Veo-Act: How Far Can Frontier Video Models Advance Generalizable Robot Manipulation?
1. 论文速览
- 难度评级:★★★★☆。需要理解视频生成模型、逆动力学模型、VLA 策略、机器人控制闭环与实验评估指标。
- 关键词:视频生成模型、机器人操作、逆动力学模型、VLA、层级控制、dexterous manipulation。
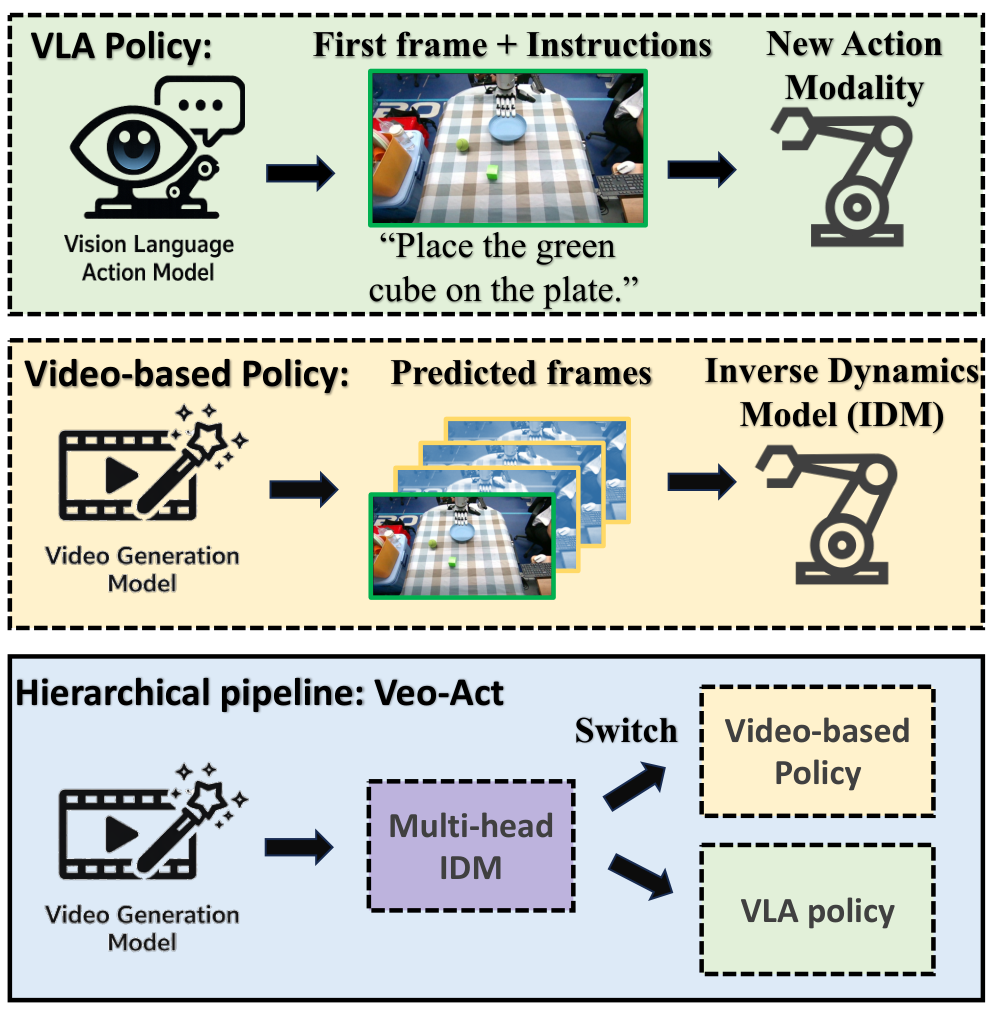
- 核心贡献 1:论文检验了一个具体问题:在零人工示范设定下,今天的前沿视频生成模型能把机器人操作推进到什么程度。这意味着论文不是只提出架构,而是先实验性评估“视频模型 + IDM”路线的上限。
- 核心贡献 2:论文发现 Veo-3 可以生成大体正确且遵循指令的任务级轨迹,但低层接触控制精度不足。这意味着视频模型更适合作为高层 motion prior,而不是直接替代控制策略。
- 核心贡献 3:论文提出 Veo-Act,把视频模型作为高层规划器,把 VLA 作为低层执行器,并用多头 IDM 的 gate 信号决定何时切换。这意味着系统试图保留视频模型的泛化能力,同时利用 VLA 的反应式接触控制能力。
2. 动机
2.1 要解决什么问题
论文关注的是开放环境中的泛化机器人操作:机器人需要在不同物体几何、语义指令和干扰物场景下完成抓取与放置。现有 VLA 模型依赖大规模机器人数据,并且从 VLM 转成 VLA 时需要引入动作模态;论文指出这会使预训练 VLM 的泛化知识难以完整保留。
论文构造的失败场景包括:目标物体不在腕部相机视野内、存在外观相似的干扰物、以及非目标物体位于机械臂经过路径上。这些场景不是单纯考察“能不能抓”,而是考察策略是否能在视觉、语义和路径干扰下仍然遵循目标指令。
2.2 已有方法的局限
- VLA 路线:RT-2、OpenVLA、$\pi_0$、$\pi_{0.5}$ 等模型把视觉语言输入映射到动作,但动作模态的引入可能削弱 VLM 预训练知识的保留;论文用这个解释 VLA 在语义混淆和分布变化下的失效。
- 视频模型 + IDM 路线:该路线保持视频模型的原生输入输出接口,能较好保留视频模型的泛化能力;但生成视频在接触丰富的低层物理交互中仍不够精确,IDM 将视觉误差转为动作后会放大控制误差。
- 单一路线的矛盾:VLA 擅长低层闭环接触但语义泛化会受限;视频模型擅长生成大体正确的任务级轨迹但低层控制不稳定。Veo-Act 的动机就是把两者分工。
2.3 本文的解决思路
高层由 Veo-3 根据初始图像和语言 prompt 生成完成任务的视频轨迹;中间由多头 IDM 把帧间变化转换为动作片段,并预测交互 gate;低层执行时,系统默认跟随视频规划动作,当 gate 表明进入接触交互阶段时,切换到 VLA 策略执行精细操作,之后可切回剩余规划队列。
3. 相关工作梳理
3.1 论文自述的相关工作
| 相关工作线 | 代表工作 | 论文中的定位 |
|---|---|---|
| 视频生成模型用于策略学习 | Sora、Veo、V-JEPA 2、Unified World Models、Vidar、VPP、AnyPos、TC-IDM | 视频模型含有物体持续性、运动连续性和粗粒度碰撞等物理先验,可生成视觉计划;但性能受视频保真度约束,尤其在接触丰富的灵巧操作中不足。 |
| Learning from Observation / IDM | LfO、VPT、Vidar、AnyPos、TC-IDM | IDM 可把状态或图像转移映射为动作,甚至可用无标签视频或 play data 学习;本文使用自监督 random play 训练多头 IDM。 |
| Vision-Language-Action Models | RT-2、OpenVLA、$\pi_0$、$\pi_{0.5}$ | VLA 是当前通用机器人策略的重要路线,但将 VLM 改造成动作输出模型会带来知识保留问题;本文把 $\pi_{0.5}$ 作为 baseline 和低层执行器。 |
3.2 直接前作对比
| 维度 | VLA / $\pi_{0.5}$ | 视频模型 + IDM / VPP | Veo-Act |
|---|---|---|---|
| 核心思路 | 直接从图像、语言和状态输出动作。 | 生成未来视频,再由 IDM 或逆模型恢复动作。 | 视频模型负责高层轨迹,VLA 负责接触交互,IDM 同时输出动作和切换 gate。 |
| 关键假设 | 训练后的动作模态仍保留 VLM/VLA 的语义泛化。 | 视频生成轨迹足够物理一致,IDM 能可靠恢复动作。 | 视频轨迹可作为任务级先验,但接触阶段需要反应式低层策略。 |
| 适用场景 | 训练覆盖充分、目标可见、语义混淆较弱的闭环操作。 | 简单交互或粗粒度任务规划。 | 语义或视角 confounder 明显,同时需要灵巧抓取的 pick-and-place。 |
| 实验性能 | 所有仿真+真实实验总体 overall success 为 102/228 = 0.45。 | 仿真中作为视频基线 VPP,多个条件低于 Veo-Act。 | 所有仿真+真实实验总体 overall success 为 182/228 = 0.80。 |
4. 方法详解
4.1 方法概览
Veo-Act 的数据流为:初始观测 $I_0$ 与任务 prompt → Veo-3 生成未来帧序列 $I^{*}_{0:n}$ → 多头 IDM 对相邻帧做逆动力学,输出动作片段 $a^{*}_{0:n-1}$ 与 gate 信号 → smoother 得到 $\bar{a}^{*}_{0:n-1}$ → 执行时从动作队列逐步 pop;如果实时 gate $G_t$ 持续高于阈值 $\tau$,切换到低层 VLA 策略 $\pi_{\mathrm{VLA}}$;gate 降低后,剪掉已过交互区间并恢复规划队列。
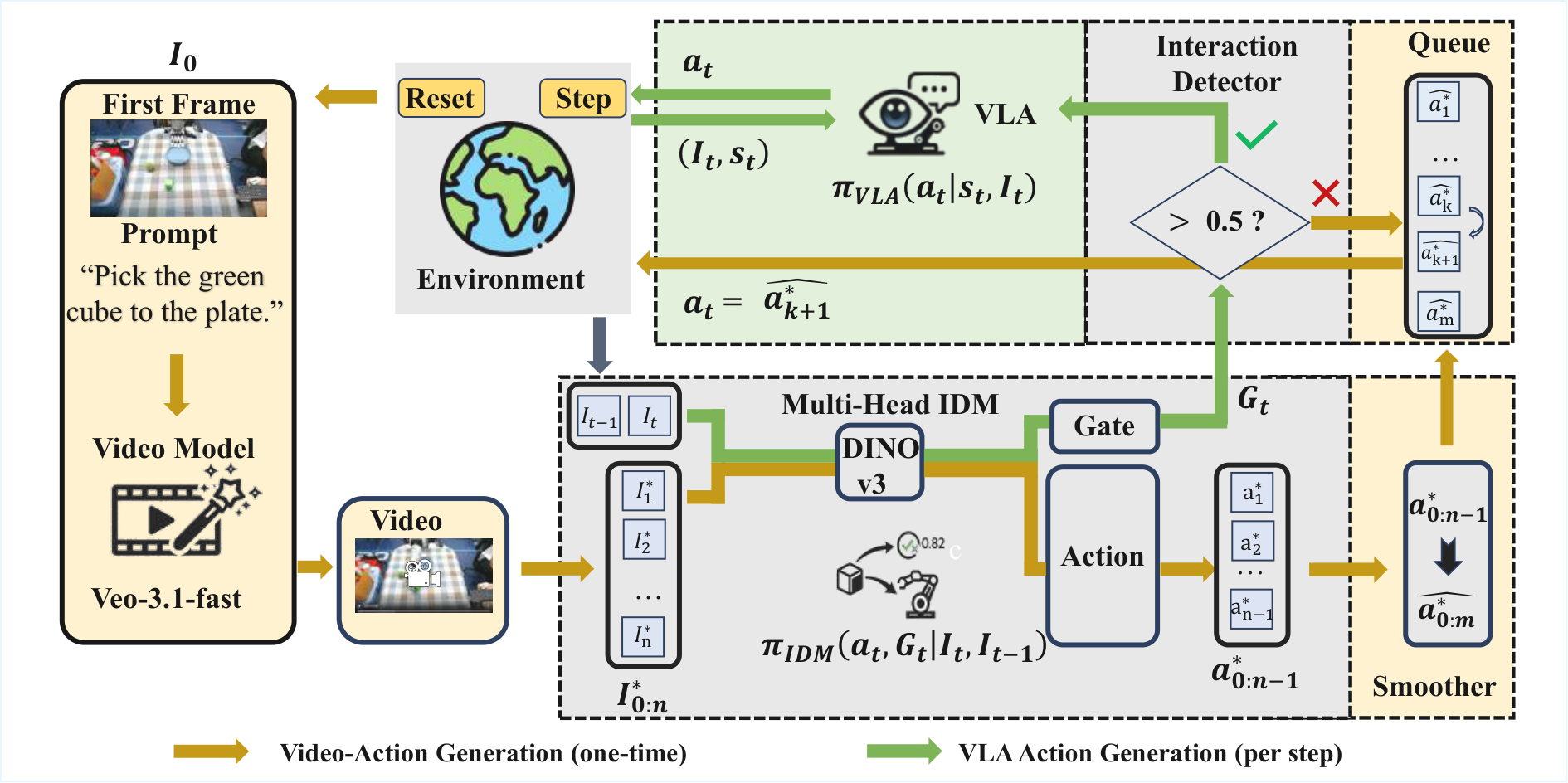

4.2 方法演变脉络
VLA 直接控制 → 输入当前观测和语言,直接输出动作;问题是 confounder 下容易误跟随错误物体或路径。
Video model + IDM → 先生成任务完成视频,再恢复动作;优势是保留视频模型的语义与物理先验,问题是接触控制精度不足。
Veo-Act → 用视频模型规划“到哪里、经过哪里”,用 VLA 完成“接触时如何稳定抓放”,并用 IDM gate 连接两种控制模式。
4.3 核心设计与数学推导
$$I^{*}_{0:n}=\{I^{*}_1,I^{*}_2,\ldots,I^{*}_n\}$$
这里 $I_0$ 是初始观测,$I^{*}_k$ 是第 $k$ 个合成未来帧,$n$ 是采样帧数。该公式的作用不是直接控制机器人,而是把语言目标转为可被 IDM 消化的视觉运动先验。
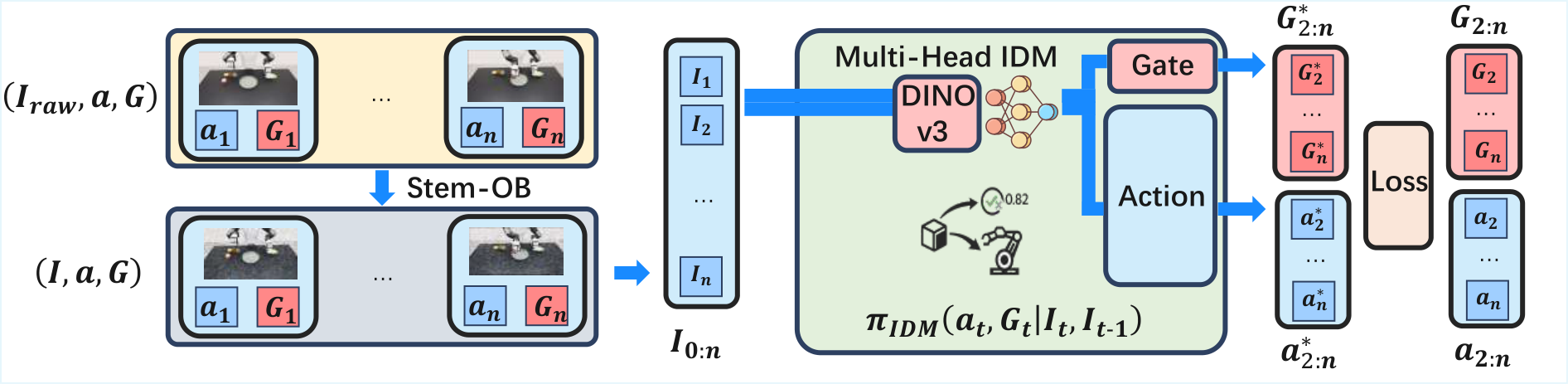
$$(a_t,G_t)=\pi_{\mathrm{IDM}}(I_{t-1},I_t,s_t)$$
| $I_{t-1}, I_t$ | 相邻两帧图像,表示视觉状态变化。 |
| $s_t$ | 机器人状态特征;实验中记录 21 维 single-arm state。 |
| $a_t$ | 恢复出的可执行动作;对生成视频整段运行可得到 $a^{*}_{0:n-1}$。 |
| $G_t\in[0,1]$ | 交互 detector 的输出,表示当前是否应交给低层 VLA。 |
直觉上,动作头负责“这两帧之间机器人应该怎么动”,gate 头负责“现在是不是进入抓取/接触等需要反应式策略的阶段”。分成两个 MLP head 是因为动作回归与二分类 gate 的数值分布不同。
$$\mathcal{L}=\lambda_{\text{act}}\mathcal{L}_{\text{act}}(a_t,\hat a_t)+\lambda_{\text{gate}}\mathcal{L}_{\text{gate}}(G_t,\hat g_t)$$
正文称动作头使用 Huber loss,gate 头使用 Binary Cross Entropy。附录进一步给出 IDM 训练目标:$\mathcal{L}_{\mathrm{IDM}}=\lambda_{\mathrm{act}}\sum_d d(a_{t,d},\hat a_{t,d})+\lambda_{\mathrm{gate}}\mathrm{BCE}(G_t,\hat g_t)$,其中 $d(\cdot)$ 是加权 Smooth L1。附录:IDM Training
补充推导:为什么 weighted Smooth L1 适合动作回归
$$\bar a^{*}_{0:n-1}=\mathrm{Smoother}(a^{*}_{0:n-1}),\qquad \mathcal Q=\{\bar a^{*}_1,\ldots,\bar a^{*}_m\}$$
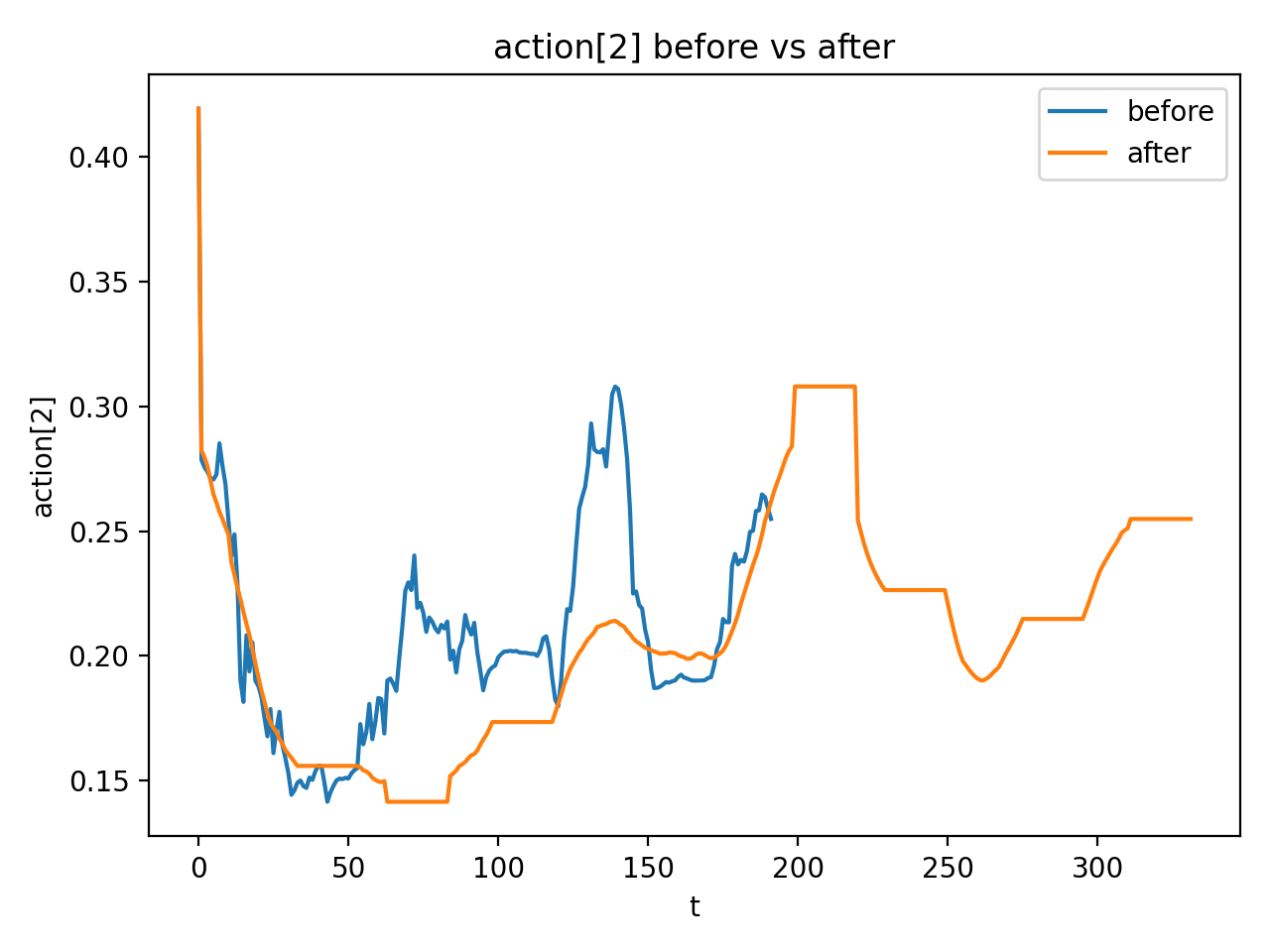
执行时默认动作是 $a_t=\bar a^{*}_{k+1}$。附录把 smoother 具体化为:对关键维度检测局部极值关键点,在相邻关键点区间内做 centered moving-average;关键点保持不变;关键点动作可额外 hold $H$ 步;最后对指定维度 $d_c=2$ 做下界 clamp,$m=0.13$。附录:Action Smoother
4.4 实现要点(面向复现)
| 模块 | 实现细节 | 来源 |
|---|---|---|
| Video prompt | prompt 明确要求机器人区分目标物与相似物、非目标物保持不动、目标在被抓取前保持原位、视角不变、运动平滑自然、容器不移动。 | 附录:Video-Generation Prompt Construction |
| 视觉编码器 | DINOv3 ViT-B/16,embedding 768,depth 12,heads 12,patch size 16,使用两个帧的 patch token 特征拼接为 1536 维。 | 附录:IDM Training |
| IDM 数据 | 正文写 300k 仿真 frame-pair,另加 100k 仿真 random-motion 与 150k 真实样本;附录写训练使用 550k frame-pair。 | 正文 §5.1 + 附录 |
| 噪声增强 | 对 RGB 轨迹运行 Stem-OB inversion 生成 noisy stem observations:50 denoising steps,10 inversion steps。 | 附录:IDM Training |
| 切换逻辑 | 维护 gate history $\mathcal H_G$;stable_high 后启用 VLA;stable_low 后关闭 VLA,并用 truncate/drop 操作跳过高 gate 对应队列段。 | 附录:Algorithmic Variants |
Hierarchical Veo-Act inference
1. reset environment and sample task
2. build video-generation prompt from task
3. generate future frames I*_{0:n} with Veo-3
4. run IDM.action over generated frames to get a*_{0:n-1}
5. smooth actions and enqueue them into Q
6. for each real timestep:
- observe current image/state
- compute gate G_t = IDM.gate(I_{t-1}, I_t)
- if gate stays low: execute next planned action from Q
- if gate stays high: execute low-level VLA action
- if gate returns low: prune high-gate queue segment and resume plan
5. 实验
5.1 实验设置
| 项目 | 内容 |
|---|---|
| 平台 | 7-DoF 机械臂 + 12-DoF 灵巧手;两个 RGB 相机:全局相机与腕部相机。视频生成和 IDM 使用全局相机;切换后低层策略可使用腕部相机。 |
| 仿真 | 使用 IsaacLab 构建与真实平台对应的高保真仿真环境。 |
| 任务 | 指定目标物体抓取并放入指定容器。 |
| 仿真 confounder | 腕部相机不可见、相似物体干扰、pass-by interaction。 |
| 真实机器人 confounder | 相似物体干扰、pass-by interaction、更复杂语义指令。 |
| Baselines | $\pi_{0.5}$ 作为 VLA baseline;仿真中还比较视频方法 VPP。Veo-Act 使用 $\pi_{0.5}$ 作为低层策略。 |
| 代码仓库 | 按 “Veo-Act code github” 与 “2604.04502 github” 检索,未找到明确官方仓库。 |
训练配置
| 超参数/配置 | 值 | 来源 |
|---|---|---|
| IDM 训练样本 | 550k frame-pair samples | 附录:IDM Training |
| IDM 训练迭代 | 85,000 iterations | 附录:IDM Training |
| IDM 硬件 | 4 NVIDIA Ampere-series 80 GPUs,约 10 小时 | 附录:IDM Training |
| IDM batch size | 每 GPU 8,总 batch size 32 | 附录:Table IDM Training |
| IDM optimizer | AdamW,$\beta=(0.9,0.999)$,$\epsilon=0.01$,weight decay 0.01 | 附录:Table IDM Training |
| IDM learning rate | DINO: $5\times10^{-5}$;其余模块: $5\times10^{-4}$ | 附录:Table IDM Training |
| IDM scheduler | Cosine scheduler,warmup 8,500 steps | 附录:Table IDM Training |
| $\pi_{0.5}$ training | batch size 32,初始 LR $2.5\times10^{-5}$,训练 40K iterations,使用官方实现与 LR scheduler | 附录:Pi0.5 Training |
5.2 主要结果
| 设置 | Baseline overall | Veo-Act overall | 论文给出的结论 |
|---|---|---|---|
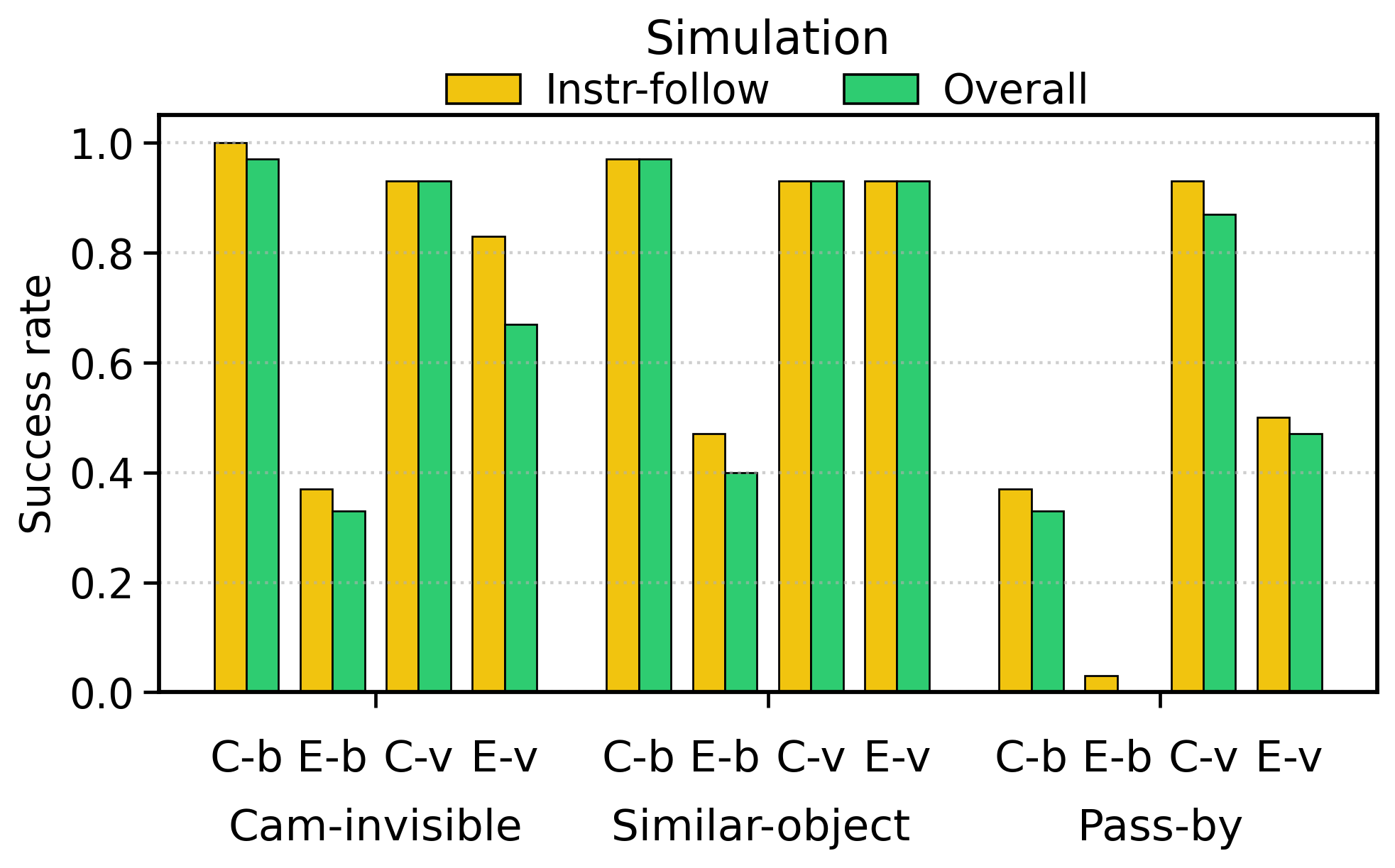
| 仿真:wrist-camera invisible / Experimental | 10/30 = 0.33 | 20/30 = 0.67 | Veo-Act 在目标不在腕部相机视野时提升到约 2 倍。 |
| 仿真:similar-object distractors / Experimental | 12/30 = 0.40 | 28/30 = 0.93 | Veo-Act 缓解相似物体语义混淆。 |
| 仿真:pass-by interaction / Experimental | 0/30 = 0.00 | 14/30 = 0.47 | Baseline 几乎失败,Veo-Act 恢复部分任务完成能力。 |
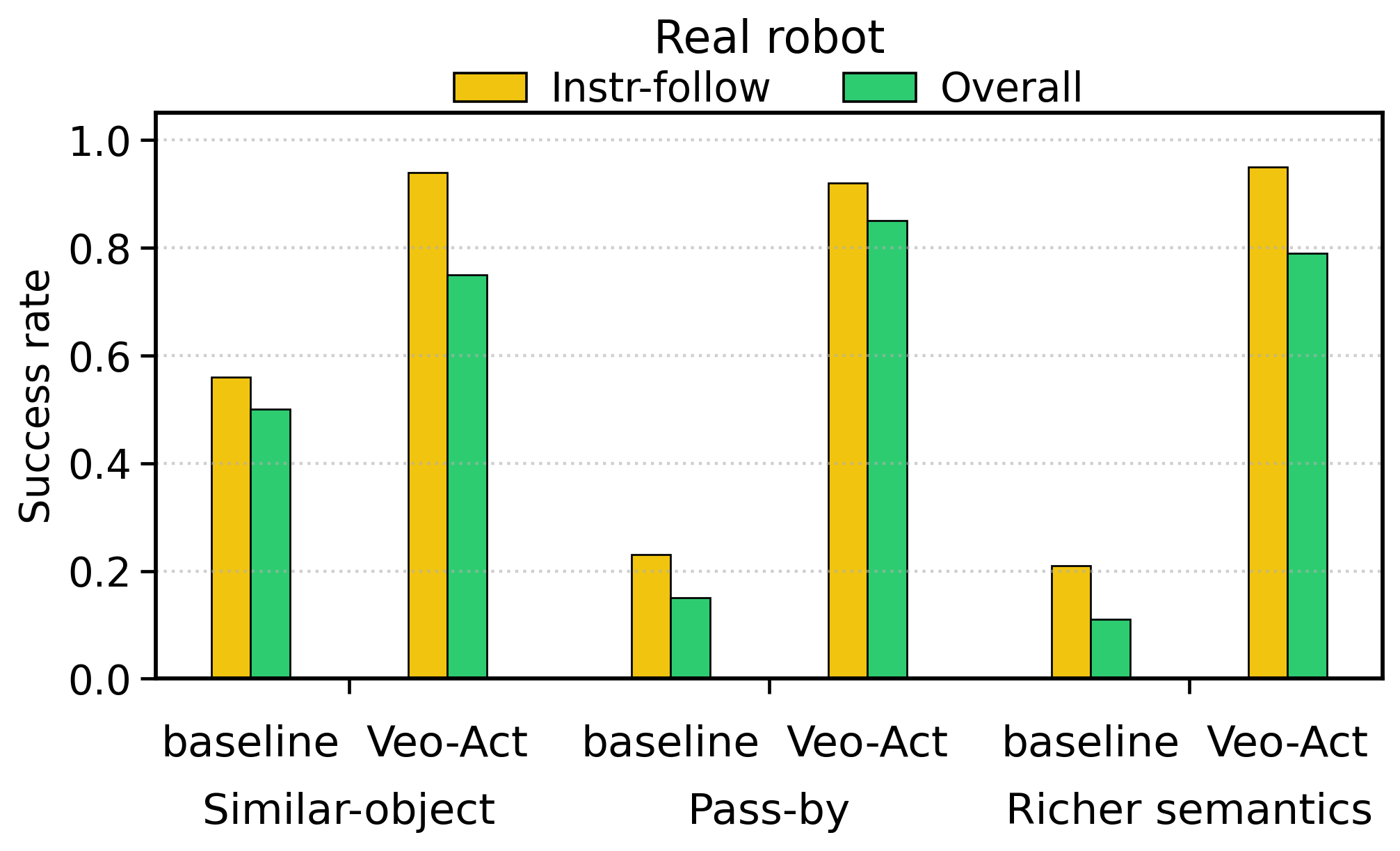
| 真实:similar-object distractors | 8/16 = 0.50 | 12/16 = 0.75 | 真实平台上同样获得提升。 |
| 真实:pass-by interaction | 2/13 = 0.15 | 11/13 = 0.85 | overall success 提升 5.7 倍。 |
| 真实:richer semantics | 2/19 = 0.11 | 15/19 = 0.79 | 复杂语义指令下 overall success 提升 7.2 倍。 |
论文汇总:仿真实验的 Experimental 条件下,baseline overall success 为 22/90 = 0.24,Veo-Act 为 62/90 = 0.69;仿真+真实所有 overall success 汇总,baseline 为 102/228 = 0.45,Veo-Act 为 182/228 = 0.80。
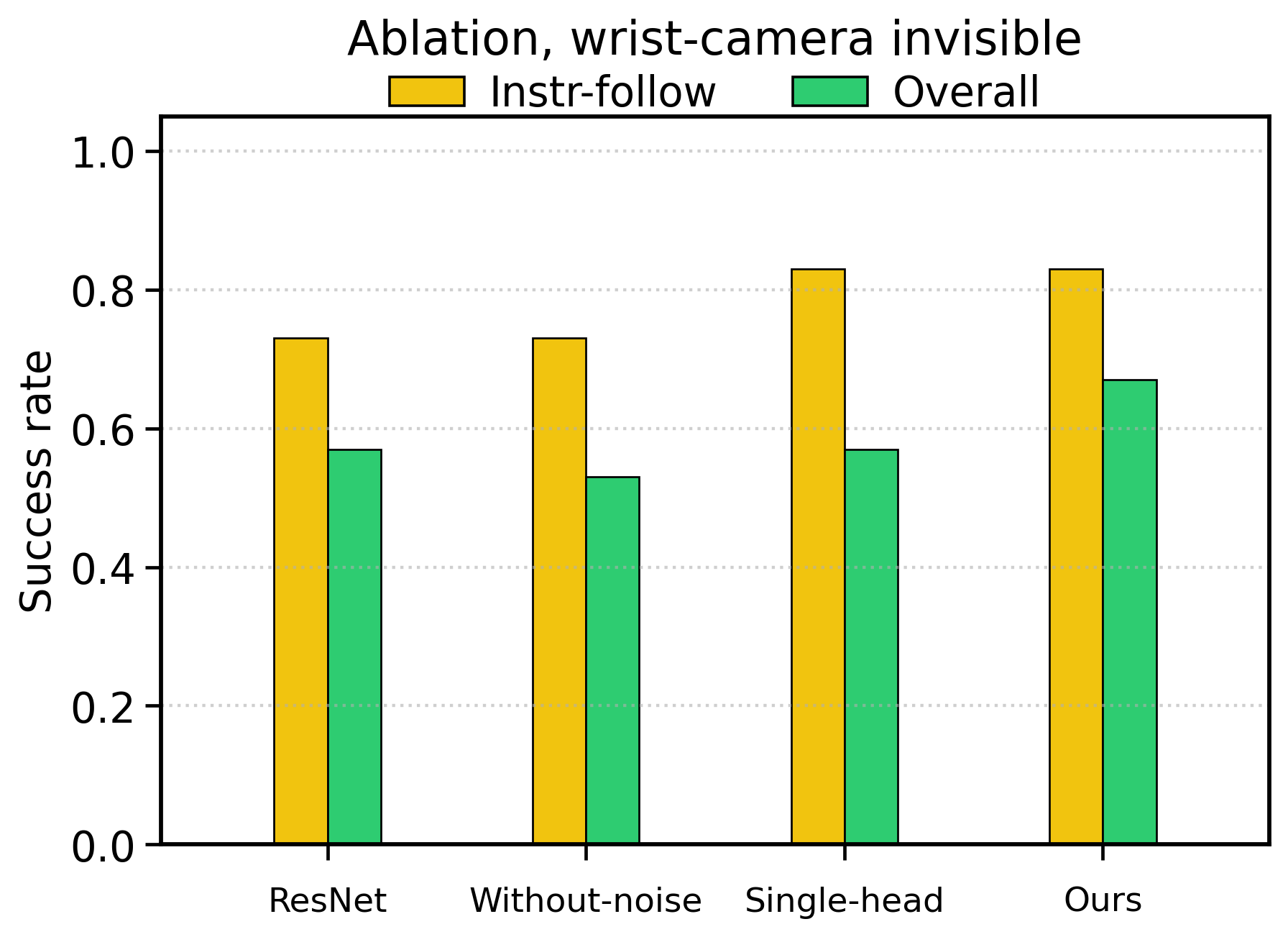
5.3 消融实验
| 变体 | Instruction-following | Overall | 验证目的 |
|---|---|---|---|
| ResNet backbone | 22/30 = 0.73 | 17/30 = 0.57 | 测试 DINOv3 视觉表征是否重要。 |
| Without noise | 22/30 = 0.73 | 16/30 = 0.53 | 测试 STEM-OB 噪声增强对鲁棒性的作用。 |
| Single head | 25/30 = 0.83 | 17/30 = 0.57 | 测试单动作头、不单独学习 interaction detector 的影响。 |
| Ours | 25/30 = 0.83 | 20/30 = 0.67 | 多头设计在不损害 instruction-following 的同时提高 overall success。 |
5.4 补充实验(来自附录)
- 四类详细设置:附录给出 invisible object、pass-by、similar-object distractors、richer semantics 的定性图示,并把这些内容补充为实验设置说明。
- Pure IDM 结果:附录报告 pure IDM 在同协议下的结果,用于隔离视频先验 + IDM 本身的能力;正文方法部分已把 pure IDM 作为 variant 解释。
- Failure analysis:附录列出实验设置中的失败类型,作为 §6 的局限与边界信息来源。
- Action smoother 可视化:附录展示平滑前后单个动作维度,说明 smoother 的实际效果。






6. 分析与讨论
6.1 论文已给出的结果分析与解释
- 论文解释 baseline 在 Experimental 条件下系统性下降,说明腕部相机视野、相似物干扰和 pass-by 干扰确实暴露了 VLA 的 instruction-following failure modes。
- 论文把 Veo-Act 的提升归因于视频模型生成的大体正确任务级轨迹,以及层级切换在接触阶段提供的闭环恢复能力。
- 论文指出 multi-head 设计提高 overall success,原因是动作预测和 interaction detection 联合学习更有利于 stage switching 和端到端执行。
6.2 作者自述的局限性
论文正文与结论中明确指出,当前视频模型还不能准确完成多数低层接触丰富的操作:Veo-3 + IDM 可生成大体正确轨迹,但低层控制精度不足,尤其在物理接触阶段。论文也指出这一路线受底层视频生成模型保真度约束,在灵巧操作这种高维动作空间和多点接触动力学场景中限制更明显。
附录 failure analysis 被纳入这里:失败主要对应 confounded 设置中目标辨识、路径干扰、接触执行和低层切换等环节。由于论文没有在正文中把这些失败扩展为新方法建议,本报告只客观记录其作为适用边界。
6.3 论文中明确写出的适用边界与讨论
- 适用条件:视频模型能生成近似正确任务级轨迹,IDM 能从帧间变化恢复可执行动作,低层 VLA 能处理接触阶段。
- 不适用或风险场景:视频预测在接触动态中明显不准确、目标/容器关系发生生成错误、gate 检测不稳定导致过早或过晚切换。
- 未来趋势:结论认为随着视频生成模型持续进步,视频模型可成为泛化机器人学习中的有价值组件;这被表述为论文总结,而非本报告的额外建议。
自验收
已完成:解析标题、作者、摘要、正文结构、方法、实验与附录。
已完成:附录中的 prompt、算法变体、pure IDM、failure analysis、smoother、IDM/$\pi_{0.5}$ 训练细节已整合到对应章节。
已完成:独立 PNG/JPG 图像已复制;主要 PDF 图已转换为 PNG 并嵌入。
注意:未找到明确官方代码仓库;报告中已按检索结果标注。