MotuBrain: An Advanced World Action Model for Robot Control
1. Reading orientation and group meeting guide
| Introductory items | What does this paper answer? | Where do you focus on when reading? |
|---|---|---|
| Research object | A unified model simultaneously performs policy, world modeling, video generation, inverse dynamics, and joint video-action prediction. | It is not a single policy head, but a multimodal generative model that can switch distributions conditionally. |
| core motivation | VLA has strong semantic generalization, but lacks fine-grained world dynamics; WAM learns future visual prediction and action generation together. | See how action learning can move from isolation imitation to joint training with predictive world modeling. |
| Main contributions | Three-stream MoT, H-bridge attention, multi-view 3D RoPE, unified relative EEF actions, post-training and real-time deployment acceleration stack. | The most worthy of careful reading are Method's inference optimization and real-time chunk fusion. |
| Experiment positioning | RoboTwin 2.0 to 95.8/96.1; WorldArena EWMScore 63.77; few-sample adaptation for real long-distance housework tasks. | Pay attention to distinguishing between public benchmarks, official page lists, and self-set real robot scores for papers. |
2. Background: Why VLA is not enough and why WAM makes sense
2.1 Shortcomings of VLA
The VLA model maps visual observations and language instructions to robot actions and inherits the semantic priors of VLM, so it is strong in object and instruction generalization. However, the author believes that the pre-training of VLA mainly comes from static image-text data and lacks prediction of fine-grained world dynamics: contact, inertia, timing changes, status updates after failure, etc. are not directly covered by static semantics.
2.2 From video generation to world model
Video generation models learn spatiotemporal priors on large-scale web videos, which are naturally suitable for predicting future visual states. The intuition for using it for robotic world modeling is strong: if the model can predict future scenes based on current observations and actions, it is possible to learn object persistence, hand-object interaction, and physical transfer.
2.3 VGM + IDM and WAM
The early route was to first use the video generation model to predict future vision, and then use the inverse dynamics model to promote action. This two-stage method can exploit video priors, but will accumulate errors. WAM puts visual dynamics and action prediction under the same generation goal, allowing future visual state and action to be aligned during training.
2.4 Upgrade of MotuBrain relative to Motus
Motus has proposed a unified world-action formulation that allows the same model to support five reasoning modes. MotuBrain continues to use UniDiffuser and Mixture-of-Transformers, but adds a more deployment-oriented design: multi-view input, independent text stream, cross-embodiment action representation, AR/Non-AR post-training, V2A-style action-only inference and real-time chunked closed-loop execution.
3. Detailed explanation of methods: UniDiffuser, third-rate MoT, pre-training and deployment stack
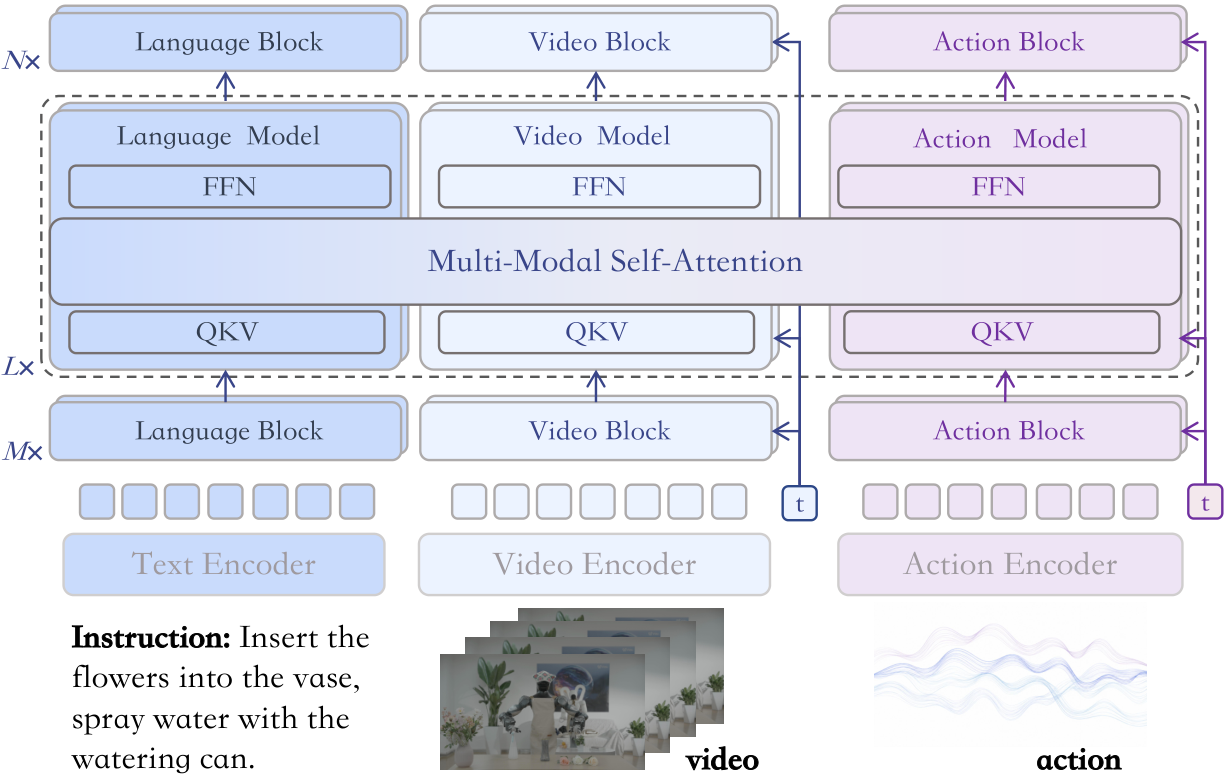
3.1 Five prediction distributions
MotuBrain uses UniDiffuser to simultaneously schedule two continuous modes, video and action, so that the same model supports multiple conditional distributions. Five goals in the non-autoregressive mode are given in Table 1 of the paper:
| mode | predicted target | Intuition |
|---|---|---|
| VLA | $p(\bm{a}_{t+1: t+k}\mid \bm{o}_t, \ell)$ | Given current observations and language, predict future actions. |
| WM | $p(\bm{o}_{t+1: t+k}\mid \bm{o}_t, \bm{a}_{t+1: t+k})$ | Given current observations and actions, predict future vision. |
| IDM | $p(\bm{a}_{t+1: t+k}\mid \bm{o}_{t: t+k})$ | Give visual trajectory and reverse the action. |
| VGM | $p(\bm{o}_{t+1: t+k}\mid \bm{o}_t, \ell)$ | Given current observations and language, future videos are generated. |
| Joint | $p(\bm{o}_{t+1: t+k}, \bm{a}_{t+1: t+k}\mid \bm{o}_t, \ell)$ | Simultaneously generate future videos and actions. |
3.2 Third-rate Mixture-of-Transformers
The model includes text stream, video stream, and action stream. Text stream is a conditional branch, and its hidden states participate in attention, but there is no text output head; video/action streams are trained with flow matching to predict the velocity fields of video latents and action tokens respectively.
Inputs include text tokens, condition-image latents encoded by Vidu VAE, noisy future video latents, and noisy action tokens. The condition image is represented as the first video latent frame and is teacher-forced in the video stream; remaining future video latents and action tokens are denoised by their respective streams.
3.3 H-bridge attention
Full-layer full video-action joint attention is costly and may also inject too much irrelevant modal information in shallow/deep layers. Therefore, MotuBrain uses H-bridge: the middle 50% Transformer layers use full V-A joint attention, and the bottom 25% and top 25% use decoupled attention, allowing video tokens and action tokens to be processed independently. Intuitively, the shallow layer retains modal features, the middle layer does semantic/action alignment, and the deep layer returns to modality-specific output.
3.4 Multi-view 3D RoPE
For multiview inputs, each camera view is independently encoded by Vidu VAE and then spliced at the token level. Since the video model uses 3D RoPE, the paper only adds view-dependent offsets in the spatial dimension, and the time dimension remains unchanged. This is equivalent to mapping different perspectives to different areas in a shared spatial position encoding, so that any number of camera views can share the same backbone.
3.5 Pre-training data pyramid
MotuBrain's data organization follows Motus' four-layer pyramid, gradually narrowing from broad vision to target embodiment control:
- Internet videos: Train the Vidu video generation base model.
- Egocentric videos: Provides first perspective on hand-object interaction dynamics.
- Heterogeneous-embodiment data: Different robot platforms, tasks and scenarios; only dual-arm robot data is used in the settings of this article.
- Specific-embodiment data: Target robot action space, camera configuration and deployment distribution.
3.6 Two-stage pre-training
Starting from Vidu pre-training weights, stage 1 only trains the video branch, and the action branch is randomly initialized but not updated. The goal is to adapt Internet video prior to embodied manipulation. In order to enhance the robustness to imperfect conditioning, the paper uses the noisy-conditioning strategy: perturbing the condition-frame latent with probability 0.5:
Meaning:
The condition frame is not always clean input, and the model is forced to learn to recover future dynamics from imperfect visual conditions.
Stage 2 is initialized from the stage 1 checkpoint, only trains the action branch, freezes the video branch, and learns a unified action representation on heterogeneous-embodiment data. Although only the action branch is updated, the target still contains two items: video/action:
3.7 Relative EEF actions across embodiments
Let the absolute end-effector chunk be $E^{abs}=\{e^{abs}_1, \ldots, e^{abs}_n\}$, and the end-effector state of the conditioned frame be $s$. Relative action is defined as:
If $e=(p, R, g)$, where $p$ is the position, $R$ is the rotation, and $g$ is the gripper state, then:
$$e_i^{rel}=(p_i-p_s, \; R_s^{-1}R_i, \; g_i).$$The original pose is input as quaternion, and the training target uses 6D rotation representation. Each end-effector action has 10 dimensions: position, rotation, and gripper state. The author only normalizes the gripper to $[-1, 1]$, and keeps the remaining dimensions in physical scale. This makes it easier to share motion patterns between different robot embodiments and initial poses.
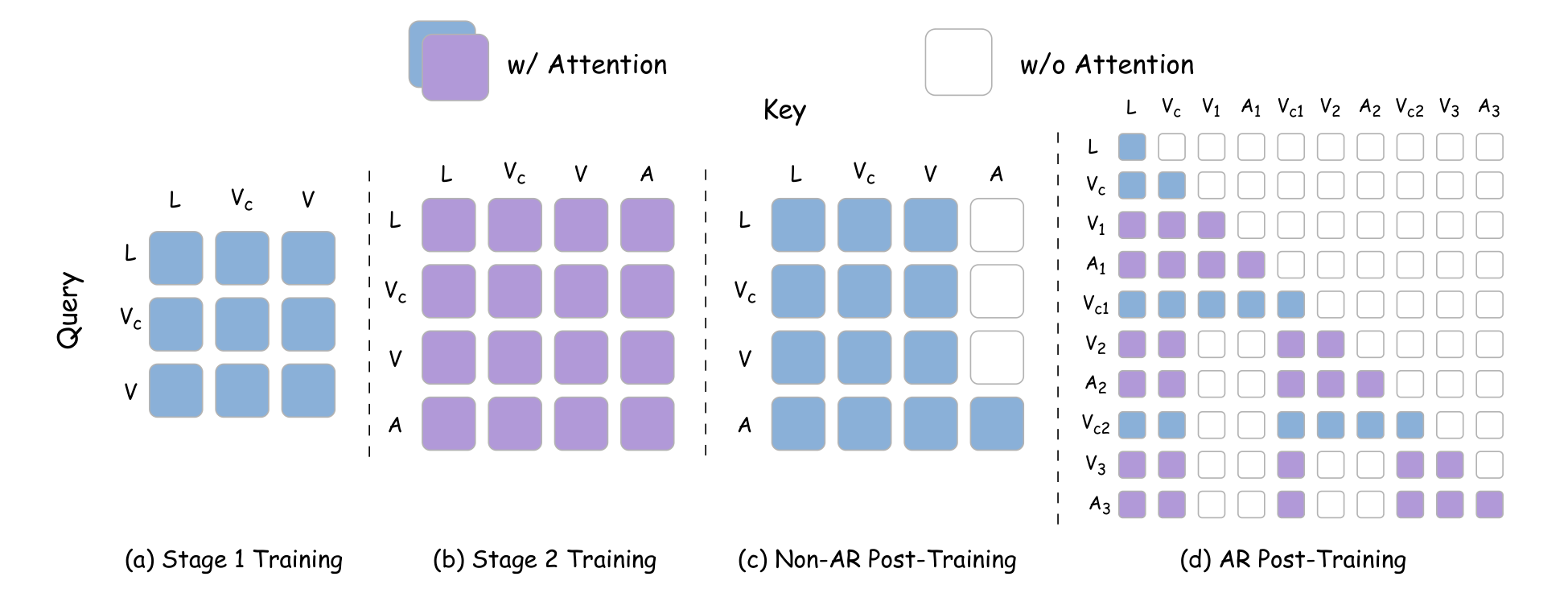
3.8 Post-training: Non-AR and AR
Post-training adaptation target embodiment, including Non-AR and AR settings. Non-AR forward denoises video/action tokens in the entire observation window at one time, suitable for efficient execution of shorter horizons. AR handles long-range tasks according to chunk-level factorization: chunks are processed in parallel during training, but block-causal mask is used; during deployment, rollout is performed sequentially, and the new observation frame is used as the clean context of the next chunk.
The key deployment tip is V2A-style attention: action tokens can attend to video/language tokens, but video tokens do not attend action tokens. In this way, when reasoning, you can first perform a short joint denoising prefix, then freeze the video stream, and only continue to update the action stream.
3.9 Inference acceleration stack
| Technology | Steps | Latency | Frequency | Speedup |
|---|---|---|---|---|
| Baseline | 50 | 4.90s | 0.20 Hz | 1.00x |
| + Noise sampling | 30 | 2.90s | 0.34 Hz | 1.69x |
| + torch.compile | 30 | 0.98s | 1.02 Hz | 5.00x |
| + FP8 quantization | 30 | 0.88s | 1.14 Hz | 5.57x |
| + DiT cache | 30 | 0.20s | 5.00 Hz | 24.5x |
| + V2A-style | 30 action-only | 0.09s | 11.11 Hz | 54.4x |
3.10 Real-time chunk fusion
For closed-loop control, MotuBrain decouples the model inference loop and the robot action execution loop: the controller executes the current action chunk, and the model asynchronously generates the next chunk based on the latest observations. The problem is that chunk switching will cause jumps. The paper uses the unexecuted part of the current chunk to constrain the next chunk: the inference delay $\delta$ and the control period $\Delta t$ define the number of freezing steps:
The first $d$ steps are completely constrained by the remaining actions of the previous chunk; after that, exponential decay weights are used:
$$g(\rho_i)=\frac{\rho_i(e^{\rho_i}-1)}{e-1}, $$ $$w_i=\begin{cases}1, &0\le iSystem maintenance delay queue $Q$, use $\hat{d}_{t+1}=\max(Q)$ as a conservative estimate to adapt to network and model latency fluctuations. This section is very engineering, but very critical for real robots.
4. Experimental results: RoboTwin, WorldArena, real long-range control
4.1 RoboTwin 2.0
According to the RoboTwin 2.0 protocol, the model uses 2, 500 clean demonstrations (50 tasks, 50 per task) and 25, 000 randomized demonstrations (500 per task). Video downsampled to 5 Hz, motion to 10 Hz. MotuBrain is fine-tuned from pretrained weights, reaching 95.8 and 96.1 in clean and randomized settings respectively.
| model | Clean | Randomized |
|---|---|---|
| $\pi_0$ | 65.9 | 58.4 |
| X-VLA | 72.9 | 72.8 |
| $\pi_{0.5}$ | 82.7 | 76.8 |
| starVLA | 88.2 | 88.3 |
| LingBot-VLA | 86.5 | 85.3 |
| Motus | 88.7 | 87.0 |
| LingBot-VA | 92.9 | 91.5 |
| Fast-WAM | 91.9 | 91.8 |
| MotuBrain w/o Pretrain | 91.5 | 91.3 |
| MotuBrain-Non-AR | 91.9 | 92.3 |
| MotuBrain | 95.8 | 96.1 |
The paper further reports: MotuBrain has 24 tasks with perfect scores in the clean setting, 25 tasks with perfect scores in the randomized setting, and 19 tasks with 100% in both settings. The number of tasks with more than 90% success rate is 42 clean tasks and 44 randomized tasks. The improvement focuses on tasks under multi-stage coordination, contact richness, spatial arrangement, and random visual perturbations.
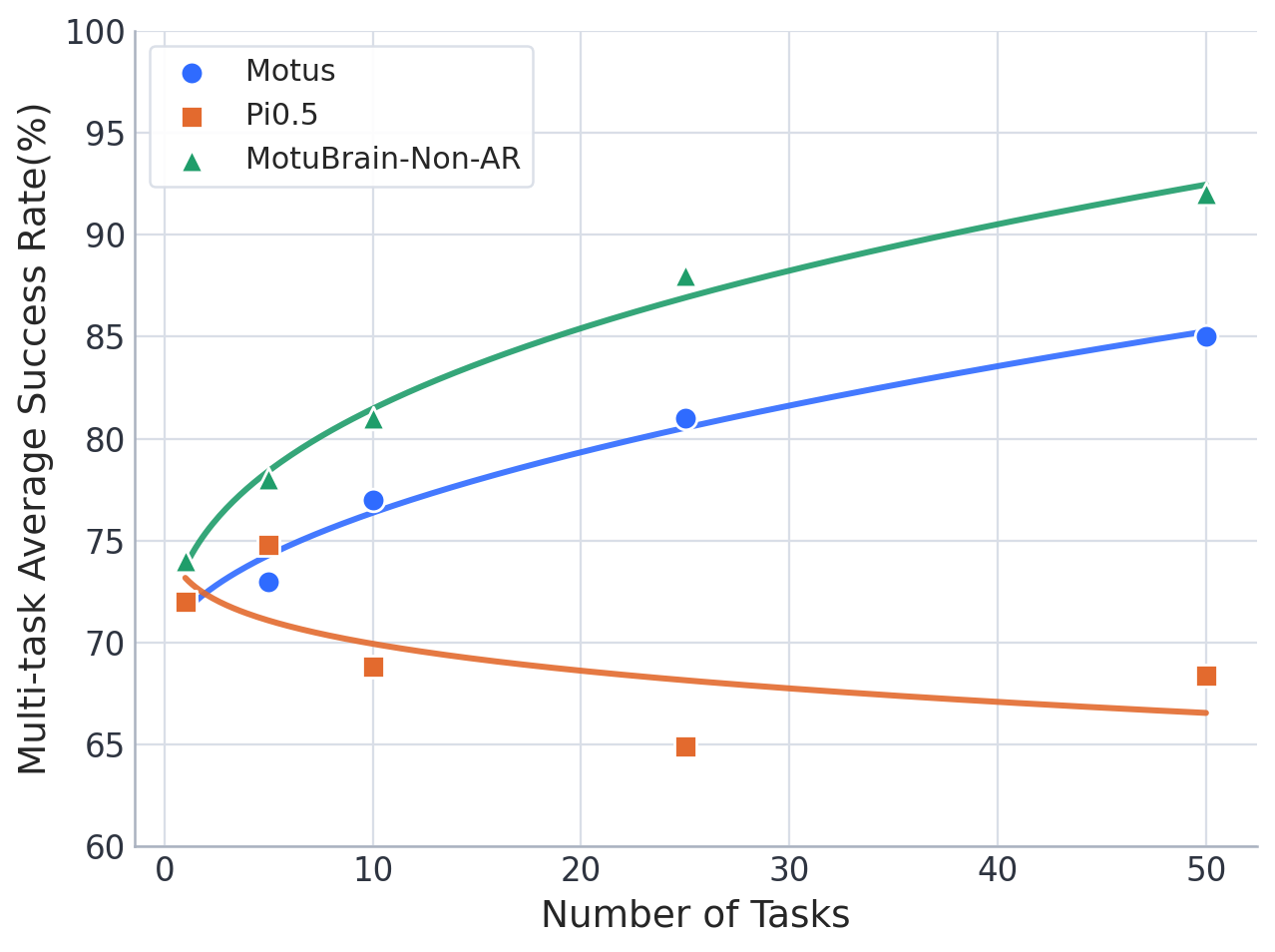
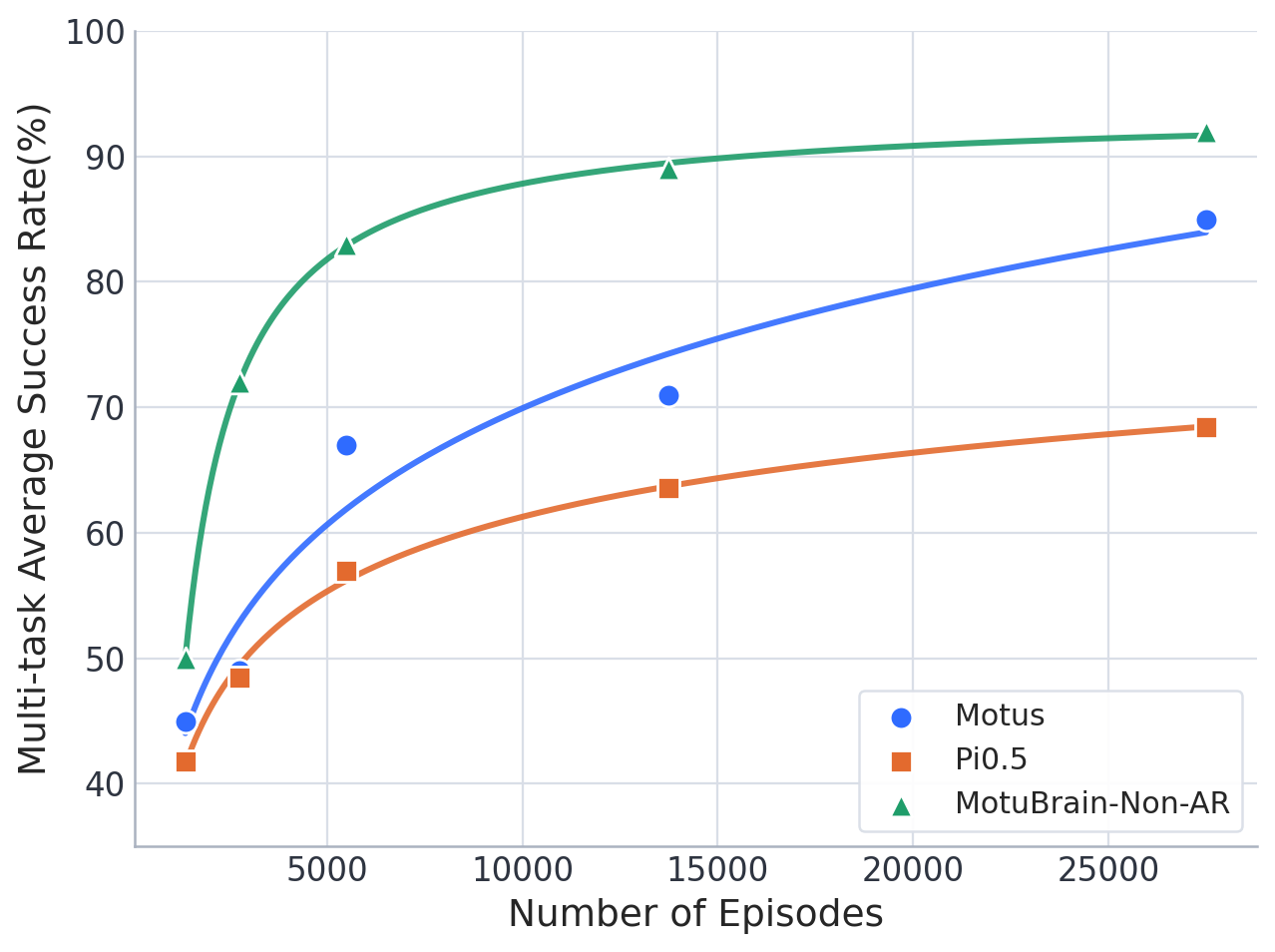
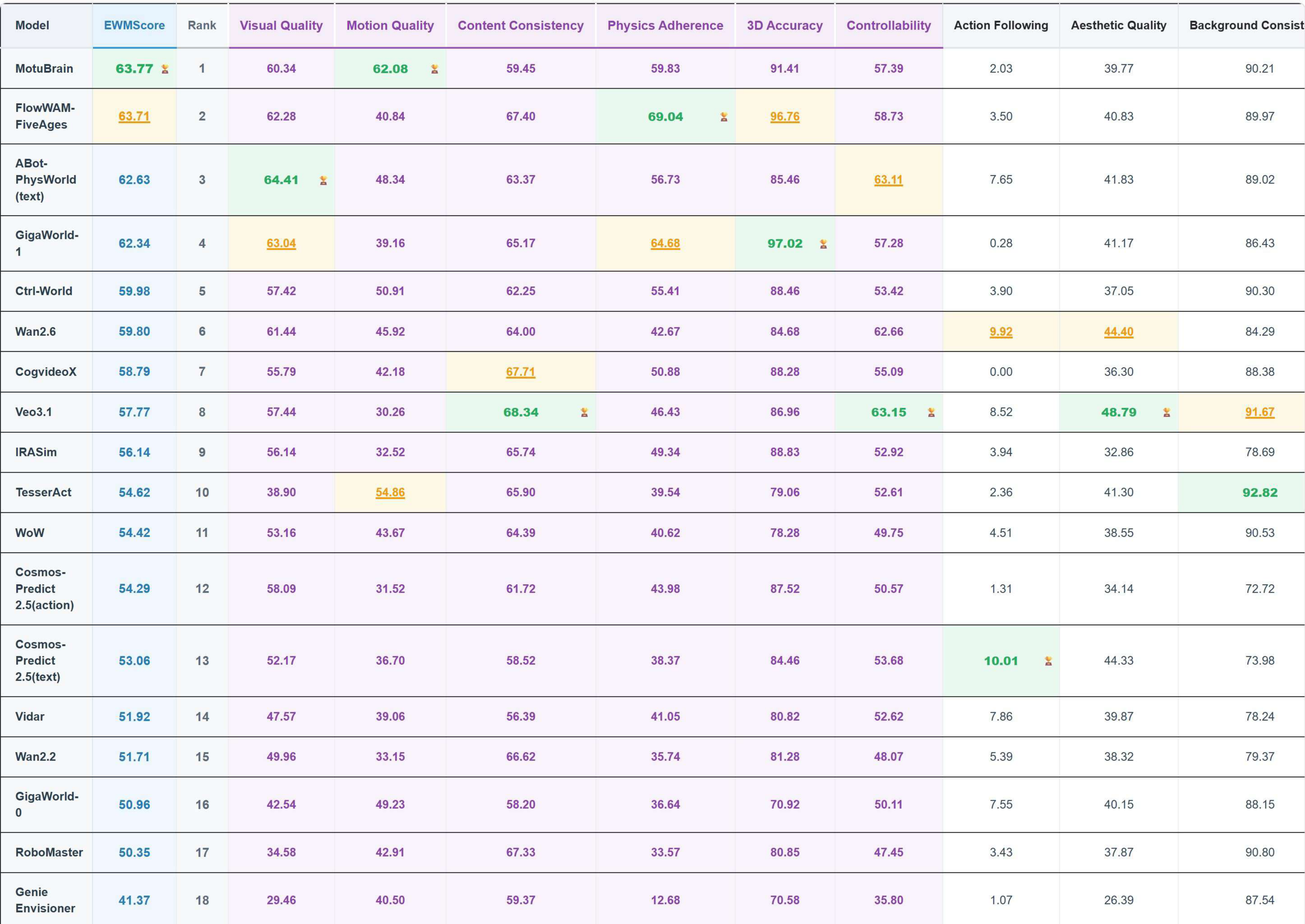
4.2 WorldArena
WorldArena evaluates embodied world models from 16 indicators in six sub-dimensions: visual quality, motion quality, content consistency, physics adherence, 3D accuracy, and controllability. MotuBrain participated in the evaluation in forward-dynamics mode, using 5 Hz video and 10 Hz actions. The EWMScore was 63.77, which the paper said was the highest in the comparison table.
| model | EWMScore ↑ | Remarks |
|---|---|---|
| MotuBrain | 63.77 | The motion quality indicator is particularly strong. |
| Veo3.1 | 57.77 | instruction following is high, but motion metrics are low. |
| Wan2.6 | 59.80 | The visual quality is strong. |
| Ctrl-World | 59.98 | subject/background consistency is highly competitive. |
| ABot-PW | 62.63 | The interaction quality is high. |
| GigaWorld-1 | 62.34 | JEPA similarity/depth/trajectory is highly competitive. |
MotuBrain leads in three motion quality indicators: Dynamic Degree, Flow Score, and Motion Smoothness. The paper emphasizes that this shows that the model does not generate beautiful videos that are close to stillness, but produces continuous, smooth, locally focused motion over embodied-relevant regions.
4.3 Real robots: few-sample adaptation
Real experiments start from a pretrained model and use 50 to 100 same-embodiment trajectories to adapt to new humanoid platforms. The paper emphasizes not relying on VLM planner, dual-system decomposition, external memory or retry-specific data.
| Task | Evaluation scale | Number of atomic actions | average execution time | total score |
|---|---|---|---|---|
| Making Oden | 5 trials | 7 | 33 s | 98.54 |
| Mixing Cocktails | 7 trials | 15 | 124 s | 97.34 |
| Flower Arrangement | 10 trials | 10 | 138 s | 83.30 |
The score is out of 100, with equal weight for each sub-task step. Full marks will be given if the first retry is completed, 80% for one retry, 50% for two retries, and 0 for three or more retries. In Flower Arrangement, the author particularly emphasizes that the model shows certain online self-correction capabilities without explicit recovery supervision.
4.4 Qualitative results of real tasks




5. Intensive reading of charts
5.1 Fig. 1: Three things in the architecture diagram
There are three layers to look at in this picture: first, text/video/action are independent streams instead of simply splicing tokens; second, H-bridge only does full cross-modal attention in the middle layer; third, multiview enters the unified RoPE space through position offsets. These three things correspond to semantic control, cross-modal alignment and real robot multi-camera input respectively.
5.2 Table 1: Five distributions are the core of unified modeling
The unity of MotuBrain is not as simple as "one model outputs many things", but writing conditional distributions as different conditional problems under the same multimodal diffusion/flow family. During the report group meeting, it was recommended to use Table 1 as the main line. The subsequent architecture, training masks and V2A inference are all to support these distributions efficiently.
5.3 Speedup table: deployment contribution is heavy
If you just look at the model structure, MotuBrain may seem like a natural extension of Motus; but the 54.4x speedup is the key engineering contribution of this paper. Without V2A-style action-only inference, DiT cache and chunk fusion, it is difficult for this type of WAM to approach real-time closed loop on real robots.
5.4 Real-world table: strong but depends on caliber
The real task score is very high, but it is not compared with the external baseline for the same protocol, but the paper's custom step scoring. It is valuable because it demonstrates the feasibility of long-range control with a small number of samples; but rigorous comparison of different methods also requires the disclosure of task definitions, evaluation scripts, complete failure examples, and multi-environment statistics.
6. reproducibility list and project details
6.1 Key configurations that can be extracted
| Project | Paper information |
|---|---|
| base model | Vidu video generation model as foundation. |
| Modeling framework | UniDiffuser, continuous video/action modalities. |
| structure | Text/video/action Third-rate Mixture-of-Transformers. |
| cross-modal attention | H-bridge: 50% layers full V-A attention in the middle; 25% decoupled at the bottom/top. |
| multiple perspectives | Each view has independent Vidu VAE encoding and spatial dimension 3D RoPE offsets. |
| action expression | relative EEF action; position direct subtraction, rotation $R_s^{-1}R_i$, gripper unchanged. |
| action dimension | Each end-effector action has 10 dimensions: position + 6D rotation + gripper. |
| RoboTwin data | 2, 500 clean demos + 25, 000 randomized demos; 50 tasks. |
| Frequency | RoboTwin videos 5 Hz, actions 10 Hz. |
| Inference optimization | step reduction, torch.compile, FP8, DiT cache, V2A action-only, action smoothing, frequency-aware interpolation. |
6.2 Recurring gaps
- No public code: There is currently no official GitHub, and it is difficult to truly reproduce the details of the inference stack.
- The pre-training data size is incomplete: Scales, cleaning and mixing ratios for Internet/ego-centric/heterogeneous data are not fully listed.
- Model scale is missing: The paper emphasizes architecture and deployment, but does not give a complete table of parameters/layers/hidden size like common model cards.
- H-bridge details: Which specific layers are joint, which decoupled, and whether the text stream is fully involved requires code confirmation.
- Real robot control stack: The low-level controller, communication delay, limiting, safety stop, failure determination and retry statistics are not fully disclosed.
- WorldArena Repeatability: Papers report leaderboard scores, but require benchmark submission configuration and generation parameters for full review.
7. Critical discussion and group meeting questions
7.1 Strong points of the paper
- Complete unity: Five inference modes and attention masks make the unifying goal of WAM clear.
- Strong deployment awareness: Not only the model score is reported, but also the inference optimization path from 4.90s to 0.09s is given.
- Multiple perspectives and embodiment migration: Solve the common problems of multiple cameras and inconsistent action spaces in real robots.
- Experimental coverage is wide: There are results for simulation, world model benchmark, and real housework tasks.
7.2 Points to be cautious about
- Systems engineering contributions and modeling contributions are intertwined: Whether RoboTwin/real deployment improvement comes from WAM representation, data, post-training, or the engineering stack requires more ablation.
- The official self-evaluation contains more elements: There is no external baseline for real tasks compared to the protocol, and the scoring method also requires more transparency.
- High threshold for recurrence: Without code, model cards, and complete data recipes, junior PhD is difficult to reproduce end-to-end.
- The Action Following indicator is not always strong: The Action Following of MotuBrain in the WorldArena table is lower than Wan2.6/Veo3.1, etc. It is necessary to understand the relationship between this indicator and the control success rate.
7.3 Group meeting discussion question 1: Does WAM's ability come from "predicting the world" or "deployment optimization"?
MotuBrain also proposes model structure, pre-training pyramid, post-training, action-only inference and real-time control fusion. To judge scientific contributions, it needs to be dismantled: fixed inference stacks are compared with different architectures, fixed architectures are compared with and without world modeling, and fixed data are compared with VLA vs WAM. Otherwise it is difficult to know the core source of 95.8/96.1.
7.4 Group meeting discussion question 2: Will unifying the five distributions restrain each other?
It is elegant for a model to do VLA, WM, IDM, VGM, and joint prediction at the same time, but different tasks may have conflicting requirements for attention mask, timestep sampling, loss weight, and data distribution. MotuBrain uses stage-wise training and V2A mask to alleviate this problem, but whether routing, task-specific adapters or dynamic loss balancing will be needed in the future is worthy of in-depth discussion.
7.5 Follow-up research directions
- Publicly reproducible kit: Publish model cards, inference stack code, benchmark configs, and failure cases.
- Fine ablation: Separate independent contributions of H-bridge, text stream, multi-view RoPE, relative EEF, V2A inference.
- Uncertainty and security: Estimate risks when WAM generates actions and incorporate security constraints/online error correction.
- Stronger open world test: Validating the world prior in mobile operations, dynamic human environments, haptically rich tasks, and long-duration tasks.
- More extreme migration across embodiments: Platforms with huge differences in shapes from double-arm humanoid to single-arm, mobile chassis, and gripper.