WorldVLA: Towards Autoregressive Action World Model
1. Quick overview of the paper
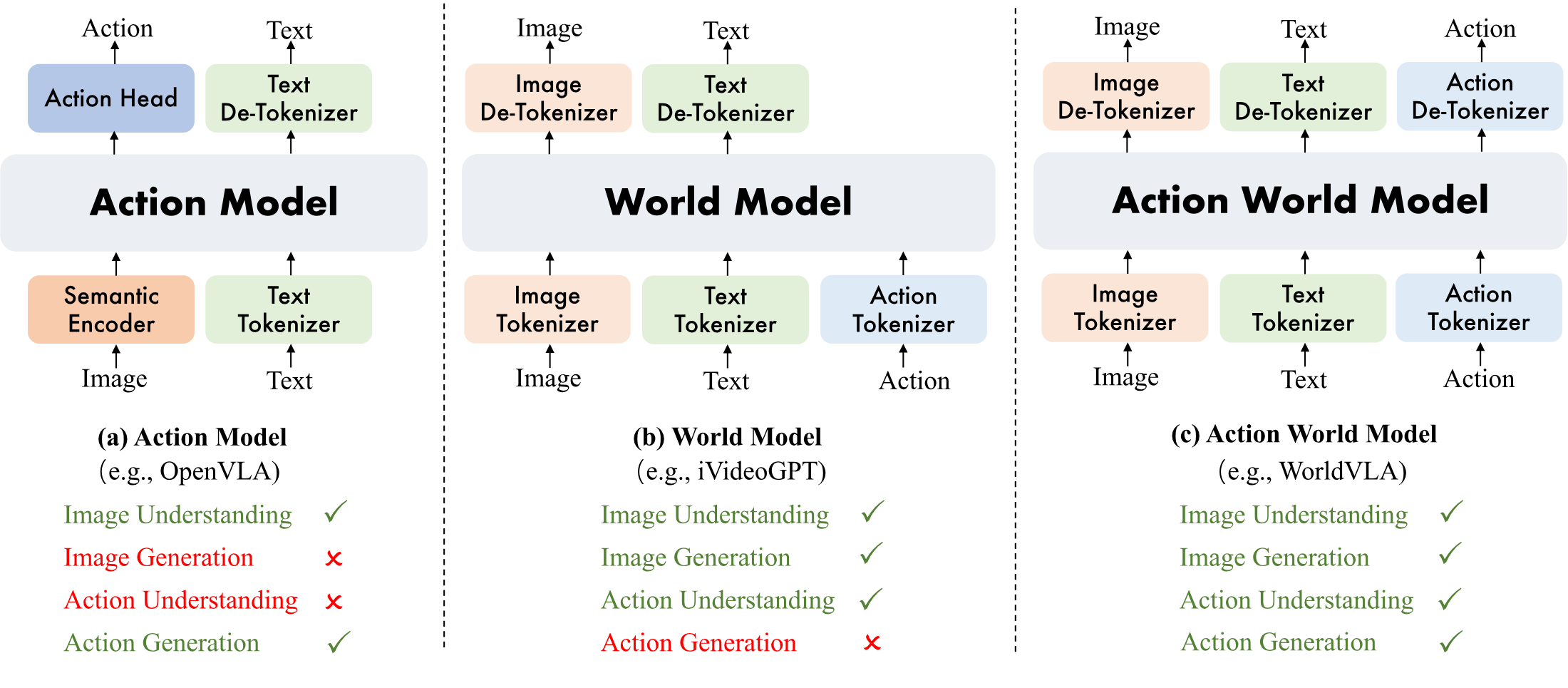
| What should the paper solve? | Existing VLA models usually only use actions as output and lack the ability to use actions as input to understand environmental dynamics; the world model can predict future visual states based on actions, but cannot directly output robot actions. WorldVLA attempts to unify these two categories of functionality. |
|---|---|
| The author's approach | Discretize text, images and 7-dimensional robot actions into tokens, and mix training action loss and world loss in an autoregressive LLM; and design an attention mask for action chunk generation that only looks at text and images and does not look at previous action tokens. |
| most important results | On LIBERO, WorldVLA 512×512 achieved an average success rate of 81.8% without large-scale robot pre-training, which is higher than OpenVLA's 76.5%. Compared with action model alone, the average SR of action-world joint training increased from 62.8% to 67.2%, and with action chunk and new mask, it increased from 76.6% to 78.1%. |
| Things to note when reading | The paper has no appendices, and many implementation hyperparameters are only given in the text; "WorldVLA" in the table sometimes refers to action-world joint training, and sometimes refers to the 256/512 resolution model, which needs to be distinguished in conjunction with the table column headers. |
keywords
Vision-Language-Action World Model Autoregressive Modeling Action Chunking LIBERO
core contribution
- Unify the understanding and generation of actions and images.The paper proposes WorldVLA, which combines action model and world model into the same autoregressive action-world model.
- Point out the error propagation problem of discrete autoregressive action chunk.The author observed that under ordinary causal mask, subsequent actions will rely on the previously generated action tokens, and if the previous actions are wrong, they will continue to bias the later actions.
- Propose action attention mask.Mask historical action tokens when generating the current action, so that each action is mainly determined by text and visual input, thereby reducing performance degradation when the action chunk length increases.
- Experiments demonstrate two-way enhancement.World model training improves action success rate, and action model training also improves long video prediction quality, especially the 50-frame FVD dropped from 718.6 to 674.1.
2. Motivation and related work
2.1 Problems to be solved
The paper divides the robot model into two complementary but incomplete capabilities: the VLA/action model outputs actions based on images and language, and the world model predicts future visual states based on the current visual state and actions. The former can perform tasks, but actions are mostly regarded as final outputs; the latter can model environmental changes caused by actions, but cannot directly give control strategies.
The motivation for WorldVLA is that if a model wants to both generate actions and imagine the next frame based on the actions, it will be forced to learn visual semantics, action semantics, and physical transfer relationships simultaneously during training. The author calls this the mutual enhancement of action model and world model.
2.2 Related work context
| Technical line | Representation method | Positioning in the paper | WorldVLA Differences |
|---|---|---|---|
| Vision-Language-Action Model | RT-1/RT-2, OpenVLA, $\pi_0$, diffusion VLA | Use MLLM or a visual backbone plus an action head to map observations and instructions to actions. | It not only predicts actions, but also uses actions as input to train predictions for the next frame, allowing the model to learn action-conditioned dynamics. |
| Video / World Model | MAGVIT, SVD, Cosmos, iVideoGPT, DWS | Video generation can be used to "imagine the future"; the world model further uses actions to control future states. | WorldVLA retains both world prediction and action output, instead of just generating video or only making strategy selection. |
| Unified Understanding and Generation | Chameleon, Emu3, Transfusion, Janus, UVA | Unify understanding and generation into the same model or system. | WorldVLA chooses the discrete token + autoregressive LLM route; UVA serves as a continuous diffusion head control in the action-world direction. |
2.3 Comparison table of method types
| Model Type | Discrete | Continuous | Input | Output |
|---|---|---|---|---|
| Action Model | OpenVLA | $\pi_0$ | T + V | A |
| Video Prediction Model | MAGVIT | SVD | T + V | V |
| World Model | iVideoGPT | DWS | T + V + A | V |
| Action World Model | WorldVLA | UVA | T + V + A | V + A |
3. Detailed explanation of method
3.1 Overall architecture
WorldVLA is initialized from Chameleon, because Chameleon itself is a discrete token model that unifies image understanding and image generation. On this basis, the paper adds three types of tokenizers: image tokenizer, text tokenizer, and action tokenizer. All modalities end up in the same sequence of autoregressive tokens.
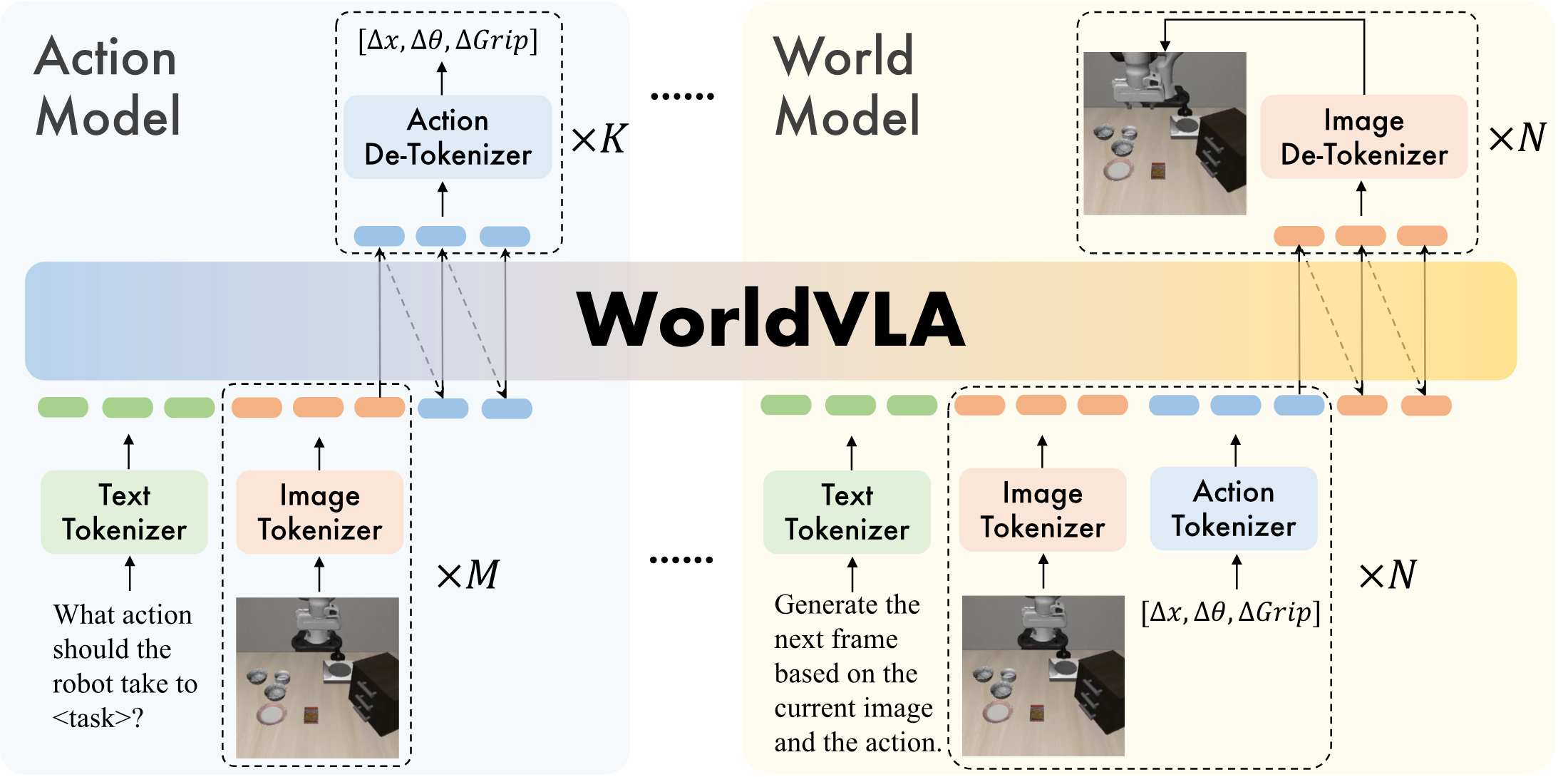
| components | The settings given in the paper | function |
|---|---|---|
| Image tokenizer | VQ-GAN; compression rate 16; codebook size 8192; 256×256 image generation 256 tokens, 512×512 image generation 1024 tokens. | Discretize the image so that LLM can generate image tokens like text tokens. |
| Text tokenizer | BPE tokenizer; vocabulary size 65, 536, including 8192 image tokens and 256 action tokens. | Unified vocabulary entry for text, image, and action tokens. |
| Action tokenizer | Each continuous action dimension is discretized into 256 bins; an action is represented by 7 tokens: 3 relative positions, 3 relative angles, and 1 absolute gripper state. | Turn the robot control variables into discrete tokens that can be predicted by the autoregressive model. |
3.2 Action Model Data
The task of the action model is to generate actions based on language instructions and image observations. The text prompt form used in the paper is:
The sequence form is:
Here $M$ is the number of input historical images, and $K$ is the length of the action chunk output at one time. During training, only the cross-entropy loss $\mathcal{L}_{action}$ on the action token is calculated.
3.3 World Model Data
The world model's task is to generate the next frame based on the current image and current action. The paper emphasizes that it does not require task instruction, because after a given action, the next state is mainly determined by the current state and action. The text prompt used is:
$N$ represents the number of rounds of continuous prediction of the next frame; the paper defaults to $N=1$ to save calculations. During training, only the loss of the generated image token is calculated.
3.4 Action Attention Mask
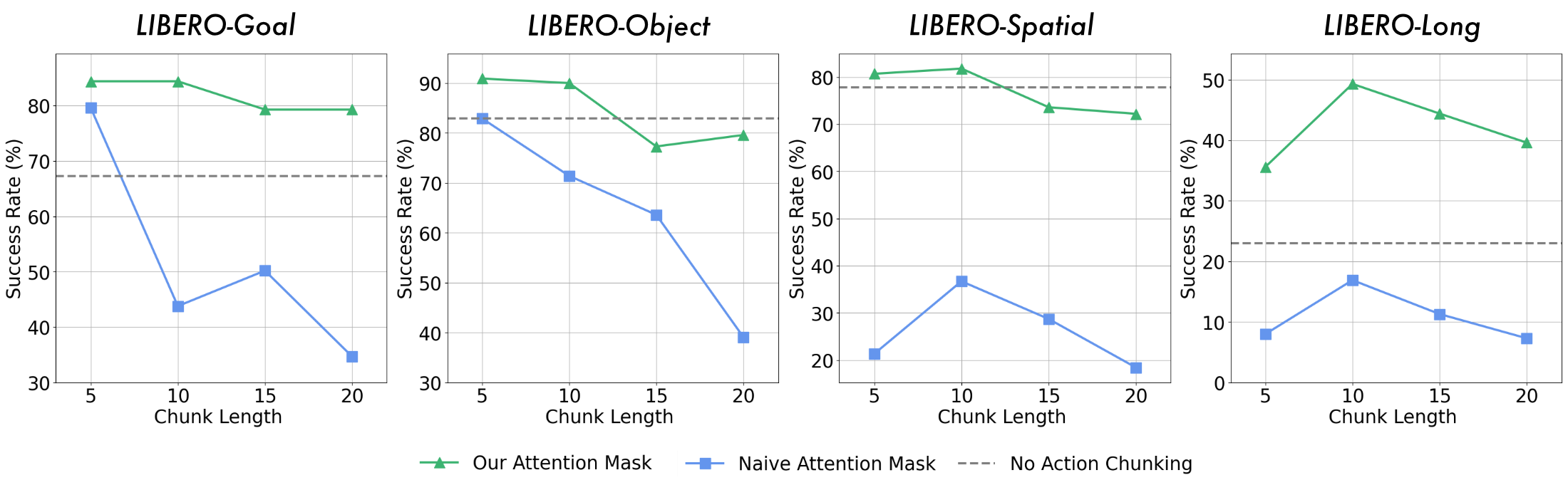
Ordinary autoregressive causal masks allow the current token to see all past tokens. This is natural for text and image generation, but it creates a problem for action chunks: subsequent action tokens will rely on previously predicted action tokens. Since basic MLLM is mainly pre-trained on text and images, action modal generalization is not as strong as text images. Once the previous action is predicted incorrectly, the error will be propagated within the chunk.
The mask strategy proposed by the author is: only text and image input are allowed to be viewed when generating the current action, and previous actions are not allowed to be viewed. In this way, $K$ actions are semantically closer to parallel prediction, and each action is directly determined by visual observation.

3.5 Forward process pseudocode
4. Mathematical forms and training objectives
4.1 Problem Formulation
Action model is answering: given historical observations and language instructions, what action should be performed currently.
$$a_t = \pi_\theta(a_t \mid o_{t-h: t}, l)$$| $a_t$ | Robot motion at time $t$. |
| $o_{t-h: t}$ | Historical image observations from $t-h$ to $t$. |
| $l$ | Natural language task instructions. |
| $\pi_\theta$ | Strategy model, also known as action model. |
World model is answering: given past observations and past actions, what will the next frame look like.
$$o_t = f_\phi(o_t \mid o_{t-h: t-1}, a_{t-h: t-1})$$| $f_\phi$ | world model. |
| $o_{t-h: t-1}$ | Sequence of image observations prior to the current frame. |
| $a_{t-h: t-1}$ | The corresponding historical action sequence. |
WorldVLA puts both capabilities into the same parametric model $M_\psi$.
$$M_\psi: \begin{cases} a_t = M_\psi^{\text{policy}}(a_t \mid o_{t-h: t}, l), \\ o_t = M_\psi^{\text{world}}(o_t \mid o_{t-h: t-1}, a_{t-h: t-1}). \end{cases}$$These are not two completely separate models, but share an autoregressive token backbone; the differences mainly come from the input sequence format, loss position and attention mask.
4.2 Joint Loss
| $\mathcal{L}_{action}$ | Cross-entropy loss on action token. |
| $\mathcal{L}_{world}$ | cross-entropy loss on generated image token. |
| $\alpha$ | The world loss weight is fixed at 0.04 in the paper experiment. |
The reason for using $\alpha$ is very practical: an action has only 7 tokens, while an image has 256 or 1024 tokens; without weighting, the number of tokens in world loss will significantly dominate the total loss.
5. Experiments and results
5.1 Experimental setup
| Project | settings |
|---|---|
| Benchmark | LIBERO, including LIBERO-Spatial, Object, Goal, Long, LIBERO-90. Spatial measures spatial relationships, Object measures object recognition, grasping and placement, Goal measures different target processes, Long contains 10 long-range tasks, and LIBERO-90 is used for pre-training. |
| Data processing | Filter failed trajectories and no-operation actions; world model evaluation requires paired video/action ground truth, so 90% trajectory is used as the training set and 10% is used as the validation set. The benchmark comparison in Table 3 was trained fairly using all available data. |
| Default hyperparameters | The default input image number of action model is $M=2$; the action chunk size of LIBERO Long is $K=10$, and the remaining three tasks are $K=5$; the default world model is $N=1$; $\alpha=0.04$. |
| Action metrics | Each task is rolled out 50 times, and the success rate is recorded in percentage. |
| World metrics | Record FVD, PSNR, SSIM, LPIPS on the validation set. |
5.2 Main benchmark results
| Continuous Action Model | Pretraining | Spatial | Object | Goal | Long | Average |
|---|---|---|---|---|---|---|
| Diffusion Policy | No | 78.3 | 92.5 | 68.3 | 50.5 | 72.4 |
| Octo | Yes | 78.9 | 85.7 | 84.6 | 51.1 | 75.1 |
| DiT Policy | Yes | 84.2 | 96.3 | 85.4 | 63.8 | 82.4 |
| OpenVLA-OFT | Yes | 96.9 | 98.1 | 95.5 | 91.1 | 95.4 |
| Discrete Action Model | Pretraining | Spatial | Object | Goal | Long | Average |
| OpenVLA | Yes | 84.7 | 88.4 | 79.2 | 53.7 | 76.5 |
| WorldVLA 256×256 | No | 85.6 | 89.0 | 82.6 | 59.0 | 79.1 |
| WorldVLA 512×512 | No | 87.6 | 96.2 | 83.4 | 60.0 | 81.8 |
The author's interpretation is that WorldVLA has surpassed discrete OpenVLA without large-scale robot pre-training. 512×512 is better than 256×256. On the one hand, Chameleon's image tokenizer and LLM components are closer to the 512×512 pre-training setting. On the other hand, high resolution provides more detailed visual information, which is important for crawling tasks.
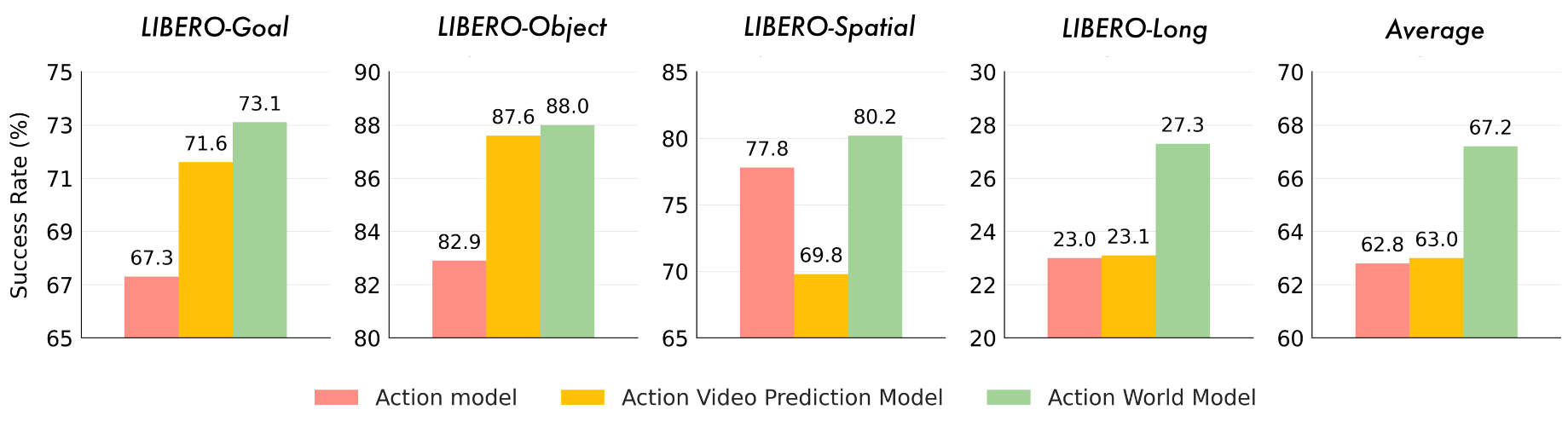
5.3 World Model helps Action Model
| Index | Action Model | World Model | Action Chunking | New Mask | Goal | Object | Spatial | Long | Average |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Yes | No | No | No | 67.3 | 82.9 | 77.8 | 23.0 | 62.8 |
| 2 | Yes | Yes | No | No | 73.1 | 88.0 | 80.2 | 27.3 | 67.2 |
| 3 | Yes | No | Yes | No | 79.6 | 82.9 | 36.7 | 16.9 | 54.0 |
| 4 | Yes | No | Yes | Yes | 84.4 | 90.9 | 81.8 | 49.3 | 76.6 |
| 5 | Yes | Yes | Yes | Yes | 85.1 | 90.9 | 84.0 | 52.4 | 78.1 |
Compared with Row 1, the average success rate of Row 2 increased from 62.8 to 67.2; compared with Row 4, the average success rate of Row 5 increased from 76.6 to 78.1. The paper explains that: the world model needs to learn the state changes caused by actions, so it will make the shared backbone better understand the physics of the environment and the meaning of actions, which will be beneficial to the action model.

5.4 Action Model helps World Model
| 10 frames | 50 frames | |||||||
|---|---|---|---|---|---|---|---|---|
| Model | FVD ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | FVD ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ |
| World Model | 250.0 | 29.62 | 90.73 | 11.97 | 718.6 | 23.98 | 83.41 | 15.60 |
| Action World Model | 255.1 | 29.77 | 90.40 | 11.94 | 674.1 | 24.30 | 83.55 | 15.44 |
On the 10-frame, the two are close, and the FVD and SSIM of the pure world model are slightly better; on the 50-frame, the action world model is better on all four indicators. The author emphasizes that action generation training can also enhance visual and behavioral pattern understanding, especially for longer sequence generation.

5.5 Action Chunking and Attention Mask
The paper observes that when the ordinary autoregressive method generates multiple continuous actions, the longer the action chunk, the easier it is to degrade performance. The reason is that subsequent actions rely too much on previously generated actions rather than being directly rooted in visual input. The new mask allows each action to rely only on text and images to avoid error propagation within the chunk.
5.6 World Model vs. Video Prediction Model
The input of the video prediction model is the current frame and task instruction, without action; the input of the world model includes action. The author compared the help of the two to the action model and found that the world model improved all evaluation tasks, while the video prediction model only helped on two tasks and had a negative impact on one task. The explanation given in the paper is: when there is no action condition, the same initial frame may correspond to multiple reasonable future frames, and the training signal is more blurred; the future state of the action-conditioned world model is more certain.
5.7 Historical image input length
| 1 frame | 2 frames | 4 frames | ||||
|---|---|---|---|---|---|---|
| Setting | SR ↑ | FPS ↑ | SR ↑ | FPS ↑ | SR ↑ | FPS ↑ |
| w/o Action Chunking | 58.4 | 2.27 | 67.3 | 1.77 | 78.7 | 1.22 |
| w/ Action Chunking | 74.0 | 3.67 | 84.4 | 3.13 | 84.7 | 2.78 |
The more history frames there are, the stronger visual context the model gets, but at the expense of FPS. With action chunking, the SR from 2 frames to 4 frames only goes from 84.4 to 84.7, so the author uses $M=2$ by default as a compromise between performance and speed.
5.8 World Model Pretraining
| Setting | Goal | Object | Spatial | Long | Average |
|---|---|---|---|---|---|
| w/o World Model Pretrain | 67.3 | 82.9 | 77.8 | 23.0 | 62.8 |
| w/ World Model Pretrain | 73.1 | 84.0 | 79.8 | 30.2 | 66.8 |
After world model pretraining, the average SR is from 62.8 to 66.8, and the Long is from 23.0 to 30.2. The author explains this as: world model pre-training forces the model to learn visual input, actions, and state transfer physics before migrating to the action model.
6. Repeat audit
6.1 Code and model
Available information: The arXiv page and source code both provide GitHub links. alibaba-damo-academy/WorldVLA. This link currently redirects to RynnVLA-002, the README shows that WorldVLA was upgraded to RynnVLA-002 on 2025-11-10, and the WorldVLA model, training code and LIBERO evaluation code were released on 2025-06-23. Still on Hugging Face WorldVLA model card, 256 and 512 resolution checkpoints are listed.
6.2 Data and preprocessing
- Use LIBERO benchmark to mainly evaluate Spatial, Object, Goal, and Long, and use LIBERO-90 as the source of pre-training related data.
- Filter unsuccessful trajectories and no-op actions, and the processing method refers to OpenVLA.
- World model evaluation requires ground-truth paired video/action data, so training/validation is divided into 90%/10% trajectories.
- The main benchmark comparison in Table 3 is trained using all available data for comparison with the previous work.
6.3 Training key hyperparameters
| Super parameters | value | Remarks |
|---|---|---|
| Backbone initialization | Chameleon | Discrete autoregressive models for unifying image understanding and generation. |
| Image resolution | 256×256 or 512×512 | A 512×512 image corresponds to 1024 image tokens, which has higher performance but a higher cost. |
| Image tokenizer codebook | 8192 | VQ-GAN tokenizer. |
| Text tokenizer vocabulary | 65, 536 | Contains image/action token. |
| Action bins | 256 bins per dimension | The bin width is determined by the training data range. |
| Action dimension | 7 tokens | 3 relative positions + 3 relative angles + 1 gripper state. |
| Historical images $M$ | Default 2 | Determined by historical frame ablation. |
| Action chunk $K$ | Long is 10, the rest are 5 | Default configuration. |
| World prediction rounds $N$ | 1 | To save calculations. |
| Loss weight $\alpha$ | 0.04 | Balancing the problem of far more image tokens than action tokens. |
6.4 Recurring gaps
- The training resources are not stated in the main text of the paper.GPU type, number, training duration, batch size, optimizer, learning rate schedule, etc. are not included in the LaTeX text.
- There are no appendices.The appendix input in the source code is commented, and no more complete superparameter list or implementation details are provided.
- The code repository has been upgraded.The WorldVLA GitHub link given in the paper currently redirects to RynnVLA-002; if you strictly reproduce the paper table, you need to confirm whether the warehouse retains the original WorldVLA version or the corresponding tag/commit.
7. Analysis, Limitations and Boundaries
7.1 The most valuable part of this paper
Judging from the paper's own evidence, the value is concentrated in two interconnected conclusions: first, world model training can improve action generation; second, action model training can also improve world prediction for longer horizons. This conclusion is not supported by concept maps alone, but is supported by action ablation tables, world model ablation tables, and visual cases.
7.2 Why the results hold up
The paper claims that three types of evidence align with each other: the main benchmark shows that WorldVLA exceeds OpenVLA in the discrete action model group; ablation clearly splits the impact of action model, world model, action chunking, and attention mask; the visualization diagram shows the typical failure modes of pure action model and pure world model. In particular, Row 3 and Row 4 of Table 4 directly illustrate that the naive autoregressive action chunk will degrade significantly, but the new mask can restore performance.
7.3 Limitations and future directions described by the author
- Data and model sizes remain scalable.The Conclusion clearly lists scaling data and model size as follow-up directions.
- Discrete image tokenizers have limited visual expression capabilities.The author points out that current tokenizers rely on discrete representations and have limited perceptual expressiveness, and a more unified and higher-quality tokenizer is needed.
- Auxiliary action heads can be added.The author believes that auxiliary action head may further improve grasping performance.
7.4 Applicable boundaries
The experimental evidence of the paper mainly comes from the LIBERO simulation benchmark; whether the model can be directly transferred to real robots, more hardware action spaces, longer task chains and more complex interactive environments, the text does not give experimental verification. The reported conclusions on generalization are therefore limited to the LIBERO setting that the paper has evaluated.
7.5 Appendix status
This arXiv source code does not contain available appendices: `\beginappendix` and `\input{sec/appendix}` in `paper.tex` are both commented, and there is no `sec/appendix.tex` in the source code Contents. Therefore, this report does not have appendix proofs, appendix superparameters or appendix supplementary experiments that can be integrated.