
MOSS-TTS-Nano
A multilingual tiny speech generation model for realtime voice cloning, CPU-friendly deployment, and lightweight product integration.
MOSS-TTS-Nano is a deployment-first TTS model designed for realtime speech generation, voice cloning, and lightweight integration. Built on an Audio Tokenizer + LLM autoregressive pipeline, it stays compact enough for practical CPU use while covering Chinese, English, and a broad multilingual set.
The model pairs a ~20M-parameter MOSS-Audio-Tokenizer-Nano with a small LLM for autoregressive token prediction. The tokenizer uses a CNN-free, causal Transformer design with RVQ 16 codebooks operating at a 12.5 Hz token stream — achieving 0.125–2 kbps variable bitrate while preserving 48 kHz stereo output quality. Voice cloning is driven entirely by a short reference clip, with no additional fine-tuning required.
Key Features
Model Size
0.1 B
Compact enough for practical CPU inference — no GPU required.
Audio Quality
48 kHz Stereo
Native 2-channel input and output at full 48 kHz sample rate.
Languages
20
Mandarin, English, Japanese, Korean, Spanish, French, and more.
Tiny Tokenizer
~20 M params
CNN-free, causal Transformer with RVQ 16 codebooks at 12.5 Hz.
Bitrate
0.125–2 kbps
Variable bitrate via configurable codebook count.
Inference
Realtime
Streaming with low first-token latency. Long text auto-chunked.
Architecture
Following the MOSS-TTS technical report, the family-level design is organized as discrete audio tokens + autoregressive modeling + large-scale pretraining. This Nano demo keeps the same recipe in a smaller, deployment-first configuration.
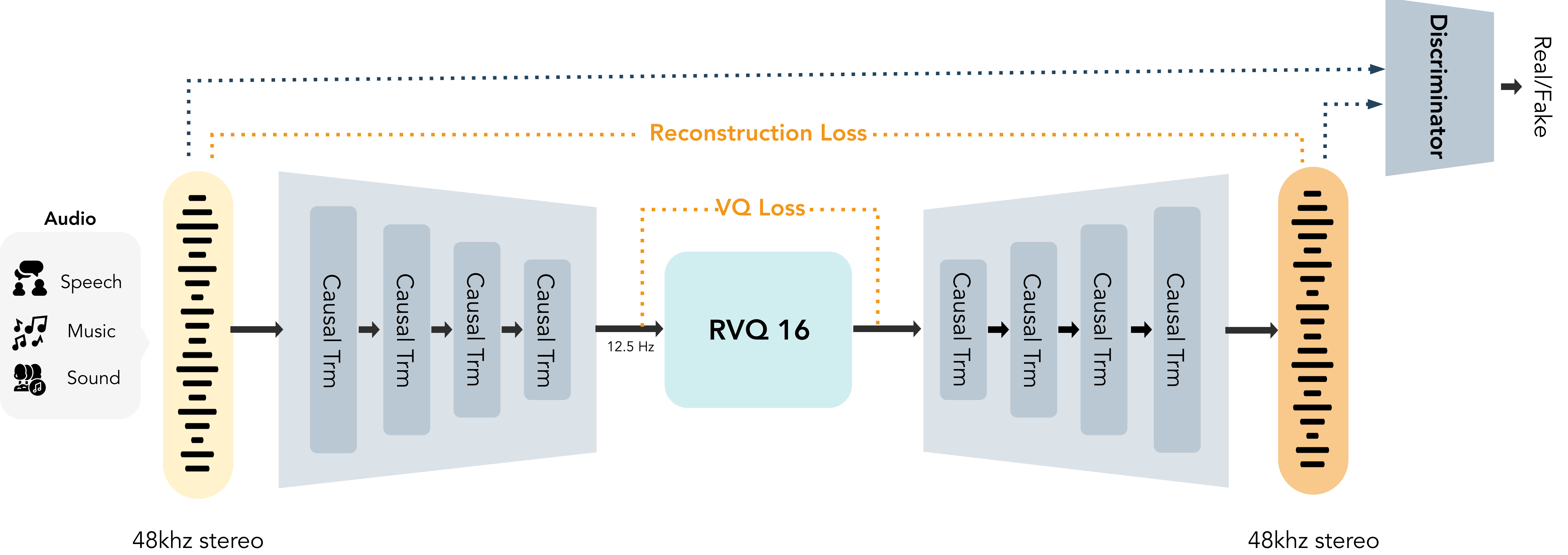
The architecture of MOSS-Audio-Tokenizer-Nano
MOSS-Audio-Tokenizer
The tokenizer is a causal Transformer audio codec that compresses 48 kHz stereo audio into a 12.5 fps RVQ token stream for scalable autoregressive modeling. In the report, the encoder and decoder each contain 12 causal Transformer blocks with sliding-window attention, and the quantizer uses 16 RVQ layers so the token sequence remains compact enough for long-context generation.
20M params
48kHz stereo
16-layer RVQ
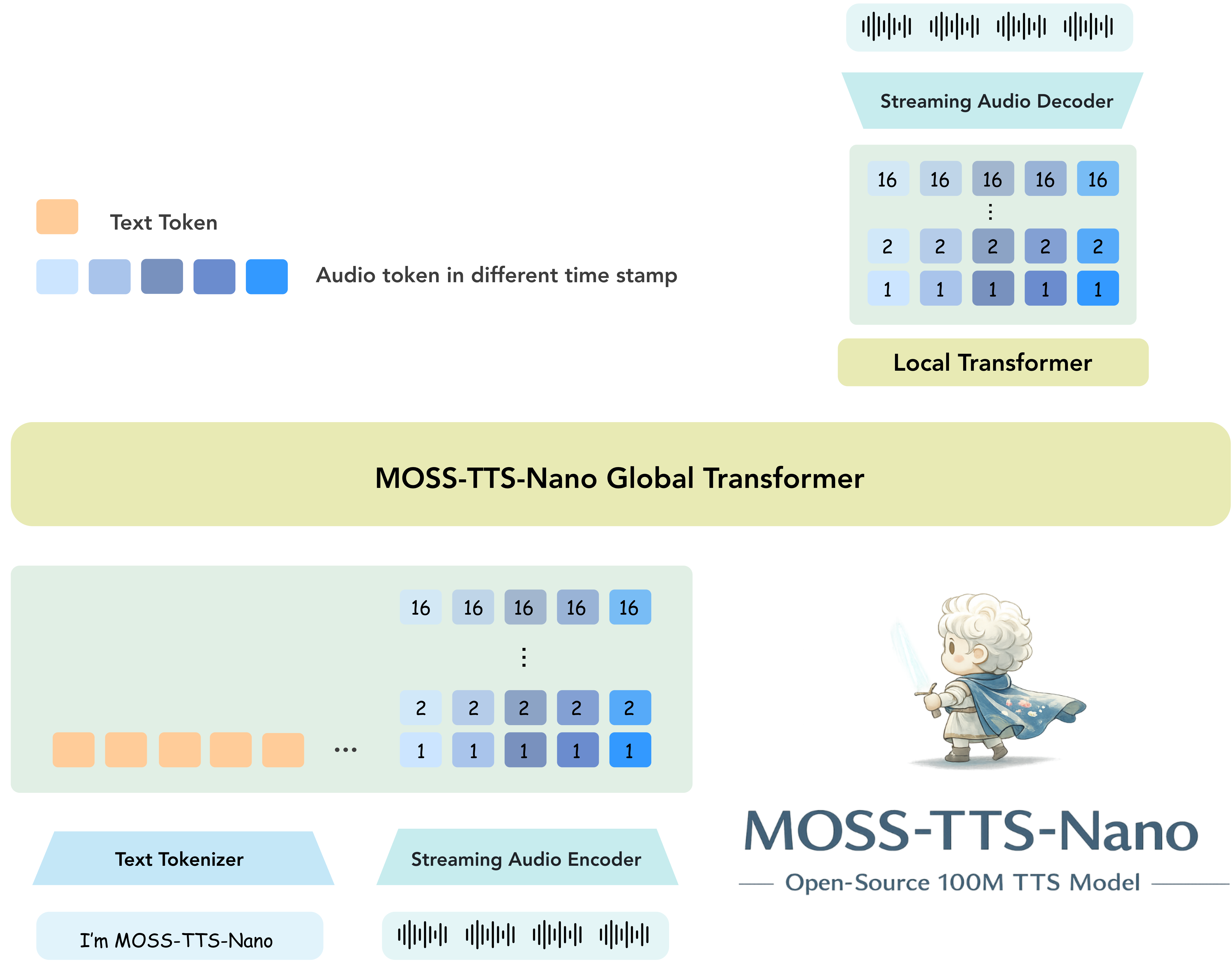
The architecture of MOSS-TTS-Nano
MOSS TTS Nano
On top of the tokenizer, MOSS-TTS-Nano can adopt a hierarchical token modeling design built around a Local Transformer. Instead of using RVQ-aware temporal delays, the model sums the embeddings from all RVQ layers at each aligned time step and feeds that hidden state into a single Transformer backbone. The backbone then produces one global latent per step, which a lightweight autoregressive Local Transformer expands into the within-step token block, sequentially predicting one text-or-pad token and 16 RVQ audio tokens.
100 M params
Local Transformer
Tiny, Fast and Powerful
Demo
Language Coverage
Japanese, Korean, Spanish, French, German, Italian, Hungarian, Russian, Persian, Arabic, Polish, Portuguese, Czech, Danish, Swedish, Greek, and Turkish — grouped with Chinese and English.