Fast-WAM: Do World Action Models Need Test-time Future Imagination?
1. Quick overview of the paper
| What should the paper solve? | Existing WAM often uses imagine-then-execute: first iteratively generate future vision, and then predict actions based on the future vision. This brings high test-time latency, but it is not clear whether "video modeling during training" is useful or "explicit future imagination during inference" is useful. |
|---|---|
| The author's approach | Construct Fast-WAM and three controlled variants: Fast-WAM-Joint, Fast-WAM-IDM, Fast-WAM w.o. video co-train, and decouple video co-training and test-time future generation under a unified backbone/training recipe. |
| most important results | Fast-WAM reaches 91.8% in RoboTwin 2.0, and LIBERO averages 97.6% without embodied pretraining; after removing video co-training, it drops to 83.8% and 93.5% respectively. In the real towel folding task, Fast-WAM has a delay of 190 ms, while Fast-WAM-IDM is 810 ms; no-video-co-train only has a 10% success rate. |
| Things to note when reading | Fast-WAM does not negate the world model, but repositions the role of the world model: it may be more like a representation shaping signal in the training phase, rather than a video plan that must be explicitly generated during deployment. |
Difficulty rating: ★★★★☆. Need to understand WAM/VLA, video diffusion transformer, flow matching, action chunk diffusion, attention mask to prevent future leakage, and simulation/real robot evaluation.
Keywords: World Action Model, video co-training, test-time future imagination, flow matching, Mixture-of-Transformer, Wan2.2-5B, LIBERO, RoboTwin, towel folding.
2. Motivation
2.1 The attraction and cost of WAM
Standard VLA directly maps visual observations and language to actions, mainly inheriting the semantic priors of web-scale visual language pre-training. But robot control also requires an understanding of how the physical world evolves under action. The appeal of WAM is to put future visual prediction and action modeling into the same framework, allowing the policy to explicitly contact the task-relevant temporal structure.
The problem is that most WAMs iterate over denoise future videos during inference and then generate actions based on this imagined future. Iterative sampling of video diffusion is very expensive, and every few hundred milliseconds in a real robot closed loop may slow down and blunt the strategy.
2.2 The real question the paper asks
Core questions: Where does WAM's revenue come from? Does predicting future videos during training allow the backbone to learn physical/motion representations, or does explicitly generating future observations during inference really give the foresight necessary for action prediction?
This question used to be difficult to answer because many WAMs tied two factors together: the same model both learned video predictions during training and generated future videos during testing. The contribution of Fast-WAM is to separate these two things and use controlled variables to experimentally determine which is more important.
4. Detailed explanation of method
4.1 Formalization of the problem
Suppose the current observation is $o$, the task language is $l$, and the action chunk is $a_{1: H}$. Standard visuomotor policy learning:
A typical imagine-then-execute WAM introduces future vision $v_{1: T}$, written as:
Intuition: First imagine the future, then generate actions based on your imagination. The price is sampling or denoise $v_{1: T}$ during inference.
Fast-WAM is changed to a direct policy interface:
Among them, $z(o, l)$ is the latent world representation obtained by the video backbone in a single forward direction of the current context. Key difference: $z(o, l)$ is not a future video generated during inference, but the current representation shaped by video co-training during training.
4.2 Architecture: Wan2.2 video DiT + action expert DiT
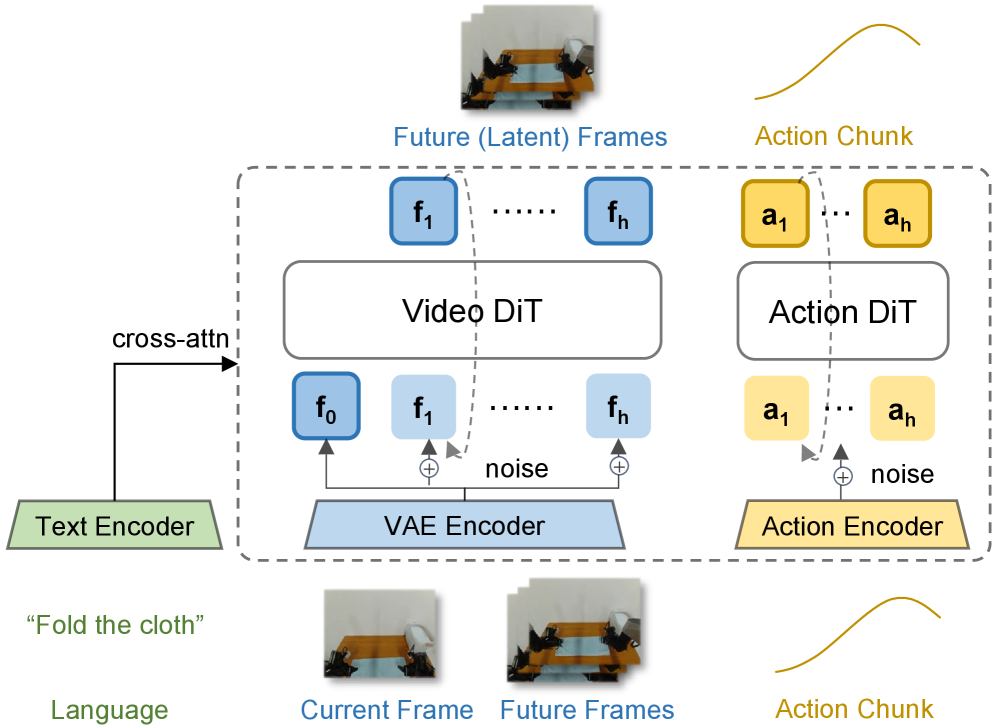
Model input tokens are divided into three groups:
- clean first-frame latent tokens: The clean latent of the current observation is the shared visual anchor.
- noisy future video latent tokens: Only exists during training and is used for future video flow matching.
- action tokens: Handled by action experts for action chunk generation.
All tokens receive language embedding via cross-attention. A Mixture-of-Transformer structure is used between the video and action branches, and a structured attention mask is used to control the information flow.
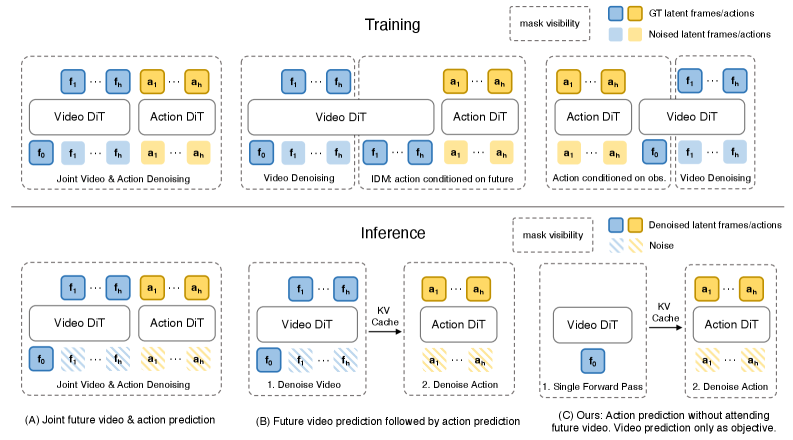
4.3 Attention mask: share context and prevent future leakage
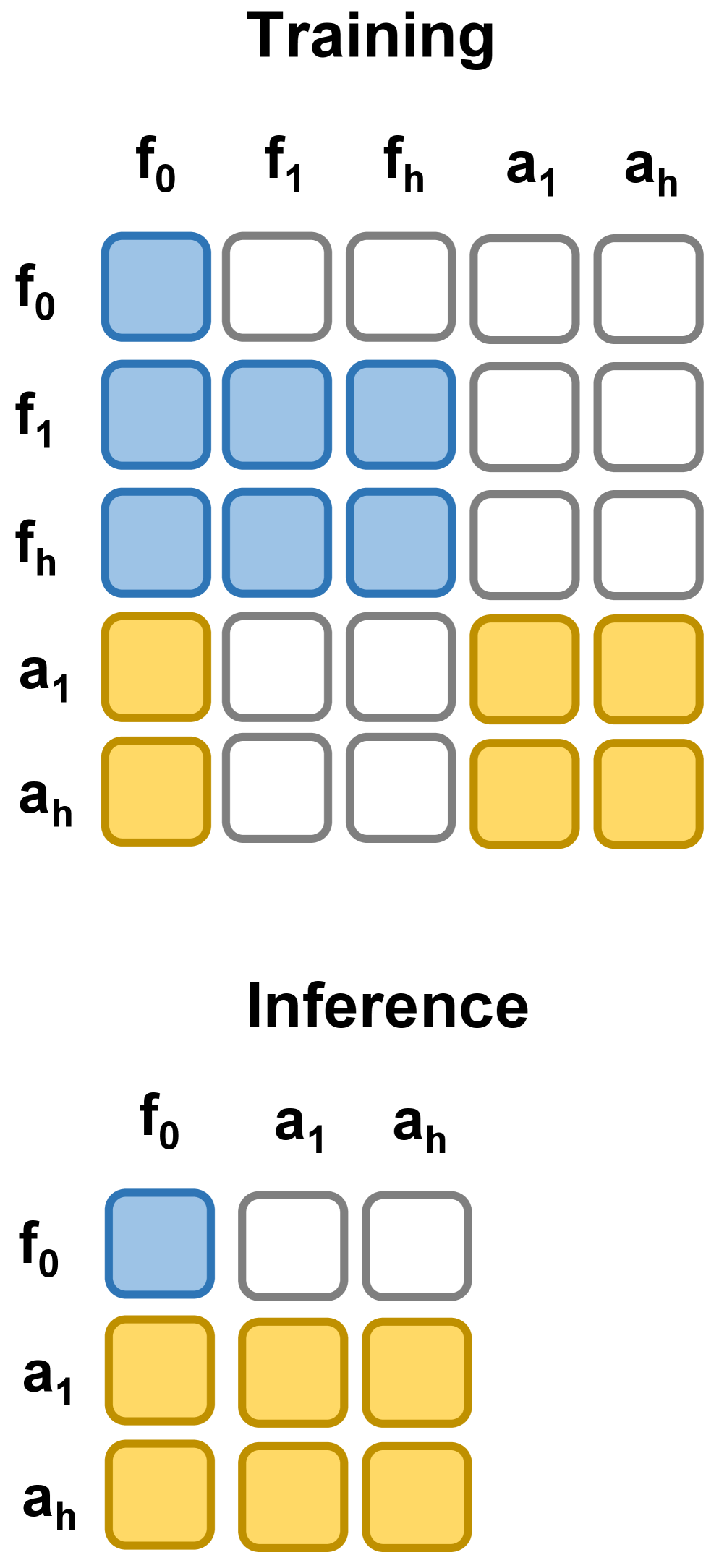
During training, future video tokens have bidirectional attention within the video branch and can access first-frame tokens; action tokens have bidirectional attention within the action branch and can also access first-frame tokens. The most critical constraint is that action tokens cannot attend to future video tokens. In this way, video modeling and action prediction both rely on the same current visual context, but the action does not peek into the ground-truth future.
During inference, the future video branch is completely deleted: only the first-frame latent tokens are retained, the video backbone generates latent world features in a single forward direction, and then performs action denoising for the action expert.
4.4 Training goal: action loss + video co-training loss
Fast-WAM uses the same flow matching form for both actions and videos. For any target variable $y$, which can be action chunk $a_{1: H}$ or future video latents $z_{1: T}$, sample noise $\epsilon\sim\mathcal{N}(0, I)$ and time step $t\in(0, 1)$:
Train the model to predict the velocity field from data to noise:
$$\mathcal{L}_{\mathrm{FM}}(y)= \mathbb{E}_{y, \epsilon, t} \left[ \left\|f_\theta(y_t, t, o, l)-(\epsilon-y)\right\|_2^2 \right].$$The actions and videos are:
$$\mathcal{L}_{\mathrm{act}}=\mathcal{L}_{\mathrm{FM}}(a_{1: H}), \qquad \mathcal{L}_{\mathrm{vid}}=\mathcal{L}_{\mathrm{FM}}(z_{1: T}).$$Total loss:
$$\mathcal{L}=\mathcal{L}_{\mathrm{act}}+\lambda\mathcal{L}_{\mathrm{vid}}.$$Intuition: $\mathcal{L}_{\mathrm{vid}}$ is not necessarily for generating video during inference, but as a world representation regularizer / co-training signal.
4.5 Three controlled variants
| Variants | video co-training | reasoning future imagination | function |
|---|---|---|---|
| Fast-WAM | Yes | None | Main method: retain the training signal and remove the inference cost. |
| Fast-WAM-Joint | Yes | Yes, video/action joint denoising | Simulate joint-modeling WAM to allow video and action tokens to pay attention to each other. |
| Fast-WAM-IDM | Yes | Yes, video-then-action | First generate future video, and then use future representation to predict actions; use LingBot-VA to do ground-truth video token noise augmentation, $p=0.5$. |
| Fast-WAM w.o. video co-train | None | None | Only remove $\mathcal{L}_{\mathrm{vid}}$ to control the contribution of video co-training. |
5. Experiment
5.1 Implementation details
- Backbone: Wan2.2-5B, including video DiT, T5 text encoder and video VAE.
- Action expert: Isomorphic to the video branch but the hidden dimension is reduced to $d_a=1024$; the action expert is about 1B, and the total model has about 6B parameters.
- Action horizon: $h=32$.
- Video chunk: The video frame time is downsampled to $4\times$, each chunk is 9 frames; multi-camera images are first assembled into one picture and then sent to VAE.
- Flow matching: Training/inference uses logit-normal $t$ schedule; inference action denoising 10 steps, CFG scale 1.0.
- Optimization: AdamW, learning rate $1\times10^{-4}$, weight decay 0.01, cosine annealing, mixed precision, gradient clipping 1.0.
- Latency measurement: Single NVIDIA RTX 5090D V2 32GB.
5.2 Benchmark settings
| Benchmark | Data and training | Assessment |
|---|---|---|
| LIBERO | Four suites: Spatial, Object, Goal, Long; each suite has 10 tasks, 500 demos; training 20k steps. | 40 tasks, different random seeds, a total of 2000 trials, reporting success rate. |
| RoboTwin 2.0 | 50+ dual-arm tasks; 2500 clean demos + 25000 heavy-randomization demos; training 30k steps. | 100 trials per task, reporting clean and randomized average success rates. |
| Real-world towel folding | Galaxea R1 Lite platform, 60 hours teleoperated demonstrations; training 30k steps. | Report success rate and average completion time; towel folding tests deformable object dynamics, long-term planning, and closed-loop operational efficiency. |

5.3 RoboTwin 2.0 Main Results
| Method | Embodied PT. | Clean | Rand. | Average |
|---|---|---|---|---|
| $\pi_0$ | Yes | 65.92 | 58.40 | 62.2 |
| $\pi_{0.5}$ | Yes | 82.74 | 76.76 | 79.8 |
| Motus | Yes | 88.66 | 87.02 | 87.8 |
| Motus from WAN2.2 | No | 77.56 | 77.00 | 77.3 |
| LingBot-VA | Yes | 92.90 | 91.50 | 92.2 |
| LingBot-VA from WAN2.2 | No | 80.60 | -- | 80.6 |
| Fast-WAM | No | 91.88 | 91.78 | 91.8 |
Fast-WAM does not use embodied pretraining, but reaches 91.8%, which is significantly higher than Motus from WAN2.2 (77.3) and LingBot-VA from WAN2.2 (80.6), which also have no embodied pretraining, and is close to LingBot-VA with embodied pretraining (92.2). Appendix Table 3 gives RoboTwin clean/rand details for each task; overall, Fast-WAM competes with the strongest baseline on many tasks, but the average value of no-video-co-train is significantly lower. Appendix Table 3.
5.4 LIBERO main results
| Method | Embodied PT. | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|---|
| OpenVLA | Yes | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| $\pi_0$ | Yes | 96.8 | 98.8 | 95.8 | 85.2 | 94.1 |
| $\pi_{0.5}$ | Yes | 98.8 | 98.2 | 98.0 | 92.4 | 96.9 |
| LingBot-VA | Yes | 98.5 | 99.6 | 97.2 | 98.5 | 98.5 |
| Motus | Yes | 96.8 | 99.8 | 96.6 | 97.6 | 97.7 |
| Fast-WAM | No | 98.2 | 100.0 | 97.0 | 95.2 | 97.6 |
The average Fast-WAM on LIBERO is 97.6%, exceeding $\pi_{0.5}$'s 96.9, and close to Motus/LingBot-VA. It does not have embodied pretraining, which is a data efficiency point emphasized by the author.
5.5 Control variables: future imagination vs video co-training
| Variant | RoboTwin Avg. | LIBERO Avg. | explain |
|---|---|---|---|
| Fast-WAM | 91.8 | 97.6 | There is video co-training for training, and there is no future imagination for reasoning. |
| Fast-WAM-Joint | 90.6 | 98.5 | joint denoise future video/action, explicit reasoning imagination. |
| Fast-WAM-IDM | 91.3 | 98.0 | First generate future video, and then action prediction. |
| Fast-WAM w.o. video co-train | 83.8 | 93.5 | The inference is the same as Fast-WAM, but the video modeling objective is removed from the training. |
This is the key evidence of the paper: the gap between Fast-WAM and the two imagine-then-execute variants is small; but the drop is more obvious after removing video co-training. RoboTwin dropped from 91.8 to 83.8, LIBERO dropped from 97.6 to 93.5, and LIBERO Spatial/Long dropped particularly significantly. Based on this, the authors believe that the main value of WAM is more likely to come from the video prediction goal during training, rather than actually generating future videos during inference.
5.6 Real Towel Folding: Performance and Latency
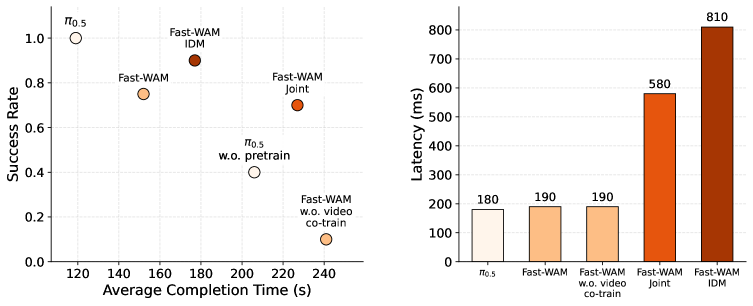
In real tasks, pre-training $\pi_{0.5}$ is still the strongest method, with the highest success rate and the shortest completion time. The performance between Fast-WAM families is similar: Fast-WAM-IDM has the highest success rate, and Fast-WAM completion time is better. More importantly, all Fast-WAM variants with video co-training are significantly stronger than $\pi_{0.5}$ without pretraining, while no-video-co-train collapses to 10% success. This again supports video co-training as the main reason.
In terms of latency, Fast-WAM is 190 ms, which is of the same order as no-video-co-train's 190 ms; Fast-WAM-Joint is 580 ms, and Fast-WAM-IDM is 810 ms. Fast-WAM therefore becomes a better compromise for deployment: retain most of WAM performance but avoid explicit future video sampling overhead.
6. Reproducible auditing
6.1 Components required to reproduce
| components | Paper information | Note for recurrence |
|---|---|---|
| Backbone | Wan2.2-5B video DiT + T5 text encoder + video VAE. | Requires loadable Wan2.2-5B; higher memory/parameter scale. |
| Action expert | DiT, isomorphic to video branch, hidden dim 1024, about 1B. | Be careful when aligning action tokens, time step embedding, cross-attention and video branches. |
| training objectives | $\mathcal{L}_{act}+\lambda\mathcal{L}_{vid}$. | The paper does not clearly give the value of $\lambda$ in the main text. reproducibility experiments need to be confirmed from the code or default configuration. |
| data | LIBERO, RoboTwin 2.0, Real Galaxea R1 Lite Towel Fold 60 Hours Data. | Simulation has high reproducibility; real data and hardware are more difficult to completely reproduce. |
| Delay measurement | Single NVIDIA RTX 5090D V2 32GB. | Latency across GPUs is not directly comparable; action denoising steps and batch settings are reported. |
6.2 Minimum recurrence route
- First implement Fast-WAM w.o. video co-train on LIBERO: only use the current first-frame latent + language + action DiT to run through action flow matching.
- Add future video latent branch and $\mathcal{L}_{vid}$, but keep action tokens and cannot see future video tokens to verify whether Fast-WAM is improved.
- Implement Fast-WAM-Joint: Release the mutual attention of action/video tokens and test whether it is close to Fast-WAM.
- Implement Fast-WAM-IDM: first generate future video representation, then condition action; note the use of $p=0.5$ ground-truth video token noise augmentation.
- Reproduce the LIBERO table and then migrate to RoboTwin multi-task training; finally consider real towel folding.
- Delay evaluation must be done separately: Fast-WAM has no future branch, but still has 10 steps of action denoising; the additional overhead of IDM/Joint comes from future video generation/joint sampling.
6.3 Recurrence risk points
| risk | Why is it important | Suggestions |
|---|---|---|
| $\lambda$ is not given in the text | The strength of video co-training directly affects the conclusion. | Prioritize checking the official code configuration; if not, do $\lambda$ sweep. |
| The mask implementation is prone to leaking futures | If action tokens can see ground-truth future video, the results will be artificially high. | Write unit tests to check attention mask reachability. |
| Multi-camera puzzle input details | Multiple cameras concat to a single image before entering VAE, which affects token layout. | Keep camera order, resolution, crop/resize consistent. |
| Real towel data cannot be publicly verified | 60 hours of teleoperation and hardware platforms have a big impact. | Treat real results as deployment evidence, and structural conclusions mainly look at simulation control variables. |
| Pre-training fairness | Different baselines use embodied pretraining or not mixed in the same table. | Group comparison during reading: The method of using both no embodied PTs is the fairest. |
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
The most valuable thing is the problem solving itself. Many WAM papers default to "generating future videos" as a necessary step, but Fast-WAM splits it into two factors: training goal and inference mechanism, and verifies it with variants in the same framework. This experimental design is more instructive than simply proposing a new model: it tells us that the value of the world model may be mainly reflected in the training representation, rather than the explicit imagination at deployment time.
The second value point is deployment orientation. The gap of 190 ms vs 580/810 ms is realistic for real robots. Fast-WAM brings WAM close to the inference interface of VLA while retaining the WAM training signal, which is a very practical compromise.
7.2 Why the results hold up
- Control variables are clear: The backbone and training recipes of Fast-WAM, Joint, IDM, and no-co-train should be aligned as much as possible.
- Consistent across benchmarks: RoboTwin, LIBERO, and real towel folding all show that the video co-training drop is larger than the future imagination variant gap.
- The efficiency indicators are clear: Real tasks report not only success, but also completion time and latency.
- Appendix fine-grained support: The RoboTwin per-task table shows that the improvement does not only come from a few tasks, but the average drop in no-co-train is obvious in clean/rand.
7.3 Limitations and points that need to be questioned
| question | influence |
|---|---|
| The conclusion is that "future imagination is not so critical", not "completely useless" | Joint/IDM on LIBERO is still slightly higher than Fast-WAM; Fast-WAM-IDM has the highest success rate in real tasks. But whether their gains are worth the delay cost depends on the deployment scenario. |
| Only study single action chunk | The authors omit outer autoregressive rollout for control variables; whether explicit future imagination is more useful in longer tasks remains to be verified. |
| The only real task is towel folding | Deformable objects are challenging, but a single real-world task is not enough to cover all robot operations. |
| The model is very large | 6B model + Wan2.2-5B backbone, high threshold for reproducibility and deployment. |
| Training details still depend on the code | The text gives most of the optimization parameters, but for key configurations such as $\lambda$, you need to check the official code. |
7.4 Questions that can be asked in group meetings
- Will test-time future imagination become important again if the task requires explicit intermediate subgoals, such as complex assembly or navigation?
- What exactly does the representation learned by Fast-WAM's video co-training encode? Can probing/attention/feature prediction be used to prove that it captures physical dynamics?
- Action tokens cannot see future video tokens, but the video branch and action branch share the first-frame anchor; is this mask optimal, or is there a thinner causal mask?
- Wan2.2 is a general-purpose video generation backbone. After switching to the robot video pre-training backbone, will the gap between Fast-WAM and Joint/IDM become larger or smaller?
- Fast-WAM has better completion time than IDM in real tasks, but its success rate is not necessarily the highest. How should the actual system choose between delay, success rate and action stability?
Attachment: This report covers inspections
Covered: Abstract, Introduction, Related Work, Method, Experiment, Conclusion, and RoboTwin per-task results in Appendix.
Chart processing: PNG images and source code images rendered using arXiv HTML are saved in figures/; Key tables have been rebuilt into HTML.
Residual risk: Real towel folding training data is not a public benchmark; complete reproducibility still relies on official code configuration, especially $\lambda$ and specific data processing.