3DFlowAction: Learning Cross-Embodiment Manipulation from 3D Flow World Model
1. Quick overview of the paper
| What should the paper solve? | The robot data action space is not uniform, such as joint angles, end poses, coordinate systems, and hardware forms, which makes cross-robot learning difficult. At the same time, generating future RGB states directly from videos is easily affected by background, robot arm appearance, and 2D plane limitations. The paper addresses the question of whether an object-centered, 3D, cross-embodiment motion representation can be used to learn motion cues from human and robot videos that can be used for real robot operations. |
|---|---|
| The author's approach | The core gripper is 3D optical flow. The author built ManiFlow-110k to extract the motion of the manipulated object in the open source human/robot video into 3D optical flow; trained a 3D flow world model based on AnimateDiff to predict the future 3D motion of the manipulated object according to language and current scene; then formed a closed-loop planning through rendering + GPT-4o verification, and used 3D flow as an optimization constraint to solve the end effector action. |
| most important results | The total success rate of the four real operation tasks reaches 70.0%, which is higher than AVDC 20.0%, ReKep 20.0%, and Im2Flow2Act* 25.0%; compared with the imitation learning method, 3DFlowAction is 70.0%, higher than PI0 50.0% and Im2Flow2Act 27.5%. Cross-platform, Franka 67.5%, XTrainer 70.0%, without hardware-specific fine-tuning. |
| Things to note when reading | The point is not "another world model", but whether 3D flow can really serve as a unified action interface. Pay special attention to: the difference between 2D flow and 3D flow, whether the GPT-4o rendering verification is reliable, whether the optimization policy can handle contact/occlusion/non-rigid bodies, and the experiment only has 10 trials per task, so statistical stability requires caution. |
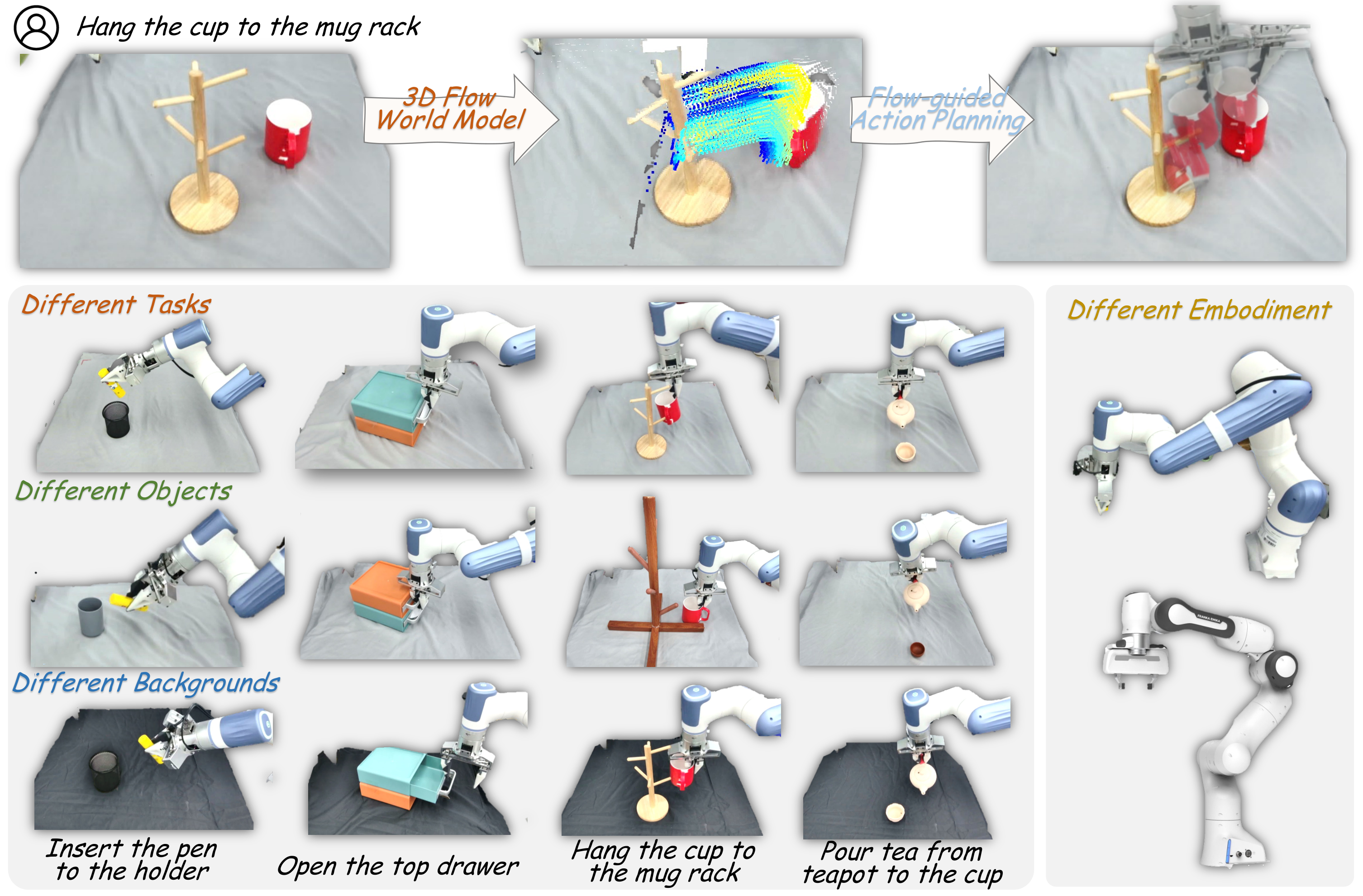
2. Motivation and problem definition
2.1 Why 3D flow is needed
The author starts from the intuition of human operation: before people perform "hanging the cup on the cup holder", they often first imagine how the object moves in space, rather than first thinking about how the joint angles change. This object motion trajectory is relatively common to humans and different robots. Therefore, the paper regards "the future 3D movement of the object" as an embodiment-agnostic action representation.
Compared with the RGB video world model, 3D flow is more centered on the object and can reduce interference from the background and the robot's appearance. Compared with 2D optical flow, 3D flow can express 3D trajectories such as movement in the depth direction, rotation, and pouring, which is especially important for tasks such as pouring tea, inserting pens, and hanging cups.
2.2 Problem setting
The input is the current RGB observation, task language and initial object point set, and the output is a temporal 3D optical flow:
The first two channels are the 2D coordinates of the image plane, the third channel is the depth, and the fourth channel is visibility. This flow describes the 3D position changes of the surface points of the manipulated object at various times in the future.
Afterwards, the system does not train a hardware-bound action head, but turns the flow into a constraint function and solves a series of end-effector poses in SE(3) through optimization.
2.3 Contribution positioning
- 3DFlowAction is proposed to use 3D optical flow as a unified, object-centric, cross-embodiment representation of robot operations.
- Build ManiFlow-110k to synthesize 110k 3D flow samples from multi-source human and robot videos via a moving object auto-detect pipeline.
- Train a 3D flow world model to learn language-conditioned object 3D motion patterns from large-scale flow demonstrations.
- Proposed flow-guided rendering + GPT-4o verified closed-loop planning, as well as task-aware grasp pose generation and flow-conditioned optimization policy.
- Validating generalization on four complex real-world tasks, across robotic platforms, OOD objects, and contexts.
4. Detailed explanation of method
4.1 ManiFlow-110k: Extract 3D flow from original video
The paper first requires a large amount of data on "how objects move". Open source robot/human videos often have cluttered backgrounds, similar objects, and robotic arm grippers, which are easily detected incorrectly by standard detectors. The author proposes a moving object detection pipeline:
- Segment the gripper mask at the first frame using Grounding-SAM2.
- Sample points in the entire image in the first frame and exclude points falling within the gripper mask.
- Track these points with CoTracker3 to find points of significant motion in the video.
- Use the maximum bounding box of these motion points to locate the manipulated object.
- Use CoTracker3 again to extract the object 2D optical flow.
- Remove camera motion flow if necessary.
- Use DepthAnythingV2 to predict depth and project 2D flows into 3D.
The author verified that the moving object detection accuracy of this pipeline exceeds 80% on BridgeV2. Finally, 110k 3D flow instances were generated from open source data such as BridgeV2, RT1, AgiWorld, Libero, RH20T-Human, HOI4D, DROID, etc.
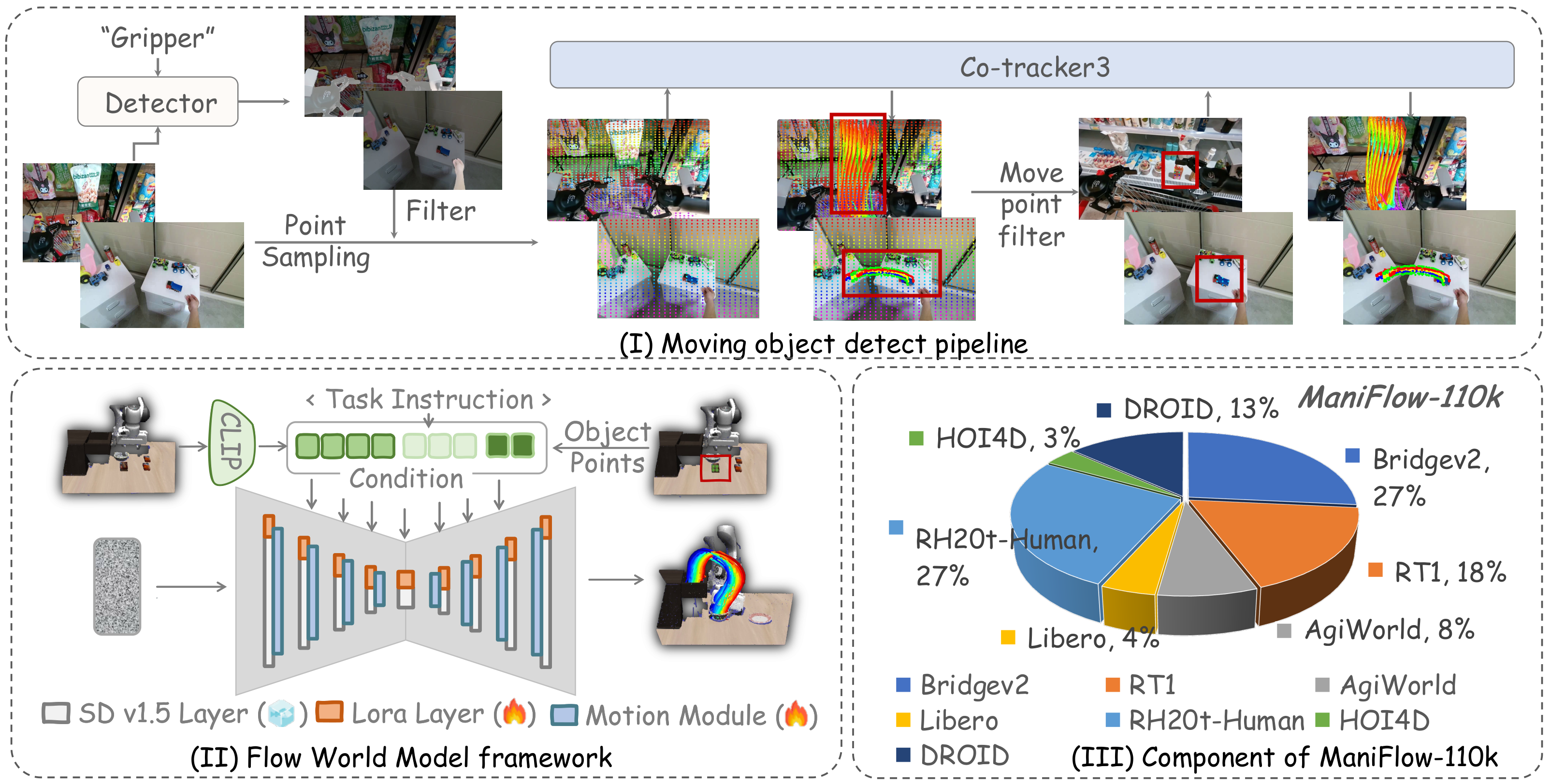
4.2 3D Flow World Model
The model goal is to generate a time-varying 3D flow $F$ based on the initial RGB observation, task prompt, and initial point $F_0$. The author follows the idea of Im2Flow2Act and uses AnimateDiff as the optical flow generator, but makes key adjustments:
- RGB observation and task prompt are encoded with CLIP encoder.
- The initial point $F_0$ uses sinusoidal positional encoding.
- The image VAE latent of 3D flow is not compressed into Stable Diffusion because the author found it difficult for VAE to encode depth information.
- Directly input the 3D flow into U-Net and train the motion module to model temporal dynamics.
- The SD body only inserts the LoRA layer to retain the pre-training generation capability; the motion module is trained from scratch.
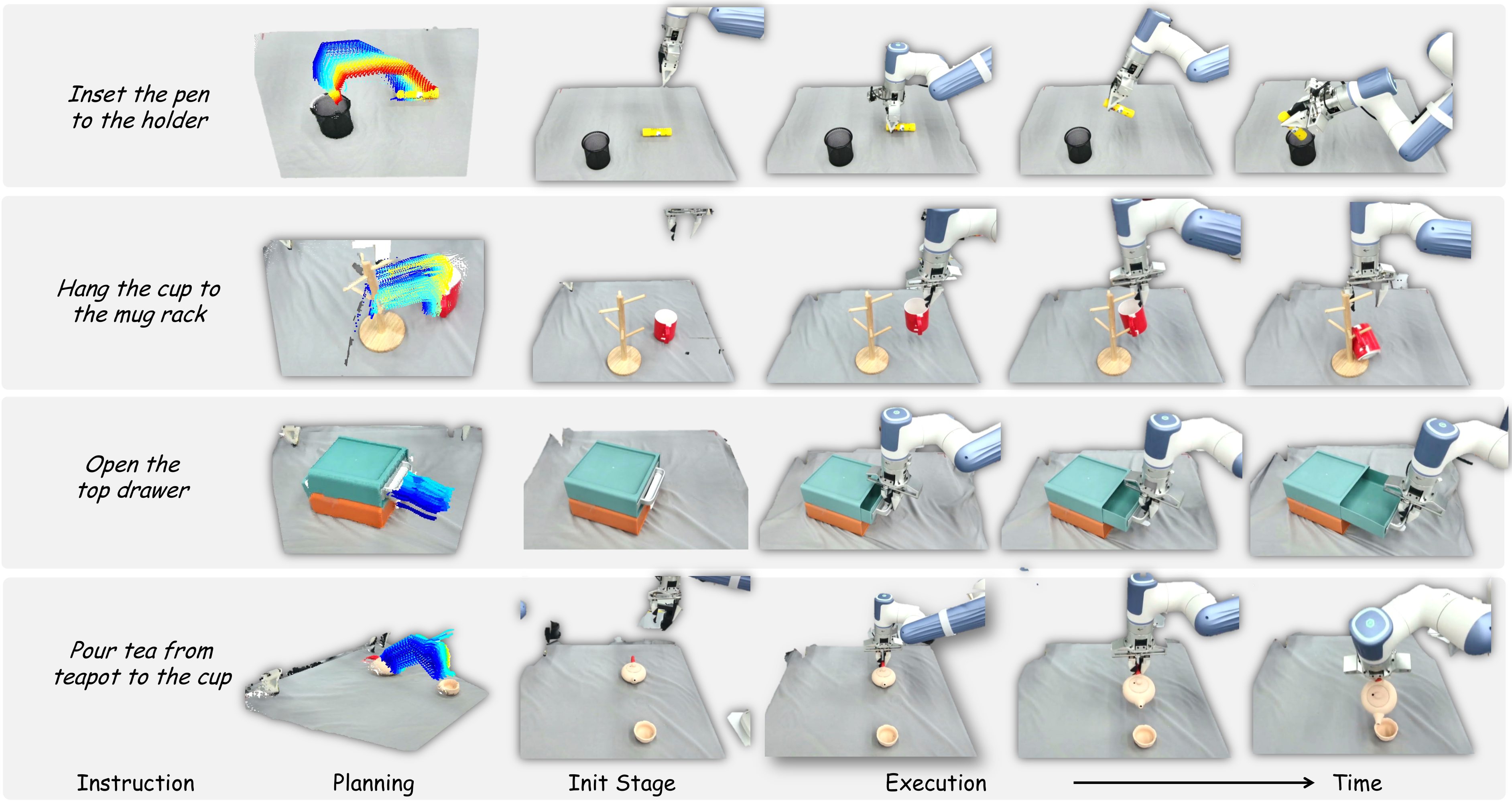
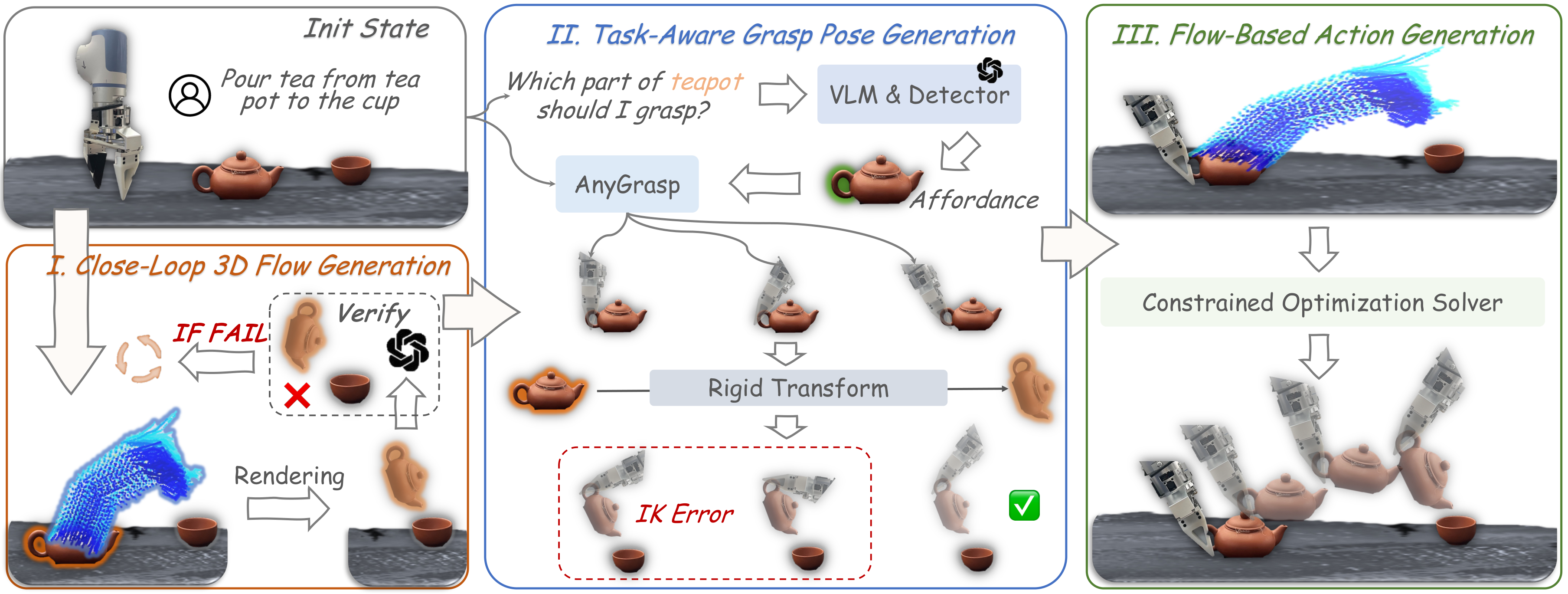
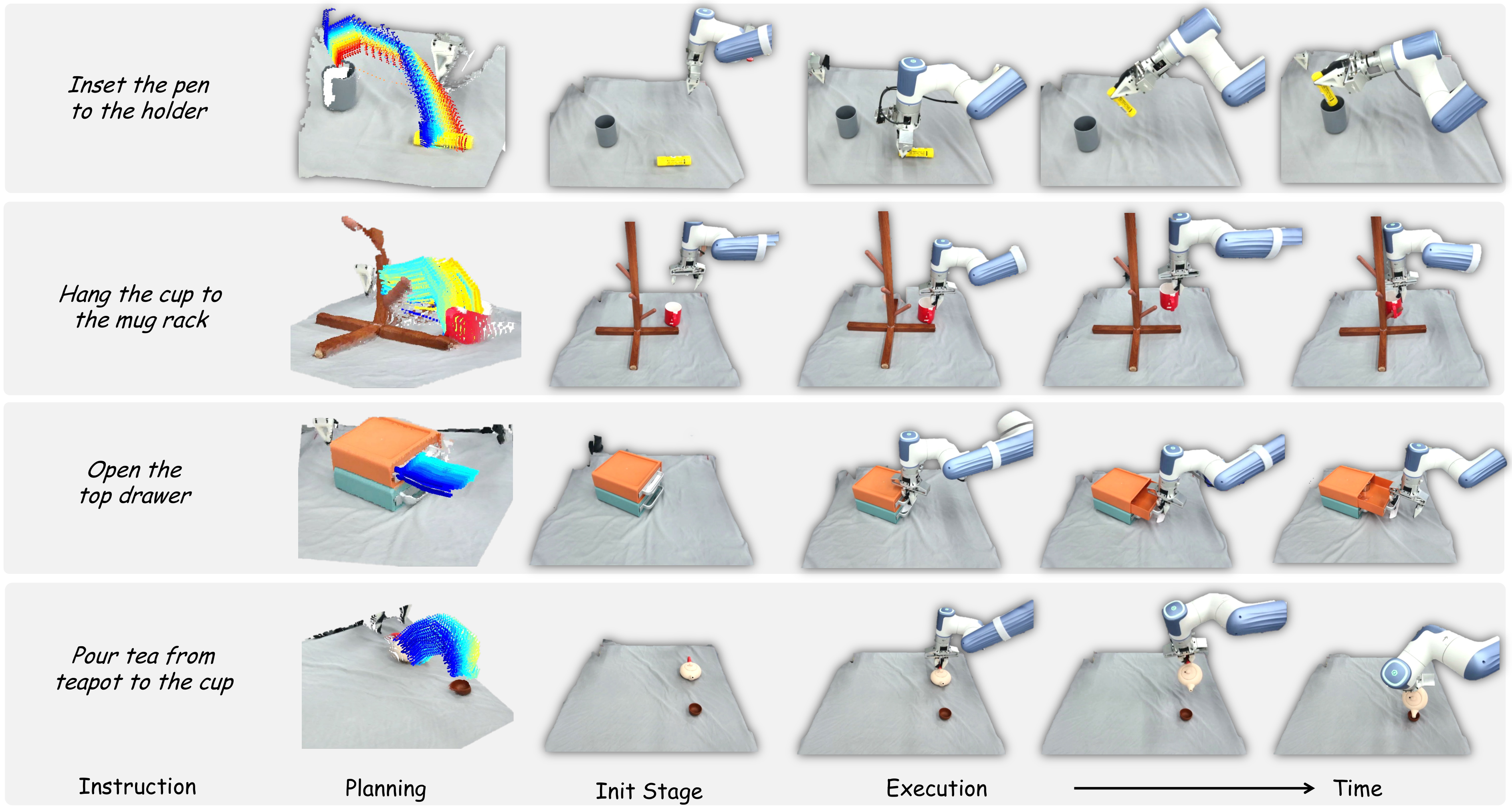
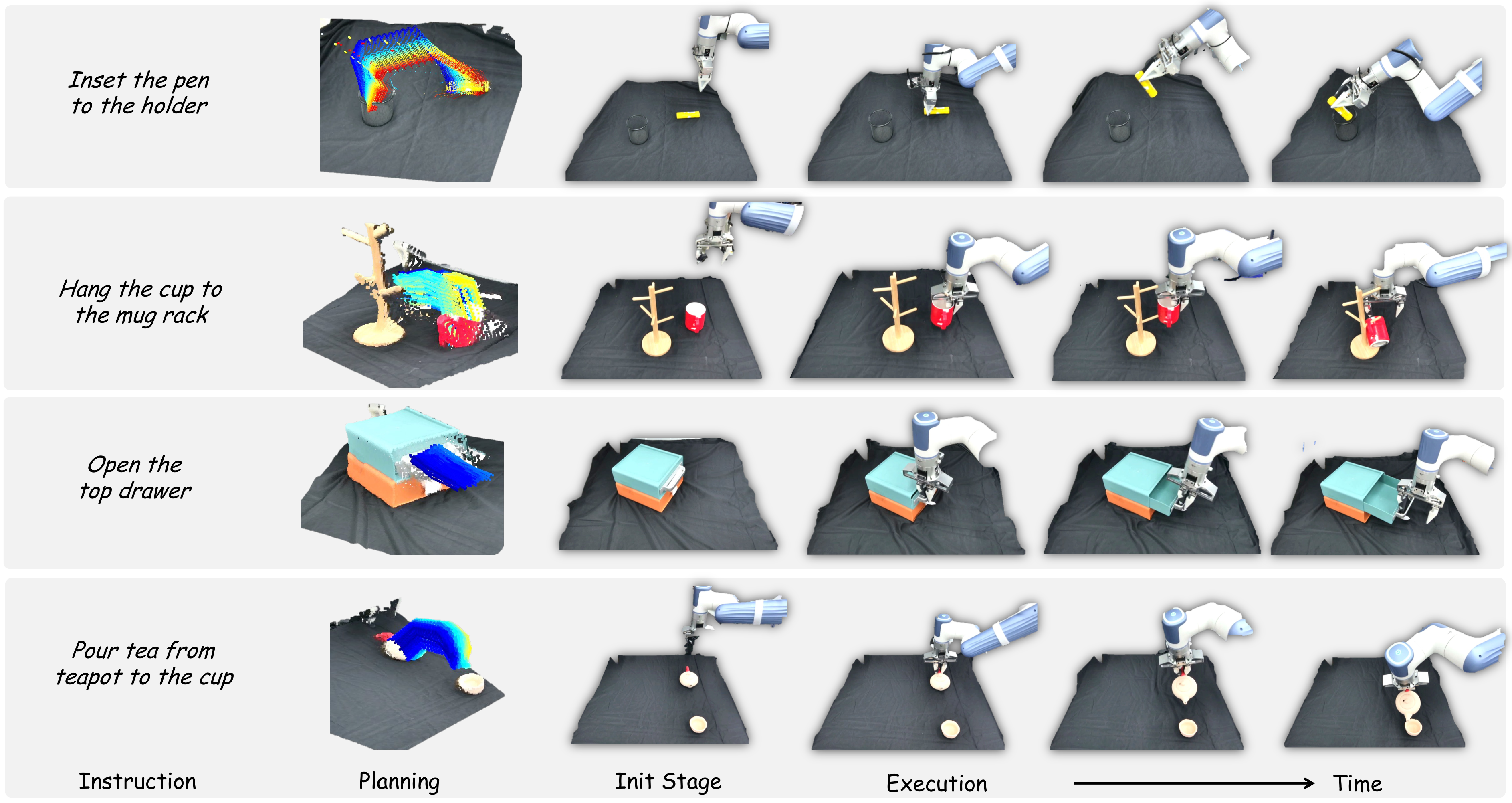
4.3 Closed-Loop Motion Planning
3D flow predictions can still be wrong. To improve stability, the author designs an object-centric target state rendering machine. Assume the flow points at the first moment are $P_1$ and the last moment are $P_2$. Use SVD to estimate the rigid body transformation between the two:
Then apply $T$ to the initial point cloud of the manipulated object to obtain the predicted target state, and then put it back into the current 3D scene point cloud and reproject it into a 2D image. Finally, input the task instructions and predicted images into GPT-4o to determine whether the flow is aligned with the task; if it fails, re-predict the flow. This mechanism changes one-time world model sampling into closed-loop planning with verification.
4.4 Task-Aware Grasp Pose Generation
If you choose the wrong grabbing pose, the target location may be unreachable or the task may not be completed. The author asked GPT-4o to output the part of the object that should be grasped according to the task, and then used AnyGrasp to generate candidate grasping poses around the part. Since AnyGrasp itself does not know the task, the system will use the previously estimated transformation matrix $T$ to transform the candidate grasping pose to the target state, and use robot IK to check the reachability, thereby selecting a task-related and reachable grasping pose.
4.5 Flow-Based Action Generation
Action generation is formulated as constrained optimization. First, select $N$ key points from the object surface through farthest point sampling, and obtain the predicted 3D flow corresponding to these points. The goal of each time step $t$ is to make the current object key point reach the position predicted by the flow world model:
IK and collision detection are also added to the real scene. The decision variable of the single-arm robot is the end-effector pose, which is a 6-dimensional variable of position and Euler angles; the position is limited by workspace bounds, and the rotation is limited to the lower hemisphere. The optimization implementation follows the ReKep style. In the first iteration, Dual Annealing is used for global search, and then SLSQP is used for local optimization; subsequent iterations are initialized with the previous stage solution and only perform local optimization.
5. Experiments and results
5.1 Experimental setup
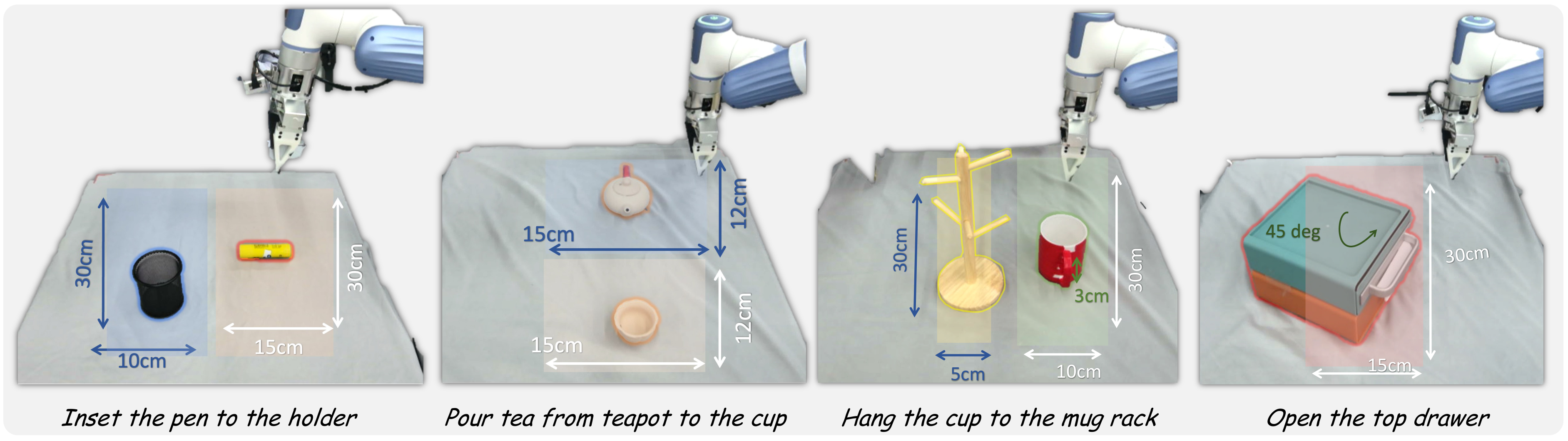
The experiment focused on four basic but space-intensive tasks: pouring tea from the teapot into the cup, inserting the pen into the pen holder, hanging the cup on the cup holder, and opening the upper drawer. Each setting is run 10 times, with random object poses, and the success rate is reported. The real hardware uses a Dobot XTrainer, and the perception uses a Femto Bolt camera, located on the opposite side of the robot, providing a third-person perspective.
In terms of fine-tuning data, the author manually collected 30 human hand demonstrations for each task, excluding robot action labels, which took about 10 minutes per task for fine-tune 3DFlowAction.
5.2 Comparison with manipulation world models
| Task | AVDC | ReKep | Im2Flow2Act* | 3DFlowAction |
|---|---|---|---|---|
| Pour tea from teapot to cup | 1/10 | 2/10 | 2/10 | 6/10 |
| Insert pen in holder | 2/10 | 1/10 | 2/10 | 7/10 |
| Hang cup to mug rack | 0/10 | 3/10 | 0/10 | 5/10 |
| Open top drawer | 5/10 | 2/10 | 6/10 | 10/10 |
| Total | 20.0% | 20.0% | 25.0% | 70.0% |
Im2Flow2Act* replaces the learnable action policy of the original method with the 2D flow baseline after the optimization process. 3DFlowAction takes the lead in all tasks, indicating that 3D flow is more expressive for tasks involving depth and rotation such as pouring tea, inserting pens, and hanging cups.

5.3 Cross-embodiment experiments
| Task | Franka | XTrainer |
|---|---|---|
| Pour tea from teapot to cup | 7/10 | 6/10 |
| Insert pen in holder | 7/10 | 7/10 |
| Hang cup to mug rack | 4/10 | 5/10 |
| Open top drawer | 9/10 | 10/10 |
| Total | 67.5% | 70.0% |
The authors emphasize that this experiment did not involve robot-related fine-tuning. Since 3D flow describes object movement rather than robot action, in theory, as long as the new robot can achieve the object movement through IK and optimization, it can be executed across platforms.
5.4 Comparison with imitation learning methods
| Task | PI0 | Im2Flow2Act | 3DFlowAction |
|---|---|---|---|
| Pour tea from teapot to cup | 5/10 | 4/10 | 6/10 |
| Insert pen in holder | 5/10 | 2/10 | 7/10 |
| Hang cup to mug rack | 4/10 | 0/10 | 5/10 |
| Open top drawer | 6/10 | 5/10 | 10/10 |
| Total | 50.0% | 27.5% | 70.0% |
PI0, as the VLA/flow action model baseline, performs well but is still lower than 3DFlowAction. The key comparison here is: 3DFlowAction does not use robot teleoperation action labels, while PI0/Im2Flow2Act class methods require action data or simulation data.
5.5 OOD Object and Background Generalization
| Task | Object Generalization | Background Generalization | ||||
|---|---|---|---|---|---|---|
| AVDC | PI0 | 3DFlowAction | AVDC | PI0 | 3DFlowAction | |
| Pour tea | 0/10 | 3/10 | 4/10 | 0/10 | 4/10 | 4/10 |
| Insert pen | 2/10 | 6/10 | 6/10 | 0/10 | 1/10 | 4/10 |
| Hang cup | 0/10 | 2/10 | 4/10 | 0/10 | 3/10 | 4/10 |
| Open drawer | 4/10 | 5/10 | 8/10 | 0/10 | 5/10 | 8/10 |
| Total | 15.0% | 40.0% | 55.0% | 0.0% | 32.5% | 50.0% |
AVDC drops to 0 during background generalization, indicating that RGB future state generation is greatly disturbed by background changes. Although 3DFlowAction also decreased, it remained around 50%, consistent with the expectation that object center representation is more resistant to background changes.
5.6 Ablation: Closed-loop planning and large-scale pre-training
| Method | Large-scale Pretrain | Rendering Machine | Success Rate | Pour tea | Insert pen | Hang cup | Open drawer |
|---|---|---|---|---|---|---|---|
| Variant 1 | Yes | No | 50.0% | 3/10 | 5/10 | 3/10 | 9/10 |
| Variant 2 | No | Yes | 30.0% | 3/10 | 3/10 | 2/10 | 4/10 |
| 3DFlowAction | Yes | Yes | 70.0% | 6/10 | 7/10 | 5/10 | 10/10 |
After turning off the rendering machine, the average drop is 20 points, indicating that GPT-4o verification and re-prediction are indeed useful; after removing ManiFlow-110k large-scale pre-training, the drop is 40 points, indicating that the downstream 10 to 30 human demonstrations per task are not enough to learn a stable 3D flow from scratch.
6. reproducibility Key Points
6.1 Data and annotation process
- Collection of human/robot videos from multiple sources, including BridgeV2, RT1, AgiWorld, Libero, RH20T-Human, HOI4D, DROID.
- Identifying grippers and filtering gripper points with Grounding-SAM2.
- Use CoTracker3 to find motion points and extract 2D object flow.
- Use DepthAnythingV2 to project 2D flow into 3D flow.
- The downstream tasks collect 10 to 30 human hand demonstrations per task, and the main experiment of the paper is 30 per task and takes about 10 minutes.

6.2 Training details
| parameters | value |
|---|---|
| Model base | AnimateDiff + Stable Diffusion v1.5 layers + motion module + LoRA |
| Training data | ManiFlow-110k |
| Learning rate | 0.0001 |
| Batch size | 512 |
| Epochs | 500 |
| Optimizer | AdamW |
| Weight decay | 0.01 |
| Epsilon | 1e-8 |
| Compute | 8x8 V100, about 2 days |
6.3 Optimization process
- The single-arm robot decision variable is the 6D end-effector pose, including position and Euler angles.
- The initial solution uses Dual Annealing global search, and then uses SLSQP local optimization.
- Subsequent iterations are initialized with the previous stage solution, and only local optimization is performed to increase the frequency.
- The optimization goal is to get the object's key points to the 3D positions predicted by the flow world model, taking into account IK and collision detection.
fig_2025/*.pdf figure, and converted 9 paper figures into PNG images that can be opened directly in HTML.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
The most valuable aspect of this paper is that it transforms the problem of cross-robot action learning from "unified robot action space" to "unified object 3D motion space". 3D flow is both more object-centered than RGB video and better expressive of depth and rotation than 2D flow, so it does have the potential to become a common interface between human video, robot video, and different hardware.
The second value point is that the system links are relatively complete: data construction, flow world model, closed-loop flow verification, grabbing pose selection and action optimization are all connected. It does not just show flow prediction visualization, but uses flow to achieve real robot task success rates.
7.2 Why the results hold up
- The main experiment included four tasks with different spatial requirements: pouring tea, inserting pens, hanging cups, and opening drawers, covering pouring, rotating, aligning, and pulling.
- At the same time, compared with video world model, VLM code constraints, 2D flow world model, VLA/imitation learning method, it is not just a single baseline.
- Cross-platform Franka has a similar success rate to XTrainer, supporting the claim of 3D flow as a cross-embodiment representation.
- OOD object and background experiments show that object-centered 3D flow is more resistant to background changes than RGB video generation.
- Ablation clearly shows that both the rendering machine and large-scale pretraining contribute significantly to the final success rate.
7.3 Main limitations
- Non-rigid bodies and severe occlusion: The author clearly points out that flexible objects, strong occlusion and complex non-rigid body deformation will make it difficult to model 3D optical flow, which will result in the inability of the action policy to output effective actions.
- Dependence on depth estimation quality: DepthAnythingV2 estimates depth from monocular video and then projects it into 3D flow; depth deviation will directly contaminate the 3D trajectory.
- Rely on GPT-4o verification: Closed-loop rendering uses GPT-4o to determine whether the predicted final state meets the task. The evaluation criteria are not completely transparent and will also introduce delays and external service dependencies.
- The number of trials is small: With 10 runs per task, the difference in success rates is large, but the statistical confidence intervals should still be cautious.
- Optimizing policy still requires engineering assumptions: Assumptions such as IK, collision, workspace bounds, grasp candidate, and rigid transform are critical to real tasks and cannot be solved end-to-end by pure learning models.
- Mainly single-arm rigid object manipulation: Dual-arm cooperation, deformable objects, tool contact, and long-term closed-loop operation have not yet been demonstrated.
7. 4 Boundary conditions
| Applicable conditions | Conditions that require caution |
|---|---|
| The manipulated object can be approximated as a rigid body and key surface points can be tracked. | Cloth, rope, liquid, soft object or strong non-rigid body deformation. |
| Tasks can be expressed through object target poses/trajectories. | Tasks rely on force control, touch, hidden states, or complex contact patterns. |
| Single-arm robots can predict object trajectories through IK. | The end is unreachable, the grab point is unstable, or re-grasp is required. |
| Allow GPT-4o to do plan verification and reforecasting. | Real-time, safety-critical, offline deployments or systems that cannot call external VLM. |
8. Preparation for group meeting Q&A
Q1: What is the biggest difference between 3DFlowAction and Im2Flow2Act?
Im2Flow2Act mainly uses 2D optical flow, which cannot fully express depth direction movement and 3D rotation; 3DFlowAction uses 2D coordinates, depth and visibility to form a 3D flow, and directly uses the 3D flow as an optimization constraint.
Q2: Why not use RGB video world model?
RGB video world model needs to generate background, robot appearance and irrelevant objects, which is computationally intensive and easily affected by OOD background. 3D flow only focuses on the movement trajectory of the manipulated object, which is more centered on the object and is more suitable for direct conversion into action constraints.
Q3: What does GPT-4o do in the system?
Two key uses: first, after flow-guided rendering, determine whether the predicted final state meets the task and decide whether to re-predict the flow; second, output the part of the object that should be grasped according to the task description to assist in selecting task-aware grasp pose.
Q4: Why can methods span embodiments?
Because the world model outputs the movement of objects in 3D space, not the specific actions of a certain robot. Different robots only need to implement the same object trajectory through their own IK, workspace bounds and optimizers.
Q5: What is the strongest evidence?
Cross-platform experiments and ablation are the most critical: Franka 67.5% and XTrainer 70.0% support cross-embodiment; removing large-scale pre-training drops from 70% to 30%, indicating that ManiFlow-110k is the core support.
Q6: What is the most likely place to be questioned?
Only 10 trials per task, relies on GPT-4o, relies on monocular depth and rigid/trackable object assumptions. In real deployment, these links may become sources of failure.