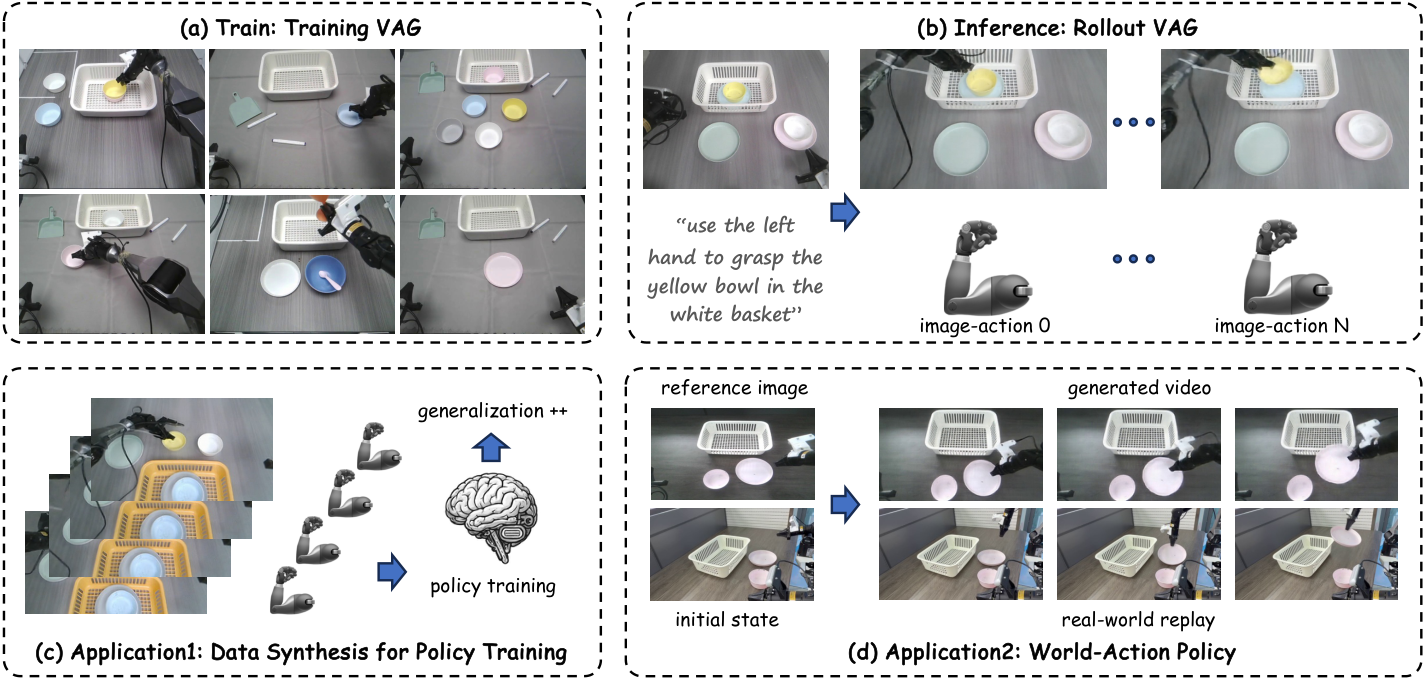
VAG: Dual-Stream Video-Action Generation for Embodied Data Synthesis
1. Reading orientation and group meeting guide
| Introductory items | What does this paper answer? | Where do you focus on when reading? |
|---|---|---|
| Research object | Given an initial image and language instructions, about 10 seconds of robot video and corresponding action trajectories are simultaneously generated. | It is not mainly about online closed-loop policy, but a data synthesis engine that can be used for policy training. |
| core issues | World Model can generate videos but no actions; two-stage video-to-action will produce error accumulation and cross-modal inconsistency. | See how VAG allows the action generation process to read the video latent at each denoising step. |
| Main contributions | Unified flow-matching dual-stream framework, simultaneous video/action denoising, adaptive 3D pooling bridging, synthetic data to enhance VLA generalization. | Focus on the directionality of the method: the video latent guides the action, but the action does not have the reverse guidance video. |
| Relationship with UVA/CoVAR | UVA tends to unify latent and multi-functional policies; CoVAR tends to preserve video DiT and parallel action DiT; VAG tends to synthesize long video-action data. | VAG is positioned closer to a "data engine" rather than using the generative model directly as a high-frequency controller. |
2. Background: Why can't World Model directly train policy?
2.1 VLA/VA policy: Can be implemented, but data is expensive
Vision-Language-Action models typically operate in a closed-loop fashion: observe the current image and state, predict an action for 1 to 2 seconds, and predict again using new observations after execution. They can already complete complex tasks, but training requires large amounts of human teleoperation data. Demonstrations must be collected for each new scenario and task, which is the data bottleneck this article aims to alleviate.
2.2 World Model: Rich videos, but no action tags
Modern video generation/World Model can generate rich visual rollout and provide diverse scenes. However, if the generated result is only video without paired action trajectory, it cannot be directly used as robot policy training data. For robots, there is a layer of motion alignment issues between "what looks like happening" in the video and the actual motor control signals.
2.3 Two-stage World-Action: Can supplement actions, but is easy to misplace
The two-stage solution first uses World Model to generate video, and then uses methods such as IDM and AnyPos to return actions from the video. This can get longer video-action pairs, but it will introduce error propagation between heterogeneous models: the video generation is a little wrong, and the action regression is a little wrong again; more troublesome is that the video and the action are not determined synchronously in the same generation process, so cross-modal inconsistencies are prone to occur.
2.4 Positioning of VAG
The goal of VAG is to serve as a World-Action data synthesis engine: instead of just using future videos as auxiliary supervision for action prediction, it directly outputs video-action pairs that can be used for policy training. The paper highlights that this generated data can also improve OOD generalization of downstream VLAs.
3. Detailed explanation of methods: flow matching, dual-stream simultaneous denoising and 3D pooling
3.1 Flow Matching Basics
VAG uses flow matching instead of traditional diffusion loss to describe the path from data to noise. Given data sample $\mathbf{x}$, Gaussian noise $\boldsymbol{\epsilon}\sim\mathcal{N}(0, I)$ and timestep $t\in[0, 1]$, the interpolated latent is:
Intuition:
When $t=0$ it is clean data, when $t=1$ it is pure noise, and the middle is straight line interpolation.
The corresponding ground-truth velocity is:
The model predicts velocity and is trained with MSE:
Reading reminder:
$\mathbf{c}$ includes text, reference images and other conditions. Both the video branch and the action branch of VAG apply this velocity matching idea, but the data spaces are different.
3.2 Video branch: video flow of Cosmos-Predict2
The video branch inherits Cosmos-Predict2 (2B-Video2World). The input includes the first frame image and language instructions, and the output is the future video $\mathbf{V}\in\mathbb{R}^{C\times T\times H\times W}$. In the experiment, $T=93$, the video frequency is 10 Hz, which is approximately equal to 10 seconds; the image is resized to $H=432, W=768$, RGB so $C=3$.
The original video is compressed by VAE tokenizer, and the time/height/width compression rates are $4\times 8\times 8$ respectively, and we get: $\mathbf{z}\in\mathbb{R}^{C'\times((T-1)/4+1)\times\lfloor H/8\rfloor\times\lfloor W/8\rfloor}$. Paper setting $C'=16$. The noise latent is concatenated with the latent prefix of the first frame and then input into DiT; the text is encoded by T5-XXL and injected through cross-attention; classifier-free guidance is used during inference.
3.3 Action branch: simultaneous denoising + global video conditions
Action branch prediction $\mathbf{A}\in\mathbb{R}^{T\times D}$. $D=16$ in AgiBot G1 dual-arm data; $D=7$ in LIBERO single-arm simulation; $D=14$ in self-collected Agilex dual-arm data. The action branch starts from Gaussian noise $\boldsymbol{\epsilon}_a\in\mathbb{R}^{T\times D}$, which is denoised with 1D U-Net adapted from Diffusion Policy.
The key design is: the action branch receives the current clean latent $\mathbf{z}_0$ predicted by the video branch at each denoising step. VAG first performs adaptive 3D pooling on $\mathbf{z}_0$, compresses the entire space-time latent into $\mathbb{R}^{C'\times1\times1\times1}$, reshapes it into $\mathbb{R}^{1\times C'}$, and then repeats/expands it into $\mathbf{e}\in\mathbb{R}^{1\times C''}$. Paper setting $C''=132$. This $\mathbf{e}$ is used together with timestep embedding as a condition for U-Net.
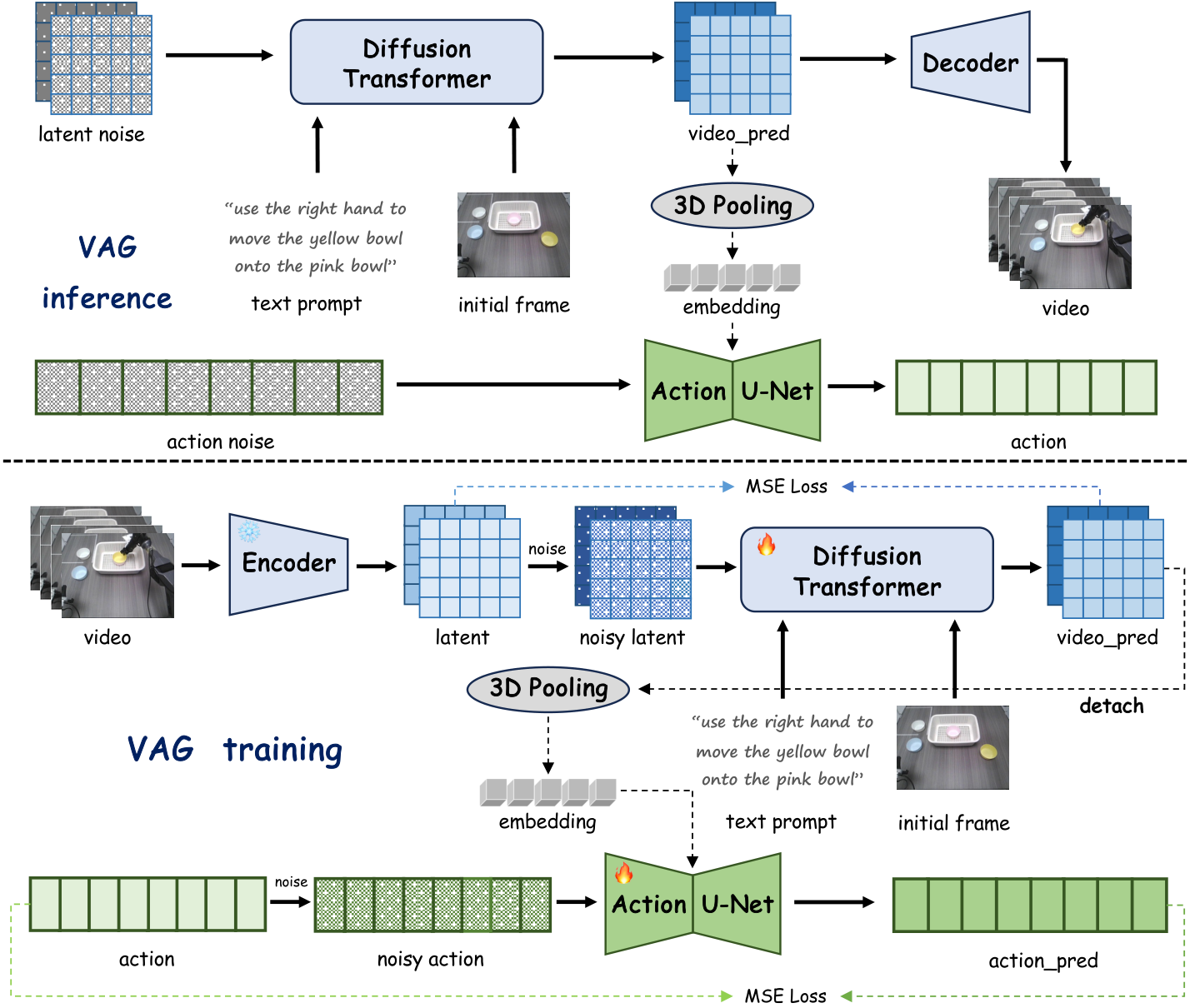
3.4 Training loss
When training, VAG uses video trajectories with actions and text instructions. For each ground-truth video, the paper uses Qwen2.5-VL to automatically extract text instructions describing the robot's behavior, and then encodes them with T5-XXL. The model is initialized from the underlying video generation model to preserve visual priors.
Video branch loss:
$$ \mathcal{L}(\theta_1)=\left\|\phi_1(\mathbf{D}(\mathbf{z}'; \theta_1))-\mathbf{z}\right\|^2. $$Meaning:
$\mathbf{D}$ is DiT, $\mathbf{z}'$ is noisy video latent, and $\phi_1$ represents the process of reconstructing clean latent from DiT output.
Action branch loss:
$$ \mathcal{L}(\theta_2)=\left\|\phi_2(\mathbf{U}(\mathbf{A}'; \theta_2))-\mathbf{A}\right\|^2. $$Meaning:
$\mathbf{U}$ is 1D U-Net, and $\mathbf{A}'$ is the action after perturbation with the same noise intensity. The action branch condition comes from detached clean video latent, which means that the action loss during training does not reversely drive the video branch.
3.5 Training/inference pseudocode
训练阶段:
for each video-action trajectory:
use Qwen2.5-VL to obtain text instruction
encode text with T5-XXL
encode video V with VAE into latent z
add flow-matching noise to z -> z'
video DiT predicts clean latent from z', first-frame prefix, text
adaptive 3D pool predicted clean video latent into global embedding e
add matched noise to action sequence A -> A'
action 1D U-Net predicts clean action from A', timestep, e
optimize video latent MSE + action MSE
推理阶段:
given initial image and instruction:
initialize video noise and action noise
for N = 35 synchronized denoising steps:
video branch predicts current clean video latent z0
pool z0 into global condition e
action branch denoises action with e
decode final video latent into video
output synchronized video V and action A4. Experimental results: generation quality, trajectory replay, VLA pre-training
4.1 Experimental setup
| Project | settings |
|---|---|
| Video basic model | Cosmos-Predict2 (2B-Video2World), generates 480P, 10 Hz video. |
| generate horizon | $T=93$ video-action frames, about 10 seconds. |
| input resolution | Video resize to $432\times768$. |
| latent channel | $C'=16$. |
| action condition embedding | $C''=132$. |
| reasoning denoising steps | $N=35$. |
| training resources | 8 NVIDIA H20 GPUs, batch size 1 per GPU, training 40, 000 iterations. |
4.2 Dataset
| Dataset | Scale and mission | How to use VAG |
|---|---|---|
| AgiBot | Large real robot data set, 1M trajectories, 217 tasks, five types of deployment scenarios. | Only using AgiBot G1 dual-arm humanoid data, 1794 training video-action pairs, 200 testing, action dimension $D=16$. |
| LIBERO | Simulation manipulation benchmark, including Spatial/Object/Goal/Long subset. | Select 400 training pairs and 50 test pairs; single-arm robot action dimension $D=7$; use head and wrist cameras to splice videos. |
| Self-collected | Agilex Cobot Magic dual-arm robot data. | Action dimension $D=14$; 131 samples are used for VAG training and 20 samples are used for VLA training. |
4.3 Video generation quality
VAG compares video generation quality on AgiBot with SVD, Wan2.2, Cosmos-Predict2 (CP2). VAG is the best in FVD, LPIPS, PSNR, FID is close to Wan2.2, SSIM is not as good as Wan2.2 but better than SVD/CP2. This result shows that after post-training on robot data, VAG does not sacrifice video quality by adding action branches.
| method | FVD ↓ | FID ↓ | LPIPS ↓ | SSIM ↑ | PSNR ↑ |
|---|---|---|---|---|---|
| SVD | 1311 | 150 | 0.421 | 0.339 | 12.7 |
| Wan2.2 | 1152 | 129 | 0.325 | 0.612 | 14.5 |
| CP2 | 988 | 135 | 0.352 | 0.427 | 14.2 |
| VAG | 965 | 130 | 0.320 | 0.512 | 15.1 |

4.4 Action Generation: Comparing Two-Stage Regression
Action baselines are a two-stage solution: first use VAG-Video to generate video, and then use ResNet or AnyPos to return actions from the video. The synchronous generation of VAG achieves the lowest Euclidean Distance and the highest Success Rate on both AgiBot and LIBERO. The definition of Success Rate is that the error in each dimension is less than 0.2 to be considered successful.
| method | AgiBot ED ↓ | AgiBot SR ↑ | LIBERO ED ↓ | LIBERO SR ↑ |
|---|---|---|---|---|
| VAG-Video + ResNet | 1.54 | 8% | 0.87 | 37% |
| VAG-Video + AnyPos | 0.98 | 29% | 0.55 | 66% |
| VAG | 0.81 | 45% | 0.38 | 79% |
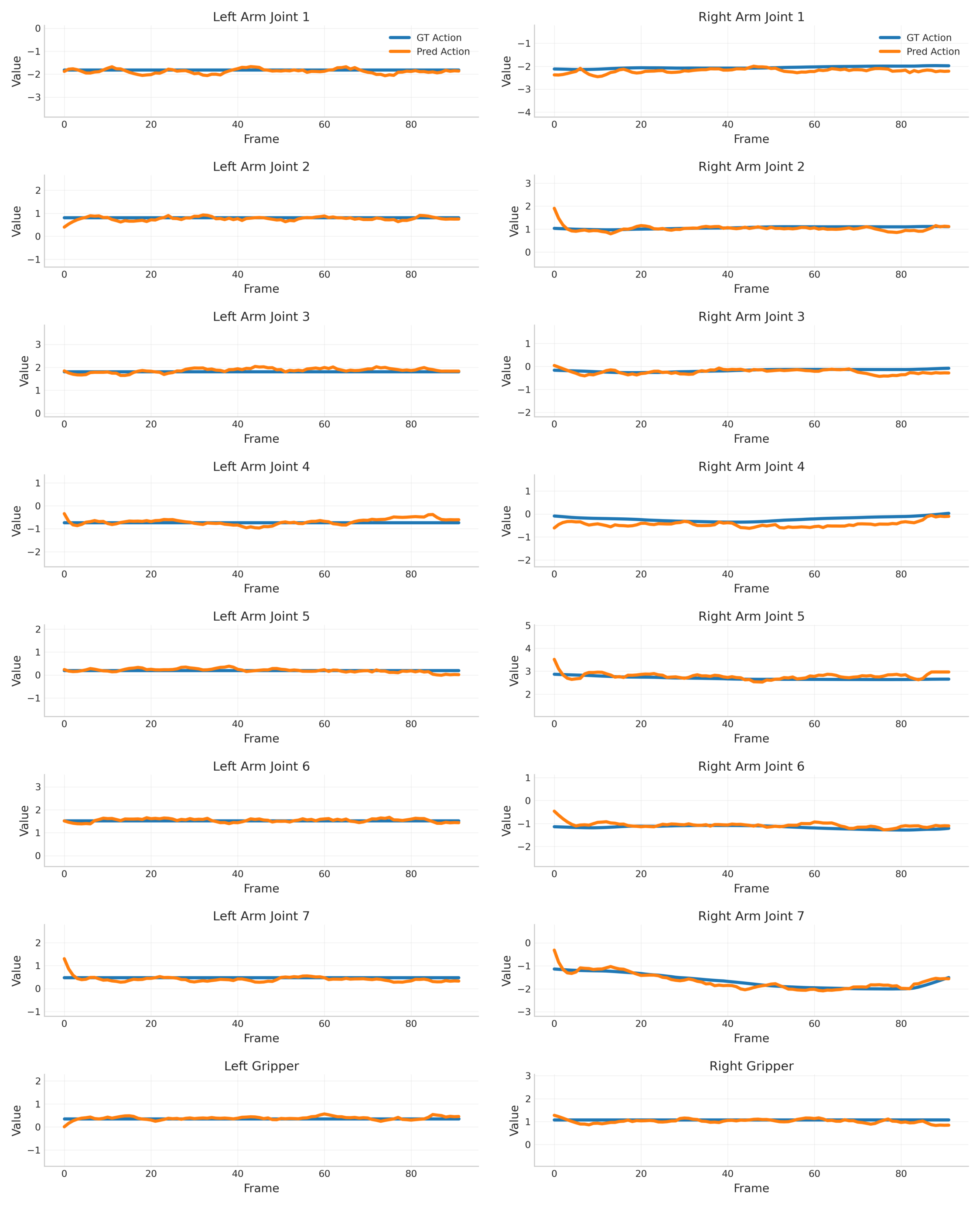
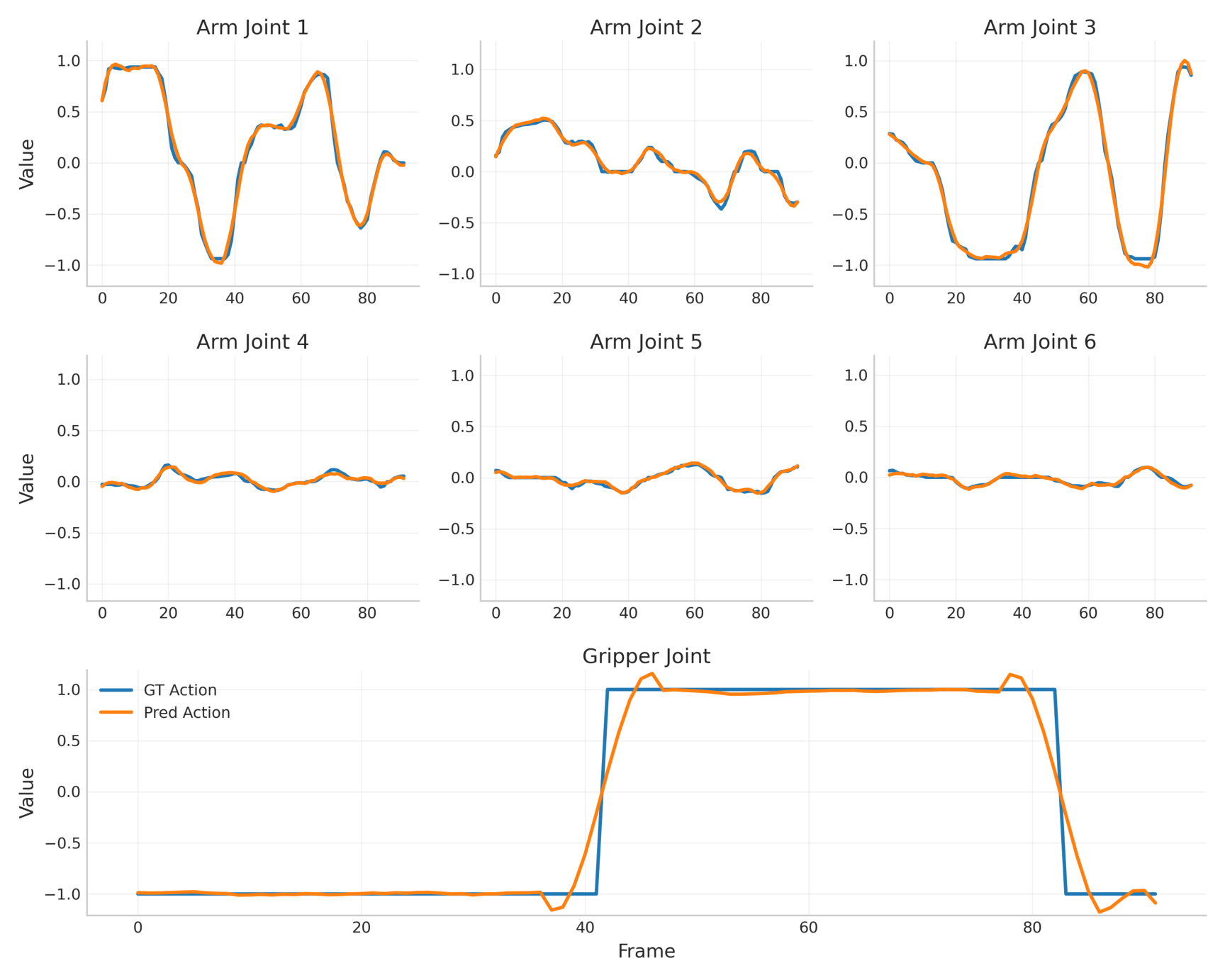
4.5 LIBERO trajectory replay
On the LIBERO benchmark, VAG not only compares action errors, but also replays the generated actions into the simulation to see the task success rate. VAG outperforms the two-stage method in the four subsets of Spatial/Object/Goal/Long, and the average replay success increases from 54% of AnyPos to 62%.
| method | Spatial ↑ | Object ↑ | Goal ↑ | Long ↑ | Avg ↑ |
|---|---|---|---|---|---|
| VAG-Video + ResNet | 33 | 34 | 23 | 10 | 25 |
| VAG-Video + AnyPos | 59 | 62 | 56 | 39 | 54 |
| VAG | 70 | 72 | 64 | 42 | 62 |

4.6 Improving VLA generalization with synthetic data
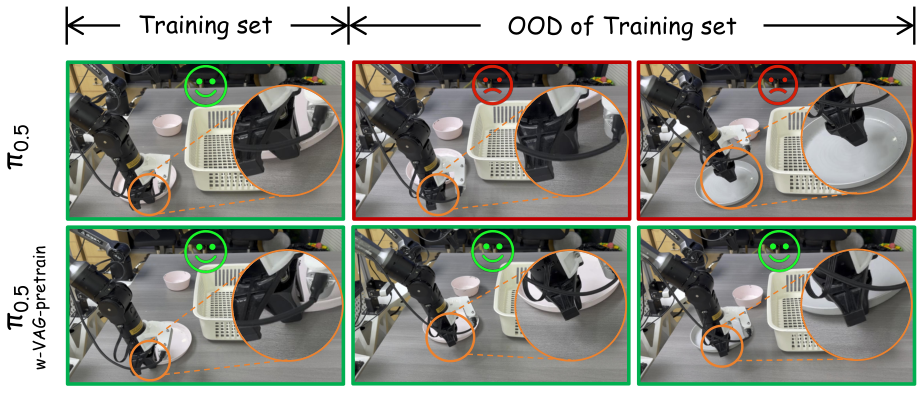
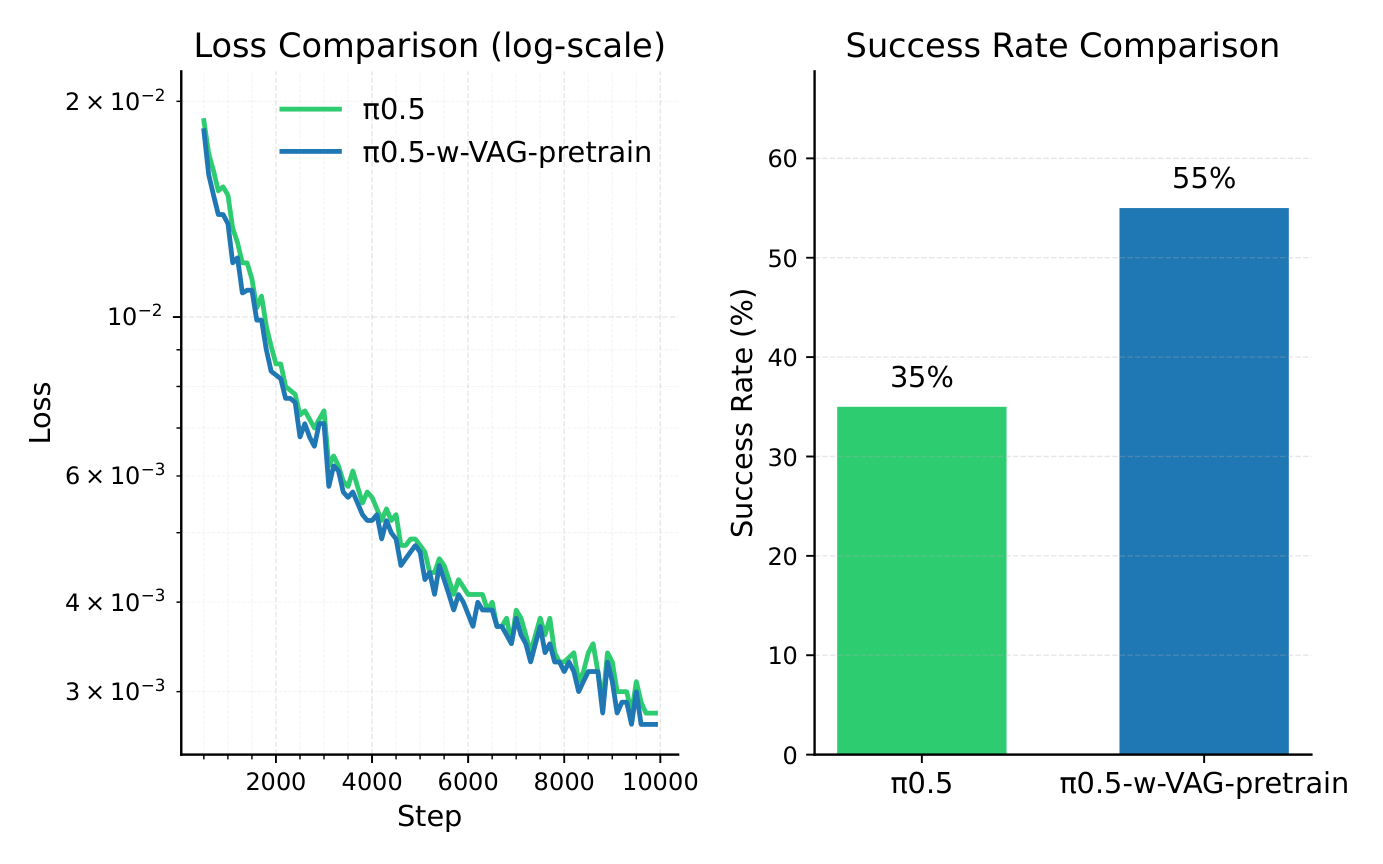
The most valuable experiment in the paper is VLA pretraining. The author first used 131 samples to train VAG on self-collected data, and then generated synthetic video-action pairs from the first frame and text prompt to form $\mathcal{X}_{syn}$. The downstream VLA is $\pi_{0.5}$: the baseline only uses 20 real samples $\mathcal{X}_b$ to train for 10, 000 iterations; the enhanced version first pretrains on the VAG synthetic data to convergence, and then uses the same $\mathcal{X}_b$ finetune for 10, 000 iterations.
In real robot tableware pick-and-place, baseline $\pi_{0.5}$ succeeded 7 times out of 20 trials, or 35%; $\pi_{0.5}$-w-VAG-pretrain succeeded 11 times, or 55%, an absolute improvement of 20%. The author pointed out that the enhanced model generalizes better when the object position or color changes, and there is no problem that baseline training loss decreases but deployment overfitting occurs.
4.7 Direct replay as World-Action policy
VAG is also used to directly generate actions "like a policy" and deploy them to Agilex robots. The input is head camera images and text instructions, and the output is video and actions; the action trajectories are replayed to the real robot. The paper shows three types of manipulation: left arm, right arm, and both arms, indicating that VAG's movements are not only suitable for offline training, but also have certain executability.

5. Intensive reading of charts
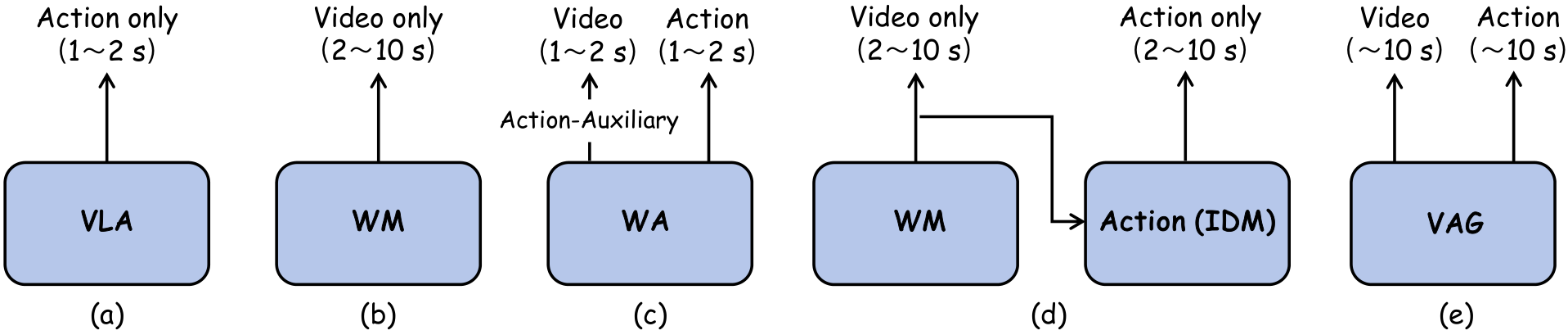
5.1 Fig. 2: The position of this paper is very clear
Fig. 2 distinguishes VAG from four routes: VLA is policy, WM is video generation, WA-policy uses future video to assist actions, and WM+IDM is two-stage synthetic data. VAG's unique positioning is to "directly synthesize training data", that is, the video-action pair itself is used as the output target.
5.2 Fig. 3: The action branch depends on clean latent, not the final video
The most important difference between VAG and the two-stage method is in Fig. 3: the action is not to regress from the decoded RGB video, but to read the currently predicted clean latent of the video branch in each denoising step. This avoids the lag and error accumulation of first generating a complete video and then reversing the action.
5.3 Table 2: AnyPos is already strong, but synchronous generation is still better
In the action table, VAG-Video + AnyPos is already much stronger than ResNet, indicating that the strong visual regressor can alleviate the two-stage problem. However, VAG still reduces ED and improves SR on both AgiBot and LIBERO, supporting the claim that "cross-modal synchronization generation is more consistent than posterior action regression".
5.4 Fig. 9: The VLA pre-training experiment is very tempting, but the number of samples is still small
The 35% to 55% improvement is one of the most eye-catching results of the paper. However, this experiment used 131 VAG training samples and 20 VLA real training samples, and the total number of trials was 20. It demonstrates that the direction is feasible, but does not yet illustrate stable gains on larger task libraries, longer horizons, or multiple robots.
5.5 Training loss curve
6. reproducibility list and project details
6.1 Hyperparameters that can be extracted directly
| Project | value |
|---|---|
| Basic video model | Cosmos-Predict2 (2B-Video2World) |
| Number of video frames | $T=93$ |
| video frequency | 10 Hz |
| Generation duration | about 10 seconds |
| video resize | $432\times768$ |
| VAE compression ratio | time/height/width = $4\times8\times8$ |
| video latent channel | $C'=16$ |
| action condition embedding | $C''=132$ |
| Reasoning steps | $N=35$ denoising steps |
| text generation | Qwen2.5-VL extracts instruction from ground-truth video |
| text encoding | T5-XXL |
| action denoiser | 1D U-Net modified from Diffusion Policy |
| training resources | 8 NVIDIA H20 GPUs, batch size 1/GPU, 40, 000 iterations |
6.2 Recurring gaps
- Official code is missing: Currently, arXiv/source does not provide an official VAG repo, so the training schedule, optimizer, learning rate, CFG scale, etc. cannot be fully confirmed.
- Cosmos-Predict2 transformation details: Video DiT requires code-level instructions on how to post-train, which layers to finetune, and how to splice prefix frames.
- Action normalization: The action scale, joint/terminal posture format, and arm splicing sequence of AgiBot/Agilex/LIBERO are not fully detailed in the text.
- Success Rate Threshold: The text states that an error of less than 0.2 per dimension is considered successful, but the action units of different data sets are different, and the physical meaning of the threshold needs to be supplemented.
- Synthetic data size: The specific number of samples, prompt sampling, and diversity enhancement methods of $\mathcal{X}_{syn}$ are not listed in detail.
- Real replay security policy: Whether there is filtering, interpolation, limiting, and collision protection when directly executing the generated action, there are no details in the text.
6.3 Technical differences with UVA/CoVAR
| method | core structure | main goal | Key trade-off |
|---|---|---|---|
| UVA | Shared video-action latent, decoupled video/action diffusion heads. | One model supports policy, video, forward/inverse dynamics. | The unification function is strong, but different tasks mask/objective may conflict. |
| CoVAR | Keep the pre-trained video DiT, parallel the Action DiT, and interact with Bridge Attention. | Jointly generate video-action, directly as policy or data source. | More protective of the video prior, but more complex parameter and synchronization communication. |
| VAG | Cosmos-Predict2 video branch + 1D U-Net action branch, synchronous flow matching. | Generate long horizon-aligned video-action pairs for data synthesis and replay. | The video guides the action, but the action is not yet back-constrained to the video. |
7. Critical discussion and group meeting questions
7.1 Strong points of the paper
- Problem location is good: Directly target the video-action in robot data synthesis to align this critical gap.
- Simple design: The video branch retains a strong foundation model, the action branch uses lightweight 1D U-Net, and the bridge uses non-learning 3D pooling.
- The experimental chain is complete: Not only video/action indicators, but also LIBERO replay, VLA pretraining, and real robot replay.
- Generate horizon length: 93 frames, about 10 seconds, is more attractive for training data synthesis than short horizon policies.
7.2 Points to be cautious about
- Action to video is a one-way coupling: The paper itself admits that the current video generation is not affected by the action branch and may waste control signals.
- The information bottleneck of adaptive 3D pooling is obvious: Averaging the entire video latent into global embedding may lose local contact, hand-eye spatial relationship and key moment information.
- The VLA boost experiment was smaller: 20 trials from 35% to 55% are valuable, but statistical robustness and task coverage still need to be expanded.
- No official code: It is currently difficult to reproduce key training configurations and real replay details.
- Real replay is not closed-loop control: The fact that actions can be replayed does not mean that the model has robust closed-loop policy capabilities.
7.3 Group meeting discussion question 1: Is 3D pooling an advantage or a bottleneck?
VAG's adaptive 3D pooling is very simple, so the training is stable and has few parameters. However, it compresses the latent spatiotemporal structure of the video into a global vector, which may lose the local contact information most needed for action generation. A follow-up can be discussed: whether using cross-attention, temporal pooling, object-centric tokens or contact-aware pooling instead of global average can improve fine-grained action alignment.
7.4 Group meeting discussion question 2: How can synthetic data prove that it really improves generalization?
The paper uses VAG-generated data to increase $\pi_{0.5}$ from 35% to 55%, which is a strong signal. But in order to prove "generalization" rather than "just enhance this set of scenarios", more systematic control is needed: the amount of synthetic data, the amount of real data, prompt diversity, generation failure sample filtering, OOD type splitting, and comparison with direct replication/perturbation of real trajectories.
7.5 Follow-up research directions
- Two-way coupling: Let the action branch also guide the video branch in the opposite direction, making the visual trajectory more constrained by the control signal.
- Stronger action branch: According to the author's suggestion, DiT is used to replace 1D U-Net to improve action sequence modeling capabilities.
- Local alignment Affiliations: Replace global average 3D pooling with attention or object/contact tokens.
- Data synthesis closed loop: Automatically filter synthetic samples with successful replay or high video-action consistency, and then train VLA.
- Large scale review: Validating synthetic data gains on more robots, more tasks, and more real-life OOD settings.