Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
1. 论文速览
| 导读项 | 这篇论文回答什么 | 读的时候重点看哪里 |
|---|---|---|
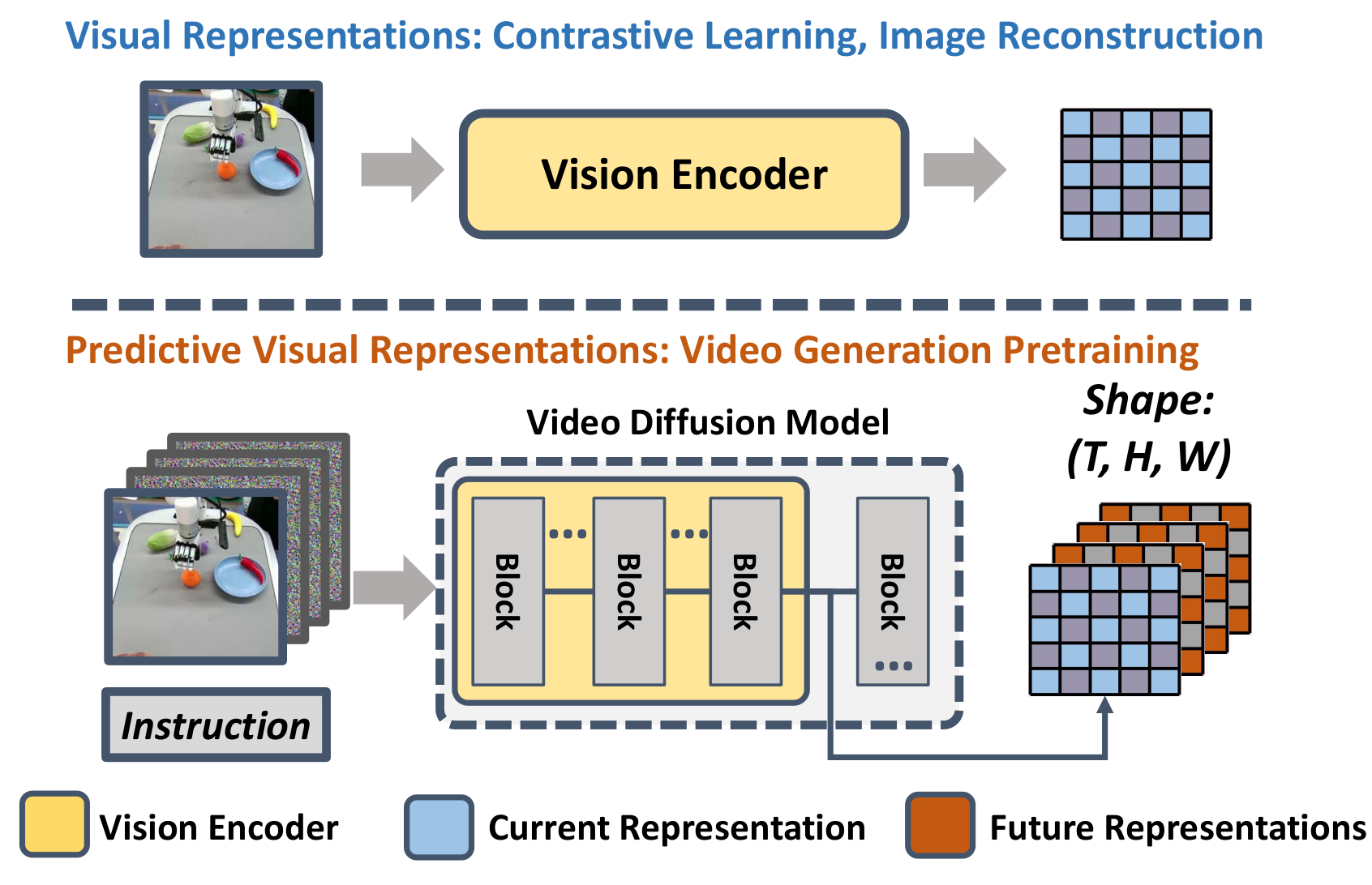
| 论文要解决什么 | 已有机器人 vision encoder 多从单图重建、双图对比或图文对比学静态信息,缺少显式未来动态;VPP 要把 video diffusion model 内部的未来预测表征转化为通用机器人策略的视觉条件。 | Introduction 的 predictive visual representations 假设,以及 Fig. 1 对当前/未来表征的对比。 |
| 作者的方法抓手 | 两阶段:先把 SVD 微调为 manipulation TVP,再把 TVP 一次前向中的多层特征聚合为 predictive representations,经 Video Former 输出 tokens,最后用 diffusion transformer policy 生成动作。 | Method 的 TVP objective、feature aggregation、Video Former spatial-temporal attention 和 diffusion action loss。 |
| 最重要的结果 | CALVIN ABC-D Avg. Len 达到 4.33;MetaWorld 50-task 平均成功率 0.682;Panda seen/unseen 为 0.85/0.73;XHand seen/unseen/tool-use 为 0.75/0.60/0.68。 | Table 1、MetaWorld 表、Table 6、附录 Panda/XHand 细分表和 ablation 表。 |
| 阅读时要注意的点 | VPP 不依赖完整 30-step 视频去噪来控制机器人,而是只用一次 TVP forward 的内部表征;这既是高频闭环控制的关键,也是和 SuSIE/Uni-Pi/GR-1 的主要差别。 | Policy roll-out details、Fig. 5 的 one-step representation、Video Former 和消融中的 latency 对比。 |
难度评级:★★★★☆。需要理解 video diffusion、Stable Video Diffusion 的 latent/upsampling features、Diffusion Policy/DiT 和多视角时空 attention。论文没有复杂定理,但方法实现链条长,组会时最容易被追问“为什么一次前向的粗糙未来表征足以指导动作”。
1.1 贡献清单
- 提出 predictive visual representations:作者认为 VDM 的内部 latent 同时包含当前帧和未来帧的信息,比只编码当前观测的视觉 encoder 更适合顺序控制。
- 构建 VPP 两阶段训练:第一阶段将 SVD 微调为 manipulation TVP;第二阶段训练 conditioned on TVP representations 的 generalist action policy。
- 高频闭环部署:不完整生成清晰视频,只取一次 forward 的表示,配合 Video Former 和 action chunking,在 RTX 4090 上达到 7-10 Hz。
- 跨仿真和真实平台验证:覆盖 CALVIN、MetaWorld、Franka Panda 和 XArm+XHand dexterous manipulation。
2. 动机与相关工作
2.1 为什么静态视觉表征不够
机器人策略需要从图像中理解“接下来世界会怎么变”。R3M、VIP、VC-1、Voltron 等视觉表征学习方法虽然可从视频或图文数据中学到语义和空间信息,但训练目标通常是单图重建、两图对比、MAE 或语言生成,模型输入输出并不显式要求预测连续未来。因此这些表征更偏向当前状态,而不是未来动力学。
2.2 为什么 video diffusion model 是合适候选
Video diffusion model 直接建模完整视频序列,text-guided video prediction model 还能基于当前观测和语言预测未来帧。作者的假设是:即使不把未来视频完整去噪到像素级清晰,VDM 内部的中间特征也已经包含物体和机器人将如何运动的粗粒度信息。VPP 将这些中间特征称为 predictive visual representations。
2.3 与未来预测控制方法的差别
SuSIE 先生成未来 goal image,再让 policy 追踪该图;Uni-Pi 在两帧之间学习 inverse dynamics;GR-1 自回归生成未来帧和动作。论文认为这些方法有两个不足:要么只用单个未来预测,无法覆盖复杂连续动态;要么需要完整去噪/自回归,控制频率低。VPP 的差异是直接使用 VDM 中间表征,而不是等待最终像素视频生成完成。
3. 预备知识
3.1 Video Diffusion Models
直观理解:
前向过程不断给真实视频 $x_0$ 加噪,直到接近高斯噪声。训练视频生成模型就是学习从 noisy video 逐步恢复 clean video 的反向过程。
在 text-guided video generation 中,模型还以初始帧和语言 prompt 为条件学习 $\epsilon_\theta(x_t,c)$。VPP 后续把这种条件视频预测模型当作视觉 encoder。
3.2 Diffusion Policy
Diffusion policy 将动作序列 $a_i=(\hat{a}_i,\ldots,\hat{a}_{i+m})$ 也看作可去噪对象。相比单峰回归,diffusion policy 可以表达多模态动作分布。VPP 在 action head 中采用 diffusion transformer block,并把 Video Former 输出的预测视觉 tokens 作为 cross-attention 条件。
4. 方法详解
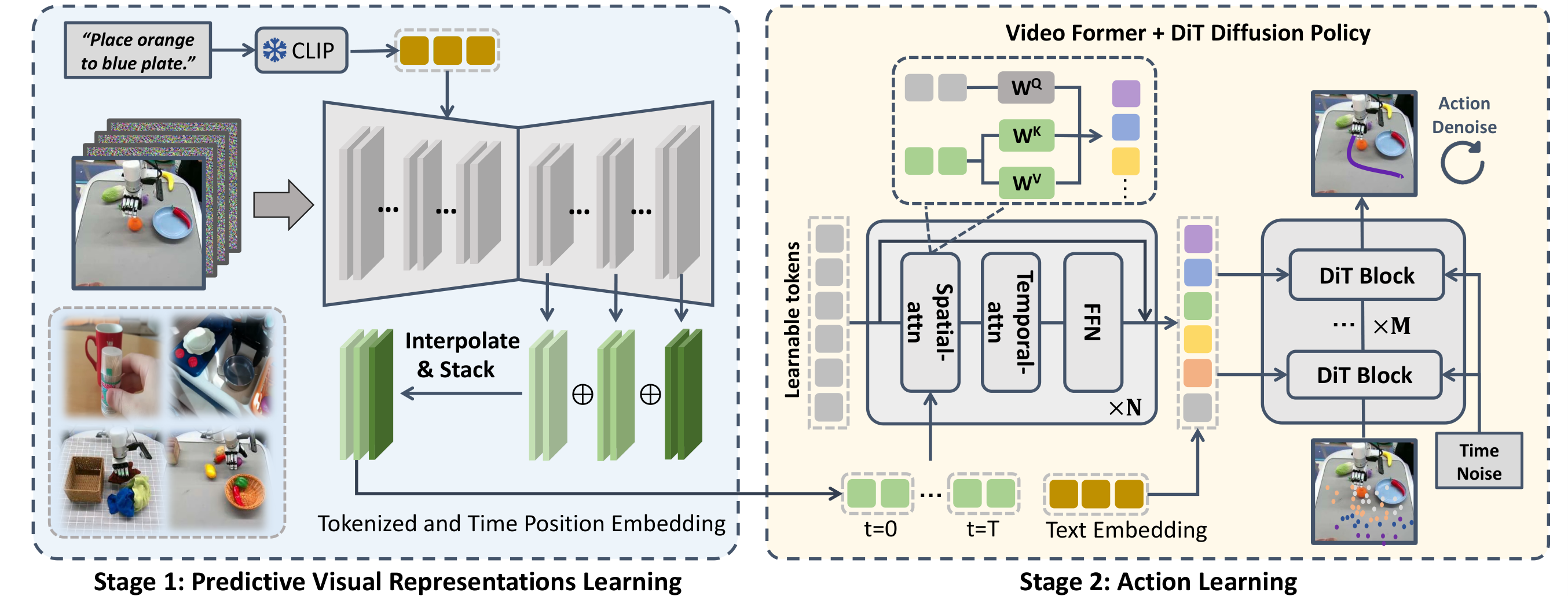
4.1 Stage 1:训练 manipulation TVP model
作者以 1.5B 参数的开源 Stable Video Diffusion (SVD) 为基础。原始 SVD 主要以初始帧 $s_0$ 为条件;VPP 增加 CLIP language feature $l_{emb}$,通过 cross-attention 注入语言条件,并把输出视频设置为 $16\times256\times256$ 来提升训练和推理效率。除这些改动外保留 SVD 主要组件。
这里 $x_0=s_{0:T}$ 是完整视频序列,$x_t=\sqrt{\bar{\alpha}_t}x_0+\sqrt{1-\bar{\alpha}_t}\epsilon$ 是加噪视频。模型学习基于初始观测和语言重建整个未来序列。
三类数据分别是 internet human manipulation、internet robot manipulation 和 self-collected/downstream data。附录给出各数据集采样比例;这些权重用于平衡不同规模和质量的数据。
| TVP 训练数据 | 轨迹数 | 采样比例 |
|---|---|---|
| Something-Something-v2 | 191,642 | 0.30 |
| RT-1 | 87,212 | 0.15 |
| Bridge | 23,377 | 0.15 |
| BC-Z | 43,264 | 0.08 |
| Taco-Play / Jaco-Play | 3,603 / 1,085 | 0.01 / 0.01 |
| CALVIN-ABC / MetaWorld | 18,033 / 2,500 | 0.10 / 0.05 |
| Panda Arm / Dexterous Hand | 2,000 / 2,476 | 0.05 / 0.10 |
| Total | 375,192 | 1.00 |
附录说明:Bridge 中 5,558 条和 Something-Something-v2 中 2,048 条按 Seer 设置留作 validation;其他数据集留 3% 作为 validation。
4.2 Stage 2:把 TVP 当作一次前向视觉 encoder
完整去噪高质量视频非常慢,且会导致 open-loop 或低频控制。VPP 的关键工程选择是:只执行 TVP 的一次 forward step,提取内部 up-sampling layers 的特征,不等待最终像素视频。
$m$ 表示 TVP 中某个 up-sampling layer。输入是当前图像 $s_0$ 与 noisy latent $q(x_{t'}|x_0)$ 的拼接;$t'$ 通常对应白噪声或接近白噪声的 latent。
为什么要聚合多层:
最终像素层包含很多与控制无关的纹理细节;中间 upsampling features 通常更保留运动和空间结构。VPP 不手选单层,而是插值到同一分辨率后按 channel 拼接。
对多视角机器人,VPP 分别为 static camera 和 wrist camera 预测未来表示,得到 $F_p^{static}$ 和 $F_p^{wrist}$。这保持了 TVP 的输入形式简单,也让 Video Former 统一处理多视角。
4.3 Video Former:压缩时空多视角表征
Predictive representation 是 $T\times C\times W\times H$ 的高维特征序列。Video Former 用固定数量 learnable tokens $Q_{[0:T,0:L]}$ 汇聚这些表征,每个 frame 先做 spatial attention,再跨时间做 temporal attention。
输出 $Q''$ 是固定长度 tokens,后续作为 diffusion policy 的 cross-attention 条件。
4.4 Diffusion transformer action head
Action head 以 noised action sequence 为输入,用 DiT/decoder blocks 逐步恢复动作。聚合后的 $Q''$ 通过 cross-attention 注入每个 transformer block。动作去噪目标为:
这里 $a_0$ 是真实动作序列,$D_\psi$ 直接预测去噪后的动作。VPP 也使用 action chunking,输出多个动作步以提升控制频率。
5. 实验结果与图表精读
5.1 仿真设置
仿真包括 CALVIN ABC$\rightarrow$D 和 MetaWorld。CALVIN 中训练环境是 ABC,测试环境是 unseen D,按照 GR-1 设置只使用 language-annotated ABC 数据训练。MetaWorld 包含 50 个 Sawyer 机器人任务,每个任务用官方 Oracle policy 采集 50 条轨迹。TVP fine-tuning 需要 8 张 A100 训练 2-3 天;policy 训练约需 4 张 A100 训练 6-12 小时。
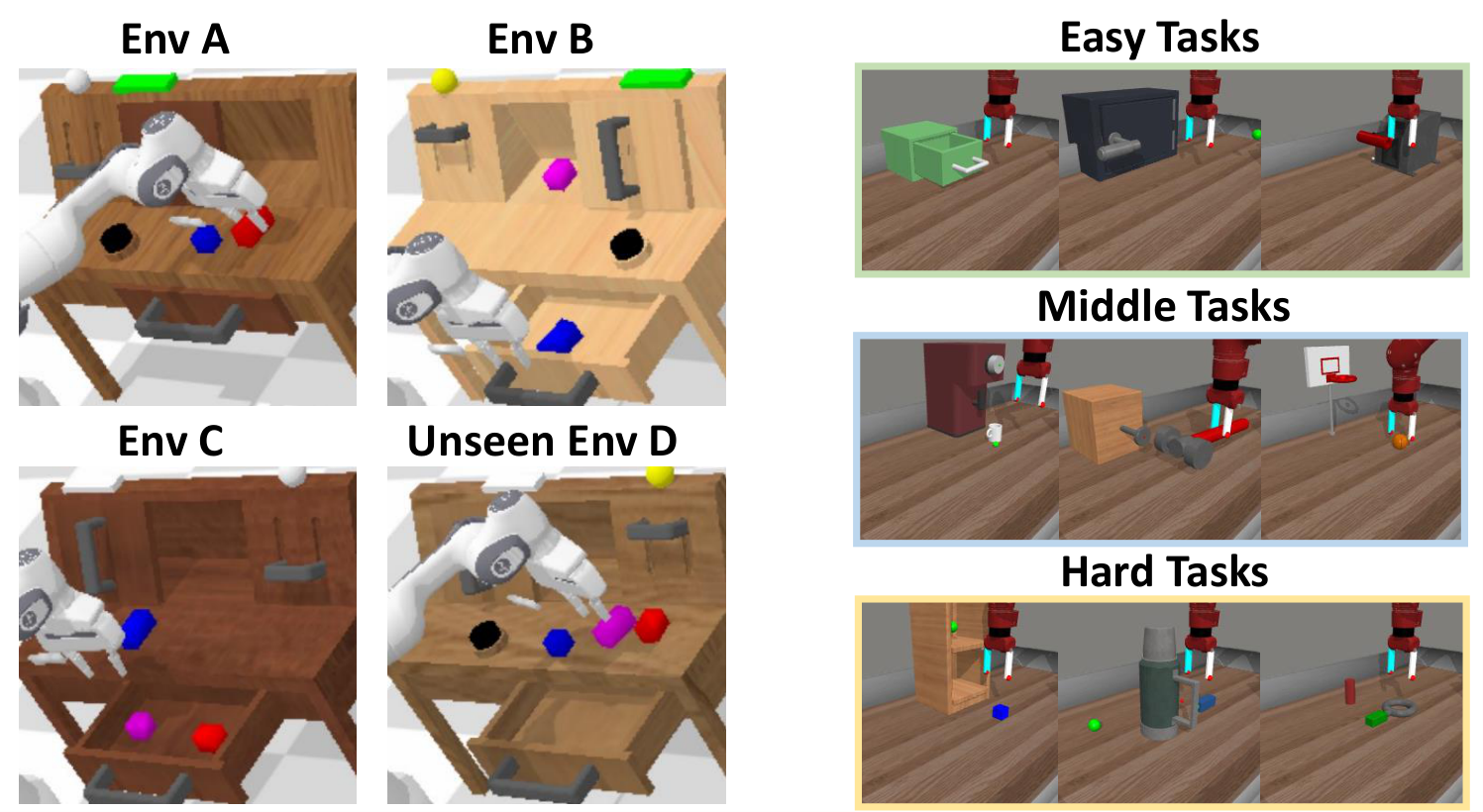
5.2 CALVIN ABC-D long-horizon
| Category | Method | Data | Task 1 | Task 3 | Task 5 | Avg. Len |
|---|---|---|---|---|---|---|
| Direct action | RT-1 | 100% ABC | 0.533 | 0.094 | 0.013 | 0.90 |
| Direct action | Diffusion Policy | 100% ABC | 0.402 | 0.026 | 0.000 | 0.56 |
| Future prediction | SuSIE | 100% ABC | 0.870 | 0.490 | 0.260 | 2.69 |
| Future prediction | GR-1 | 100% ABC | 0.854 | 0.596 | 0.401 | 3.06 |
| Future prediction | VidMan | 100% ABC | 0.915 | 0.682 | 0.467 | 3.42 |
| 3D method | RoboUniview | 100% ABC | 0.942 | 0.734 | 0.507 | 3.65 |
| Ours | VPP | 100% ABC | 0.965 | 0.866 | 0.769 | 4.33 |
| Data efficiency | GR-1 | 10% ABC | 0.672 | 0.198 | 0.069 | 1.41 |
| Data efficiency | VPP | 10% ABC | 0.878 | 0.632 | 0.453 | 3.25 |
CALVIN 的评价是连续完成 5 个指令任务,Avg. Len 越高越好。VPP 在第 5 个任务成功率仍有 0.769,说明长链任务衰减明显小于 GR-1 和 VidMan。10% 数据设置中,VPP 的 3.25 也超过多种 full-data future prediction 方法。
5.3 MetaWorld 50-task
| Method | Easy (28) | Middle (11) | Hard (11) | Average |
|---|---|---|---|---|
| RT-1 | 0.605 | 0.042 | 0.015 | 0.346 |
| Diffusion Policy | 0.442 | 0.062 | 0.095 | 0.279 |
| SuSIE | 0.560 | 0.196 | 0.255 | 0.410 |
| GR-1 | 0.725 | 0.327 | 0.451 | 0.574 |
| VPP | 0.818 | 0.493 | 0.526 | 0.682 |
MetaWorld 结果用于证明 VPP 不只适用于 CALVIN 长链语言任务。在 hard tasks 上 VPP 为 0.526,高于 GR-1 的 0.451;平均成功率从 0.574 到 0.682,论文称比最强 GR-1 baseline 高 10.8 个百分点。
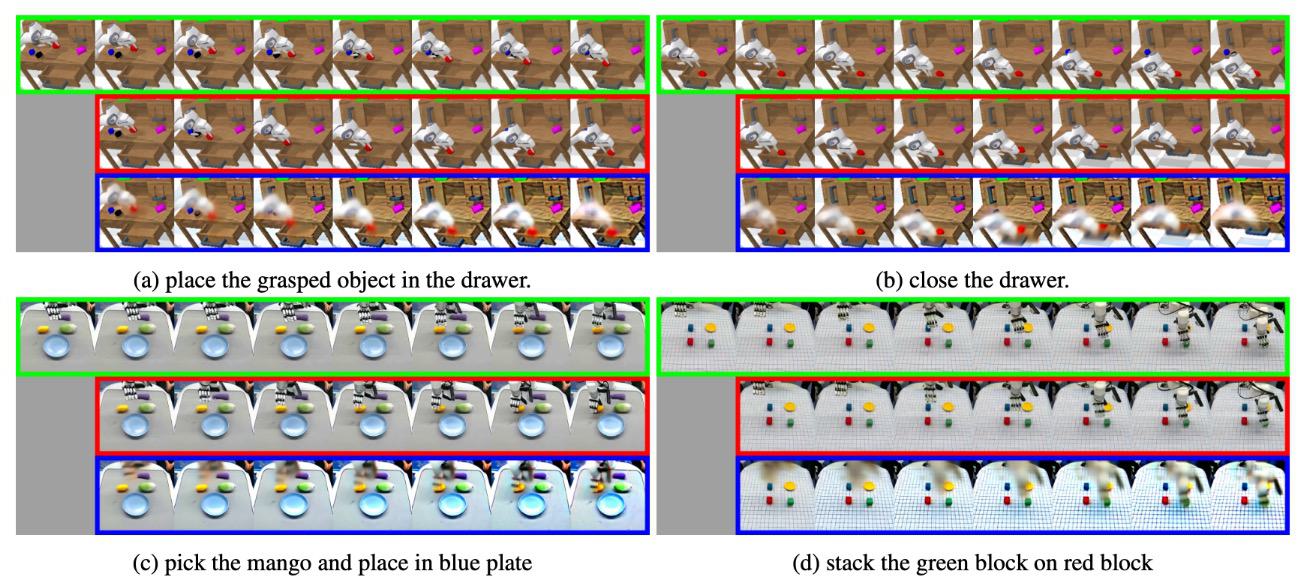
5.4 一次前向预测表征可视化
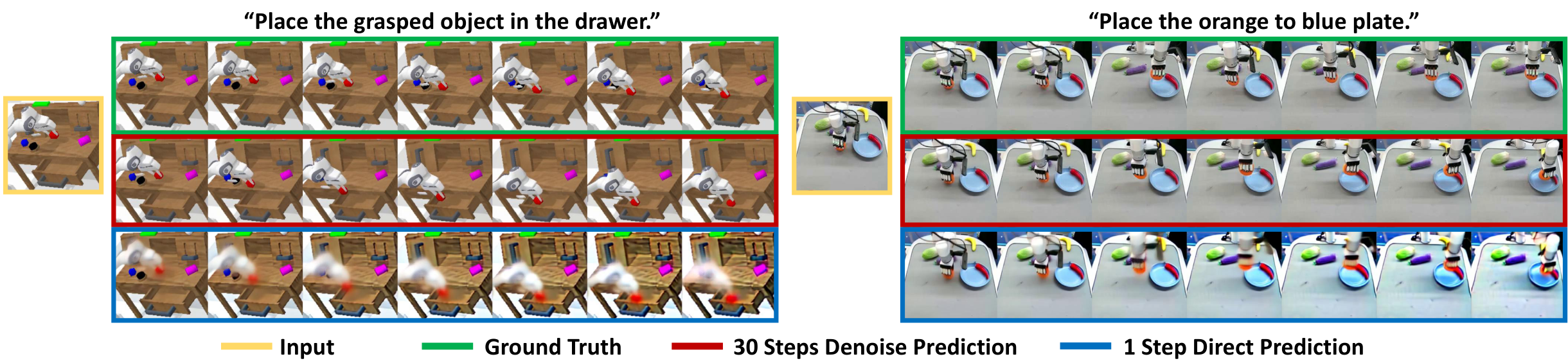
这张图是理解 VPP 的关键:作者不是说一次前向能生成漂亮视频,而是说它能在中间表示中编码足以支持 action learning 的动态趋势。控制不需要 pixel-perfect future,只需要能让 inverse dynamics tracker 追踪未来运动。
5.5 Ablations
| Ablation | Avg. Len | Latency | 解释 |
|---|---|---|---|
| VPP | 4.33 | 约 140 ms | 完整模型 |
| w/o Internet data | 3.97 | 约 140 ms | 去掉 internet manipulation co-training |
| w/o Calvin video | 3.31 | 约 140 ms | 不在下游 CALVIN 视频上微调 TVP |
| w/o Internet data + w/o SVD pretrain | 1.63 | 约 140 ms | 从头训练视频预测模型,性能大幅下降 |
| w/o Video Former | 3.86 | 约 450 ms | 准确率下降且推理变慢 |
| w/o Feature Aggregation | 3.60 | 约 140 ms | 只用最终层特征而非多层聚合 |
| Visual encoder | Pre-training type | Avg. Len |
|---|---|---|
| VDM (VPP) | Video generation | 4.33 |
| Stable-VAE | VAE reconstruction | 2.58 |
| VC-1 | MAE reconstruction | 1.23 |
| Voltron | MAE reconstruction + language generation | 1.54 |
| 更多附录消融 | 结果 |
|---|---|
| Feature layer | Layer-3 3.72;Layer-6 3.88;Layer-9 4.29;Layer-12 4.05;VPP 4.33 |
| Diffusion time-step | Time-step 10: 4.21;20: 4.33;30: 4.25 |
| Single-view | Avg. Len 3.58,只用 static view;作者指出该结果仍超过 3D Diffuser Actor 的 3.35 |
| Ablation 1 | 去掉 Video Former 的 Temporal-attn,Avg. Len 4.18 |
| Ablation 2 | TVP 用 2-step denoising 得表征,Avg. Len 4.19,延迟接近翻倍 |
5.6 Real-world results

Panda 平台收集 2,000 条轨迹,覆盖 30+ tasks、6 categories,包括 picking、placing、pressing、routing、opening、closing。XHand 平台使用 Vision Pro 捕捉人手关节运动并 retarget 到 12-DoF dexterous hand;正文写 4,000 条、100+ tasks、13 categories,附录表述为 2.5k trajectories、100+ tasks、10 categories,并额外报告 tool-use tasks。报告按正文和附录分别呈现,注意该处存在口径差异。
| Platform / setting | Diffusion Policy | SuSIE | GR-1 | VPP |
|---|---|---|---|---|
| Panda seen | 0.42 | 0.56 | 0.52 | 0.85 |
| Panda unseen | 0.25 | 0.46 | 0.38 | 0.73 |
| XHand seen | 0.28 | 0.45 | 0.32 | 0.75 |
| XHand unseen | 0.11 | 0.28 | 0.15 | 0.60 |
| XHand tool-use | 0.05 | 0.23 | 0.15 | 0.68 |
附录细分显示,Panda unseen 中 pick/place/press/route/drawer 分别为 0.80/0.72/0.80/0.70/0.60。XHand tool-use 包括 Spoon 0.9、Hammer 0.6、Drill 0.8、Pipette 0.4,平均 0.68。

5.7 Prediction quality
附录在 Bridge validation 上报告 FVD:VideoFusion 501.2,Tune-A-Video 515.7,Seer 246.3,VPP 41.4。作者解释该提升来自使用预训练 SVD 作为基础,而 Seer 等早期 TVP 没有利用这种视频 foundation model。


6. 复现清单与工程细节
6.1 官方代码与 checkpoints
GitHub README 提供 PyTorch 实现,主要目录包括 video_models、policy_models、policy_training、policy_evaluation、video_dataset、video_conf 和 policy_conf。复现 CALVIN 需要先安装官方 CALVIN 环境并下载 ABC-D dataset,README 估计数据约 500 GB。
| 步骤 | 入口 | 说明 |
|---|---|---|
| 环境 | conda create -n vpp python==3.10;pip install -r requirements.txt | CALVIN 需按 mees/calvin 安装;README 提到 torch 版本 warning 可忽略。 |
| Video model | step1_prepare_latent.py / step1_train_svd.py | README 称主函数入口;仓库中文件名也包含 step1_prepare_latent.py。 |
| Action model | step2_train_action_calvin.py / step2_train_action_xbot.py | 分别训练 CALVIN 和 XBot/XHand 策略。 |
| CALVIN evaluation | policy_evaluation/calvin_evaluate.py | 需要 svd-robot-calvin、dp-calvin、CLIP 和 CALVIN ABC dataset 路径。 |
| Video prediction demo | make_prediction.py --eval --config video_conf/val_svd.yaml ... | 可在 provided video_dataset_instance 样例上试预测。 |
README 提供 Hugging Face checkpoints:CLIP text encoder 约 600M;svd-robot 约 8G;svd-robot-calvin 约 8G;dp-calvin 约 1G。
6.2 架构超参
| Type | CALVIN | MetaWorld | Franka Panda | XHand |
|---|---|---|---|---|
| Video length | 16 | 8 | 16 | 16 |
| Action shape | 10 x 7 | 4 x 4 | 10 x 7 | 10 x 18 |
| Language shape | 20 x 512 | 20 x 512 | 20 x 512 | 20 x 512 |
| Image shape | 256 x 256 | 256 x 256 | 256 x 256 | 256 x 256 |
| Video Former token shape | 16 x 14 x 384 | 8 x 28 x 384 | 14 x 16 x 384 | 14 x 16 x 384 |
| Video Former input/latent dim | 1280 / 512 | 1280 / 512 | 1280 / 512 | 1280 / 512 |
| Video Former heads/layers | 8 / 6 | 8 / 6 | 8 / 6 | 8 / 6 |
| Diffusion Transformer latent dim | 384 | 384 | 384 | 384 |
| Condition shape | 225 x 384 | 225 x 384 | 225 x 384 | 225 x 384 |
| Encoder/decoder layers | 4 / 4 | 4 / 4 | 4 / 4 | 4 / 4 |
| Sampling steps | 10 | 10 | 10 | 10 |
| TVP batch / policy batch | 4 / 76 | 4 / 64 | 4 / 128 | 4 / 128 |
| Epochs / LR | 12 / 1e-4 | 30 / 5e-5 | 30 / 1e-4 | 40 / 1e-4 |
6.3 复现风险点
- 数据量大:CALVIN 官方 dataset 约 500 GB,TVP 训练还涉及多源 internet/robot/self-collected 数据。
- 训练资源高:TVP fine-tuning 需要 8 张 A100 训练 2-3 天;policy 训练需要 4 张 A100 训练 6-12 小时。
- 代码 README 与论文名字有小差异:README 中提到
step1_prepare_latent_data.py,仓库列表中也有step1_prepare_latent.py;实际复现需按仓库当前文件核对。 - 核心不是生成清晰视频:如果复现时把重点放在完整 30-step denoising,而不是 one-step internal features,会偏离论文的高频控制设定。
- 多层特征和 timestep 需要按论文设置:附录显示 Layer-9 接近最优,diffusion time-step 20 最优,盲目换层会影响结果。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
按论文自己的实验证据,VPP 最核心的价值是把“未来预测”从昂贵的像素视频生成改写为可闭环部署的表征抽取问题。Table 1、Fig. 5 和 w/o Video Former/2-step denoising 消融共同说明:控制策略并不需要等待清晰未来视频,只需 TVP 一次 forward 的 predictive representation,加上 Video Former 压缩,就能在 CALVIN、MetaWorld 和真实机器人任务上提升表现并保持 7-10 Hz 控制频率。
7.2 结果为什么站得住
论文通过四类证据支撑主张:第一,替换成 Stable-VAE、VC-1、Voltron 后 Avg. Len 从 4.33 降到 2.58/1.23/1.54,说明不是任意视觉 encoder 都能达到该效果;第二,去掉 internet data、Calvin video 或 SVD pretrain 都下降,说明视频 foundation prior 和 manipulation domain adaptation 都有贡献;第三,layer/time-step/Video Former 消融解释哪些设计在起作用;第四,真实 Panda 和 XHand 上的 seen/unseen/tool-use 结果检查了跨平台泛化。
7.3 论文自身显式或由实验暴露出的边界
- 需要较强视频基础模型和大量视频数据:从头训练且不使用 SVD pretrain 时 Avg. Len 只有 1.63,说明 VPP 对 video foundation prior 依赖明显。
- TVP domain adaptation 很关键:w/o Calvin video 从 4.33 降到 3.31;w/o Internet data 从 4.33 降到 3.97,说明下游域视频和多源数据共同影响表征质量。
- 控制频率依赖 one-step encoder 设计:2-step denoising 没有提升性能,还几乎翻倍推理时间;完整视频去噪不符合论文的闭环控制路线。
- 真实任务仍依赖平台内数据对齐:虽然作者强调 internet pretraining 帮助未见任务,但真实 Panda 和 XHand 仍分别收集了平台数据,并训练对应 generalist policy。
- 指标口径需要区分:CALVIN relative improvement 在摘要、正文和项目页使用了不同 baseline 口径;组会报告时应直接展示 Table 1 数值。
7.4 组会讨论题 1:预测表征和世界模型有什么本质差别?
VPP 的 TVP 会预测未来视觉序列,但 policy 并不在预测世界里 rollout 或规划,而是把一次 forward 的内部表征当作条件输入来学 inverse dynamics。可以讨论:这种方法更像 representation learning,还是 implicit planning?如果未来要和 MPC/world-model RL 结合,需要补上哪些状态、动作、reward 或 uncertainty 结构?
7.5 组会讨论题 2:one-step predictive representation 的信息到底来自哪里?
附录 layer/time-step 消融显示 Layer-9、time-step 20 较好;Fig. 5 显示 one-step representation 虽然模糊但能表达运动。讨论点是:该信息来自 SVD 预训练中的物理先验、manipulation TVP fine-tuning、语言条件,还是多层 feature aggregation?这关系到 VPP 是否能迁移到更复杂接触、遮挡或长程任务。