FLARE: Robot Learning with Implicit World Modeling
1. Quick overview of the paper
| Reading targeting item | content |
|---|---|
| What should the paper solve? | Explicitly generating world models of future images/videos is computationally expensive, and pixel-level reconstruction conflicts with the compact task representation required for motion control; the authors hope to turn future modeling into a latent alignment goal that is lightweight and compatible with high-frequency control. |
| The author's approach | Add $M$ learnable future tokens to the DiT policy input sequence, extract the activations of these tokens in the internal $L$ layer, and align them with the future observation embedding after MLP; the total loss is action flow-matching loss plus $\lambda$ times future latent alignment loss. |
| most important results | RoboCasa 24 tasks average 70.1%, and GR1 simulation 24 tasks average 55.0%, which are higher than policy-only, UWM, GR00T N1 scratch and Diffusion Policy; real GR1 reaches a maximum of 95.1% under the 100 trajectories/task setting, which is 14% higher than the baseline on average. |
| Things to note when reading | FLARE is not a "generate future images and then act" method like CoT-VLA; it predicts a control-centric latent representation of future observations. There is no need to generate future embeddings during inference, and human first-view videos without action labels can also be used during training. |
difficulty rating
4/5. Requires familiarity with flow matching / diffusion policy, DiT, VLA, representation alignment, Q-former and imitation learning benchmark. There are not many formulas, but to truly reproduce, you need to understand embedding target, future token stream, EMA target update and multi-data source training.
keywords
Implicit World Modeling; Future Latent Representation Alignment; Flow Matching Policy; Diffusion Transformer; Vision-Language-Action; Q-former; Human Egocentric Videos
Core contribution list
- Future latent alignment target.FLARE does not predict future pixels, but instead aligns the policy's internal future-token representation with future observation embeddings.
- Light architectural changes.Just add a few future tokens and alignment heads to the standard VLA / flow-matching policy, no full future image generator is required.
- action-aware embedding target. The author built a Q-former based vision-language embedding module and used action flow-matching for pre-training to make future targets closer to control.
- Motionless video available.When there is human first-person video but no robot action, future alignment loss can still be used to learn latent dynamics.
- Covers simulated and real robots.Experiments include RoboCasa, GR1 simulation, real GR1 humanoid, and novel object few-shot + human video co-training.
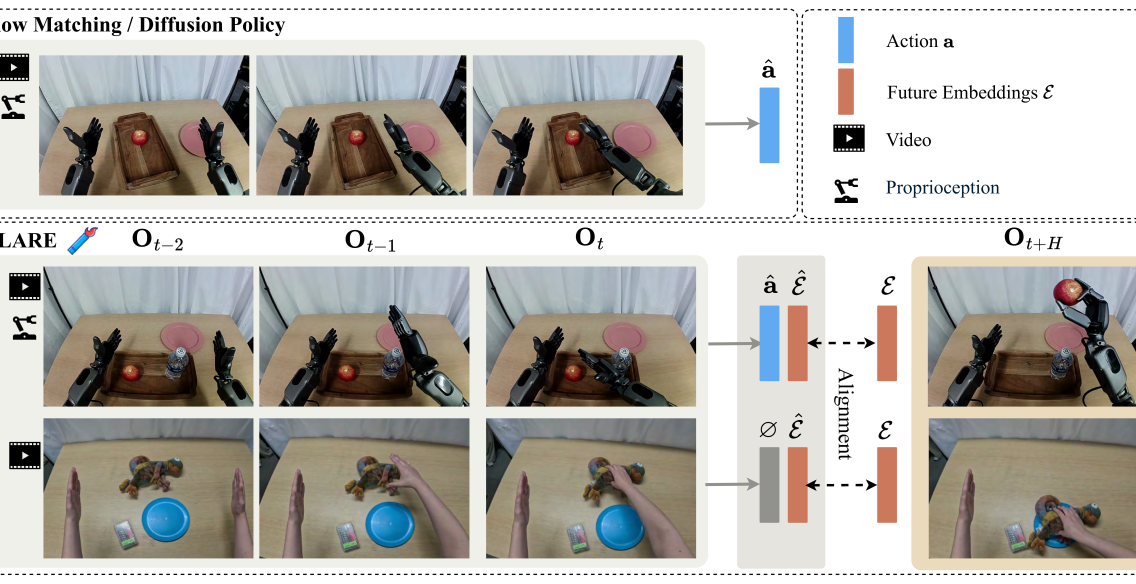
2. Motivation
2.1 What problem should be solved?
The paper starts from an intuition: When humans act, they implicitly predict the future state. For example, when reaching for a cup on the table, they will predict the path of the hand, obstacles, and the touch after grabbing. Robot policies also require similar predictive capabilities, especially in multi-step manipulation, occlusion, complex object geometry, or two-arm humanoid tasks.
However, existing methods of connecting world models to policy often require predicting future images or video frames. The author believes that there are two problems with this approach: first, high-fidelity visual generation requires large models, which brings training and inference overhead; second, pixel reconstruction cares about texture and spatial details, while motion control cares about task-related abstract information, and the two requirements for model capacity are not completely consistent.
2.2 Limitations of existing methods
Routes such as GR1, GR2, UWM, and UVA explicitly predict future image tokens or VAE latent while learning actions. They are intuitive but still deal with future visual reconstruction problems. The paper points out that control tasks do not necessarily require "predicting every pixel". For example, when grabbing a water bottle and putting it into a container, the key is the position, orientation and geometric relationship between the water bottle and the target container, rather than irrelevant details in the background.
In addition, if the future prediction target is general visual embedding, it does not necessarily contain action-related information; if pixel / VAE latent is used directly, it may be too expensive. Therefore, the core compromise of FLARE is: learn a compact and action-aware embedding of future observations, and align the internal representation of the policy to this embedding.
2.3 The solution ideas of this article
FLARE places world modeling in the policy's latent space. During training, the current observation and action chunk still learn actions through flow matching; at the same time, learnable future tokens are added to the DiT input sequence, allowing these tokens to form predictions of future observation embedding in the middle layer. This prediction does not require image generation, only cosine alignment.
This brings an important result: for human first-view videos without action labels, although action flow-matching loss cannot be calculated, future alignment loss can still be calculated, so they can participate in training latent dynamics.
4. Detailed explanation of method
4.1 Background: Flow Matching Policy
The paper follows the flow-matching action learning of $\pi_0$ and GR00T N1. Let $o_t$ be the current observation, including image and language; $q_t$ is the proprioceptive state; $A_t=(a_t, \dots, a_{t+H})$ is the expert action chunk; $\phi_t=VL(o_t)$ is the visual language embedding.
During training, the real action chunk is first mixed with Gaussian noise to obtain a noisy action; the model learns the velocity field from the noisy action to the real action.
$$A_t^\tau = \tau A_t + (1-\tau)\epsilon, \quad \epsilon\sim\mathcal{N}(0, I)$$ $$\mathcal{L}_{fm}(\theta)=\mathbb{E}_{\tau}\left[\left\|V_\theta(\phi_t, A_t^\tau, q_t)-(\epsilon-A_t)\right\|^2\right]$$| $A_t$ | Action chunk in expert demonstration. |
| $A_t^\tau$ | Noisy action chunk under flow-matching timestep $\tau$. |
| $V_\theta$ | DiT policy predicted denoising direction. |
| $\tau$ | Sampling from the Beta distribution, the paper follows the $s=0.999$ setting of GR00T N1. |
During inference, starting from $A_t^0\sim\mathcal{N}(0, I)$, use $K$ step Euler integration to obtain the action chunk; $K=4$ in all experiments.
4.2 FLARE architecture
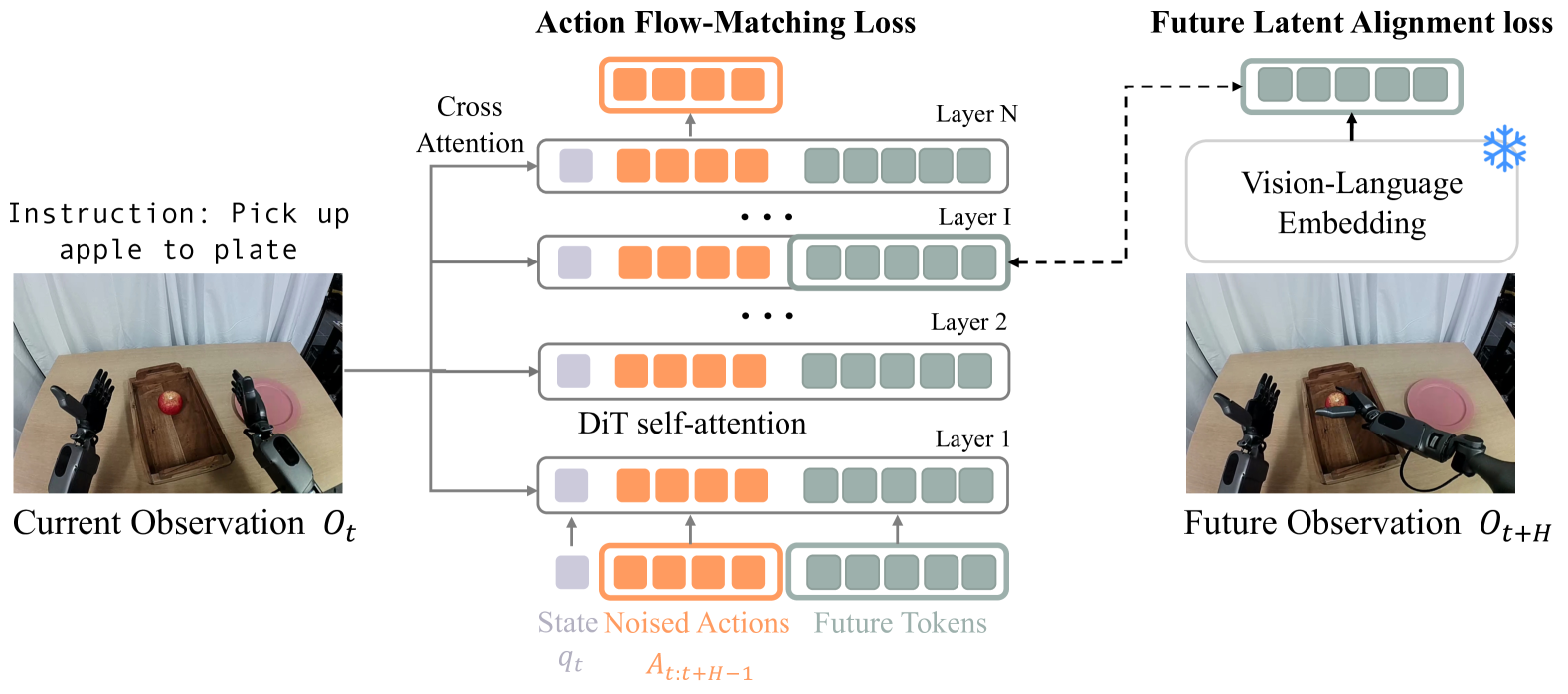
The input sequence of FLARE contains three parts:
- The current proprioceptive state $q_t$ is the state token obtained by the state encoder.
- Noisy action chunk $A_t^\tau=\{\tau a_t+(1-\tau)\epsilon\}_{t}^{t+H}$ action tokens obtained through action encoder.
- $M$ learnable future token embeddings.
In the internal layer $L$ of DiT, the model extracts the hidden states corresponding to future tokens, and after MLP projection, they are aligned with the embedding of future observation $\phi_{t+H}$.
4.3 Future Latent Representation Alignment
The meaning of FLARE loss is to make the future-token representation inside the action denoising network close to the visual language embedding of future observations.
$$\mathcal{L}_{align}(\theta)=-\mathbb{E}_{\tau}\left[\cos\left(f_\theta(\phi_t, A_t^\tau, q_t), g(\phi_{t+H})\right)\right]$$ $$\mathcal{L}=\mathcal{L}_{fm}+\lambda\mathcal{L}_{align}$$| $f_\theta$ | The future-token activations taken from the $L$ layer of DiT are projected and output as $B\times M\times D$ representation. |
| $g$ | Observe the embedding encoder in the future and output the $B\times M\times D$ target of the same shape. |
| $M$ | Number of future/embedding tokens; Q-former in the main design is compressed into $M=32$ tokens. |
| $\lambda$ | Alignment loss coefficient; in the main experiment, $\lambda=0.2$, ablation shows that this value has the best effect. |
Its relationship to REPA is: REPA aligns image diffusion transformers with visual representations to accelerate image generation; FLARE aligns policy DiT and future observation embedding, for robot action learning.
4.4 Action-aware Future Embedding Model
The authors found that the choice of target embedding is important. Directly using tokens from a general vision encoder is feasible, but a better approach is to train an action-aware vision-language embedding model so that it is both compact and contains control-relevant information.
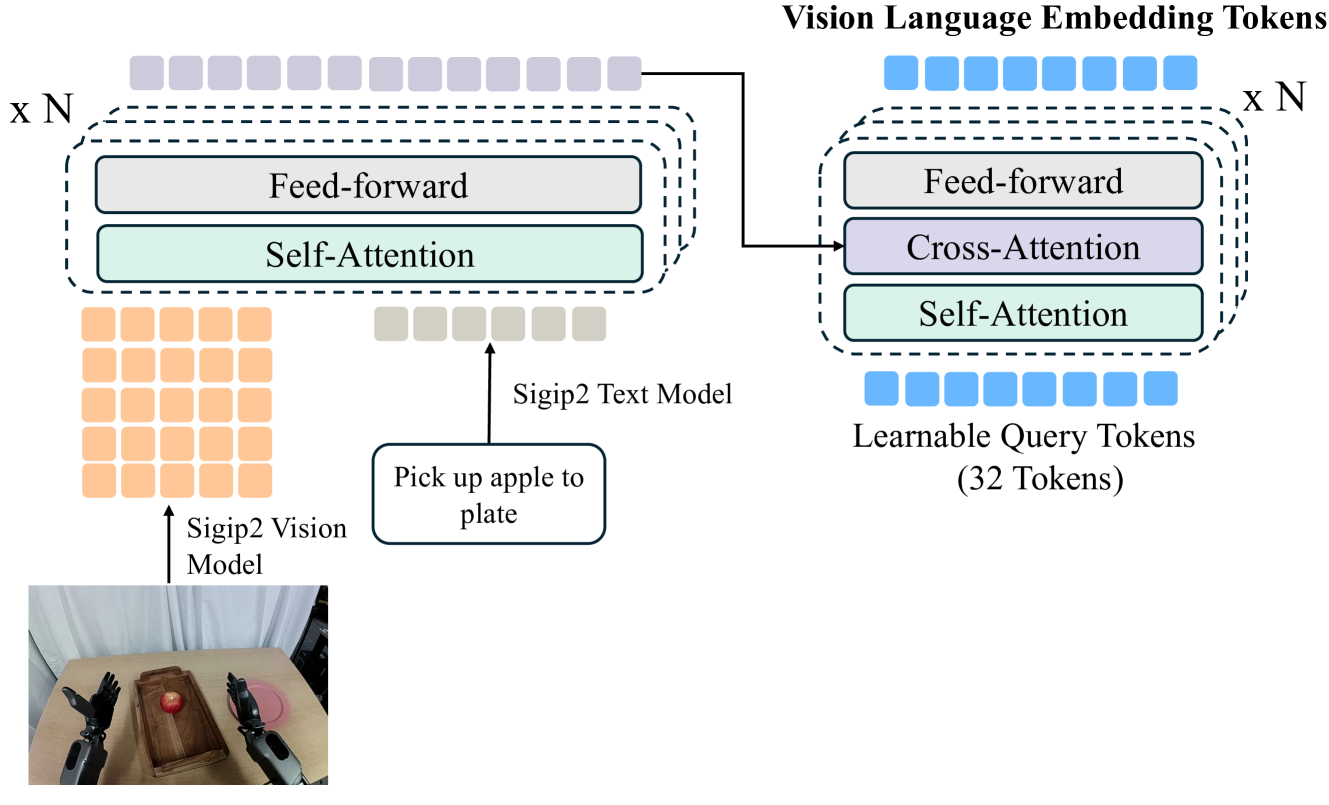
Appendix A The specific structure is as follows: adopt siglip2-large-patch16-256 As a vision and language encoder; each $256\times256$ image generates 256 patch tokens; the language instructions are padded to generate 32 language tokens; the two are spliced into 288 tokens, which are fused by 4 layers of self-attention transformer; finally, the 32 learnable query tokens of Q-former are used to compress into 32 vision-language tokens.
4.5 EMA Target Update
In downstream post-training, there is a distribution shift between the target embedding model and policy encoder. The paper does not completely freeze the target embedding, but uses EMA to let the target slowly follow the visual language encoder of the policy.
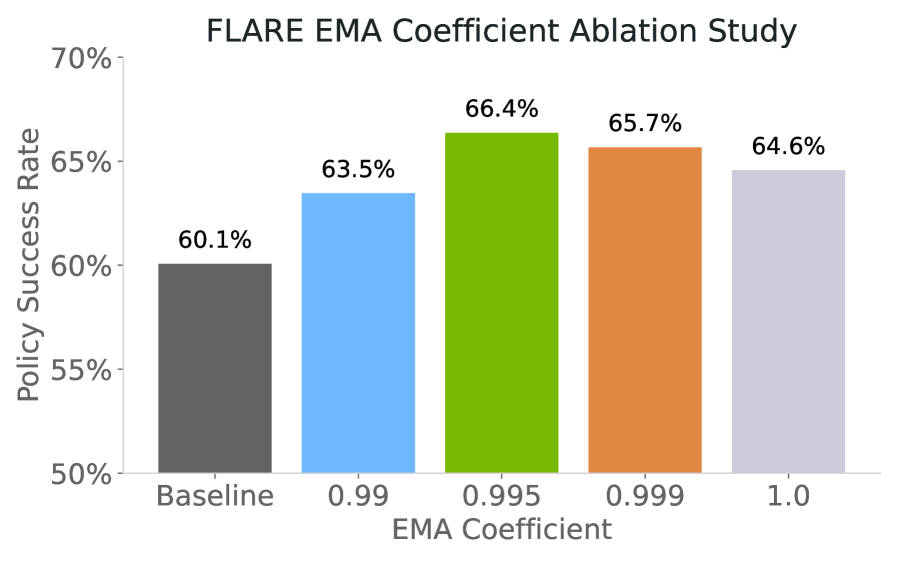
The author tested $\rho\in\{0.99, 0.995, 0.999, 1.0\}$ and finally used $\rho=0.995$; even if $\rho=1.0$ does not do EMA, FLARE still exceeds the policy-only baseline, but $\rho=0.995$ is the best.
4.6 Training pseudocode
Appendix D Gives Python-style pseudocode. The core process can be condensed into:
5. Experiments and results
5.1 Multitask Simulation Benchmarks

RoboCasa includes kitchen tasks such as pick-and-place, door manipulation, faucet operation, etc., and the observation is left/right/wrist three-way RGB. The GR-1 simulation includes 18 object rearrangement tasks and 6 articulated object tasks, and the observation is the head first-view RGB.
For fair comparison, the main benchmark does not use cross-embedding pre-trained embedding models, but pre-trains embedding models on the same in-domain multitask dataset for 80, 000 gradient steps. Except for UWM, all methods train for 80k steps; UWM is still improving after 80k steps and is extended to 400k steps.
5.2 Main results table
| Methods | FLARE | Policy Only | UWM | GR00T N1 Scratch | Diffusion Policy |
|---|---|---|---|---|---|
| Pick and Place | 53.2% | 43.8% | 35.6% | 44.1% | 29.2% |
| Open & Close Doors / Drawers | 88.8% | 78.7% | 82.0% | 80.0% | 78.7% |
| Others | 80.0% | 75.2% | 74.2% | 69.6% | 61.3% |
| 24 RoboCasa Tasks Average | 70.1% | 61.9% | 60.8% | 60.6% | 51.7% |
| Pick and Place Tasks | 58.2% | 46.6% | 30.1% | 51.8% | 40.4% |
| Articulated Tasks | 51.3% | 47.4% | 38.4% | 42.8% | 50.1% |
| 24 GR1 Tasks Average | 55.0% | 44.0% | 29.5% | 45.1% | 40.9% |
The result table shows that FLARE is the highest in all summary categories for both benchmarks. Compared to policy-only, RoboCasa improves from 61.9% to 70.1% on average, and GR1 improves from 44.0% to 55.0% on average. FLARE avoids explicit future VAE latent generation and is significantly higher on both RoboCasa and GR1 compared to UWM.
5.3 Data-efficient Post-training

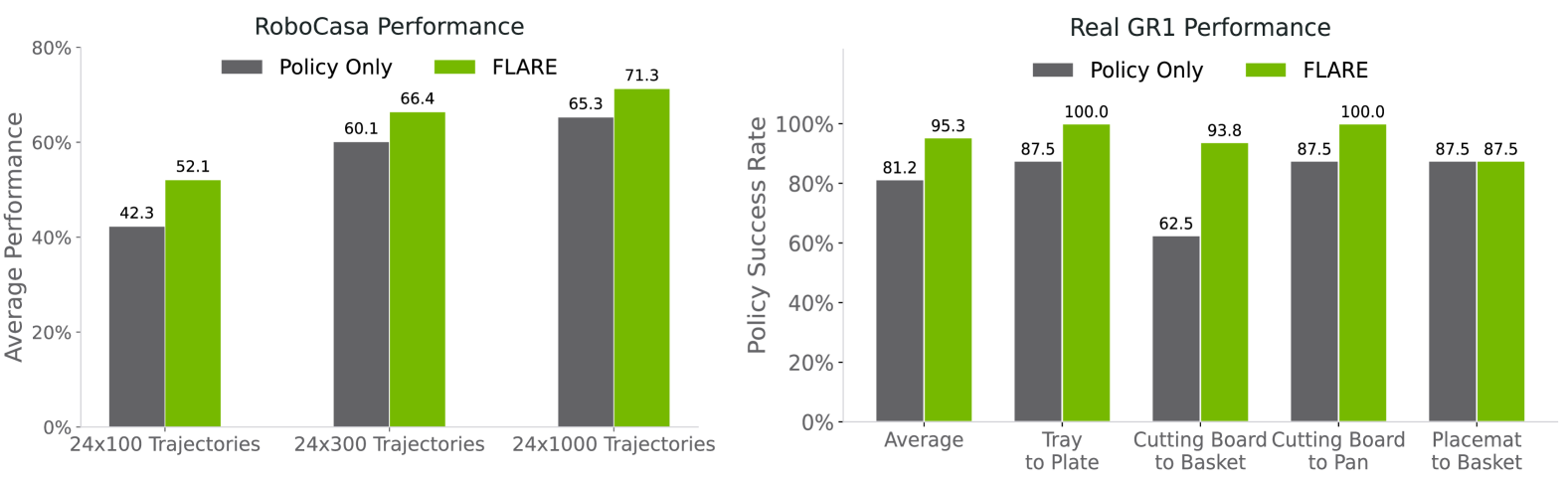
This section evaluates the effect of cross-embodiment pretrained embedding models on unseen embodiments/tasks. policy-only baseline initializes Q-former embedding and DiT weights at the same time; FLARE only warm starts vision-language embedding, and uses pretrained embedding model as future prediction target.
Paper report: Under the data-limited setting of RoboCasa 100 trajectories/task, FLARE is 10% higher than policy-only; on real GR1, FLARE has a maximum success rate of 95.1%, which is 14% higher than baseline on average. In qualitative observations, baseline often knocks over water bottles or cans when they are close to the hand, while FLARE learns to go around or over the objects before grabbing them.
5.4 Human Egocentric Videos without Action Labels
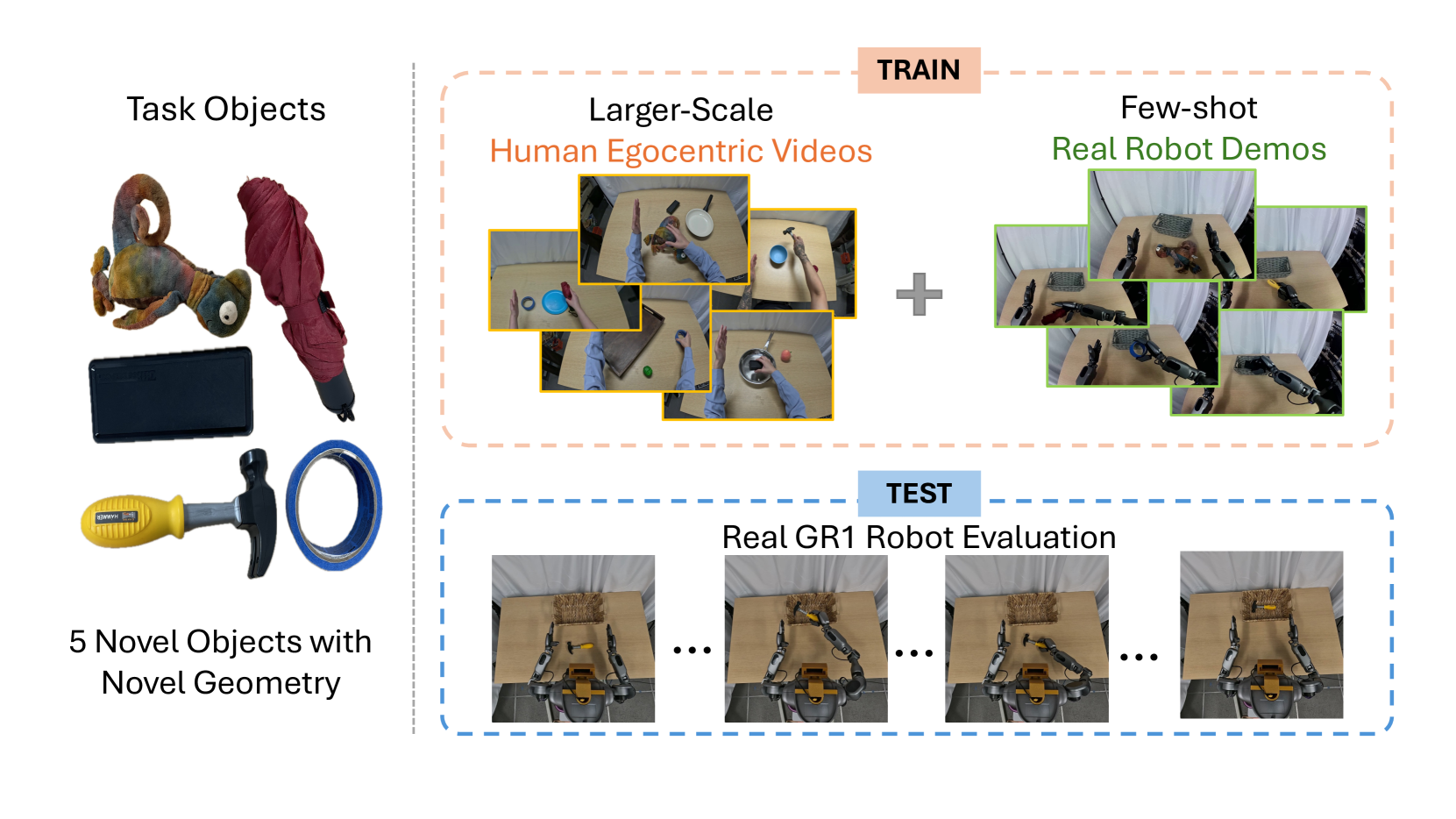
The author selects 5 novel objects, and each object collects 150 human first-person perspective demonstrations by using a demonstrator wearing a GoPro to perform similar tasks; each object on the robot side only collects a maximum of 10 teleoperated demonstrations. For robot demos, both action flow-matching loss and future alignment objective are used during training; for human egocentric videos, only future alignment loss is used because there are no action labels.
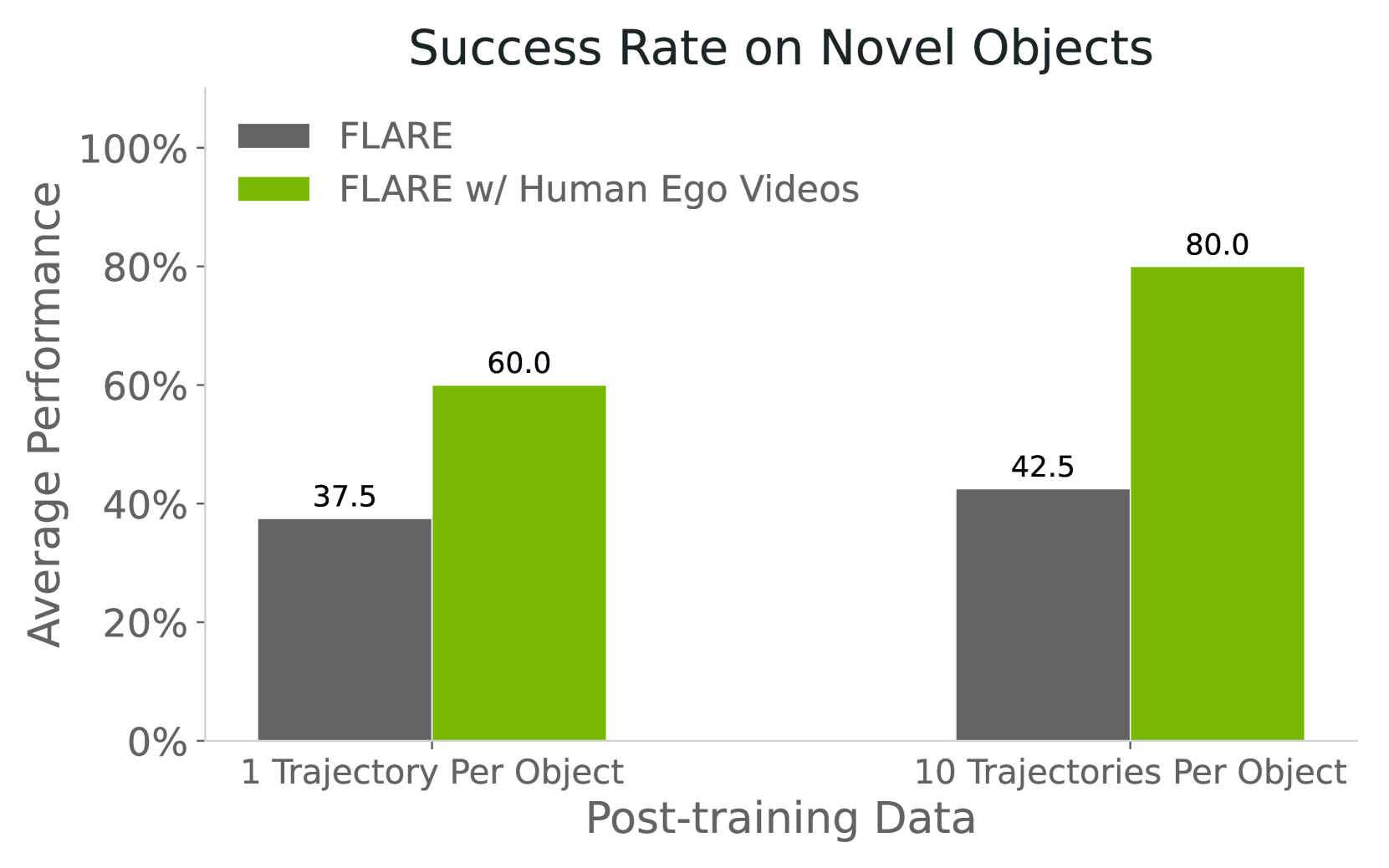
Paper report: When there is only one teleoperated trajectory for each object, FLARE can reach a maximum success rate of 60%; when there are 10 robot trajectories for each object and combined with human videos, the success rate increases to 80%, which is approximately twice that of the action-labeled data baseline alone. The project page further gives a specific value: 1-shot without human video is 37.5%, and with human egocentric videos it is 60%.
5.5 Ablations
| Target embedding model | Success Rate |
|---|---|
| No FLARE loss | 43.9% |
| SigLIP2 | 49.6% |
| SigLIP2 average pooled | 50.9% |
| Action-aware Embedding | 55.0% |
This table shows that FLARE is compatible with the general vision encoder target: even using SigLIP2 is about 7% higher than no-FLARE; but action-aware embedding is the best, indicating that it is important to align the target embedding with the control task.
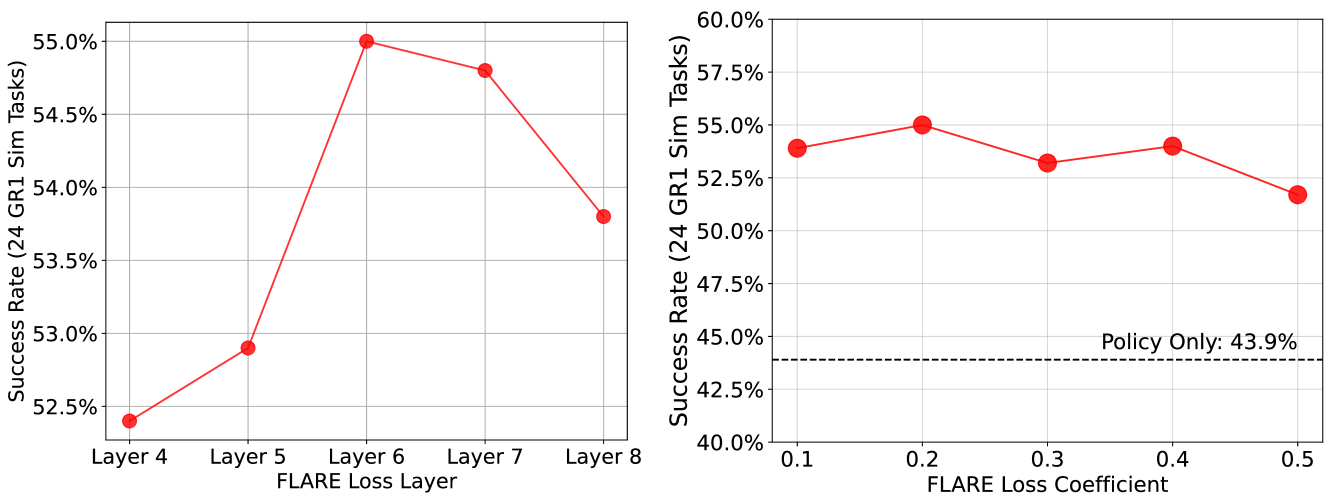
The author pointed out: Layers applying FLARE loss too early, such as layer 4, will significantly decline; the reason may be that the early layer is still processing low-level action denoising representations, and premature alignment of future embedding will conflict with action prediction. Deeper layers allow more model weights to benefit from future supervision, but also avoid excessive conflicts.
6. Repeat audit
6.1 Pre-training data mixture
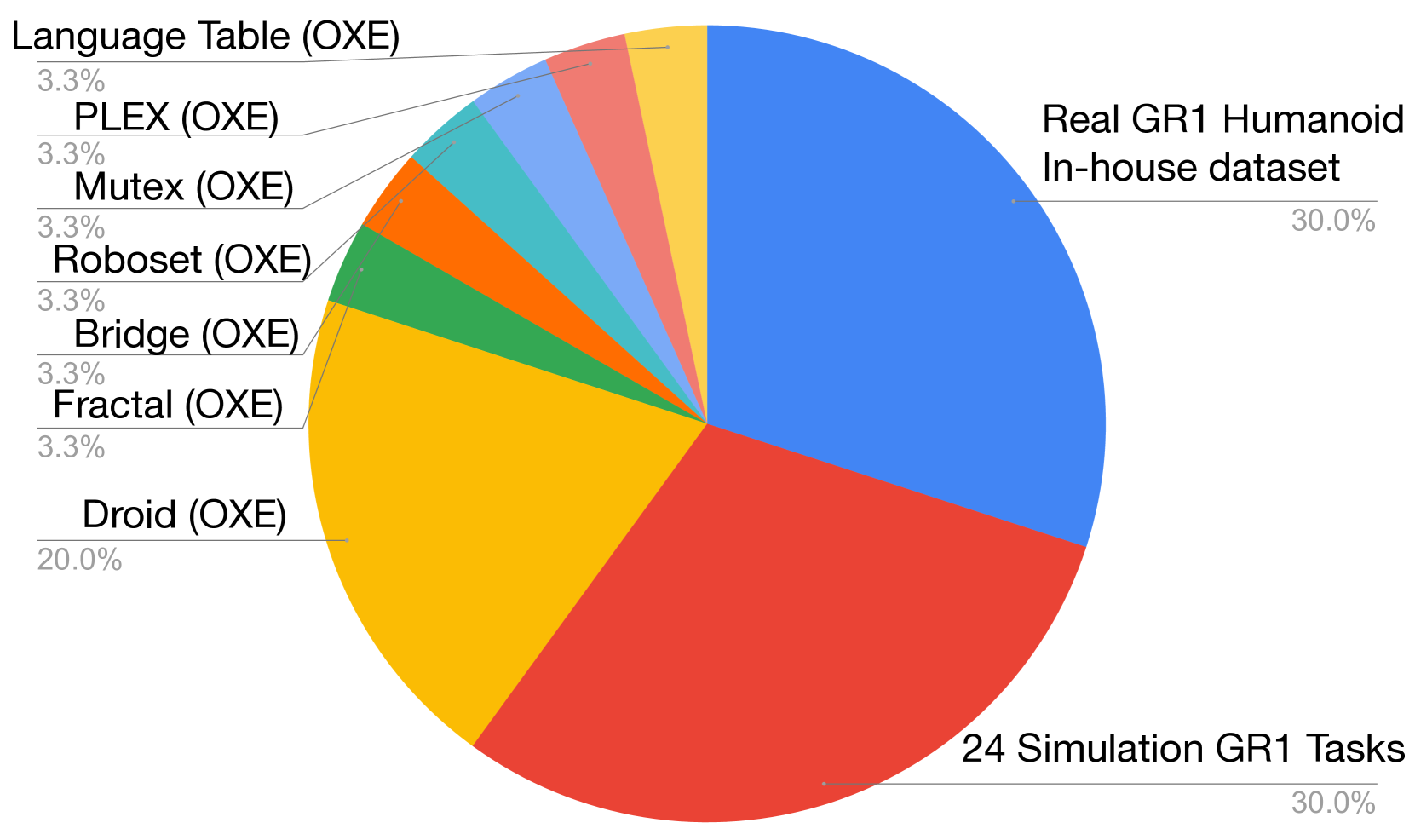
Appendix B The statistics of action-aware vision-language embedding pretraining are given, totaling 169.5M frames and 2, 989.5 hours.
| Dataset | Frames | Duration | FPS | Camera View | Category |
|---|---|---|---|---|---|
| GR-1 In-house | 6.4M | 88.4 hr | 20 | Egocentric | Real robot |
| DROID (OXE) | 23.1M | 428.3 hr | 15 | Left, Right, Wrist | Real robot |
| RT-1 (OXE) | 3.7M | 338.4 hr | 3 | Egocentric | Real robot |
| Language Table (OXE) | 7.0M | 195.7 hr | 10 | Front-facing | Real robot |
| Bridge-v2 (OXE) | 2.0M | 111.1 hr | 5 | Shoulder, left, right, wrist | Real robot |
| MUTEX (OXE) | 362K | 5.0 hr | 20 | Wrist | Real robot |
| Plex (OXE) | 77K | 1.1 hr | 20 | Wrist | Real robot |
| RoboSet (OXE) | 1.4M | 78.9 hr | 5 | Left, Right, Wrist | Real robot |
| GR-1 Simulation | 125.5M | 1, 742.6 hr | 20 | Egocentric | Simulation |
| Total | 169.5M | 2, 989.5 hr | -- | -- | -- |
6.2 Training hyperparameters
| stage | settings |
|---|---|
| Embedding model pretraining | 256 NVIDIA H100 GPUs; batch size 8192; 150, 000 gradient steps. |
| Optimizer | AdamW; $\beta_1=0.95, \beta_2=0.999, \epsilon=1e-8$; weight decay 1e-5. |
| Learning rate schedule | Cosine schedule; warmup ratio 0.05. |
| Flow-matching timestep | $p(\tau)=\text{Beta}((s-\tau)/s; 1.5, 1)$, $s=0.999$. |
| Multitask experiments | 32 NVIDIA H100 GPUs; batch size 1024; 80, 000 gradient steps; the rest of the super participating pre-training are consistent. |
| Inference denoising | $K=4$ Euler integration steps. |
| FLARE loss | $M=32$ future/embedding tokens; main experiment layer 6 / 8; $\lambda=0.2$; EMA $\rho=0.995$. |
6.3 reproducibility checklist
The paper gives relatively sufficient information
Fully: Core formula, DiT token structure, Q-former embedding structure, main loss, main experiment benchmark, baseline, number of training steps, GPU scale, batch size, optimizer, data table, pseudo code, key hyperparameter ablation.
Still need to add: GitHub shows coming soon on the project page; the complete data preprocessing script, real GR1 control interface, task configuration file for each benchmark, precise model config, checkpoint, and human video alignment/sampling details are not fully disclosed in the source code.
Minimum recurrence path
- Implements the action-aware VL embedding module of SigLIP2 + 4-layer fusion transformer + Q-former, outputting 32 tokens.
- Use mixtures such as GR-1/OXE/RoboSet for embedding model pre-training, and use action flow-matching objective to ensure action-awareness.
- Implement GR00T N1 style DiT flow-matching policy, input state token, noisy action tokens and future tokens.
- Take future-token activations on layer 6 and do cosine alignment with target future observation embedding.
- The total training loss is $\mathcal{L}_{fm}+0.2\mathcal{L}_{align}$, and the EMA target embedding of $\rho=0.995$ is used in post-training.
- Evaluated at 50 episodes/task on RoboCasa/GR1, checkpoints are evaluated every 1000 steps, and the maximum success rate of the last five checkpoints is reported.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Judging from the paper's own problem setting and experiments, the most valuable part is to reduce the dimensionality of world modeling supervision from "predicting the visible future" to "aligning and controlling the relevant future latent". This not only retains the benefits of future prediction as an auxiliary signal, but also avoids the computational burden of pixel/frame generation. It also naturally explains why video-only human demonstrations are available: action flow matching cannot be trained on action-free data, but current/future observation pairs can be provided to train latent dynamics.
7.2 Why the results hold up
The support for the results comes from four types of evidence: first, two multitask simulation benchmarks cover single-arm and humanoid tabletop manipulation, and FLARE is the highest in all main summary indicators; second, UWM is still lower than FLARE after being trained to 400k steps, reducing the explanation of "just training for longer"; third, target embedding, loss layer, $\lambda$, and EMA are all ablated; fourth, real GR1 and novel objects + human egocentric videos The description method is not only valid in simulation.
7.3 Author's statement of limitations
- Task scope: The paper mainly focuses on imitation learning and real humanoid pick-and-place, and has not yet covered more complex fine dexterity operations.
- Training paradigm: The author considers incorporating reinforcement learning as a future direction, and the current method is mainly imitation learning.
- Expert data relies on: Although it can generalize to novel objects, it still relies on a small number of expert demonstrations; it limits scalability when expert demonstrations are difficult to obtain.
- Human video source: The egocentric human videos in the paper are from a head-mounted GoPro in a controlled setting; scaling up to data from larger, more naturalistic settings remains future work.
7.4 Applicable boundaries
FLARE is suitable for manipulation tasks where latent dynamics can be learned from current observations and future observations, and future visual language embedding can express task progress. It does not directly provide explicit planning rollout, nor does it generate inspectable future images; therefore if the user needs interpretable visual prediction trajectories, FLARE's latent world model is not as intuitive as the explicit image generation method.
In addition, FLARE's benefits depend on target embedding quality. The generic SigLIP2 target can bring improvements, but action-aware embedding is significantly better; this means that when reproducing in new domains, the data coverage and action-awareness of the embedding model may become a major bottleneck.
7.5 Appendix rollout information

