1. 论文速览
DexWorldModel 提出 Causal Latent World Model (CLWM),目标是把 World-Action Model 真正部署到机器人执行中。它把未来状态生成从 pixel/VAE latent 改为 DINOv3 feature,使用 Dual-State TTT Memory 替代线性增长的 KV cache,并用 Speculative Asynchronous Inference (SAI) 把部分去噪计算藏到物理执行时间里。数据侧则提出 EmbodiChain,用持续生成的物理可信仿真轨迹替代有限静态数据集。
| 论文要解决什么 | 现有 WAM/VLA 在机器人部署中有三类瓶颈:未来图像重建浪费容量;自回归历史 KV cache 随时间 $\mathcal{O}(T)$ 增长;必须等待真实观测再推理,导致闭环控制延迟高。另一个系统瓶颈是机器人训练数据生产速度远慢于模型容量增长。 |
|---|---|
| 作者的方法抓手 | CLWM 用 DINOv3 latent 作为生成目标,MoT 共享视频/动作 transformer backbone;Dual-State TTT Memory 将历史压进可测试时更新的 MLP 权重;SAI 用预测未来语义做后台 pre-denoising;EmbodiChain 用 generative simulation、domain expansion 和 ODS 持续注入新轨迹。 |
| 最重要的结果 | RoboTwin 平均成功率 94.00%,高于 $\pi_{0.5}$ 76.76%、X-VLA 72.84%、Motus 87.02%、LingBot-VA 91.55%;真实双臂 zero-shot sim-to-real 四任务达到 95/90/80/65%,高于使用真实示教微调的 $\pi_0$ 与 GR00T N1.5;SAI 将阻塞延迟降低约 50%。 |
| 阅读时要注意的点 | 这篇不是单纯提出一个 policy,而是“模型表征 + 长程记忆 + 推理调度 + 数据生成基础设施”的组合系统。实验结论很强,但复现成本也极高:64 H100、20 天训练、EmbodiChain 数据引擎都不是轻量条件。 |
2. 动机与背景
论文从 VLA 的“反应式”限制讲起:常规 VLA 直接把视觉和语言映射到动作,缺乏显式 forward dynamics,因此容易把视觉相关性和真实物理因果混在一起。World Action Models 则先预测未来世界状态,再基于未来状态推断动作,让动作生成显式依赖物理想象。
作者认为现有 WAM 仍卡在三个工程瓶颈上。第一,pixel/VAE latent future prediction 会花大量容量重建光照、背景、纹理这些对控制无关的细节。第二,长时序自回归必须维护 KV cache,内存随时间线性增长。第三,真实机器人执行中“执行动作、等观测、再推理”的串行流程让控制频率被扩散/flow matching 采样拖慢。
3. 预备知识
3.1 VLA 与 WAM
VLA 把当前历史观测和语言映射到未来动作块:
$$a_{t:t+K-1}\sim \pi_\theta(\cdot\mid o_{\le t},l).$$
WAM 则拆成 forward visual dynamics 和 inverse/action dynamics 两步:
$$\hat{o}_{t+1}\sim p_\theta(\cdot\mid o_{\le t},a_{ $$a_t\sim g_\psi(\cdot\mid o_{\le t},a_{ 这个拆分让动作生成不再只是 reactive mapping,而是基于“如果世界下一步变成这样,我该做什么”的因果结构。 CFM 用 ODE flow 从噪声 $\epsilon$ 变换到目标 $x$: $$\frac{dx^{(s)}}{ds}=v_\phi(x^{(s)},s\mid c),\quad x^{(0)}=\epsilon\sim\mathcal{N}(0,I).$$ 若采用线性插值 $x^{(s)}=(1-s)\epsilon+s x$,目标速度为 $\dot{x}^{(s)}=x-\epsilon$,训练目标是: $$\mathcal{L}_{CFM}=\mathbb{E}_{s,\epsilon,x,c}\left[\|v_\phi(x^{(s)},s\mid c)-\dot{x}^{(s)}\|^2\right].$$3.2 Conditional Flow Matching
4. CLWM 方法详解
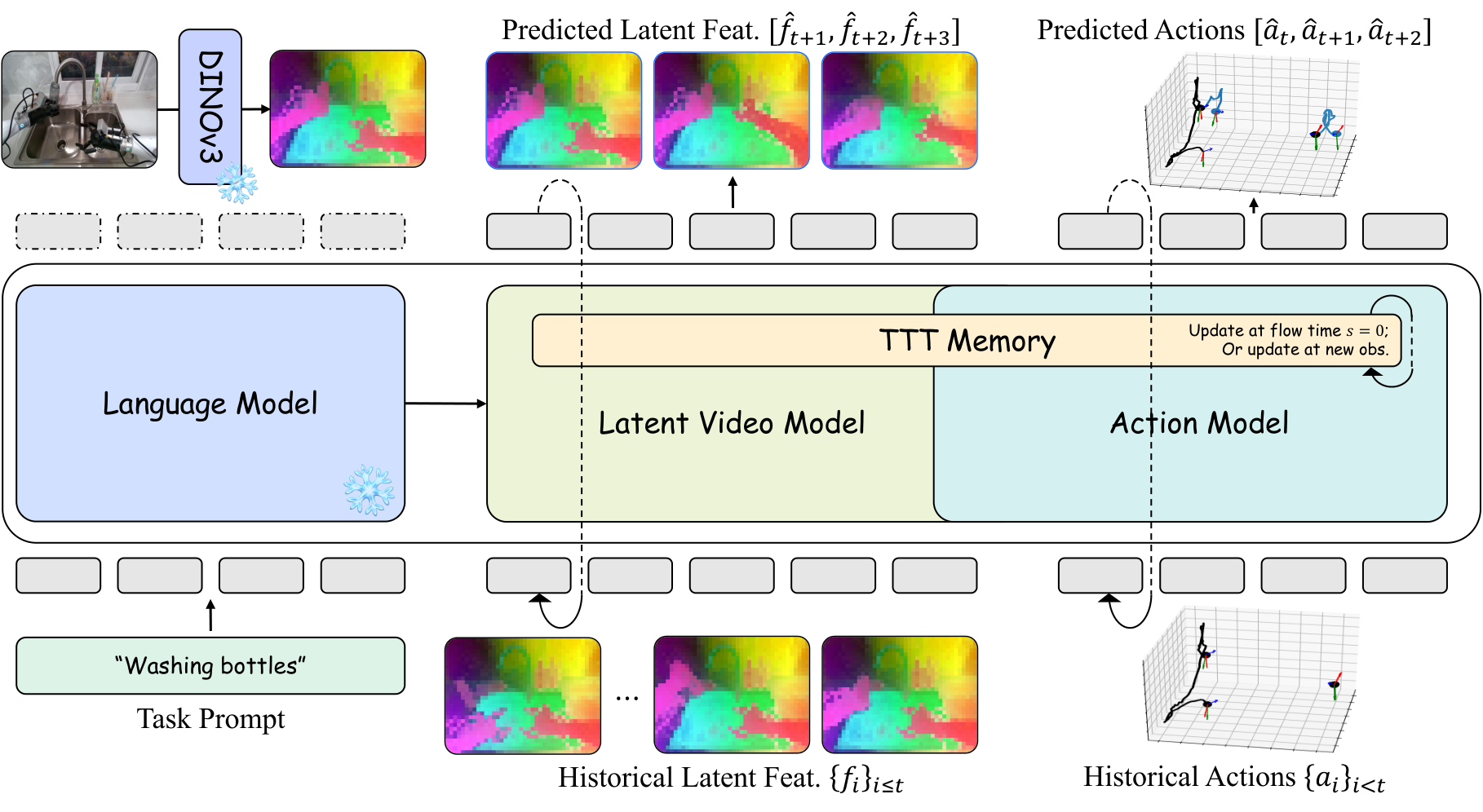
4.1 DINOv3 Latent 作为世界状态
CLWM 不生成 RGB,而是用 frozen DINOv3 base model 提取 latent feature map:
$$f_t=\Phi_{\mathrm{DINO}}(o_t)\in\mathbb{R}^{C\times H'\times W'},\quad H'=H/P,\ W'=W/P,\ P=16.$$
这和 LDA-1B 的思想相近:把未来预测目标放在结构化语义空间,减少背景和纹理重建压力,让模型容量服务于交互语义和物体状态转移。
4.2 Mixture of Transformers
CLWM 使用 MoT:latent video model 和 action model 共享核心 transformer blocks,初始化自 Wan2.2-5B;不同模态只在 flow timestep embedding 与 input/output projection 上独立:
$$\phi_{vid}=\phi_{vid}^{out}\circ\phi_{share}\circ\phi_{vid}^{in},\quad \phi_{act}=\phi_{act}^{out}\circ\phi_{share}\circ\phi_{act}^{in}.$$
共享 backbone 强制视觉 latent 和动作学习共用环境动力学,而 projection 层保留模态差异。
4.3 两阶段自回归生成
Stage 1: Latent Video Flow Matching. 给定历史 memory context $h_{\le t}$ 和语言 $l$,视频模型把噪声 $\epsilon_{vid}$ 去噪为未来 DINO feature $f_{t+1}$:
$$\mathcal{L}_{video}=\mathbb{E}\left[\left\|v_{\phi_{vid}}(f_{t+1}^{(s)},s\mid h_{\le t},l)-\dot{f}_{t+1}^{(s)}\right\|^2\right].$$
Stage 2: Action Flow Matching. action model 解码 action chunk $a_t=\{a_{t,1},...,a_{t,\tau}\}$,$\tau=16$,条件包括历史、语言和 Stage 1 预测的未来语义 $\hat f_{t+1}$。为了让 action model 能处理不完美历史,训练时以 $p=0.5$ 对历史 latent 注入噪声,$s_{aug}\in[0.5,1]$:
$$\tilde f_{\le t}=(1-s_{aug})\epsilon+s_{aug}f_{\le t}.$$
动作目标为:
$$\mathcal{L}_{action}=\mathbb{E}\left[\left\|v_{\phi_{act}}(a_t^{(s)},s\mid\tilde h_{\le t},l,\tilde f_{t+1})-\dot a_t^{(s)}\right\|^2\right].$$
4.4 Dual-State TTT Memory
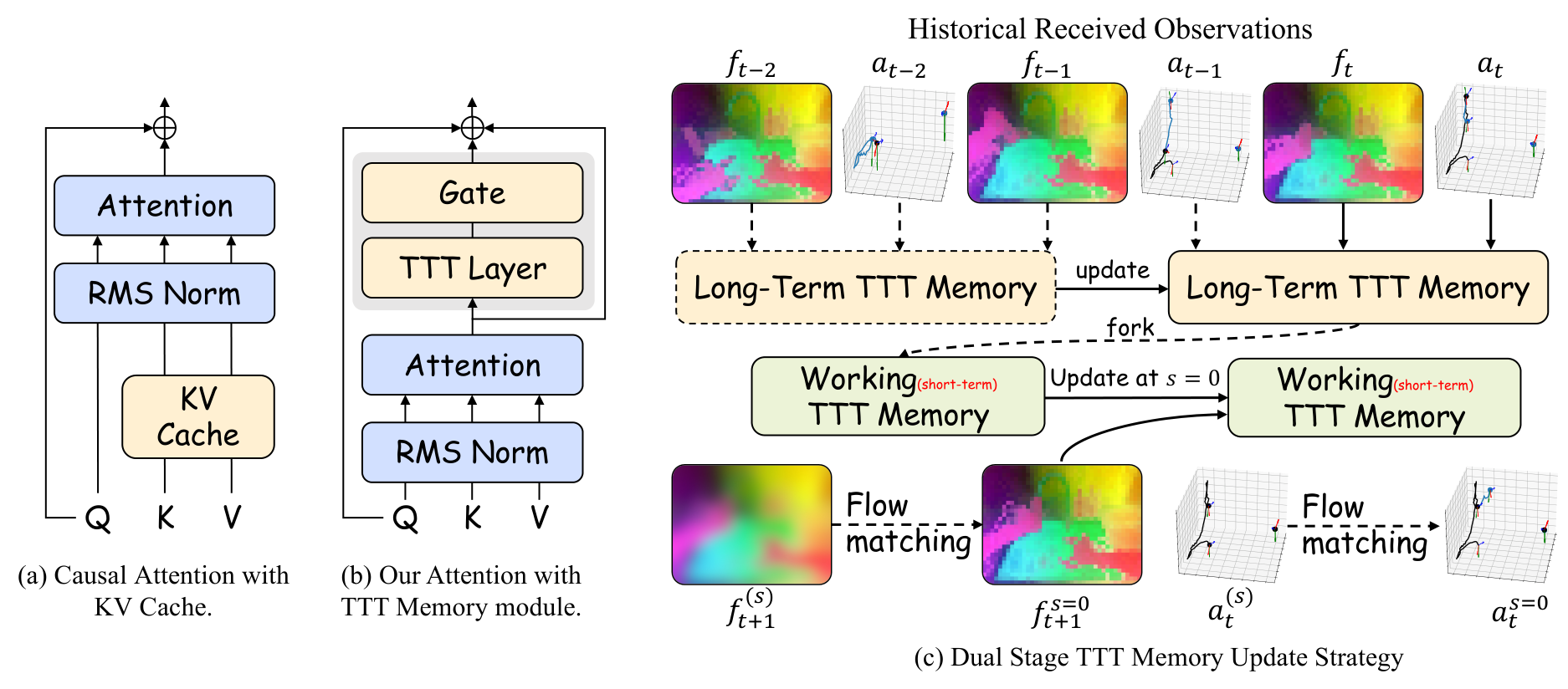
TTT layer 的自监督任务是用 $\theta_K z_t$ 重构 $\theta_V z_t$:
$$\ell_{self}(\mathcal{W};z_t)=\|f(\theta_K z_t;\mathcal{W})-\theta_V z_t\|^2.$$
输出通过 query projection 获取:
$$l_t=f_{TTT_{mlp}}(\theta_Q z_t;\mathcal{W}_t).$$
为稳定微调,TTT 输出用门控残差注入:
$$f_{TTT}(z_t;\mathcal{W}_t)=\tanh(\alpha)\otimes f_{TTT_{mlp}}(\theta_Q z_t;\mathcal{W}_t)+z_t,$$
其中 $\alpha$ 初始为 0.1。Long-Term TTT Memory 在真实观测和动作到来时更新:
$$\mathcal{W}_t^{long}=\mathcal{W}_{t-1}^{long}-\eta\nabla_\mathcal{W}\ell_{self}(\mathcal{W}_{t-1}^{long};h_t).$$
生成时 fork 出 Working Memory。Stage 1 ODE 期间工作记忆冻结;得到 $\hat f_{t+1}$ 后,在 $s=0$ 立刻更新 working memory,再供 Stage 2 action generation 使用。这样真实历史不会被预测状态污染,同时上下文长度不再带来 KV cache 线性增长。
4.5 Speculative Asynchronous Inference
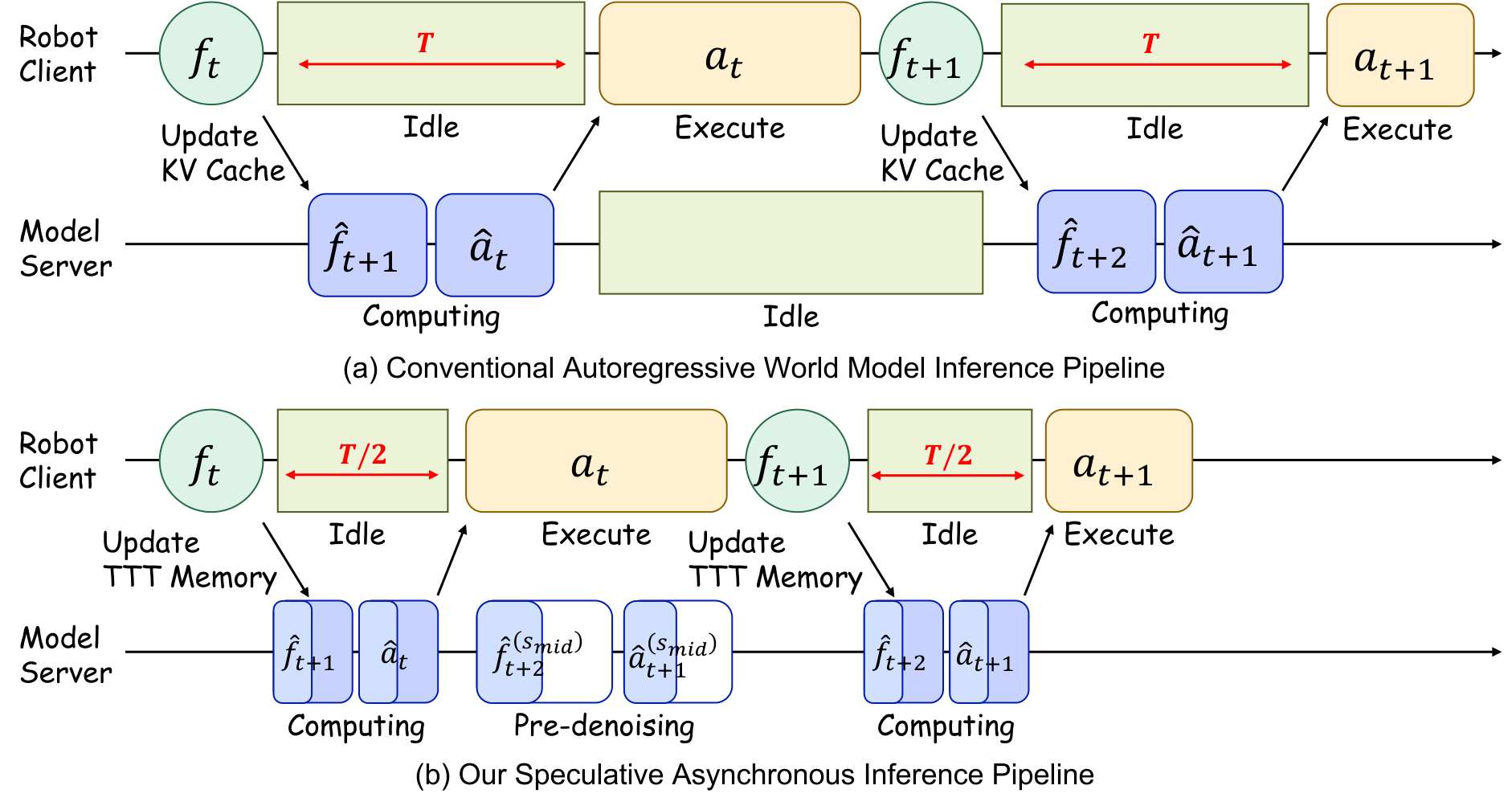
SAI 分两步。Phase 1 中,机器人执行当前 action chunk 时,模型用上一步预测的 $\hat f_t$ 作为 surrogate observation,把 ODE 从 $s=0$ 预积分到 $s_{mid}$。Phase 2 中,真实 $o_t$ 到达后提取 DINO feature $f_t$,更新 long-term memory,用真实上下文替换 speculative context,再从 $s_{mid}$ 积分到 $s=1$。由于 action model 训练时见过 noisy history,前半段 speculative denoising 不会轻易跑偏。
5. EmbodiChain
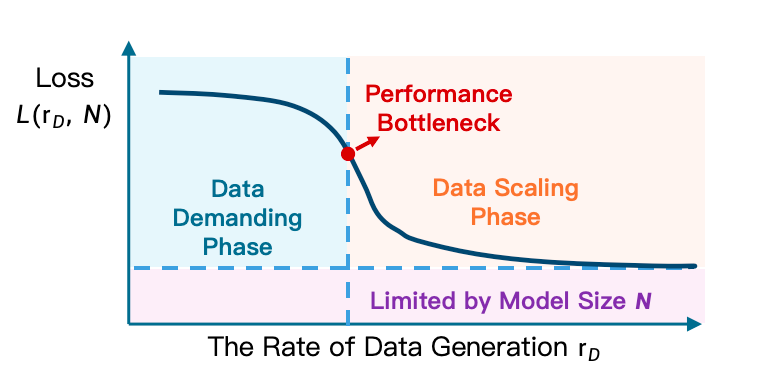
EmbodiChain 是论文的数据引擎。它的核心论点是 Efficiency Law:在 embodied learning 中,有效 scaling 主要取决于训练过程中“新鲜、多样、物理有效经验”的生成速率,而不是静态数据集大小。作者用 Experience Throughput $\mathcal{E}$ 描述每个训练迭代摄入的 unique state-action pairs;在固定 compute $C$ 和参数 $P$ 下,只有当 $\mathcal{E}$ 超过阈值 $\tau(C,P)$,智能才会有效增长。
5.1 Generative Simulation
- Asset generation and optimization: 用生成模型产生 3D meshes 后,优化几何、尺度、坐标系、质量分布、摩擦系数、碰撞属性、grasp pose 和 affordance,输出带物理/语义 metadata 的 USD 资产。
- Scene layout synthesis: 生成场景布局,并把任务相关前景对象放在机器人可达工作区内;背景资产通过梯度优化避免穿透,保证碰撞自由。

5.2 Domain Expansion
- Reachability-aware sampling: 在可达工作空间采样候选机器人状态,按末端接近方向、接触几何、交互结果等 task-centric features 最大化差异,避免轨迹同质化。
- Closed-loop error recovery: 当出现滑落、抓取错位、越界等失败时,replanning 生成纠正轨迹,并把 recovery sequences 重新标注后并入数据。
- Visual augmentation: 在线采样 lighting temperature、BRDF、sensor drift 等视觉因素,并用平滑随机过程保证时间一致性。
- Physics-grounded generation: 域扩展不做无约束随机化,而保持多体结构、质量、摩擦和关节参数物理一致。
5.3 Online Data Streaming
ODS 是 storage-less online pipeline:仿真和生成 worker 异步写入 CPU/GPU VRAM 的 lock-free circular buffer,learner worker 通过 zero-copy 消费 batch。数据可以被有限复用以摊销生成成本,但会严格控制 replay 次数,避免 buffer 变成静态数据集。
6. 实验复现要点
6.1 数据与训练
| 阶段 | 设置 |
|---|---|
| Pretraining Data | RoboMind, Agibot World Beta, InternData-A1 等开源机器人操作数据 |
| Video representation | DINOv3 base, patch size $P=16$ |
| Action representation | LingBot-VA 风格统一动作;双臂 $((7\mathrm{DoF\ EEF}+7\mathrm{joint}+1\mathrm{gripper})\times2)=30$ 维 |
| Post-training | 完全依赖 EmbodiChain 生成数据,不手工采集下游 real-world demos |
| Optimizer | AdamW, lr $1\times10^{-4}$, global batch 128, 约 20 epochs |
| Compute | 64 NVIDIA H100 GPUs, 连续训练约 20 天 |
| RoboTwin finetune | 25,000 synthetic trajectories, 40k iterations, lr $1\times10^{-5}$ |
6.2 RoboTwin 主结果
CLWM 在 RoboTwin 多个双臂任务上平均成功率 94.00%,高于 $\pi_{0.5}$ 76.76%、X-VLA 72.84%、Motus 87.02%、LingBot-VA 91.55%。优势明显的任务包括 Blocks Ranking Size 97% vs LingBot-VA 96%/Motus 63%,Handover Block 80% vs 78%/73%,Hanging Mug 40% vs 28%/38%,Place Mouse Pad 98% vs 96%/68%,Turn Switch 65% vs 44%/78%(这里 Motus 高于 CLWM)。
| Method | Average Success |
|---|---|
| $\pi_{0.5}$ | 76.76% |
| X-VLA | 72.84% |
| Motus | 87.02% |
| LingBot-VA | 91.55% |
| CLWM | 94.00% |
6.3 EmbodiChain 消融
| Configuration | ID Success | OOD Success |
|---|---|---|
| Spatial Randomization Only | 64% | 25% |
| + Visual Augmentation | 75% | 42% |
| + Physics-grounded Generation | 81% | 56% |
| + Reachability-aware Sampling | 95% | 82% |
| Training Configuration | Hanging Mug | Turn Switch | Stack Bowls |
|---|---|---|---|
| Static Baseline (1,500 demos) | 62% | 85% | 88% |
| ODS sample 213 | 60% | 84% | 85% |
| ODS sample 50 | 92% | 92% | 96% |
| ODS sample 10 | 96% | 98% | 98% |
这组实验支撑 Efficiency Law:当在线数据 replay bound 从 213 降到 50/10,单条轨迹复用减少,新鲜经验吞吐增加,成功率显著上升。
6.4 Zero-shot Sim-to-Real
真实平台是 Agilex CobotMagic bimanual platform。CLWM 和 Sim2Real-VLA 只用 EmbodiChain 仿真数据训练;$\pi_0$ 与 GR00T N1.5 使用每任务 50 条真实 expert demos 微调。
| Methods | Dual-Arm Water Pouring | Table Rearrangement | Items Hand-Over and Place | Pan Open and Place |
|---|---|---|---|---|
| $\pi_0$ | 25% | 20% | 20% | 5% |
| GR00T N1.5 | 35% | 20% | 15% | 5% |
| Sim2Real-VLA | 80% | 80% | 40% | 35% |
| CLWM | 95% | 90% | 80% | 65% |
7. 讨论与局限
7.1 这篇论文最有价值的地方
最有价值的是把世界模型部署瓶颈拆成了四层并同时处理:表征层用 DINOv3 latent 避免像素重建;记忆层用 TTT 替代 KV cache;推理层用 SAI 重叠计算和物理执行;数据层用 EmbodiChain 提供持续经验流。这个组合比单点模型改进更接近真实机器人系统需要。
第二个价值是明确提出 embodied scaling 的数据吞吐观点。很多机器人论文把“更多数据”理解成更大的静态数据集,而这篇论文强调新鲜、物理有效、失败可恢复的在线数据流。
7.2 结果为什么站得住
- 主任务覆盖面广:RoboTwin 列了近 50 个双臂/物体操作任务,平均成功率高于多条强基线。
- 消融和系统 claim 对应:domain expansion 每加一个模块,ID/OOD 都上升;ODS replay 次数越低,成功率越高,直接验证 Efficiency Law。
- 真实任务结论有冲击力:CLWM zero-shot sim-to-real 超过用真实示教微调的 $\pi_0$/GR00T N1.5,说明数据生成和 latent 表征确实缓解了虚实差距。
7.3 局限
复现门槛极高:64 H100 连续约 20 天,加上 EmbodiChain 数据基础设施,远超一般实验室资源。
架构贡献耦合较强:DINO latent、MoT、TTT、SAI、EmbodiChain 同时出现,虽然有数据侧消融,但模型侧单独 ablation 信息不足。
真实任务数量有限:四个双臂任务结果很强,但还不足以证明所有开放真实场景的泛化。
附录未实际输入:源码中 `sections/8_appendix.tex` 被注释掉,未提供更多模型侧超参、真实硬件细节或失败案例。
8. 组会追问
Q1: 为什么 DINOv3 latent 比 VAE/pixel 更适合 WAM?
DINOv3 latent 更偏对象语义和空间结构,弱化纹理、光照和背景。WAM 的目标是控制,不是视频画质;用 DINO latent 可以把生成容量集中在交互语义演化上。
Q2: TTT Memory 为什么能做到 O(1)?
它不保存不断增长的历史 token/KV cache,而是把历史通过 inner-loop gradient update 压进 TTT-MLP 的动态权重 $\mathcal{W}$。权重规模固定,所以空间复杂度不随时间增长。
Q3: 为什么要区分 Long-Term 和 Working Memory?
Long-Term 只吸收真实观测和已执行动作,保持物理历史锚点;Working 从 Long-Term fork 出来,可以吸收预测的 $\hat f_{t+1}$ 作为动作生成上下文,但不会污染真实历史。
Q4: SAI 会不会因为预测未来错了导致预去噪白做?
会有这个风险。作者用 history augmentation 训练 action model 处理 noisy/imperfect history,并在真实观测到达后用 Long-Term Memory 校准,只保留剩余细粒度去噪。SAI 的有效性依赖预测 latent 与真实 latent 不偏离太多。
Q5: EmbodiChain 的核心不是 domain randomization 吗?
不是简单随机化。它包含物理约束资产/场景生成、reachability-aware sampling、失败恢复轨迹回流、时间一致视觉增强和 ODS 流式训练。重点是“持续物理有效经验吞吐”,不是静态随机数据量。
9. 复现信息
9.1 资源链接
- arXiv: https://arxiv.org/abs/2604.16484
- DexForce PDF: https://dexforce.com/docs/DexWorldModel.pdf
- EmbodiChain project: https://dexforce.com/embodichain/index.html
- EmbodiChain GitHub: https://github.com/DexForce/EmbodiChain
9.2 训练速记
Visual target: DINOv3 base latent, patch size P=16
Backbone: Mixture of Transformers initialized from Wan2.2-5B
Action chunk: tau = 16
Action dim: dual-arm 30D = (7 EEF + 7 joints + 1 gripper) * 2
TTT Memory: TTT-MLP, 4x expansion, GELU, alpha init 0.1
History augmentation: p = 0.5, s_aug in [0.5, 1]
Pretraining: AdamW, lr 1e-4, global batch 128, about 20 epochs
Compute: 64 H100 GPUs, about 20 days
RoboTwin finetune: 25k synthetic trajectories, 40k iters, lr 1e-59.3 覆盖检查
本报告覆盖 Abstract、Introduction、Preliminaries、Causal Latent World Model、EmbodiChain、Experiments、Conclusion。源码中 `sections/8_appendix.tex` 被注释,未发现实际附录正文可整合;相关实现细节已从正文长节和表格中整合进方法、数据与实验章节。
生成日期:2026-05-09。源码、PDF 和解压目录保留未清理,便于后续核查。