GR-MG: Leveraging Partially-Annotated Data via Multi-Modal Goal-Conditioned Policy
1. Quick overview of the paper
Difficulty rating: ★★★★☆. Reading requires familiarity with language conditional imitation learning, goal-conditioned policy, diffusion image editing, Transformer policy, cVAE action trajectory prediction, and CALVIN long-range evaluation.
Keywords: Robot manipulationPartially annotated dataGoal image generationMulti-modal goal-conditioned policyTask progress
| Reading targeting item | Short answer |
|---|---|
| What should the paper solve? | Language-conditional robot operation requires trajectories with both action and text annotations, but this fully-annotated data is expensive; the paper must include both "videos with text and no actions" and "robot trajectories with actions and no text" into training. |
| The author's approach | Split the goal into two levels: first use InstructPix2Pix style progress to guide the goal image generator to generate sub-goal image, and then use GPT-style policy that is simultaneously conditioned on text + goal image to predict action trajectories, future images and task progress. |
| most important results | The average number of completions of 5 consecutive tasks in CALVIN ABC→D increased from 3.35 to 4.04; the real robot simple setting increased from 68.7% to 78.1%, and the generalization average increased from 44.4% to 60.6%. |
| Things to note when reading | The core is not simply "generating a good-looking target map", but the progress conditions, text+image bi-conditional policy, and two types of partially annotated data entering the training paths of the two modules respectively. |
Core contribution list
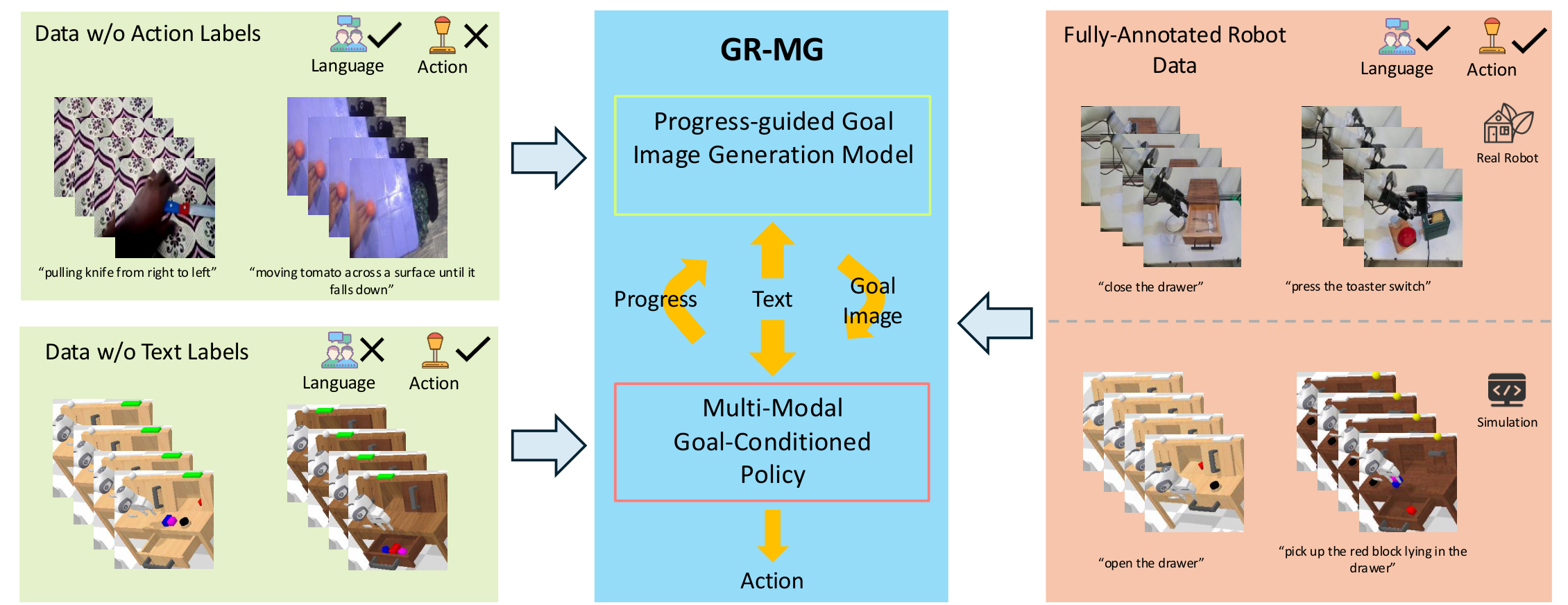
- Generative Robot Policy with Multi-modal Goals (GR-MG) is proposed, which can simultaneously utilize data lacking action labels and text labels during training.
- Add task progress condition in the target image generation stage, and inject "percentage completed" into the T5 text encoder by appending sentences to the text.
- Validate multi-tasking, out-of-distribution generalization, data scarcity, ablation, and few-shot novel skill learning on simulated and real robots.
2. Motivation
2.1 What problem should be solved?
The paper focuses on language-conditioned visual robot manipulation. A standard strategy can be written as:
The strategy uses language, historical images and robot status to directly predict the current action trajectory.
$$\mathbf{a}_{t} = \pi(l, \mathbf{o}_{t-h: t}, \mathbf{s}_{t-h: t})$$| $l$ | Natural language task instructions. |
| $\mathbf{o}_{t-h: t}$ | For the RGB observation sequence from $t-h$ to $t$, the paper uses static camera and wrist-mounted camera. |
| $\mathbf{s}_{t-h: t}$ | End-effector 6-DoF pose and binary gripper state sequence. |
| $\mathbf{a}_{t}$ | The current action trajectory to be output, not the single step action. |
The difficulty lies in the data: fully-annotated trajectory contains language, images, states, and actions at the same time, and the acquisition and labeling costs are high. In contrast, text-annotated human activity videos lack actions but are easily obtained from public video data; robot trajectories without text labels lack language but can be collected autonomously or semi-autonomously by robots. The goal of GR-MG is to convert both types of data into trainable signals.
2.2 Where are the existing methods stuck?
The paper divides existing routes into two categories: one category only uses data lacking a certain label, such as learning representations from videos or training with languageless robot trajectories; the other category uses generated target images/future videos as conditions for policy or inverse dynamics. The author pointed out that these methods usually have two problems: first, goal generation tends to ignore the task progress, resulting in the generation of wrong goals in tasks where "the current observations are the same but in different stages"; second, if the policy only relies on generated images, once the generated images deviate from the language instructions, subsequent action predictions will become fragile.
2.3 Solution ideas of this article
The high-level design of GR-MG is "generative goal + multi-modal conditional strategy". The generator is responsible for converting the language and current observation into an intermediate target image; the strategy not only looks at this target image, but also retains the language conditions, so when the generated image is inaccurate, there is still a text signal to constrain action prediction. The task progress is predicted by policy in rollout, and then fed back to the generator to form a closed loop.
4. Detailed explanation of method
4.1 Data form and training signal distribution
The fully-annotated trajectory is written as:
Among them, language $l$, observation $\mathbf{o}$, status $\mathbf{s}$, and action $\mathbf{a}$ are all available. GR-MG splits the data into different modules according to the missing tags:
| data type | What's included | Which module to use for training | How to use during training |
|---|---|---|---|
| fully-annotated robot trajectories | Language, image, status, action | two modules | The generator uses the current frame, language, future frames, and progress; the policy uses language, real target graphs, historical observations/states, and actions. |
| data w/o action labels | Video with text, no action | goal image generation model | No action is required, just sample the current image and future target image from the video. |
| data w/o text labels | Robot trajectory with motion, no text | multi-modal goal-conditioned policy | Use null string as the text condition, train the policy first, and then finetune the fully-annotated data. |
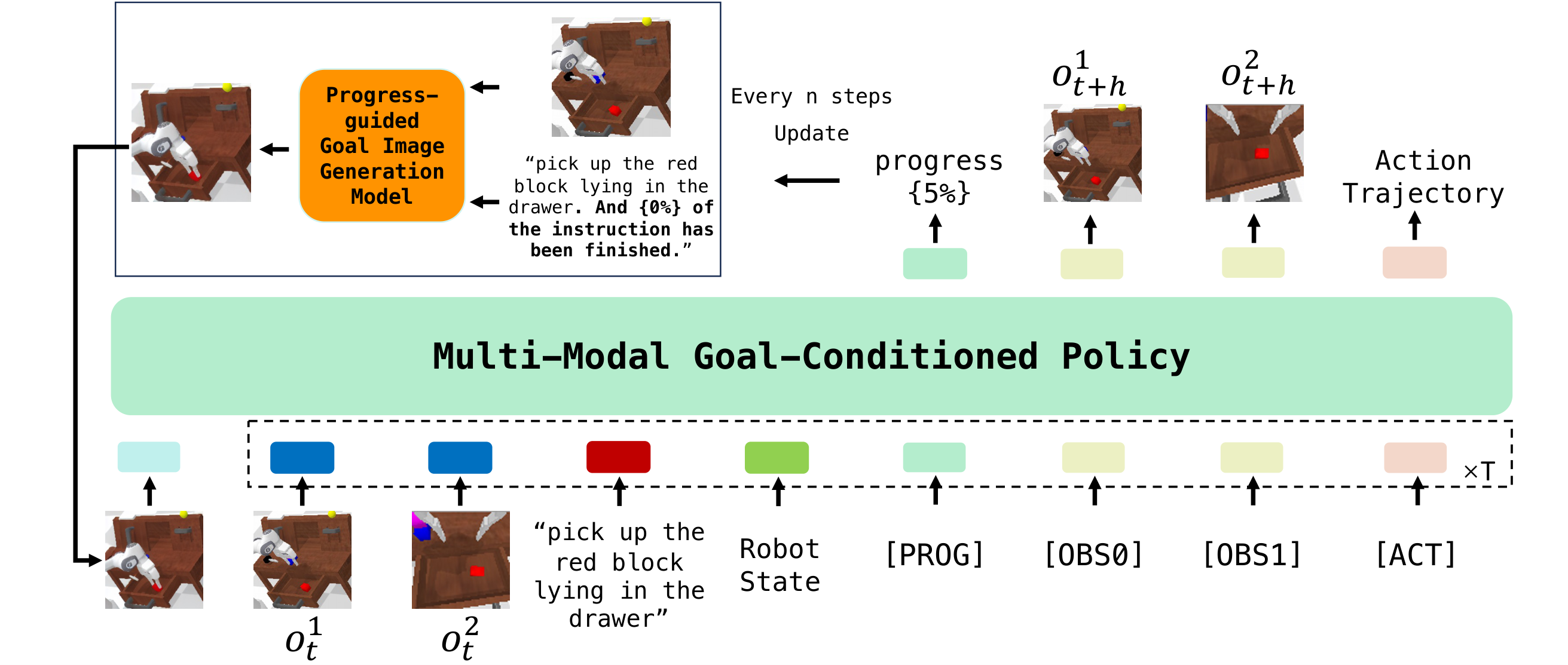
4.2 Progress-guided Goal Image Generation Model
The generator is based on InstructPix2Pix, a diffusion-based image-editing model. The input is the current observation image, text task description and task progress, and the output is the sub-goal image after $N$ steps. The author follows Susie's sub-goal idea and does not directly generate the final state, but regularly updates the intermediate goals.
Appendix Data/Generation Model reproducibility details are given: the image is first resized to $256\times256$; the training sample is $(l, o_t, o_{t+k}, p)$; the goal image is sampled from frames in the future $k_\mathrm{min}$ to $k_\mathrm{max}$; latent diffusion uses VAE image encoder, U-Net denoising, text cross-attention and classifier-free guidance; the inference denoising steps are 50.
| Dataset | $k_\mathrm{min}$ | $k_\mathrm{max}$ | Description |
|---|---|---|---|
| CALVIN | 20 | 22 | Simulation benchmark. |
| Something-Something-V2 | 11 | 14 | Text annotation of human activity videos. |
| RT-1 | 5 | 6 | Real robot data for scaling generator training. |
| Real | 30 | 35 | Real robot data in this article. |
4.3 Multi-modal Goal-Conditioned Policy
policy inherits the GPT-style Transformer structure of GR-1, but makes three key changes:
- Add goal image condition: Use MAE tokenization to encode the generated target image, and put these tokens at the front of the input sequence so that subsequent tokens can attend to the target image.
- Join
[PROG]query token: The output embedding of this token is regressed through linear layer task progress. - Use cVAE to predict the $k$ step action trajectory: compile the action trajectory into a style vector, and then combine
[ACT]The token output and $k$ learnable tokens are sent to the Transformer decoding action trajectory together.
Appendix Multi-modal Goal Conditioned Policy Further explanation: Each picture is first encoded into 196 patch tokens and 1 global token; the 196 patch tokens are reduced to 9 tokens by Perceiver Resampler; the language is encoded with CLIP; the robot state is encoded with a linear layer; all tokens are aligned to the GPT hidden size through the linear layer. GPT hidden size is 384, 12 heads, 12 layers.
Algorithm: GR-MG inference loop
Input: text instruction l, observation/history o, robot state s
progress p = 0
Every n steps:
prompt = l + " And {p}% of the instruction has been completed."
goal_image = ProgressGuidedGenerator(current_image, prompt)
Each policy step:
tokens = [MAE(goal_image), CLIP(l), MAE(o_{t-h:t}), Linear(s_{t-h:t}), [PROG], [OBS], [ACT]]
action_trajectory, future_images, progress = GPTPolicy(tokens)
execute first part of action_trajectory
feed predicted progress back to generator at next goal update
4.4 Training objectives
The goal image generation model is trained according to the DDPM noise prediction method; the policy predicts actions, future images and progress at the same time. policy loss is:
This is not a single action cloning loss, but a joint constraint of action, image prediction, VAE regularization, and progress regression.
$$L = l_\mathrm{arm} + 0.01 l_\mathrm{gripper} + 0.1 l_\mathrm{img} + l_\mathrm{kl} + l_\mathrm{prog}$$| $l_\mathrm{arm}$ | Robotic arm action prediction loss. |
| $l_\mathrm{gripper}$ | Gripper action prediction loss, weight 0.01. |
| $l_\mathrm{img}$ | Future image prediction loss, weight 0.1, follows the GR-1 training signal. |
| $l_\mathrm{kl}$ | KL divergence of cVAE. |
| $l_\mathrm{prog}$ | The task progress prediction loss is fed back to the generator. |
5. Experiment

5.1 Experimental setup
| experimental group | Data and settings | Review questions |
|---|---|---|
| CALVIN ABC→D | Train on Env A/B/C, test on Env D; ~18k fully-annotated trajectories; evaluate 1000 5-task chains. | Multitasking and generalization to unseen environments. |
| CALVIN data scarcity | Only 10% fully-annotated data is used, about 1.8k trajectories / 0.1M frames; at the same time, the text-free trajectories of 1M frames in Env A/B/C are used to train the policy first. | Is data w/o text labels helpful when fully-annotated data is missing? |
| real robot | Kinova Gen-3 + Robotiq 2F-85 + static/wrist cameras; 18k demonstrations, 37 training tasks; SSV2 and RT-1 added when training the generator. | Generalization of simple, unseen distractors, unseen instructions, unseen backgrounds, unseen objects. |
| few-shot novel skills | Hold out 8 tasks from 37 tasks, 7 of which are novel skills; first train on 29 tasks/15k trajectories, and then finetune with 10 or 30 trajectories per task. | Few-shot learning capabilities for new skills. |
5.2 CALVIN main result
| method | 1 task | 3 tasks | 5 tasks | Avg. Len. |
|---|---|---|---|---|
| 3D Diff Actor | 93.8% | 66.2% | 41.2% | 3.35 ± 0.04 |
| GR-MG w/o image | 91.0% | 67.8% | 47.7% | 3.42 ± 0.28 |
| GR-MG w/o text | 91.8% | 68.9% | 48.1% | 3.46 ± 0.04 |
| GR-MG w/o progress | 94.1% | 75.2% | 56.3% | 3.76 ± 0.11 |
| GR-MG | 96.8% | 81.5% | 64.4% | 4.04 ± 0.03 |
The most critical way to read the main table is to look at the long-horizon indicator: the single task success rate has not improved much from 93.8% to 96.8%, but the 5 consecutive tasks have increased from 41.2% to 64.4%, and the average completion length has increased from 3.35 to 4.04, indicating that the robustness improvement under error accumulation is more obvious. The performance of w/o text and w/o image is similar and both are lower than the full model, supporting the paper's conclusion about the biconditional complementarity of text + image.
5.3 Data scarcity and partially labeled data
| method | fully-annotated data | partially-annotated data | 1 task | 5 tasks | Avg. Len. |
|---|---|---|---|---|---|
| GR-1 | 10% | No | 67.2% | 6.9% | 1.41 ± 0.06 |
| GR-MG w/o part. ann. data | 10% | No | 82.4% | 19.7% | 2.33 ± 0.04 |
| GR-MG | 10% | Yes | 90.3% | 37.5% | 3.11 ± 0.08 |
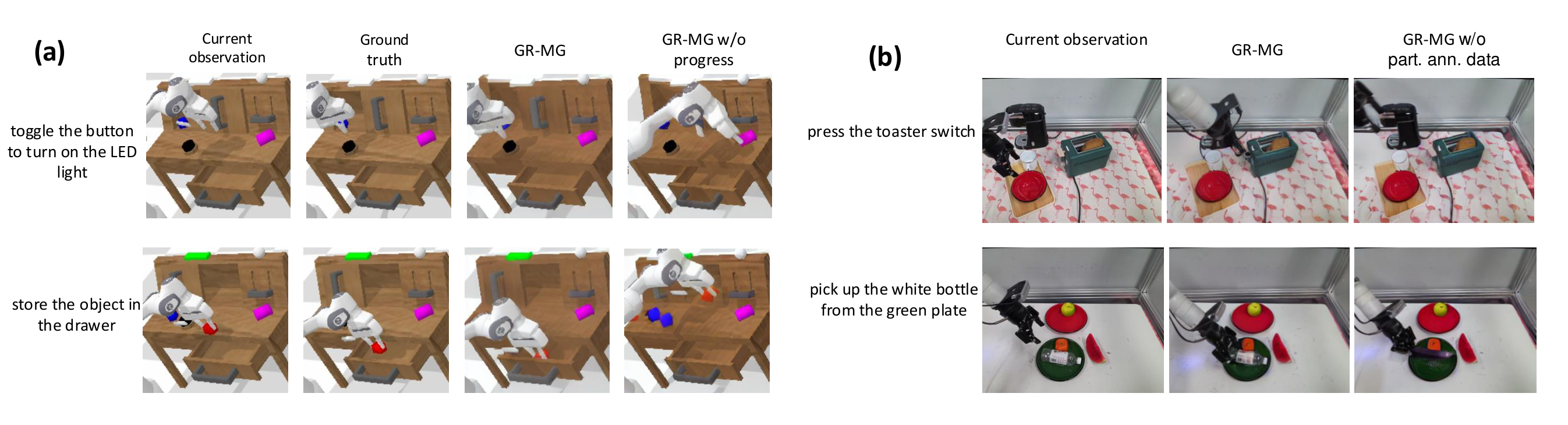
When only 10% of the fully annotated data is given, the additional 1M frames of text-free trajectories significantly improve policy capabilities. The author observed that w/o part. ann. data can often generate the correct target graph, but the policy has insufficient ability to follow the target graph. Therefore, the main enhancement of the textless robot trajectory is the policy, not the generator.
5.4 Progress condition ablation
| method | MSE ↓ | PSNR ↑ | SSIM ↑ | CD-ResNet50 ↑ |
|---|---|---|---|---|
| GR-MG w/o progress | 965.347 | 18.821 | 0.721 | 0.945 |
| GR-MG | 903.139 | 19.121 | 0.730 | 0.946 |
This set of experiments turns "whether progress condition is just an additional prompt decoration" into a testable question. All four target map similarity metrics improve; the qualitative plot shows w/o progress that it can produce target maps of higher visual quality but inconsistent with the language, while the full model is closer to the ground truth.
5.5 Real robot results
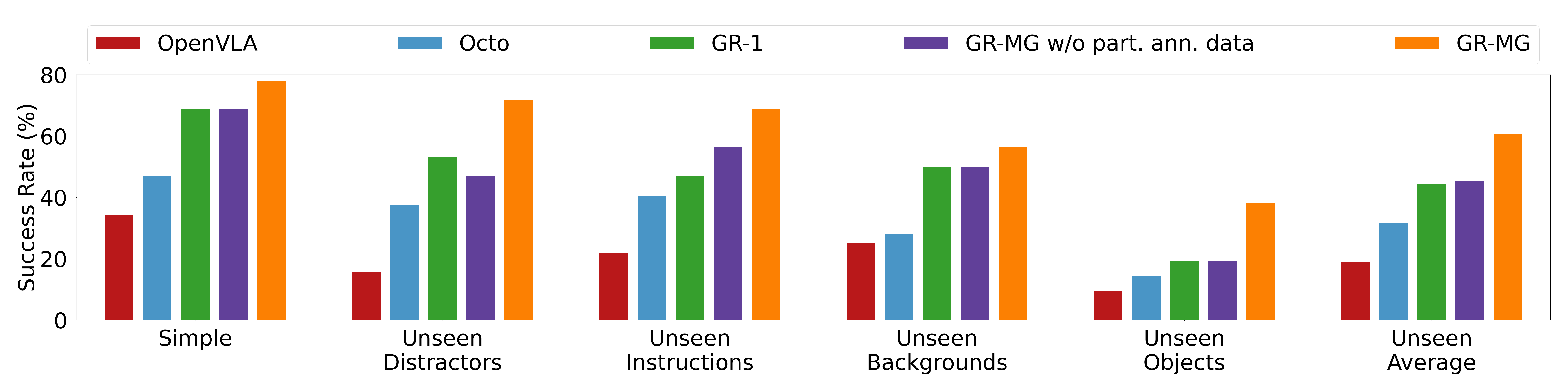
A total of 58 tasks were evaluated on real robots. The paper reports that GR-MG improves the average success rate from 68.7% to 78.1% in the simple setting, and from 44.4% to 60.6% in the four-category generalization average. The author also explained the typical failures of baseline one by one: OpenVLA's discrete action space and lack of history/wrist camera input affect grasping and gripper opening and closing timing; Octo has history and proprioception, but generalization of unseen backgrounds/objects is weak; GR-1 easily selects the wrong object among unseen objects. When comparing w/o part. ann. data, the authors attribute the improvement to additional action-labeled videos improving language semantic understanding and OOD robustness.
5.6 Few-shot Novel Skills
| method | 10-shot | 30-shot |
|---|---|---|
| OpenVLA | 0.0% | 2.5% |
| Octo | 0.0% | 0.0% |
| GR-1 | 2.5% | 22.5% |
| GR-MG w/o part. ann. data | 10.0% | 27.5% |
| GR-MG | 17.5% | 37.5% |
An important observation in the few-shot part is that the target map generator can generate more accurate target maps after finetuning with few samples, but policy is still the main bottleneck. This observation corresponds to the future work in the conclusion, which is to further expand the real-world text-free trajectory training of the policy.
6. Repeat audit
6.1 Code and resources
Already published: The official GitHub is bytedance/GR-MG. The README provides the installation script, training script and CALVIN evaluation script of the goal image generation model and multi-modal goal-conditioned policy, and provides policy checkpoint, goal generation checkpoint, InstructPix2Pix, MAE and CALVIN data download entrances.
Heavy dependence: The official README indicates that the test environment is CUDA 12.1 + Python 3.9; goal generation and policy dependencies are installed separately. reproducibility requires not only CALVIN, but also Ego4D pretraining checkpoint or self-pretraining.
6.2 Key hyperparameters
| Project | Goal Image Generation Model | Multi-modal Goal-Conditioned Policy |
|---|---|---|
| batch size | 1024 | 512 |
| learning rate | 8e-5 | 1e-3 |
| optimizer | AdamW | AdamW |
| weight decay | 1e-2 | 0 |
| Adam beta1 / beta2 | 0.95 / 0.999 | 0.9 / 0.999 |
| epochs | 50 | 50 |
Appendix Training: The generator is trained on 16 NVIDIA A100 80GB for 50 epochs, CALVIN is about 18 hours, and the real robot is about 30 hours; the policy is trained on 32 NVIDIA A800 40GB for 50 epochs, CALVIN is about 17 hours, and the real robot is about 7 hours. Generator training using CenterCrop, ColorJitter, EMA is critical for stable performance.
6.3 reproducibility path
- Prepare the official environment: install separately
goal_gen/install.shwithpolicy/install.shRequired dependencies. - Download InstructPix2Pix weights to
resources/IP2P/, download the MAE encoder toresources/MAE/, prepare CALVIN data. - Training target graph generator: modifications
goal_gen/config/train.jsonrun afterbash ./goal_gen/train_ip2p.sh ./goal_gen/config/train.json. - Policy pre-training: You can use the Ego4D-pretrained checkpoint provided by the author, or
bash ./policy/main.sh ./policy/config/pretrain.jsonPre-train on your own. - Training policy: settings
/policy/config/train.jsonpretrained model path in, runbash ./policy/main.sh ./policy/config/train.json. - CALVIN evaluation: run
bash ./evaluate/eval.sh ./policy/config/train.json, and specify goal generation model and policy checkpoint in the script.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Judging from the experimental design of the paper itself, the value is concentrated in "connecting data with two different missing labels to different modules respectively." Videos lacking action labels are not suitable for direct supervision of actions, but are suitable for training "current picture + language + progress → future goal picture"; robot trajectories lacking text labels are not suitable for training language understanding, but are suitable for training goal image conditioned policy on how to convert visual goals into actions. This division of module labor makes the usage path of partially-annotated data clearer.
7.2 Why the results hold up
The paper does not only give a single main table, but uses multiple sets of corresponding evidence to support the core design: the CALVIN main table verifies the long-horizon improvement of the complete GR-MG; w/o text, w/o image verifies the bimodal condition; w/o progress and the target graph similarity index verify the progress condition; 10% data scarcity verifies that the textless robot trajectory is useful for policy; the real robot w/o part. ann. data and the generated graph visualize the missing action label video for the generator and OOD Goal understanding helps. The few-shot part also points out that policy is the bottleneck, which is consistent with the expansion direction in the conclusion.
7.3 Limitations and future directions described by the author
- The two modules are currently trained independently: the generator uses timestep to obtain progress and ground-truth future frames, and the policy uses ground-truth goal image; the author leaves joint training as future work.
- Among the few-shot novel skills, the target graph generator can generate accurate target graphs, but the policy is still difficult to implement. The authors plan to expand the policy training with more real-world data w/o text labels.
- The conclusion also proposes to expand the partially-annotated data training scale of the two modules and consider introducing depth information to improve action prediction accuracy.
7.4 Applicable boundaries
GR-MG is suitable for operational tasks that can express intermediate goal states visually, and assumes that the generator can regularly generate sub-goal images useful for policy. The paper does not provide sufficient coverage for tasks where the goal cannot be expressed by a single RGB sub-goal, depth/contact information is critical, or the policy has extremely high requirements on real execution dynamics. Although the real robot experiments include non-pick-and-place tasks and multiple types of OOD settings, they are still verified within the author's own platform, camera configuration, and task set.