FLARE: Robot Learning with Implicit World Modeling
1. 论文速览
| 阅读定位项 | 内容 |
|---|---|
| 论文要解决什么 | 显式生成未来图像/视频的 world model 计算昂贵,而且 pixel-level reconstruction 与动作控制所需的紧凑任务表征存在目标冲突;作者希望把未来建模变成轻量、可与高频控制兼容的 latent 对齐目标。 |
| 作者的方法抓手 | 在 DiT policy 输入序列中加入 $M$ 个 learnable future tokens,在内部第 $L$ 层取出这些 token 的激活,经 MLP 后与未来观测 embedding 对齐;总损失为 action flow-matching loss 加上 $\lambda$ 倍 future latent alignment loss。 |
| 最重要的结果 | RoboCasa 24 任务平均 70.1%,GR1 仿真 24 任务平均 55.0%,均高于 policy-only、UWM、GR00T N1 scratch 和 Diffusion Policy;真实 GR1 在 100 trajectories/task 设置下最高 95.1%,比 baseline 平均高 14%。 |
| 阅读时要注意的点 | FLARE 不是 CoT-VLA 那类“生成未来图像再行动”的方法;它预测的是未来观测的 control-centric latent representation,推理时不需要生成未来 embedding,训练时也能利用无动作标签的人类第一视角视频。 |
难度评级
4/5。需要熟悉 flow matching / diffusion policy、DiT、VLA、representation alignment、Q-former 和 imitation learning benchmark。公式不多,但要真正复现,需要理解 embedding target、future token stream、EMA target update 和多数据源训练。
关键词
Implicit World Modeling;Future Latent Representation Alignment;Flow Matching Policy;Diffusion Transformer;Vision-Language-Action;Q-former;Human Egocentric Videos
核心贡献清单
- 未来 latent 对齐目标。FLARE 不预测未来像素,而是让 policy 的内部 future-token 表征对齐未来观测 embedding。
- 轻量架构改动。只需给标准 VLA / flow-matching policy 加入少量 future tokens 和 alignment head,不需要完整未来图像生成器。
- action-aware embedding target。作者构建 Q-former based vision-language embedding module,用 action flow-matching 预训练,使未来 target 更贴近控制。
- 可利用无动作视频。有人类第一视角视频但没有 robot action 时,仍可用 future alignment loss 学习 latent dynamics。
- 覆盖仿真和真实机器人。实验包括 RoboCasa、GR1 simulation、真实 GR1 humanoid,以及 novel object few-shot + human video co-training。
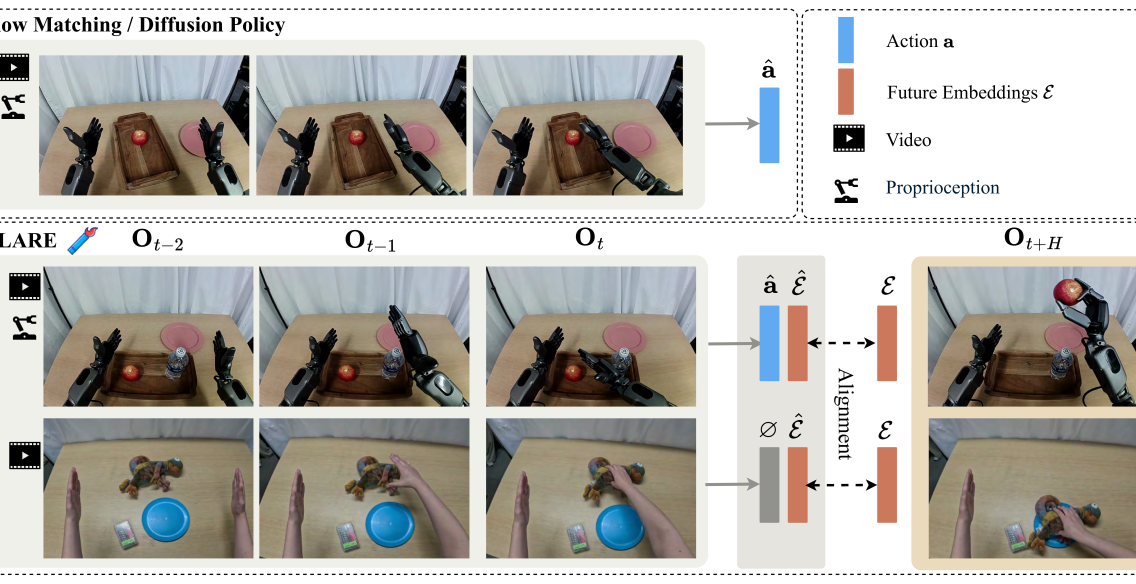
2. 动机
2.1 要解决什么问题
论文从一个直觉出发:人类行动时会隐式预测未来状态,例如伸手拿桌上的杯子时,会预判手的路径、障碍物、抓取后的触感。机器人 policy 也需要类似的 predictive capability,尤其是在多步操控、遮挡、物体几何复杂或双臂 humanoid 任务中。
但已有把 world model 接入 policy 的方式经常要求预测未来图像或视频帧。作者认为这种做法有两个问题:第一,高保真视觉生成需要大模型,带来训练和推理开销;第二,像素重建关心纹理和空间细节,而动作控制关心任务相关的抽象信息,两者对模型容量的需求并不完全一致。
2.2 已有方法的局限
GR1、GR2、UWM、UVA 等路线显式预测未来图像 token 或 VAE latent,同时学习动作。它们直观,但仍要处理未来视觉重建问题。论文指出,控制任务并不一定需要“预测每个像素”,例如抓水瓶放进容器时,关键是水瓶和目标容器的位置、朝向和几何关系,而不是背景中无关细节。
此外,若未来预测目标是通用视觉 embedding,它不一定包含动作相关信息;若直接使用 pixel / VAE latent,又可能过于昂贵。因此 FLARE 的核心折中是:学习一个 compact 且 action-aware 的未来观测 embedding,并把 policy 内部表征往这个 embedding 对齐。
2.3 本文的解决思路
FLARE 把 world modeling 放在 policy 的 latent space 中。训练时,当前观测和动作 chunk 仍通过 flow matching 学动作;同时,在 DiT 输入序列中加入 learnable future tokens,让这些 token 在中间层形成对未来观测 embedding 的预测。这个预测不要求生成图像,只需要 cosine alignment。
这带来一个重要结果:对于没有 action labels 的人类第一视角视频,虽然不能计算 action flow-matching loss,但仍可以计算 future alignment loss,因此它们可以参与训练 latent dynamics。
4. 方法详解
4.1 Background: Flow Matching Policy
论文沿用 $\pi_0$ 和 GR00T N1 的 flow-matching 动作学习。令 $o_t$ 是当前观测,包含图像和语言;$q_t$ 是 proprioceptive state;$A_t=(a_t,\dots,a_{t+H})$ 是专家动作 chunk;$\phi_t=VL(o_t)$ 是视觉语言 embedding。
训练时先把真实动作 chunk 与高斯噪声混合,得到一个带噪动作;模型学习从带噪动作指向真实动作的速度场。
$$A_t^\tau = \tau A_t + (1-\tau)\epsilon,\quad \epsilon\sim\mathcal{N}(0,I)$$ $$\mathcal{L}_{fm}(\theta)=\mathbb{E}_{\tau}\left[\left\|V_\theta(\phi_t,A_t^\tau,q_t)-(\epsilon-A_t)\right\|^2\right]$$| $A_t$ | 专家 demonstration 中的动作 chunk。 |
| $A_t^\tau$ | flow-matching timestep $\tau$ 下的 noisy action chunk。 |
| $V_\theta$ | DiT policy 预测的 denoising direction。 |
| $\tau$ | 从 Beta 分布采样,论文沿用 GR00T N1 的 $s=0.999$ 设置。 |
推理时,从 $A_t^0\sim\mathcal{N}(0,I)$ 开始,用 $K$ 步 Euler integration 得到动作 chunk;所有实验中 $K=4$。
4.2 FLARE 架构
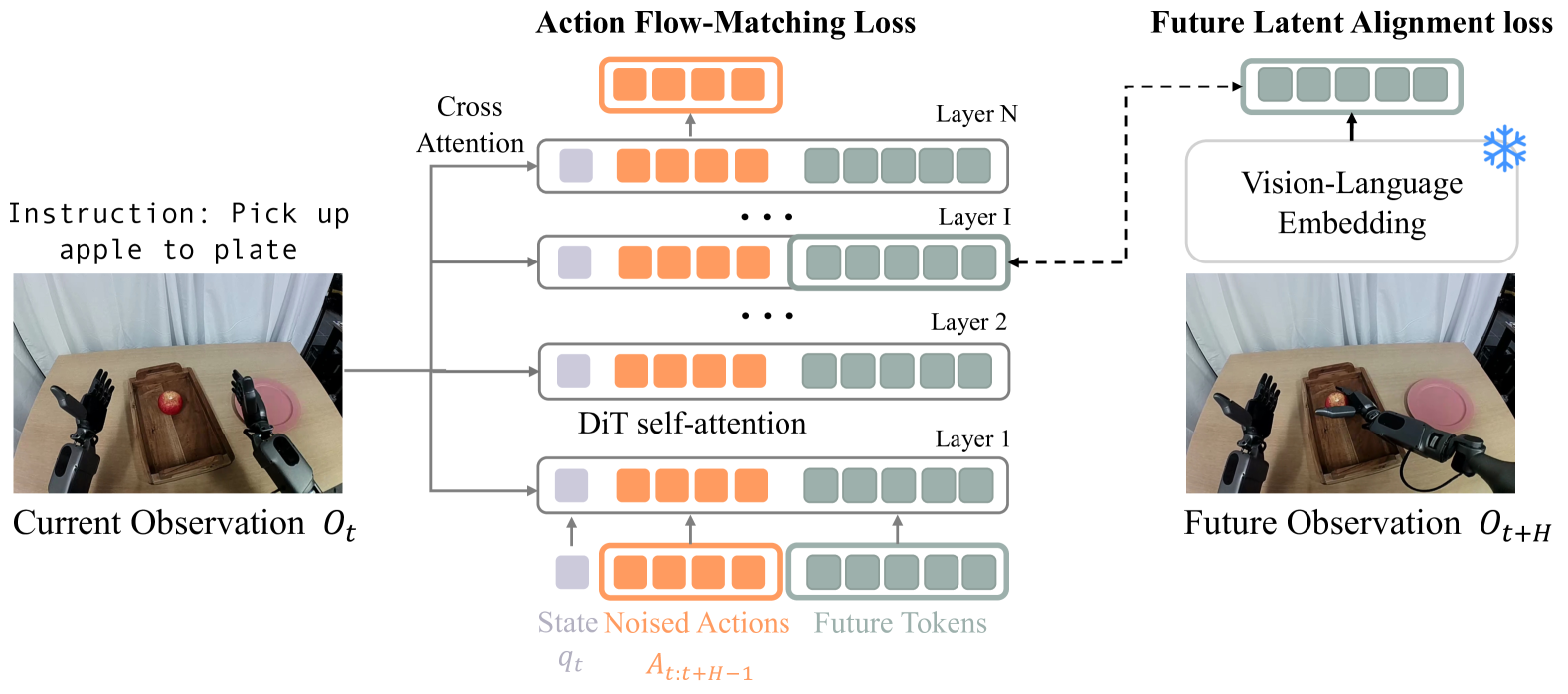
FLARE 的输入序列包含三部分:
- 当前 proprioceptive state $q_t$ 经 state encoder 得到的 state token。
- noised action chunk $A_t^\tau=\{\tau a_t+(1-\tau)\epsilon\}_{t}^{t+H}$ 经 action encoder 得到的 action tokens。
- $M$ 个 learnable future token embeddings。
在 DiT 的内部第 $L$ 层,模型取出 future tokens 对应的 hidden states,经 MLP 投影后,与未来观测 $\phi_{t+H}$ 的 embedding 对齐。
4.3 Future Latent Representation Alignment
FLARE loss 的意思是:让 action denoising network 内部的 future-token 表征,接近未来观测的视觉语言 embedding。
$$\mathcal{L}_{align}(\theta)=-\mathbb{E}_{\tau}\left[\cos\left(f_\theta(\phi_t,A_t^\tau,q_t),g(\phi_{t+H})\right)\right]$$ $$\mathcal{L}=\mathcal{L}_{fm}+\lambda\mathcal{L}_{align}$$| $f_\theta$ | 从 DiT 第 $L$ 层取出的 future-token activations,经 projection 后输出 $B\times M\times D$ 表征。 |
| $g$ | 未来观测 embedding encoder,输出同样形状的 $B\times M\times D$ target。 |
| $M$ | future / embedding token 数;主设计中 Q-former 压缩为 $M=32$ tokens。 |
| $\lambda$ | alignment loss 系数;主实验中 $\lambda=0.2$,消融显示该值效果最好。 |
它与 REPA 的关系是:REPA 对齐图像 diffusion transformer 与视觉表征以加速图像生成;FLARE 则对齐 policy DiT 与 future observation embedding,用于机器人动作学习。
4.4 Action-aware Future Embedding Model
作者发现,target embedding 的选择很重要。直接使用通用视觉 encoder 的 tokens 可行,但更好的做法是训练一个 action-aware vision-language embedding model,使它既紧凑又含有控制相关信息。
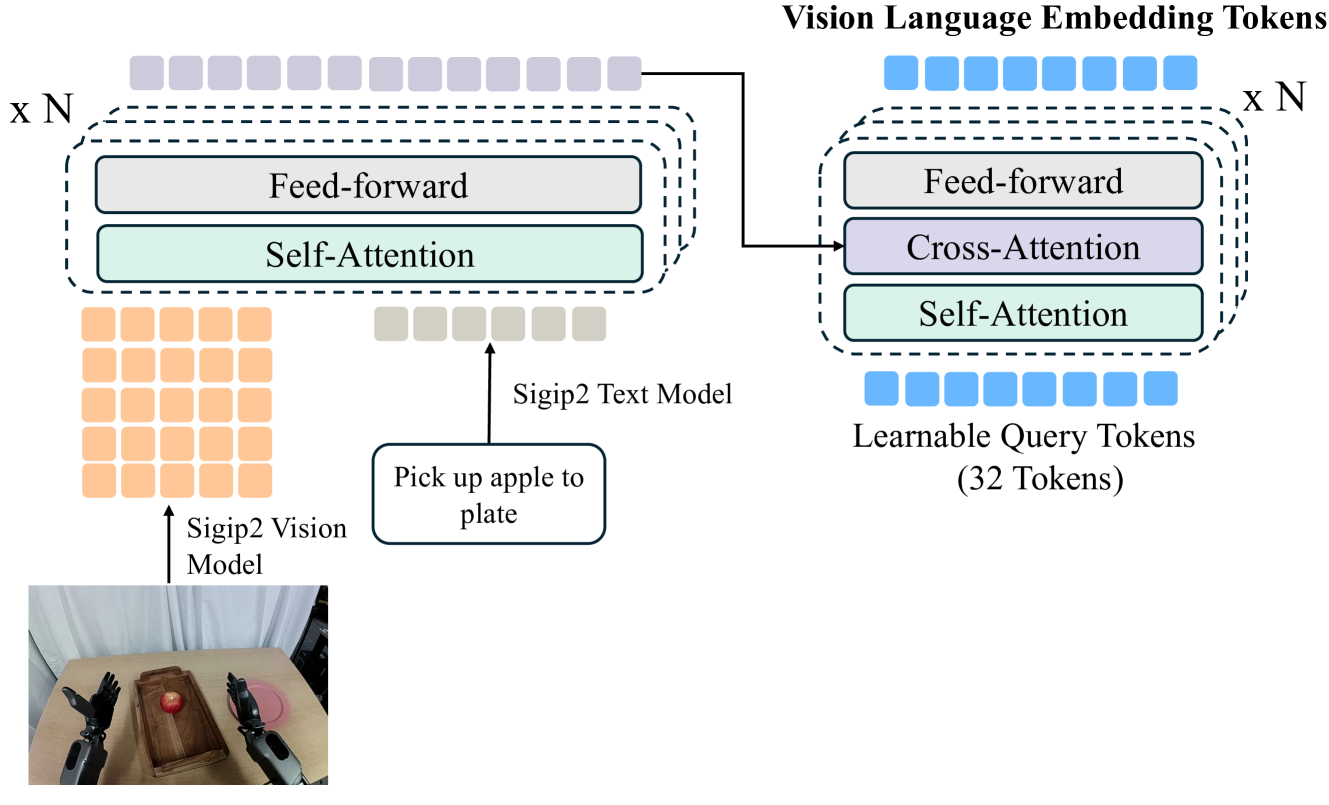
附录 A 具体结构如下:采用 siglip2-large-patch16-256 作为 vision 和 language encoder;每张 $256\times256$ 图像产生 256 个 patch tokens;语言指令 padded 后产生 32 个 language tokens;两者拼接为 288 个 tokens,经 4 层 self-attention transformer 融合;最后用 Q-former 的 32 个 learnable query tokens 压缩成 32 个 vision-language tokens。
4.5 EMA Target Update
在下游 post-training 中,target embedding model 与 policy encoder 存在 distribution shift。论文不是完全冻结 target embedding,而是用 EMA 让 target 慢速跟随 policy 的视觉语言 encoder。
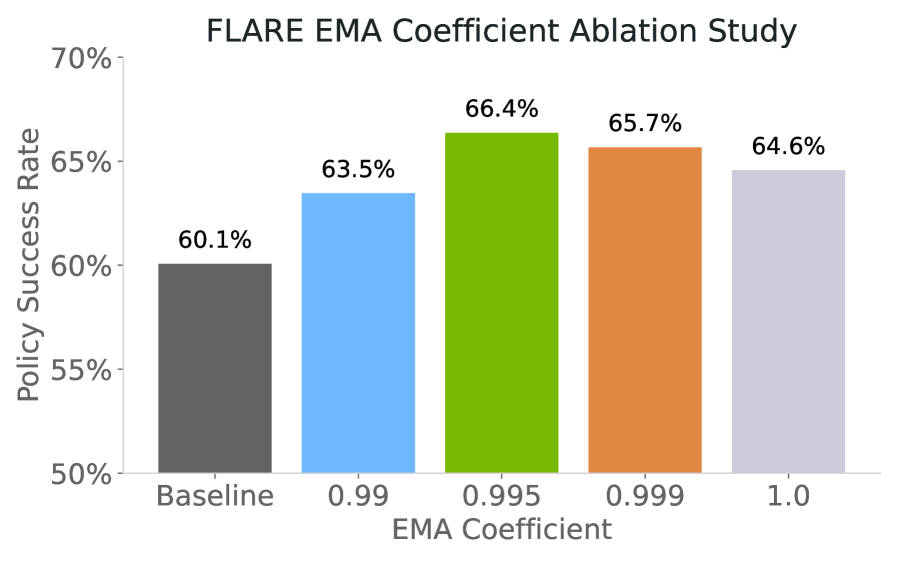
作者测试 $\rho\in\{0.99,0.995,0.999,1.0\}$,最终使用 $\rho=0.995$;即便 $\rho=1.0$ 不做 EMA,FLARE 仍超过 policy-only baseline,但 $\rho=0.995$ 最好。
4.6 训练伪代码
附录 D 给出 Python-style pseudocode。核心流程可浓缩为:
5. 实验与结果
5.1 Multitask Simulation Benchmarks

RoboCasa 包含 pick-and-place、door manipulation、faucet operation 等厨房任务,观测为 left/right/wrist 三路 RGB。GR-1 仿真包含 18 个 object rearrangement 任务和 6 个 articulated object 任务,观测为头部第一视角 RGB。
为公平比较,主 benchmark 不使用跨 embodiment 预训练 embedding model,而是在同一 in-domain multitask dataset 上预训练 embedding model 80,000 gradient steps。除 UWM 外,所有方法训练 80k steps;UWM 因 80k 结束仍在提升,延长到 400k steps。
5.2 主结果表
| Methods | FLARE | Policy Only | UWM | GR00T N1 Scratch | Diffusion Policy |
|---|---|---|---|---|---|
| Pick and Place | 53.2% | 43.8% | 35.6% | 44.1% | 29.2% |
| Open & Close Doors / Drawers | 88.8% | 78.7% | 82.0% | 80.0% | 78.7% |
| Others | 80.0% | 75.2% | 74.2% | 69.6% | 61.3% |
| 24 RoboCasa Tasks Average | 70.1% | 61.9% | 60.8% | 60.6% | 51.7% |
| Pick and Place Tasks | 58.2% | 46.6% | 30.1% | 51.8% | 40.4% |
| Articulated Tasks | 51.3% | 47.4% | 38.4% | 42.8% | 50.1% |
| 24 GR1 Tasks Average | 55.0% | 44.0% | 29.5% | 45.1% | 40.9% |
结果表显示 FLARE 在两个 benchmark 的所有汇总类别上均最高。与 policy-only 相比,RoboCasa 平均从 61.9% 提升到 70.1%,GR1 平均从 44.0% 提升到 55.0%。与 UWM 相比,FLARE 避开显式未来 VAE latent 生成,在 RoboCasa 和 GR1 上均显著更高。
5.3 Data-efficient Post-training

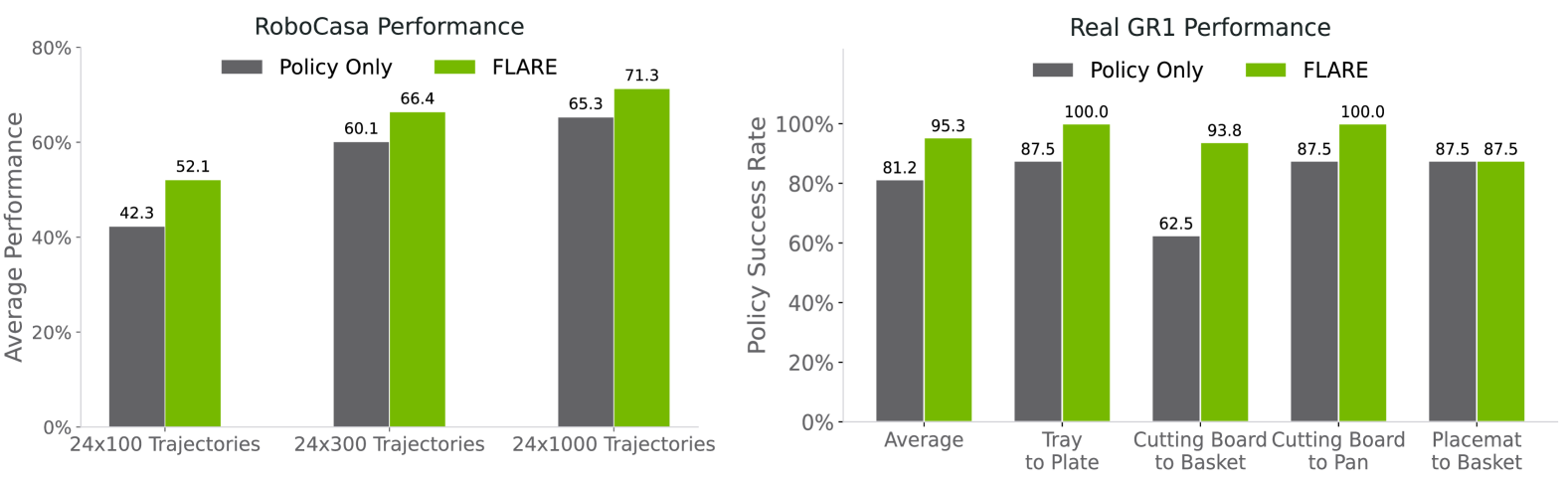
这一节评估跨 embodiment 预训练 embedding model 在未见过的 embodiment / task 上的作用。policy-only baseline 同时初始化 Q-former embedding 和 DiT weights;FLARE 只 warm start vision-language embedding,并用 pretrained embedding model 作为 future prediction target。
论文报告:在 RoboCasa 100 trajectories/task 的数据受限设置下,FLARE 比 policy-only 高 10%;在真实 GR1 上,FLARE 最高成功率 95.1%,平均比 baseline 高 14%。定性观察中,baseline 常在水瓶或易拉罐靠近手时碰倒物体,而 FLARE 学到绕过或越过物体再抓取。
5.4 Human Egocentric Videos without Action Labels
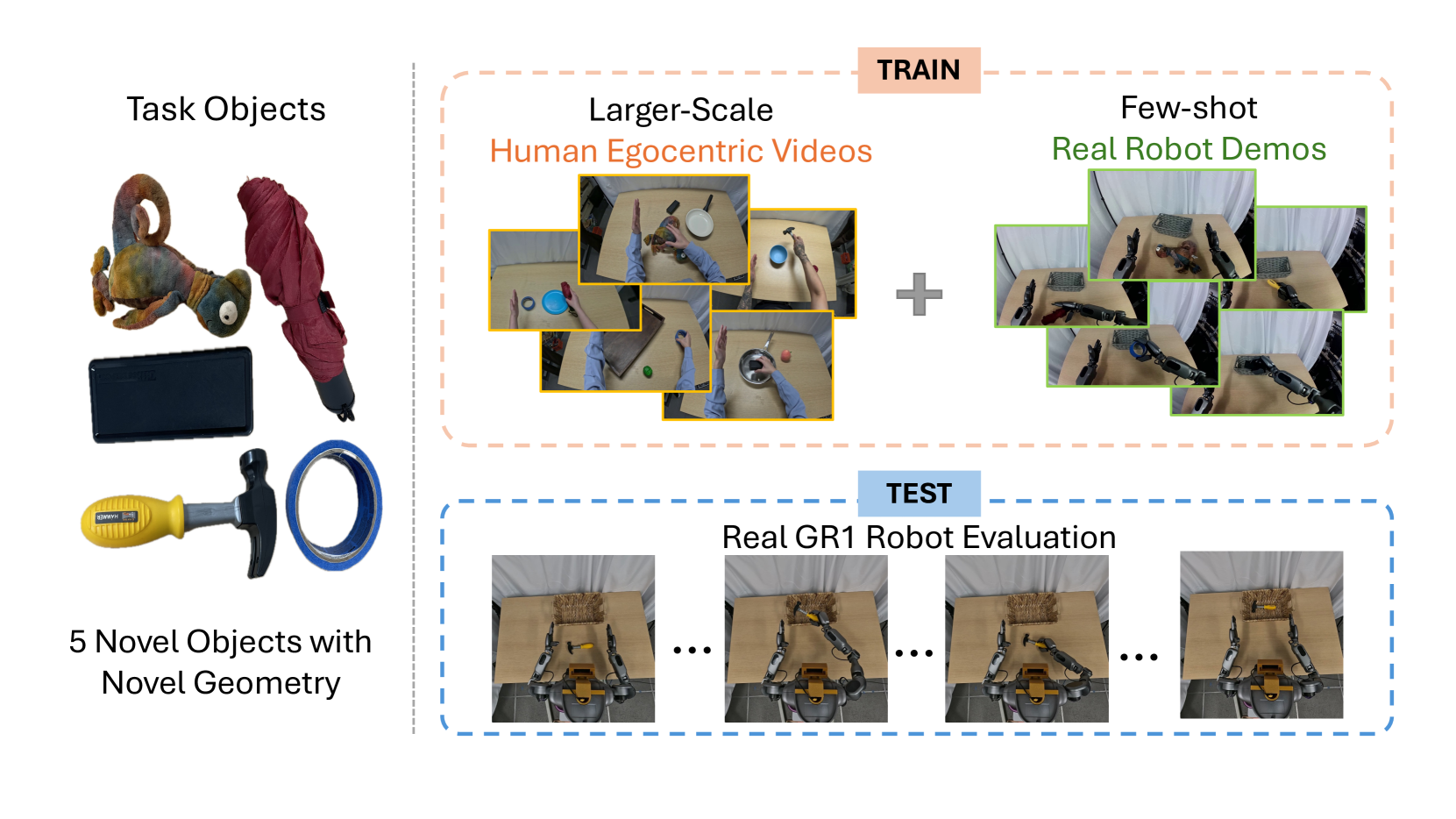
作者选取 5 个 novel objects,每个物体收集 150 条人类第一视角 demonstrations,方式是示范者头戴 GoPro 执行类似任务;机器人侧每个物体只收集最多 10 条 teleoperated demonstrations。对于 robot demos,训练时同时使用 action flow-matching loss 和 future alignment objective;对于 human egocentric videos,因为没有 action labels,只使用 future alignment loss。
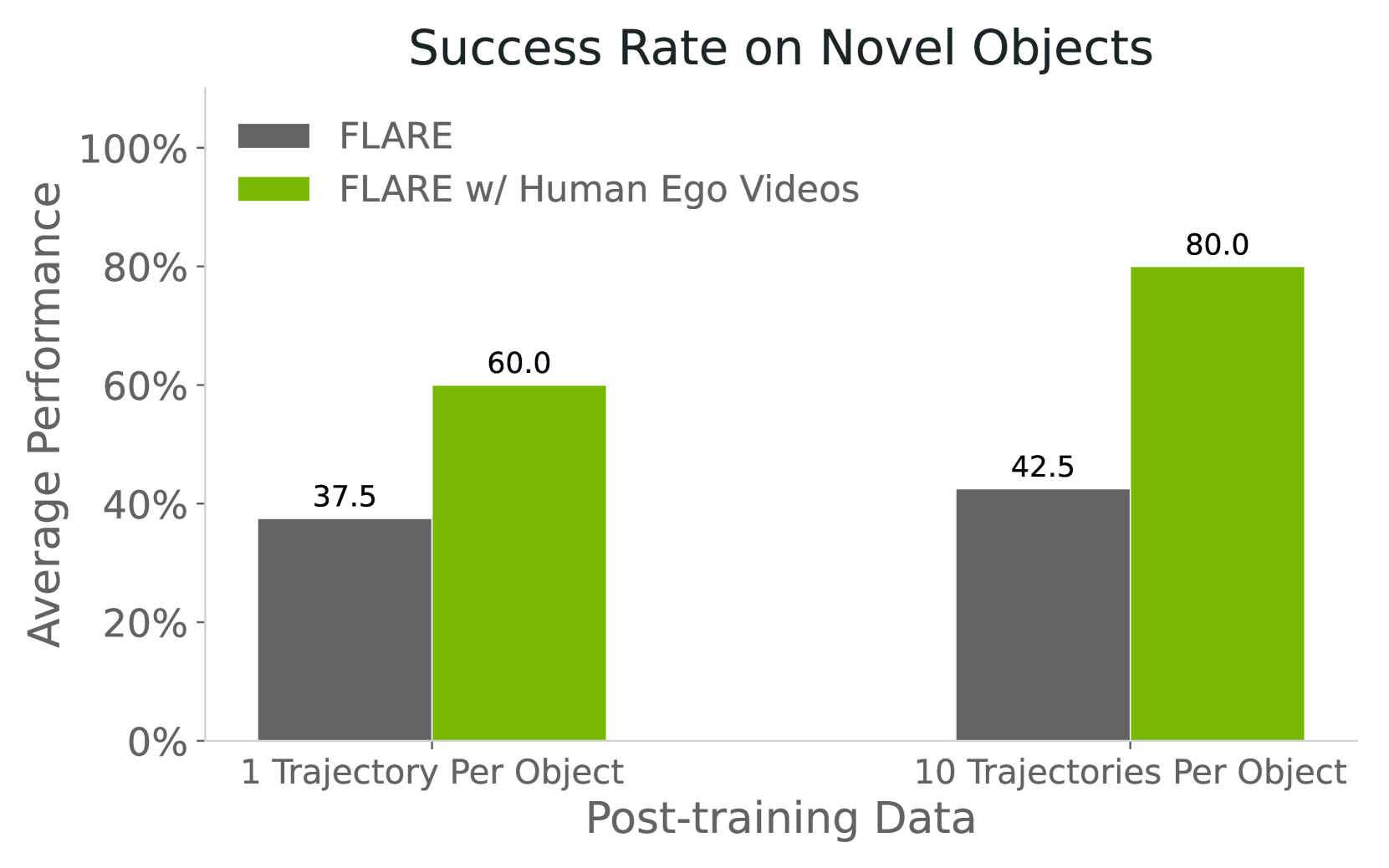
论文报告:每个物体只有 1 条 teleoperated trajectory 时,FLARE 已可达到最高 60% 成功率;每个物体 10 条机器人轨迹并联合 human videos 时,成功率提升到 80%,约为仅用 action-labeled data baseline 的两倍。项目页进一步给出一个具体数值:1-shot 不加 human video 为 37.5%,加 human egocentric videos 后为 60%。
5.5 Ablations
| Target embedding model | Success Rate |
|---|---|
| No FLARE loss | 43.9% |
| SigLIP2 | 49.6% |
| SigLIP2 average pooled | 50.9% |
| Action-aware Embedding | 55.0% |
这个表说明 FLARE 兼容通用视觉 encoder target:即使用 SigLIP2 也比 no-FLARE 高约 7%;但 action-aware embedding 最好,说明 target embedding 与控制任务对齐很重要。
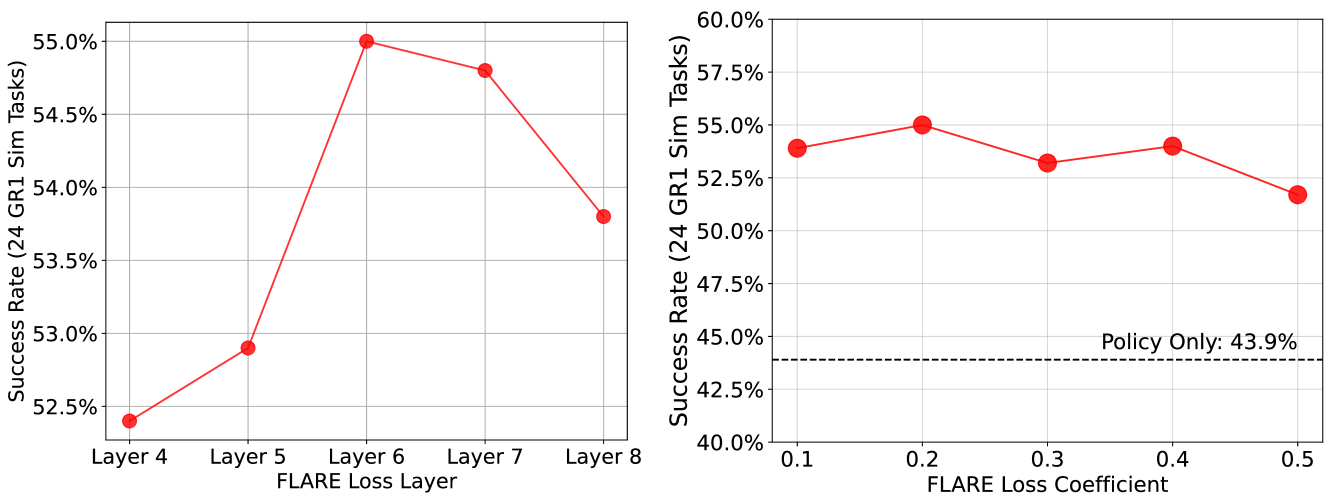
作者指出:施加 FLARE loss 的层过早,例如 layer 4,会明显下降;原因可能是 early layer 还在处理低层 action denoising 表征,过早对齐未来 embedding 会与动作预测冲突。较深层能让更多模型权重从未来监督中受益,但也要避免过强冲突。
6. 复现审计
6.1 预训练数据 mixture
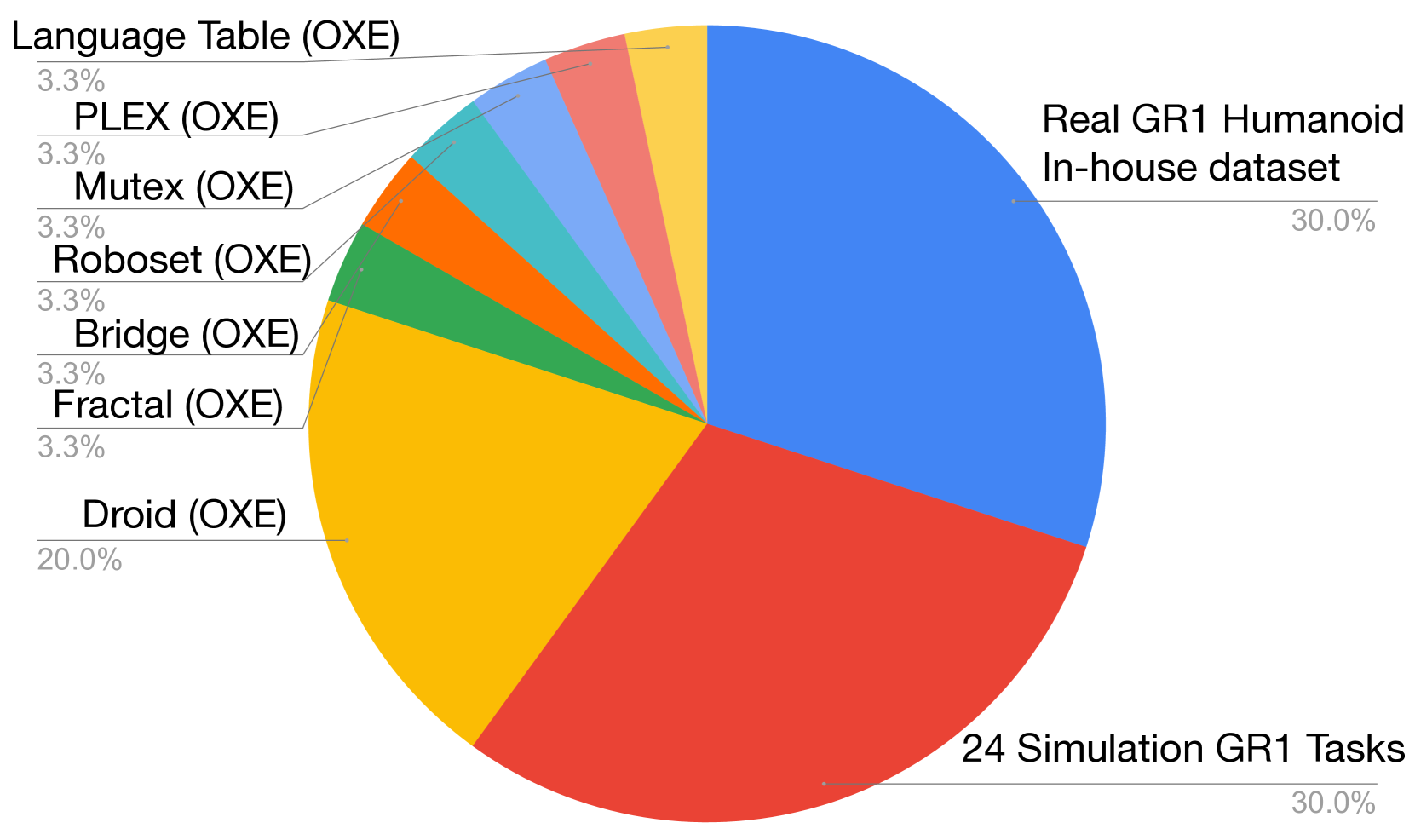
附录 B 给出了 action-aware vision-language embedding pretraining 的数据统计,总计 169.5M frames、2,989.5 小时。
| Dataset | Frames | Duration | FPS | Camera View | Category |
|---|---|---|---|---|---|
| GR-1 In-house | 6.4M | 88.4 hr | 20 | Egocentric | Real robot |
| DROID (OXE) | 23.1M | 428.3 hr | 15 | Left, Right, Wrist | Real robot |
| RT-1 (OXE) | 3.7M | 338.4 hr | 3 | Egocentric | Real robot |
| Language Table (OXE) | 7.0M | 195.7 hr | 10 | Front-facing | Real robot |
| Bridge-v2 (OXE) | 2.0M | 111.1 hr | 5 | Shoulder, left, right, wrist | Real robot |
| MUTEX (OXE) | 362K | 5.0 hr | 20 | Wrist | Real robot |
| Plex (OXE) | 77K | 1.1 hr | 20 | Wrist | Real robot |
| RoboSet (OXE) | 1.4M | 78.9 hr | 5 | Left, Right, Wrist | Real robot |
| GR-1 Simulation | 125.5M | 1,742.6 hr | 20 | Egocentric | Simulation |
| Total | 169.5M | 2,989.5 hr | -- | -- | -- |
6.2 训练超参
| 阶段 | 设置 |
|---|---|
| Embedding model pretraining | 256 NVIDIA H100 GPUs;batch size 8192;150,000 gradient steps。 |
| Optimizer | AdamW;$\beta_1=0.95,\beta_2=0.999,\epsilon=1e-8$;weight decay 1e-5。 |
| Learning rate schedule | Cosine schedule;warmup ratio 0.05。 |
| Flow-matching timestep | $p(\tau)=\text{Beta}((s-\tau)/s;1.5,1)$,$s=0.999$。 |
| Multitask experiments | 32 NVIDIA H100 GPUs;batch size 1024;80,000 gradient steps;其余超参与预训练一致。 |
| Inference denoising | $K=4$ Euler integration steps。 |
| FLARE loss | $M=32$ future/embedding tokens;主实验 layer 6 / 8;$\lambda=0.2$;EMA $\rho=0.995$。 |
6.3 复现 checklist
论文给得比较充分的信息
充分:核心公式、DiT token 结构、Q-former embedding 结构、主要 loss、主实验 benchmark、baseline、训练步数、GPU 规模、batch size、optimizer、数据表、伪代码、关键超参消融。
仍需补充:GitHub 在项目页显示 coming soon;完整数据预处理脚本、真实 GR1 控制接口、每个 benchmark 的任务配置文件、精确 model config、checkpoint、human video 对齐/采样细节没有在源码中完整开放。
最小复现路径
- 实现 SigLIP2 + 4-layer fusion transformer + Q-former 的 action-aware VL embedding module,输出 32 tokens。
- 用 GR-1/OXE/RoboSet 等 mixture 做 embedding model 预训练,并用 action flow-matching objective 保证 action-awareness。
- 实现 GR00T N1 风格 DiT flow-matching policy,输入 state token、noisy action tokens 和 future tokens。
- 在第 6 层取 future-token activations,与 target future observation embedding 做 cosine alignment。
- 训练总损失 $\mathcal{L}_{fm}+0.2\mathcal{L}_{align}$,post-training 时用 $\rho=0.995$ 的 EMA target embedding。
- 在 RoboCasa / GR1 上按 50 episodes/task 评估,每 1000 steps 评估 checkpoint,并报告最后五个 checkpoints 的最大成功率。
7. 分析、局限与边界
7.1 这篇论文最有价值的地方
从论文自己的问题设定和实验看,最有价值的地方是把 world modeling 的监督从“预测可视未来”降维成“对齐控制相关未来 latent”。这样既保留了未来预测作为 auxiliary signal 的好处,又避免 pixel/frame generation 的计算负担。它还自然解释了为什么 video-only human demonstrations 可用:无动作数据无法训练 action flow matching,但可以提供当前/未来观测对来训练 latent dynamics。
7.2 结果为什么站得住
结果的支撑来自四类证据:第一,两个 multitask simulation benchmark 覆盖单臂和 humanoid tabletop manipulation,且 FLARE 在所有主汇总指标上最高;第二,UWM 被训练到 400k steps 后仍低于 FLARE,降低了“只是训练更久”的解释;第三,target embedding、loss layer、$\lambda$、EMA 都做了消融;第四,真实 GR1 和 novel objects + human egocentric videos 说明方法不是只在仿真中有效。
7.3 作者自述局限
- 任务范围:论文主要聚焦 imitation learning 和真实 humanoid pick-and-place,尚未覆盖更复杂的精细灵巧操作。
- 训练范式:作者把 incorporating reinforcement learning 作为未来方向,当前方法主要是 imitation learning。
- 专家数据依赖:虽然能泛化到 novel objects,但仍依赖少量 expert demonstrations;在专家演示难获取时会限制可扩展性。
- 人类视频来源:论文中的 egocentric human videos 来自受控设置下的 head-mounted GoPro;扩展到更大规模、更自然环境的数据仍是未来工作。
7.4 适用边界
FLARE 适合当前观测到未来观测存在可学习 latent dynamics、且未来视觉语言 embedding 能表达任务进展的 manipulation 任务。它不直接提供显式 planning rollout,也不生成可检查的未来图像;因此若用户需要可解释的视觉预测轨迹,FLARE 的 latent world model 不如显式图像生成方法直观。
另外,FLARE 的收益依赖 target embedding 质量。通用 SigLIP2 target 可以带来提升,但 action-aware embedding 明显更好;这意味着在新领域复现时,embedding model 的数据覆盖和 action-awareness 可能成为主要瓶颈。
7.5 附录 rollout 信息

