GigaWorld-Policy: An Efficient Action-Centered World--Action Model
1. Quick overview of the paper
| What should the paper solve? | Existing VLA only relies on sparse action label learning, and the supervision density is insufficient; existing WAM often strongly couples "future video generation" and "action prediction", and a large number of video tokens must be sampled during inference, resulting in high latency, and action quality is easily affected by future video prediction errors. |
|---|---|
| The author's approach | Change WAM to action-centered: the model first predicts action chunks and action latents, and then uses these action conditions to predict future videos. The causal attention mask ensures that the action token cannot see future video tokens, so only the action branch can be sampled during inference, and the video branch is only a dynamic constraint and optional diagnostic output during training. |
| most important results | On RoboTwin 2.0, the GigaWorld-Policy average success rate Clean/Rand is 0.87/0.85, close to Motus's 0.89/0.87, but inference drops from Motus's 3231 ms to 360 ms; the real four-task average success rate is 0.83, higher than Motus 0.76, $\pi_{0.5}$ 0.69 and GigaBrain-0 0.68. |
| Things to note when reading | The proposition of this article is not that "video prediction must be done during inference", but "use future videos as high-density physical supervision during training, and action paths are independently available during inference." Therefore, the information flow design of causal mask is the most critical reproducible detail of the full text. |
2. Problem background and motivation
2.1 Why VLA alone is not enough
The VLA model usually learns $a_{t: t+p-1}\sim q_{\Theta}(\cdot\mid o_t, s_t, l)$, the input is the current image, robot state and language, and the output is a future action. The authors believe that the weakness of this type of paradigm is the sparse action supervision: actions are low-dimensional and have repetitive patterns, while observations and language are very high-dimensional. The model may learn a shallow context-to-action template mapping, but is not forced to understand how the world will change after the action is executed.
2.2 Why ordinary WAM is not enough
Recently, WAM uses video generation models to introduce temporal intensive supervision, which theoretically allows the strategy to learn physical dynamics. However, many methods strongly couple actions with future videos: joint action-video prediction generates future visual trajectories during inference, while the two-stage method first generates future videos and then uses IDM to decode actions. This brings two risks: first, diffusion video token sampling is very slow; second, video prediction errors will be transmitted to actions, and small errors will accumulate in long time series.

2.3 The core turn of this article
This article does not deny the value of future video supervision, but changes its role in the system: future video is an auxiliary task for regularizing action rationality during training, not an intermediate product that must be completed during inference. Action tokens are designed to rely only on current observations, states, and language, and future video tokens can only be generated after actions, so video prediction can be turned off.
4. Detailed explanation of method
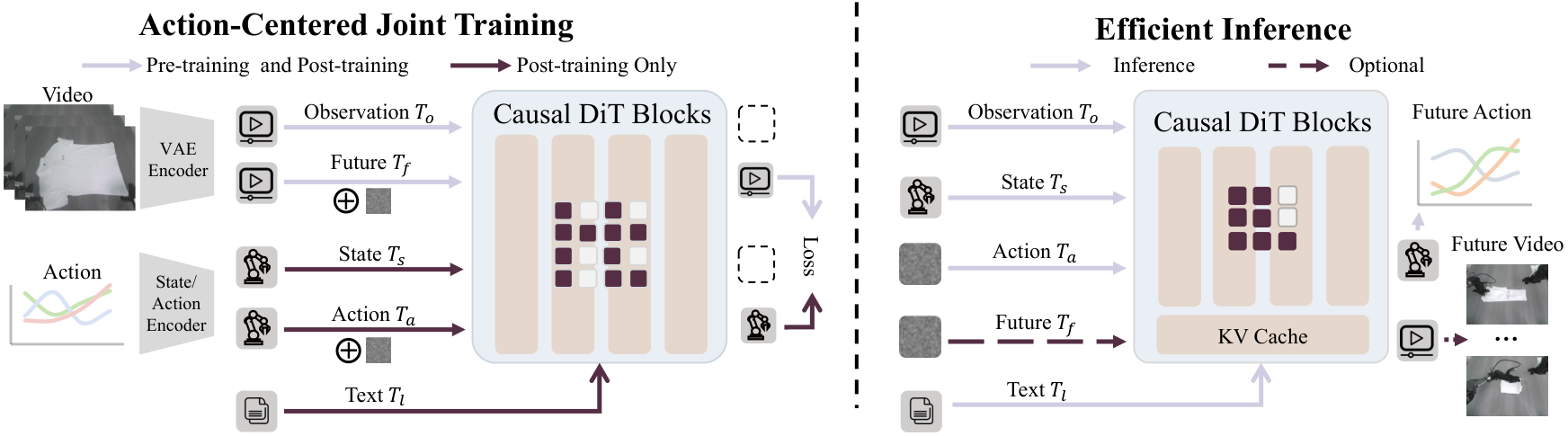
4.1 Formalization of tasks
At each moment $t$, the robot receives multi-view RGB observation $o_t=\{o_t^v\}_{v\in S}$, including $S=\{left, front, right\}$, language instructions $l$ and body status $s_t$. The policy outputs an action chunk with a length of $p$:
$$a_{t: t+p-1}=(a_t, a_{t+1}, \ldots, a_{t+p-1}).$$
Traditional VLA learns:
$$a_{t: t+p-1}\sim q_\Theta(\cdot\mid o_t, s_t, l).$$
GigaWorld-Policy lets the unified model $g_\Theta$ parameterize two conditional distributions at the same time. Action side:
$$\big(a_{t: t+p-1}, c_t\big)\sim g_\Theta(\cdot\mid o_t, s_t, l), $$
Among them, $c_t$ is the action latent conditioning signal used for visual prediction. Visual dynamic side:
$$ (o_{t+\Delta}, o_{t+2\Delta}, \ldots, o_{t+K\Delta}) \sim g_\Theta(\cdot\mid o_t, s_t, l, c_t), \quad K=\lfloor p/\Delta\rfloor. $$
This decomposition is critical: the action is modeled first, and the future video is a subsequent prediction conditioned by the action, rather than a pre-prediction that the action must depend on.
4.2 Input token and multi-view splicing
In order to process the three-way camera without changing the video generation backbone, the author combined the three perspectives of left/front/right into a composite image:
$$o_t^{comp}=\mathrm{Compose}(o_t^{left}, o_t^{front}, o_t^{right}).$$
Both current observations and future observations are encoded into visual latent through the same pre-trained VAE, and then cut into spatiotemporal visual tokens: the current observation token is recorded as $T_o$, and the future video token is recorded as $T_f$. The ontology state and action are mapped to the hidden dimension through the linear layer, resulting in $T_s$ and $T_a$ respectively. The language instructions are obtained by the pre-trained language encoder $T_l$ and injected in a cross-attention manner.
4.3 Sharing Transformer and causal mask
Unlike MoE or multi-branch experts, this article puts all tokens into the same group of Transformer blocks and shares Q/K/V projections. The unified sequence is written as:
$$T_t=[\, T_o; \, T_s; \, T_a; \, T_f\, ].$$
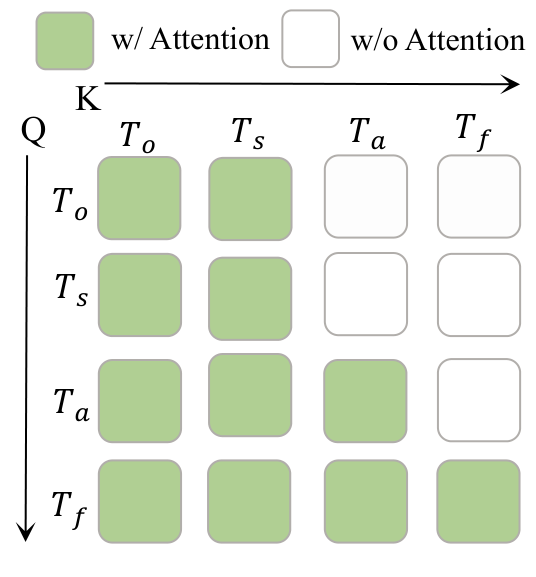
This mask imposes three dependencies: $T_s$ and $T_o$ can pay attention to each other, but cannot look at the action or the future; $T_a$ can look at $T_s, T_o$, but not $T_f$; $T_f$ can look at $T_s, T_o, T_a$. What it means is: action prediction is determined only by the current context, and future video prediction is determined by the current context and action. In this way, the visual dynamic supervision during training will not "cheat" into the action token through information leakage, and also provide structural guarantee for closing future video branches during inference.
4.4 Training goals: two flow-matching losses
For either action token or future video latent mode $x$, sample flow time $s\sim U(0, 1)$ and noise $\epsilon\sim\mathcal N(0, I)$, construct:
$$x^{(s)}=(1-s)\epsilon+s x, \qquad \dot{x}^{(s)}=x-\epsilon.$$
Future video loss is defined on VAE latent $z_f$:
$$ \mathcal L_{video}= \mathbb E_{s, \epsilon}\left[ \left\| g_\Theta(z_f^{(s)}, s\mid T_s, T_o, T_a, T_l)-\dot z_f^{(s)} \right\|^2 \right]. $$
Action loss is only conditioned on historical context and language, not future videos:
$$ \mathcal L_{action}= \mathbb E_{s, \epsilon}\left[ \left\| g_\Theta(a^{(s)}, s\mid T_s, T_o, T_l)-\dot a^{(s)} \right\|^2 \right]. $$
Only video flow matching is optimized in the pre-training stage; joint optimization is performed in the post-training stage:
$$\mathcal L_{all}=\lambda_{video}\mathcal L_{video}+\lambda_{action}\mathcal L_{action}.$$
4.5 Reasoning: action-only decoding
The context during inference is $w_t=(T_l, T_s, T_o)$. The model only initializes and samples action tokens:
$$a^{(0)}\sim\mathcal N(0, I), \qquad \frac{d a^{(s)}}{ds}=g_\Theta(a^{(s)}, s\mid w_t), \ s\in[0, 1].$$
After integrating, $a^{(1)}$ is decoded into the continuous action chunk $\hat a_{t: t+p-1}$. After execution, the new observation is used to close the loop. If you need visualization or diagnosis, you can also open the video branch: either combine denoise future video tokens, or reuse the KV cache during the denoising action to regenerate the video. But the control itself does not depend on this step.
5. Key points of data, training and reproducibility
5.1 Pre-training data
The author used about 10, 000 hours of embodied data for pre-training, ranging from real robot videos, egocentric human videos, and general interaction videos. The estimated hours in the table are as follows:
| data source | hours | function |
|---|---|---|
| EgoDex | 800 | Hand/object interaction, daily operation primitives |
| Agibot | 2, 500 | Robot real operation and workspace visual distribution |
| EGO4D | 3, 500 | Long-term human first-person perspective activity structure |
| RoboMind | 300 | Robot operation video |
| RDT | 25 | Robot operation video |
| Open X-Embodiment | 3, 500 | Cross-robot/cross-task vision coverage |
| DROID | 350 | real robot manipulation |
| ATARA | 10 | Robot mission video |
| Something-Something V2 | 200 | Object interaction dynamic prior |
5.2 Training formula
- Backbone: Wan 2.2 5B diffusion Transformer.
- Action chunk length: $p=48$.
- Default future observation stride: $\Delta=12$, so $K=\lfloor 48/12\rfloor=4$ future frames.
- Post-training loss weight: $\lambda_{action}=5$, $\lambda_{video}=1$.
- The pre-training hyperparameters are from the appendix: about 6000 GPU hours, global batch size 256, AdamW, $\beta_1=0.85, \beta_2=0.9$, learning rate from $1\times10^{-4}$ cosine decay to $1\times10^{-6}$.
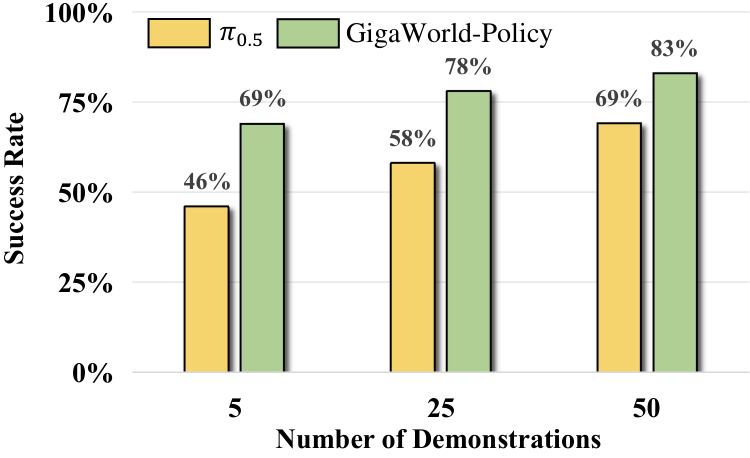
- For real tasks, 50 demonstration trajectories are collected for each task for post-training; each method is tested for 20 trials per task, with a maximum of 5 trials per trial.
- Each task is simulated with 100 test episodes; the training data is 50 demos per task for clean scenes and 500 demos for randomized scenes per task, totaling 2, 500 clean + 25, 000 randomized demonstrations.
6. Analysis of experimental results
6.1 Inference speed and success rate
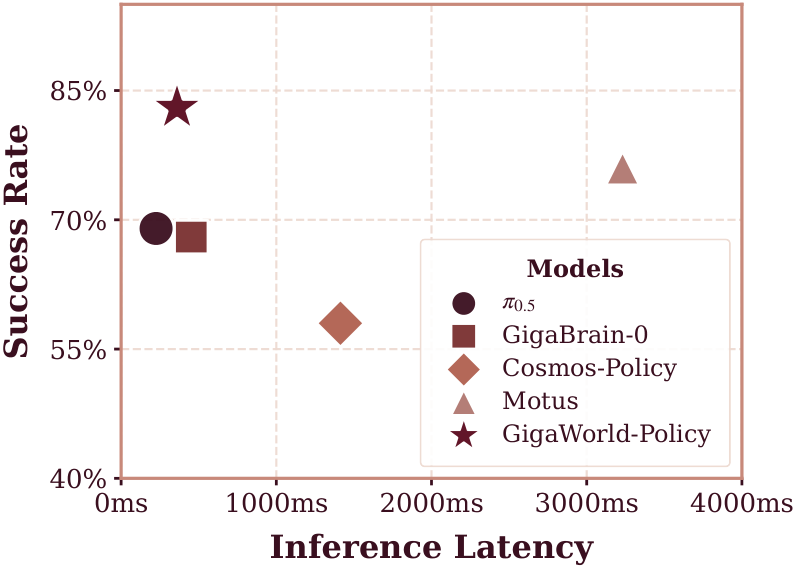
| method | Time (ms) | Simulation SR | Real-world SR |
|---|---|---|---|
| $\pi_{0.5}$ | 225 | 0.48 | 0.69 |
| GigaBrain-0 | 452 | -- | 0.68 |
| Motus | 3231 | 0.88 | 0.76 |
| Cosmos-Policy | 1413 | -- | 0.58 |
| GigaWorld-Policy | 360 | 0.86 | 0.83 |
Compared to Motus, GigaWorld-Policy has a slightly lower simulation success rate of 0.02, but the latency drops from 3231 ms to 360 ms, and the real success rate is higher. This result supports the authors' core argument: the world model training signal is useful, but the complete generation of future videos is not necessary for inference.
6.2 RoboTwin 2.0 simulation
RoboTwin 2.0 contains 50 representative manipulation tasks, evaluating clean and randomized scenes. The average values of the main table are: $\pi_{0.5}$ 0.43/0.44, X-VLA 0.73/0.73, Motus 0.89/0.87, GigaWorld-Policy 0.87/0.85. In other words, the method in this article is close to the strongest WAM baseline, but it is significantly ahead in real-time performance.
6.3 Real robot tasks
The real platform is the AgileX PiPER 6-DoF robotic arm. Four tasks are defined from the appendix:
- Clean the Desk: Move various dishes to the target basket, and the dishes are required to be under the bowl.
- Stack Bowls: Two bowls in any initial pose are nested and stacked.
- Scan a QR Code: Take the scanner, grab the target object, align it with the QR code and read the code, then put it back on the target object.
- Sweep up Trash: Take a brush and dustpan and sweep small scattered objects into the dustpan.
| method | Clean Desk | Scan QR | Sweep Trash | Stack Bowls | Avg. |
|---|---|---|---|---|---|
| $\pi_{0.5}$ | 0.75 | 0.55 | 0.65 | 0.80 | 0.69 |
| GigaBrain-0 | 0.70 | 0.65 | 0.60 | 0.75 | 0.68 |
| Motus | 0.80 | 0.75 | 0.70 | 0.80 | 0.76 |
| Cosmos-Policy | 0.65 | 0.50 | 0.45 | 0.70 | 0.58 |
| GigaWorld-Policy | 0.90 | 0.75 | 0.75 | 0.90 | 0.83 |



6.4 Data efficiency and ablation
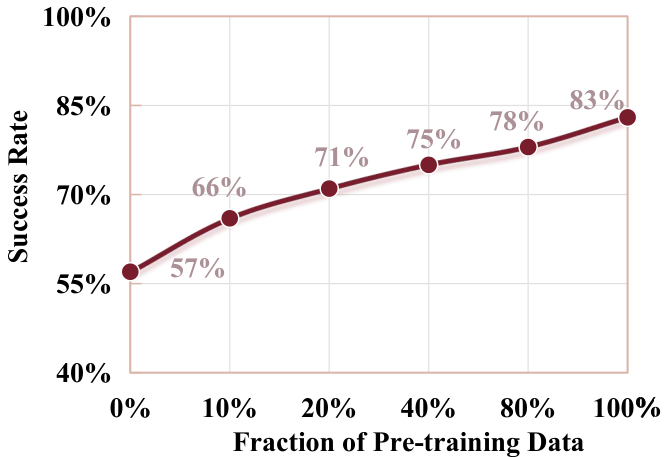
| ablation term | settings | result | explain |
|---|---|---|---|
| Pre-training combination | scratch / video init / embodied pretraining / both | SR: 0.45 / 0.57 / 0.73 / 0.83 | Universal video priors and embodied data pretraining complement each other. |
| number of future frames | $\Delta=0, 4, 8, 12, 24, 48$ | SR: 0.60 / 0.76 / 0.78 / 0.83 / 0.80 / 0.76 | The right amount of future modeling is helpful, but too dense a forecast has diminishing returns. |
| Causal mask | Self-Attn vs Ours | SR 0.81 vs 0.83; PSNR 27.87 vs 28.41; SSIM 0.892 vs 0.901 | Avoid future token leaks while improving action condition video prediction quality. |

7. Discussion: Value, Credibility and Limitations
7.1 The most valuable part of this paper
The greatest value is to provide a clean structural solution to the deployment bottleneck of WAM. In the past, many methods of "using world models to make strategies" emphasized the reasoning link: both imagining the future and extracting actions from the imagination. This paper retains future dynamics as training signals and decouples the action reasoning path from the video reasoning path. This is important for real robots, because 3 seconds of reasoning, even if the success rate is good, will destroy the closed-loop control frequency; although 360 ms is not yet a high-frequency servo, it has entered the scope of the deployable strategy layer.
Another value is that it does not reduce future video prediction to "useless visualization". The ablation shows that the success rate drops significantly when $K=0$ is used, indicating that future dynamic supervision does indeed provide action learning signals; however, the optimal $\Delta=12$ also shows that dense video prediction is not more, the better. This result is more detailed than "the world model must be rolled out".
7.2 Why the results hold up
The chain of evidence has three levels. First, the speedometer directly compares the action-only path with the WAM baseline that requires video reasoning, and the numerical difference is huge. Second, RoboTwin 2.0 has been compared with the real platform, which shows that it is not only effective in simulation. Third, ablation separates pre-training, the number of future frames and the causal mask, which can correspond to the three main claims of the method: large-scale embodied pretraining is useful, future dynamic supervision is useful, and the mask makes video branches optional and reduces leakage.
Especially for causal mask ablation, although the SR only goes from 0.81 to 0.83, PSNR/SSIM and visualization together show that the mask improves the modeling quality of action-conditioned dynamics. This is consistent with the method assumption: actions should not steal information from future frames, and future frames should be interpreted by actions.
7.3 Main limitations
- reproducibility resources are heavy. 5B diffusion Transformer, about 10, 000 hours of data, and 6000 GPU hours of pre-training, this is not a level that ordinary laboratories can fully reproduce.
- Some key engineering details still require code confirmation. For example, multi-view puzzle layout, action representation/normalization, flow sampling steps, post-training data cleaning, real robot control interface, etc. are not described in detail in the main text.
- The number of real tasks is limited. Four PiPER missions illustrate deployment potential, but are not sufficient to cover more contact-rich, dynamic object, human-robot collaboration, or long-duration missions.
- Speed is still policy layer speed. 360 ms is much faster than WAM, but if the task requires higher-frequency fine force control, it still needs the cooperation of an underlying controller or a lightweight distillation strategy.
- There are slight inconsistencies in official statements. The paper table shows 9x and +7%, and the project page shows 10x and +35%; which value should be quoted clearly when reporting at the group meeting.
8. Questions can be asked during group meetings
- If future videos are not generated at all during inference, through which parameter paths does $\mathcal L_{video}$ during training affect action prediction? Is sharing Transformer blocks enough to explain this migration?
- Causal mask prevents action tokens from seeing future video tokens, but action loss and video loss still share the backbone. Is there possible gradient-level conflict, and is $\lambda_{action}=5, \lambda_{video}=1$ sensitive to different tasks?
- Is the optimal $\Delta=12$ related to the action chunk length $p=48$, robot control frequency and task duration? How to set up when changing robots or faster tasks?
- Composite multi-view image sacrifices inter-camera geometry explicitness. Compared with independent view token + view embedding, does its advantage mainly come from compatibility with video backbone?
- How strongly does the future video prediction quality metric PSNR/SSIM correlate with the real control success rate? Are there cases where the video looks bad but the action is still right, or the video is good but the action fails?
- There are 50 demos for each real task, and the model has large-scale pre-training. If only a small number of downstream demos are allowed, does the performance bottleneck come more from action head adaptation or visual dynamic prior not being close enough?
9. Recurrence Checklist
| module | What must be confirmed | Information given in the paper |
|---|---|---|
| code/weight | Official warehouse, model weights, inference scripts, training configurations | github.com/open-gigaai/giga-world-policy |
| Input processing | Three-view compose rules, image resolution, VAE latent shape | The three perspectives are combined into a composite image with the same resolution; the visual token is encoded with VAE. |
| model | Wan 2.2 5B access method, state/action projection, language cross-attention | Shared Transformer blocks, visual 2D PE, state/action 1D temporal PE. |
| training | flow steps, batching, loss weight, optimizer, data sampling ratio | AdamW, batch 256, lr 1e-4 to 1e-6; post-training $\lambda_a=5, \lambda_v=1$. |
| Assessment | RoboTwin 2.0 task list, randomization settings, real robot trial protocol | 50 tasks; clean/randomized; 20 trials of real tasks, maximum 5 attempts per trial. |
| reasoning | action-only sampling steps, whether to use KV cache, control frequency | Future videos are turned off by default and only denoise action tokens; optionally enable video branches or reuse KV cache. |
Paper page: arXiv: 2603.17240; PDF: arxiv.org/pdf/2603.17240; Project page: GigaWorld-Policy Project.