Mask World Model: Predicting What Matters for Robust Robot Policy Learning
1. Quick overview of the paper
Difficulty rating: ★★★★☆. Requires familiarity with robot imitation learning, video diffusion/world model, diffusion policy, VAE latent and transformer token representation.
Keywords: Mask World ModelSemantic BottleneckVideo DiffusionDiffusion PolicyRobot Generalization
| Reading targeting item | content |
|---|---|
| What should the paper solve? | The RGB video world model spends capacity predicting nuisance variables such as texture, lighting, and background, resulting in appearance-driven drift and fragile generalization in closed-loop control. |
| The author's approach | During the training period, the semantic mask is used as the future prediction target to form a geometric information bottleneck; during the deployment period, no external segmenter is required, and only raw multi-view RGB is input. |
| most important results | MWM has an average success rate of 98.3% in LIBERO, 68.3% in RLBench, and 67.5% in the real Franka four tasks, and maintains higher robustness under visual perturbation and random token pruning. |
| Things to note when reading | The core is not to "use mask as an additional input", but to "let the world model learn to predict mask dynamics, and let the policy explicitly consume these predicted features." |
Core contribution list
- Proposed Mask World Model.It internally predicts future semantic masks, uses semantic supervision during training, and still only uses raw RGB during testing; this means that the deployment link does not rely on real-time segmentation models.
- Design mask-guided diffusion policy.Action generation is conditioned on mask-centric predictive features; this means that masks are not visual by-products but intermediate representations that go into control decisions.
- Compare various methods of extracting and using mask information.Experiments show that mask-centric designs consistently outperform future RGB prediction; this means that the gain mainly comes from the transfer of representation and target space, not just a specific architecture.
2. Motivation
2.1 What problem should be solved?
The paper focuses on the reliability of generalist robot manipulation policy under real visual changes. Existing video world models can provide long-term prediction and data efficiency, but if the goal is to predict future RGB, the model will simultaneously fit the contact geometry that is really needed for robot control, as well as texture, lighting, reflection, and dynamic background that are weakly related to action selection.
The specific failure chain given in the paper is: the RGB prediction target treats illumination/background change as equally important as contact-relevant motion; in closed-loop execution, small appearance errors will accumulate, causing predictive drift, making the strategy brittle under medium distribution shifts.
2.2 Limitations of existing methods
- RGB-centric world models: Optimizing photometric fidelity can easily entangle appearance and dynamics.
- VLA policies: Leveraging large-scale visual language representations, but still requiring more explicit object state and interaction geometry for precise spatial relationships and contact-sensitive control.
- Semantic helper methods: Often semantics are used as input cues for the current observation or rely on external grounding masks; this article emphasizes predictive semantic lookahead and maintains a pure-RGB interface during testing.
2.3 The solution ideas of this article
The core insight is: For control, the evolution of future object identity, spatial layout, and contact relationships is more critical than whether future pixels are realistic. Therefore, MWM transforms the world model prediction space from RGB to semantic masks, forming a geometric information bottleneck to filter redundant appearances while preserving object geometry and interaction structures.
3. Summary of related work
3.1 Related work of the thesis self-description
| Technical line | How to summarize a paper | The difference in this article |
|---|---|---|
| Video world models for robot policy learning | From latent dynamics / Dreamer-style agents to diffusion / transformer video generators, recently used in robotic prediction and physics simulation. | Most targets are still RGB reconstruction or related photometric latent; MWM predicts future semantic mask dynamics. |
| Vision-Language-Action models | VLA utilizes pre-trained visual language representations to map instructions and observations to actions. | MWM does not take semantics as the current input cue, but learns semantic lookahead and trains policy consumption prediction features. |
| Structured representations under masking | Object-centric representations, scene factorization, and masked modeling/token dropping all support the intuition that structured compact representations improve stability. | MWM embodies this idea into predictable mask dynamics in robot control, and verifies it with real robots and disturbances. |
3.2 Direct comparison with previous works
| Dimensions | RGB world model / VPP class methods | GE-ACT / VLA baseline | $\pi0$ baseline | MWM |
|---|---|---|---|---|
| Core idea | Predict future RGB or RGB latent and use its characteristics to guide policy. | Using a visual action conditioning strategy as a strong RGB-centric baseline. | General robot strategy baseline, compared in real robot experiments. | Predict future semantic masks and feed intermediate predictive tokens into the diffusion policy. |
| key assumptions | High-quality visual predictions can provide control information. | Current visual representations are sufficient to support controlled generalization. | Pre-trained generic policies can be adapted to the task. | Control requires geometry and contact evolution, and mask bottleneck can filter nuisance variables. |
| deployment input | Usually raw RGB. | raw RGB. | raw RGB. | raw multi-view RGB; no test period splitter required. |
| Experimental performance | RGB prediction variants are lower than MWM in LIBERO. | LIBERO average 96.5%; real task 23.8%; nPAUC 0.629. | Real task 38.8%; visual generalization OOD-SR 19.2%. | LIBERO 98.3%; real task 67.5%; nPAUC 0.648; visual generalization OOD-SR 42.1%. |
4. Detailed explanation of method
4.1 Method overview
The data flow of MWM can be split into two stages: the first stage starts from historical observations and language conditions, training the mask dynamics backbone to predict future semantic masks; the second stage freezes or reuses the intermediate features of the backbone, and trains the diffusion policy to generate future action sequences. The training period requires offline semantic mask supervision, and the testing period only provides raw RGB and language instructions.
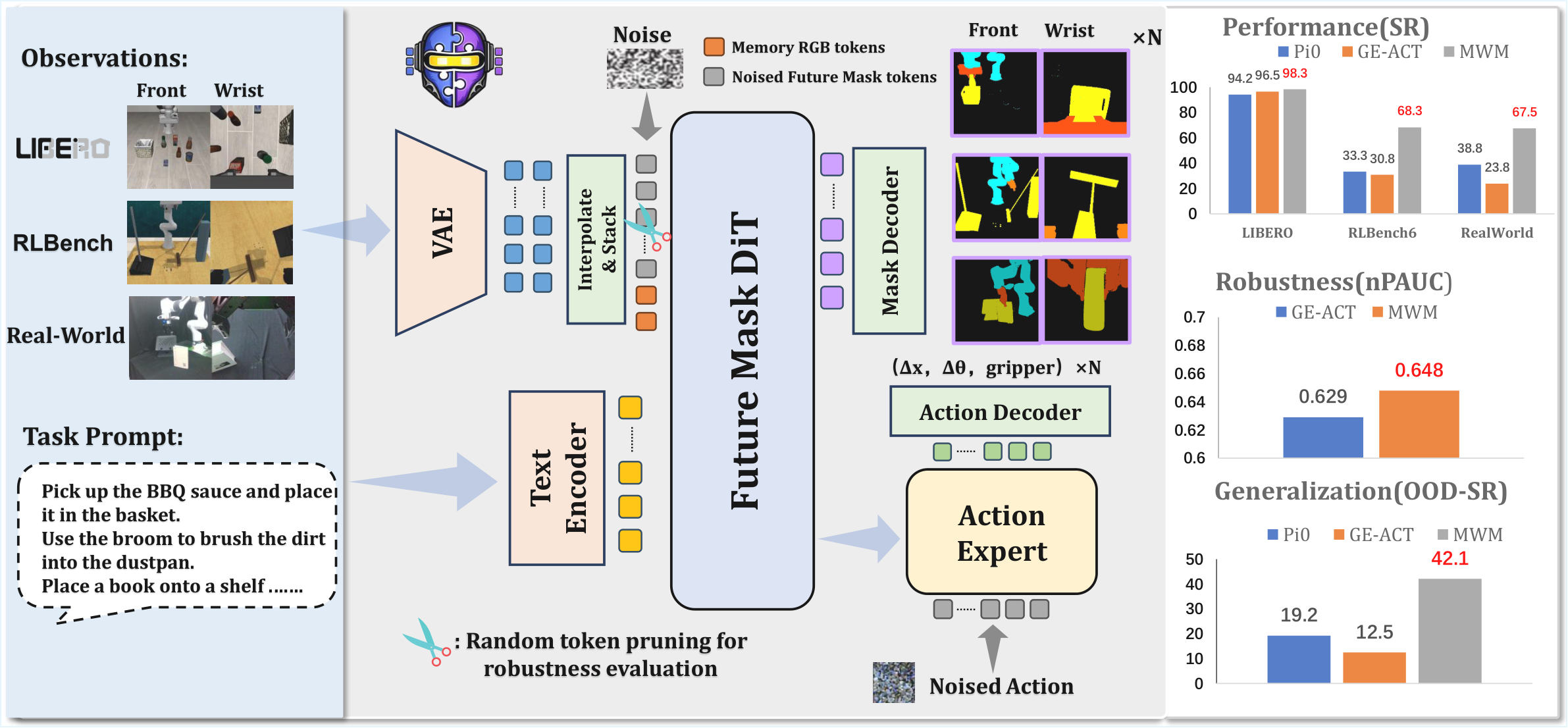
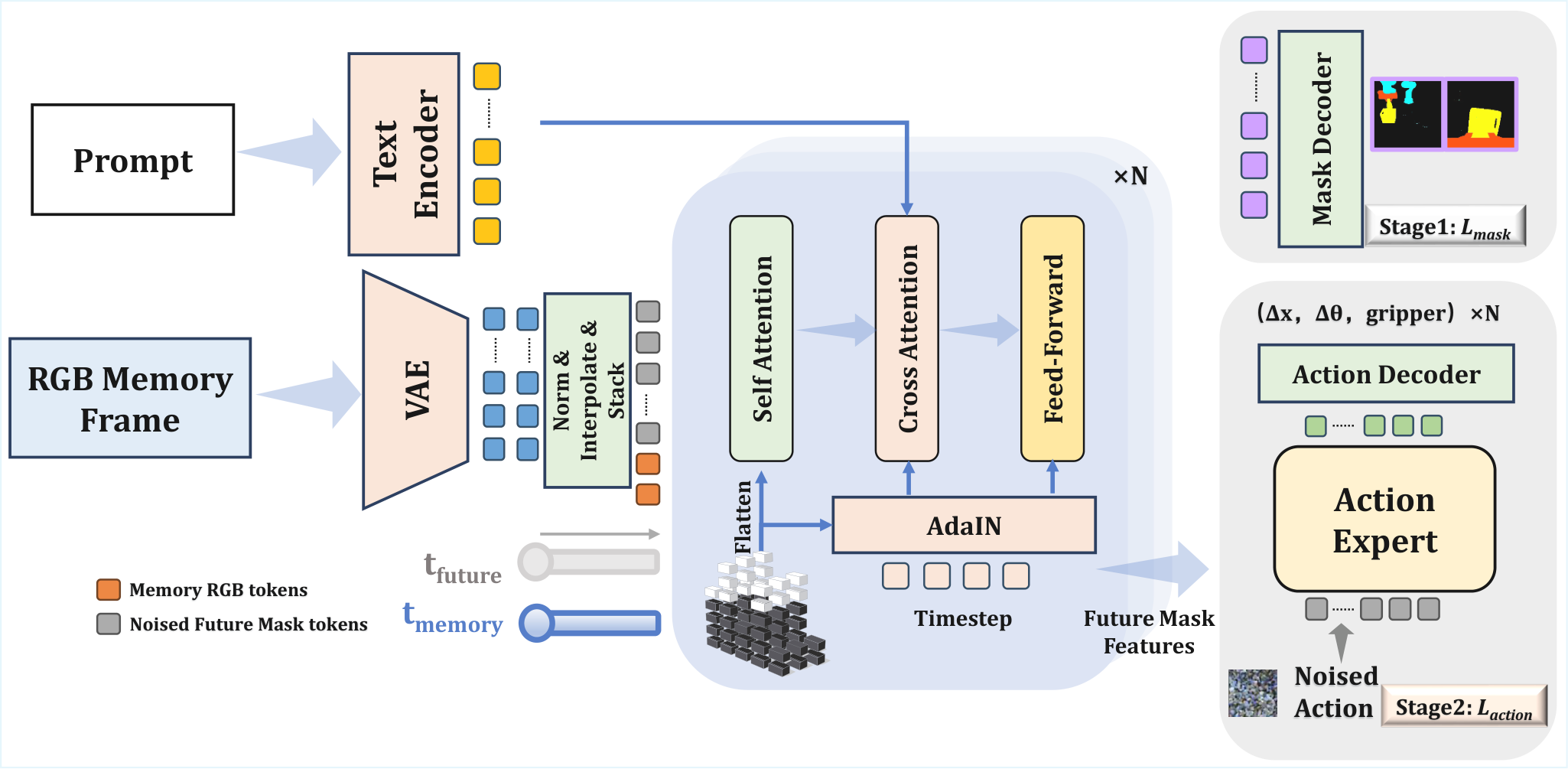
4.2 Method evolution
Video prediction policy → RGB-centric world model → Mask World Model. The first two use future visual prediction as a control auxiliary signal, but the prediction target still contains a lot of photometric nuisance. MWM changes the prediction goal: instead of letting the model "look predictive like a video", let the model predict the semantic layout of future objects/robots/task-relevant regions.
4.3 Core design and mathematical derivation
4.3.1 Geometric Information Bottleneck
The theoretical motivation of the paper is to use semantic masks as bottleneck: retain decision-relevant geometric variables and compress texture, lighting and background. The text does not give a complete information theory proof, but it implements the hypothesis into specific training goals and controlled experiments.
4.3.2 Mask latent encoding
| $\mathbf{o}_t$ | Multi-view RGB observation at time $t$. |
| $\tilde{\mathbf{m}}_t$ | The semantic mask generated offline can include categories such as robots, grippers, and task objects. |
| $\mathcal{E}$ | VAE encoder; the main text and appendix explain that VAE can be trained in Stage 1 and frozen in Stage 2. |
| $\mathbf{z}^{o}_t, \mathbf{z}^{m}_t$ | RGB latent and mask latent serve as the tokenized input of the video diffusion backbone. |
Here $\oslash$ represents element-wise division, and $\boldsymbol{\mu}_{\text{VAE}}$ and $\boldsymbol{\sigma}_{\text{VAE}}$ are VAE latent statistics. The implementation should be unified and normalized before being sent to transformer/diffusion, and the same convention should be maintained during decode or loss alignment.
4.3.3 Flow-matching style mask prediction
| $s\in[0, 1]$ | Diffusion/flow time. |
| $\mathbf{z}_0$ | Source distribution sample or noise side latent. |
| $\mathbf{z}_1$ | Target future mask latent. |
| $\mathbf{z}_s$ | Interpolation state, as velocity network input. |
$\mathbf{c}_t$ is a conditional context containing historical RGB observations, language instructions, and temporal/spatial position encoding. $w(s)$ is the time weight. This loss causes the dynamics backbone not to fit the future RGB texture, but to fit the geometric evolution of the future mask.
Supplementary derivation: why the target speed is $\mathbf{z}_1-\mathbf{z}_0$
4.3.4 Conditional noising for future masks
| $\mathbf{b}$ | A binary mask that distinguishes conditional frame positions from future positions that need to be predicted/denoised. |
| $n$ | The length of the historical observation window. |
| $\tau$ | future prediction horizon. |
| $\hat{\mathbf{z}}^o$ | Standardized observation latent. |
| $\hat{\mathbf{z}}^m$ | Standardized future mask latent. |
The key to the implementation of this design is the mask alignment of the batch dimension, time dimension and view/token dimension; if the $\mathbf{b}$ broadcasting is wrong, the historical conditions will also be noisy, destroying the condition prediction.
4.3.5 Spatio-temporal positional scaling and AdaLN/RMS modulation
During implementation, $\alpha(s)$ and $\beta(s)$ need to be broadcast to the token/channel dimension; $1+\alpha$ retains the identity path to facilitate initialization and stable training.
4.3.6 Action diffusion objective
| $\tilde{\mathbf{u}}$ | Noise action sequences. |
| $\sigma$ | noise scale. |
| $\mathbf{H}_t$ | Predictive features provided by mask dynamics backbone. |
| $\phi_\xi$ | diffusion policy/action head. |
| $\lambda(\sigma)$ | Loss weights for different noise scales. |
4.4 Implementation Points (For reproducibility)
MWM training sketch
Input: demonstrations D = {(RGB observations, language, actions)}, offline masks M
Stage 1:
encode historical RGB and future semantic masks into VAE latents
sample diffusion/flow time s and noise epsilon
train world model W_theta to predict future mask dynamics
Stage 2:
freeze or reuse W_theta as predictive feature extractor
condition action diffusion head phi_xi on W_theta features H_t
train phi_xi to denoise future action sequence
Inference:
input raw multi-view RGB + language only
run W_theta internally to produce mask-centric predictive features
sample action sequence with diffusion policy head
5. Experiment
5.1 Experimental setup
| Project | settings |
|---|---|
| Simulation benchmark | LIBERO (Spatial/Object/Goal/Libero-10, 500 episodes per suite); RLBench (6 tasks, 20 episodes each with randomized seeds). |
| real robot | 7-DoF Franka Emika Panda, two Intel RealSense D435i: fixed third-person + wrist-mounted eye-in-hand; RGB-D resize to $256\times256$; deployed at 10Hz.Appendix Real-World Experimental Setup |
| real tasks | Task1: Placing food items into a basket; Task2: Opening a drawer to insert a pen; Task3: Pouring water into a bowl; Task4: Shelving a book. 50 post-train demonstrations per method per task. |
| Baselines | LIBERO/RLBench includes RGB-centric world model / policy variants and GE-ACT; real experiments compare GE-ACT and $\pi0$. |
| indicator | Success Rate (SR); visual generalization report ID SR, BG/Light/Color shift SR, OOD-SR, Retain; RTP report normalized pruning AUC (nPAUC). |
| code | https: //github.com/LYFCLOUDFAN/mask-world-model |
Complete hyperparameter table
| Configuration | Stage 1 Dynamics | Stage 2 Policy | Source |
|---|---|---|---|
| Learning Rate | $3\times10^{-4}$ | $5\times10^{-5}$ | Appendix Implementation Details |
| Batch Size | 128 global | 128 global | Same as above |
| Weight Decay | $1\times10^{-5}$ | $1\times10^{-5}$ | Same as above |
| Warmup Steps | 1000 | 1000 | Same as above |
| Gradient Clip | 1.0 | 1.0 | Same as above |
| Precision | bfloat16 | bfloat16 | Same as above |
| Layers | 28 | 28 | Same as above |
| Hidden Dimension | 2048 | 512 | Same as above |
| Attention Heads | 32 | 16 | Same as above |
| Cross-Attn Dim | 2048 | 2048 | Same as above |
| VAE | Trainable | Frozen | Same as above |
| Backbone / Policy | Trainable | Trainable | Same as above |
| Observation / action horizon | 4 frames | 36 actions | Same as above |
| Spatial / temporal compression | $f_s=32$, $f_t=8$ | - | Same as above |
| Resolution | $256\times256$ | - | Same as above |
5.2 Main results
LIBERO
| Method | Spatial | Object | Goal | Libero-10 | Avg. |
|---|---|---|---|---|---|
| Best non-MWM row reported in table | 0.982 | 0.976 | 0.958 | 0.944 | 0.965 |
| MWM variant before final | 0.948 | 0.988 | 0.922 | 0.812 | 0.918 |
| MWM (ours) | 0.988 | 1.000 | 0.982 | 0.960 | 0.983 |
The main table shows that MWM is the highest or tied for the highest on all four LIBERO suites, with an average SR of 98.3%. Libero-10 is the long task combination setting, and the MWM improves from 0.944 for the best non-MWM row to 0.960.
RLBench
| Method group | Avg. SR |
|---|---|
| 3rd-view RGB baseline group | 42.5% / 50.0% |
| 3rd+wrist RGB baseline group | 23.3% / 33.3% / 30.8% |
| MWM (ours) | 68.3% |
The RLBench table is evaluated on 20 episodes of randomized seeds, and the average MWM success rate is 68.3%, which is higher than each RGB-centric baseline row in the table.
real robot

| Method | Task1 | Task2 | Task3 | Task4 | Avg. |
|---|---|---|---|---|---|
| GE-ACT | 35% | 20% | 10% | 30% | 23.8% |
| $\pi0$ | 50% | 30% | 5% | 70% | 38.8% |
| MWM (ours) | 75% | 55% | 60% | 80% | 67.5% |
The authors point out that the greatest improvement occurs in tasks such as drawer manipulation and pouring where goal constraints are tighter and are more sensitive to compounding errors. This explanation comes from the main text Results and analysis.
5.3 Ablation experiment
The main text focuses on "whether mask-centric representation/objective is better than future RGB prediction" and "whether different mask information extraction and use methods are stable." The MWM variants in the LIBERO table show that the final MWM averages 0.983, which is higher than other mask/RGB variants; the paper shows that the performance improvement mainly comes from representation and target space transfer, rather than single architectural details.
5.4 Supplementary experiments (from appendix)
Random token pruning detailed list
| Pruning r | MWM Spatial | MWM Object | MWM Goal | MWM L10 | GE-ACT Spatial | GE-ACT Object | GE-ACT Goal | GE-ACT L10 |
|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.98 | 1.00 | 0.98 | 0.96 | 0.96 | 0.99 | 0.95 | 0.94 |
| 0.4 | 0.95 | 0.97 | 0.89 | 0.79 | 0.96 | 0.96 | 0.89 | 0.77 |
| 0.6 | 0.85 | 0.80 | 0.65 | 0.37 | 0.83 | 0.47 | 0.67 | 0.39 |
| 0.8 | 0.05 | 0.10 | 0.07 | 0.00 | 0.11 | 0.00 | 0.21 | 0.00 |
| 0.9 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
Text summary nPAUC: MWM 0.648, GE-ACT 0.629. The detailed table in the appendix shows that the retention rate of MWM in the Object suite is significantly high under medium pruning. For example, the MWM Object is 0.80 for $r=0.6$, while the GE-ACT Object is 0.47.Appendix Detailed Random Token Pruning Results
Visual generalization detailed list

| Shift | GE-ACT Avg. | $\pi0$ Avg. | MWM Avg. |
|---|---|---|---|
| Background | 3.8% | 13.8% | 27.5% |
| Lighting | 18.8% | 17.5% | 56.3% |
| Object Color | 15.0% | 26.3% | 42.5% |
| OOD-SR summary | 12.5% | 19.2% | 42.1% |
| Retain | 0.53 | 0.49 | 0.62 |
The appendix expands each type of shift into four tasks; MWM has the highest average success rate under all three shifts. The authors explicitly refer to these shifts as nuisance variables for overfitting stress tests.Appendix Detailed Visual Generalization Results
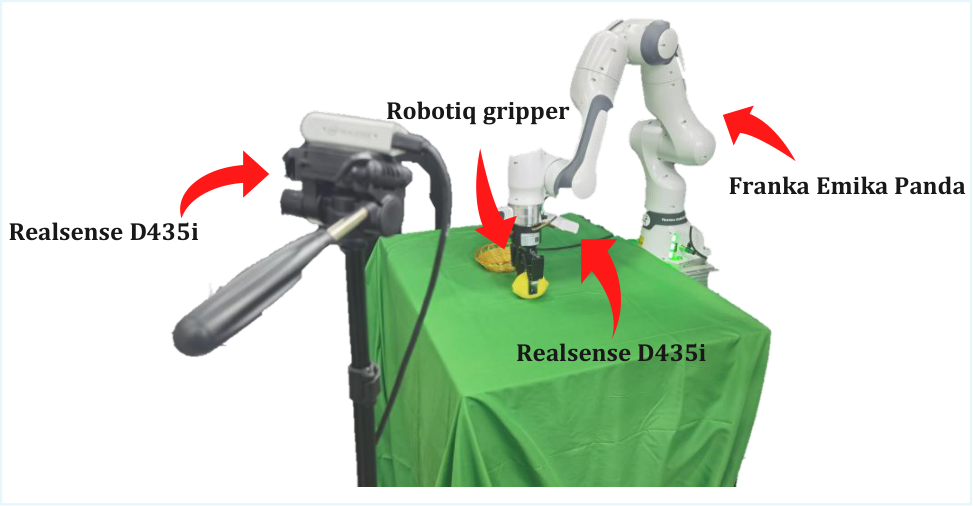
6. Summary of recurrence information
| Recurring items | Information given in the paper | Notch/Note |
|---|---|---|
| Source code | Provide a link to the GitHub repository. | You need to refer to the warehouse README to confirm the released checkpoints and data download method. |
| data | LIBERO, RLBench, real Franka four tasks; real 50 demonstrations per task. | Whether the real data is public requires checking the code repository. |
| semantic mask | Real robots use RoboEngine to generate semantic annotations offline. | Reproducing Stage 1 must have an equivalent mask annotation pipeline. |
| Hardware | Franka Panda + Dual RealSense D435i, $256\times256$, 10Hz. | Training GPU model/number is not explicitly listed in the source snippet. |
| hyperparameters | The appendix gives learning rate, batch, model width/depth, precision, gradient clip, etc. | If the details of optimizer betas and scheduler are not added in the code, they need to be confirmed from the warehouse. |
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Based on the paper's own claims and experiments, the core value is that it changes the goal of the robot world model from photometric prediction to decision-relevant semantic dynamics prediction, and through the design of semantic supervision during the training period and pure RGB during the test period, it avoids dependence on external segmenters during deployment. This value is supported by LIBERO/RLBench main results, real robot results, visual perturbation and token pruning stress tests.
7.2 Why the results hold up
- Cross-domain verification: Results cover LIBERO, RLBench and the real Franka robot, rather than being reported only in a single simulation environment.
- Disturbance verification: The paper performs real robot stress tests on background, lighting, and object color shift, and provides OOD-SR and Retain.
- Robustness probe: Random token pruning tests observability/compute stress at the transformer token level; MWM nPAUC is higher than GE-ACT.
- Appendix detailed table: The appendix gives item-by-item results for pruning ratio and task-level results for each type of visual generalization shift, supporting trends in the main text.
7.3 Analysis and explanation of the results given in the paper
The author explains that real robot improvements come from semantic bottlenecks and multi-view observations that provide more decision-relevant representations, especially on tasks with tighter goal constraints and more sensitive compounding errors. RGB-based policies are more prone to appearance-driven drift. For visual generalization, the author regards BG/Light/Color shift as stress tests to detect whether the model is overfitting nuisance variables such as table texture, illumination or object color.
7.4 Limitations of the author's statement
The Conclusion of the paper does not include a dedicated limitations section. The boundaries that can be clearly read in the main text and appendices are: Stage 1 training requires offline semantic masks; real robot experiments are limited to four tabletop manipulation tasks; RLBench evaluates 20 episodes per task; real robots have 50 demonstrations post-training per task. The above are all boundaries set by the paper's experiments, rather than additional inferences by the report author.
7.5 Applicable boundaries and discussion
- Prerequisite: Task geometry, object identity, spatial relationships, and contact evolution are more critical than appearance texture.
- Deployment conditions: Inference only requires raw RGB and language, but semantic mask supervision must be available during training.
- Experimental Boundaries: The paper presents real-world results based on Franka Panda, dual RealSense, four tasks, and a 10Hz control setting.
- Future work: The original article Conclusion mainly summarizes that MWM provides a mask-centric predictive framework for robust robot policy learning, and does not expand on the specific future work list.