Latent Action Pretraining From Videos
1. Quick overview of the paper
| What should the paper solve? | Existing VLA pre-training usually relies on robot action labels, which require human teleoperation to collect and are difficult to scale. Internet videos and human-operated videos are huge, but there are no robot action labels, and the distribution is different from the robot embodiment/environment. What the paper wants to solve is: how to learn action priors useful for robot strategies from videos without using ground-truth robot action labels. |
|---|---|
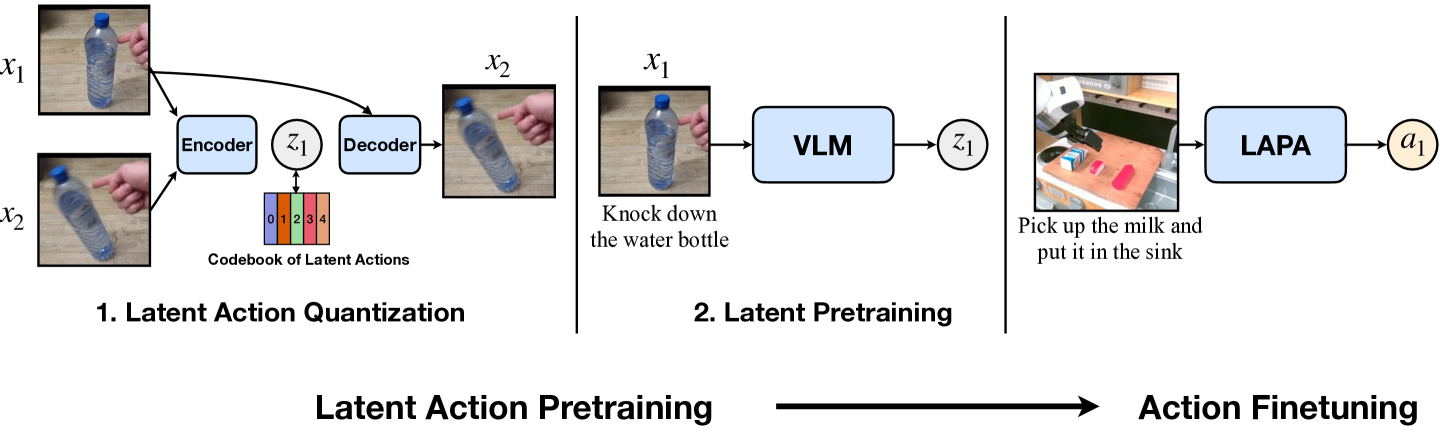
| The author's approach | The gripper "tokenizes" the action. The first stage trains a VQ-VAE style latent action quantization model to learn the discrete latent action \(z_t\) from the current frame \(x_t\) and the future frame \(x_{t+H}\). The second stage uses these \(z_t\) as pseudo labels to let VLM predict latent actions based on current observations and language instructions. In the third stage, only small-scale action-labeled robot trajectories are used for action finetuning, and latent actions are migrated to real 7-DoF end-effector delta actions. |
| most important results | In real desktop operations, the total success rate of LAPA (Open-X) is 50.09%, which is higher than the 43.87% of OpenVLA (Open-X). The paper summarizes the improvement as +6.22% relative to OpenVLA; at the same time, LAPA pre-training only uses 8×H100 for 34 hours of training, about 272 H100-hours, while OpenVLA is about 21, 500 A100-hours. LAPA also shows that pre-training using only Something-Something V2 human operation videos can also achieve positive transfer, and the average performance on real robots exceeds OpenVLA (Bridge). |
| Things to note when reading | The focus is not on "pre-training VLA with video" itself, but on whether the latent action truly becomes a shared action representation across embodiments and environments. When reading, you should keep an eye on three things: whether the tokens learned by the quantitative model are semantically interpretable; whether latent pretraining is more stable than baselines without action labels such as VPT/UniPi; and finally, whether a small amount of action finetuning is enough to fill the gap from latent action to real robot action, especially fine-grained grasping. |
Contribution in one sentence
LAPA uses discrete latent actions to turn videos without action labels into action pseudo-labels that can be trained on VLA, thus integrating Internet/human videos into robot strategy pre-training.
keywords
Vision-Language-Action Latent Action VQ-VAE Actionless Video Pretraining Cross-Embodiment Transfer
2. Research questions and motivations
2.1 Why action labels are the bottleneck of VLA
VLA models usually connect the VLM with the action head and are trained on real robot trajectories. The problem is that robot action labels come from remote operations, which have high acquisition costs, strong hardware dependence, and limited data scale. Models such as OpenVLA have proven the value of action-labeled robot data, but they are still limited by the data source "must have robot actions".
In contrast, Internet videos and videos of human actions contain a large number of physical interactions and task behaviors. They do not have robot end-effector action, joint position, or torque tags, and the embodiment is different from robots. The basic judgment of LAPA is: if discrete action tokens can be learned from pure visual changes, these videos can be turned into VLA pre-training data.
2.2 Why not just create world model or IDM directly?
The video world model route can generate future frames, and then use the inverse dynamics model to rotate the action, but the paper believes that this method is susceptible to diffusion planning and IDM errors in long horizon and precise 7-DoF actions. The VPT route relies on action-labeled data to train IDM, and then pseudo-labels the video; this makes IDM unstable across environments. The difference between LAPA is that latent action quantization does not require real action labels and directly learns discrete action representations from the changes between two visual states.
2.3 The core hypothesis of the paper
The core assumption is that visible state changes in different embodiments and environments can be expressed through a shared latent action space. This space is not necessarily equivalent to real robot movements, but it is enough to carry coarse-grained behavioral priors such as "visual changes related to left, downward, approaching, and grabbing". Subsequently, a small amount of labeled robot data is used to align this prior to the action space of the specific robot.
4. Detailed explanation of method
4.1 Overall process
Latent Action Pretraining consists of two sequentially learned models and a fine-tuning stage:
- Latent Action Quantization. Train an encoder-decoder to learn the discrete latent action \(z_t\) using \(x_t\) and \(x_{t+H}\).
- Latent Pretraining. Use the quantized model encoder to give latent action pseudo-labels to videos without action labels, and train VLM to predict \(z_t\) from the current image and language instructions.
- Action Finetuning. Throw away the latent action head, replace it with a real action head, and learn an executable end-effector delta action with a small number of robot action labels.
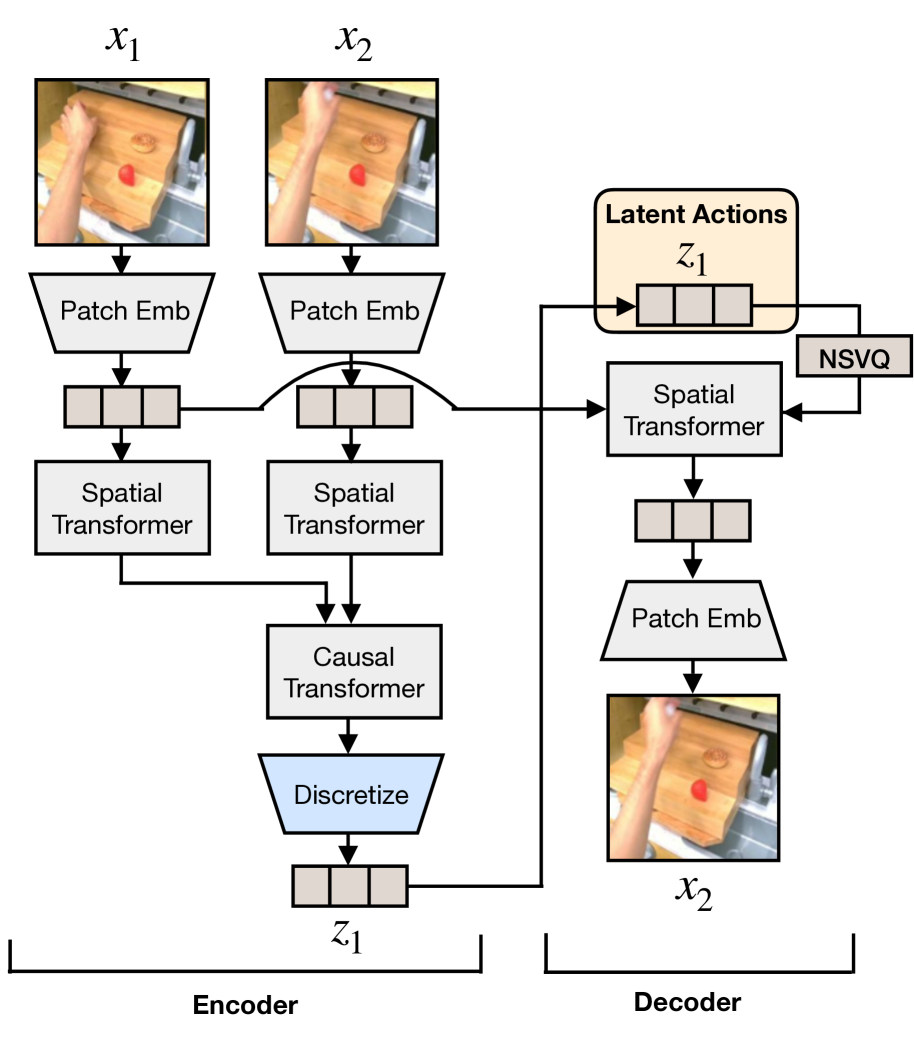
4.2 Latent Action Quantization
The quantization model inputs the current frame \(x_t\) and the future frame \(x_{t+H}\), and outputs latent action \(z_t\). The Encoder looks at two frames at the same time and uses spatial transformer and temporal/causal transformer to obtain continuous embedding; the Decoder inputs \(x_t\) and \(z_t\) and reconstructs \(x_{t+H}\). Intuitively, \(z_t\) is forced to encode an "action change" from a current observation to a future observation.
The paper is based on the VQ-VAE objective and discretizes continuous differential embedding into the codebook. Appendix A gives a more specific form: two frames of patch embedding, then spatial transformer, and then causal transformer to get \(e_1, e_2\), let \(d_1=e_2-e_1\), and select the nearest codebook token:
In order to avoid the common codebook / representation collapse in VQ-VAE, the author uses NSVQ and applies stop gradient to the current frame patch embedding \(p_1\) in the decoder. Decoder uses cross attention to let the quantized action represent the attend current frame:
The paper also shows that it is easier to capture semantically meaningful latent actions using cross attention empirically than with GENIE-style additive embedding.
4.3 Latent Pretraining
After training the quantized model, use its encoder as the inverse dynamics model: given \(x_t\) and future frames, mark the latent action \(z_t\). Then train the pre-trained VLM, input the current image \(x_t\) and video language instructions, and predict \(z_t\). Here a separate latent action head, an MLP, is used to output the token distribution on the codebook vocabulary \(|C|\).
In the default training settings, the vision encoder is frozen and the language model is unfrozen. This design allows pre-training to not rely on any robot action labels, nor does it require preset action granularity, such as end-effector position, joint position or torque; the action granularity is determined by the observed changes themselves.
4.4 Action Finetuning
The latent action is not a directly executable robot action, so in the end a small number of labeled trajectories are needed. The author discretizes each dimension of the continuous robot action into equal-frequency bins to perform action token prediction similar to RT-2/OpenVLA. During fine-tuning, the latent action head is discarded and the real action head is re-initialized; the vision encoder is still frozen and the language model is unfrozen.
The author also tried to retain the latent action head and add additional heads to decode the real action, but the effect was not as good as reinitializing the action head. The paper speculates that the reason may be that the underlying policy model is very large, and it is easier to directly fine-tune the new action head to adapt to the real robot action space.
5. Experiments and results
5.1 Experimental setup
The paper was evaluated on 2 simulation environments and 3 real robot tasks, covering a total of 9 types of tasks. Core questions include: whether cross-task, cross-environment, and cross-embodiment transfer; whether LAPA is more suitable for multiple embodiments than ground-truth action pretraining; whether using only human manipulation videos is also effective.
| environment | Category | Pre-training data | Pre-trained trajectories | Fine-tuning data | Fine-tune the trajectory |
|---|---|---|---|---|---|
| LangTable | In-domain | Sim 5 tasks | 181k | 5 tasks, MT/MI | 1k |
| LangTable | Cross-task | Sim 5 tasks | 181k | 1 task, MI | 7k |
| LangTable | Cross-env | Real 5 tasks | 442k | 5 tasks, MT/MI | 1k |
| SIMPLER | In-domain | Bridgev2 | 60k | 4 tasks, MT | 100 |
| SIMPLER | Cross-emb | Something v2 | 200k | 4 tasks, MT | 100 |
| Real-world | Cross-emb | Bridgev2 | 60k | 3 tasks, MI | 450 |
| Real-world | Multi-emb | Open-X | 970k | 3 tasks, MI | 450 |
| Real-world | Cross-emb | Something v2 | 200k | 3 tasks, MI | 450 |



5.2 Baselines
The underlying VLM uses the 7B Large World Model (LWM-Chat-1M). The main baselines include: SCRATCH, which is only fine-tuned on downstream tasks; UNIPI, which uses a video diffusion model to generate video rollouts and then uses IDM to convert actions; VPT, which uses action-labeled data to train IDM and then gives pseudo actions to the original video; ACTIONVLA, which is pre-trained with ground-truth robot action labels and can be regarded as having a label upper bound; OpenVLA, which currently has a 7B VLA baseline.
[Appendix C] The UNIPI diffusion model is trained with batch 128, and is re-planned every two steps during inference; VPT's IDM is ResNet18 + MLP, trained on a single A6000 with Adam and learning rate \(10^{-4}\); OpenVLA fine-tuning defaults to LoRA, batch size 32, until the action accuracy reaches 95%. ACTIONVLA and LAPA use batch size 128 and use image augmentation when fine-tuning the real robot.
5.3 Language Table results
| method | In-domain Seen | In-domain Unseen | Cross-task Seen | Cross-task Unseen | Cross-env Seen | Cross-env Unseen |
|---|---|---|---|---|---|---|
| SCRATCH | 15.6 ± 9.2 | 15.2 ± 8.3 | 27.2 ± 13.6 | 22.4 ± 11.0 | 15.6 ± 9.2 | 15.2 ± 8.3 |
| UNIPI | 22.0 ± 12.5 | 13.2 ± 7.7 | 20.8 ± 12.0 | 16.0 ± 9.1 | 13.6 ± 8.6 | 12.0 ± 7.5 |
| VPT | 44.0 ± 7.5 | 32.8 ± 4.6 | 72.0 ± 6.8 | 60.8 ± 6.6 | 18.0 ± 7.7 | 18.4 ± 9.7 |
| LAPA | 62.0 ± 8.7 | 49.6 ± 9.5 | 73.2 ± 6.8 | 54.8 ± 9.1 | 33.6 ± 12.7 | 29.6 ± 12.0 |
| ACTIONVLA | 77.0 ± 3.5 | 58.8 ± 6.6 | 77.0 ± 3.5 | 58.8 ± 6.6 | 64.8 ± 5.2 | 54.0 ± 7.0 |
Reading of this table: LAPA does not use action labels for pre-training, but it significantly exceeds SCRATCH, UNIPI and VPT. The advantages are obvious in in-domain and cross-env; VPT is slightly higher in cross-task unseen. The author explains that VPT uses more labeled data to train IDM, and the pseudo labels may be more accurate. ACTIONVLA is pre-trained with real action labels, so it is still a strong upper bound, especially cross-env.
5.4 Real robot results
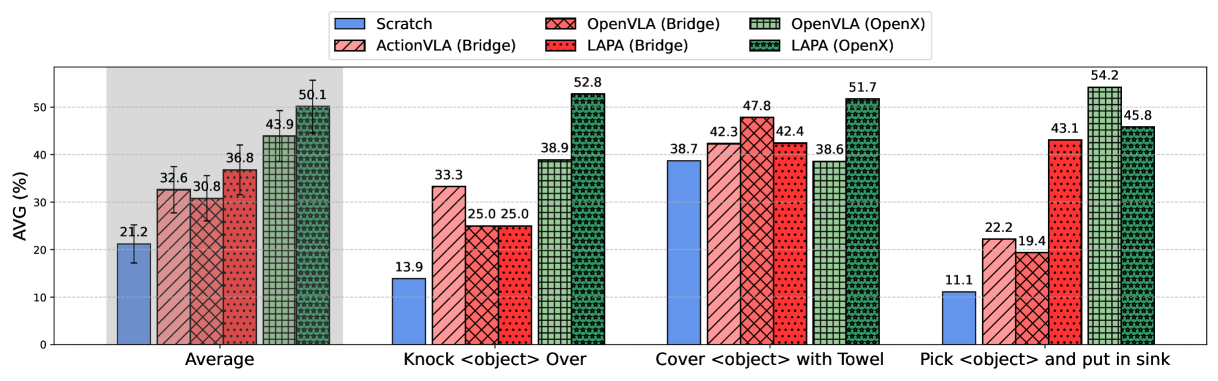
| method | Seen Obj. Unseen Combo | Unseen Obj. | Seen Obj. Unseen Instr. | AVG |
|---|---|---|---|---|
| SCRATCH | 18.0 | 20.3 | 25.4 | 21.2 |
| ACTIONVLA (Bridge) | 38.3 | 31.8 | 27.7 | 32.6 |
| OPENVLA (Bridge) | 35.6 | 34.6 | 22.1 | 30.8 |
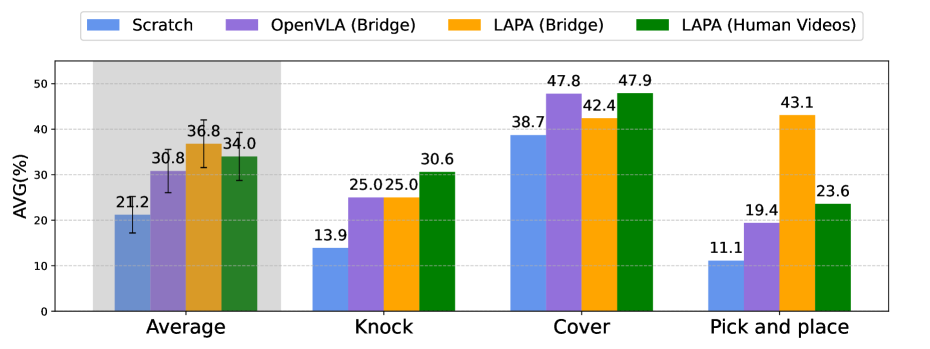
| LAPA (Bridge) | 43.4 | 31.4 | 35.6 | 36.8 |
| OPENVLA (Open-X) | 46.2 | 42.1 | 43.4 | 43.9 |
| LAPA (Open-X) | 57.8 | 43.9 | 48.5 | 50.1 |
| LAPA (Human Videos) | 36.5 | 37.4 | 28.1 | 34.0 |
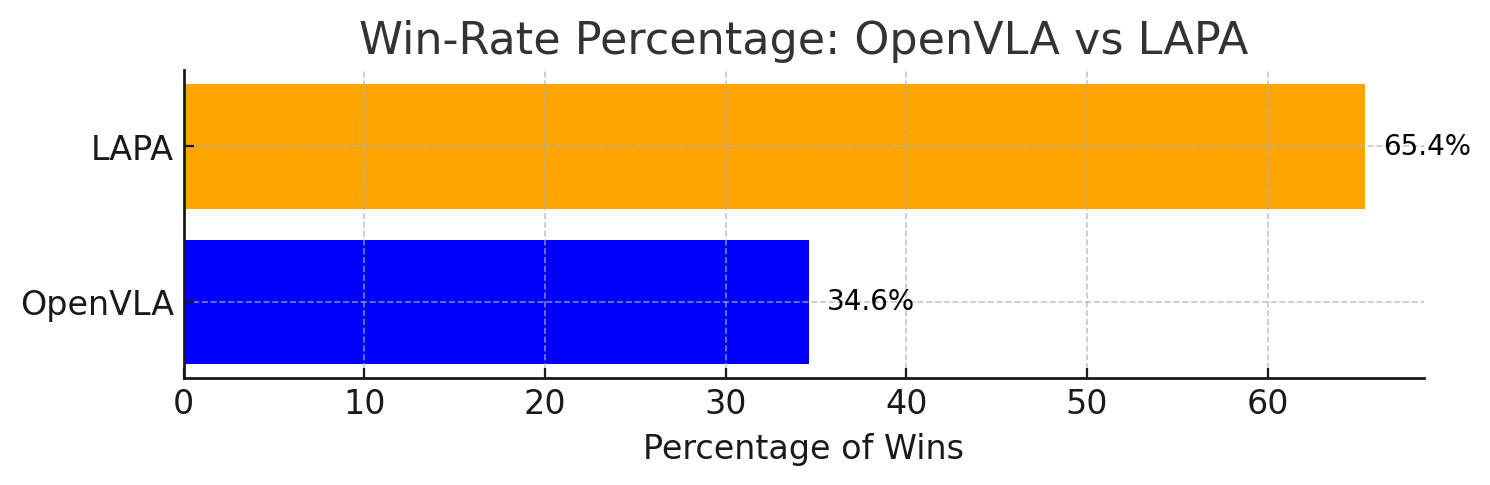
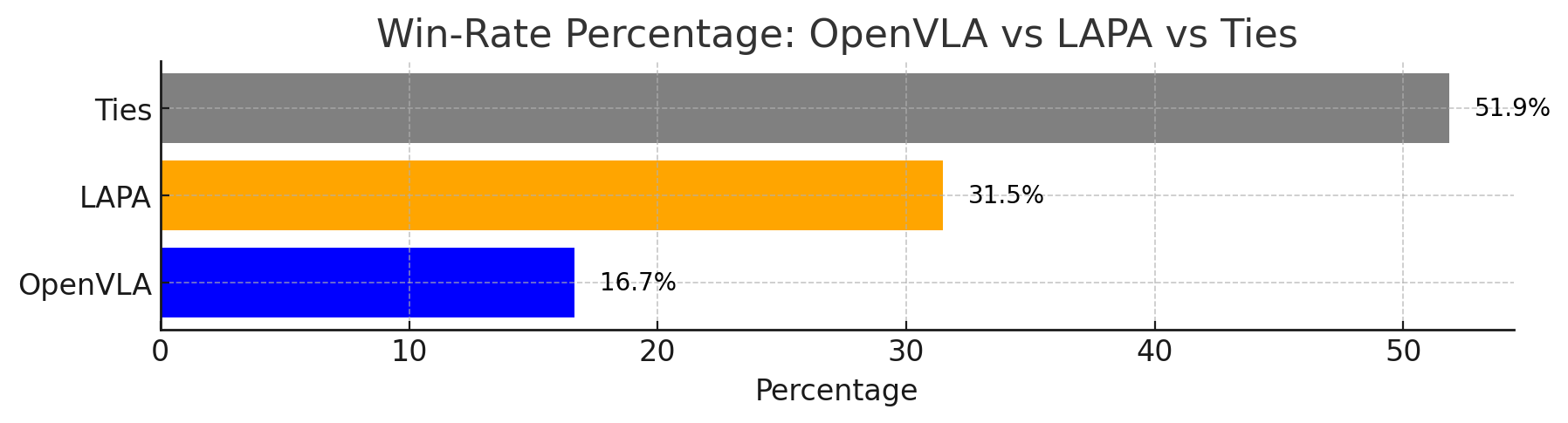
The most critical comparison is LAPA(Open-X) vs OpenVLA(Open-X): LAPA is higher on all three generalization settings, AVG 50.1 vs 43.9. The summary table in Appendix G.3 gives a more precise total success rate of 50.09% vs 43.87%. The author also pointed out that LAPA is inferior to OpenVLA in pick-and-place, and the main failure comes from early grasping; however, LAPA's reaching success is higher than OpenVLA, indicating that its language conditions and coarse-grained planning are stronger, and fine-grained grasping still needs to be improved.

5.5 Human manipulation videos
The authors test the extreme embodiment gap using 220k human operation videos from Something-Something V2. Because human videos do not have robot action labels, ACTIONVLA is not trainable; LAPA can still learn latent actions from visual changes.
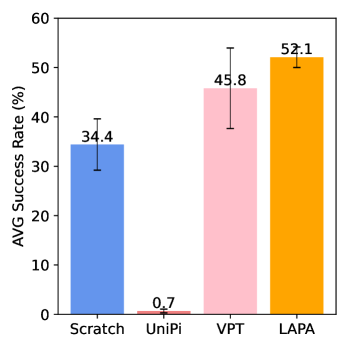
[Appendix G.2] In the SIMPLER human-video table, Success AVG: VPT 45.8, UNIPI 0.7, LAPA 52.1, LAPA(10%) 50.0; Moving AVG: VPT 66.6, UNIPI 27.1, LAPA 72.9, LAPA(10%) 62.5. This supports the claim that "human videos can also be positively migrated", but it also shows that 10% of the data is already very close to complete data, and a more systematic scaling law is needed in the future.
5.6 SIMPLER and efficiency
[Appendix G.2] The SIMPLER table of Bridgev2 pretraining shows that Success AVG: SCRATCH 34.4, UNIPI 1.3, VPT 51.0, LAPA 57.3, ACTIONVLA 63.5, OpenVLA 36.4. LAPA significantly outperforms the baseline without action labels and is close to ACTIONVLA using full Bridgev2 action labels.
In terms of efficiency, LAPA (Open-X) uses 8 H100s to train for 34 hours, batch size 128, totaling about 272 H100-hours; OpenVLA requires about 21, 500 A100-hours, batch size 2048. Based on this, the author believes that LAPA pre-training is about 30-40 times more efficient, while the real robot results are still better than OpenVLA.
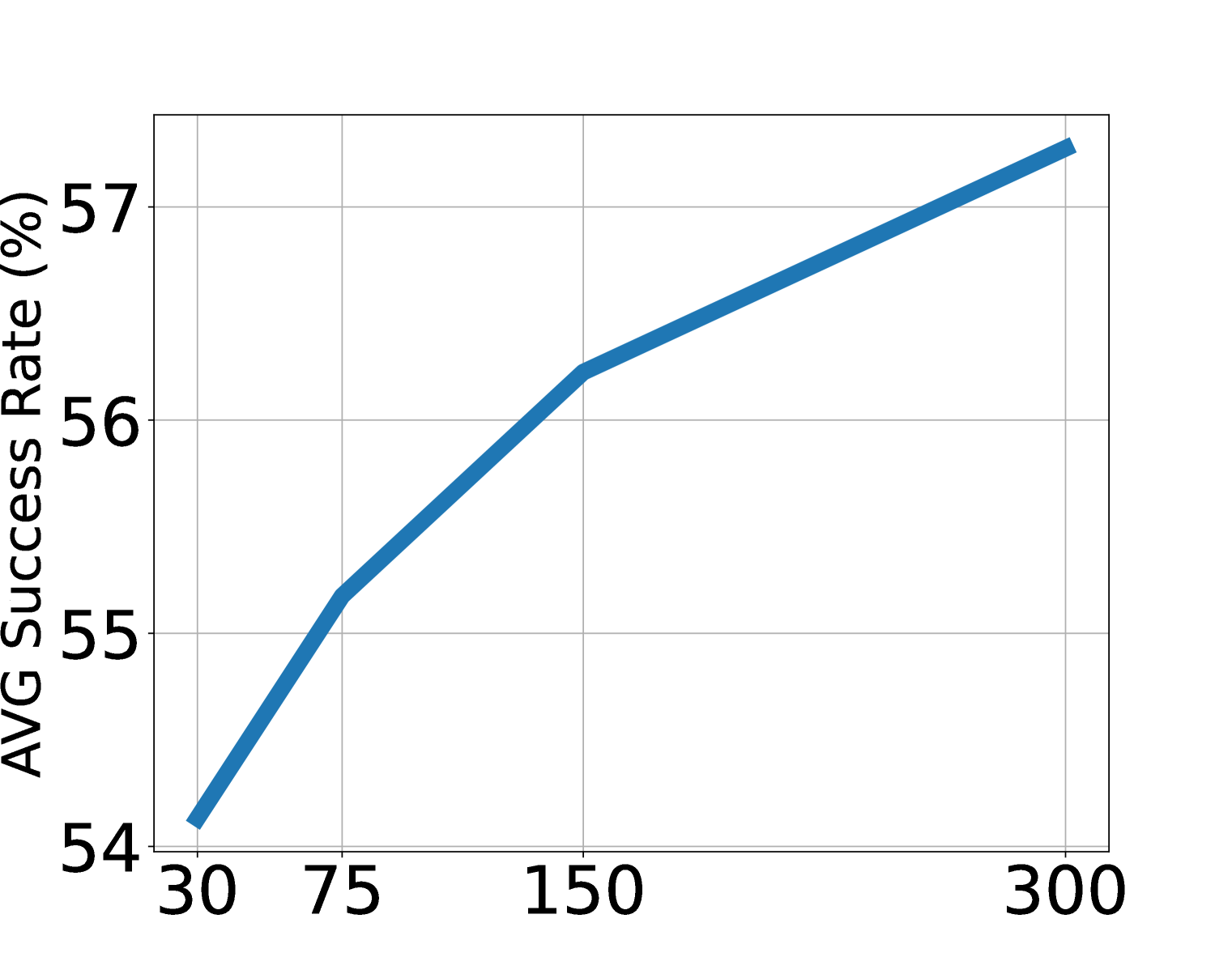
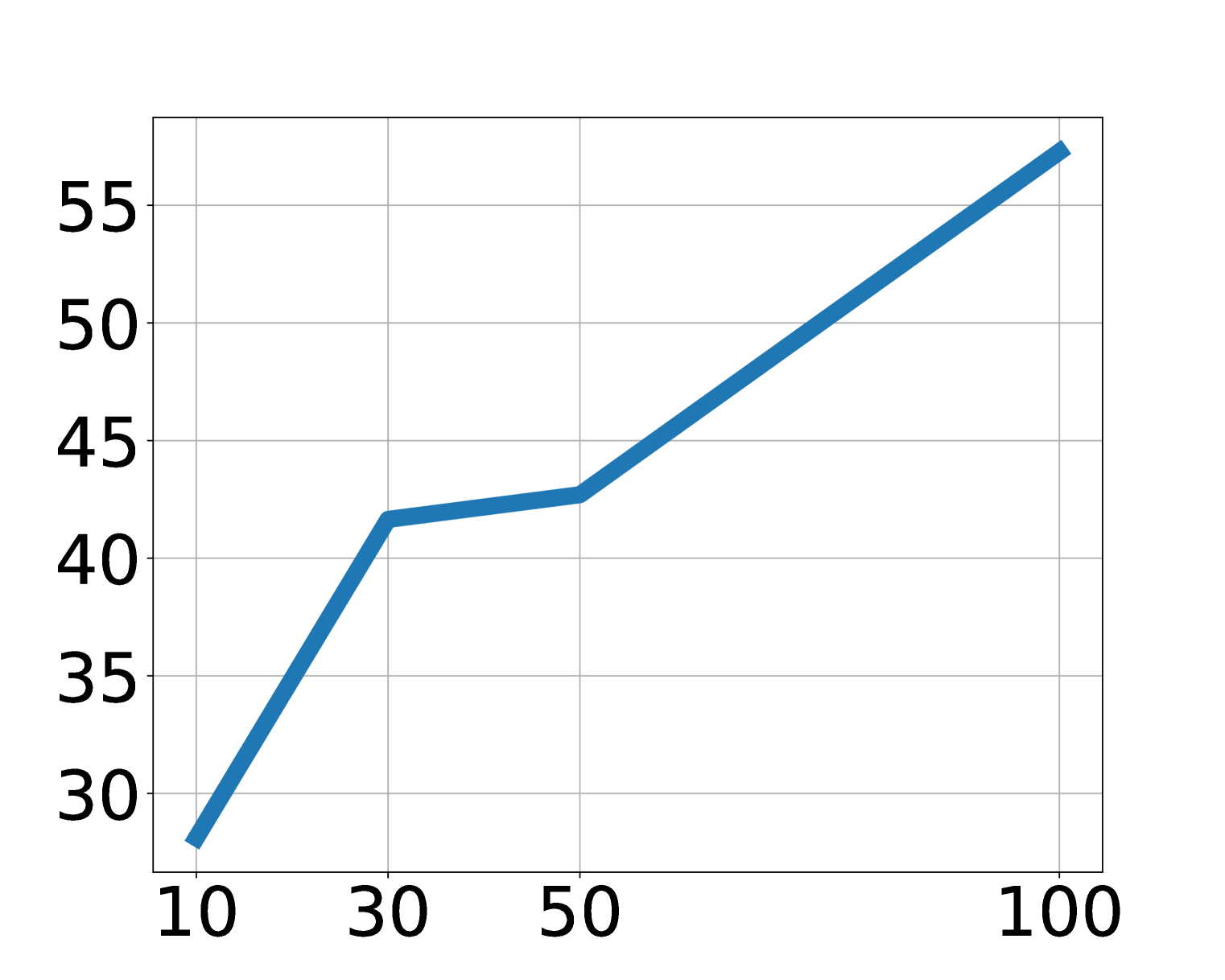
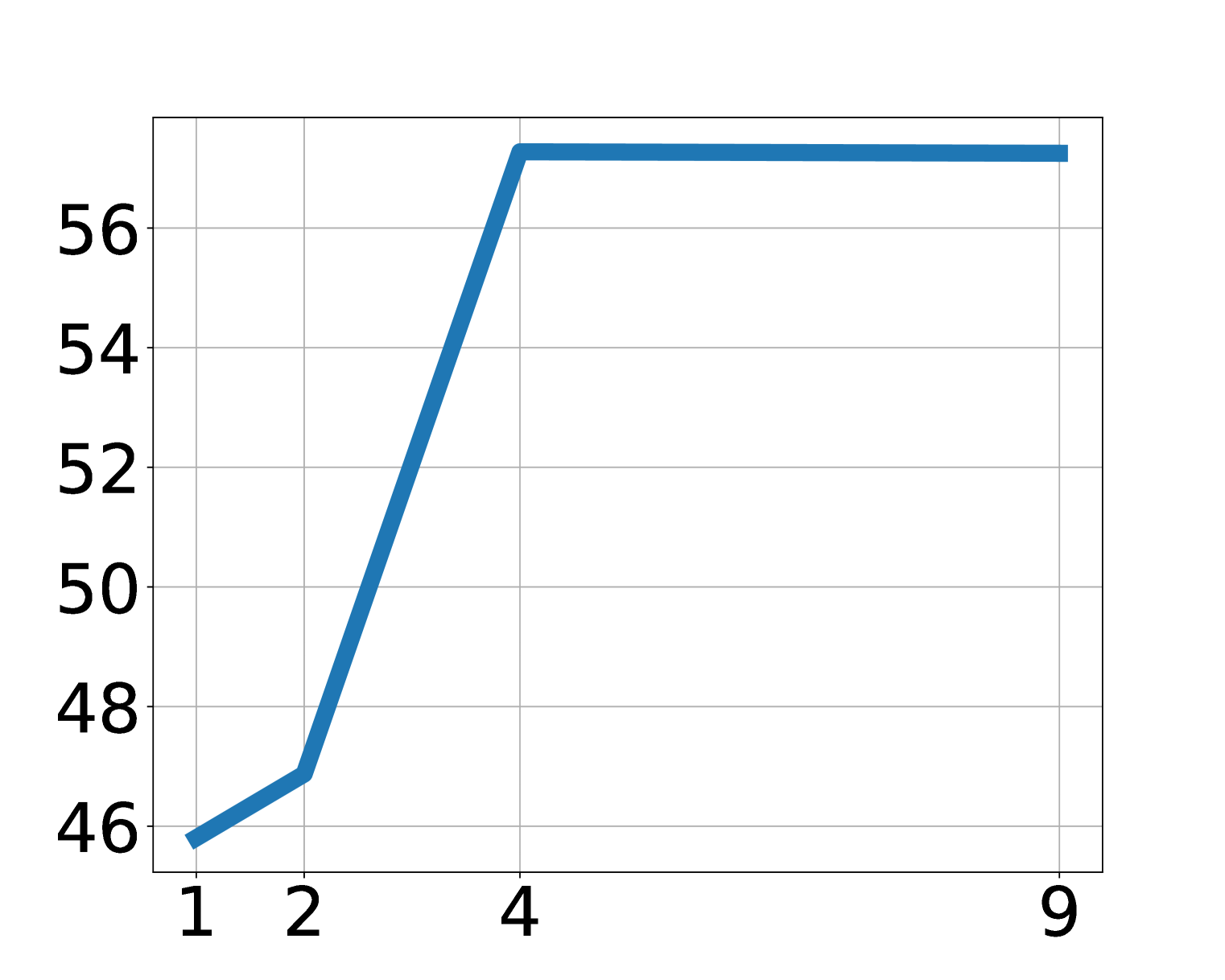
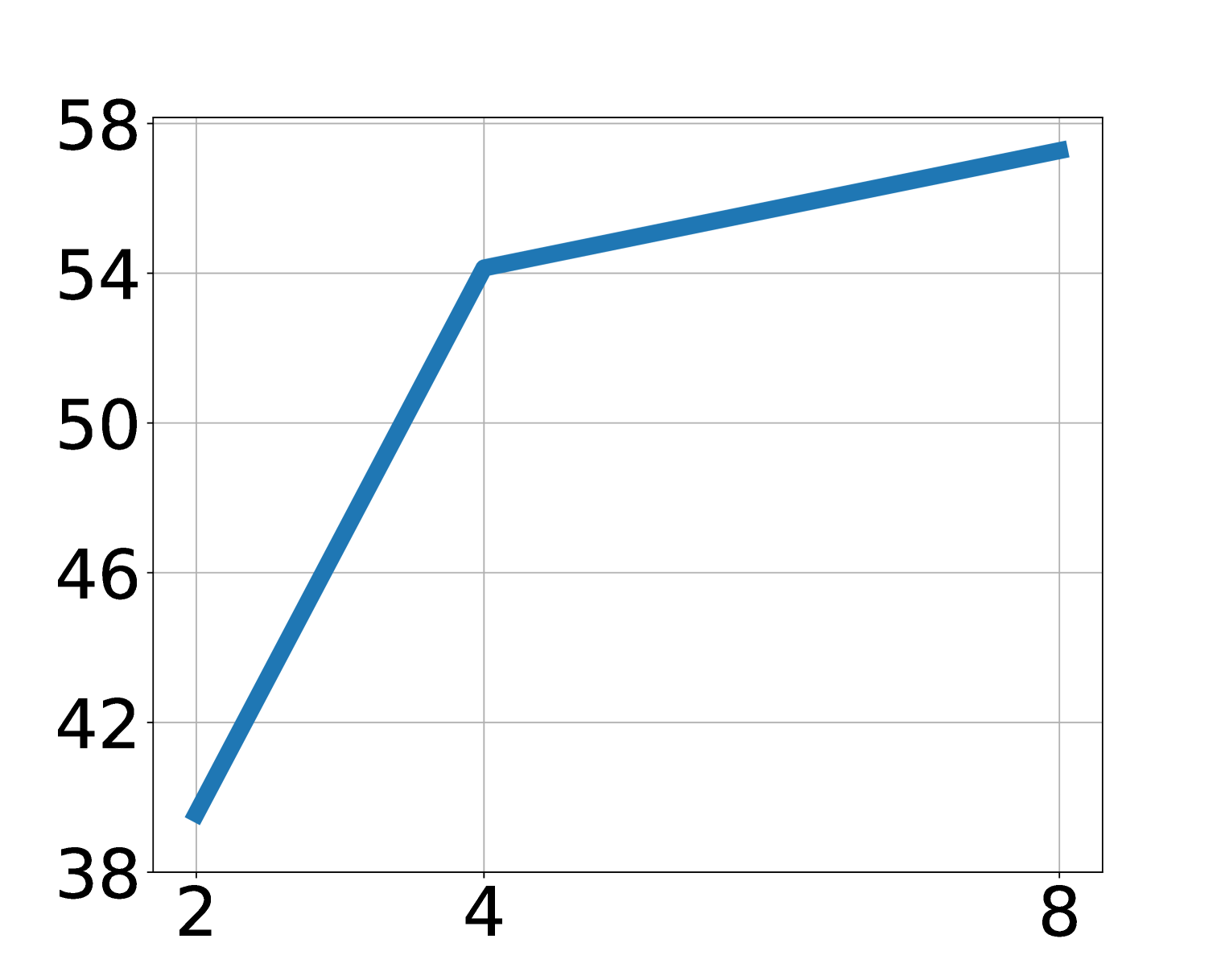
5.7 Scaling and latent action analysis
Ablation shows that LAPA improves with increasing model size, data volume, and latent action space. The paper points out that in the main experiment, except for the Language Table, the generation space of LAPA is maintained at \(8^4\). For a visually simple Language Table, increasing vocabulary is more effective than increasing sequence length; for more complex operations, both sequence length and vocab may need to be expanded with the action dimension.


5.8 Appendix Supplementary Charts
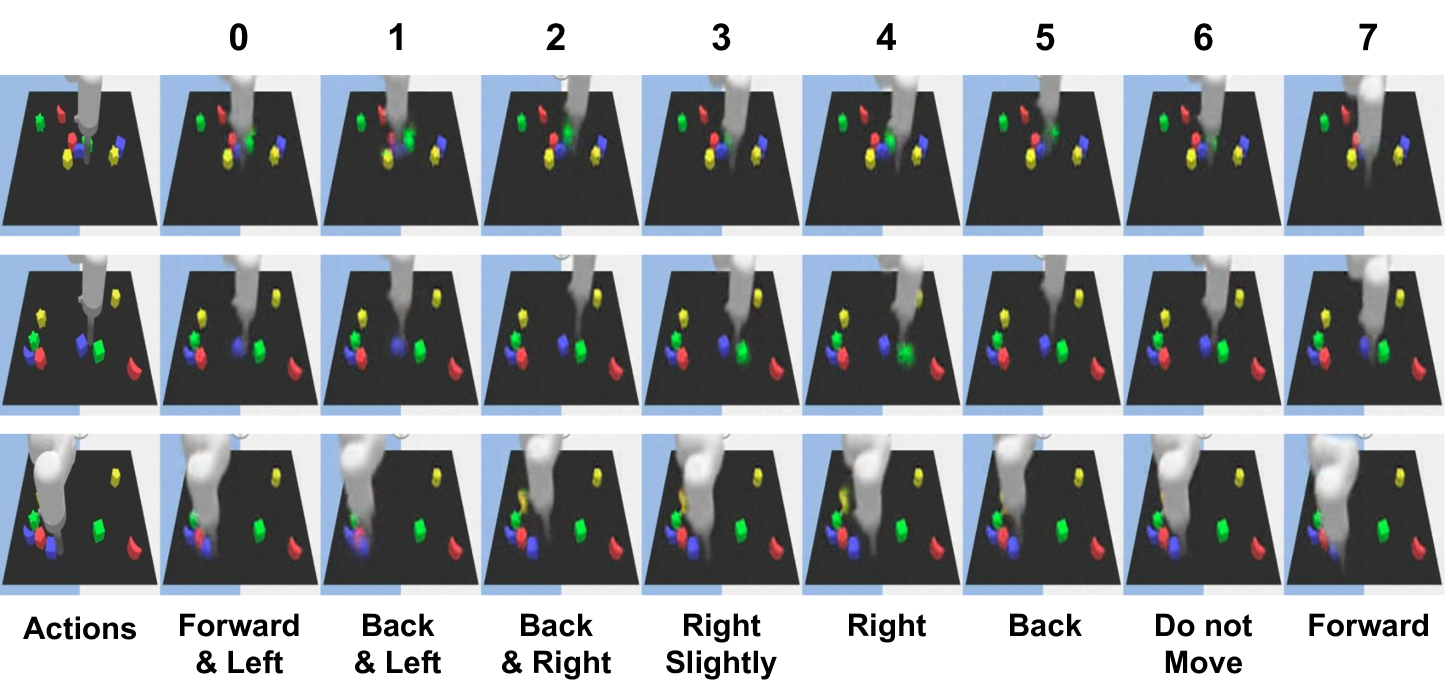



6. reproducibility Key Points
6.1 Latent action quantization
[Appendix A] The quantitative model uses a C-ViViT style architecture to reproduce GENIE's latent action model. Input two frames of \(x_1, x_2\), obtain \(e_1, e_2\) through patch embedding, spatial transformer, and causal transformer, and then perform codebook nearest neighbor quantization on \(d_1=e_2-e_1\). The decoder only contains the spatial transformer and uses cross attention and stop-gradient embedding of the current frame to reconstruct future frames.
Window size \(H\) is set according to video fps: robot operation videos default to future frames about 0.6 seconds after the current frame; human manipulation videos are set to about 2.4 seconds due to slower inter-frame dynamics. Appendix F shows the default \(H=3\) on Bridgev2, and the performance decreases if the window is too large.
6.2 Pretraining / finetuning configuration
- Backbone: 7B LWM-Chat-1M.
- Latent pretraining: Freeze the vision encoder, unfreeze the language model, and add latent action MLP head.
- Action finetuning: Discard the latent head and re-initialize the action head; each dimension of the continuous action is discretized according to equal frequency bins.
- LAPA(Open-X) pre-training: 8×H100, 34 hours, batch size 128, about 272 H100-hours.
- OpenVLA comparison: About 21, 500 A100-hours, batch size 2048.
- Real robot fine-tuning: ACTIONVLA and LAPA use batch size 128 and use image augmentation.
6.3 Evaluation protocol
[Appendix B] Language Table evaluates 50 rollouts per subtask category, for a total of 250 rollouts/model/table across 5 categories of tasks. SIMPLER evaluates 24 rollouts per task, randomizing initial object positions. The real robot has 3 categories of evaluation capabilities for each task: seen objects unseen combinations, unseen objects, and seen objects unseen instructions; 6 rollouts per category, totaling 54 rollouts/model for the 3 tasks.
The real robot part uses partial success: knocking reaches the correct object and gives 0.5, knocking down gives 1; covering picks up the towel 0.33, contact/partial coverage 0.66, complete coverage 1; pick-and-place reaches 0.25, grabs 0.5, moves to the sink direction 0.75, and puts into the sink 1.
6.4 Recurrence risk list
- arXiv source code restrictions: This local source code package has only one PDF image source, and the report images are mainly downloaded from the arXiv HTML rendering; it is recommended to cross-check with PDF/HTML when reproducing the charts.
- latent action space hyperparameters: Sequence length, vocab size, and window \(H\) will affect the action granularity; the optimal values are different in different environments.
- Human video annotation: LAPA requires video language instructions or descriptions; when web videos scale, video text quality will affect latent pretraining.
- Real robot variance: 54 rollouts/model is not large. The paper uses pairwise win rate to supplement statistics. However, the real robot evaluation may still be affected by the initial position, object attributes, and grasp difficulty.
- Fine-grained actions: Grasping is the main shortcoming of LAPA. A small amount of finetuning data may not be enough to learn grasping related to the physical properties of objects.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
The most valuable part is turning "videos without action labels" into action pre-training signals that can be consumed by VLA. Rather than just learning visual representations or generating future videos, LAPA explicitly learns discrete latent action tokens and connects them to the action prediction training goal of monolithic VLA. This makes it possible for Internet videos, human operation videos, and multi-embodiment robot videos to enter the same pre-training paradigm.
The second value point is that the evidence chain covers cross-task, cross-environment, cross-embodiment and human-to-robot scenarios. The paper not only compares the unlabeled pre-training baseline in Language Table / SIMPLER, but also compares it with OpenVLA on real robots, and analyzes the relationship between pre-training task distribution and downstream tasks. This makes the claim that "latent action is a shared action space" not just based on method intuition.
7.2 Why the results hold up
The results are relatively tenable, first of all because the baseline design is relatively targeted: SCRATCH measures no pre-training, UNIPI measures video generative planning, VPT measures IDM pseudo-labels, ACTIONVLA measures the upper bound of real action labels, and OpenVLA measures existing VLA. LAPA achieves stable improvements over multiple no-action label baselines and outperforms OpenVLA in real robot Open-X settings.
Secondly, the appendix adds a lot of decomposition evidence: Language Table detailed table for each type of task, SIMPLER success/grasping/moving decomposition, real robot three-type ability decomposition, pairwise win rate, latent action semantic visualization and scaling ablation. Together, these evidences suggest that improvements in LAPA are not a single-table coincidence, but result from interpretable latent action representations and data scale/action space expansion.
7.3 Clear limitations of the paper
- Insufficient fine-grained actions: LAPA is not as good as action-labeled pretraining in fine-grained motion generation such as grasping. The author believes that expanding the latent action generation space may be helpful.
- Real-time inference latency: Similar to other VLAs, LAPA also suffers from real-time inference latency issues. The author recommends using hierarchical architecture in the future to allow the small head to predict actions at high frequency.
- The scope of application is still narrow: Although latent action captures camera movements, the paper has not explored non-manipulation videos such as autonomous driving, navigation, and landscape videos.
7.4 Additional boundaries and questionable points
- latent action is not isomorphic to real control: It learns from visual changes, possibly mixing camera motion, object motion, and robot motion; this is useful for human videos, but can also make real-life motion decoding harder.
- A small amount of action finetuning is still not possible: LAPA reduces the dependence on action labels, but does not completely eliminate the need for real robot action data.
- Task distribution is important: Appendix D shows that Sthv2 has more knocking/covering related trajectories, and Bridgev2 has more pick-and-place; whether the pre-training data contains similar skills still strongly affects the downstream.
- The world model capability is still a qualitative demonstration: Figure 7 shows a latent decoder closed-loop rollout, but this is not yet a strict interactive physics simulation evaluation.
8. Preparation for group meeting Q&A
Q1: Both LAPA and VPT use pseudo action tags, what is the difference?
VPT first uses action-labeled data to train IDM, and then uses IDM to add pseudo actions to the video; therefore, IDM quality and environment migration are critical. LAPA's latent action quantization does not require real action labels and directly learns discrete tokens from the changes between two visual states, so it is more suitable for actionless videos and cross-embodiment data.
Q2: Can latent action be executed directly?
No. The latent action is a visual change token, not the end-effector delta action. LAPA must go through action finetuning, using a small number of trajectories with real action labels to map the pre-training prior to the specific robot action space.
Q3: Why might LAPA be more suitable for many embodiments than action-labeled pretraining?
Real action labels have different coordinates, joints, control frequencies and action spaces in different robots, and direct mixing may introduce representation mismatch. LAPA learns to observe changing latent tokens, which are shared across datasets more like language/image representations, and therefore have positive migration in Open-X multi-embodiment settings.
Q4: What is the strongest quantitative evidence in the paper?
The total success rate of real robots: LAPA (Open-X) 50.09%, OpenVLA (Open-X) 43.87%; at the same time, LAPA pre-training is about 272 H100-hours, OpenVLA is about 21, 500 A100-hours. This result supports both performance and efficiency claims.
Q5: What is the most questionable aspect?
Mainly fine-grained actions and real robot statistics. LAPA is still weaker than OpenVLA in pick-and-place grasping, indicating that the coarse-grained prior of latent action is not equal to precise control; the 54 rollouts/model of real robots are still limited, and more tasks and larger-scale real evaluations are needed to confirm generalization.