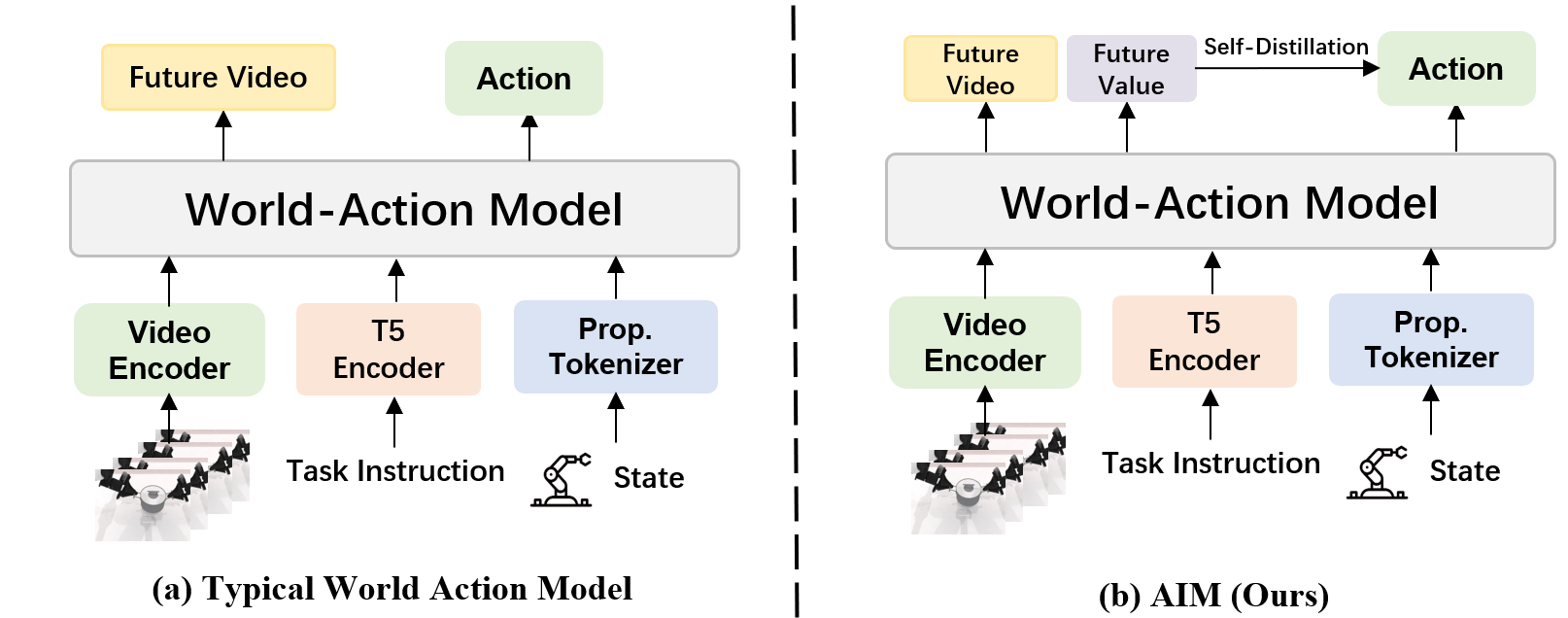
AIM: Intent-Aware Unified world action Modeling with Spatial Value Maps
1. Quick overview of the paper
| Reading positioning | content |
|---|---|
| What should the paper solve? | There are unified world action models that can predict future images, but action decoding still requires implicit recovery of contact positions and operation intentions from dense RGB latent, resulting in high robot domain adaptation costs. |
| The author's approach | Introducing action-based spatial value maps aligned to future frames as an explicit spatial interface between future visual prediction and action decoding. |
| most important results | On the 50 simulation tasks of RoboTwin 2.0, AIM reached Easy 94.0%, Hard 92.1%, and an average of 93.1%, which is higher than Stage1's 92.5% and external baselines. |
| Things to note when reading | The core is not to "add one more heatmap supervision", but to use intent-causal attention to force the action branch to read future information only through the value map. |
Difficulty rating: ★★★★☆. Need to understand video diffusion / flow matching, Transformer attention mask, VLA / world-action model, and PPO / GRPO type goals in RL post-training.
Keywords: Unified World Action Model; Spatial Value Map; Intent-Causal Attention; Mixture-of-Transformers; GRPO Post-Training; RoboTwin 2.0.
Core contribution list
- Intent-aware unified world action model: Adding a spatial value-map interface between future prediction and action decoding enables the model to explicitly represent task-related interaction structures.
- Spatially grounded control training framework: Put joint frame-value generation, intent-causal attention and self-distillation RL post-training into the same framework.
- 30K simulation trajectory data set: Construct data containing multi-view videos, action sequences, task identifiers, and step-by-step value-map annotations for training and evaluation.
- RoboTwin 2.0 performance: Achieving 94.0%/92.1% average SR on Easy/Hard settings, respectively, for 50 simulation tasks.
Appendix status No Appendix / Supplementary section was found in the source code; all contents of this report come from the text, charts and reference files.
2. Motivation
2.1 What problem should be solved?
The core issue that the paper focuses on is: how to reliably transform the visual dynamic priors learned by large-scale video generation models into continuous actions in contact-intensive robot operations. Video models are good at answering "what does the scene look like next", but robot control also needs to answer "where should the end effector touch and why this position is useful for the task." In tasks such as grabbing, placing, pressing, scanning, switching, etc., this kind of information is usually sparse contact area, while RGB future latent contains a lot of appearance details.
The authors point out that existing unified world-action models typically have the action head decode actions directly from a shared future visual representation. This forces the model to implicitly recover the manipulation intent from the dense visual representation; this inverse dynamics problem is more difficult for cluttered scenes or contact-sensitive tasks.
2.2 Limitations of existing methods
- Traditional VLA: Directly from observation + language to action, it can imitate the demonstration, but does not explicitly model how the action changes future observations.
- Two-stage WAM: The future state is predicted first and then handed over to the action model; there is a lack of controllable and explicit interactive interface between the future state and action decoding.
- Phase 1 WAM: Future state prediction and action prediction share the observation stream; the action head still needs to extract sparse action cues from the dense RGB future.
- Spatial grounding method: Existing work has proven that operable regions, voxel-aligned action spaces, etc. are useful for manipulation, but they are usually used as independent policy heads or perception modules, without being directly embedded in the generative world-action model.
2.3 The solution ideas of this article
The high-level insight of AIM is to let the model first compress future visual dynamics into "task-related spatial interaction areas", and then let the action head generate actions based on this spatial representation. In other words, future RGB is used to model how the world evolves, value map is used to express future interaction intentions, and action head only receives future information through value map.
3. Summary of related work
3.1 Related work of the thesis self-description
| Technical line | How to position the paper | The difference between AIM |
|---|---|---|
| Video generation for robot learning | Work such as DreamZero, VPP, and Video Generators use pretrained video generators as visual dynamic priors for robot learning. | AIM uses Wan2.2-TI2V-5B as the video backbone, but adds value-map prediction and action branches. |
| Unified world action model | LingBot-VA, GigaWorld-Policy, Fast-WAM, DreamZero, etc. put future observations and actions into a unified architecture. | AIM does not let actions directly depend on future RGB, but adds an explicit spatial intermediate interface. |
| Spatially grounded representations | Where2Act, PerAct, CLIPort, CALAMARI, etc. emphasize the role of interaction region / spatial grounding on manipulation. | AIM integrates spatial value prediction directly into the generative world-action model, rather than a separate perception or policy head. |
3.2 Direct comparison with previous works
| Dimensions | LingBot-VA | GigaWorld-Policy / Fast-WAM | AIM |
|---|---|---|---|
| Core idea | Learning video prediction and action generation in a shared latent space. | Emphasis on action-centered or efficient world-action modeling. | Jointly predict future RGB, future value map and future action. |
| key assumptions | Shared visual latent is sufficient to serve motion decoding. | world-action cotraining improves strategy. | Actions require explicit spatial intent representation and cannot rely solely on dense future RGB. |
| information flow | Actions can take information from the shared future representation. | Depending on the specific model design, there is usually no value-map gating. | Intent-causal attention prevents the action branch from looking directly at future RGB. |
| Experimental performance | RoboTwin has an average SR of 92.2%. | Fast-WAM 91.8%, Giga-World 86.0%. | RoboTwin has an average SR of 93.1%. |
4. Detailed explanation of method
4.1 Method overview
The input of AIM is the history window $\mathcal{H}_t=\{o_{t-k: t}, a_{t-k: t-1}\}$, where $o_t$ is the simultaneous multi-view observation and $a_t$ is the robot action. The model outputs future RGB frames $X^+$, future value maps $M^+$, and future actions $A^+$ for horizon-$h$.
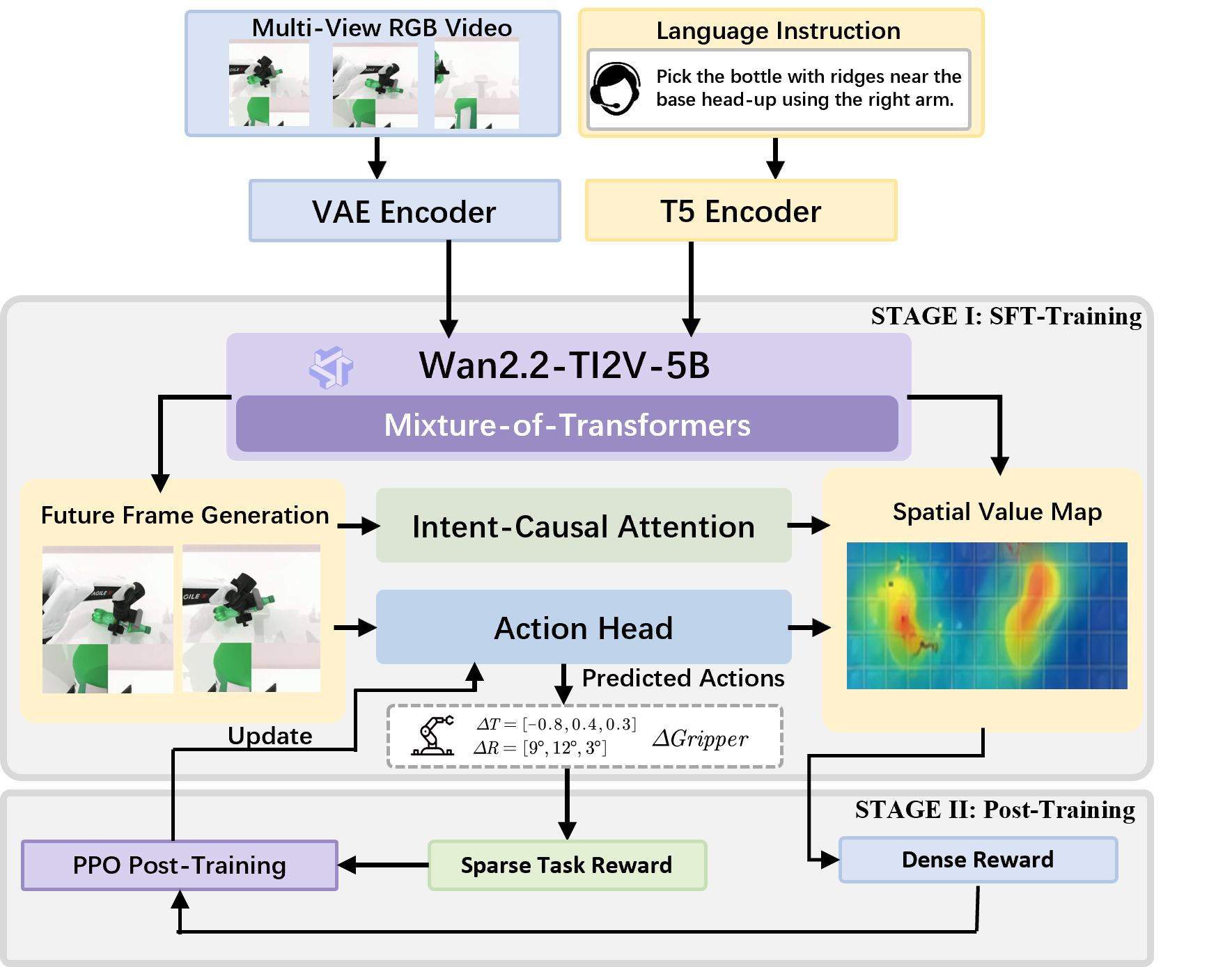
This decomposition is saying: first predict the future world and spatial intention, and then generate actions based on the spatial intention.
$$p(X^+, M^+, A^+ \mid \mathcal{H}_t)=p(X^+, M^+ \mid \mathcal{H}_t)\, p(A^+ \mid \mathcal{H}_t, M^+)$$| $X^+$ | A sequence of future RGB frames representing the future visual state imagined by the model. |
| $M^+$ | A value map spatially aligned with future frames, encoding task-relevant interaction regions. |
| $A^+$ | Future continuous robot action chunk. |
| $\mathcal{H}_t$ | The context consists of historical observations, historical actions and language instructions. |
4.2 Method evolution
4.3 Core design and mathematical derivation
4.3.1 Tokenization and prefix construction
The three inputs are packed RGB, packed ASVM and continuous action. The paper follows LingBot-VA's multi-view packing: the head camera is placed at the top, and the left and right wrist cameras are placed on both sides to form a T-pose canvas.
This formula feeds both the RGB image and the value map into the same Wan2.2 VAE, so that they are geometrically aligned in latent space.
$$z_t^o = E_{\mathrm{vae}}( ilde x_t), \qquad z_t^m = E_{\mathrm{vae}}( ilde m_t)$$| $ ilde x_t$ | RGB observation after three-view splicing. |
| $ ilde m_t$ | RGB ASVM with the same T-pose layout. |
| $z_t^o, z_t^m$ | VAE latent tokens; shared VAE avoids redoing the visual tokenizer. |
This formula turns actions and languages into tokens so that they can enter the Transformer framework.
$$z_t^a=E_a(a_t), \qquad z^\ell=E_{\mathrm{t5}}(c)$$Among them, $a_t\in\mathbb{R}^{d_a}$ is the continuous action vector of both arms, $E_a$ is a lightweight MLP, and $c$ is a language instruction. Language tokens are only injected into the video model through cross-attention and are not directly injected into the action branch.
This prefix defines the historical context that the model can see when rolling out.
$$\mathcal{H}^{\mathrm{tok}}_t=[z_{t-k: t}^o, \, z_{t-k: t-1}^a, \, z^\ell]$$It also contains recent observations, recent actions and task language, which are used to estimate robot status and predict future chunks.
4.3.2 Mixture-of-Transformers three-stream architecture
The model includes video generation model and action head. The video branch is initialized by Wan2.2 and is used for future RGB and value-map generation; the action head has the same depth but smaller hidden width and is used for action denoising.
When rollout begins, the three future token streams all start with noise and then gradually denoise.
$$\hat z_0^x, \hat z_0^m, \hat z_0^a\sim\mathcal{N}(0, I)$$The value stream also receives the learned value noise token $n^m$, and the actual input is $[\hat z_0^m, n^m]$. The RGB and value maps denoise along the same flow-matching trajectory, and the action token is denoised by the action head.
Each output is reduced to an interpretable object by the corresponding decoder.
$$\hat X^+=D_x(z^x), \qquad \hat M^+=D_m(z^m), \qquad \hat A^+=D_a(z^a)$$| $D_x$ | Future RGB decoder. |
| $D_m$ | value-map decoder. |
| $D_a$ | Continuous action decoder. |
The key to MoT is: attention shares interactions, FFN keeps branches private.
$$Q_s^\ell=h_s^\ell W_{Q, s}^\ell, \quad K_s^\ell=h_s^\ell W_{K, s}^\ell, \quad V_s^\ell=h_s^\ell W_{V, s}^\ell, \quad s\in\{x, m, a\}$$Each stream first uses its own projection to obtain Q/K/V, then casts it into the common attention dimension for masked shared self-attention, and finally casts it back to its respective hidden space and goes branch-specific feed-forward.
The training goals simultaneously constrain future vision, spatial intentions, and movements.
$$\mathcal{L}=\mathcal{L}_{\mathrm{rgb}}+\lambda_m\mathcal{L}_{\mathrm{map}}+\lambda_a\mathcal{L}_{\mathrm{act}}$$$\mathcal{L}_{\mathrm{rgb}}$ and $\mathcal{L}_{\mathrm{map}}$ supervise flow-matching velocity field; $\mathcal{L}_{\mathrm{act}}$ supervises inverse-dynamics action prediction.
4.3.3 Intent-Causal Self-Attention
This is a structural constraint of AIM: action tokens are not allowed to directly attend future RGB tokens, and future information can only be accessed through future value tokens.
Three visible token sets define what each channel can see in shared attention.
$$egin{aligned} \mathcal{V}_x&=[z_t^o, z_{t-k: t-1}^o, z_{t-k: t-1}^a, z^\ell, z^x], \ \mathcal{V}_m&=[z_t^o, z_{t-k: t-1}^o, z^x, z^m], \ \mathcal{V}_a&=[z_t^o, z_{t-k: t-1}^a, z^m, z^a]. \end{aligned}$$| $\mathcal{V}_x$ | Future video can see current observations, historical observations/actions, language and its own future video token. |
| $\mathcal{V}_m$ | The future value map looks at current/historical observations and future video, allowing the value map to be bound to the sampled future state. |
| $\mathcal{V}_a$ | Action can see current observations, historical actions, future value map and its own action token, but cannot see future RGB. |
Masked attention only takes K/V from the corresponding visible set.
$$ ilde h_s^\ell=\mathrm{Attn}(Q_s^\ell, K(\mathcal{V}_s), V(\mathcal{V}_s))$$Therefore, the task semantics first enter the video branch, the future state information is then imported into the value stream, and the action branch finally only receives future information through value representation.
4.3.4 Self-Distillation RL Post-Training
The supervised learning of Stage I allows the action head to imitate the actions of the data set; Stage II only updates the action head in a closed-loop environment, freezing the video generator and value-map head to avoid future frame / value-map prediction drift.
dense reward: Whether the reward action point falls in the high value area predicted by the model itself.
$$r_t=\lambda_d r_t^{\mathrm{dense}}+\lambda_s r_t^{\mathrm{sparse}}, \qquad r_t^{\mathrm{dense}}=M_t(\Pi(p_t))$$| $r_t^{\mathrm{sparse}}$ | Environment-level task success or completion signal. |
| $p_t$ | Predict action landing points or end effector targets. |
| $\Pi(\cdot)$ | The camera projection function projects the 3D object onto the image plane. |
| $M_t$ | Freeze the value map predicted by the value head. |
GRPO uses clipped ratio to limit the policy update range of the action head.
$$\mathcal{L}_{\mathrm{GRPO}}(\phi)=\mathbb{E}_t\left[\min\left( ho_t(\phi)\hat A_t, \mathrm{clip}( ho_t(\phi), 1-\epsilon, 1+\epsilon)\hat A_t ight) ight]$$ $$ ho_t(\phi)=rac{\pi_\phi(a_t\mid\mathcal{H}_t, m_{t+1: t+h})}{\pi_{\phi_{\mathrm{old}}}(a_t\mid\mathcal{H}_t, m_{t+1: t+h})}$$$\hat A_t$ is an advantage based on combined reward. The authors call it self-distillation because the frozen value head guides the action head online without the need for additional manual labeling.
4.4 Implementation Points (For reproducibility)
- Visual input: Three-view synthesis T-pose canvas remains compatible with the input interface of Wan2.2 video VAE.
- value-map input: Initialized to a pure black image, equivalent to null value prior; the task-related spatial structure is learned through denoising.
- Language injection: T5 language token only cross-attends to the video model; the language conditions of the action head must be passed indirectly through the world/value representation.
- attention mask: When implementing, it must be ensured that the action token is not visible to future RGB tokens, otherwise the intent-causal constraints of the paper will be violated.
- Reasoning efficiency: Autoregressive chunk-wise rollout supports KV cache and only recalculates attention for newly added real observations and prediction tokens.
- RL stability: Stage II freezes the video generation model and value-map head, and only updates the action head.
5. Experiment
5.1 Experimental setup
| Project | settings |
|---|---|
| Dataset | 30K RoboTwin 2.0 simulation trajectories; each contains synchronized multi-view video, action sequence, task ID, per-step value-map annotations. |
| Task | RoboTwin 2.0's 50 simulation manipulation tasks, including Easy and Hard settings. |
| Backbone | The video generation model is initialized from Wan2.2-TI2V-5B. |
| Baselines | $\pi_0$, $\pi_{0.5}$, X-VLA, Motus, Fast-WAM, Giga-World, LingBot-VA; also reports Stage1 as RL pre-supervised model. |
| indicator | Success Rate (SR), statistics based on task success rate. |
| RL post-training | The action head is initialized from the Stage1 checkpoint; the video generation model and value-map head are frozen. |
| Hardware/Hyperparameters | The text does not give the specific values of GPU, training duration, batch size, learning rate, $\lambda_m$, $\lambda_a$, $\lambda_d$, $\lambda_s$, and GRPO clipping $\epsilon$. |
| code repository | The arXiv page and source code do not provide an official GitHub/project URL. |
5.2 Value-map annotation process
| Task type | Mark source | Generation method | meaning |
|---|---|---|---|
| Pick | The contact surface point cloud when the gripper is in effective gripping contact with the target object. | Use the camera calibration matrix to project to the image plane, and then perform Gaussian smoothing; the kernel width is dynamically adjusted with the camera parameters and depth. | The grasp affordance region is the spatial region where the end effector successfully physically interacts with the target object. |
| Place | When the object reaches a stable placement state, the contact region between the grasped object and the target support surface. | Detect placement completion with a small center-of-mass velocity threshold, and then project the contact area to generate a heat map. | placement contact region, that is, the location that should contact the environment when the placement target is met. |
5.3 Main results
| Setting | $\pi_0$ | $\pi_{0.5}$ | X-VLA | Motus | Fast-WAM | Giga-World | LingBot-VA | Stage1 | AIM |
|---|---|---|---|---|---|---|---|---|---|
| Easy | 65.9% | 82.7% | 72.8% | 88.7% | 91.9% | 87.0% | 92.9% | 93.0% | 94.0% |
| Hard | 58.4% | 76.8% | 72.8% | 87.0% | 91.8% | 85.0% | 91.6% | 92.0% | 92.1% |
| Average | 62.2% | 79.8% | 72.8% | 87.8% | 91.8% | 86.0% | 92.2% | 92.5% | 93.1% |
Looking column by column, AIM is +5.3% / +5.0% higher than Motus on Easy / Hard respectively; +11.3% / +15.3% higher than $\pi_{0.5}$ respectively. Stage1 has reached 93.0% / 92.0%, and Stage II RL has further reached 94.0% / 92.1%, indicating that the main gains come from the spatial interface and supervised training, and RL post-training provides additional small improvements.
Expansion: per-task SR table for 50 tasks
| Task | $\pi_{0.5}$ Easy | $\pi_{0.5}$ Hard | X-VLA Easy | X-VLA Hard | Motus Easy | Motus Hard | Stage1 Easy | Stage1 Hard | AIM Easy | AIM Hard |
|---|---|---|---|---|---|---|---|---|---|---|
| Adjust Bottle | 100% | 99% | 100% | 99% | 89% | 93% | 98% | 99% | 100% | 100% |
| Beat Block Hammer | 96% | 93% | 92% | 88% | 95% | 88% | 98% | 100% | 100% | 100% |
| Blocks Ranking RGB | 92% | 85% | 83% | 83% | 99% | 97% | 91% | 77% | 92% | 77% |
| Blocks Ranking Size | 49% | 26% | 67% | 74% | 75% | 63% | 47% | 44% | 47% | 43% |
| Click Alarmclock | 98% | 89% | 99% | 99% | 100% | 100% | 98% | 99% | 100% | 100% |
| Click Bell | 99% | 66% | 100% | 100% | 100% | 100% | 98% | 99% | 100% | 100% |
| Dump Bin Bigbin | 92% | 97% | 79% | 77% | 95% | 91% | 98% | 100% | 100% | 100% |
| Grab Roller | 100% | 100% | 100% | 100% | 100% | 100% | 98% | 99% | 100% | 100% |
| Handover Block | 66% | 57% | 73% | 37% | 86% | 73% | 92% | 89% | 93% | 90% |
| Handover Mic | 98% | 97% | 0% | 0% | 78% | 63% | 82% | 82% | 83% | 81% |
| Hanging Mug | 18% | 17% | 23% | 27% | 38% | 38% | 43% | 43% | 43% | 42% |
| Lift Pot | 96% | 85% | 99% | 100% | 96% | 99% | 98% | 100% | 100% | 100% |
| Move Can Pot | 51% | 55% | 89% | 86% | 34% | 74% | 99% | 97% | 100% | 98% |
| Move Pillbottle Pad | 84% | 61% | 73% | 71% | 93% | 96% | 97% | 99% | 97% | 98% |
| Move Playingcard Away | 96% | 84% | 93% | 98% | 100% | 96% | 98% | 100% | 100% | 100% |
| Move Stapler Pad | 56% | 42% | 78% | 73% | 83% | 85% | 91% | 83% | 92% | 84% |
| Open Laptop | 90% | 96% | 93% | 100% | 95% | 91% | 98% | 100% | 100% | 100% |
| Open Microwave | 34% | 77% | 79% | 71% | 95% | 91% | 83% | 80% | 83% | 79% |
| Pick Diverse Bottles | 81% | 71% | 58% | 36% | 90% | 91% | 99% | 97% | 100% | 98% |
| Pick Dual Bottles | 93% | 63% | 47% | 36% | 96% | 90% | 92% | 90% | 93% | 91% |
| Place A2B Left | 87% | 82% | 48% | 49% | 82% | 79% | 93% | 91% | 94% | 92% |
| Place A2B Right | 87% | 84% | 36% | 36% | 90% | 87% | 89% | 89% | 90% | 88% |
| Place Bread Basket | 77% | 64% | 81% | 71% | 91% | 94% | 92% | 90% | 93% | 91% |
| Place Bread Skillet | 85% | 66% | 77% | 67% | 86% | 83% | 98% | 100% | 100% | 100% |
| Place Burger Fries | 94% | 87% | 94% | 94% | 98% | 98% | 98% | 100% | 100% | 100% |
| Place Can Basket | 62% | 62% | 49% | 52% | 81% | 76% | 78% | 77% | 78% | 76% |
| Place Cans Plasticbox | 94% | 84% | 97% | 98% | 98% | 94% | 98% | 100% | 100% | 100% |
| Place Container Plate | 99% | 95% | 97% | 95% | 98% | 99% | 100% | 96% | 100% | 97% |
| Place Dual Shoes | 75% | 75% | 79% | 88% | 93% | 87% | 100% | 99% | 100% | 98% |
| Place Empty Cup | 100% | 99% | 100% | 98% | 99% | 98% | 98% | 100% | 100% | 100% |
| Place Fan | 87% | 85% | 80% | 75% | 91% | 87% | 93% | 89% | 93% | 90% |
| Place Mouse Pad | 60% | 39% | 70% | 70% | 66% | 68% | 97% | 96% | 97% | 95% |
| Place Object Basket | 80% | 76% | 44% | 39% | 81% | 87% | 93% | 88% | 93% | 89% |
| Place Object Scale | 86% | 80% | 52% | 74% | 88% | 85% | 100% | 97% | 100% | 98% |
| Place Object Stand | 91% | 85% | 86% | 88% | 98% | 97% | 98% | 100% | 100% | 100% |
| Place Phone Stand | 81% | 81% | 88% | 87% | 87% | 86% | 82% | 81% | 82% | 80% |
| Place Shoe | 92% | 93% | 96% | 95% | 99% | 97% | 98% | 100% | 100% | 100% |
| Press Stapler | 87% | 83% | 92% | 98% | 93% | 98% | 96% | 95% | 96% | 94% |
| Put Bottles Dustbin | 84% | 79% | 74% | 77% | 81% | 79% | 80% | 75% | 80% | 74% |
| Put Object Cabinet | 80% | 79% | 46% | 48% | 88% | 71% | 81% | 75% | 81% | 74% |
| Rotate QRcode | 89% | 87% | 34% | 33% | 89% | 73% | 98% | 99% | 100% | 98% |
| Scan Object | 72% | 65% | 14% | 36% | 67% | 66% | 98% | 97% | 100% | 98% |
| Shake Bottle Horizontally | 99% | 99% | 100% | 100% | 100% | 98% | 98% | 100% | 100% | 100% |
| Shake Bottle | 99% | 97% | 99% | 100% | 100% | 97% | 98% | 100% | 100% | 100% |
| Stack Blocks Three | 91% | 76% | 6% | 10% | 91% | 95% | 100% | 99% | 100% | 98% |
| Stack Blocks Two | 97% | 100% | 92% | 87% | 100% | 98% | 98% | 100% | 100% | 100% |
| Stack Bowls Three | 77% | 71% | 76% | 86% | 79% | 87% | 100% | 99% | 100% | 98% |
| Stack Bowls Two | 95% | 96% | 96% | 93% | 98% | 98% | 100% | 97% | 100% | 98% |
| Stamp Seal | 79% | 55% | 76% | 82% | 93% | 92% | 100% | 100% | 100% | 100% |
| Turn Switch | 62% | 54% | 40% | 61% | 84% | 78% | 100% | 99% | 100% | 98% |
5.4 Ablation and supplementation results
The ablation explicitly reported in the paper is Stage1 vs AIM: Stage1 represents the supervised model before RL post-training, and AIM represents the model after adding self-distillation RL. The average SR ranges from 92.5% to 93.1%, Easy from 93.0% to 94.0%, and Hard from 92.0% to 92.1%. This shows that additional improvements after RL training exist, but the magnitude is smaller than the gap with external baselines.
The author pointed out that the tasks with more obvious gains are concentrated in contact-sensitive and stage-dependent manipulation: Place Mouse Pad reaches 97% / 95%, Scan Object reaches 100% / 98%, and Turn Switch reaches 100% / 98%. These tasks require accurate localization of task-relevant interaction areas.

7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Based on the paper's own description and experiments, the core value of AIM lies in splitting the implicit coupling between "future visual prediction" and "action decoding" into a checkable spatial interface: the future frame is responsible for scene evolution, the value map is responsible for the task-relevant interaction region, and the action head only reads future information through the value map. This structure allows model performance improvements to be aligned with value-map localization and projected action targets in visualization.
7.2 Why the results hold up
The evidence given in the paper is three-fold: first, AIM in the average SR table is higher than external baselines in the three summary dimensions of Easy/Hard/Average; second, the comparison from Stage1 to AIM isolates the contribution of RL post-training; third, the author's analysis and visual explanation of contact-sensitive tasks, future frames, value maps and projected actions are consistent in the operation stage, supporting the original explanation of "the benefits come from spatial bridges rather than shortcut correlations".
7.3 Analysis and explanation of the results given in the paper
- The authors explain that AIM has obvious benefits in contact-sensitive and stage-dependent tasks, because these tasks rely on accurate positioning of interaction areas.
- The authors point out that value maps concentrate on meaningful interaction regions rather than generic saliency, and projected action targets fall within high-value areas.
- The author attributes the high performance of Stage1 to joint frame-value generation and intent-causal attention, and RL post-training only brings further improvements.
7.4 Limitations of the author's statement
The main text and Conclusion do not list limitations separately, nor do they explicitly state failure cases. The coverage boundary of the paper can be objectively summarized from the experimental settings: the experiments were conducted in the RoboTwin 2.0 simulation environment, and the value-map annotation relied on simulation contact API, camera calibration, and physical state; the text did not report real robot experiments, cross-dataset generalization, training costs, hyperparameter sensitivity, or failed task analysis. The above are coverage boundaries based on the original experimental range, not additional performance judgments.
7.5 Applicable boundaries and discussion
- Applicable scenarios: Multiple perspectives, language conditions, contact-intensive manipulation, and settings for value-map supervision can be obtained or automatically generated.
- Key prerequisites: The value map must be spatially aligned with the future RGB; the intent-causal mask must block the action branch's direct access to the future RGB.
- Data premise: Training relies on 30K RoboTwin trajectories containing multi-view videos, actions, and per-step value-map annotations.
- Not covered: The source code does not provide an Appendix; it does not provide complete hyperparameters, hardware, training duration, code warehouse or real robot deployment details.
Acceptance record
- Chapter coverage: Abstract, Introduction, Related Work, Overview, Method, Dataset and Value-Map Annotation, Experiments, and Conclusion have all been mapped to report chapters.
- Chart overlay: The three separate PNG charts have been copied and embedded; the two results tables have been reconstructed as HTML tables, with the per-task table placed in a collapsed area.
- Appendix coverage: There is no Appendix in the source code; the report is clearly marked.
- Objectivity: The analysis and limitations are based on the original experiments, charts and conclusions, and no additional improvement suggestions are added.