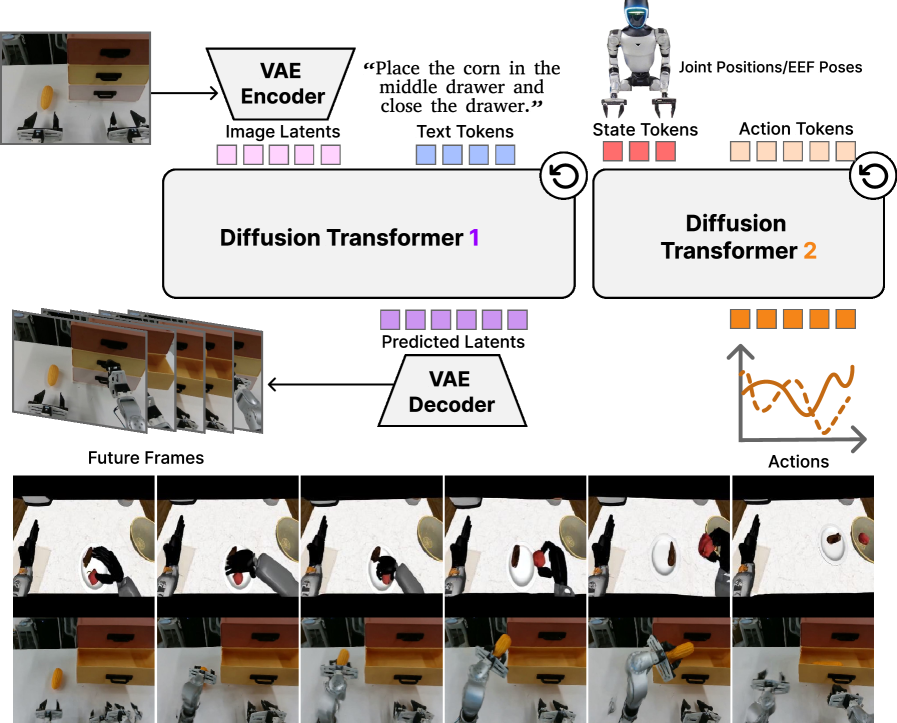
4.3 Dual-DiT architecture
Video DiT。作者用 Cosmos-Predict2.5-2B 初始化视频骨干。其 causal video VAE 将当前观测 $\mathbf{o}_t$ 和未来帧 $\mathbf{o}_{t+1}$ 编码为 latent $\mathbf{z}_t^0,\mathbf{z}_{t+1}^0$;DiT 使用 flow-prediction parameterization,并通过 Cosmos-Reason1 的多层语言 embedding 条件化。关键是,DiT4DiT 不把完整生成帧当作动作输入,而是在指定 flow timestep 和 transformer block 上抽取中间激活:
这个公式在说:把视频生成网络当成“物理动态特征提取器”,hook 它在未来帧去噪过程中的内部表示。
$$\mathbf{h}_t^{\tau_f}=\mathcal{H}[v_\theta^{video}](\mathbf{z}_{t+1}^{\tau_f},\tau_f\mid \mathbf{z}_t^0,l),\quad \mathbf{z}_{t+1}^{\tau_f}\xrightarrow{\tau_f\to 0}\mathbf{z}_{t+1}^0$$| $\mathbf{h}_t^{\tau_f}$ | 供 Action DiT 使用的 temporally grounded hidden features。 |
| $\tau_f$ | 固定特征抽取 timestep;选择哪个噪声阶段会影响动作成功率。 |
| $v_\theta^{video}$ | 视频 DiT 的速度场预测网络。 |
Action DiT。动作模块改自 GR00T-N1 的 action diffusion transformer。它使用 AdaLN 注入动作 diffusion timestep,用 cross-attention 读取 $\mathbf{h}_t^{\tau_f}$。输入序列由 proprioceptive state embeddings、noisy action trajectories 和 learnable future tokens 拼接而成;输出为动作序列的 velocity field。
4.4 Tri-timestep 与联合训练
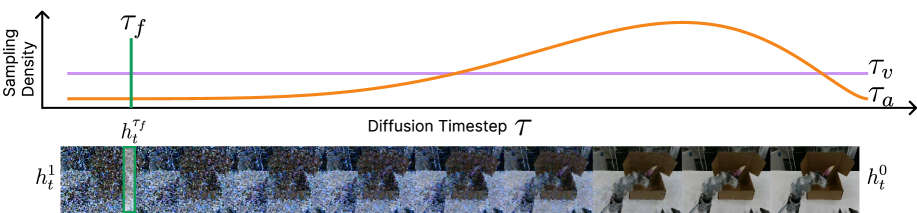
| Timestep | 采样方式 | 功能 |
|---|---|---|
| $\tau_v$ | $\tau_v\sim\mathcal{U}[0,1]$ | 训练视频模块,让它覆盖完整去噪轨迹。 |
| $\tau_f$ | 固定 deterministic timestep;算法框中实现为从离散 buckets 中选择。 | 抽取稳定视觉条件,避免 action module 在训练和推理时收到漂移表征。 |
| $\tau_a$ | $\tau_a=1-\sigma,\ \sigma\sim\mathrm{Beta}(\alpha,\beta)$ | 训练动作模块,把更多容量放在关键控制阶段。 |
总损失由两项组成:动作 flow matching 是主任务,视频 flow matching 用系数 $\lambda$ 保持视频动态建模能力。
$$\mathcal{L}^{total}_t = \mathbb{E}_{\tau_a,\epsilon}\left[\left\|v_\phi^{action}(\mathbf{a}_t^{\tau_a},\tau_a\mid \mathbf{h}_t^{\tau_f},s)-(\epsilon-\mathbf{a}_t^0)\right\|^2\right] +\lambda \mathbb{E}_{\tau_v,z}\left[\left\|v_\theta^{video}(\mathbf{z}_{t+1}^{\tau_v},\tau_v\mid \mathbf{z}_t^0,l)-(z-\mathbf{z}_{t+1}^0)\right\|^2\right]$$| $s$ | 机器人 proprioceptive state。 |
| $\mathbf{a}_t^0$ | 真实动作轨迹。 |
| $\epsilon$ | 动作噪声。 |
| $\lambda$ | 视频损失的权重。 |
4.5 训练与推理流程
encode current and future observations with frozen VAE
sample video timestep tau_v and noise z
construct noisy future latent z_{t+1}^{tau_v}; predict video velocity
sample or choose feature timestep tau_f; hook hidden states h_t^{tau_f}
sample action timestep tau_a from Beta schedule and action noise epsilon
construct noisy action a_t^{tau_a}; predict action velocity with h_t^{tau_f} and state s
optimize L_action + lambda * L_video, with action mask M when computing action loss
optionally generate future video by Euler sampling through Video DiT
for action prediction, draw one future noise latent and run a single deterministic feature extraction at tau_f
initialize action from Gaussian noise
Euler integrate Action DiT for N_a steps to produce final action trajectory
这里最容易误读的一点是:真实控制不需要先完整生成视频。论文强调动作条件只需要一个固定 timestep 的单次 hidden feature extraction;这也是后面消融中“一步 denoising 最好”的原因之一。
5. 实验、结果与复现设置
5.1 实验设置
| 评测场景 | 机器人/动作空间 | 数据与评测 |
|---|---|---|
| LIBERO | Franka Emika Panda,7-DoF | Spatial/Object/Goal/Long 四个 suite;每类标准数据含 500 条 demonstration,10 个任务。 |
| RoboCasa-GR1 tabletop | Fourier GR1 humanoid:双 7-DoF arms、双 6-DoF dexterous hands、3-DoF waist,29 维 action space | 24 个 household manipulation tasks;每任务 1,000 条 human-collected trajectories;每任务 50 个 rollouts,最大 720 environment steps。 |
| Real-world G1 | Unitree G1 humanoid,双 7-DoF arms + ALOHA2 grippers,连续 16-DoF action space;只用 ego-view camera | 7 个真实任务,每任务 200 条 teleop demonstrations;每任务 20 次真实 rollout。 |
仿真实验中,DiT4DiT 和参数匹配 baseline Qwen3DiT 都从 scratch 训练;外部 baselines 使用官方开源预训练权重。真实实验中,DiT4DiT 先在 241,450 条 simulated GR1 episode 上预训练,再用真实 G1 teleop 数据 fine-tune;Qwen3DiT 走完全相同 pipeline;GR00T-N1.5 则从官方预训练权重初始化。作者强调 DiT4DiT 的预训练数据量约为 GR00T-N1.5 所用数据规模的 15%。
5.2 附录整合:模型与训练配置
| 模块 | 关键配置 |
|---|---|
| Video DiT | Base VGM: Cosmos-Predict2.5-2B;attention: flash_attention_2;hidden feature dim 2048;extract layer 18。 |
| Action DiT | DiT-B;hidden size 2560;max sequence length 1024;action dim 32;state dim 64;future action window 15;action horizon 16;cross attention dim 2048;dropout 0.2;AdaLN;16 layers;num inference timesteps 4。 |
| Training | per-device batch size 8;32 GPUs;max train steps 100,000;warmup steps 5,000;VGM LR $1\times10^{-5}$;Action LR $1\times10^{-4}$;cosine_with_min_lr;min LR $5\times10^{-7}$;gradient clipping 1.0;AdamW,$(\beta_1,\beta_2)=(0.9,0.95)$;weight decay $1\times10^{-8}$。 |
附录 A.1 这些配置对复现很关键,尤其是 extract layer 18、action inference timesteps 4、Video/Action 两个学习率相差 10 倍。
| Dataset | Episode count | Embodiment | DoF |
|---|---|---|---|
| Fourier_GR1_Unified_1K | 24,000 | GR1 humanoid | 29 |
| Fourier_GR1_Pretrain_10K | 241,450 | GR1 humanoid | 29 |
| LIBERO | 1,693 | Franka Emika Panda | 7 |
| Real Robot | 1,400 | G1 humanoid | 16 |
附录 A.2 数据集配置说明:仿真 benchmark 直接用目标数据训练;真实机器人前先用 Fourier_GR1_Pretrain_10K 做 sim pre-training,再用 1,400 条真实 teleop episode fine-tune。
5.3 LIBERO 主要结果
| Method | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|
| Diffusion Policy | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Dita | 97.4 | 94.8 | 93.2 | 83.6 | 92.3 |
| $\pi_0$ | 96.8 | 98.8 | 95.8 | 85.2 | 94.2 |
| UniVLA | 96.5 | 96.8 | 95.6 | 92.0 | 95.2 |
| $\pi_{0.5}$ | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| OpenVLA-OFT | 97.6 | 98.4 | 97.9 | 94.5 | 97.1 |
| CogVLA | 98.6 | 98.8 | 96.6 | 95.4 | 97.4 |
| GR00T-N1.5 | 96.2 | 94.0 | 96.0 | 90.0 | 94.1 |
| Qwen3DiT (from scratch) | 98.0 | 98.8 | 96.0 | 93.6 | 96.6 |
| DiT4DiT (from scratch) | 98.4 | 99.6 | 98.6 | 97.6 | 98.6 |
作者强调两个点:第一,DiT4DiT 在 Object、Goal、Long 三个 suite 取最高值;第二,Long suite 的 97.6% 被用来支撑“显式建模 spatiotemporal dynamics 有助于多阶段长时序执行”的论点。
5.4 RoboCasa-GR1 主要结果
| Task | GR00T-N1.5 | GR00T-N1.6 | Qwen3DiT | DiT4DiT |
|---|---|---|---|---|
| BottleToCabinetClose | 40.0 | 36.0 | 50.0 | 48.0 |
| CanToDrawerClose | 56.0 | 28.0 | 48.0 | 74.0 |
| CupToDrawerClose | 50.0 | 12.0 | 42.0 | 52.0 |
| MilkToMicrowaveClose | 52.0 | 20.0 | 38.0 | 50.0 |
| PotatoToMicrowaveClose | 22.0 | 28.0 | 18.0 | 36.0 |
| WineToCabinetClose | 44.0 | 18.0 | 28.0 | 42.0 |
| FromCuttingboardToBasket | 46.0 | 42.0 | 42.0 | 52.0 |
| FromCuttingboardToCardboardbox | 44.0 | 40.0 | 30.0 | 48.0 |
| FromCuttingboardToPan | 58.0 | 62.0 | 50.0 | 76.0 |
| FromCuttingboardToPot | 48.0 | 60.0 | 44.0 | 62.0 |
| FromCuttingboardToTieredbasket | 28.0 | 48.0 | 36.0 | 50.0 |
| FromPlacematToBasket | 32.0 | 42.0 | 14.0 | 50.0 |
| FromPlacematToBowl | 52.0 | 34.0 | 28.0 | 56.0 |
| FromPlacematToPlate | 42.0 | 42.0 | 40.0 | 32.0 |
| FromPlacematToTieredshelf | 26.0 | 24.0 | 30.0 | 18.0 |
| FromPlateToBowl | 38.0 | 48.0 | 36.0 | 56.0 |
| FromPlateToCardboardbox | 40.0 | 44.0 | 36.0 | 58.0 |
| FromPlateToPan | 56.0 | 48.0 | 34.0 | 68.0 |
| FromPlateToPlate | 50.0 | 66.0 | 44.0 | 58.0 |
| FromTrayToCardboardbox | 36.0 | 42.0 | 48.0 | 38.0 |
| FromTrayToPlate | 54.0 | 52.0 | 44.0 | 56.0 |
| FromTrayToPot | 36.0 | 64.0 | 34.0 | 54.0 |
| FromTrayToTieredbasket | 34.0 | 42.0 | 36.0 | 46.0 |
| FromTrayToTieredshelf | 22.0 | 38.0 | 18.0 | 38.0 |
| Average | 41.8 | 40.8 | 36.2 | 50.8 |
DiT4DiT 在 24 个任务中 16 个取得最高成功率,平均 50.8%,高于 GR00T-N1.5 9.0 个百分点、高于 GR00T-N1.6 10.0 个百分点、高于参数匹配的 Qwen3DiT 14.6 个百分点。作者尤其点名 CanToDrawerClose、FromCuttingboardToPan、FromPlateToPan 等对空间协调和物理交互要求较高的任务。
5.5 真实机器人与泛化结果

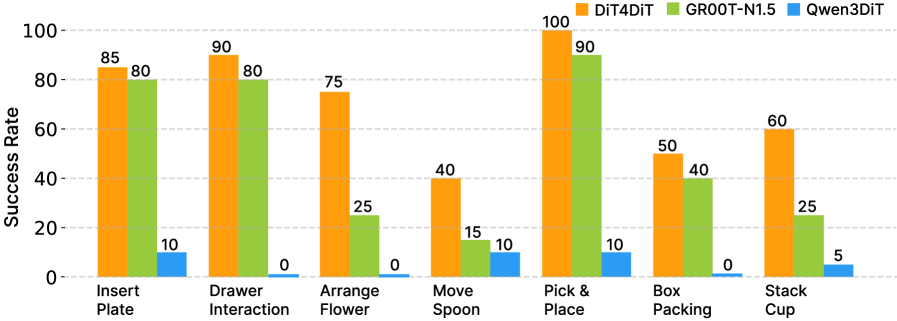
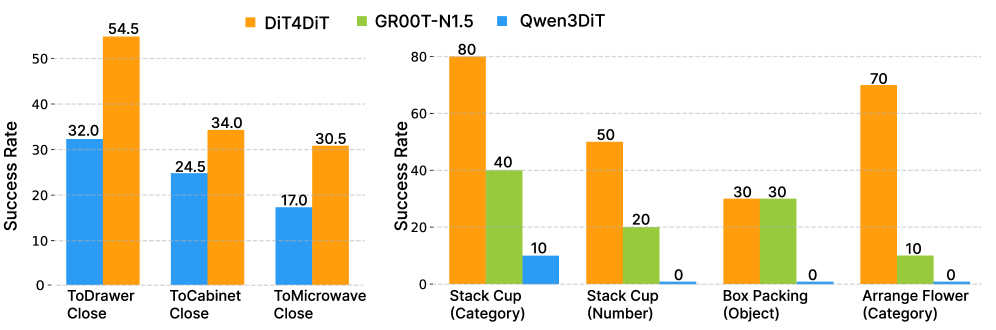
真实实验部分的关键对照是:Qwen3DiT 走同样 sim pre-training + real fine-tuning pipeline,但在真实任务中几乎崩溃,所有任务不超过 10%,Drawer Interaction、Arrange Flower、Box Packing 为 0%。DiT4DiT 仍能在只用单个 ego camera 的条件下完成高精度任务,作者将其归因于视频生成 backbone 对未来动态和细粒度视觉细节的保留。

6. 图表与消融解读
6.1 Feature extraction layer
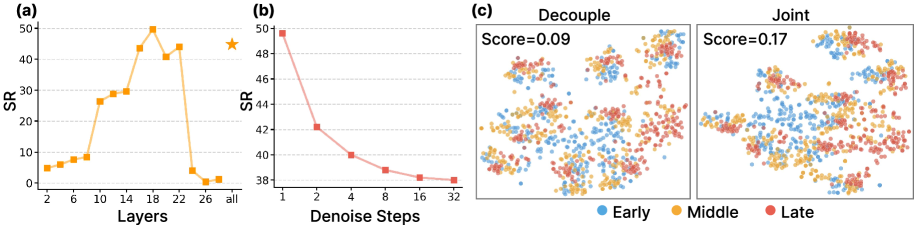
作者在 RoboCasa-GR1 的 5 个任务上测试不同 video transformer block 的 hidden states,包括 CanToDrawerClose、FromCuttingboardToBasket、FromPlacematToBowl、FromPlateToCardboardbox、FromTrayToPot。早期层 2-8 表现差,作者解释为更偏低层纹理;中深层逐步变好,并在 layer 18 达到峰值;最后层 24-28 出现明显下降,作者认为末端层更专注视频去噪和像素重建,反而丢掉 control-relevant abstraction。因此默认选择第 18 层。附录 A.1
6.2 Denoising steps
对 action conditioning 来说,单步 denoising 的表现最高,steps 从 1 增至 32 时成功率单调下降。论文的解释是:过多迭代会让 hidden states 过度承诺到某个具体重建未来的像素细节,削弱可泛化的 action priors。这个结论也有工程意义:真实控制可以绕开多步视频生成,只做单次 forward feature extraction。
6.3 Joint vs. decoupled training
t-SNE 可视化显示,decoupled training 的特征虽然形成 task clusters,但 cluster 内时间阶段更碎片化;joint training 后 Early/Middle/Late 的阶段过渡更清楚,silhouette score 从 0.09 提升到 0.17,约两倍。作者用这一点支撑“联合训练让视觉 backbone 嵌入连续、物理感知的 temporal progression”。
6.4 系统与生成计划图


6.5 部署效率
| Model | Trainable params | Deployment frequency |
|---|---|---|
| GR00T-N1.5 | 2.7B | 13 Hz |
| Qwen3DiT | 2.3B | 9 Hz |
| DiT4DiT | 2.2B | 6 Hz |
DiT4DiT 不是靠更大 trainable parameter count 获得结果;它反而是三者中最小的 2.2B。代价是控制频率降低到 6 Hz。作者指出对于固定任务,LLM features 可预提取和缓存,因为 DiT4DiT policy learning 不训练 LLM 组件,这能改善有效部署频率。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
从论文自身论证看,最核心的价值不是“又做了一个 VLA baseline”,而是把 video generation 明确当作机器人策略学习的 scaling proxy,并用同一篇论文中的三层证据闭环支撑:先用 proxy task 对照说明 video generation 比 Grounding/FLARE-style 更高效;再用 dual-DiT + dual flow matching 给出端到端实现;最后用 LIBERO、RoboCasa-GR1、真实 Unitree G1 和 zero-shot generalization 验证这种 proxy 能转化为控制性能。
7.2 结果为什么站得住
论文的结果支撑来自多个相互补位的对照。第一,Qwen3DiT 是参数匹配 baseline,并共享 Action DiT,这使“静态 VLM prior vs. 视频生成 prior”的差异更清楚。第二,仿真和真实实验都报告了细分任务而不只是平均值;RoboCasa-GR1 的 24 任务表显示 DiT4DiT 不是只在少数任务上拉高平均。第三,消融覆盖了 feature extraction layer、denoising steps 和 joint vs. decoupled training,对方法里的关键设计分别给出证据。第四,附录提供训练配置、数据配置和真实系统硬件,能解释作者的资源与数据条件。
7.3 作者自述的局限
附录 A.4 作者明确承认真实部署只依赖单个 egocentric camera。虽然这凸显了视频表征的空间推理能力,但 single-view setup 容易受到严重遮挡影响,尤其在复杂双臂任务中,机器人手臂或大物体可能暂时挡住视线,从而破坏视觉特征的时间连续性。作者提出未来可加入 wrist-mounted cameras 或 tactile feedback,并与 Video DiT backbone 融合,以在遮挡下维持更稳健的 state estimation。
第二个边界与数据规模相关。作者指出真实 zero-shot generalization 只用了约 GR00T 数据量 15% 的 pre-training corpus,但下一步仍需要把预训练数据扩展到更多 embodiment,例如不同 kinematics、grippers 和 camera parameters。也就是说,论文展示了 data-efficient 的趋势,但更大规模 cross-embodiment foundation model 仍是未来方向。
7.4 适用边界
- 适合的场景:需要连续控制、物理动态、时序状态转移、长 horizon 操作的机器人任务,尤其当静态语义表征不足以描述接触和运动过程时。
- 当前约束:需要大型视频 DiT、Action DiT 和较高训练资源;附录配置为 32 GPUs、100k steps,对普通实验室复现并不轻。
- 部署取舍:6 Hz 控制频率可用于论文任务,但相比 GR00T-N1.5 的 13 Hz 和 Qwen3DiT 的 9 Hz 更慢;如果任务需要更高频闭环控制,需要额外优化缓存、蒸馏或轻量化。
- 数据解释:真实任务并非完全无预训练,DiT4DiT 使用了 241,450 条 simulated GR1 episode,再 fine-tune 1,400 条真实 G1 episode;读结果时要区分仿真 from scratch 和真实两阶段 pipeline。
8. 复现审计
代码与模型
可定位:论文和项目页给出代码仓库 https://github.com/Mondo-Robotics/DiT4DiT。arXiv 摘要说明 code and models 会在项目页发布;项目页明确提供 Code 链接。
模型初始化
较清楚:Video DiT 初始化自 Cosmos-Predict2.5-2B;语言条件来自 Cosmos-Reason1 embeddings;Action DiT adapted from GR00T-N1。附录列出 action model 维度、层数、dropout、timestep 数和优化器。
数据
部分依赖外部/自采数据:LIBERO 和 RoboCasa-GR1 相关数据可按公开 benchmark 路径寻找;真实 G1 数据是作者自采 1,400 条 teleop episode,复现真实结果需要相近硬件、VR teleoperation pipeline 与数据采集过程。
算力
成本较高:附录训练配置为 32 GPUs、100,000 steps、per-device batch size 8。真实部署推理在单张 RTX 4090 workstation 上运行;部署效率表另报告 single A100 下 6 Hz。
最小复现实验建议
若目标是验证核心机制而非复现完整 SOTA,可先在 RoboCasa-GR1 的 5 个消融任务上复现 layer 18 / one-step feature extraction / joint training 三个关键设置;它们正好对应论文的主要设计证据。