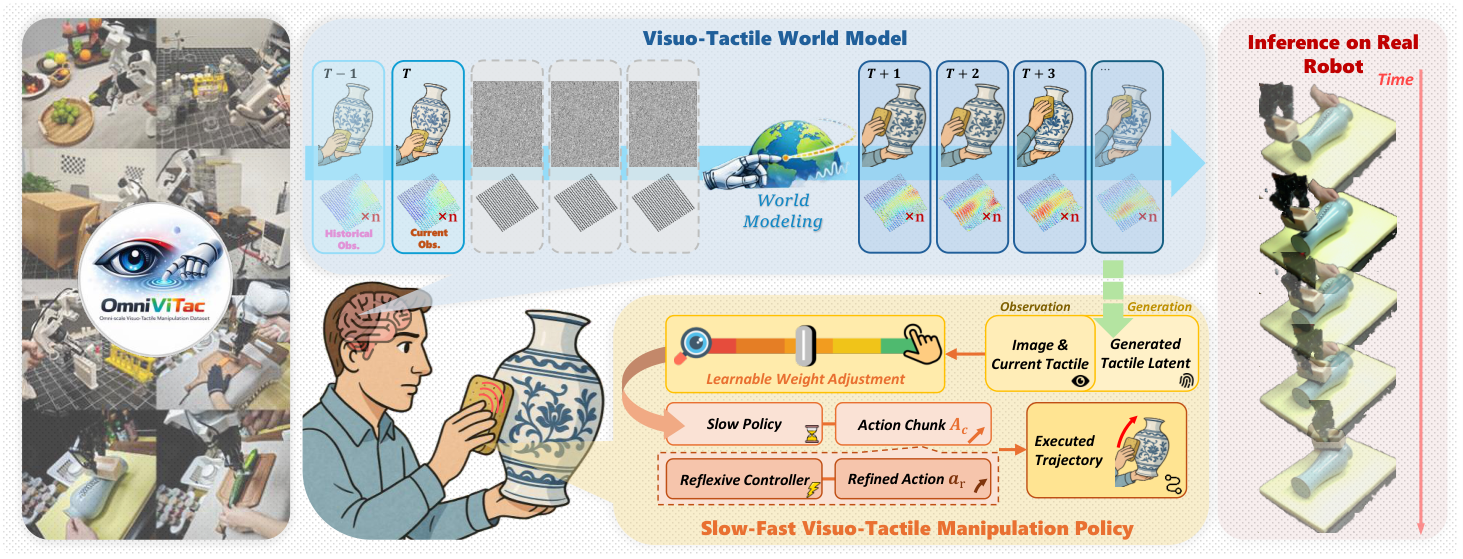
OmniVTA: Visuo-Tactile World Modeling for Contact-Rich Robotic Manipulation
1. Quick overview of the paper
Difficulty rating: ★★★★☆. Requires understanding of diffusion policy / diffusion transformer, VAE/implicit neural representation, multi-modal fusion, tactile sensor data representation, and real robot imitation learning experimental design.
Keywords: Visuo-Tactile ManipulationWorld ModelContact-Rich ManipulationTactileVAEReflexive Control
| Reading targeting item | A brief answer based on the original text |
|---|---|
| What should the paper solve? | The existing visual and tactile operation data scale and task coverage are insufficient; existing methods mostly treat haptics as passive observation and lack explicit contact dynamic modeling and high-frequency closed-loop tactile control. |
| The author's approach | First, OmniViTac is used to provide aligned visual and tactile action data of 21, 879 items, 86 tasks, and 100+ objects, and then TactileVAE, two-stream VTWM, LTD+gating fusion strategy and RLTC are used to form OmniVTA. |
| most important results | OmniVTA outperforms DP, DP+tactile, KineDex, ForceMimic, and RDP overall on six categories of real robotic tasks, and maintains the highest or tied highest success rate under generalization and perturbation robustness settings. |
| Things to note when reading | The core is not "adding touch" per se, but turning touch into a prediction object, integrating modulation signals and high-frequency correction targets; it should also be noted that there is no appendix in the source code, and the hyperparameters are concentrated in the text of the experimental settings. |
Core contribution list
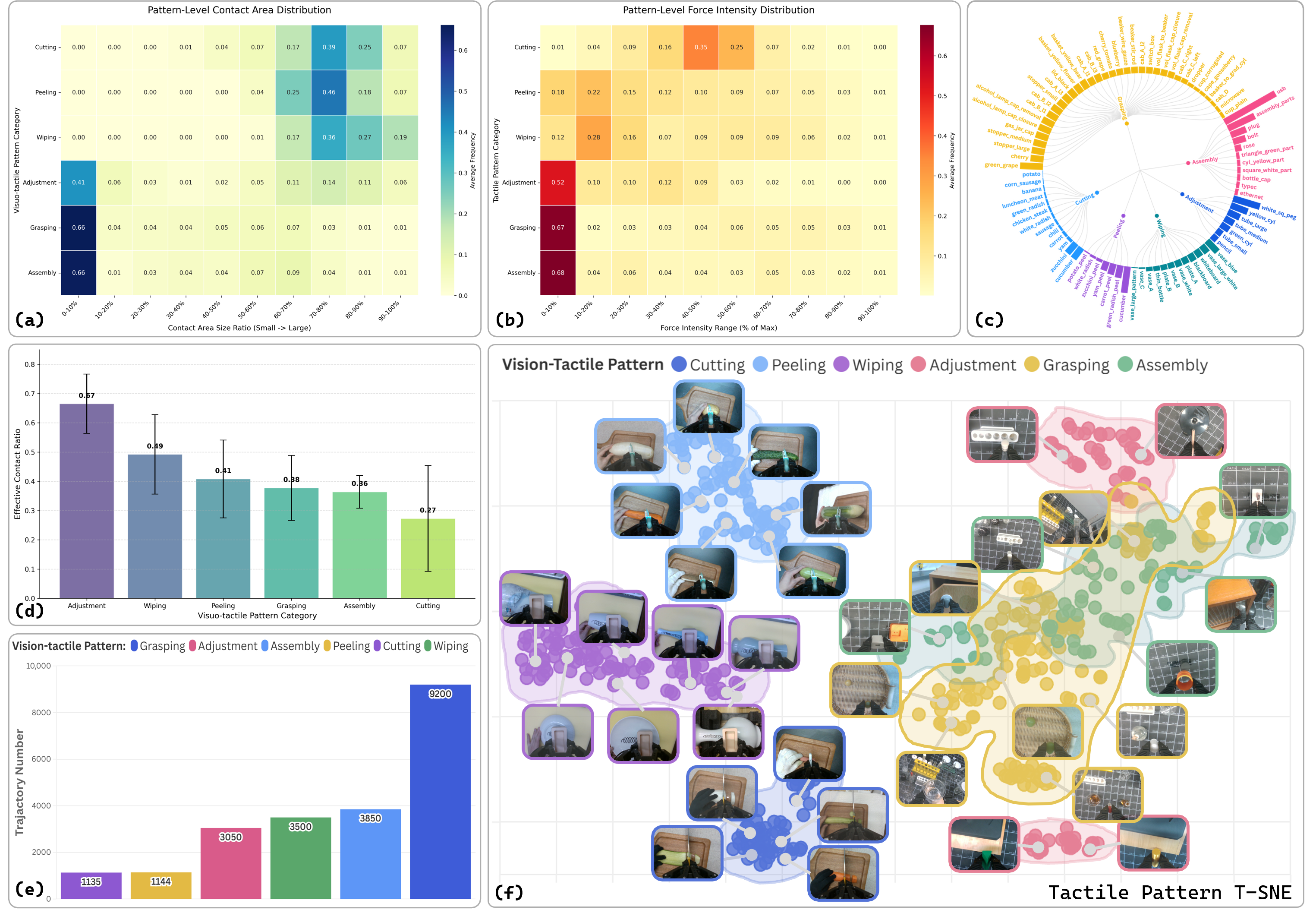
- OmniViTac dataset.21, 879 synchronized trajectories, 86 tasks, 126 objects, and six types of physical contact patterns; the significance is to use data scale, task diversity, and tactile-visual-action time alignment as the basis for training the world model at the same time.
- OmniVTA method framework.Putting tactile representation learning, visuo-tactile world model, contact perception adaptive fusion and 60 Hz closed-loop tactile control into a unified pipeline; the meaning is to allow tactile sensation to participate in both prediction and strategy generation and execution correction.
- Real robot verification.Compare multiple imitation learning / force-conditioned / reactive baselines on six types of contact enrichment tasks; the significance is to verify that predictive contact modeling and high-frequency tactile feedback directly contribute to generalization and perturbation recovery.
2. Motivation
2.1 What problem should be solved?
The paper focuses on tasks that are exposed to rich operations, such as wiping, assembly, peeling, cutting, etc. This type of task cannot rely solely on visual judgment, because the key states often come from tactile information such as contact force, friction changes, slippage, insertion obstruction, force mutation at the moment of cut-off, etc. Vision can tell the robot "where the object is", but it is difficult to reliably tell the robot "whether the current contact is stable, whether it is too forceful, or whether it is about to slip."
The author divides the problem into two levels: the data level lacks large-scale, task-diverse and strictly time-aligned vision-tactile-action demonstrations; the method level lacks strategies for explicitly using tactile signals for contact dynamic prediction and closed-loop control.
2.2 Limitations of existing methods
- Data set limitations: Early tactile data are mostly static pressing or object texture collection; although newer manipulation datasets have action trajectories, the number of tasks, number of objects, sensor types and high-frequency tactile-visual synchronization are still insufficient.
- Express limitations: Many methods use touch as an auxiliary input to compensate for occlusion or identify contact status, but do not take future contact evolution as an explicit prediction goal.
- Control limitations: Action chunking is often executed in an open loop at a lower frequency, and cannot be corrected immediately when encountering slippage, dislocation, or external disturbance. Although reactive methods such as RDP introduce fast feedback, the author reports that it may produce too strong contact in strong contact tasks, leading to the risk of sensor damage.
2.3 The solution ideas of this article
The author draws on human sensorimotor control: on the one hand, it forms feedforward anticipation for contact evolution, and on the other hand, it uses tactile feedback for rapid reflexive correction. Corresponding to the method, OmniVTA first predicts the short-term future tactile latent, then performs contact perception fusion based on the current/predicted tactile difference, and finally uses 60 Hz RLTC to correct the action based on the deviation between the predicted tactile sensation and the actual tactile sensation.
3. Summary of related work
3.1 Related work of the thesis self-description
| Technical line | Representative work and positioning | The difference in this article |
|---|---|---|
| Tactile sensing and tactile representation learning | Visuo-tactile sensors such as GelSight and DIGIT provide high-resolution contact geometry; Sparsh, AnyTouch, UniT, etc. learn tactile representation through masked autoencoding, contrastive learning or VQGAN-like latent modeling. | This article not only learns static tactile representation, but uses operational data supported by four types of tactile sensors to train task-independent tactile latent and serve the world model and strategy. |
| Visuo-tactile manipulation policies | See-to-Touch, RoboPack, 3D-ViTac, RDP, VLA-Touch, Tactile-VLA, TA-VLA, etc. show that haptics can complement visual occlusion and fine-grained control. | This article emphasizes the predictive use of haptics: predicting future contacts, modulating visuo-tactile weights based on contact probabilities, and using prediction/observation differences for closed-loop control. |
| Visuo-tactile manipulation datasets and systems | ObjectFolder2.0, AnyTouch, Octopi-1.5, RH20T, FreeTacMan, VLA-Touch, exUMI, AgiBot World, etc. cover different levels of tactile, visual, and action data. | OmniViTac expands the number of tasks to 86, trajectories to 21, 879, and objects to 126, while retaining 30-60 Hz tactile and motion data and time synchronization. |
3.2 Direct comparison with previous works
| Dimensions | DP / DP+tactile | RDP | KineDex / ForceMimic | OmniVTA |
|---|---|---|---|---|
| Core idea | Diffusion policy generates action chunk; DP+tactile additionally stitches tactile features. | Slow diffusion planner + fast tactile reactive controller. | Jointly predict action and force based on visual observations. | The world model predicts future tactile latent, the fusion strategy generates slow motion, and RLTC high-frequency correction. |
| key assumptions | Current/historical observations are sufficient to generate short-term actions. | Haptics can be used for reactive correction. | force or tactile embedding are available as kinetically relevant quantities. | Future tactile prediction can provide a priori of contact status, and the prediction-observation difference can guide correction. |
| Applicable scenarios | General visual imitation learning; the tactile version is suitable for tasks involving contact observation. | Reactive operations under contact perturbations. | Diffusion strategies requiring force/contact information. | Wiping, peeling, cutting, assembling, grabbing, adjusting and other contact-rich tasks. |
| Experimental performance | In Table 2, DP is set to 0 under multinomial P; DP+tactile has improved but is still lower than OmniVTA. | Stronger than normal DP, but the authors observed excessively strong contact in the strong contact task. | Some tasks are better than DP+tactile, but overall they are not as good as OmniVTA. | Most O/G/P settings in Table 2 are the highest; RLTC significantly improves perturbation performance compared to w/o RLTC. |
4. Dataset: OmniViTac
OmniViTac is the training basis for this method. It contains 21, 879 synchronized trajectories, 86 tasks, 126 objects, recording RGB-D, tactile signals, motion trajectories and continuous gripper aperture. The author organized the tasks into six categories of physical contact modes: Assembly, Cutting, Adjustment, Peeling, Wiping, and Grasping.
4.1 Collection system
- Robot demonstrations: UFACTORY xArm-7, includes two modes: kinesthetic teaching and GELLO teleoperation.
- Human demonstrations: TacUMI handheld acquisition device, using RealSense T265 to output 6-DoF poses at 200 Hz; tracking drift is checked after the trajectory ends, and samples with position errors greater than 8 mm are discarded.
- Isomorphic end effector: The robot uses the same parallel gripper as TacUMI and records the continuous gripper width normalized to $[0, 1]$.
- Vision: wrist-view and third-person RGB-D; $640\times480$ for D435, $1280\times720$ for L515, camera 30 Hz.
- Touch: Xense, Daimon, Tac3D-A1, GelSight Mini; Xense is the main large-scale acquisition sensor, providing $35\times20$ 3D displacement fields at 60 Hz.
4.2 Data processing and quality control
During acquisition, all sensory streams are recorded asynchronously at the native frequency, and post-processing is synchronized according to timestamps. For every 50 trajectories, 3 trajectories are randomly visualized for online quality inspection; the offline tool continues to check and delete abnormal samples. Before training, remove the first and last still frames, align RGB-D, haptics, and actions through timestamps with a time error of less than 10 ms, and split them into training segments.
4.3 Six types of tactile modes
| mode | contact mechanism | tactile information function |
|---|---|---|
| Assembly | Contact geometry and multidirectional force coordination | Sensing tight tolerances and successful insertion. |
| Cutting | The normal force gradually increases and decreases when cutting off | Determine the penetration/cutting process. |
| Adjustment | torsion and shear forces | Perceiving slippage and in-hand redirection states. |
| Peeling | Continuous coupling of shear and normal forces | Maintain tool-surface contact. |
| Wiping | Normal pressure + plane shear | Keep surfaces snug and overcome friction. |
| Grasping | Various force types covering fragile, transparent and articulated objects | Confirm stable grip and adjust normal/shear. |

5. Detailed explanation of method
5.1 Method overview
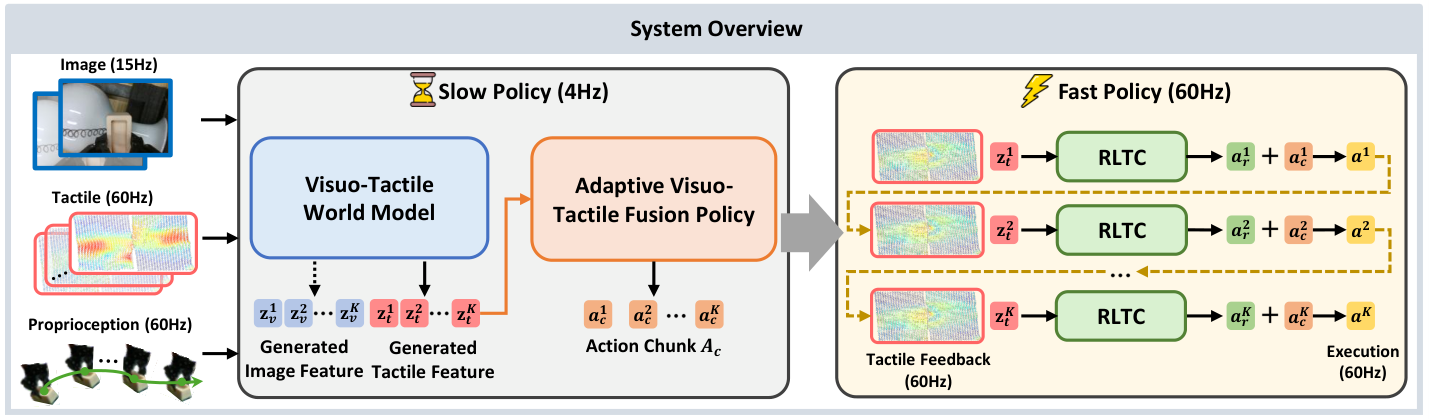
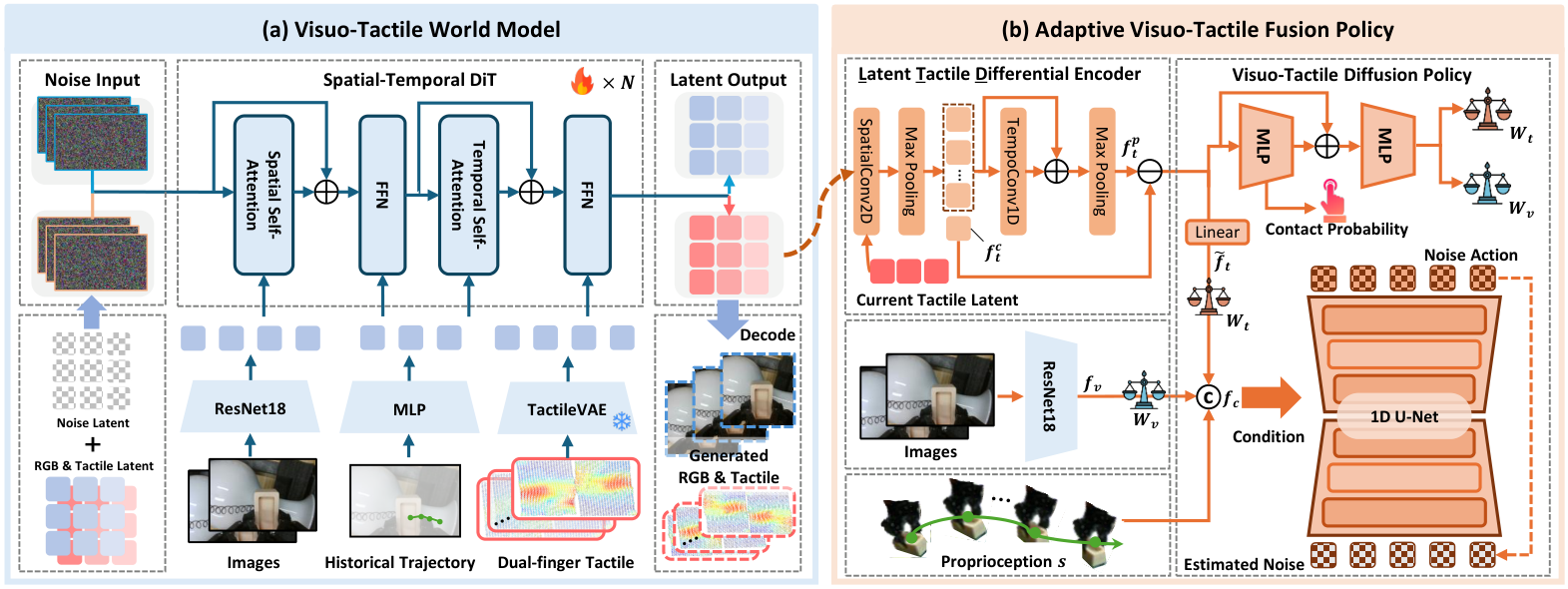
OmniVTA is a hierarchical slow-fast policy. Slow Policy consists of Visuo-Tactile World Model (VTWM) and Adaptive Fusion Policy (AFP), which uses low-frequency vision, high-frequency tactile and ontology states to plan long-term action chunks; Fast Policy is the Reflexive Latent Tactile Controller (RLTC), which outputs fine-grained corrections based on observed tactile and predicted tactile sensations at 60 Hz. The final execution action is the weighted sum of the slow policy action and the fast controller output.
5.2 Method evolution
General visual diffusion policy → Join Current tactile input → Explicit modeling Future tactile predictions → use LTD and gating Convert predictive tactile input to contact sensing strategy → use RLTC Convert prediction-observation differences into high-frequency corrective actions. Each step corresponds to a gap pointed out in the paper: vision cannot directly read the contact state; the current touch has no prior contact with the future; simple splicing does not change the modal weight with the contact state; the open-loop execution of the action chunk cannot respond quickly to disturbances.
5.3 TactileVAE
The input to TactileVAE is not a high-resolution tactile image, but a 3D marker displacement. A single frame can be expressed as $H\times W\times3$, and the three channels correspond to $x, y, z$ displacement. The author uses causal 3D convolution for spatio-temporal encoding, so that the latent at time $t$ only relies on current and past observations, ensuring that there is no future information leakage during deployment.
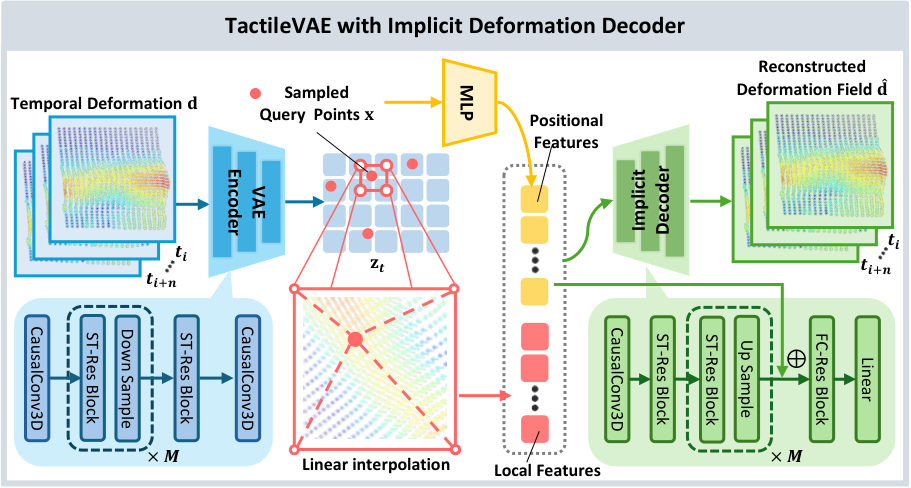
| $\mathbf{x}\in\mathbb{R}^2$ | 2D query coordinates on tactile surfaces. |
| $\mathbf{z}_t$ | The tactile latent feature map output by the encoder has sizes $H/s\times W/s\times C$ and $s=2^M$. |
| $\gamma(\mathbf{x})$ | Position encoding enables MLP to express high-frequency spatial changes. |
| $\Phi(\mathbf{z}_t, \mathbf{x})$ | Local features extracted from latent map through spatial interpolation. |
| $\mathcal{D}_\theta$ | MLP implicit decoder. |
| $\mathbf{d}(\mathbf{x})\in\mathbb{R}^3$ | The three-dimensional deformation vector of the point. |
Intuition: The deformation of the tactile colloid surface is a continuous field and should not be reconstructed only by pixels/marker points. The INR decoder allows querying deformations at arbitrary coordinates, thereby preserving local spatial structure in latent feature maps.
The first one supervises the 3D deformation of reconstruction; the second one is KL regularization of VAE. $\lambda_{\text{KL}}=10^{-6}$ in experimental setup.
5.4 Visuo-Tactile World Model (VTWM)
VTWM adopts a two-stream conditional generative framework: the visual branch uses SD-VAE to extract image latents, and the tactile branch uses pre-trained TactileVAE to compress tactile signals; the two modes each enter the spatial-temporal diffusion transformer to predict the future under shared conditions. Conditions are derived from a multi-modal observation conditioner that aggregates visual, tactile, and action sequences separately and represents actions as 2D image-plane projections of 3D end-effector positions.
| $\mathbf{z}_o=\{\mathbf{z}_o^1, \dots, \mathbf{z}_o^K\}$ | Observed latent sequence, including tactile latent $\mathbf{z}_t$ and visual latent $\mathbf{z}_v$. |
| $m_i$ | Time mask; historical conditioning frames are not used to generate errors, and future frames participate in prediction. |
| $\epsilon_i$ | Realistic noise added by the diffusion process. |
| $\boldsymbol{\epsilon}_\theta(\cdot)_i$ | Noise predicted by the model at time step $i$. |
The former highlights locations with rapid changes in time, and the latter highlights locations with large contact response amplitudes. Both are resized from raw tactile resolution to latent resolution, used to emphasize high-frequency contact dynamics and local contact intensity.
$\lambda_{\text{dyn}}=1.0$, $\lambda_{\text{amp}}=1.0$ in the experiment. This is not an additional prediction target, but a spatial-temporal reweighting of the diffusion noise prediction error.
5.5 Adaptive Visuo-Tactile Fusion Policy (AFP)
AFP consists of three parts: LTD Encoder, contact-aware gating, and visuo-tactile diffusion policy.
| $f_t^c$ | The global representation of the current tactile observation after 2D conv + max pooling. |
| $f_t^p$ | Predict future tactile representations of multi-frame tactile latents after frame-by-frame spatial aggregation and 1D temporal conv + max pooling. |
| $f_t^p-f_t^c$ | Highlights the difference between the predicted contact state and the current tactile state. |
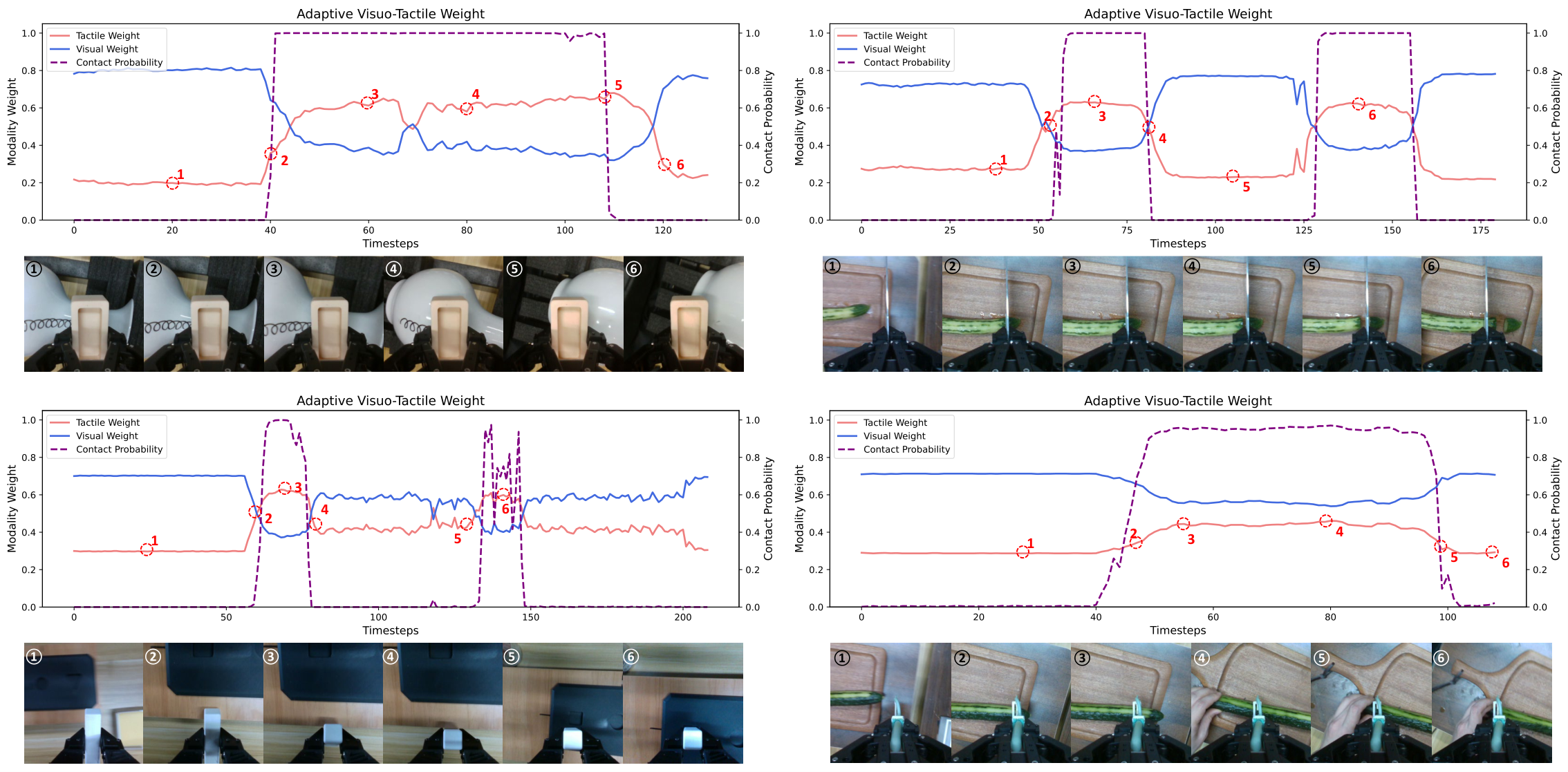
Contact probabilities are predicted by tactile representation via MLP + sigmoid, labels are obtained by tactile deformation magnitude threshold, and trained with BCE loss. The Gating network outputs the channel-by-channel weight $W_v, W_t$, which satisfies $W_v+W_t=1$. When there is no contact, the tactile weight is close to 0; when the contact probability increases, the tactile weight increases.
$A_c=(a_c^1, \dots, a_c^H)$ is a coarse action chunk; $f_c=\text{concat}(f_{vt}, s)$ is a fusion of multi-modal features and robot body state. Train to predict the target using DDPM noise:
$$\mathcal{L}_{act}=\mathbb{E}_{t, A_{c, 0}, \epsilon_t}\left[\left\|\epsilon_t-\epsilon_\theta(\bar{\alpha}_t A_{c, 0}+\bar{\beta}_t\epsilon_t, t, f_c)\right\|_2^2\right]$$The overall target of AFP is $\mathcal{L}_{AFP}=\mathcal{L}_{act}+\lambda_{ct}\mathcal{L}_{bce}$, and the experiment is $\lambda_{ct}=0.2$.
5.6 Reflexive Latent Tactile Controller (RLTC)
RLTC solves the problem of open-loop execution of action chunks. It repeats the single-frame tactile feedback $M$ times to adapt to the time compression of TactileVAE; upsamples the world model low-frequency predicted tactile latent nearest neighbor to 60 Hz, aligned with the current tactile feature; then uses LTD Encoder to encode the current/predicted tactile, and then splices the delta actions and delta gripper in the TCP coordinate system of the past $h$ steps. states, the single-step refined action $a_r$ is output through three layers of MLP.
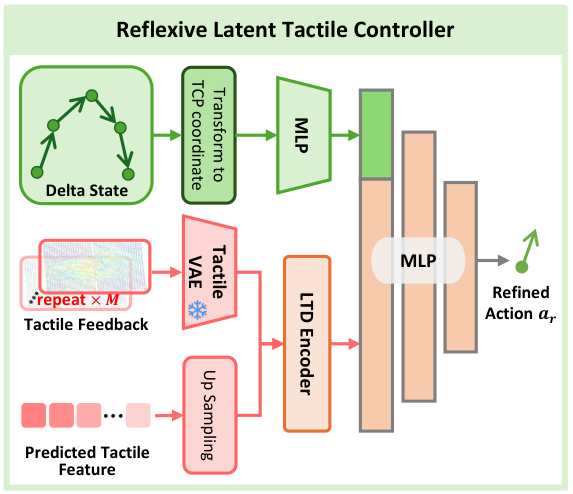
The training data comes from abnormal contact recovery episodes. The author first estimates the mean and standard deviation of the effective tactile distribution for each type of task, identifies excessively large or small contact forces as abnormal states, and then extracts recovery segments that return from abnormality to effective distribution as a correction demonstration.
5.7 Implementation Points
- Tactile input uses 3D marker displacement instead of raw tactile images to reduce resolution and increase inference frequency.
- TactileVAE uses causal 3D convolutions to avoid deployment dependencies on future frames.
- VTWM does not generate visual observations during inference, but only predicts future tactile signals to increase the rollout frequency; the visual generation branch is only used for analysis in training/ablation.
- The action condition of the World model uses the 2D image-plane projection of the 3D end position. The author's experiments show that it is better than 3D absolute/relative actions in the unseen position.
- Policy uses the current and previous frames of vision, 8 frames of haptics in the same time window, and 2 ontology states; outputs chunks of 6 actions, and interpolates to 60 Hz for execution.
6. Experiment
6.1 Experimental setup

| Project | settings |
|---|---|
| Task | Wipe, Peel, Cut, Assembly, Grasp, Adjustment. |
| training object | Choose 5-6 objects for each category, and 150 trajectories for each object; for example, wipe uses 4 colors/shapes of vases, plates, and whiteboards, and cut uses cucumber, Chinese yam, carrot, pepper, and banana. |
| Data partition | World model training/testing is 90%/10%. |
| Real robot platform | UFactory xArm7 + parallel two-finger gripper + two fingertip tactile sensors; wrote RealSense D435 RGB at 15 Hz; tactile 60 Hz; only Xense was used for real operation experiments. |
| Review settings | Object diversity (O), Generalization (G: unseen heights / unseen knife), Perturbation robustness (P: Disturbance of objects in the vertical direction destroys contact). |
| Evaluation index | The main indicator is success rate. Wipe/Peel/Cut is used to handle the length ratio; Assembly/Grasp is used to insert completely or grab without loss; Adjustment is used to change the attitude beyond 60°. |
Training configuration table
| module | Training/Hyperparameters | Source |
|---|---|---|
| TactileVAE | Using 20% manipulation trajectories + 10 additional object tactile interaction data, ~1.2M tactile samples; training 50 epochs; 8 NVIDIA A100 GPUs; $\lambda_{KL}=1e-6$. | Text §Experimental Setup |
| VTWM | AdamW, lr $1\times10^{-4}$, weight decay 0, per-GPU batch size 5, 100, 000 steps, gradient norm threshold 0.1, enable gradient clipping after 20, 000 steps; $\lambda_{dyn}=1.0$, $\lambda_{amp}=1.0$. | Text §Training Details |
| AFP | The same training set; OmniVTA and policy baselines are combined to train a unified model for each type of data; AFP 250k steps; other baselines 350k steps; $\lambda_{ct}=0.2$. | Text §Training Details |
| Policy input/output | Vision 15 Hz, touch 60 Hz, body 60 Hz; input is the current + previous frame of vision, 8 frames of tactile in the same window, and 2 body observations; output 6 action chunks, interpolated to 60 Hz during execution. | Text §Parameter settings |
| Reasoning time | Slow Policy 230 ms; Slow Policy w/ Visual Gen. 480 ms; Fast Policy 3.5 ms; Hardware RTX 4090D. | Table policy_time |
6.2 Main results

| Method | Wipe O/G/P | Peel O/G/P | Cut O/G/P | Assembly O/G/P | Grasp O | Adjustment O/G |
|---|---|---|---|---|---|---|
| DP | 0.12/0.05/0 | 0.06/0/0 | 0.28/0.10/0 | 0.10/0/0.05 | 0.20 | 0/0 |
| DP+tactile | 0.36/0.28/0 | 0.32/0.20/0.08 | 0.33/0.15/0.13 | 0.30/0.10/0.10 | 0.48 | 0.25/0.15 |
| RDP | 0.50/0.38/0.42 | 0.48/0.36/0.45 | 0.65/0.50/0.43 | 0.60/0.50/0.35 | 0.88 | 0.50/0.50 |
| OmniVTA w/o RLTC | 0.66/0.40/0.25 | 0.40/0.30/0.20 | 0.50/0.50/0.20 | 0.40/0.35/0.20 | 0.70 | 0.40/0.30 |
| OmniVTA | 0.80/0.58/0.60 | 0.55/0.48/0.63 | 0.85/0.83/0.60 | 0.60/0.50/0.40 | 0.90 | 0.65/0.65 |
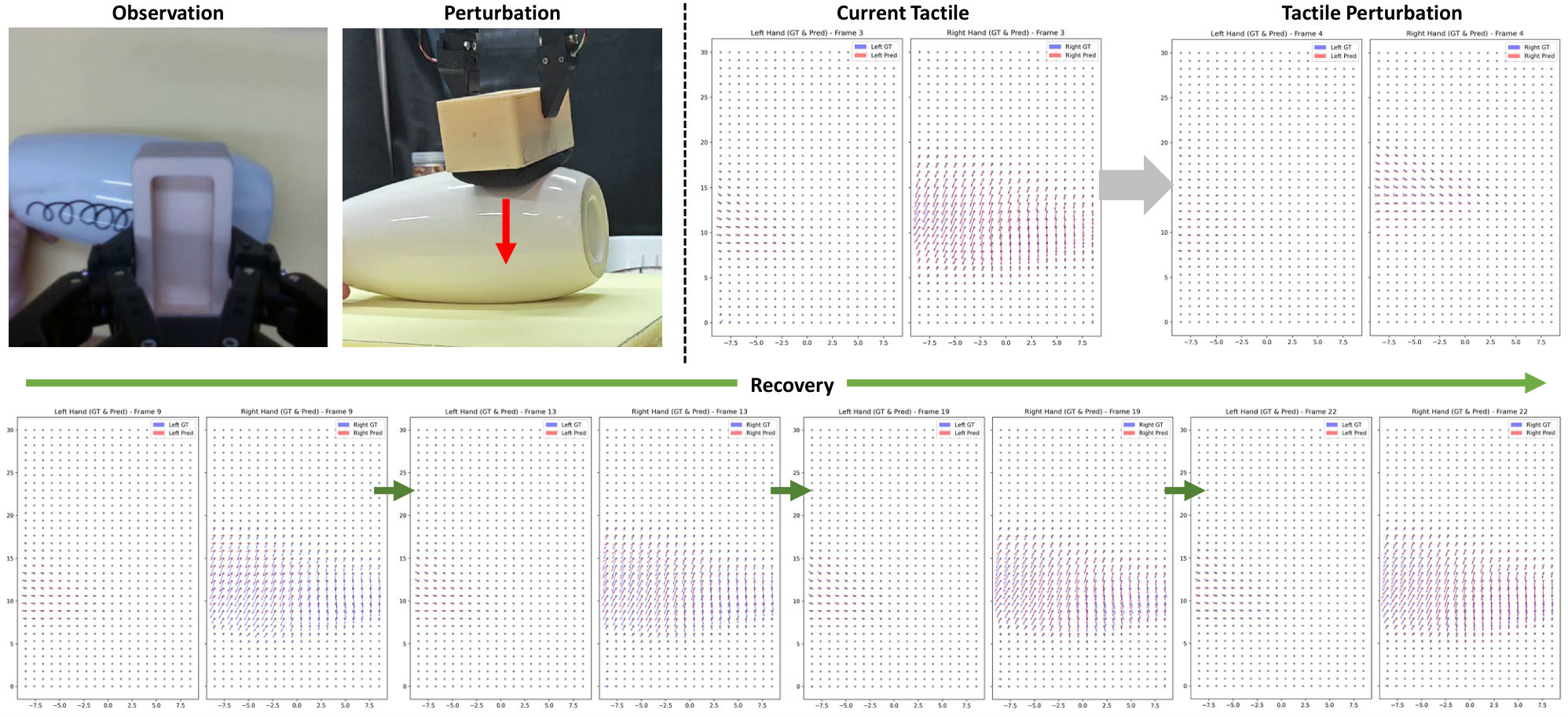
The most critical comparison in the table is between OmniVTA and OmniVTA w/o RLTC: the closed-loop control has Wipe P from 0.25 to 0.60, Peel P from 0.20 to 0.63, Cut P from 0.20 to 0.60, and Assembly P from 0.20 to 0.40, indicating that the main benefit of RLTC is reflected in disturbance recovery. Compared to RDP, OmniVTA reported lower tactile deformation during the strong contact task: 0.35 mean, 0.72 max, compared to RDP 0.56 mean, 1.1 max.
6.3 TactileVAE results
| Method | Wipe L2/cos | Peel | Cut | Assembly | Grasp | Adjustment |
|---|---|---|---|---|---|---|
| PCA | 0.091/0.810 | 0.085/0.430 | 0.109/0.400 | 0.071/0.720 | 0.036/0.600 | 0.069/0.560 |
| PointNet-AE | 0.059/0.910 | 0.067/0.850 | 0.062/0.840 | 0.058/0.900 | 0.028/0.750 | 0.047/0.760 |
| Ours | 0.038/0.930 | 0.033/0.880 | 0.031/0.940 | 0.022/0.910 | 0.011/0.720 | 0.017/0.850 |
TactileVAE has the lowest L2 in all six types of tasks, and the cosine similarity is the highest except for Grasp. The cos of PointNet-AE in Grasp is 0.750, which is higher than the 0.720 of Ours, but the L2 of Ours is 0.011, which is significantly lower than the 0.028 of PointNet-AE.
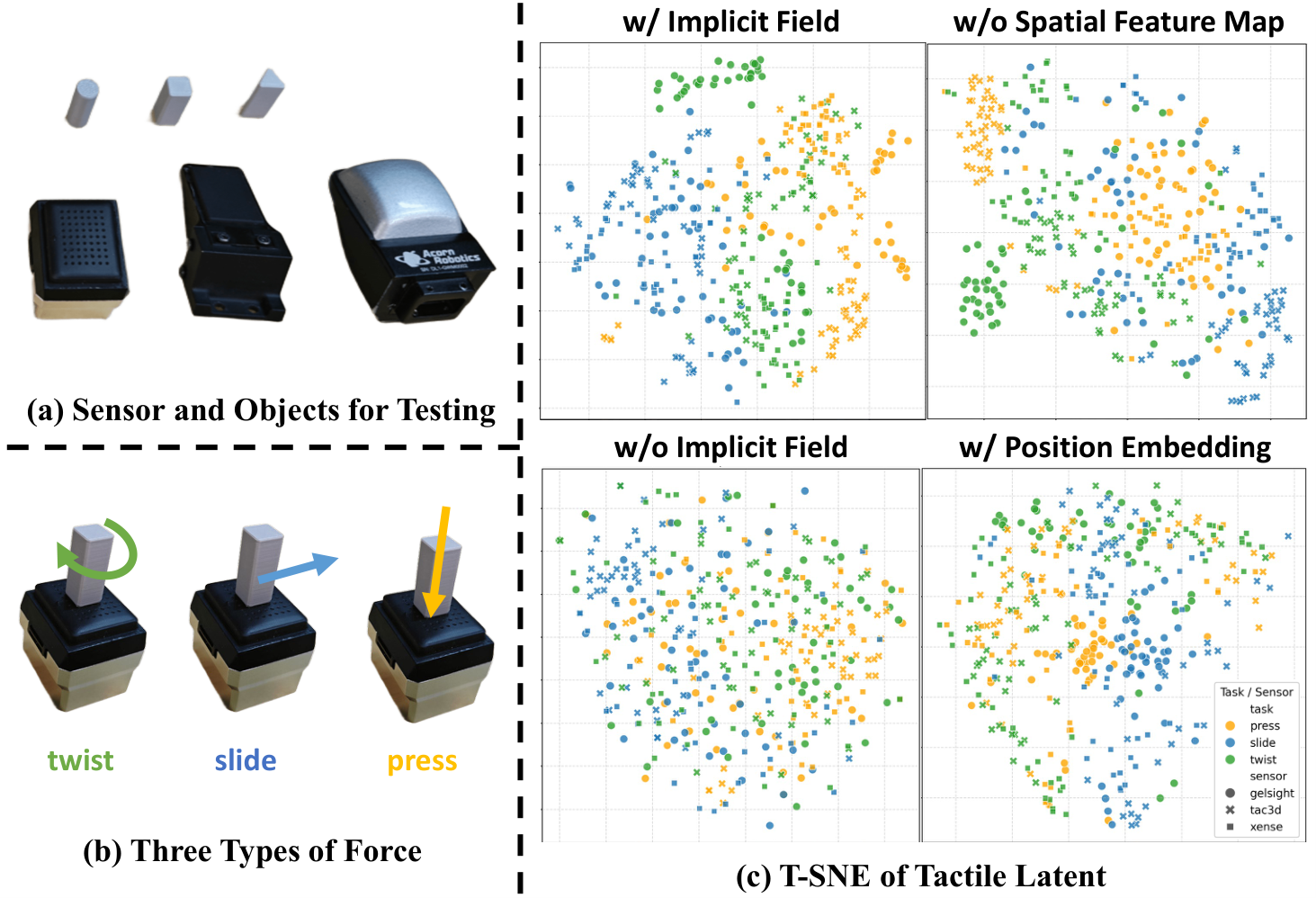
| TactileVAE Design | GelSight-Mini L2 | Tac3D-A1 L2 | Xense-QN1 L2 |
|---|---|---|---|
| w/o implicit decoder | 0.126 | 0.098 | 0.038 |
| w/ position embed. | 0.102 | 0.085 | 0.035 |
| w/o spatial feature map | 0.107 | 0.084 | 0.071 |
| w/ implicit decoder | 0.047 | 0.058 | 0.034 |
6.4 VTWM results and ablation
| Task | Ours L2avg / Cavg | Sub-optimal baseline L2avg/Cavg | Interpretation |
|---|---|---|---|
| Wipe | 0.059 / 0.93 | KineDex 0.082 / 0.81 | Ours simultaneously reduces error and improves directional consistency. |
| Peel | 0.036 / 0.87 | KineDex 0.066 / 0.79 | The prediction advantage is obvious in the continuous shear/normal coupling task. |
| Cut | 0.050 / 0.88 | UVA 0.077 / exUMI 0.72 | The high-force change scenario still maintains good long-term forecasts. |
| Adjustment | 0.025 / 0.85 | KineDex 0.053 / 0.70 | Torsion/shear dynamics of in-hand adjustments are better modeled. |
| Assembly | 0.030 / 0.89 | KineDex 0.047 / 0.78 | The world model is relatively stable in the local contact geometry task. |
| Grasp | 0.010 / 0.68 | KineDex 0.017 / 0.59 | Grasp L2 is the lowest, but the absolute value of cosine is lower than other tasks. |
| ablate | settings | L2 | Cos | Conclusion |
|---|---|---|---|---|
| Action representation | Unseen position: 3D absolute / 3D relative / 2D | 0.075 / 0.056 / 0.042 | 0.72 / 0.88 / 0.91 | 2D image-plane action generalizes best to unseen position. |
| Joint generation | Seen position: no joint gen vs joint gen | 0.041 → 0.038 | 0.90 → 0.92 | Jointly generated visual features provide global dynamic cues for tactile prediction. |
| Dynamic weighting | Seen position: add dyn. weight | 0.038 → 0.035 | 0.92 → 0.93 | Emphasizing rapid changes and strong contact areas aids tactile prediction. |
6.5 AFP and RLTC ablation
| Tactile pred. length | LTD | Gating | Visual gen. | Wipe | Peel | Avg. |
|---|---|---|---|---|---|---|
| 0 | × | × | × | 0.12 | 0.06 | 0.09 |
| 2 | × | × | × | 0.40 | 0.26 | 0.33 |
| 4 | × | × | × | 0.45 | 0.30 | 0.38 |
| 6 | × | × | × | 0.50 | 0.30 | 0.40 |
| 6 | ✓ | × | × | 0.57 | 0.36 | 0.47 |
| 6 | ✓ | ✓ | × | 0.66 | 0.40 | 0.53 |
| 6 | ✓ | ✓ | ✓ | 0.70 | 0.38 | 0.54 |
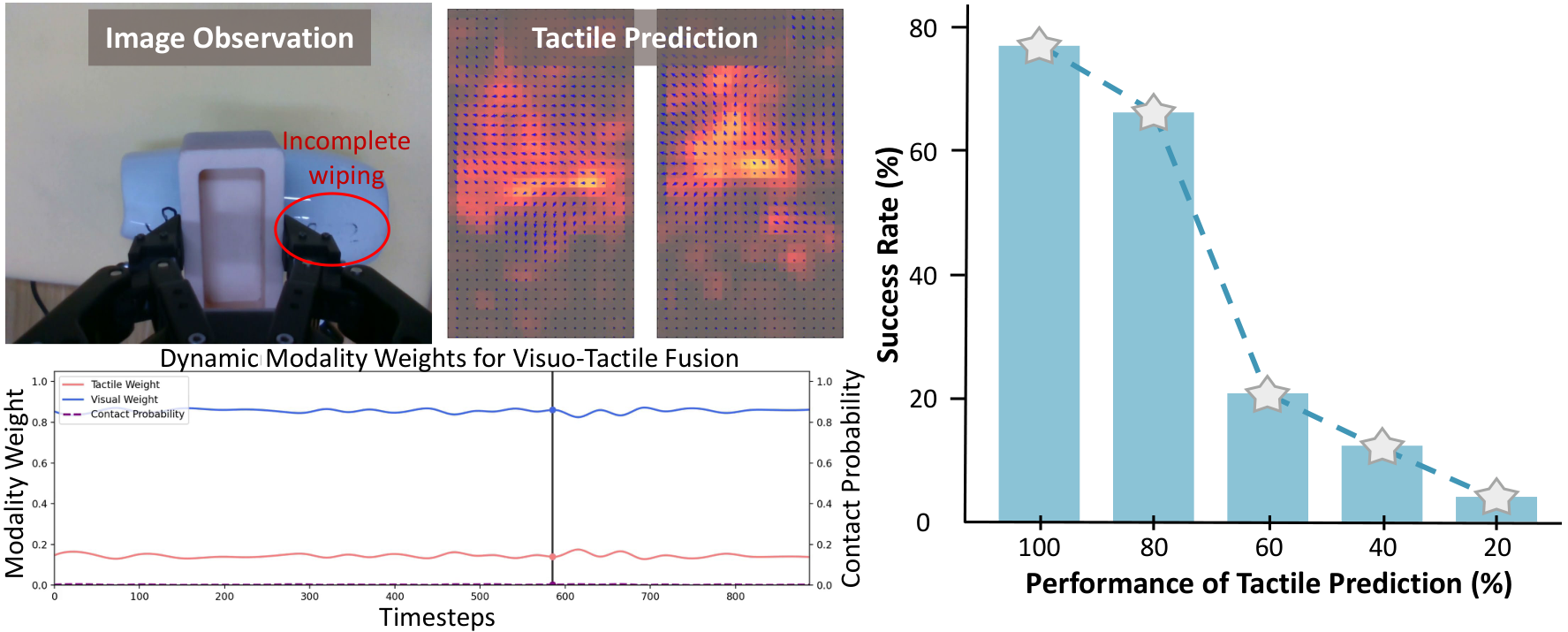
Ablation shows: predicting tactile length from 0 to 6, the average success rate rises from 0.09 to 0.40; adding LTD rises to 0.47; adding gating rises to 0.53. The average gain of adding visual generation is only 0.54, which is a small gain, while the inference time increases from 230 ms to 480 ms, so the final design does not rely on future visual generation.

7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Based on the paper's own contributions and experiments, the core value is to upgrade "tactile" from a passive policy input to three trainable/verifiable objects: compressible tactile representation, predictable future contact status, and target signals that can be used for high-frequency closed-loop correction. This value is not demonstrated by a module alone, but is supported by data set statistics, VTWM predictors, AFP ablation, and real robot perturbation experiments.
7.2 Why the results hold up
- Task coverage: Six types of physical contact modes cover precision contact, surface friction, strong normal force, continuous shear, grasping and in-hand adjustment.
- Assessment settings: Not only object diversity is reported, but also unseen heights, unseen tool, and contact perturbations are reported.
- Module evidence chain: TactileVAE reconstruction table, VTWM prediction table, AFP ablation table, and policy success table correspond to representation, prediction, fusion, and control respectively.
- Mechanism visualization: The gate weight changes with the contact probability, the prediction accuracy decreases, resulting in a decrease in the success rate, and the perturbation visualization shows the process from no-contact to recovery.
7.3 Limitations clearly stated by the author or in the source code
The text Conclusion does not formally expand limitations; there is a commented out "Limitation and future work" paragraph at the end of the source code, which reads: OmniViTac is currently a single-arm, gripper-based tactile manipulation benchmark, and has not yet covered dual-arm setting or other end-effector types, such as dexterous hands. The note also mentions that future work will explore extending the world model with larger and more diverse data, extending to dexterous hands and dual-arm manipulation, and cross-embodiment transfer. Since this paragraph is commented in the source code, this report labels it as "author's intention in source code comments", which is not equivalent to the formal text conclusion.
7.4 Applicable boundaries clearly stated in the paper
- The real operation experiment uses xArm7, parallel two-finger gripper and Xense tactile sensor; other sensors are mainly used for TactileVAE representation validation.
- The task definition focuses on six contact-rich manipulation patterns and does not cover dexterous full-hand haptics, dual-arm collaboration, or non-gripper end effectors.
- The VTWM reasoning stage mainly uses future tactile prediction and does not use future visual generation; the author's basis is that visual generation reasoning is costly and does not significantly improve the strategy success rate.
- Training of RLTC relies on identifying abnormal tactile states and recovery segments from human trajectories; this process assumes that the effective tactile distribution can be estimated for each type of task.
7.5 Summary of Chapter Coverage and Acceptance
Completed Phase 2.5 internal chapter inventory: Abstract, Introduction, Related Works, The OmniViTac Dataset, Methodology, Experimental Evaluation, Conclusion, and Acknowledgments have all been mapped to the corresponding chapters of the report; there is no Appendix file.
Covered All source code image files: teaser, dataset_teaser, OmniVTA-6pattern, data_stat_family, system, vae, slow-policy, controller, object, manipulation, tsne, wm, wm_disturb, gate_weight, mp_disturb, prediction.
Covered Main tables: dataset comparison summary, object/task setup, main success rate, TactileVAE comparison, TactileVAE ablation, VTWM prediction summary, VTWM ablation, AFP ablation, policy inference time.
Note Since the arXiv source code does not have an appendix, there is no appendix reference mark in the report; this is not an omission, but is caused by the structure of the source file.